In October of this year – after eight years, six months, and five days with the Bodleian Libraries – I’ll be leaving for pastures new. Owing to a
combination of my current work schedule, holidays, childcare commitments and conferences, I’ve got fewer than 29 days left in the office.
I’ve been keeping a countdown on my whiteboard to remind my colleagues to hurry up and ask me anything they need in order to survive in my absence.
Instead, I’ll be starting work with Automattic Inc.. You might not have heard of them, but you’ve definitely used some of their
products, either directly or indirectly. Ever hear of WordPress.com, WooCommerce, Gravatar or Longreads? Yeah; that’s the guys.
It’s a gear stick. For an automatic car. ‘Cos I’m “shifting into Automattic”. D’you get it? Do you? Do you?
I’m filled with a mixture of joyous excitement and mild trepidation. It’s mostly the former, thankfully, but there’s still a little nervousness there too. Mostly it’s a kind of imposter syndrome, I guess: Automattic have for many, many years been on my “list of companies I’d love to work for, someday”, and
the nature of their organisation means that they have their pick of many of the smartest and most-talented geeks in the world. How do I measure up?
During my final months I’m taking the opportunity to explore bits of the libraries I’ve not been to before. Y’know, before they revoke my keycard.
It’s funny: early in my career, I never had any issue of imposter syndrome. I guess that when I was young and still thought I knew everything – fuelled by a little talent and a lot of
good fortune in getting a head-start on my peers – I couldn’t yet conceive of how much further I had to go. It took until I was well-established in my industry before I could begin to
know quite how much I didn’t know. I’d like to think that the second decade of my work as a developer has been dominated by unlearning all of the things that I did wrong, while flying
by the seat of my pants, in the first decade.
I’ll be mostly remote-working for Automattic, so I can guarantee that my office won’t be as pretty as my one at the Bod was. Far fewer Muses on the roof, too.
I’m sure I’ll have lots more to share about my post-Bodleian life in due course, but for now I’ve got lots of projects to wrap up and a job description to rewrite (I’m recommending that
I’m not replaced “like-for-like”, and in any case: my job description at the Bodleian does not lately describe even-remotely what I actually do), and a lot of documentation to
bring up-to-date. Perhaps then this upcoming change will feel “real”.
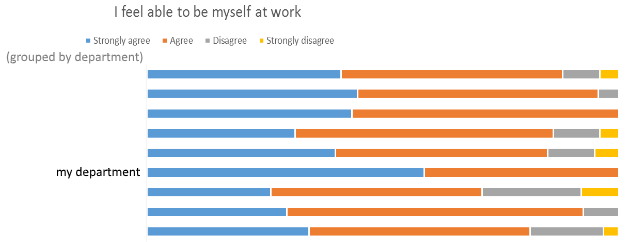
Lots of interesting results from the @bodleianlibs staff survey. Pleased to have my suspicions confirmed about my department’s propensity
to be accepting of individuals: it’s the only one where a majority of people strongly agreed with the statement “I feel able to by myself at work” and one of only two where
