Jeremy Keith posted his salary history last week. I absolutely agree with him that employers exploit
the information gap created by opaque salary advertisement, and I think that our industry of software engineering is especially troublesome for this.
So I’m joining him (and others) in choosing to share my salary history. I’ve set up a new page for that purpose, but here’s the summary of its
initial state:
Understand
A few understandings and caveats:
For most of my career I’ve described myself as a “Full-Stack Web Applications Developer”, but I’ve worked outside of every one of those words and my job titles have often been more
like “CMS Developer” or “Senior Engineer (Security)”.
My specialisms and “hot areas” are security engineering, web standards, performance, and accessibility.
When I worked multiple roles in a year, I’ve tried to capture that, but there’ll be some fuzziness around the edges.
The salaries are rounded slightly to make nice readable numbers.
I’ve not always worked full-time; all salaries are translated into “full-time equivalent”1.
I’ve only included jobs that fit into my software engineering career2.
If the table below looks out-of-date then I’ve probably just forgotten to update it. Let me know!
Ad-hoc and hard to estimate.
Alongside full-time study.
What does that look like?
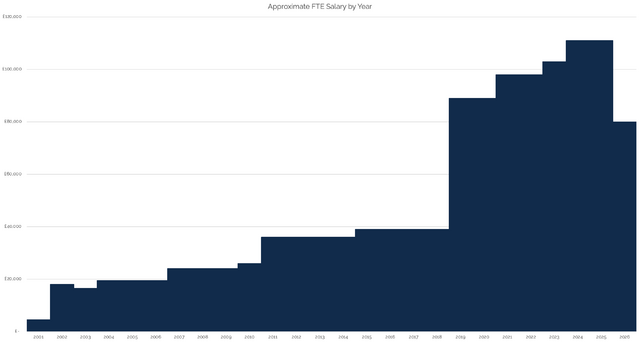
I drew a graph, but I don’t like it. Mostly because I don’t see my salary as a “goal” to aim for or some kind of “score”.
It’s gone up; it’s gone down; but I’ve always been more-motivated by what I’m working on, with whom, and for what purpose than I have been on how much I get paid for it3.
But if you want to see:
I’m not sure to what degree my career looks typical or not. But I guess I also don’t care! My motivations are probably different than most (a little-more idealistic, a little-less
capitalistic), I’d guess.
Footnotes
1 i.e. what I’d have earned if I had worked full-time
2 That summer back in college that I worked in a factory building striplight fittings
doesn’t appear, for example!
3 Pro-tip if you’re looking at my CV and pitching me an opportunity:
mention what you expect to pay, sure, but if you’re trying to win me over then tell me about the problems I’ll be solving and how that’ll make the world a better
place. That’s how you motivate me to accept your offer!
Mike Cook wrote a provocative blog post this weekend; an
anti-preservationist argument for video games. The essence of his arguments seem to boil down to:
Emphasising creation over preservation is liberating, as demonstrated by the imagination in the livecoding community.
Archiving without intensive curation is building an emotional or intellectual safety net you never expect to be used.
Digital preservation is a lossy process: effort spent on accurately preserving some media is at the expense of other media, whose lossy preservation paints in inaccurate picture of
what is lost.
Recreation, rather than strict preservation, ensures the continuity of the most culturally-important parts of games
Art is important for culture, and it’s important for nostalgia, but it’s hard to draw the line between where one purpose ends and the other begins.
He concludes to say:
60 games are released on Steam every day.
There are 294 game jams active on Steam as I write this.
Preserve nothing. Make more.
To make is to preserve.
Let games die.
Digital preservationism
Philosophically-speaking, there’s no doubt that I am a digital preservationist. I argue against unnecessary URI changes. I donate to
The Internet Archive. Back at the Bodleian, I used to carve out free time from project work to spend time making sure the University’s “older”
exhibition websites could be made to survive1. My approach to running out of hard drive space is to buy more hard drives. Even my blog retains
content going back into the last millennium2!
My reimplementation of Pong had several distinct differences from the original… but to a layperson – for whom Pong are the target audience! – those differences are
irrelevant. To what level fidelity matters depends on many factors, and the biggest problem is that we don’t know what those factors are until it’s time to retrieve these historical
media.
This screenshot isn’t from the original site but from my homage to it. More on that later.
This makes it seem like I’m very much on the side of recreation, rather than preservation, but that’s not the case. In both of these projects I started by disassembling the
original works.
That I chose to make them accessible to a modern audience by reimplementation rather than by emulation was an artistic choice. I opted for lower fidelity by making something
mildly-transformative. I chose to appeal to the widest possible audience, at the expense of presenting an experience that was totally in-keeping with the original.
But I couldn’t have done that without access to the originals. Had I recreated Pong from memory rather than from re-playing it, I’d have doubtless introduced
inconsistencies that would have “felt wrong” to people whose memories of the game, while fundamentally accurate, differed from mine. Had I recreated Axe Feather without
first coming up with a mechanism to extract and reformat the video clips in the original I’d have failed to tap into the specific nostalgia of some of its users, which was tied to the
specific actor who performed in it3.
So I guess it’s important to me that somebody is preserving these things. So that I can use them to create new things. I stand for preservation for culture’s
sake, so that I personally can enjoy the benefits for nostalgia’s sake.
For all that I feel like I’m making the case for “preserve everything; work out what’s important later”, Mike’s argument gives me an uncomfortable cognitive dissonance. Because
I’ve also come to discover a joy in the ephemeral, too.
I don’t know who’ll preserve ARCC, with its permanently-capped 500-playerbase limit, but I’m happy that I’ll probably always hold
the highscore on driving/racing minigame M1.
Increasingly, I’m okay with just taking the experience of something with me. It bothers me that my memory is fallible and that I can’t necessarily recreate a digital
experience whose technology has been lost to time, but I am, for the most part, okay with it.
Some of the best gaming experiences I’ve ever had are impossible to “capture” in an archive anyway. They were conversations over the tabletop roleplaying table, or moments of tension
resulting from a videogame’s emergent gameplay, or random occurrences unlikely to be replicated. Those get preserved in my memory alone, retold as stories with
gradually-decreasing accuracy as new memories take their place.
That said…
Who decides what games get preserved?
I feel like the decision about what to preserve and how should be in the hands of the audience of a piece of art, not its creators. If a videogame (or film, or book, or
whatever) is culturally-significant enough to warrant a high-fidelity preservation, it ought to be ultimately up to the members of that culture to make that decision!
Transport Tycoon Deluxe met that bar, and it’s possible to play both faithful recreations or modern reimplementations (the latter having excellent new features)
courtesy of the OpenTTD project4.
But modern videogames are, perhaps, getting harder to preserve. Always-online features, insidious DRM, digital distribution, live updates, and games-as-a-service streaming
all shift the balance of power more-firmly into the hands of publishers5
rather than players. It’s already hard to play a randomly-selected thirty-year-old videogame today; I reckon it’ll be almost impossible to do the same thirty years
hence.
Saying “let games die” feels a bit like giving up to that inevitability. Like saying to the slimier publishers “it’s okay, we didn’t care about keeping that anyway” when they shut down
servers or remotely kill games. I know that’s not what Mike’s saying, but it could be wilfully misinterpreted that way.
Anyway: I don’t have a nice conclusion to any of this. Just a lot of mixed-up feelings.
