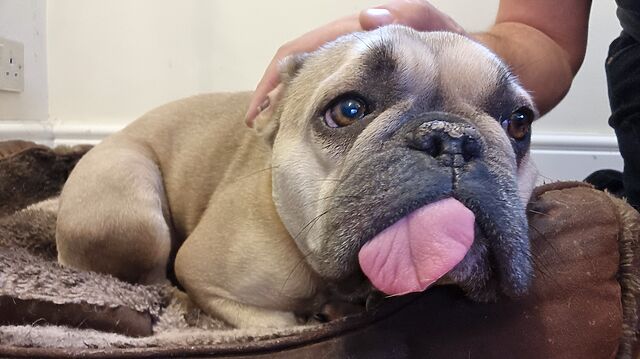
It’s the Seventh of Bleptember, and our dorky doggo has decided that this is somehow a comfortable position in which to take a nap.

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
It’s the Seventh of Bleptember, and our dorky doggo has decided that this is somehow a comfortable position in which to take a nap.
This checkin to GCBC09Z A Riverside Walk reflects a geocaching.com log entry. See more of Dan's cache logs.
FTF after a delightful walk and a surprisingly challenging hunt!
When I woke this morning and saw a new semi-local cache, about when I ought to be getting myself and the geopup up anyway, I was intrigued. Bed called me back for a Sunday morning lie-in, but eventually I escaped its clutches and the geohound and I set out on our adventure.
Parking in Bladon was a challenge but we were fortune enough to find a residential road with a few spots up towards St. Martin’s Church. After that, and working out how to open the gate to the Community Footpath, we were on our way.

Passing the world’s most pointless gate and a heron finding his breakfast (both pictured), the doggo and I enjoyed our riverside stroll in relative peace and quiet, excepting the occasional jogger or dog walker that would come the other way. Eventually we found the bridge, stopped to enjoy the view a little, and then began the hunt.

Even with the hint and a strong idea of what I was looking for, this was a challenging search. I’ll bet my kids would’ve found the cache much faster than my ~15-20 minute search, but eventually I caught a glimpse of it, worked my way to it, and retrieved the log. Seeing it still blank, I claimed my FTF, and then had a brief panic when I discovered that I could no longer see it’s hiding place! A brief re-search and I’d found it again, but for a while there I was kicking myself for taking the time to return to the wall of the bridge to write my log!

Returned as found. TFTC, and for the lovely walk!
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
I am Doggle. See me Blep.
Happy Sixth of Bleptember from this sofa-loving pupper.

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
It’s the Fifth of Bleptember, and our bleppy young lady is enjoying some reassurance that the team of tree surgeons working noisily on the other side of the road don’t pose any threat to her.
Today, for the first time ever, I simultaneously published a piece of content across five different media: a Weblog post, a video essay, a podcast episode, a Gemlog post, and a Spartanlog post.
Must be about something important, right?
Nope, it’s a meandering journey to coming up with a design for a £5 coin that will never exist. Delightfully pointless. Being the Internet I want to see in the world.
This post is also available as an article. So if you'd rather read a conventional blog post of this content, you can!
This post is also available as a podcast. Listen here, download for later, or subscribe wherever you consume podcasts.
This post is also available as a video. If you'd prefer to watch/listen to me talk about this topic, give it a look.
The novelisation of The Hitch-Hiker’s Guide to the Galaxy came out in 1979, just a smidge before I was born. There’s a well-known scene in the second chapter featuring Ford Prefect, an alien living on Earth, distracting his human friend Arthur Dent. Arthur is concerned about the imminent demolition of his house by a wrecking crew, and Ford takes him to the pub to get him drunk, in anticipation of the pair attempting to hitch a lift on an orbiting spacecraft that’s about to destroy the planet:
“Six pints of bitter,” said Ford Prefect to the barman of the Horse and Groom. “And quickly please, the world’s about to end.”
The barman of the Horse and Groom didn’t deserve this sort of treatment, he was a dignified old man. He pushed his glasses up his nose and blinked at Ford Prefect. Ford ignored him and stared out of the window, so the barman looked instead at Arthur who shrugged helplessly and said nothing.
So the barman said, “Oh yes sir? Nice weather for it,” and started pulling pints.
He tried again.
“Going to watch the match this afternoon then?”
Ford glanced round at him.
“No, no point,” he said, and looked back out of the window.
“What’s that, foregone conclusion then you reckon sir?” said the barman. “Arsenal without a chance?”
“No, no,” said Ford, “it’s just that the world’s about to end.”
“Oh yes sir, so you said,” said the barman, looking over his glasses this time at Arthur. “Lucky escape for Arsenal if it did.”
Ford looked back at him, genuinely surprised.
“No, not really,” he said. He frowned.
The barman breathed in heavily. “There you are sir, six pints,” he said.
Arthur smiled at him wanly and shrugged again. He turned and smiled wanly at the rest of the pub just in case any of them had heard what was going on.
None of them had, and none of them could understand what he was smiling at them for.
A man sitting next to Ford at the bar looked at the two men, looked at the six pints, did a swift burst of mental arithmetic, arrived at an answer he liked and grinned a stupid hopeful grin at them.
“Get off,” said Ford, “They’re ours,” giving him a look that would have an Algolian Suntiger get on with what it was doing.
Ford slapped a five-pound note on the bar. He said, “Keep the change.”
“What, from a fiver? Thank you sir.”
There’s a few great jokes there, but I’m interested in the final line. Ford buys six pints of bitter, pays with a five-pound note, and says “keep the change”, which surprises the barman. Presumably this is as a result of Ford’s perceived generosity… though of course what’s really happening is that Ford has no use for Earth money any longer; this point is hammered home for the barman and nearby patrons when Ford later buys four packets of peanuts, also asking the barman to keep the change from a fiver.

