I’m not saying the plain-text is the best web experience. But it is an experience. Perfect if you like your browsing fast, simple, and readable. There are no
cookie banners, pop-ups, permission prompts, autoplaying videos, or garish colour schemes.
I’m certainly not the first person to do this, so I thought it might be fun to gather a list of websites which you browse in text-only mode.
…
Terence Eden’s maintaining a list of websites that are presented as, or are wholly or partially available via, plain text. Obviously my own text/plain
blog is among them, and is as far as I’m aware the only one to be entirely presented as text/plain.
Anyway, this inspired me to write a post of my own (on text/plain blog, of course!), in which I ask the question: what do we
consider plain text? Based on the sites in the list, Markdown is permissible as plain text, (for the purposes of Terence’s list), but this implies that “plain text” is a
spectrum of human-readability.
If Markdown’s fine, then presumably Gemtext would be too? How about BBCode? HTML and RTF are explicitly excluded by Terence’s rules,
but I’d argue that HTML 1.0 could be more human-readable than some of the more-sophisticated dialects of BBCode (or any Markdown that contains tables, unless those tables are laid-out
in a way that specifically facilitates human-readability)?
As I say in my post:
<-- More human-readable Less human-readable -->
|-----------|-----------|-----------|------------|-----------|-----------|-----------|-----------|
Plain text Gemtext Markdown BBCode HTML 1.0 Modern HTML RTF
This provocation is only intended to get you to think about “what does it mean for a markup language to be ‘human readable’?” Where do you draw the line?
HTTP/1 may appear simple because of several reasons: it is readable text, the most simple use case is not overly complicated and existing tools like curl and browsers help making
HTTP easy to play with.
The HTTP idea and concept can perhaps still be considered simple and even somewhat ingenious, but the actual machinery is not.
[goes on to describe several specific characteristics of HTTP that make it un-simple, under the headings:
newlines
whitespace
end of body
parsing numbers
folding headers
never-implemented
so many headers
not all methods are alike
not all headers are alike
spineless browsers
size of the specs
]
I discovered this post late, while catching up on posts in the comp.infosystems.gemini newsgroup,
but I’m glad I did because it’s excellent. Daniel Stenberg is, of course, the creator of cURL and so probably knows more about the intricacies of HTTP
than virtually anybody (including, most-likely, some of the earliest contributors to its standards), and in this post he does a fantastic job of dissecting the oft-made argument that
HTTP/1 is a “simple” protocol; based usually upon the argument that “if a human can speak it over telnet/netcat/etc., it’s simple”.
This argument, of course, glosses over the facts that (a) humans are not simple, and the things that we find “easy”… like reading a string of ASCII representations of digits and
converting it into a representation of a number… are not necessarily easy for computers, and (b) the ways in which a human might use HTTP 0.9 through 1.1 are rarely representative of
the complexities inherent in more-realistic “real world” use.
Obviously Daniel’s written about Gemini, too, and I agree with some of his points there (especially the fact that the
specification intermingles the transfer protocol and the recommended markup language; ick!). There’s a reasonable rebuttal here (although it has its faults too, like how it conflates the volume of data involved in the
encryption handshake with the processing overhead of repeated handshakes). But now we’re going way down the rabbithole and you didn’t come here to listen to me dissect
arguments and counter-arguments about the complexities of Internet specifications that you might never use, right? (Although maybe you should: you could have been reading this blog post via Gemini, for instance…)
But if you’ve ever telnet’ted into a HTTP server and been surprised at how “simple” it was, or just have an interest in the HTTP specifications, Daniel’s post is worth a read.
Got to admit, this is really cool and something I can see myself using a lot. So I installed the prerequisites:
brew install asciinema
npm install -g svg-term-cli
Then I gave it a go. I needed to use asciinema rec -f asciicast-v2 myfile.cast to record my screen into Asciinema‘s version 2 format,
because the new version 3 format isn’t yet supported by svg-term-cli (but there is at least an asciinema
convert command if you record in the “wrong” one).
Then I ran cat myfile.cast | svg-term --out myfile.cast.svg to convert that terminal recording into an SVG: I happened to be in a directory containing the source code of FreeDeedPoll.org.uk, so recorded myself running an 11ty development server with npm serve:
I’ve never been even remotely into Sex and the City. But I can’t help but love that this developer was so invested in the characters and their relationships that when
he asked himself “couldn’t all this drama and heartache have been simplified if these characters were willing to consider polyamorous relationships rather than serial
monogamy?”1,
he did the maths to optimise his hypothetical fanfic polycule:
As if his talk at !!Con 2024 wasn’t cool enough, he open-sourced the whole thing, so you’re free to try the calculator online for yourself or expand upon or adapt it to your heart’s content. Perhaps you disagree with his assessment of the
relative relationship characteristics of the characters2: tweak them and
see what the result is!
Or maybe Sex and the City isn’t your thing at all? Well adapt it for whatever your fandom is! How I Met Your Mother,Dawson’s Creek, Mamma
Mia and The L-Word were all crying out for polyamory to come and “fix” them3.
Perhaps if you’re feeling especially brave you’ll put yourself and your circles of friends, lovers, metamours, or whatever into the algorithm and see who it matches up. You never know,
maybe there’s a love connection you’ve missed! (Just be ready for the possibility that it’ll tell you that you’re doing your love life “wrong”!)
Footnotes
1 This is a question I routinely find myself asking of every TV show that presents a love
triangle as a fait accompli resulting from an even moderately-complex who’s-attracted-to-whom.
2 Clearly somebody does, based on his commit “against his will” that increases Carrie and Big’s
validatesOthers scores and reduces Big’s prioritizesKindness.
3 I was especially disappointed with the otherwise-excellent The L-Word, which
did have a go at an ethical non-monogamy storyline but bungled the “ethical” at every hurdle while simultaneously reinforcing the “insatiable bisexual” stereotype. Boo!
Anyway: maybe on my next re-watch I’ll feed some numbers into Juan’s algorithm and see what comes out…
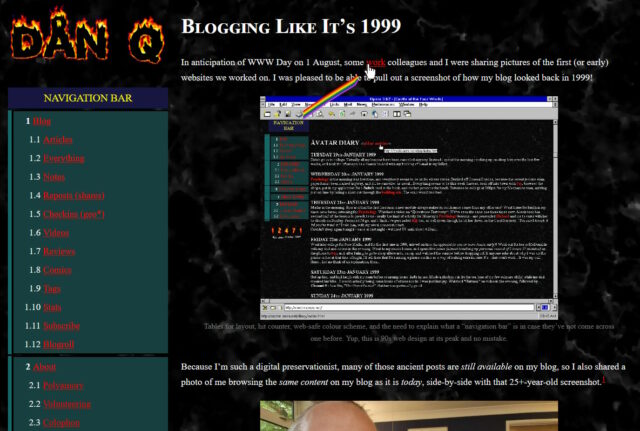
Last month I implemented an alternative mode to view this website “like it’s 1999”, complete with with cursor trails, 88×31 buttons, tables for
layout1,
tiled backgrounds, and even a (fake) hit counter.
