Don’t remember the last time I felt so run-down. I’ve been unwell since Sunday with an illness I can only assume I caught from the 11-year-old, who’s been unable to keep food down for
several days.
In my case, though, I’ve mostly been full of muscular aches and cramps, ocassionally fits of shivers, and strange dizziness.
I’ve spent the last day and a bit mostly drifting in and out of sleep, where I’ve had the weirdest dreams. I just woke from one where I was lost in a sprawling hotel, looking for my
room which was number 317 or possibly 305, I couldn’t remember. The signage didn’t make sense to me and I couldn’t read it, and found myself wandering around a sprawling resort, with
hot air balloon services connecting different parts. At one point I found myself lost in a library whose winding shelves formed a Escherian maze, and a small child watched me with
suspicion as I fumbled around for an exit.
In a disturbing dream from yesterday afternoon, I was lying in a desert of cold sand as the wind gradually piled up more and more sand against me. At first I felt fascinated, thinking
I’d learned something about how dunes form, until I discovered that I wasn’t able to move. I gradually sunk deeper and deeper underground, in pain except when I lay very still and let
it take me, until eventually I started to become the very sand that I was disappearing into. I felt flakes of myself break away and become part of the desert, unable to resist
the change nor reconstruct myself, resigned to my fate.
I’m in less pain so far this morning than yesterday, so I think I’m recovering, but man this has been an unpleasant ride. Whatever I’m infected with: do not recommend, would not
contract again, one out of five.
5. If you use AI, you are the one who is accountable for whatever you produce with it. You have to be certain that whatever you produced was correct. You cannot ask the system
itself to do this. You must either already be expert at the task you are doing so you can recognise good output yourself, or you must check through other, different means the
validity of any output.
…
9. Generative AI produces above average human output, but typically not top human output. If you overuse generative AI you may produce more mediocre output than you are capable of.
…
I was also tempted to include in 9 as a middle sentence “Note that if you are in an elite context, like attending a university, above average for humanity widely could be below
average for your context.”
Point 5 is a reminder that, as I’ve long said, you can’t trust an AI to do anything that you can’t do for yourself. I
sometimes use a GenAI-based programming assistant, and I can tell you this – it’s really good for:
Fancy autocomplete: I start typing a function name, it guesses which variables I’m going to be passing into the function or that I’m going to want to loop through the
output or that I’m going to want to return-early f the result it false. And it’s usually right. This is smart, and it saves me keypresses and reduces the embarrassment of mis-spelling
a variable name1.
Quick reference guide: There was a time when I had all of my PHP DateTimeInterface::format character codes memorised. Now I’d have to look them up. Or I can write a comment (which I should anyway, for the next human) that says something like //
@returns String a date in the form: Mon 7th January 2023 and when I get to my date(...) statement the AI will already have worked out that the format is 'D
jS F Y' for me. I’ll recognise a valid format when I see it, and I’ll be testing it anyway.
Boilerplate: Sometimes I have to work in languages that are… unnecessarily verbose. Rather than writing a stack of setters and getters, or laying out a repetitive
tree of HTML elements, or writing a series of data manipulations that are all subtly-different from one another in ways that are obvious once they’ve been explained to you… I can just
outsource that and then check it2.
Common refactoring practices: “Rewrite this Javascript function so it doesn’t use jQuery any more” is a great example of the kind of request you can throw at an LLM.
It’s already ingested, I guess, everything it could find on StackOverflow and Reddit and wherever else people go to bemoan being stuck with jQuery in their legacy codebase. It’s not
perfect – just like when it’s boilerplating – and will make stupid mistakes3
but when you’re talking about a big function it can provide a great starting point so long as you keep the original code alongside, too, to ensure it’s not removing any
functionality!
Other things… not so much. The other day I experimentally tried to have a GenAI help me to boilerplate some unit tests and it really failed at it. It determined pretty quickly,
as I had, that to test a particular piece of functionality need to mock a function provided by a standard library, but despite nearly a dozen attempts to do so, with copious prompting
assistance, it couldn’t come up with a working solution.
Overall, as a result of that experiment, I was less-effective as a developer while working on that unit test than I would have been had I not tried to get AI assistance: once I
dived deep into the documentation (and eventually the source code) of the underlying library I was able to come up with a mocking solution that worked, and I can see why the AI failed:
it’s quite-possibly never come across anything quite like this particular problem in its training set.
Solving it required a level of creativity and a depth of research that it was simply incapable of, and I’d clearly made a mistake in trying to outsource the problem to it. I was able to
work around it because I can solve that problem.
But I know people who’ve used GenAI to program things that they wouldn’t be able to do for themselves, and that scares me. If you don’t understand the code your tool has
written, how can you know that it does what you intended? Most developers have a blind spot for testing and will happy-path test their code without noticing if they’ve
introduced, say, a security vulnerability owing to their handling of unescaped input or similar… and that’s a problem that gets much, much worse when a “developer” doesn’t even
look at the code they deploy.