We’re never told exactly what the barman would have charged Ford. But looking at the history of average UK beer prices and assuming that the story is set in 1979, we can assume that the pints will have been around 34p each1, so around £2.04 for six of them. So… Ford left a 194% tip for the beer2.
By the time I first read Hitch-Hikers, around 1990, this joke was already dated. By then, an average pint of bitter would set you back £1.10. I didn’t have a good awareness of that, being as I was well-underage to be buying myself alcohol! But I clearly had enough of an awareness that my dad took the time to explain the joke… that is, to point out that when the story was written (and is presumably set), six pints would cost less than half of five pounds.
But by the mid-nineties, when I’d found a friend group who were also familiar with the Hitch-Hikers… series, we’d joke about it. Like pointing out that by then if you told the barman to keep the change from £5 after buying six pints, the reason he’d express surprise wouldn’t be because you’d overpaid…

Precocious drinker that I was, by the late nineties I was quite aware of the (financial) cost of drinking.

And so when it was announced that a new denomination of coin – the £2 coin – would enter general circulation3 I was pleased to announce how sporting it was of the government to release a “beer token”.
With the average pint of beer at the time costing around £1.90 and a still cash-dominated economy, the “beer token” was perfect! And in my case, it lasted: the bars I was drinking at in the late 1990s were in the impoverished North, and were soon replaced with studenty bars on the West coast of Wales, both of which allowed the price of a pint to do battle with inflationary forces for longer than might have been expected elsewhere in the country. The “beer token” that was the £2 coin was a joke that kept on giving for some time.

As the cost of living rapidly increased circa 2023, the average price of a pint of beer in the UK finally got to the point where, rounded to the nearest whole pound, it was closer to £5 than it is to £44.
And while we could moan and complain about how much things cost nowadays, I’d prefer to see this as an opportunity. An opportunity for a new beer token: a general-release of the £5 coin. We already some defined characteristics that fit: a large, heavy coin, about twice the weight of the £2 coin, with a copper/nickel lustre and struck from engravings with thick, clear lines.
And the design basically comes up with itself. I give you… the Beer Token of the 2020s:

It’s time for the beer token to return, in the form of the £5 coin. Now is the time… now is the last time, probably… before cash becomes such a rarity that little thought is evermore given to the intersection of its design and utility. And compared to a coin that celebrates industry while simultaneously representing a disfunctional machine, this is a coin that Brits could actually be proud of. It’s a coin that tourists would love to take home with them, creating a satisfying new level of demand for the sinking British Pound that might, just might, prop up the economy a little, just as here at home they support those who prop up the bar.
I know there must be a politician out there who’s ready to stand up and call for this new coin. My only fear is that it’s Nigel Fucking Farage… at which point I’d be morally compelled to reject my own proposal.
But for now, I think I’ll have another drink.
1 The recession of the 1970s brought high inflation that caused the price of beer to rocket, pretty much tripling in price over the course of the decade. Probably Douglas Adams didn’t anticipate that it’d more-than-double again over the course of the 1980s before finally slowing down somewhat… at least until tax changes in 2003 and the aftermath of the 2022 inflation rate spike!
2 We do know that the four packets of peanuts Ford bought later were priced at 7p each, so his tip on that transaction was a massive 1,686%: little wonder the barman suddenly started taking more-seriously Ford’s claims about the imminent end of the world!
3 There were commemorative £2 coins of a monometallic design floating around already, of course, but – being collectible – these weren’t usually found in circulation, so I’m ignoring them.
4 Otherwise known as “two beer tokens”, of course. As in “Bloody hell, 2022, why does a pint of draught cost two beer tokens now?”
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
It’s the Fourth of Bleptember, but I couldn’t help but share a photo from the Third, when our dog just couldn’t find space for her tongue and her ball in her mouth at the same time… but soon found a workaround.