One thing I’d have liked to do for 1999 Mode but didn’t get around to would have been to make the images look like it was the 90s, too.
Back then, many Web users only had graphics hardware capable of displaying 256 distinct colours. Across different platforms and operating systems, they weren’t even necessarily
the same 256 colours2!
But the early Web agreed on a 216-colour palette that all those 8-bit systems could at least approximate pretty well.
I had an idea that I could make my images look “216-colour”-ish by using CSS to apply an SVG filter, but didn’t implement it.
But Spencer, a long-running source of excellent blog comments, stepped up and wrote an SVG
filter for me! I’ve tweaked 1999 Mode already to use it… and I’ve just got to say it’s excellent: huge thanks, Spencer!
The filter coerces colours to their nearest colour in the “Web safe” palette, resulting in things like this:
The flat surfaces are particularly impacted in this photo (as manipulated by the CSS SVG filter described above). Subtle hues and the gradients coalesce into slabs of colour, giving
them an unnatural and blocky appearance.
Plenty of pictures genuinely looked like that on the Web of the 1990s, especially if you happened to be using a computer only capable of 8-bit colour to view a page built by
somebody who hadn’t realised that not everybody would experience 24-bit colour like they did3.
Dithering
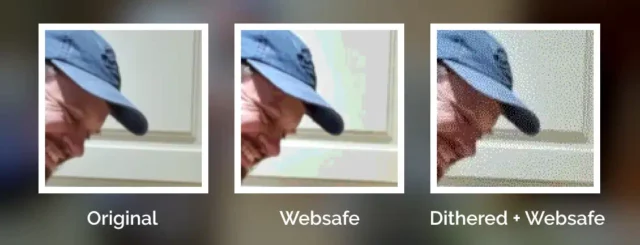
But not all images in the “Web safe” palette looked like this, because savvy web developers knew to dither their images when converting them to a limited palette.
Let’s have another go:
This image uses exactly the same 216-bit colour palette as the previous one, but looks a lot more “natural” thanks to the Floyd–Steinberg dithering algorithm.
Dithering introduces random noise to media4
in order to reduce the likelihood that a “block” will all be rounded to the same value. Instead; in our picture, a block of what would otherwise be the same colour ends up being rounded
to maybe half a dozen different colours, clustered together such that the ratio in a given part of the picture is, on average, a better approximation of the correct
colour.
The result is analogous to how halftone printing – the aesthetic of old comics and newspapers, with different-sized dots made from
few colours of ink – produces the illusion of a continuous gradient of colour so long as you look at it from far-enough away.
Zooming in makes it easy to see the noisy “speckling” effect in the dithered version, but from a distance it’s almost invisible.
The other year I read a spectacular article by Surma that explained in a very-approachable way
how and why different dithering algorithms produce the results they do. If you’ve any interest whatsoever in a deep dive or just want to know what blue noise is and why you
should care, I’d highly recommend it.
You used to see digital dithering everywhere, but nowadays it’s so rare that it leaps out as a revolutionary aesthetic when, for example, it gets used in
a video game.
Dithering can be so effective that it can even make an image “work” all the way down to 1-bit (i.e. true monochrome/black-and-white) colour. Here I’ve used Jarvis, Judice & Ninke’s dithering algorithm, which is highly-effective for picking out subtle colour differences in what would
otherwise be extreme dark and light patches, at the expense of being more computationally-expensive (to initially create) than other dithering strategies.
All of which is to say that: I really appreciate Spencer’s work to make my “1999 Mode” impose a 216-colour palette on images. But while it’s closer to the truth, it still doesn’t
quite reflect what my website would’ve looked like in the 1990s because I made extensive use of dithering when I saved my images in Web safe palettes5.
Why did I take the time to dither my images, back in the day? Because doing the hard work once, as a creator of graphical Web pages, saves time and computation (and can look
better!), compared to making every single Web visitor’s browser do it every single time.
Which, now I think about it, is a lesson that’s still true today (I’m talking to you, developers who send a tonne of JavaScript and ask my browser to generate the HTML for you
rather than just sending me the HTML in the first place!).
Footnotes
1 Actually, my “1999 mode” doesn’t use tables for layout; it pretty much only applies a
CSS overlay, but it’s deliberately designed to look a lot like my blog did in 1999, which did use tables for layout. For those too young to remember: back before CSS
gave us the ability to lay out content in diverse ways, it was commonplace to use a table – often with the borders and cell-padding reduced to zero – to achieve things that today
would be simple, like putting a menu down the edge of a page or an image alongside some text content. Using tables for non-tabular data causes problems, though: not only is
it hard to make a usable responsive website with them, it also reduces the control you have over the order of the content, which upsets some kinds of accessibility
technologies. Oh, and it’s semantically-invalid, of course, to describe something as a table if it’s not.
2Perhaps as few as 22 colours were defined the same across all
widespread colour-capable Web systems. At first that sounds bad. Then you remember that 4-bit (16 colour) palettes used to look look perfectly fine in 90s videogames. But then you
realise that the specific 22 “very safe” colours are pretty shit and useless for rendering anything that isn’t composed of black, white, bright red, and maybe one of a few
greeny-yellows. Ugh. For your amusement, here’s a copy of the image rendered using only the “very safe” 22
colours.
3 Spencer’s SVG filter does pretty-much the same thing as a computer might if asked to
render a 24-bit colour image using only 8-bit colour. Simply “rounding” each pixel’s colour to the nearest available colour is a fast operation, even on older hardware and with larger
images.
4 Note that I didn’t say “images”: dithering is also used to produce the same “more
natural” feel for audio, too, when reducing its bitrate (i.e. reducing the number of finite states into which the waveform can be quantised for digitisation), for example.
5 I’m aware that my footnotes are capable of nerdsniping Spencer, so by writing this
there’s a risk that he’ll, y’know, find a way to express a dithering algorithm as an SVG filter too. Which I suspect isn’t possible, but who knows! 😅
If you’ve been a programmer or programming-adjacent nerd1
for a while, you’ll have doubtless come across an ASCII table.