nobody disagreed with it. That feels like an accurate representation of my experience with my team these last 7-8 years!
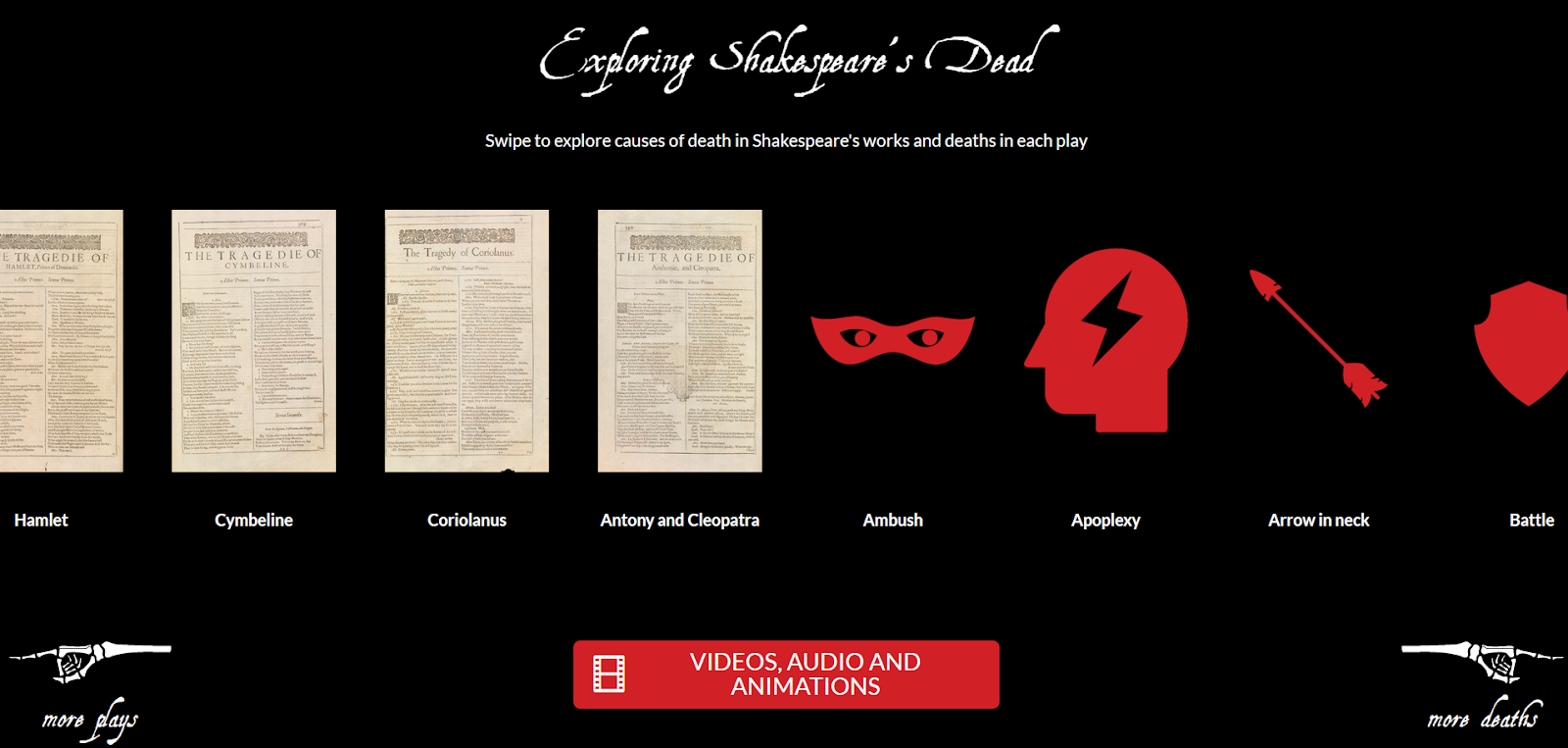
The Bodleian Digital Comms team is no stranger to developing out of the ordinary content. Want to represent all of the varied and gruesome deaths in Shakespeare in a fun and
engaging way? We’re on it!
We manage almost all of the Libraries’ public facing digital ‘stuff’, from our main websites to social media and digital signage. When we tot it all up, it’s over fifty websites, a
similar number of blogs, the full range of social media platforms, more than twenty digital screens, a handful of interactive experiences a year, plus…well, not actually a partridge
in a pear tree, but there areunicorns in arks.
From ambush to war crimes, a chance to delve into death in Shakespeare’s works, and to think about how it differed from
the reality
Whatever the platform, our team’s focus is on finding ways to engage the Libraries’ audiences — whether students, researchers, tourists or those around the globe who can’t actually
visit in person — with our work and our collections.
Received a letter to “Dan Q, Developer”. In case there’s multiple Dan Qs @bodleianlibs? Nope: everyone‘s had the last
word of their job title: Wikmedian in Residence > “Residence”, Press & Media Officer > “Officer”… #mailmerge #fail?
If you look closely, you’ll find I’ve shown you a sneak-peek at some of what’s behind tomorrow’s door. Shh. Don’t tell our social media officer.
As each door is opened, a different part of a (distinctly-Bodleian/Oxford) winter scene unfolds, complete with an array of fascinating characters connected to the history, tradition,
mythology and literature of the area. It’s pretty cool, and you should give it a go.
If you want to make one of your own – for next year, presumably, unless you’ve an inclination to count-down in this fashion to something else that you’re celebrating 25 days
hence – I’ve shared a version of the code that you can adapt for yourself.
The open-source version doesn’t include the beautiful picture that the Bodleian’s does, so you’ll have to supply your own.
Features that make this implementation a good starting point if you want to make your own digital advent calendar include:
Secure: your server’s clock dictates which doors are eligible to be opened, and only content legitimately visible on a given date can be obtained (no path-traversal,
URL-guessing, or traffic inspection holes).
Responsive: calendar adapts all the way down to tiny mobiles and all the way up to 4K fullscreen along with optimised images for key resolutions.
Friendly: accepts clicks and touches, uses cookies to remember the current state so you don’t have to re-open doors you opened yesterday (unless you forgot to open
one yesterday), “just works”.