Security, accessibility, maintainability and performance – among others, I’ve no doubt – are all hard problems that are not made easier when you use an AI to write code that
you don’t understand.
Footnotes
1 I’ve 100% had an occasion when I’ve called something $theUserID in one
place and then $theUserId in another and not noticed the case difference until I’m debugging and swearing at the computer
2 I’ve described the experience of using an LLM in this way as being a little like having
a very-knowledgeable but very-inexperienced junior developer sat next to me to whom I can pass off the boring tasks, so long as I make sure to check their work because they’re so
eager-to-please that they’ll choose to assume they know more than they do if they think it’ll briefly impress you.
3 e.g. switching a selector from $(...) to
document.querySelector but then failing to switch the trailing .addClass(...) to .classList.add(...)– you know: like an underexperienced but
eager-to-please dev!
Especially outside of urban centres, and especially if you’re on foot, OpenStreetMap is way better than Google Maps, Bing Maps,
Apple Maps, or what-have-you.
The area at the North end of Sutton Lane, near where I live, is mostly just a huge expanse of nothing in Google Maps, but OpenStreetMap shows footpaths, gates, bridges, house names,
driveways, and land use indicators.
OpenStreetMap is especially good for walkers, with its more-comprehensive coverage of public footpaths as well as the ability to drill-down for accessibility information: whether a path
ends in a gate or a stile matters a lot if you can’t climb the latter (or you’re walking with a small-but-muddy dog who’ll need lifting over).
Sure, you don’t get (as much) street view photography. But how often do you use that, anyway?1
Of course, some of the places near me at which OpenStreetMap especially excels are… because of me! A little amateur cartography can go a long way.
I’ve heard it argued that OpenStreetMap, with its Wikipedia-like “anybody can edit it” model, cannot be relied upon. And sure, if you’re looking for an “official” level of accuracy and
the alternative is an Ordinance Survey map, then that’s what you should go for.
But there’s nothing specific to, say, Google Maps that makes it fundamentally more “accurate” for most2
geographic features than OpenStreetMap. The vast of cartographic data on Google Maps is produced by humans, looking at satellite photos, and then tracing the features on them, probably
with AI assistance. And the vast majority of cartographic data on OpenStreetMap is produced… exactly the same way, although without the AI “helping”.
Google Maps has mistakes, just like every map3. And it’s
got trap streets, like most commercially-produced maps (including the Ordinance Survey). Google Maps’ mistakes tend to be made by somebody on the other side of the world
from the feature, doing a bad job of tracing what they think might be a road… while OpenStreetMaps’ mistakes are for the most part omissions in areas that are under-explored by
local contributors. And there are plenty of areas – like those near where I live, especially if you’re on foot – where the latter mistakes are much less-troublesome.
If you’re looking to make a delivery to my village, where most buildings are named rather than numbered, postcode areas are broad, and it’s not always clear where it’ll be safe to
park… you’d do a lot better to use OpenStreetMap than any other digital map.
I fixed a couple of omissions on OpenStreetMap just earlier today. While I was out walking the dog, earlier, I added the names of two houses whose identities weren’t specifically marked on the map, and I
added detail to the newly-constructed Deansfield estate. Google Maps shows there being only
two houses on Deansfield Estate, among other inaccuracies, even though they’ve got up-to-date aerial and street photography.
Google Maps is fine if you want to drive to Sheffield, you need public transport connections to Plymouth4, or you’re looking for a restaurant nearby and you want
the data about them to be accurate. But next time you’re walking somewhere, or when you’re looking for a specific address… I’d suggest you give OpenStreetMap a go. You
might be pleasantly surprised.
Footnotes
1 I say that as somebody who uses street view and satellite photography a more
than average amount, for geohashing purposes. But I can switch mapping software on-the-fly; nobody’s stopping me looking at “ostrich” photos when I need them.
2 The place that Google Maps really beats OpenStreetMap, in my mind, is in the integration
of its business directory. If you search for a business in Google Maps, you’ll probably find it and get reasonably-accurate opening hours and contact details. But that’s a
factor of two things: the Google My Business directory, and – more importantly – the popularity of the application and the fact that the mobile app “nudges” people to check on the
places around them. By the way: if you want to contribute to making maps better in that way without becoming an unpaid researcher working to line Google’s pockets, StreetComplete is an app that helps fill-out business and related information on OpenStreetMap!
Checked up on this cache while the dog and I were nearby. It’s in fine condition and ready to find. The latch for the container is beginning to rust, but the whole thing is perfectly
serviceable. Go find it!
I don’t believe AI will replace software developers, but it will exponentially boost their productivity. The more I talk to developers, the more I hear the same thing—they’re now
accomplishing in half the time what used to take them days.