2 Even where those writings don’t really represent me well any more.
3 It turns out that, for a significant number of folks who are mostly younger-than-me,
this advertisement represented a kind of sexual awakening, based on some of the comments and emails I’ve received about it!
4 Which I’ve also donated too. Turns out I’m happy to invest in both pure
preservation and in spiritual-successor reimplementation!
5 Supposing that Sonic Rumble Party somehow wasn’t a catastrophic
pay-to-win nightmare and somehow was deemed culturally-significant… how would you go about archiving it? Without Sega/Sonic Team’s consent, you’d be totally out of luck.
[a quote from Ed Catmull’s book Creativity Inc.] made me think a lot about the early days of Gutenberg and the huge
resistance it had in the community, including causing the fork of ClassicPress. Now that we’re much further along there’s a pretty widespread acceptance of Gutenberg, and it’s
responsible for the vast majority of all WP posts and pages made, however if we had taken a vote for whether it should happen or not, it probably wouldn’t have ever gotten off the
ground.
What’s funny is if you go back even further, using a visual WYSIWYG editor in the first place was very controversial, and many people didn’t want the classic editor brought into
WordPress.
Long-term WordPresser here; I remember when 2.0 integrated TinyMCE and it was absolutely necessary to ensure that raw HTML editing
remained an option, clear and up-front. Which I’m glad of: I probably hit raw HTML about once a month when I’m blogging, to this day!
I was among those who strongly resisted Gutenberg. Nowadays I use it every day! But my primary personal blog, which was already almost six years old when it migrated to WordPress 1.2
back in 2004, still uses the classic editor. I enjoy that I have the freedom to do that.
When we talk about open source meaning freedom, this is the kind of thing we mean. Years ago, I was in charge of the CMS for a major academic
institution when the company behind that CMS made a gradual and concerted effort to become less-open-source. That CMS didn’t have the ecosystem
and community around it that WordPress has, and so no forks took off, and so my employer got locked-in to upgrading to a new version that was mostly-closed-source and was in some ways
inferior. Ugh.
(Incidentally, I got them off that CMS: they’re now using a mixture of WordPress and Drupal for most of their
systems. Open source won.)
Change isn’t always good. But open source provides the freedom to embrace change in the way that suits you best.
Setting up and debugging your FreshRSS XPath Scraper
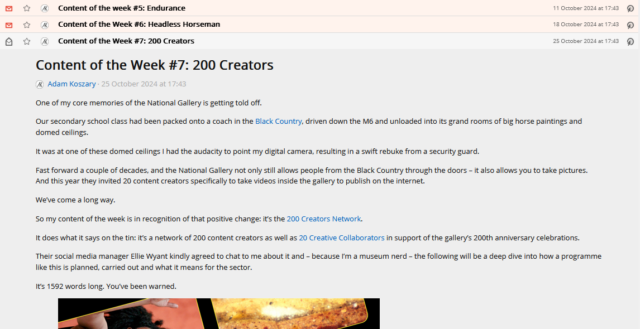
Okay, so here’s Adam’s blog. I’ve checked, and there’s no RSS feed1, so it’s time to start planning my XPath Scraper. The first thing I want to do is to find some way of identifying the “posts” on the page. Sometimes people use
solid, logical id="..." and class="..." attributes, but I’m going to need to use my browser’s “Inspect Element” tool to check:
If you’re really lucky, the site you’re scraping uses an established microformat like h-feed. No such luck here, though…
The next thing that’s worth checking is that the content you’re inspecting is delivered with the page, and not loaded later using JavaScript. FreshRSS’s XPath Scraper works with the raw
HTML/XML that’s delivered to it; it doesn’t execute any JavaScript2,
so I use “View Source” and quickly search to see that the content I’m looking for is there, too.
New developers are sometimes surprised to see how different View Source and Inspect Element’s output can be3.
This looks pretty promising, though.
Now it’s time to try and write some XPath queries. Luckily, your browser is here to help! If you pop up your debug console, you’ll discover that you’re probably got a predefined
function, $x(...), to which you can path a string containing an XPath query and get back a NodeList of the element.
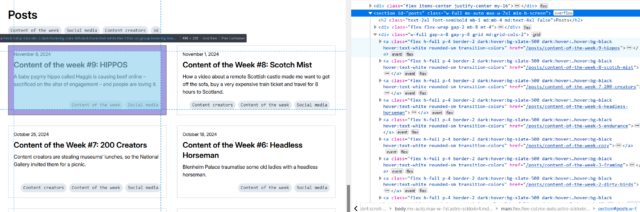
First, I’ll try getting all of the links inside the #posts section by running $x( '//*[@id="posts"]//a' ) –
Once you’ve run a query, you can expand the resulting array and hover over any element in it to see it highlighted on the page. This can be used to help check that you’ve found what
you’re looking for (and nothing else).
In my first attempt, I discovered that I got not only all the posts… but also the “tags” at the top. That’s no good. Inspecting the URLs of each, I noticed that the post URLs all
contained /posts/, so I filtered my query down to $x( '//*[@id="posts"]//a[contains(@href, "/posts/")]' ) which gave me the
expected number of results. That gives me //*[@id="posts"]//a[contains(@href, "/posts/")]
as the XPath query for “news items”:
I like to add the rules I’ve learned to my FreshRSS configuration as I go along, to remind me what I still need to find.
Obviously, this link points to the full post, so that tells me I can put ./@href as the “item link” attribute in FreshRSS.
Next, it’s time to see what other metadata I can extract from each post to help FreshRSS along:
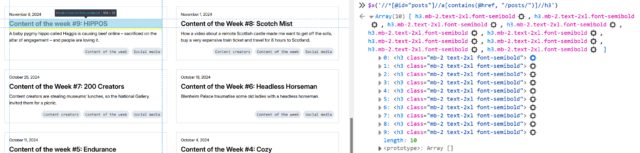
Inspecting the post titles shows that they’re <h3>s. Running $x( '//*[@id="posts"]//a[contains(@href, "/posts/")]//h3' ) gets them.
Within FreshRSS, everything “within” a post is referenced relative to the post, so I convert this to descendant::h3 for my “XPath (relative to item) for Item
Title:” attribute.
I was pleased to see that Adam’s using a good accessible heading cascade. This also makes my XPathing easier!
Inspecting within the post summary content, it’s… not great for scraping. The elements class names don’t correspond to what the content is4: it looks like Adam’s using a utility class library5.
Everything within the <a> that we’ve found is wrapped in a <div class="flex-grow">. But within that, I can see that the date is
directly inside a <p>, whereas the summary content is inside a <p>within a<div class="mb-2">. I don’t want my code to
be too fragile, and I think it’s more-likely that Adam will change the class names than the structure, so I’ll tie my queries to the structure. That gives me
descendant::div/p for the date and descendant::div/div/p for the “content”. All that remains is to tell FreshRSS that Adam’s using F j, Y as his
date format (long month name, space, short day number, comma, space, long year number) so it knows how to parse those dates, and the feed’s good.
If it’s wrong and I need to change anything in FreshRSS, the “Reload Articles” button can be used to force it to re-load the most-recent X posts. Useful if you need to tweak things. In
my case, I’ve also set the “Article CSS selector on original website” field to article so that the full post text can be pulled into my reader rather than having to visit
the actual site. Then I’m done!