An ASCII table is useful. But did you know it’s also beautiful and elegant.
Even non-programmer-adjacent nerds may have a cultural awareness of ASCII thanks to books and
films like The Martian2.
ASCII‘s still very-much around; even if you’re transmitting modern Unicode3 the
most-popular encoding format UTF-8 is specifically-designed to be backwards-compatible with ASCII! If
you decoded this page as ASCII you’d get the gist of it… so long as you ignored the garbage
characters at the end of this sentence! 😁
History
ASCII was initially standardised in X3.4-1963 (which just rolls off the tongue, doesn’t it?) which assigned meanings to 100 of the
potential 128 codepoints presented by a 7-bit4
binary representation: that is, binary values 0000000 through 1111111:
Notably absent characters in this first implementation include… the entire lowercase alphabet! There’s also a few quirks that modern ASCII fans might spot, like the curious “up” and “left” arrows at the bottom of column 101____ and the ACK and ESC control
codes in column 111____.
If you’ve already guessed where I’m going with this, you might be interested to look at the X3.4-1963 table and see that yes, many of the same elegant design choices I’ll be talking
about later already existed back in 1963. That’s really cool!
Table
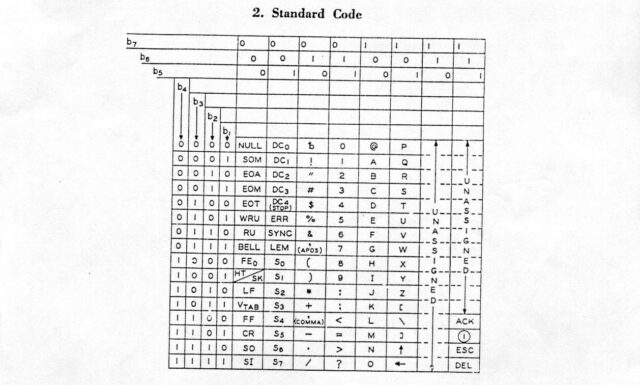
In case you’re not yet intimately familiar with it, let’s take a look at an ASCII table. I’ve
colour-coded some of the bits I think are most-beautiful:
That table only shows decimal and
hexadecimal values for each character, but we’re going to need some binary too, to really appreciate some of the things that make ASCII sublime and clever.
Control codes
The first 32 “characters” (and, arguably, the final one) aren’t things that you can see, but commands sent between machines to provide additional instructions. You might be
familiar with carriage return (0D) and line feed (0A) which mean “go back to the beginning of this line” and “advance to the next line”,
respectively5.
Many of the others don’t see widespread use any more – they were designed for very different kinds of computer systems than we routinely use today – but they’re all still there.
32 is a power of two, which means that you’d rightly expect these control codes to mathematically share a particular “pattern” in their binary representation with one another, distinct
from the rest of the table. And they do! All of the control codes follow the pattern 00_____: that is, they begin with two zeroes. So when you’re reading
7-bit ASCII6, if it starts with
00, it’s a non-printing character. Otherwise it’s a printing character.
Not only does this pattern make it easy for humans to read (and, with it, makes the code less-arbitrary and more-beautiful); it also helps if you’re an ancient slow computer system
comparing one bit of information at a time. In this case, you can use a decision tree to make shortcuts.
That there’s one exception in the control codes: DEL is the last character in the table, represented by the binary number 1111111. This
is a historical throwback to paper tape, where the keyboard would punch some permutation of seven holes to represent the ones and zeros of each character. You can’t delete
holes once they’ve been punched, so the only way to mark a character as invalid was to rewind the tape and punch out all the holes in that position: i.e. all
1s.
Space
The first printing character is space; it’s an invisible character, but it’s still one that has meaning to humans, so it’s not a control character (this sounds obvious today,
but it was actually the source of some semantic argument when the ASCII standard was first being
discussed).
Putting it numerically before any other printing character was a very carefully-considered and deliberate choice. The reason: sorting. For a computer to sort a list
(of files, strings, or whatever) it’s easiest if it can do so numerically, using the same character conversion table as it uses for all other purposes7.
The space character must naturally come before other characters, or else John Smith won’t appear before Johnny Five in a computer-sorted list as you’d expect him to.
Being the first printing character, space also enjoys a beautiful and memorable binary representation that a human can easily recognise: 0100000.
Numbers
The position of the Arabic numbers 0-9 is no coincidence, either. Their position means that they start with zero at the nice round binary value 0110000
(and similarly round hex value 30) and continue sequentially, giving:
Binary
Hex
Decimal digit (character)
011 0000
30
0
011 0001
31
1
011 0010
32
2
011 0011
33
3
011 0100
34
4
011 0101
35
5
011 0110
36
6
011 0111
37
7
011 1000
38
8
011 1001
39
9
The last four digits of the binary are a representation of the value of the decimal digit depicted. And the last digit of the hexadecimal representation
is the decimal digit. That’s just brilliant!
If you’re using this post as a way to teach yourself to “read” binary-formatted ASCII in your head,
the rule to take away here is: if it begins 011, treat the remainder as a binary representation of an actual number. You’ll probably be
right: if the number you get is above 9, it’s probably some kind of punctuation instead.
Shifted Numbers
Subtract 0010000 from each of the numbers and you get the shifted numbers. The first one’s occupied by the space character already, which is a
shame, but for the rest of them, the characters are what you get if you press the shift key and that number key at the same time.
“No it’s not!” I hear you cry. Okay, you’re probably right. I’m using a 105-key ISO/UK QWERTY keyboard and… only four of the nine digits 1-9 have their shifted variants
properly represented in ASCII.
That, I’m afraid, is because ASCII was based not on modern computer keyboards but on the shifted
positions of a Remington No. 2 mechanical typewriter – whose shifted layout was the closest compromise we could find as a standard at the time, I imagine. But hey, you got to learn
something about typewriters today, if that’s any consolation.
Bonus fun fact: early mechanical typewriters omitted a number 1: it was expected that you’d use the letter I. That’s fine for printed work, but not much help for computer-readable
data.
Letters
Like the numbers, the letters get a pattern. After the @-symbol at 1000000, the uppercase letters all begin
10, followed by the binary representation of their position in the alphabet. 1 = A = 1000001, 2 = B = 1000010, and so on up to 26 = Z =
1011010. If you can learn the numbers of the positions of the letters in the alphabet, and you can count
in binary, you now know enough to be able to read any ASCII uppercase letter that’s been encoded as
binary8.