But there’s a risk… Less experienced developers often take shortcuts, relying on AI to fix bugs, write code, and even test it—without fully understanding what’s happening under the
hood. And the less you understand your code, the harder it becomes to debug, operate, and maintain in the long run.
So while AI is a game-changer for developers, junior engineers must ensure they actually develop the foundational skills—otherwise, they’ll struggle when AI can’t do all the heavy
lifting.
Eduardo picks up on something I’ve been concerned about too: that the productivity boost afforded to junior developers by AI does not provide them with the necessary experience to be
able to continue to advance their skills. GenAI for developers can be a dead end, from a personal development perspective.
That’s a phenomenon not unique to AI, mind. The drive to have more developers be more productive on day one has for many years lead to an increase in developers who are hyper-focused on
a very specific, narrow technology to the exclusion even of the fundamentals that underpin them.
When somebody learns how to be a “React developer” without understanding enough about HTTP to explain which bits of data exist on the server-side and which are delivered to the client,
for example, they’re at risk of introducing security problems. We see this kind of thing a lot!
There’s absolutely nothing wrong with not-knowing-everything, of course (in fact, knowing where the gaps around the edges of your knowledge are and being willing to work to fill them
in, over time, is admirable, and everybody should be doing it!). But until they learn, a developer that lacks a comprehension of the fundamentals on which they depend needs to
be supported by a team that “fill the gaps” in their knowledge.
AI muddies the water because it appears to fulfil the role of that supportive team. But in reality it’s just regurgitating code synthesised from the fragments it’s read in the
past without critically thinking about it. That’s fine if it’s suggesting code that the developer understands, because it’s like… “fancy autocomplete”, which you can
accept or reject based on their understanding of the domain. I use AI in exactly this way many times a week. But when people try to use AI to fill the “gaps” at the edge of their
knowledge, they neither learn from it nor do they write good code.
I’ve long argued that as an industry, we lack a pedagogical base: we don’t know how to teach people to do what we do (this is evidenced by the relatively
high drop-out rate on computer science course, the popular opinion that one requires a particular way of thinking to be a programmer, and the fact that sometimes people who fail to
learn programming through paradigm are suddenly able to do so when presented with a different one). I suspect that AI will make this problem worse, not better.
I was experimenting with VP8/VP9 WebM video transparency and I made a stupid thing: a URL that, if you go to it, means you’ll he followed around my blog by a video of me just hanging
out in the corner of the page – https://danq.me/?fool_id=06
I’ve added it to my list of “stupid/random things that can happen if you visit my blog on April Fools’ Day”: https://danq.me/fools/
Ruth bought me a copy of The Adventure Challenge: Couples
Edition, which is… well, it’s basically a book of 50 curious and unusual ideas for date activities. This week, for the first time, we gave it a go.
Each activity is hidden behind a scratch-off panel, and you’re instructed not to scratch them off until you’re committed to following-through with whatever’s on the other side. Only
the title and a few hints around it provide a clue as to what you’ll actually be doing on your date.
As a result, we spent this date night… baking a pie!
The book is written by Americans, but that wasn’t going to stop us from making a savoury pie. Of course, “bake a pie” isn’t much of a challenge by itself, which is why the book
stipulates that:
One partner makes the pie, but is blindfolded. They can’t see what they’re doing.
The other partner guides them through doing so, but without giving verbal instructions (this is an exercise in touch, control, and nonverbal communication).
I was surprised when Ruth offered to be the blindfoldee: I’d figured that with her greater experience of pie-making and my greater experience of doing-what-I’m-told, that’d be the
smarter way around.
We used this recipe for “mini creamy mushroom
pies”. We chose to interpret the brief as permitting pre-prep to be done in accordance with the ingredients list: e.g. because the ingredients list says “1 egg, beaten”, we were
allowed to break and beat the egg first, before blindfolding up.
This was a smart choice (breaking an egg while blindfolded, even under close direction, would probably have been especially stress-inducing!).
I’d do it again but the other way around, honestly, just to experience both sides! #JustSwitchThings
I really enjoyed this experience. It forced us into doing something different on date night (we have developed a bit of a pattern, as folks are wont to do), stretched our
comfort zones, and left us with tasty tasty pies to each afterwards. That’s a win-win-win, in my book.
Plus, communication is sexy, and so anything that makes you practice your coupley-communication-skills is fundamentally hot and therefore a great date night activity.
Our pies may have been wonky-looking, but they were also delicious.
So yeah: we’ll probably be trying some of the other ideas in the book, when the time comes.
Some of the categories are pretty curious, and I’m already wondering what other couples we know that’d be brave enough to join us for the “double date” chapter: four challenges for
which you need a second dyad to hang out with? (I’m, like… 90% sure it’s not going to be swinging. So if we know you and you’d like to volunteer yourselves, go ahead!)
Had a fight with the Content-Security-Policy header today. Turns out, I won, but not without sacrifices.