Debuggable: a password-protected debug mode makes it easy for you to test, even on a production server, without exposing the secret messages behind each door.
Expandable: lots of scope for the future, e.g. a progressive web app version that you can keep “on you” and which notifies you when a new door’s ready to be opened,
was one of the things I’d hoped to add in time for this year but didn’t quite get around to.
The Bodleian has a specific remit for digital archiving… but sometimes they just like collecting stuff, too, I’m sure.
The team responsible for digital archiving had plans to spend World Digital Preservation Day running a stand in Blackwell Hall for some
time before I got involved. They’d asked my department about using the Heritage Window – the Bodleian’s 15-screen video wall – to show a carousel of slides with relevant content over
the course of the day. Or, they added, half-jokingly, “perhaps we could have Pong up there as it’ll be its 46th birthday?”
Free reign to play about with the Heritage Window while smarter people talk to the public about digital archives? Sure, sign me up.
But I didn’t take it as a joke. I took it as a challenge.
Emulating Pong is pretty easy. Emulating Pong perfectly is pretty hard. Indeed, a lot of the challenge in the preservation of (especially digital) archives in general is in
finding the best possible compromise in situations where perfect preservation is not possible. If these 8″ disks are degrading, is is acceptable to copy them onto a different medium? If this video file is unreadable in
modern devices, is it acceptable to re-encode it in a contemporary format? These are the kinds of questions that digital preservation specialists have to ask themselves all the damn
time.
The JS Gamepad API lets your web browser talk to controller devices.
Emulating Pong in a way that would work on the Heritage Window but be true to the original raised all kinds of complications. (Original) Pong’s aspect ratio doesn’t fit nicely on a 16:9
widescreen, much less on a 27:80 ultrawide. Like most games of its era, the speed is tied to the clock rate of the processor. And of course, it should be controlled using a
“dial”.
By the time I realised that there was no way that I could thoroughly replicate the experience of the original game, I decided to take a different track. Instead, I opted to
reimplement Pong. A reimplementation could stay true to the idea of Pong but serve as a jumping-off point for discussion about how the experience of playing the game
may be superficially “like Pong” but that this still wasn’t an example of digital preservation.
Bip… boop… boop… bip… boop… bip…
Here’s the skinny:
A web page, displayed full-screen, contains both a <canvas> (for the game, sized appropriately for a 3 × 3 section of the video wall) and a
<div> full of “slides” of static content to carousel alongside (filling a 2 × 3 section).
Javascript writes to the canvas, simulates the movement of the ball and paddles, and accepts input from the JS
Gamepad API (which is awesome, by the way). If there’s only one player, a (tough! – only three people managed to beat it over the course of the day!) AI plays the other paddle.
A pair of SNES controllers adapted for use as USB
controllers which I happened to own already.
Increasingly, the Bodleian’s spaces seem to be full of screens running Javascript applications I’ve written.
I felt that the day, event, and game were a success. A few dozen people played Pong and explored the other technology on display. Some got nostalgic about punch tape, huge floppy disks,
and even mechanical calculators. Many more talked to the digital archives folks and I about the challenges and importance of digital archiving. And a good time was had by all.
I’ve open-sourced the entire thing with a super-permissive license so you can deploy it yourself (you know, on your ultrawide
video wall) or adapt it as you see fit. Or if you’d just like to see it for yourself on your own computer, you can (but unless
you’re using a 4K monitor you’ll probably need to use your browser’s mobile/responsive design simulator set to 3200 × 1080 to make it fit your screen). If you don’t have
controllers attached, use W/S to control player 1 and the cursor keys for player 2 in a 2-player game.
Some days my job… isn’t like other people’s jobs. Lately, I’ve been reimplementing Pong in Javascript for the @bodleianlibs’ video wall for an event on Thursday.
You may recall that on Halloween I mentioned that the Bodleian had released a mini choose-your-own-adventure-like adventure game book, available freely online. I decided that this didn’t go quite far
enough and I’ve adapted it into a hypertext game, below. (This was also an excuse for me to play with Chapbook, Chris Klimas‘s new under-development story format for Twine.
If the thing you were waiting for before you experienced Shadows Out of Time was it to be playable in your browser, wait no longer: click here to play the game…
Today, @bodleianlibs releases Shadows Out of Time, a Choose-Your-Own-Destiny story. It’s amazing – go read it: https://s.danq.me/Np
#halloween #InteractiveFiction
Notes from #musetech18 presentations (with a strong “collaboration” theme). Note that these are “live notes” first-and-foremost for my own use and so are probably full of typos. Sorry.