Yet another blog I can read entirely from my feed reader, despite the fact that it doesn’t offer a “feed”.
Takeaways
Use Inspect Element to find the elements you want to scrape for.
Use $x( ... ) to test your XPath expressions.
Remember that most of FreshRSS’s fields ask for expressions relative to the news item and adapt accordingly.
If you make a mistake, use “Reload Articles” to pull them again.
2 If you need a scraper than executes JavaScript, you need something more-sophisticated. I
used to use my very own RSSey for this purpose but nowadays XPath Scraping is sufficient so I don’t bother any more, but RSSey might be a
good starting point for you if you really need that kind of power!
3 If you’ve not had the chance to think about it before: View Source shows you the actual
HTML code that was delivered from the web server to your browser. This then gets interpreted by the browser to generate the DOM, which might result in changes to it: for example,
invalid elements might be removed, ambiguous markup will have an interpretation applied, and so on. The DOM might further change as a result of JavaScript code, browser plugins, and
whatever else. When you Inspect Element, you’re looking at the DOM (represented “as if” it were HTML), not the actual underlying HTML
4 The date isn’t in a <time> element nor does it have a class like
.post--date or similar.
5 I’ll spare you my thoughts on utility class libraries for now, but they’re… not
positive. I can see why people use them, and I’ve even used them myself before… but I don’t think they’re a good thing.
Has anyone informed work/colleagues about being ENM and how was it received?
I’ve informed a few colleagues but I am considering informing my team as part of my Team Champion and EDI role.
…
I’ve been “out” at every one of the employers1 since I entered into my first open/nonmonogamous
relationship a couple of decades ago.
I didn’t do so immediately: in fact, I waited almost until the point that coming out was an academic necessity! The point at which it was
only a matter of time before somebody thought they’d caught us “cheating”… or else because I didn’t want to have to lie to coworkers about e.g. from whom a romantic gift might have
come.
I guess I’ll squeeze in “come out to colleagues” in between the project planning meeting and working on rolling out the server upgrades.
Here’s how it went to be “out” at each of the three full-time jobs I’ve held over that period:
We lived and worked in and around a small town, and in our small tight-knit team we all had a reasonable handle on what was going on in one another’s personal lives. By the time I was
actively in a relationship with Ruth (while still in a relationship with Claire, whom all my coworkers had met at e.g. office parties and the
like), it just seemed prudent to mention it, as well as being honest and transparent.
This photograph – featuring some of my coworkers – was taken in 2005. At that point, they probably all thought of me as a regular, normal person. At least, as far as my relationship
structure was concerned. Not in any other way. Obviously.
It went fine. And it made Monday watercooler conversations about “who what I did at the weekend” simpler. Being a small team sharing a single open-plan office meant that I
was able to mention my relationship status to literally the entire company at once, and everybody took it with a shrug of noncommittal acceptance.
The Bodleian Libraries was a much bigger beast, and in turn a part of the massive University of Oxford. It was big enough to have a “LGBT+ Staff”
network within its Equality and Diversity unit, within which – because of cultural intersections2
– I was able to meet a handful of other poly folk at the University.
This motley crew were exactly as warm and accepting a bunch as you could ask for.
I mentioned very early on – as soon as it came up organically – the structure of the relationship I was in, and everybody was cool (or failing that, at least professional) about it.
Curious coworkers asked carefully-crafted questions, and before long (and following my lead) my curious lifestyle choices were as valid a topic for light-hearted jokes as anything else
in that fun and gossipy office.
And again: it paid-off pragmatically, especially when I took parental leave after the birth of each of our two kids3.
It also helped defuse a situation when I was spotted by a more-distant coworker on my way back from a lunchtime date with a lover who wasn’t Ruth, and my confused colleague
introduced herself to the woman that she assumed must’ve been the partner she’d heard about. When I explained that no, this is a different person I’m seeing my
colleague seemed taken aback, and I was glad to be able to call on a passing coworker who knew me better to back me up in my assertion that no, this wasn’t just me trying to lie to
cover some illicit work affair! Work allies are useful.
I’ve been with Automattic for four and a half years now, and this time around I went one step further in telling potential teammates about my relationship structure by mentioning it in
my “Howdymattic” video – a video introduction new starters are encouraged to record to say hi to the rest of the company4.
Some full-on MSPaint grade titling made it into that video, didn’t it?
A convenient side-effect of this early coming-out was that I found myself immediately inducted into the “polymatticians” group – a minor diversity group within Automattic, comprising a
massive 1.2% of the company, who openly identify as engaging in nonmonogamous relationships5!
That was eye-opening. Not only does Automattic have a stack of the regular inclusivity groups you might expect from a big tech company (queer, Black, women, trans,
neurodiverse) and a handful of the less-common ones (over-40s, cancer survivors, nondrinkers, veterans), they’ve also got a private group for those of us who happen to be both
Automatticians and in (or inclined towards) polyamorous relationships. Mind blown.
My relationship structure’s been… quietly and professionally accepted. It doesn’t really come up (why would it? in a distributed company it has even less-impact on anything than it did
in my previous non-distributed roles)… outside of the “polymatticians” private space.
In summary: I can recommend being “out” at work. So long as you’d feel professionally safe to do so: relationship structure isn’t necessarily a protected characteristic
(it’s complicated), and even if it were you might be careful about mentioning it in some environments. It’s great to have the transparency to not have to watch your words when a
coworker asks about “your partner”. Plus being free to be emotionally honest at work is just good for your mental wellbeing, in my opinion! If you trust your coworkers, be honest with
them. If you don’t… perhaps you need to start looking for a better job?
Footnotes
1 I’m not counting my freelance work during any of those periods, although I’ve been
pretty transparent with them too.
2 Let’s be clear: most queer folks, just like most straight folks, seem to be
similarly-inclined towards monogamy. But ethnical non-monogamy in various forms seems to represent a larger minority within queer communities than outside them. There’s all kinds of
possible reasons for this, and smarter people than me have written about them, but personally I’m of the opinion that, for many, it stems from the fact that by the time you’re
societally-forced to critically examine your relationships, you might as well go the extra mile and decide whether your relationship structure is right for you too. In other
words: I suspect that cis hetro folks would probably have a proportional parity of polyamory if they weren’t saturated with media and cultural role models that show them what their
relationship “should” look like.
3 Unwilling to lie, I made absolutely clear that I was neither the father of either of
them nor the husband of their mother (among other reasons, the law prohibits Ruth from marrying me on account of being married to JTA), but pointed out that my contract merely stipulated that I was the partner of a birth parent, which was something I’d made completely
clear since I first started working there. I’m not sure if I was just rubber-stamped through the University’s leave process as a matter of course or if they took a deeper look at me
and figured “yeah, we’re not going to risk picking a legal fight with that guy”, but I got my leave granted.
4 If you enjoyed my “Howdymattic”, you’ll probably also love the outtakes.
One of my favourite parts of my former role at
the Bodleian Libraries was getting to work on exhibitions. Not just because it was varied and interesting work, but because it let me get
up-close to remarkable artifacts that
most people never even get the chance to see.
We also got to play dollhouse, laying out exhibitions in miniature.
A personal favourite of mine are the Herculaneum Papyri. These charred scrolls were part of a private library near
Pompeii that was buried by the eruption of Mount Vesuvius in 79 CE. Rediscovered from 1752, these ~1,800 scrolls were distributed to
academic institutions around the world, with the majority residing in Naples’ Biblioteca Nazionale Vittorio Emanuele III.