Apparently I can’t just insert <style> tags into my posts anymore, because otherwise I’d have to somehow either put nonces on them, or hash their content (which would
be more preferrable, because that way it remains static).
I could probably do the latter by rewriting HTML at publish-time, but I’d need to hook into my Markdown parser and process HTML for that, and, well, that’s really complicated,
isn’t it? (It probably is no harder than searching for Webmention links, and I’m overthinking it.)
I’ve had this exact same battle.
Obviously the intended way to use nonces in a Content-Security-Policy is to have the nonce generated, injected, and served in a single operation. So in PHP,
perhaps, you might do something like this:
<?php$nonce=bin2hex(random_bytes(16));
header("Content-Security-Policy: script-src 'nonce-$nonce'");
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>PHP CSP Nonce Test</title>
</head>
<body>
<h1>PHP CSP Nonce Test</h1>
<p>
JavaScript did not run.
</p>
<!-- This JS has a valid nonce: -->
<script nonce="<?phpecho$nonce; ?>">
document.querySelector('p').textContent = 'JavaScript ran successfully.';
</script>
<!-- This JS does not: -->
<script nonce="wrong-nonce">
alert('The bad guys won!');
</script>
</body>
</html>
Viewing this page in a browser (with Javascript enabled) should show the text “JavaScript ran successfully.”, but should not show an alertbox containing the text “The bad
guys won!”.
But for folks like me – and you too, Vika,, from the sounds of things – who serve most of their pages, most of the time, from the cache or from static HTML files… and who add the CSP
header on using webserver configuration… this approach just doesn’t work.
I experimented with a few solutions:
A long-lived nonce that rotates.
CSP allows you to specify multiple nonces, so I considered having a rotating nonce that was applied to pages (which were then cached for a period) and delivered
by the header… and then a few hours later a new nonce would be generated and used for future page generations and appended to the header… and after the
cache expiry time the oldest nonces were rotated-out of the header and became invalid.
Dynamic nonce injection.
I experimented with having the webserver parse pages and add nonces: randomly generating a nonce, putting it in the header, and then basically doing a
s/<script/<script nonce="..."/ to search-and-replace it in.
Both of these are terrible solutions. The first one leaves a window of, in my case, about 24 hours during which a successfully-injected script can be executed. The second one
effectively allowlists all scripts, regardless of their provenance. I realised that what I was doing was security theatre: seeking to boost my A-rating to an A+-rating on SecurityHeaders.com without actually improving security at all.
But the second approach gave me an idea. I could have a server-side secret that gets search-replaced out. E.g. if I “signed” all of my legitimate scripts with something like
<script nonce="dans-secret-key-goes-here" ...> then I could replace s/dans-secret-key-goes-here/actual-nonce-goes-here/ and thus have the best of both
worlds: static, cacheable pages, and actual untamperable nonces. So long as I took care to ensure that the pages were never delivered to anybody with the secret key still
intact, I’d be sorted!
Alternatively, I was looking into whether Caddy can do something like mod_asis does for Apache: that is, serve a
file “as is”, with headers included in the file. That way, I could have the CSP header generated with the page and then saved into the cache, so it’s delivered with the same
none every time… until the page changes. I’d love more webservers to have an “as is” mode, but I appreciate that might be a big ask (Apache’s mechanism, I suspect,
exploits the fact that HTTP/1.0 and HTTP/1.1 literally send headers, followed by two CRLFs, then content… but that’s not what happens in HTTP/2+).
So yeah, I’ll probably do a server-side-secret approach, down the line. Maybe that’ll work for you, too.
When you’re writing online, being unique doesn’t matter nearly as much as being found.
I’m not sure I could disagree more. But I’ve jumped in half way through his post. Let’s backtrack a bit.
Andy begins:
A blogger showed me his website the other day.
…
But no one was reading it.
Firstly: let’s just observe that you were shown a website… and now you’re talking about it… but you haven’t linked to it? You’re complaining about its lack of discoverability,
while simultaneously being part of the problem.
Hyperlinks remain, as they have been since the mid-to-late 1990s, a primary mechanism in helping search engines’ spiders to discover new sites, and nowadays they’re doubly-important
because they help establish legitimacy.
When you search for, say, “history of web search” and this Wikipedia article is at the top, a significant
reason for that is that people link to that page when talking about the history of web search! A secondary reason is that lots of people link to Wikipedia in
general.
Your mileage may vary depending on your preferred search engine and other factors.
Berating somebody for an unindexed site… but not linking to that site… feels awfully-close to victim-blaming!
(Especially recently, as still-dominant search engine Google continues to make it harder and harder for “new” sites to get onto the ladder.)
When I asked him why he didn’t just use WordPress or Bear Blog, he looked offended.
“Those are so basic. Everyone uses those. I wanted something unique.”