And once you know the uppercase letters, the lowercase ones are easy too. Their position in the table means that they’re all exactly 0100000higher than the uppercase variants; i.e. all the lowercase letters begin 11! 1 = a = 1100001, 2 = b = 1100010, and 26 = z =
1111010.
If you’re wondering why the uppercase letters come first, the answer again is sorting: also the fact that the first implementation of ASCII, which we saw above, was put together before it was certain that computer systems would need separate
character codes for upper and lowercase letters (you could conceive of an alternative implementation that instead sent control codes to instruct the recipient to switch case, for
example). Given the ways in which the technology is now used, I’m glad they eventually made the decision they did.
Beauty
There’s a strange and subtle charm to ASCII. Given that we all use it (or things derived from it)
literally all the time in our modern lives and our everyday devices, it’s easy to think of it as just some arbitrary encoding.
But the choices made in deciding what streams of ones and zeroes would represent which characters expose a refined logic. It’s aesthetically pleasing, and littered with
historical artefacts that teach us a hidden history of computing. And it’s built atop patterns that are sufficiently sophisticated to facilitate powerful processing while being coherent
enough for a human to memorise, learn, and understand.
Footnotes
1 Programming-adjacent? Yeah. For example, geocachers who’ve ever had to decode a
puzzle-geocache where the coordinates were presented in binary (by which I mean: a binary representation of ASCII) are “programming-adjacent nerds” for the purposes of this discussion.
2 In both the book and the film, Mark Watney divides a circle around the recovered
Pathfinder lander into segments corresponding to hexadecimal digits 0 through F to allow the rotation of its camera (by operators on Earth) to transmit pairs of 4-bit words.
Two 4-bit words makes an 8-bit byte that he can decode as ASCII, thereby effecting a means to
re-establish communication with Earth.
3 Y’know, so that you can type all those emoji you love so much.
4 ASCII is often thought of as an 8-bit code, but it’s not: it’s 7-bit. That’s why virtually every ASCII message you see starts every octet with a zero. 8-bits is a convenient number for transmission purposes (thanks
mostly to being a power of two), but early 8-bit systems would be far more-likely to use the 8th bit as a parity check, to help
detect transmission errors. Of course, there’s also nothing to say you can’t just transmit a stream of 7-bit characters back to back!
5 Back when data was sent to teletype printers these two characters had a distinct
different meaning, and sometimes they were so slow at returning their heads to the left-hand-side of the paper that you’d also need to send a few null bytes e.g. 0D 0A
00 00 00 00 to make sure that the print head had gotten settled into the right place before you sent more data: printers didn’t have memory buffers at this point! For
compatibility with teletypes, early minicomputers followed the same carriage return plus line feed convention, even when outputting text to screens. Then to maintain backwards
compatibility with those systems, the next generation of computers would also use both a carriage return and a line feed character to mean “next line”. And so,
in the modern day, many computer systems (including Windows most of the time, and many Internet protocols) still continue to use the combination of a carriage return
and a line feed character every time they want to say “next line”; a redundancy build for a chain of backwards-compatibility that ceased to be relevant decades ago but which
remains with us forever as part of our digital heritage.
6 Got 8 binary digits in front of you? The first digit is probably zero. Drop it. Now
you’ve got 7-bit ASCII. Sorted.
7 I’m hugely grateful to section 13.8 of Coded Character Sets, History and
Development by Charles E. Mackenzie (1980), the entire text of which is available freely
online, for helping me to understand the importance of the position of the space character within the ASCII character set. While most of what I’ve written in this blog post were things I already knew, I’d never fully grasped
its significance of the space character’s location until today!
8 I’m sure you know this already, but in case you’re one of today’s lucky 10,000 to discover that the reason we call the majuscule and minuscule letters “uppercase” and “lowercase”, respectively, dates to 19th
century printing, when moveable type would be stored in a box (a “type case”) corresponding to its character type. The “upper” case was where the capital letters would typically be
stored.
I’ve tried a variety of unusual strategies to combat email spam over the years.
Here are some of them (each rated in terms the geekiness of its implementation and its efficacy), in case you’d like to try any yourself. They’re all still in use in some form or
another:
Spam filters
Geekiness: 1/10
Efficacy: 5/10
Your email provider or your email software probably provides some spam filters, and they’re probably pretty good. I use Proton‘s
and, when I’m at my desk, Thunderbird‘s. Double-bagging your spam filter only slightly reduces the amount of spam
that gets through, but increases your false-positive rate and some non-spam gets mis-filed.
A particular problem is people who email me for help after changing their name on FreeDeedPoll.org.uk, probably
because they’re not only “new” unsolicited contacts to me but because by definition many of them have strange and unusual names (which is why they’re emailing me for help in the first
place).
Frankly, spam filters are probably enough for many people. Spam filtering is in general much better today than it was a decade or two ago. But skim the other suggestions in
case they’re of interest to you.
Unique email addresses
Geekiness: 3/10
Efficacy: 8/10
If you give a different email address to every service you deal with, then if one of them misuses it (starts spamming you, sells your data, gets hacked, whatever), you can just block
that one address. All the addresses come to the same inbox, for your convenience. Using a catch-all means that you can come up with addresses on-the-fly: you can even fill a paper
form with a unique email address associated with the company whose form it is.
On many email providers, including the ever-popular GMail, you can do this using plus-sign notation. But if you want to take your unique addresses to the
next level and you have your own domain name (which you should), then you can simply redirect all email addresses on that
domain to the same inbox. If Bob’s Building Supplies wants your email address, give them bobs@yourname.com, which works even if Bob’s website erroneously doesn’t
accept email addresses with plus signs in them.
This method actually works for catching people misusing your details. On one occasion, I helped a band identify that their mailing list had been hacked. On another, I caught a
dodgy entrepreneur who used the email address I gave to one of his businesses without my consent to send marketing information of a different one of his businesses. As a bonus, you can
set up your filtering/tagging/whatever based on the incoming address, rather than the sender, for the most accurate finding, prioritisation, and blocking.
Also, it makes it easy to have multiple accounts with any of those services that try to use the uniqueness of email addresses to prevent you from doing so. That’s great if, like me, you
want to be in each of three different Facebook groups but don’t want to give Facebook any information (not even that you exist at the intersection of those groups).