The second time I was in an exhibition room with the Bodleian’s rolled-up Herculaneum Papyri was for an exhibition specifically about humanity’s relationship with volcanoes.
As you might expect of ancient scrolls that got buried, baked, and then left to rot, they’re pretty fragile. That didn’t stop Victorian era researchers trying a variety of techniques to
gently unroll them and read what was inside.
Unrolling the scrolls tends to go about as well as you’d anticipate. A few have been deciphered this way. Many others have been damaged or destroyed by unrolling efforts.
Like many others, what I love about the Herculaneum Papyri is the air of mystery. Each could be anything from a lost religious text to, I don’t
know, somebody’s to-do list (“buy milk, arrange for annual service of chariot, don’t forget to renew volcano insurance…”).1
In recent years, we’ve tried “virtually unrolling” the scrolls using a variety of related technologies. And – slowly – we’re getting there.
X-ray tomography is amazing, but it’s hampered by the fact that the ink and paper have near-equivalent transparency to x-rays. Plus, all the other problems.
But new techniques are helping to overcome them.
So imagine my delight when this week, for the first time ever, a complete word was extracted from
one of the carbonised, still-rolled-up scrolls from Herculaneum. Something that would have seemed inconceivable to the historians who first discovered and catalogued the scrolls is now
possible, thanks to their careful conservation over the years along with the steady advance of technology.
The word appears to be “purple”: either πορφύ̣ρ̣ας̣ (a noun, similar to how we might say “pass the purple [pen]” or πορφυ̣ρ̣ᾶς̣: if we can decode more words around it then it which
might become clear from the context.
Anyway, I thought that was exciting news so I wanted to share.
You know that strange moment when you see your old coworkers on YouTube doing a cover of an Adam and the Ants song? No: just me?
Still good to see the Bodleian put a fun spin on promoting their lockdown-friendly reader services. For some reason they’ve marked this video “not embeddable” (?) in their YouTube
settings, so I’ve “fixed” the copy above for you.
A former colleague talks about some of the artefacts from the Bodleian’s collections that didn’t make it into the Talking Maps exhibition (one of the last exhibitions I got to work on during my time there; indeed, you’ll see plenty of
pictures from it in my post about making digital interactives). I was particularly pleased by the Soviet map of Oxford, but everything Nick presents
in this video is pretty awesome: it’s a great reminder that for every fantastic exhibition you see at a good museum, there’s always at least as much material “behind the
scenes” that you’re missing out on!
Eight years, six months, and one week after I started at the Bodleian, we’ve gone our separate ways. It’s genuinely been the nicest place I’ve
ever worked; the Communications team are a tightly-knit, supportive, caring bunch of diverse misfits and I love them all dearly, but the time had come for me to seek my next challenge.
My imminent departure began to feel real when I turned over my badge and gun card and keys.
Being awesome as they are, my team threw a going-away party for me, complete with food from Najar’s Place, about which I’d previously
raved as having Oxford’s best falafels. I wasn’t even aware that Najar’s place did corporate catering… actually, it’s possible that they don’t and this was just a (very)
special one-off.
Start from the left, work towards the right.
Following in the footsteps of recent team parties, they’d even gotten a suitably-printed cake with a picture of my face on it. Which meant that I could leave my former team with one
final magic trick, the never-before-seen feat of eating my own head (albeit in icing form).
Of course, the first thing I was asked to do was to put a knife through my own neck.
As the alcohol started to work, I announced an activity I’d planned: over the weeks prior I’d worked to complete but not cash-in reward cards at many of my favourite Oxford eateries and
cafes, and so I was now carrying a number of tokens for free burritos, coffees, ice creams, smoothies, pasta and more. Given that I now expect to spend much less of my time in the city
centre I’d decided to give these away to people who were able to answer challenge questions presented – where else? – on our digital signage
simulator.
Among the games was Play Your Shards Right, a game of “higher/lower” played across London’s skyscrapers.
I also received some wonderful going-away gifts, along with cards in which a few colleagues had replicated my long tradition of drawing cartoon animals in other people’s cards, by
providing me with a few in return.
“Wait… all of these Javascript frameworks look like they’re named after Pokémon!”
Later, across the road at the Kings’ Arms and with even more drinks inside of me, I broke out the lyrics I’d half-written to a rap song about my time at the
Bodleian. Because, as I said at the time, there’s nothing more-Oxford than a privileged white boy rapping about how much he’d loved his job at a library (video also available on QTube [with lyrics] and on Videopress).
It’s been an incredible 8½ years that I’ll always look back on with fondness. Don’t be strangers, guys!
My department’s made far too much use out of that “Sorry you’re leaving” banner, this year. Here’s hoping they get a stabler, simpler time next year.
I’ve just cleared out my desk at the Bodleian in anticipation of my imminent departure and discovered that I’ve managed to
successfully keep not only my P60s but also every payslip I’ve ever received in the 8½ years I’ve worked there. At a stretch, I
might just end up requiring those for the current tax year but I can’t conceive of any reason I’ll ever need the preceding hundred or so of them, so the five year-old and I
shredded them all.
If you’ve ever wanted to watch five solid minutes of cross-cut shredding shot from an awkwardly placed mobile phone camera, this is the video for you. Everybody else can move along.
As part of the preparing to leave the Bodleian I’ve been revisiting a lot of the documentation I’ve written over the last eight
years. It occurred to me that I’ve never written publicly about how the Bodleian’s digital signage/interactives actually work; there are possible lessons to learn.
The Bodleian‘s digital signage is perhaps more-diverse, both in terms of technology and audience, than that of most organisations. We’ve got
signs in areas that are exclusively reader-facing to help students and academics find what they’re looking for, signs in publicly accessible rooms that advertise and educate, and signs
in gallery spaces upon which we try to present engaging and often-interactive content to support exhibitions.
Getting an extra touchscreen for the office for prototyping/user testing purposes was great, even when it wasn’t showing MLP: FiM.
Throughout those three spheres, we’ve routinely delivered a diversity of content (let’s just ignore the countdown clock, for now…). Traditional
directional signage, advertisements, games, digital exhibitions, interpretation, feedback surveys…
In the vast majority of cases – and this is where the Bodleian’s been unusual (though certainly not unique) among cultural sector institutions – we’ve created
those in-house rather than outsourcing them.
Using off-the-shelf technology also allows the Bodleian to in-house much of their hardware maintenance, as a secondary part of other job roles. Singing into your screwdriver remains
optional, though.
To do this economically – the volume of work on interactive signage is inconsistent throughout the year – we needed to align the skills required with skills used elsewhere in the
organisation. To do this, we use the web as our medium! Collectively, the Bodleian’s Digital Communications team already had at least some experience in programming, web design, graphic
design, research, user testing, copyediting etc.: the essential toolkit for web application development.
Whether you were playing Pong on the video wall at the back or testing your Middle-earth knowledge on the touchscreen at the front… behind the
scenes you were interacting with a web page I wrote.
By shifting our digital signage platform to lean heavily on web technologies, we were able to leverage talented people we already had to produce things that we might otherwise
have had to outsource. This, in turn, meant that more exhibitions and displays get digital enhancement, on a shorter turnaround.
It also means that there’s a tighter integration between exhibition content and content for web and social media: it’s easier for us to re-use content across multiple platforms.