I’m not sure I understand the logic of the person whose argument against e.g. WordPress is that it’s not “unique”. There are lots of great reasons that you might use WordPress. There
are lots of great reasons that you might not. The right choice of CMS should be based on a variety of factors.
It’s possible that the person being referred to meant “customisable”. They’d still be wrong (in the case of WordPress, at least: Bear Blog offers significantly less customisation
options, which is fine if the other features are what you’re looking for), but anyway: the short of it is that I briefly agreed, here, until:
WordPress powers about 43% of all websites. That means search engines know exactly how to read WordPress sites.
They know where to look for the content, the metadata, the tags.
Let’s correct the points here:
Search engines know exactly how to read HTML. WordPress outputs HTML. (If you’re outputting HTML, your site can be indexed. Hell, even that isn’t a firm
requirement: my plaintext-only blog shows up in search engines!)
Web standards dictate how content, metadata, and tags should be laid out. A search engine’s spider doesn’t look at your site and go “hey, it’s WordPress, so I need to
look for this“. Instead, it’ll generally look for content and metadata based on established standards. Titles, headings, <meta> tags, semantic elements:
these are the things a search engine looks for.
Sure, WordPress gets those things right. But they’re not hard to get right. You shouldn’t use WordPress (or Bear, or anything else) based just on the fact
that it exposes metadata correctly. Any site can do this. And because what’s eventually exposed to the search engine – and to the user – is HTML code… which is independent of the CMS
that generated it… it doesn’t have to matter what the underlying CMS is.
Then there’s some more confusion:
Here’s what matters: WordPress and other major platforms have spent years optimising for search engines and social sharing.
They’ve spent millions making sure posts load fast.
This sounds like it’s conflating WordPress (the open-source CMS) with one or more of several WordPress hosting providers (probably WordPress.com). That’s a common mistake, but it is a mistake.
WordPress can do terrible SEO. WordPress can be really slow. Trust me: in a previous life I’ve made a part of my living out of fixing and improving people’s WordPress-powered websites!
A large part of this comes from WordPress’s flexibility: the theme you choose, for example, can completely change the functionality of your site. Inspired by my plain text blog,
Terence Eden made a WordPress theme that does the same thing! That WordPress theme completely
upends the way that most people would use WordPress, but it’s still fundamentally WordPress, even though it exposes to search engines no HTML code, no metadata,
and no tags.
WordPress can also do great SEO, and it can be really fast. A properly-configured WordPress site can be a well-oiled machine. But if you conflate WordPress itself with its output,
you’re arguing against a straw man.
Don’t get me wrong: I love WordPress! But I dislike people making the false claim that if you’re not using it (or another popular blogging tool), you’re destined to fail at SEO. There’s
nothing “magical” about WordPress. It just takes content and renders HTML, in the end!
But all of this is moot, perhaps, when we get back to that first point:
When you’re writing online, being unique doesn’t matter nearly as much as being found.
This entire statement presupposes the purpose of “writing online”.
It’s 100% okay to write for yourself, first and foremost. It’s also okay to write for a small target audience, like for your friends or family. It’s okay to write content that
isn’t exposed to search engines (consider all of the wonderful content that my fellow RSS Club members put out, sometimes!). It’s
okay to write just for the joy of making things.
A website doesn’t have to be “professional”, as Andy’s post goes on to imply. A website doesn’t have to be anything in particular. A website can just… be. And that’s
enough.
It’s possible I don’t understand social media any more. To be fair, it’s possible that I never did.
This is something between absurd and hilarious. Aside from the 100 year plan (which is fascinating, and I keep meaning to share my thoughts
on), I’m not sure what it’s supposed to be advertising. Maybe it’s trying to showcase how cool it is to work with Automattic? (It’s
not… exactly like it’s depicted in the video. But I’d be lying if I said that fewer than 50% of my meetings this week have included a discussion on snack foods, so maybe we are
I guess at least a little eccentric.)
I think I understand what it’s parodying. And that’s fun. But… wow. You don’t see many videos like this attached to a corporate YouTube account, do you? Kudos for keeping the Internet
fun and weird, WordPress.com.
A lunchtime dog walk was made especially delightful by the growing warmth of the approaching British springtime. It’s really bright and pretty out, this afternoon!
As I mentioned in my recent Blog Questions Challenge, I recently switched my blog from WordPress, which it had been running on for over 20 years of its 26 year history, to ClassicPress.1
I’m aware that I’m not the only person for whom ClassicPress might be a better fit
than WordPress2,
so I figured I should share the process by which I undertook the change.
Switching from WordPress to ClassicPress
Switching from WordPress to ClassicPress should be a non-destructive, 100% reversible process, but (even though I’ve got solid backups) I wasn’t ready to
trust that, so I decided to operate on a copy of my site. I’m glad I did, because there were a couple of teething issues I needed to tackle before I could launch.
