Perhaps it’s because I’ve been away for a couple of days and she’s missed me… but this bleppy dog wanted lots of cuddles and reassurance as we prepared for the school run, this Twenty-Fifth of Bleptember.

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Perhaps it’s because I’ve been away for a couple of days and she’s missed me… but this bleppy dog wanted lots of cuddles and reassurance as we prepared for the school run, this Twenty-Fifth of Bleptember.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
I’ve spent most of the Twenty-Fourth of Bleptember travelling, but my bleppy doggo got to go out and play with her best dogfriend.

Photo courtesy of Lisa from Muddy Paws.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
“What’chu lookin’ at?” I’m away from home this Twenty-Third of Bleptember, but managed to snap this epic blep before I left.

Attempt #2 to get to Belfast starts… at 3:30am in a Premier Inn in Gatwick. 🥱 Today, perhaps, I’ll catch a plane! 🤞

After standing completely stationary on the M25 for over an hour and a half and with no end in sight, I’m getting increasingly confident that I’m not going to catch my flight from Gatwick whose gate closes… in half an hour. 😢

Well, fuck.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Just blepping around the garden this Twenty-Second of Bleptember.

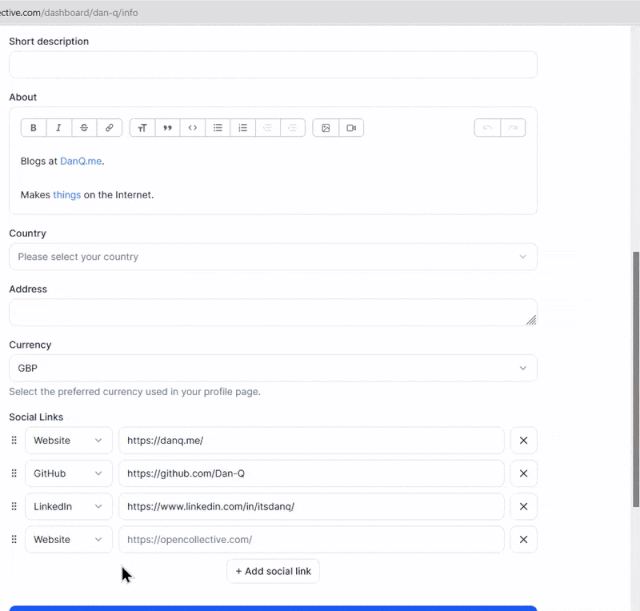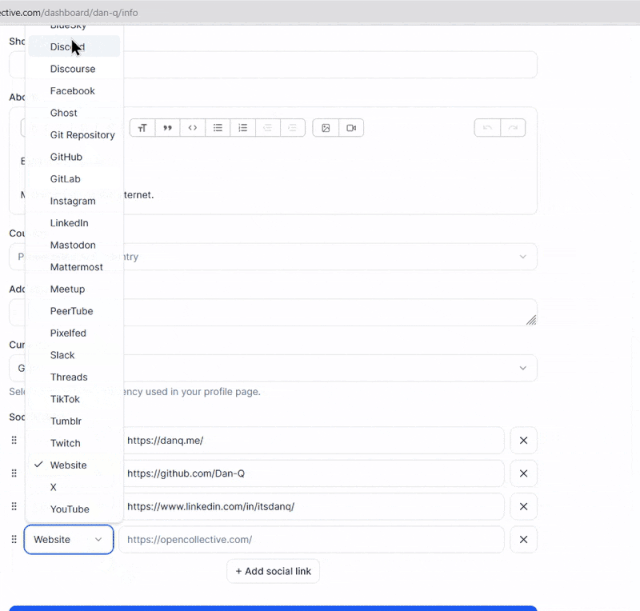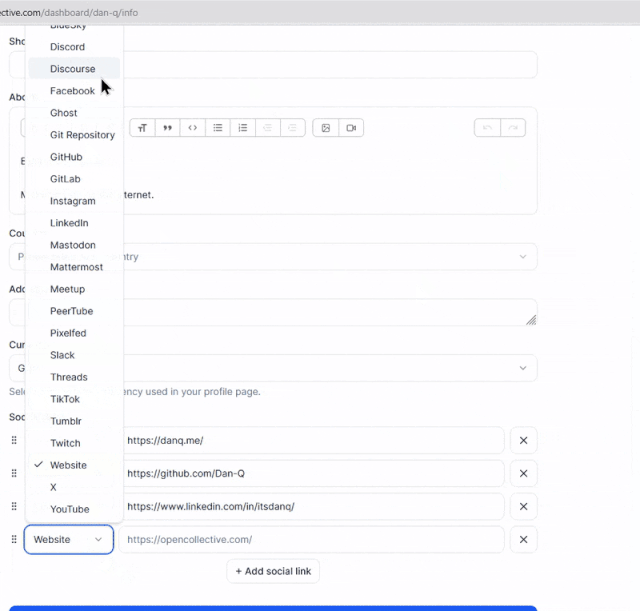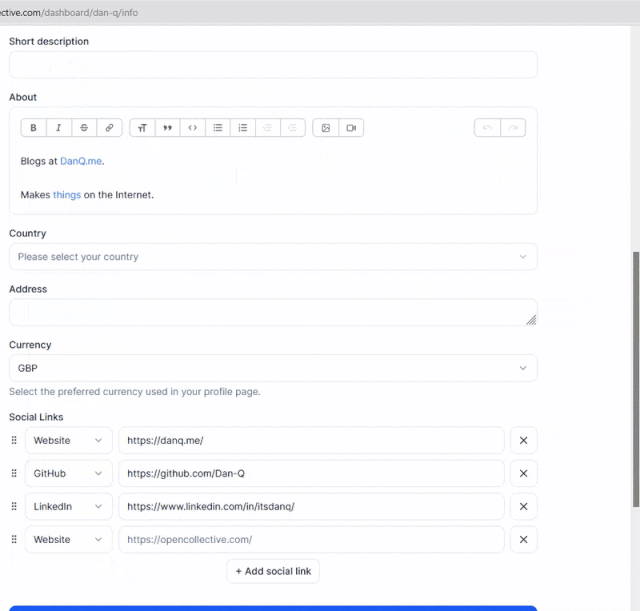
Developers just love to take what the Web gives them for free, throw it away, and replace it with something worse.
Today’s example, from Open Collective, is a dropdown box: standard functionality provided by the <select> element. Except
they’ve replaced it with a JS component that, at some screen resolutions, “goes off the top” of the page… while simultaneously disabling the scrollbars so that you can’t reach it. 🤦♂️
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
On the Twenty-First of Bleptember this young doggo was very excited to see a field of goats. Goats! I like to interpret her expression as saying “OMG have you seen the thing that’s living in this field!?”
An inquisitive and excited expression let down only slightly by the inevitable blep and by a tentacle of drool! 😂