Signed unique email addresses
Geekiness: 10/10
Efficacy: 2/10
Unique email addresses introduce two new issues: (1) if an attacker discovers that your Dreamwidth account has the email address dreamwidth@yourname.com, they can
probably guess your LinkedIn email, and (2) attackers will shotgun “likely” addresses at your domain anyway, e.g. admin@yourname.com,
management@yourname.com, etc., which can mean that when something gets through you get a dozen copies of it before your spam filter sits up and takes notice.
What if you could assign unique email addresses to companies but append a signature to each that verified that it was legitimate? I came up with a way to do this and
implemented it as a spam filter, and made a mobile-friendly webapp to help generate the necessary signatures. Here’s what it looked like:
The domain directs all emails at that domain to the same inbox.
If the email address is on a pre-established list of valid addresses, that’s fine.
Otherwise, the email address must match the form of:
A string (the company name), followed by
A hyphen, followed by
A hash generated using the mechanism described below, then
The @-sign and domain name as usual
The hashing algorithm is as follows: concatenate a secret password that only you know with a colon then the “company name” string, run it through SHA1, and truncate to the first eight characters. So if my password were swordfish1 and I were generating a password for Facebook, I’d go:
Therefore, the email address is facebook-977046ce@myname.com
If any character of that email address is modified, it becomes invalid, preventing an attacker from deriving your other email addresses from a single point (and making it
hard to derive them given multiple points)
I implemented the code, but it soon became apparent that this was overkill and I was targeting the wrong behaviours. It was a fun exercise, but ultimately pointless. This is the one
method on this page that I don’t still use.
Honeypots
Geekiness: 8/10
Efficacy: ?/10
A honeypot is a “trap” email address. Anybody who emails it get aggressively marked as a spammer to help ensure that any other messages they send – even to valid email
addresses – also get marked as spam.
I litter honeypots all over the place (you might find hidden email addresses on my web pages, along with text telling humans not to use them), but my biggest source of
honeypots is formerly-valid unique addresses, or “guessed” catch-all addresses, which already attract spam or are otherwise compromised!
I couldn’t tell you how effective it is without looking at my spam filter’s logs, and since the most-effective of my filters is now outsourced to Proton, I don’t have easy access to
that. But it certainly feels very satisfying on the occasions that I get to add a new address to the honeypot list.
Instant throwaways
Geekiness: 5/10
Efficacy: 6/10
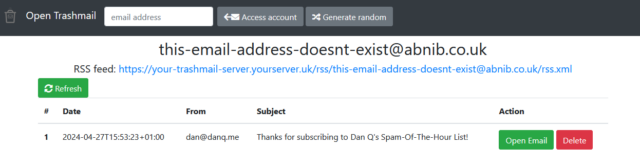
OpenTrashmail is an excellent throwaway email server that you can deploy in seconds with Docker, point some MX records at, and be all set! A throwaway email server gives you an infinite number of unique email addresses, like other solutions described
above, but with the benefit that you never have to see what gets sent to them.
If you offer me a coupon in exchange for my email address, it’s a throwaway email address I’ll give you. I’ll make one up on the spot with one of my (several) trashmail domains at the
end of it, like justgivemethedamncoupon@danstrashmailserver.com. I can just type that email address into OpenTrashmail to see what you sent me, but then I’ll never check it
again so you can spam it to your heart’s content.
As a bonus, OpenTrashmail provides RSS feeds of inboxes, so I can subscribe to any email-based service using my feed reader,
and then unsubscribe just as easily (without even having to tell the owner).
Summary
With the exception of whatever filters your provider or software comes with, most of these options aren’t suitable for regular folks. But you’re only a domain name (assuming you don’t
have one already) away from being able to give unique email addresses to everybody you deal with, and that’s genuinely a game-changer all by itself and well worth considering, in my
opinion.
I clearly nerdsniped Terence at least a little when I asked whether a blog necessarily had to be HTML, because he went on to implement a WordPress theme that delivers content entirely in plain text.
theunderground.blog‘s content, with the exception of its homepage, is delivered entirely through an XML Atom feed. Atom feed entries do require <title>s, of course, so that’s not the strongest counterexample!
This blog is available over several media other than the Web. For example, you can read this blog post:
We’ve looked at plain text, which as a format clearly does not have to have a title. Let’s go one step further and implement it. What we’d need is:
A webserver configured to deliver plain text files by preference, e.g. by adding directives like index index.txt; (for Nginx).5
An index page listing posts by date and URL. Most browser won’t render these as “links” so users will have to copy-paste
or re-type them, so let’s keep them short,
Pages for each post at those URLs, presumably without any kind of “title” (just to prove a point), and
An RSS feed: usually I use RSS as shorthand for all feed
types, but this time I really do mean RSS and not e.g. Atom because RSS, strangely, doesn’t require that an <item> has a <title>!
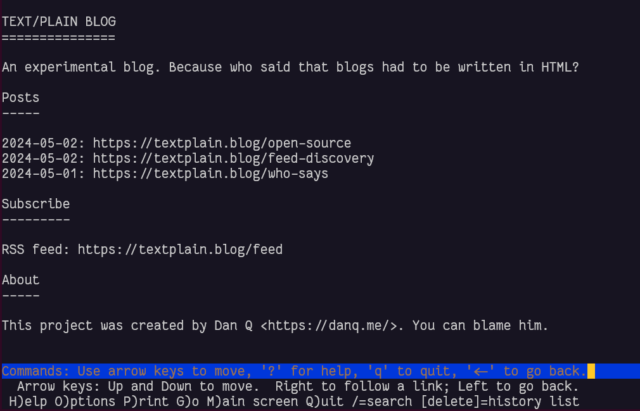
Unlike other sites, I didn’t need to test textplain.blog in Lynx to
know it’d work well. But I did anyway.
In the end I decided it’d benefit from being automated as sort-of a basic flat-file CMS, so I wrote it in PHP. All requests are routed by the webserver to the program, which determines whether they’re a request for the homepage, the RSS feed, or a valid individual post, and responds accordingly.
It annoys me that feed
discovery doesn’t work nicely when using a Link: header, at least not in any reader I tried. But apart from that, it seems pretty solid, despite its limitations. Is this,
perhaps, an argument for my.well-known/feedsproposal?
I think I might be more-prone to nerd sniping when I’m travelling.
Last week, a coworker pointed out an unusually-large chimney on the back of a bus depot and I lost sleep poring over 50s photos of Dutch building sites to try to work out if it was
original.
When a boat tour guide told me that the Netherlands used to have a window tax, I fell down a rabbit hole of how it influenced local architecture and why the influence was different in the UK.