1. Duplicating the site
I took a simple approach to duplicating the site: (1) I copied the site directory, and (2) I copied the database, and (3) I set up a new subdomain to use for testing. Here’s how I did
each step:
1.1. Copying the site directory
This should’ve been simple, but a du -sh revealed that my /wp-content/uploads directory is massive (I should look into that) and I didn’t want to
clone it. And I didn’t want r need to clone my /wp-content/cache directory either. So I ran:
rsync -av --exclude=wp-content ./old-site-directory/ ./new-site-directory/ to copy everything exceptwp-content, and then
rsync -av --exclude=uploads --exclude=cache ./old-site-directory/wp-content/ ./new-site-directory/wp-content/ to copy wp-contentexcept the
uploads and cache subdirectories, and then finally
ln -s ./old-site-directory/wp-content/uploads ./new-site-directory/wp-content/uploads to symlink the uploads directory, sharing it between the two sites
1.2. Copying the database
I just piped mysqldump into mysql to clone from one database to the other:
mysqldump -uUSERNAME -p --lock-tables=false old-site-database | mysql -uUSERNAME -p new-site-database
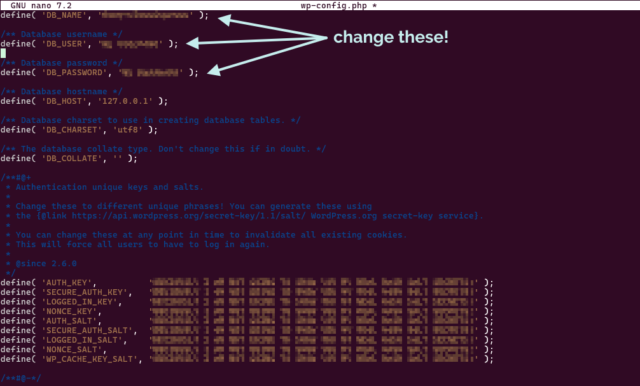
I edited DB_NAME in wp-config.php in the new site’s directory to point it at the new database.
If you’re going to clone your WordPress site before converting to ClassicPress, you’ll want to be comfortable editing your wp-config.php.
1.3. Setting up a new subdomain
My DNS is already configured with a wildcard to point (almost) all *.danq.me subdomains to this server already. I decided to use the name classicpress-testing.danq.me as my
temporary/test domain name. To keep any “changes” to my cloned site to a minimum, I overrode the domain name in my wp-config.php rather than in my database, by adding the
following lines:
Because I use Caddy/FrankenPHP as my webserver3,
configuration was really easy: I just copied the relevant part of my Caddyfile (actually an include), changed the domain name and the root, and it just worked,
even provisioning me out a LetsEncrypt SSL certificate. Magical4.
2. Switching the duplicate to ClassicPress
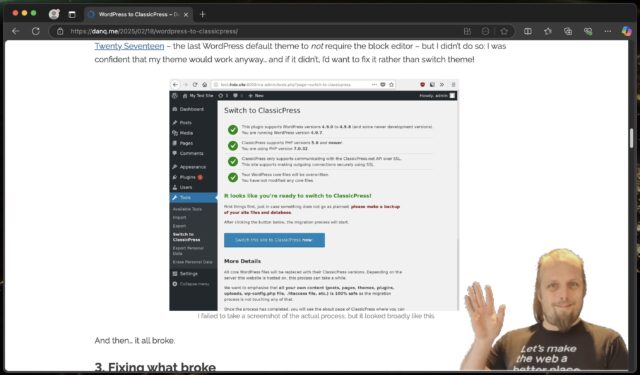
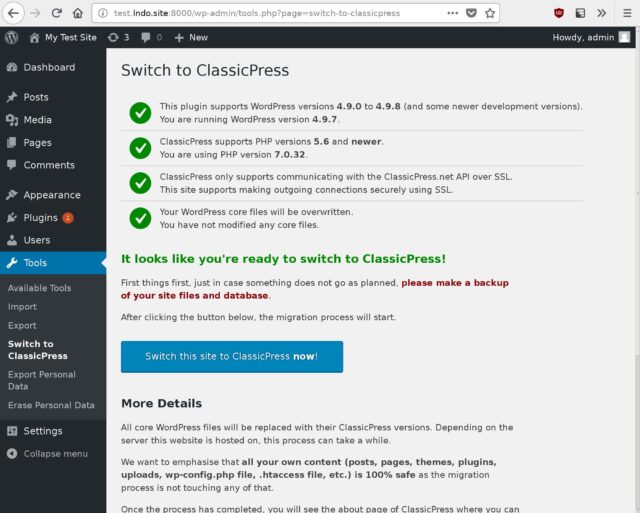
Now that I had a duplicate copy of my blog running at https://classicpress-testing.danq.me/, it was time to switch it to ClassicPress. I started by switching my wp-admin
colour scheme to a different one in my cloned site, so it’d be immediately visually-obvious to me if I’d accidentally switched and was editing the “wrong” site (I also made sure I was
logged-out of my primary, live site, so I was confident I wouldn’t break anything while I was experimenting!).