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
It’s the Twentieth of Bleptember, and I still struggle to conceive of how it’s comfortable to lie down with not only your head but also 50% of your tongue lying flat on your soft, furry pillow.

(This troublesome young lady stole and tried to eat a dry-wipe whiteboard pen yesterday. She’s fine, but it was briefly alarming when she started vomiting bright green ink everywhere…)
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Even play-fighting isn’t an excuse for our bleppy dog to put her tongue away. Happy Nineteenth of Bleptember!

Photo courtesy Lisa from Muddy Paws.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
We took a longer-than-usual walk on this warm Eighteenth of Bleptember morning, and the doggle’s all tuckered-out.

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Sofa Time is Best Time.

Happy Seventeenth of Bleptember.
Sometimes you really want the apparel for a band or album to exist and it just doesn’t. And so, not for the first time, I made my own…

Source image available for if you want one too: https://danq.link/slamilton-svg
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
It’s the Sixteenth of Bleptember, and our derpy doggle’s back from a playdate with her best friend… although you wouldn’t know how close they are from this picture, in which she seems to be blowing a raspberry at him as she walks away!

Photo courtesy Lisa from Muddy Paws.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
It’s the Fifteenth of Bleptember, and our young doggo has never looked so inelegant as when she lies on her back on the sofa with a dorky tongueful grin on her face.