Sometimes we’ve even made our digital interactives, or adapted version of them, available directly online, allowing our exhibitions to reach people that can’t get to our physical spaces
at all.
Because we’re able to produce our own content on-demand, even our smaller, shorter-duration displays can have hands-on digital interactives associated with them.
On to the technology! We’re using a real mixture of tech: when it’s donated or reclaimed from previous projects (and when the bidding and acquisition processes are, well… as you’d
expect at the University of Oxford), you learn not to say no to freebies. Our fleet includes:
Samsung Android tablets with freestanding kiosk frames. We run the excellent-value Kiosk Browser Lockdown app on
these, which loads on boot and prevents access to anything but a specified website.
OnelanNTBs connected to a mixture of
touch and non-touch screens, wall-mounted or in kiosk frames. We use Onelan’s standard digital signage features as well as – for interactive content – their built-in touch-capable web
browser.
Dell PCs of the standard variety supplied by University IT services, connected to wall-mounted touch screens, running Google Chrome in Kiosk Mode. More on this below.
The browsers’ responsive simulators are invaluable when we’re targeting signage at five (!) different resolutions.
When you’re developing content for a very small number of browsers and a limited set of screen sizes, you quickly learn to throw a lot of “best practice” web development out of the
window. You’ll never come across a text browser or screen reader, so alt-text doesn’t matter. You’ll never have to rescale responsively, so you might as well absolutely-position almost
everything. The devices are all your own, so you never need to ask permission to store cookies. And because you control the platform, you can get away with making configuration tweaks
to e.g. allow autoplaying videos with audio. Coming from a conventional web developer background to producing digital signage content makes feels incredibly lazy.
Helping your users see your interactive as “app-like” rather than “web-like” encourages them to feel comfortable engaging with it in ways uncharacteristic of web pages. In our Shakespeare’s Dead interactive, for example, we started the experience in the middle of a long horizontally-scrolling “page”, which might
feel very unusual in a conventional browser.
Using Chrome to run digital signage requires, in the Bodleian’s case, a couple of configuration tweaks and the right command-line switches. We use:
chrome://flags/#overscroll-history-navigation – disabling this prevents users from triggering “back”/”forward” by swiping with two fingers
chrome://flags/#pull-to-refresh – disabling this prevents the user from triggering a “refresh” by scrolling up beyond the top of the page (this only happens on some
kinds of devices)
chrome://flags/#system-keyboard-lock – we don’t use attached keyboards, but if you do, you might want to set this flag so you can use the keyboard.lock()
API to intercept e.g. ALT+F4 so users can’t escape the application
running on startup with e.g. chrome --kiosk --noerrdialogs --allow-file-access-from-files --disable-touch-drag-drop --incognito https://example.com/some/url
Kisok mode makes the browser run fullscreen and prevents e.g. opening additional tabs, giving an instant “app-like” experience. As we don’t have keyboards attached to our
digital signage, this also prevents visitors from closing Chrome.
Turning off error dialogs reduces the risk that an error will result in an unslightly message to the user.
Enabling “file access from files” allows content hosted at file:// addresses to access content at other file:// addresses, which makes it possible to write “offline” sites
(sometimes useful where we’re serving large videos or on previous occasions when WiFi has been shaky) that can still take advantage of features like the Fetch API.
Unless you need drag-and-drop, it’s simpler to disable it; this prevents a user long-press-and-dragging an image around the screen.
Incognito mode ensures that the browser doesn’t remember what site was showing last time it ran; our computers often end up switched off at the wall at the end of the day, and
without this the browser will offer to load the site it had open last time, when it runs.
We usually host our interactives directly on the web, at “secret” addresses, and this is generally preferable to us as we can more-easily make on-the-fly adjustments to
content (plus it makes it easier to hook up analytic tools).
Be sure to test the capabilities of your hardware! Our Onelan NTBs, unlike your desktop PCs, can’t handle multitouch input, which
affects the design of our user interfaces for these devices.
Meanwhile, in the application’s CSS code, we set * { user-select: none; } to prevent the user from highlighting
text by selecting it with their finger. We also make heavy use of absolutely-sized/positioned, overflow: hidden blocks to ensure that scrollbars never appear, and
CSS animations to make content feel dynamic and to draw attention to particular elements.
There’s no substitute for good testing. And there’s no stress-testing quite like letting a 5 year-old loose on your work.
Altogether, this approach gives the Bodleian the capability to produce engaging interactive content at low cost and using the existing skills of their digital and exhibitions teams.
It’s not an approach that would work for every cultural institution: in particular, some of the Bodleian’s sister institutions already
outsource the technical parts of their web work, and so don’t have the expertise in-house to share with a web-powered digital signage solution.
A few minor CSS tweaks to make the buttons finger-friendly and our Halloween game Shadows Out Of
Time, which I’d already made web-friendly, was touchscreen-ready too. I wonder if they’ll get this one out again, this
Halloween?
But for those museums that can fit into this model – or can adapt to do so in future – using the web to produce interactive digital content and digital signage is a highly
cost-effective way to engage with visitors, even (or especially!) when dealing with short-lived and/or rotating displays.
It’s also been among my favourite parts of my job at the Bod these last 8½ years, and I’m sure I’ll miss it!
I wasn’t sure that my whiteboard at the Bodleian, which reminds my co-workers exactly how many days I’ve got left in the office, was
attracting as much attention as it needed to. If I don’t know what my colleagues don’t know about how I do my job, I can’t write it into my handover notes.
Tick, tick, tick, tick, boom.
So I repurposed a bit of digital signage in the office with a bit of Javascript to produce a live countdown. There’s a lot of code out there to produce countdown timers, but mine
had some very specific requirements that nothing else seems to “just do”. Mine needed to:
Only count down during days that I’m expected to be in the office.
Only count down during working hours.
Carry on seamlessly after a reboot.
[insert Countdown theme song here]
Naturally, I’ve open-sourced it in case anybody else needs one, ever. It’s pretty basic, of course,
because I’ve only got a hundred and fifty-something hours to finish a lot of things so I only wanted to throw a half hour at this while I ate my lunch! But if you want one,
just put in an array of your working dates, the time you start each day, and the number of hours in your workday, and it’ll tick away.
One of the best things about working atThe Bodleian Libraries, University of Oxford? Pretending to be a PhD student for a photo shoot! Watch out for me
appearing in a website near you…
My team and I do get up to some unusual stuff, it’s true. I took part in this photoshoot, too:
I’m absolutely not above selling out myself and my family for the benefit of some stock photos for the University, it seems. The sharp-eyed might even have spotted the kids in this video promoting the Ashmolean or a recent tweet by the Bodleian…
I recently announced that I’d accepted a job offer from Automattic and I’ll be
starting work there in October. As I first decided to apply for the job 128 days ago – a nice round number – I thought I’d share with you my journey over the
last 128 days.
Automattic conduct their entire interview process via Slack online chat. I’ve still never spoken to any of my new co-workers by phone, let alone seen them in person. This is both
amazing and terrifying.
Here’s my timeline so far:
Application (days -179 to -178)
Like many geeks, I keep a list of companies that I’ve fantasised about working for some day: mine includes the Mozilla Foundation and DuckDuckGo, for example, as well as Automattic Inc. In case it’s not obvious, I like companies that I feel make the Web a better place! Just out of
interest, I was taking a look at what was going on at each of them. My role at the Bodleian, I realised a while ago, is likely to evolve
into something different probably in the second-half of 2020 and I’d decided that when it does, that would probably be the point at which I should start looking for a new challenge.