ClassicPress provides a migration plugin which checks for common problems and then switches your site
from WordPress to ClassicPress, so I installed it and ran it. It said that everything was okay except for my (custom) theme and a my self-built plugins, which it understandably couldn’t
check compatibility of. It recommended that I install Twenty Seventeen – the last WordPress default theme to not
require the block editor – but I didn’t do so: I was confident that my theme would work anyway… and if it didn’t, I’d want to fix it rather than switch theme!
I failed to take a screenshot of the actual process, but it looked broadly like this.
And then… it all broke.
3. Fixing what broke
After swiftly doing a safety-check that my live site was still intact, I started trying to work out why my site wasn’t broken. Debugging a ClassicPress PHP issue is functionally
identical to debugging a similar WordPress issue, for obvious reasons: check the logs, work out what’s broken, realise it’s a plugin, disable that plugin while you investigate further,
etc.
EWWW Image Optimizer: I use this plugin to pregenerate WebP variants of my images, which I then serve using webserver rules. It’s not a
complex job, and I should probably integrate the feature into my theme at some point, but for now I use this plugin. Version 8.0.0 of the plugin doesn’t work on ClassicPress 2.3.1, so
I used WP-CLI to downgrade to the last version that does (7.7.0), and then it worked fine.
Dan’s Geocaching Log Reposter: a self-made plugin that copies my logs from geocaching websites stopped working properly, which I think is because
ClassicPress is doing a more-aggressive job than WordPress at nonce validation on admin REST endpoints? I put a quick hack into my plugin to work around it, but I’ll need to look into
this properly at some point.
Some other bits of my stack, e.g. CapsulePress (my Gemini/Spartan/Nex server), have their own copies of my
database credentials, because I’ve been too lazy to centralise them into environment variables, and needed updating (but not until live switchover time).
I ran the two sites in-parallel for a couple of weeks, with the ClassicPress one as a “read only” version (so I didn’t pollute my uploads directory!), but it was pretty unnecessary
because it all worked pretty seamlessly, despite my complex stack of custom code. When I wanted to switch for-real, all I needed to do was swap the domain names over in my Caddyfile and
edit the wp-config.php of my ClassicPress installation: step 1.3, but in reverse!
If you hadn’t been told5, you probably wouldn’t have even known I’d made a change: I suppress basically all infrastructure-identifying
headers from my server output as a matter of course, and ClassicPress and WordPress are functionally-interchangeable from a front-end perspective6.
So what’s difference?
From my experience, here are the differences I’ve discovered since switching from WordPress to ClassicPress:
The good stuff
😅 ClassicPress has no Gutenberg/block editor. This would absolutely be a showstopper for many people, and that’s fine: I have nothing against the block editor (I
use it basically every day elsewhere!), but I’ve never really used it on danq.me and don’t feel the need to change that! My theme, my workflow, and my custom plugins are all
geared around the perfectly-good “classic” editor, and so getting a more-lightweight CMS by removing a feature I wasn’t using anyway falls somewhere between neutral and a blessing.
⚡The backend is fast again! One of the changes the ClassicPress team have been working on applying to WordPress is to strip out jQuery and other redundancies from
the backend, and I love how much faster and lighter my editor interface is as a result. (With caveat; see below!)
🔌Virtually everything “just works”. With the few exceptions described above, everything works exactly as it does under WordPress. Which is what you’d hope for a fork
that’s mostly “WordPress, but without the block editor”, right, but it’s still reassuring (and, for me, an essential feature). There are a few “new” features to do with paging through
posts and the media library and they’re fine, I suppose, but not by themselves worth switching for (though it might be nice to backport them into WordPress!).
The bad stuff
🏷️ Adding tags to posts takes a step backwards. A side-effect of dropping jQuery is the partial loss of the autocomplete feature when selecting tags to add to a post.
You still get a partial autocomplete, but not after typing a comma: you need to press enter to submit the tag you were writing and then start typing them next, which
frankly sucks. This is because they’re relying on a <datalist>, which isn’t as full-featured as the Javascript solution WordPress employs. This bugs
me almost enough to be a showstopper, but I gather it’s getting fixed in a near-future version.
🗺️ You’re in uncharted territory when things go wrong. One great benefit of WordPress is the side-effects of its ubiquity. If you have a query or a problem
you can throw a stone at your favourite search engine and get a million answers… and some of them will even be right! If you have a problem in ClassicPress and it’s not shared with (or
you’re not sure if it’s shared with) WordPress… you’re mostly on your own. The forums are good and friendly,
but if you want a quick answer to something, you’re likely to have to roll your sleeves up and open some source code. I don’t mind this at all – when I first started using WordPress,
this was the case, too! – but it might be a showstopper for some folks.