Why does travelling make me more-prone to nerd sniping? Maybe I should see if there’s any likely psychological effect that might cause that…
I’ve got a (now four-year-old) Unraid NAS called Fox and I’m a huge fan. I particularly love the fact that Unraid can work not only as a NAS, but also as a fully-fledged Docker appliance, enabling me to easily install and maintain all manner of applications.
There isn’t really a generator attached to Fox, just a UPS battery backup. The sign was liberated from our shonky home electrical system.
I was chatting this week to a colleague who was considering getting a similar setup, and he seemed to be taking notes of things he might like to install, once he’s got one. So I figured
I’d round up five of my favourite things to install on an Unraid NAS that:
Don’t require any third-party accounts (low dependencies),
Don’t need any kind of high-powered hardware (low specs), and
Provide value with very little set up (low learning curve).
It’d have been cooler if I’d have secretly written this blog post while sitting alongside said colleague (shh!). But sadly it had to wait until I was home.
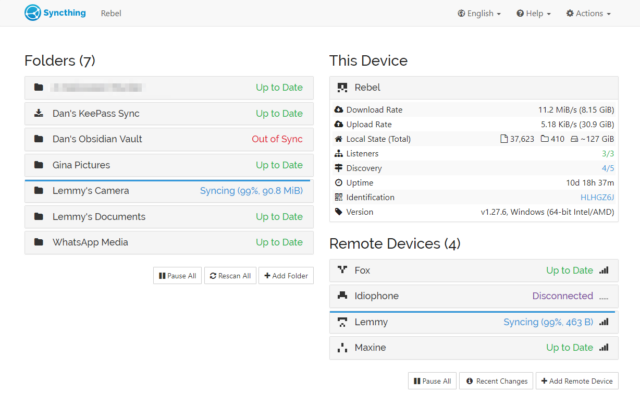
Syncthing’s just an awesome piece of set-and-forget software that facilitates file synchronisation between all of your devices and can also form part of a backup strategy.
Here’s the skinny: you install Syncthing on several devices, then give each the identification key of another to pair them. Now you can add folders on each and “share” them with the
others, and the two are kept in-sync. There’s lots of options for power users, but just as a starting point you can use this to:
Manage the photos on your phone and push copies to your desktop whenever you’re home (like your favourite cloud photo sync service, but selfhosted).
Keep your Obsidian notes in-sync between all your devices (normally costs $4/month).1
Get a copy of the documents from all your devices onto your NAS, for backup purposes (note that sync’ing alone, even with
versioning enabled, is not a good backup: the idea is that you run an actual backup from your NAS!).
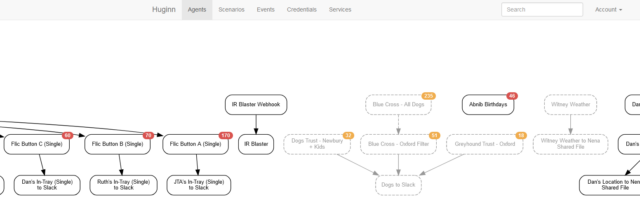
You know IFTTT? Zapier? Services that help you to “automate” things based on inputs and outputs. Huginn’s like that, but selfhosted.
Also: more-powerful.
When we first started looking for a dog to adopt (y’know, before we got this derper), I set up Huginn watchers to monitor the websites of several
rescue centres, filter them by some of our criteria, and push the results to us in real-time on Slack, giving us an edge over other prospective puppy-parents.
The learning curve is steeper than anything else on this list, and I almost didn’t include it for that reason alone. But once you’ve learned your way around its idiosyncrasies and
dipped your toe into the more-advanced Javascript-powered magic it can do, you really begin to unlock its potential.
It couples well with Home Assistant, if that’s your jam. But even without it, you can find yourself automating things you never expected to.
Many of these suggested apps benefit well from you exposing them to the open Web rather than just running them on your LAN,
and an RSS reader is probably the best example (you want to read your news feeds when you’re out and about, right?). What you
need for that is a reverse proxy, and there are lots of guides to doing it super-easily, even if you’re not on a static IP
address.2.
Alternatively you can just VPN in to your home: your router might be able to arrange this, or else Unraid can do it for you!
You know how sometimes you need to give somebody your email address but you don’t actually want to. Like: sure, I’d like you to email me a verification code for this download, but I
don’t trust you not to spam me later! What you need is a disposable email address.3
How do you feel about having infinite email addresses that you can make up on-demand (without even having access to a computer), subscribe to by RSS, and never have to see unless you specifically want to.
You just need to install Open Trashmail, point the MX records of a few domain names or subdomains (you’ve got some spare domain names
lying around, right? if not; they’re pretty cheap…) at it, and it will now accept email to any address on those domains. You can make up addresses off the top of your head,
even away from an Internet connection when using a paper-based form, and they work. You can check them later if you want to… or ignore them forever.
Couple it with an RSS reader, or Huginn, or Slack, and you can get a notification or take some action when an email arrives!
Need to give that escape room your email address to get a copy of your “team photo”? Give them a throwaway, pick up the picture when you get home, and then forget you ever gave it
to them.
Company give you a freebie on your birthday if you sign up their mailing list? Sign up 366 times with them and write a Huginn workflow that puts “today’s” promo code into your
Obsidian notetaking app (Sync’d over Syncthing) but filters out everything else.
Suspect some organisation is selling your email address on to third parties? Give them a unique email address that you only give to them and catch them in a honeypot.
It isn’t pretty, but… it doesn’t need to be! Nobody actually sees the admin interface except you anyway.
Plus, it’s just kinda cool to be able to brand your shortlinks with your own name, right? If you follow only one link from this post, let it be to watch this video
that helps explain why this is important: danq.link/url-shortener-highlights.
I run many, many other Docker containers and virtual machines on my NAS. These five aren’t even the “top five” that I
use… they’re just five that are great starters because they’re easy and pack a lot of joy into their learning curve.
And if your NAS can’t do all the above… consider Unraid for your next NAS!
Footnotes
1 I wrote the beginnings of this post on my phone while in the Channel Tunnel and then
carried on using my desktop computer once I was home. Sync is magic.
2 I can’t share or recommend one reverse proxy guide in particular because I set my own up
because I can configure Nginx in my sleep, but I did a quick search and found several that all look good so I imagine you can do the same. You don’t have to do it on day one, though!
Ever wondered why Oxford’s area code is 01865? The story is more-complicated than you’d think.
As a child, I was told that city STD codes were usually associated to the letters that appear on some telephones… but that
wouldn’t make any sense for Oxford’s code!