What I’d intended to do on this day 128 days ago, which we’ll call “day -179”, was to flick through the careers pages of these and a few other companies, just to get a better
understanding of what kinds of skills they were looking for. I didn’t plan on applying for new jobs yet: that was a task for next-year-Dan.
I love working here, but over the last 8 years I feel like I’ve “solved” all of the most-interesting problems.
But then, during a deep-dive into the things that make Automattic unique (now best-explained perhaps by this episode of the Distributed podcast), something clicked for me. I’d loved the creed for as long as I’d known about it, but today was the day that I finally got it, I think. That was it: I’d drunk the Kool-Aid,
and it was time to send off an application.
I sat up past midnight on day -179, sending my application by email in the small hours of day -178. In addition to attaching a copy of my CV I wrote a little under 2,000 words about why I think I’m near-uniquely qualified to work for them: my experience of distributed/remote working with
SmartData and (especially) Three Rings, my determination to remain a multidisciplinary full-stack developer despite increasing pressure to “pick a side”, my contributions towards (and use, since almost its beginning of) WordPress, and of course the diverse portfolio of projects large and
small I’ve worked on over my last couple of decades as a software engineer.
VR experiments are among the more-unusual things I’ve worked on at the Bodleian (let’s not forget that, strictly, I’m a web developer).
At the time of my application (though no longer, as a result of changes aimed at improving
gender equality) the process also insisted that I include a “secret” in my application, which could be obtained by following some instructions and with only a modest
understanding of HTTP. It could probably be worked out even by a developer who didn’t, with a little of the kind of
research that’s pretty common when you’re working as a coder. This was a nice and simple filtering feature which I imagine helps to reduce the number of spurious applications that must
be read: cute, I thought.
Fun and simple, and yet an effective way to filter out the worst of the spurious applications.
I received an automated reply less that a minute later, and an invitation to a Slack-based initial interview about a day and a half after that. That felt like an incredibly-fast
turnaround, and I was quite impressed with the responsiveness of what must necessarily be a reasonably-complex filtering and process-management process… or perhaps my idea of what
counts as “fast” in HR has been warped by years in a relatively slow-moving and bureaucratic academic environment!
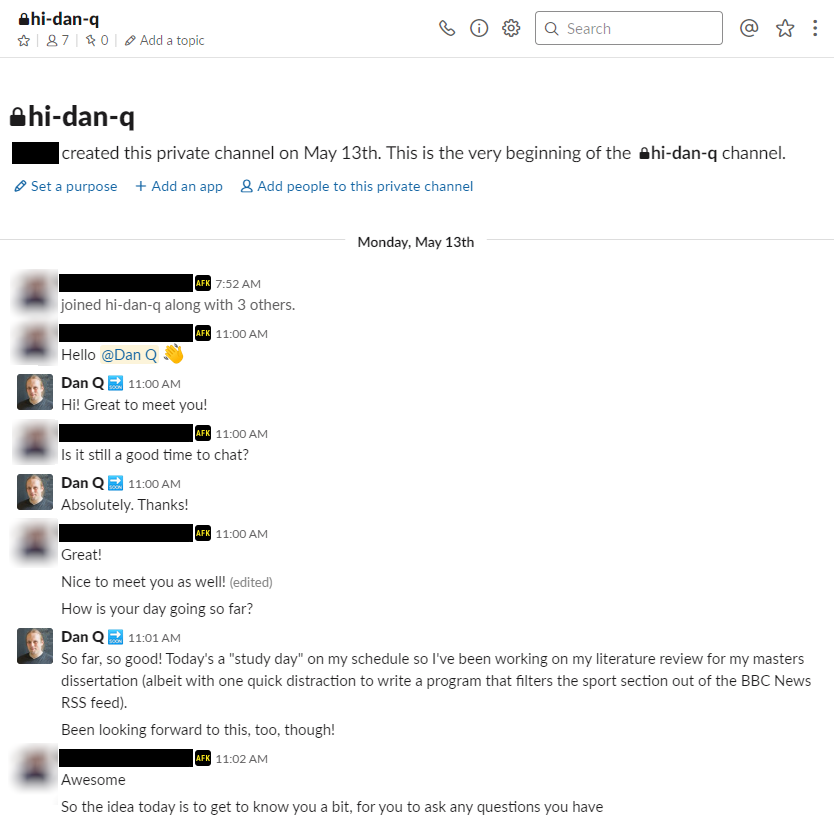
Initial Interview (day -158)
I’ve got experience on both sides of the interview table, and I maintain that there’s no single “right” way to recruit – all approaches suck in different ways – but the approaches used by companies like Automattic (and for
example Bytemark, who I’ve shared details of before) at least
show a willingness to explore, understand, and adopt a diversity of modern practices. Automattic’s recruitment process for developers is a five-step (or something like that) process, with the first two stages being the application and the initial interview.
My initial interview took place 20 days after my application: entirely over text-based chat on Slack, of course.
For all you know, your interviewer might be hanging out in the same cafe or co-working space as you. But they probably aren’t. Right?
The initial interview covered things like:
Basic/conversational questions: Why I’d applied to Automattic, what interested me about working for them, and my awareness of things that were going on at the company
at the moment.
Working style/soft skills: Questions about handling competing priorities in projects, supporting co-workers, preferred working and development styles, and the like.
Technical/implementation: How to realise particular ideas, how to go about debugging a specific problem and what the most-likely causes are, understanding
clients/audiences, comprehension of different kinds of stacks.
My questions/lightweight chat: I had the opportunity to ask questions of my own, and a number of mine probed my interviewer as an individual: I felt we’d “clicked”
over parts of our experience as developers, and I was keen to chat about some up-and-coming web technologies and compare our experiences of them! The whole interview felt about as
casual and friendly as an interview ever does, and my interviewer worked hard to put me at ease.
Skills Test (day -154)
At the end of the interview, I was immediately invited to the next stage: a “skills test”: I’d be given access to a private GitHub repository and a
briefing. In my case, I was given a partially-implemented WordPress plugin to work on: I was asked to –
add a little functionality and unit tests to demonstrate it,
improve performance of an existing feature,
perform a security audit on the entire thing,
answer a technical question about it (this question was the single closest thing to a “classic programmer test question” that I experienced), and
suggest improvements for the plugin’s underlying architecture.
I was asked to spend no more than six hours on the task, and I opted to schedule this as a block of time on a day -154: a day that I’d have otherwise been doing freelance work. An
alternative might have been to eat up a couple of my evenings, and I’m pretty sure my interviewer would have been fine with whatever way I chose to manage my time – after all, a
distributed workforce must by necessity be managed firstly by results, not by approach.
Scheduling my code test for a period when the kids were out of the house allowed me to avoid this kind of juggling act.
My amazingly-friendly “human wrangler” (HR rep), ever-present in my Slack channel and consistently full of encouragement and joy,
brought in an additional technical person who reviewed my code and provided feedback. He quite-rightly pulled me up on my coding standards (I hadn’t brushed-up on the code style guide), somewhat-monolithic commits, and a few theoretical error conditions that I hadn’t
accounted for, but praised the other parts of my work.