Matt Locke (StoryThings, @matlocke):
Over the last 100 years, proportional total advertising revenue has been stolen from newspapers by radio, then television: scheduled media that is experienced
simultaneously. But we see a recent drift in “patterns of attention” towards the Internet. (Schedulers, not producers, hold the power in radio/television.)
The new attention “spectrum” includes things that aren’t “20-60 minutes” (which has historically been dominated by TV) nor “1-3 hours” (which has been film), but now there are
shorter and longer forms of popular medium, from tweets and blog posts (very short) to livestreams and binging (very long). To gather the full spectrum of attention, we need to span
these spectra.
Rhythm is the traditions and patterns of how work is done in your industry, sector, platforms and supply chains. You need to understand this to be most-effective (but this is
hard to see from the inside: newcomers are helpful). In broadcast television as a medium, the schedules dictate the rhythms… in traditional print publishing, the major
book festivals and “blockbuster release” cycles dominate the rhythm.
Then how do we collaborate with organisations not in our sector (i.e. with different rhythms)? There are several approaches, but think about the rhythmic impact.
Partnered with Google Arts & Heritage; Google’s first single-partner project and also their first project with a multi-site organisation.
This kind of tech can be used to increase access (e.g. street view of closed sites) and also support curatorial/research aims (e.g. ultra-high-resolution photography).
Aside from the tech access, working with a big company like Google provides basically “free” PR. In combination, these benefits boost reach.
Learnings: prepare to work hard and fast, multi-site projects are a logistical nightmare, you will need help, stay organised and get recordkeeping/planning in place early, be aware
that there’ll be things you can’t control (e.g. off-brand PR produced by the partner), don’t be afraid to stand your ground where you know your content better.
Decide what successw looks like at the outset and with all relevant stakeholders involved, so that you can stay on course. Make sure the project is integrated into contributors’
work streams.
Daria Cybulska (Wikimedia UK, @DCybulska):
Collaborative work via Wikimedians-in-residence not only provides a boost to open content but involves engagement with staff and opens further partnership opportunities.
Your audience is already using Wikipedia: reaching out via Wikipedia provides new ways to engage with them – see it as a medium as well as a platform.
Wikimedians-in-residence, being “external”, are great motivators to agitate processes and promote healthy change in your organisation.
Creative Collaborations ([1] Kate Noble @kateinoble, Ina Pruegel @3today, [2] Joanna Salter, [3] Michal Cudrnak, Johnathan Prior):
Digital making (learning about technology through making with it) can link museums with “maker culture”. Cambridge museums (Zoology, Fitzwilliam) used a “Maker in Residence”
programme and promoted “family workshops” and worked with primary schools. Staff learned-as-they-went and delivered training that they’d just done themselves (which fits maker culture
thinking). Unexpected outcomes included interest from staff and discovery of “hidden” resources around the museums, and the provision of valuable role models to participants. Tips: find
allies, be ambitious and playful, and take risks.
National Maritime Museum Greenwich/National Maritime Museum – “re.think” aimed to engage public with emotive topics and physically-interactive exhibits. Digital wing allowed leaving
of connections/memories, voting on hot issues, etc. This leads to a model in which visitors are actively engaged in shaping the future display (and interpretation) of exhibitions.
Stefanie Posavec appointed as a data artist in residence.
SoundWalk Strazky at Slovak National Gallery: audio-geography soundwalks as an immersive experiential exhibition; can be done relatively cheaply, at the basic end. Telling fictional
stories (based on reality) can help engage visitors with content (in this case, recreating scenes from artists’ lives). Interlingual challenges. Delivery via Phonegap app which provides
map and audio at “spots”; with a simple design that discourages staring-at-the-screen (only use digital to improve access to content!).
Lightning talks:
Maritime Museum Greenwich: wanted to find out how people engage with objects – we added both a museum interpretation and a community message to each object. Highly-observational
testing helped see how hundreds of people engage with content. Lesson: curators are not good judges of how their stuff will be received; audience ownership is amazing. Be reactive.
Visitors don’t mind being testers of super-rough paper-based designs.
Nordic Museum / Swedish National Heritage Board explored Generous Interfaces: show first, don’t ask, rich overviews, interobject relationships, encourage exploration etc. (Whitelaw,
2012). Open data + open source + design sprints (with coding in between) + lots of testing = a collaborative process. Use testing to decide between sorting OR filtering;
not both! As a bonus, generous interfaces encourage finding of data errors. bit.ly/2CNsNna
IWM on the centenary of WWI: thinking about continuing the crowdsourcing begun by the IWM’s original mission. Millions of assets have been created by users. Highly-collaborative
mechanism to explore, contribute to, and share a data space.