I’ll share the story on my blog, of course. But before then, I’ll be telling it from the stage of the Jericho Tavern at 21:15 on Wednesday 17 April as
my third(?) appearance at Oxford Geek Nights! So if you’re interested in learning about some of the quirks of UK telephone numbering
history, I can guarantee that this party’s the only one to be at that Wednesday night!
Not your jam? That’s okay: there’s plenty of more-talented people than I who’ll be speaking, about subjects as diverse as quantum computing with QATboxen, bringing your D&D experience to stakeholder management (!), video games
without screens, learnings from the Horizon scandal, and whatever Freyja Domville means by The Unreasonable Effectiveness of the Scientific Method (but I’m seriously excited by that title).
Anyway: I hope you’ll be coming along to Oxford Geek Nights 57 next month, if not to hear me witter on about the
fossils in our telecommunications networks then to enjoy a beer and hear from the amazing speakers I’ll be sharing the stage with. The event’s always a blast, and I’m looking forward to
seeing you there!
This post is also available as an article. So
if you'd rather read a conventional blog post of this content, you can!
This is a video version of my blog post, Length Extension Attack. In it, I talk through the theory of length extension
attacks and demonstrate an SHA-1 length extension attack against an (imaginary) website.
This post is also available as a video. If you'd
prefer to watch/listen to me talk about this topic, give it a look.
Prefer to watch/listen than read? There’s a vloggy/video version of this post in which I explain all the
key concepts and demonstrate an SHA-1 length extension attack against an imaginary site.
I understood the concept of a length traversal
attack and when/how I needed to mitigate them for a long time before I truly understood why they worked. It took until work provided me an opportunity to play with one in practice (plus reading Ron Bowes’ excellent article on the subject) before I really grokked it.
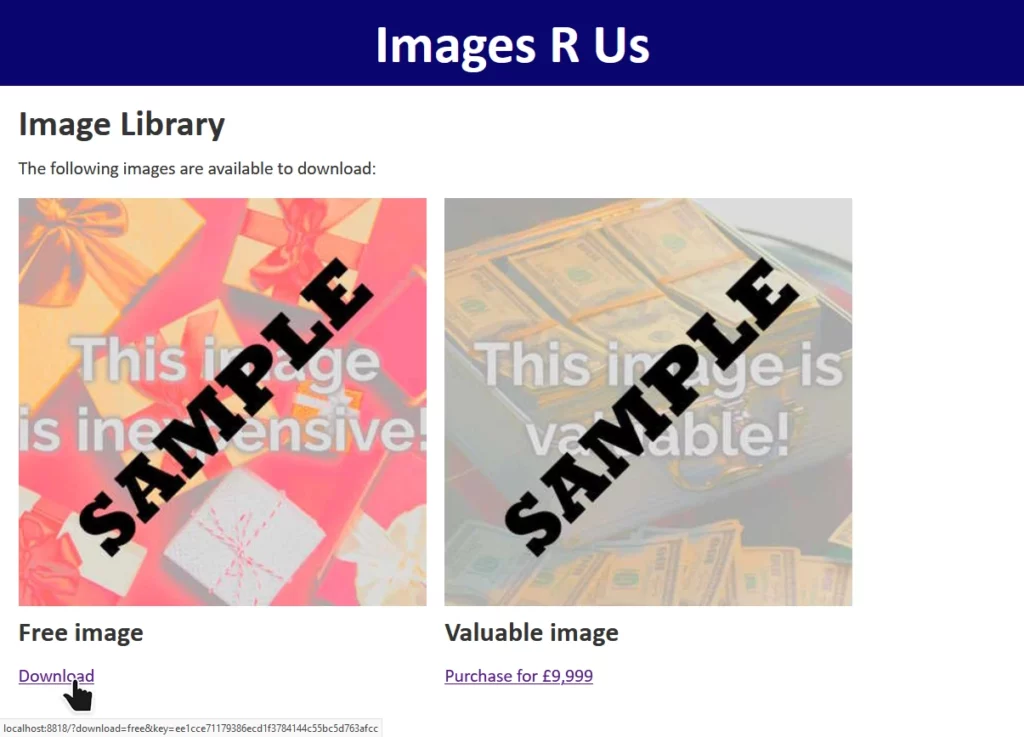
For the demonstration, I’ve built a skeletal stock photography site whose download links are protected by a hash of the link parameters, salted using a secret string stored securely
on the server. Maybe they let authorised people hotlink the images or something.
You can check out the code and run it using the instructions in the
repository if you’d like to play along.
Using hashes as message signatures
The site “Images R Us” will let you download images you’ve purchased, but not ones you haven’t. Links to the images are protected by a SHA-1 hash1, generated as follows:
The nature of hashing algorithms like SHA-1 mean that even a small modification to the inputs, e.g. changing one character in
the word “free”, results in a completely different output hash which can be detected as invalid.
When a “download” link is generated for a legitimate user, the algorithm produces a hash which is appended to the link. When the download link is clicked, the same process is followed
and the calculated hash compared to the provided hash. If they differ, the input must have been tampered with and the request is rejected.
Without knowing the secret key – stored only on the server – it’s not possible for an attacker to generate a valid hash for URL parameters of the attacker’s choice. Or is it?
Changing download=free to download=valuable invalidates the hash, and the request is denied.
Actually, it is possible for an attacker to manipulate the parameters. To understand how, you must first understand a little about how SHA-1 and its siblings actually work:
SHA-1‘s inner workings
The message to be hashed (SECRET_KEY + URL_PARAMS) is cut into blocks of a fixed size.2
The final block is padded to bring it up to the full size.3
A series of operations are applied to the first block: the inputs to those operations are (a) the contents of the block itself, including any padding, and (b) an initialisation
vector defined by the algorithm.4
The same series of operations are applied to each subsequent block, but the inputs are (a) the contents of the block itself, as before, and (b) the output of the previous
block. Each block is hashed, and the hash forms part of the input for the next.
The output of running the operations on the final block is the output of the algorithm, i.e. the hash.
SHA-1 operates on a single block at a time, but the output of processing each block acts as part of the input of the one that
comes after it. Like a daisy chain, but with cryptography.
In SHA-1, blocks are 512 bits long and the padding is a 1, followed by as many 0s as is necessary,
leaving 64 bits at the end in which to specify how many bits of the block were actually data.