Most-importantly, he stated that he was happy to recommend that I be moved forward to the next stage: phew!
Trial (days -147 through -98)
Of all the things that make Automattic’s hiring process especially unusual and interesting, even among hip Silicon Valley(-ish, can a 100%
“distributed” company really be described in terms of its location?) startups, probably the most (in)famous is the trial contract. Starting from day -147, near the end of May, I was
hired by Automattic as a contractor, given a project and a 40-hour deadline, at $25 USD per hour within which to (effectively) prove myself.
As awesome as it is to be paid to interview with a company, what’s far more-important is the experience of working this way. Automattic’s an unusual company, using an
unusual workforce, in an unusual way: I’ve no doubt that many people simply aren’t a good fit for distributed working; at least not yet. (I’ve all kinds of thoughts about the
future of remote and distributed working based on my varied experience with which I’ll bore you another time.) Using an extended trial as an recruitment filter provides a level of
transparency that’s seen almost nowhere else. Let’s not forget that an interview is not just about a company finding the right employee for them but about a candidate finding the right
company for them, and a large part of that comes down to a workplace culture that’s hard to define; instead, it needs to be experienced.
For all that a traditional bricks-and-mortar employer might balk at the notion of having to pay a prospective candidate up to $1,000 only to then reject them, in addition to normal
recruitment costs, that’s a pittance compared to the costs of hiring the wrong candidate! And for a company with an unusual culture, the risks are multiplied: what if
you hire somebody who simply can’t hack the distributed lifestyle?
Page 1 of 6, all written in the USA dialect of legalese, but the important part is right there at the top: the job title is
“Trial Code Wrangler”. Yeah.
It was close to this point, though, that I realised that I’d made a terrible mistake. With an especially busy period at both the Bodleian and at Three Rings and deadlines
looming in my masters degree, as well as an imminent planned anniversary break with Ruth, this was
not the time to be taking on an additional piece of contract work! I spoke to my human wrangler and my technical supervisor in the Slack channel dedicated to that purpose and explained
that I’d be spreading my up-to-40-hours over a long period, and they were very understanding. In my case, I spent a total of 31½ hours over six-and-a-bit weeks working on a project
clearly selected to feel representative of the kinds of technical problems their developers face.
That’s reassuring to me: one of the single biggest arguments against using “trials” as a recruitment strategy is that they discriminate against candidates who, for whatever reason,
might be unable to spare the time for such an endeavour, which in turn disproportionately discriminates against candidates with roles caring for other (e.g. with children) or who
already work long hours. This is still a problem here, of course, but it is significantly mitigated by Automattic’s willingness to show significant flexibility with their candidates.
I was given wider Slack access, being “let loose” from the confines of my personal/interview channel and exposed to a handful of other communities. I was allowed to mingle amongst not
only the other developers on trial (they have their own channel!) but also other full-time staff. This proved useful – early on I had a technical question and (bravely) shouted out on
the relevant channel to get some tips! After every meaningful block of work I wrote up my progress via a P2 created for that purpose, and I shared my
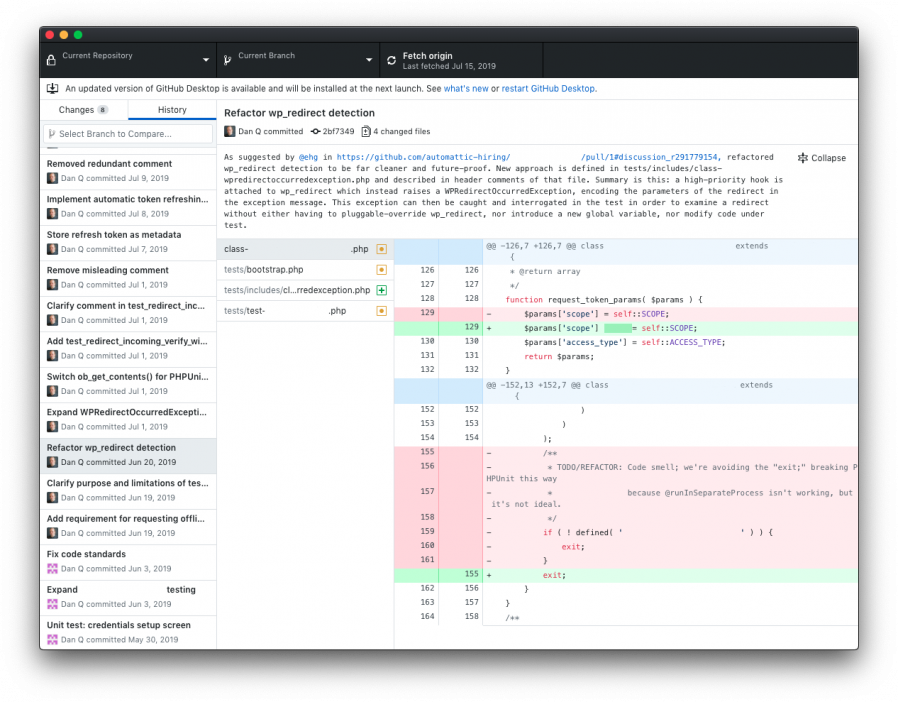
checkins with my supervisors, cumulating at about the 20-hour mark in a pull request that I felt was not-perfect-but-okay…
I’m normally more of a command-line git users, but I actually really came to appreciate the GitHub Desktop diff interface while describing my commits during this project.
…and then watched it get torn to pieces in a code review.
Everything my supervisor said was fair, but firm. The technologies I was working with during my trial were ones on which I was rusty and, moreover, on which I hadn’t enjoyed the benefit
of a code review in many, many years. I’ve done a lot of work solo or as the only person in my team with experience of the languages I was working in, and I’d developed a lot
of bad habits. I made a second run at the pull request but still got shot down, having failed to cover all the requirements of the project (I’d misunderstood a big one, early on, and
hadn’t done a very good job of clarifying) and having used a particularly dirty hack to work-around a unit testing issue (in my defence I knew what I’d done there was bad, and my aim
was to seek support about the best place to find documentation that might help me solve it).
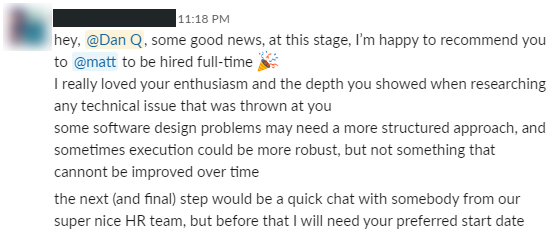
I felt deflated, but pressed on. My third attempt at a pull request was “accepted”, but my tech supervisor expressed concerns about the to-and-fro it had taken me to get there.
Finally, in early July (day -101), my interview team went away to deliberate about me. I genuinely couldn’t tell which way it would go, and I’ve never in my life been so nervous to hear
back about a job.
A large part of this is, of course, the high esteem in which I hold Automattic and the associated imposter syndrome I talked about
previously, which had only been reinforced by the talented and knowledgable folks there I’d gotten to speak to during my trial. Another part was seeing their recruitment standards
in action: having a shared space with other candidate developers meant that I could see other programmers who seemed, superficially, to be doing okay get eliminated from their
trials – reality TV style! – as we went along. And finally, there was the fact that this remained one of my list of “dream companies”:
if I didn’t cut it by this point in my career, would I ever?