In summary: I’m enjoying using ClassicPress, even where there are rough edges. For me, 99% of my experience with it is identical to how I used WordPress anyway, it’s relatively
lightweight and fast, and it’s easy enough to switch back if I change my mind.
Footnotes
1 It saddens me that I have to keep clarifying this, but I feel like I do: my switch from
WordPress to ClassicPress is absolutely nothing to do with any drama in the WordPress space that’s going on right now: in fact, I’d been planning to try it out since before
any of the drama appeared. I appreciate that some people making a similar switch, including folks who use this blog post as a guide, might have different motivations to me, and that’s
fine too. Personally, I think that ditching an installation of open-source WordPress based on your interpretation of what’s going on in the ecosystem is… short-sighted? But
hey: the joy of open source is you can – and should! – do what you want. Anyway: the short of it is – the desire to change from WordPress to ClassicPress was, for me, 100% a
technical decision and 0% a political one. And I’ll thank you for leaving any of your drama at the door if you slide into my comments, ta!
2Matt recently described ClassicPress as “the last decent fork
attempt for WordPress”, and I absolutely agree. There’s been a spate of forks and reimplementations recently. I’ve looked into many of them and been… very much underwhelmed. Want my
hot take? Sure, here you go: AspirePress is all lofty ideas and no deliverables. FreeWP seems to be the same, but somehow without the lofty ideas. ForkPress is a ghost. Speaking of
ghosts, Ghost isn’t a WordPress fork; they have got some cool ideas though. b2evolution is even less a WordPress fork but it’s pretty cool in its own right. I’m not sure what
clamPress is trying to achieve but I’ve not given it a serious look. So yeah: ClassicPress is, in my mind, the only WordPress fork even worth consideration at this point, and as I
describe in this blog post: it’s not for everybody.
3 I switched from Nginx over the winter and it’s been just magical: I really love
Caddy’s minimal approach to production configuration. The only thing I’ve been able to fault it on is that it’s not capable of setting up client-side SSL certificate authentication on
a path, only on an entire domain, which meant I needed to reimplement the authentication mechanism I use on a small part of my (non-blog) internal
infrastructure.
4 To be fair, it wouldn’t have been hard if I’d still be using Nginx, because I’d
set up Certbot to use DNS-based vertification to issue me wildcard SSL certificates. But doing this in Caddy still felt magical.
6 Indeed, I wouldn’t have considered a switch to ClassicPress in the first place if it
wasn’t a closely-aligned-enough fork that I retained the ability to flip-flop between the two to my heart’s content! I’ve loved WordPress for over two decades; that’s not going to
change any time soon… and if e.g. ClassicPress ceased tracking WordPress releases and the fork diverged too far for my comfort, I’d probably switch back to regular old WordPress!
Large companies find HTML & CSS frustrating “at scale” because the web is a fundamentally anti-capitalist mashup art experiment, designed to give consumers all the power.
This. This is what I needed to be reminded, today.
When somebody complains that the Web is hard to scale, they’re already working against the grain of the Web.
At its simplest – and the way we used to use it – a website is a collection of .html files, one of which might have a special name so the webserver knows to put it first.
Writing HTML is punk rock. A “platform” is the tool of the establishment.
A straight white guy friend was complaining about not being able to find any gaming groups for WoW that weren’t full of MAGA assholes. He said he keeps joining guilds with older
(60+) casual gamers like himself because he can’t keep up with the kids, and he’ll start to make friends, but then they will reveal themselves to be Trump-lovers. He asked, “What am
I doing wrong?”
…
This was about 3 months ago. Now, he tells me he joined a guild labeled as LGBTQ-friendly and has made several new cool friends.
…
He mentioned that there are many women and PoC in the group too, and “Everyone’s so nice on dungeon runs, telling people they did a good job and being supportive, sharing loot.”
I didn’t tell him that this is what the whole world would be like without patriarchal toxic masculinity, because I think he figured it out himself.
I’ve plucked out the highlights, but the deeper moral is in the full anecdote. I especially loved “…furries are
like lichen…”. 😆

![Comic comparing 'Devs Then' to 'Devs Now'. The 'Devs Then' are illustrated as muscular men, with captions 'Writes code without AI or Stack Overflow', 'Builds entire games in Assembly', 'Crafts mission-critical code fo [sic] Moon landing', and 'Fixes memory leaks by tweaking pointers'. The 'Devs Now' are illustrated with badly-drawn, somewhat-stupid-looking faces and captioned 'Googles how to center a div in 2025?', 'ChatGPT please fix my syntax error', 'Cannot exit vim', and 'Fixes one bug, creates three new ones'.](https://bcdn.danq.me/_q23u/2025/02/devs-then-devs-now-lieo-640x601.jpg)