Padding the final block
Looking at the final block in a given message, it’s apparent that there are two pieces of data that could produce exactly the same output for a given function:
The original data, (which gets padded by the algorithm to make it 64 bytes), and
A modified version of the data, which has be modified by padding it in advance with the same bytes the algorithm would; this must then be followed by an
additional block
A “short” block with automatically-added padding produces the same output as a full-size block which has been pre-populated with the same data as the padding would
add.5In the case where we insert our own “fake” padding data, we can provide more message data after the padding and predict the overall hash. We can do this because
we the output of the first block will be the same as the final, valid hash we already saw. That known value becomes one of the two inputs into the function for the block that
follows it (the contents of that block will be the other input). Without knowing exactly what’s contained in the message – we don’t know the “secret key” used to salt it – we’re
still able to add some padding to the end of the message, followed by any data we like, and generate a valid hash.
Therefore, if we can manipulate the input of the message, and we know the length of the message, we can append to it. Bear that in mind as we move on to the other half
of what makes this attack possible.
Parameter overrides
“Images R Us” is implemented in PHP. In common with most server-side scripting languages,
when PHP sees a HTTP query string full of key/value pairs, if
a key is repeated then it overrides any earlier iterations of the same key.
Many online sources say that this “last variable matters” behaviour is a fundamental part of HTTP, but it’s not: you can
disprove is by examining $_SERVER['QUERY_STRING'] in PHP, where you’ll find the entire query string.
You could even implement your own query string handler that instead makes the first instance of each key the canonical one, if you really wanted.6It’d be tempting to simply override the download=free parameter in the query string at “Images R Us”, e.g. making it
download=free&download=valuable! But we can’t: not without breaking the hash, which is calculated based on the entire query string (minus the &key=...
bit).
But with our new knowledge about appending to the input for SHA-1 first a padding string, then an extra block containing our
payload (the variable we want to override and its new value), and then calculating a hash for this new block using the known output of the old final block as the
IV… we’ve got everything we need to put the attack together.
Putting it all together
We have a legitimate link with the query string download=free&key=ee1cce71179386ecd1f3784144c55bc5d763afcc. This tells us that somewhere on the server, this is
what’s happening:
I’ve drawn the secret key actual-size (and reflected this in the length at the bottom). In reality, you might not know this, and some trial-and-error might be necessary.7If we pre-pad the string download=free with some special characters to replicate the padding that would otherwise be added to this final8 block, we can add a second block containing
an overriding value of download, specifically &download=valuable. The first value of download=, which will be the word free followed by
a stack of garbage padding characters, will be discarded.
And we can calculate the hash for this new block, and therefore the entire string, by using the known output from the previous block, like this:
The URL will, of course, be pretty hideous with all of those special characters – which will require percent-encoding – on the end of the word ‘free’.
Doing it for real
Of course, you’re not going to want to do all this by hand! But an understanding of why it works is important to being able to execute it properly. In the wild, exploitable
implementations are rarely as tidy as this, and a solid comprehension of exactly what’s happening behind the scenes is far more-valuable than simply knowing which tool to run and what
options to pass.
That said: you’ll want to find a tool you can run and know what options to pass to it! There are plenty of choices, but I’ve bundled one called hash_extender into my example, which will do the job pretty nicely:
which algorithm to use (sha1), which can usually be derived from the hash length,
the existing data (download=free), so it can determine the length,
the length of the secret (16 bytes), which I’ve guessed but could brute-force,
the existing, valid signature (ee1cce71179386ecd1f3784144c55bc5d763afcc),
the data I’d like to append to the string (&download=valuable), and
the format I’d like the output in: I find html the most-useful generally, but it’s got some encoding quirks that you need to be aware of!
hash_extender outputs the new signature, which we can put into the key=... parameter, and the new string that replaces download=free, including
the necessary padding to push into the next block and your new payload that follows.
Unfortunately it does over-encode a little: it’s encoded all the& and = (as %26 and %3d respectively), which isn’t what we
wanted, so you need to convert them back. But eventually you end up with the URL:
http://localhost:8818/?download=free%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%e8&download=valuable&key=7b315dfdbebc98ebe696a5f62430070a1651631b.
Disclaimer: the image you get when you successfully exploit the test site might not actually be valuable.
And that’s how you can manipulate a hash-protected string without access to its salt (in some circumstances).
Mitigating the attack
The correct way to fix the problem is by using a HMAC in place
of a simple hash signature. Instead of calling sha1( SECRET_KEY . urldecode( $params ) ), the code should call hash_hmac( 'sha1', urldecode( $params ), SECRET_KEY
). HMACs are theoretically-immune to length extension attacks, so long as the output of the hash function used is
functionally-random9.
Ideally, it should also use hash_equals( $validDownloadKey, $_GET['key'] ) rather than ===, to mitigate the possibility of a timing attack. But that’s another story.
Footnotes
1 This attack isn’t SHA1-specific: it works just as well on many other popular hashing algorithms too.
2 SHA-1‘s blocks are 64 bytes
long; other algorithms vary.
3 For SHA-1, the padding bits
consist of a 1 followed by 0s, except the final 8-bytes are a big-endian number representing the length of the message.
4 SHA-1‘s IV is 67452301 EFCDAB89 98BADCFE 10325476 C3D2E1F0, which you’ll observe is little-endian counting from 0 to
F, then back from F to 0, then alternating between counting from 3 to 0 and C to F. It’s
considered good practice when developing a new cryptographic system to ensure that the hard-coded cryptographic primitives are simple, logical, independently-discoverable numbers like
simple sequences and well-known mathematical constants. This helps to prove that the inventor isn’t “hiding” something in there, e.g. a mathematical weakness that depends on a
specific primitive for which they alone (they hope!) have pre-calculated an exploit. If that sounds paranoid, it’s worth knowing that there’s plenty of evidence that various spy
agencies have deliberately done this, at various points: consider the widespread exposure of the BULLRUN programme and its likely influence on Dual EC
DRBG.
5 The padding characters I’ve used aren’t accurate, just representative. But there’s the
right number of them!
6 You shouldn’t do this: you’ll cause yourself many headaches in the long run. But you
could.
7 It’s also not always obvious which inputs are included in hash generation and how
they’re manipulated: if you’re actually using this technique adversarily, be prepared to do a little experimentation.
8 In this example, the hash operates over a single block, but the exact same principle
applies regardless of the number of blocks.
9 Imagining the implementation of a nontrivial hashing algorithm, the predictability of
whose output makes their HMAC vulnerable to a length extension attack, is left as an exercise for the reader.


























{kind=link}