Lauren Bassam (@lswbassam) on LGBT History and co-opting of Instagram as an archival space: Instagram is an unconventional archival source, but provides a few benefits in
collaboration and engagement management, and serves as a viable platform for stories that are hard to tell using the collections in conventional archives. A suitably-engaged community
can take pride in their accuracy and their research cred, whether or not you strictly approve of their use of the term “archivist”. With closed stacks, we sometimes forget how important
engagement, touch, exploration and play can be.
Owen Gower (@owentg) from Dr. Jenner’s House Museum and Garden: they received EU REVEAL funding to look at VR as an engagement tool. Their game is for PSVR and has a commercial
release. The objects that interested the game designers the most weren’t necessarily those which the curators might have chosen. Don’t let your designers get carried away and fill the
game with e.g. zombies. But work with them, and your designers can help you find not only new ways to tell stories, but new stories you didn’t know you could
tell. Don’t be afraid to use cheap/student developers!
Rebecca Kahm @rebamex from Pelagios Commons (@Pelagiosproject): the problem with linked data is that it’s hard to show its value to end users (or even show museums “what you can do”
with it). Coins have great linked data, in collections. Peripleo was used to implement a sort-of “reverse Indiana Jones”: players try to recover information to find where an
artefact belongs.
Jon Pratty: There are lots of useful services (Flickr, Storify etc.) and many are free (which is great)… but this produces problems for us in terms of the long-term
life of our online content, not to mention the ethical issues with using services whose business model is built on trading personal data of our users. [Editor’s note: everything being
talked about here is the stuff that the Indieweb movement have been working on for some time!] We need to de-siloise and de-centralise our content
and services. redecentralize.org? responsibledata.io?
In-House Collaboration and the State of the Sector:
Rosie Cardiff @RosieCardiff, Serpentine Galleries on Mobile Tours. Delivered as web application via captive WiFi hotspot. Technical challenges were significant for a relatively
small digital team, and there was some apprehension among frontline staff. As a result of these and other problems, the mobile tours were underused. Ideas to overcome barriers: report
successes and feedback, reuse content cross-channel, fix bugs ASAP, invite dialogue. Interesting that they’ve gained a print guides off the back of the the digital. Learn lessons and
relaunch.
Sarah Younaf @sarahyounas, Tyne & Wear Museums. Digital’s job is to ask the questions the museum wouldn’t normally ask, i.e. experimentation (with a human-centric bias). Digital is
quietly, by its nature, “given permission” to take risks. Consider establishing relationships with (and inviting-in) people who will/want to do “mashups” or find alternative uses for
your content; get those conversations going about collections access. Experimental Try-New-Things afternoons had value but this didn’t directly translate into ideas-from-the-bottom,
perhaps as a result of a lack of confidence, a requirement for fully-formed ideas, or a heavy form in the application process for investment in new initiatives. Remember you can’t
change everyone, but find champions and encourage participation!
Kati Price @katiprice on Structuring for Digital Success in GLAM. Study showed that technical leadership and digital management/analysis is rated as vital, yet they’re also
underrepresented. Ambitions routinely outstrip budgets. Assumptions about what digital teams “look” like from an org-chart perspective don’t cover the full diversity: digital teams look
very different from one another! Forrester Research model of Digital Maturity seems to be the closest measure of digital maturity in GLAM institutions, but has flaws (mostly relating to
its focus in the commercial sector): what’s interesting is that digital maturity seems to correlate to structure – decentralised less mature than centralised less mature than
hub-and-spoke less mature than holistic.
Jennifer Wexler, Daniel Pett, Chiara Bonacchi on Diversifying Museum Audiences through Participation and stuff. Crowdsourcing boring data entry tasks is sometimes easier than asking
staff to do it, amazingly. For success, make sure you get institutional buy-in and get press on board. Also: make sure that the resulting data is open so everybody can
explore it. Crowdsourcing is not implicitly democratisating, but it leads to the production of data that can be. 3D prints (made from 3D cutouts generated by crowdsourcing) are a useful
accessibility feature for bringing a collection to blind or partially-sighted visitors, for example. Think about your audiences: kids might love your hip VR, but if their parents hate
it then you still need a way to engage with them!
Implemented a demonstrative XSS payload targetting a CMS (as a
teaching tool, to demonstrate how a series of minor security vulnerabilities can cascade into one huge one).
Gotten my ‘flu jab.
Not every day is like this. But sometimes, just sometimes, one can be.
![Dan's whiteboard: "You have [29] work days left to ask Dan that awkward question".](https://bcdn.danq.me/_q23u/2019/07/20190719_154737-1024x498.jpg)