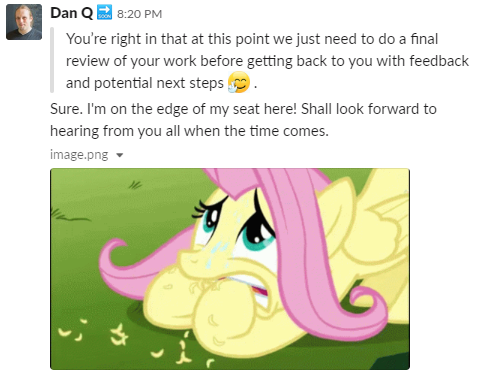
Two days later, on day -99, I shared what felt like an appropriate My Little Pony: Friendship is Magic GIF with
the interview team via Slack.
It took 72 hours after the completion of my trial before I heard back.
I was to be recommended for hire.
On day -98 I literally jumped for joy. This was a hugely exciting moment.
It was late in the day, but not too late to pour myself a congratulatory Caol Ila.
OMGOMGOMGOMG.
Final Interview (day -94)
A lot of blog posts about getting recruited by Automattic talk about the final interview being with CEO Matt Mullenweg himself, which I’d always thought must be an unsustainable use of his time once you get into the multiple-hundreds of employees. It looks like I’m
not the only one who thought this, because somewhere along the line the policy seems to have changed and my final interview was instead with a human wrangler (another
super-friendly one!).
That was a slightly-disappointing twist, because I’ve been a stalker fanboy of Matt’s for almost 15 years… but I’ll probably get to meet him at some point or other now
anyway. Plus, this way seems way-more logical: despite Matt’s claims to the contrary, it’s hard to see Automattic as a “startup” any longer (by age alone: they’re two years
older than Twitter and a similar age to Facebook).
The final interview felt mostly procedural: How did I find the process? Am I willing to travel for work? What could have been done differently/better?
Conveniently, I’d been so enthralled by the exotic hiring process that I’d kept copious notes throughout the process, and – appreciating the potential value of honest, contemporaneous
feedback – made a point of sharing them with the Human League (that’s genuinely what Automattic’s HR department are called, I kid you
not) before the decision was announced as to whether or not I was to be hired… but as close as possible to it, so that it could not influence it. My thinking was this: this
way, my report couldn’t help but be honest and unbiased by the result of the process. Running an unusual recruitment strategy like theirs, I figured, makes it harder to get
honest and immediate feedback: you don’t get any body language cues from your candidates, for a start. I knew that if it were my company, I’d want to know how it was working
not only from those I hired (who’d be biased in favour it it) and from those who were rejected (who’d be biased against it and less-likely to be willing to provide in-depth feedback in
general).
I guess I wanted to “give back” to Automattic regardless of the result: I learned a lot about myself during the process and especially during the trial, and I was grateful for
it!
Show me the money!
One part of the final interview, though, was particularly challenging for me, even though my research had lead me to anticipate it. I’m talking about the big question that
basically every US tech firm asks but only a minority of British ones do: what are your salary expectations?
As a Brit, that’s a fundamentally awkward question… I guess that we somehow integrated a feudalistic class system into a genetic code: we don’t expect our lords to pay us
peasants, just to leave us with enough grain for the winter after the tithes are in and to protect us from the bandits from the next county over, right? Also: I’ve known for a long
while that I’m chronically underpaid in my current role. The University of Oxford is a great employer in many ways but if you stay with them for any length of time then it has to be for
love of their culture and their people, not for the money (indeed: it’s love of my work and colleagues that kept me there for the 8+ years I
was!).
I’m pretty sure that most Brits are at least a little uncomfortable, even, when Dennis gives lip to King Arthur in Monty Python and the Holy Grail.
Were this an in-person interview, I’d have mumbled and shuffled my feet: you know, the British way. But luckily, Slack made it easy at least for me to instead awkwardly copy-paste some
research I’d done on StackOverflow, without which, I wouldn’t have had a clue what I’m allegedly-worth! My human wrangler took my garbled nonsense away to do some internal
research of her own and came back three hours later with an offer. Automattic’s offer was very fair to the extent that I was glad to have somewhere to sit down and process it
before responding (shh… nobody tell them that I am more motivated by impact than money!): I hadn’t been
emotionally prepared for the possibility that they might haggle upwards.
Three months on from writing my application, via the longest, most self-reflective, most intense, most interesting recruitment process I’ve ever experienced… I had a contract awaiting
my signature. And I was sitting on the edge of the bath, trying to explain to my five year-old why I’d suddenly gone weak at the knees.
I wanted to insert another picture of the outside of my office at the Bodleian here, but a search of my photo library gave me this one and it was too adorable to not-share.
Getting Access (day -63)
A month later – a couple of weeks ago, and a month into my three-month notice period at the Bodleian – I started getting access to Auttomatic’s computer systems. The ramp-up to getting
started seems to come in waves as each internal process kicks off, and this was the moment that I got the chance to introduce myself to my team-to-be.
I can see my team… and they can see me? /nervous wave/
I’d been spending occasional evenings reading bits of the Automattic Field Guide – sort-of a living staff handbook for Automatticians – and this was the moment when I discovered that a
lot of the links I’d previously been unable to follow had suddenly started working. You remember that bit in $yourFavouriteHackerMovie where suddenly the screen
flashes up “access granted”, probably in a green terminal font or else in the centre of a geometric shape and invariably accompanied by a computerised voice? It felt like that. I still
couldn’t see everything – crucially, I still couldn’t see the plans my new colleagues were making for a team meetup in South Africa and had to rely on Slack chats with my new
line manager to work out where in the world I’d be come November! – but I was getting there.
Getting Ready (day -51)
The Human League gave me a checklist of things to start doing before I started, like getting bank account details to the finance department. (Nobody’s been able to confirm nor denied
this for me yet, but I’m willing to bet that, if programmers are Code Wranglers, devops are Systems Wranglers, and HR are Human
Wranglers, then the finance team must refer to themselves as Money Wranglers, right?)
They also encouraged me to get set up on their email, expenses, and travel booking systems, and they gave me the password to put an order proposal in on their computer hardware ordering
system. They also made sure I’d run through their Conflict of Interest checks, which I’d done early on because for various reasons I was in a more-complicated-than-most position.
(Incidentally, I’ve checked and the legal team definitely don’t call themselves Law Wranglers, but that’s probably because lawyers understand that Words Have Power and must be
used correctly, in their field!)
Wait wait wait… let me get this straight… you’ve never met me nor spoken to me on the phone and you’re willing to post a high-end dev box to me? A month and a half before I
start working for you?
So that’s what I did this week, on day -51 of my employment with Automattic. I threw a couple of hours at setting up all the things I’d need set-up before day 0, nice and early.
I’m not saying that I’m counting down the days until I get to start working with this amazing, wildly-eccentric, offbeat, world-changing bunch… but I’m not not saying that,
either.






![A browser's debug console executes $x('//*[@id="posts"]//a') , and gets 14 results.](https://bcdn.danq.me/_q23u/2024/11/adam-k-xpath-1-640x188.png)




















![You have [20] work days left to ask Dan that awkward question.](https://bcdn.danq.me/_q23u/2019/09/20190903_152221-898x437.jpg)