Photo courtesy Lisa from Muddy Paws.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
It’s the Third of Bleptember, and this routine-loving pupper is still confused by the fact that the elder child doesn’t come on the school-run morning walk any more, instead leaving early to catch the bus to her new school. Look at those big anxious eyes, poor thing!

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
The Second of Bleptember brought back the morning school run into this doggo’s routine. And while she was glad of the extra walk, she also seemed glad of the opportunity to lie down in a quiet, child-free hallway upon our return home.

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Bleptember’s upon us once again, so I’ll be attempting to snap a daily picture of my bleppy doggo with her tongue sticking out!

This young lady is dog-tired after a long day of running around and playing, this First of Bleptember.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
In 2024, we each seperately submitted Freedom of Information requests to our country’s railway operators, asking for specification about how their barcodes worked. This has made a lot of people very angry and has been widely regarded as a bad move.
This talk details the drama, lies, and nonsense, that ensued as seemingly every part of the UK’s and Slovenian rail industry set out to stop us from getting access to the documents we requested.
Train tickets in the UK can be issued in two formats: on security card stock, or as a barcode on a mobile phone. Being the curious beings we are, we were curious about what was in those barcodes. What information on us is processed in them? How do they encode our journeys? Can we do anything interesting with their contents?
…
In spite of knowledge from the reverse engineering work about these tickets’ use of public/private key cryptography, and the absolute non-issue of making public keys, well, public, seemingly every part of the UK rail industry put Q’s picture on their office dartboard and vowed to never let them have these documents.
…
A really interesting-sounding session at MRMCD 2025 in a couple of weeks, by that other hacker called Q. Wish I could be there… but failing that, perhaps the talk, or at least the discoveries, will make their way onto the open Internet?
The dog came out for a walk with the eldest kid and I, but we couldn’t stop her sticking her head down rabbitholes!

(Oh, and the dog kept doing it, too.)
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Mastodon shows an “Alt” button in the bottom right of images that have associated alt text. This button, when clicked, shows the alt text the author has written for the image.
…
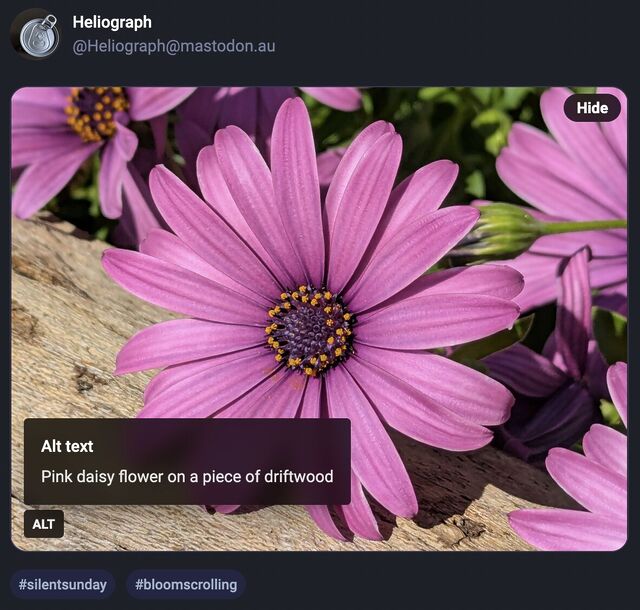
After using this button a few times, I realised how much I appreciated reading the alt text for an image. Reading the alt text helped me better understand an image. In some cases, I saw posts where the alt text contained context about an image I otherwise would not have had (i.e. the specific name of the game from which a screenshot was taken).
…
Like James, I’ve also long enjoy Mastodon’s tools to help explore alt-text more-easily, but until I saw this blog post of his I’d never have considered porting such functionality to my own sites.
He’s come up with an implementation, described in his post, that works pretty well. I find myself wondering if a <details>/<summary> UI metaphor
might be more appropriate than a visually-hidden checkbox. Where CSS is disabled or fails, James’ approach displays a checkbox, the word “ALT”, and the entire alt text, which is
visually confusing and will result in double-reading by screen readers.
 A
A <details>/<summary> approach would be closer to
semantically-valid (though perhaps I’m at risk of making them a golden hammer?), and would degrade more gracefully
into situations in which CSS wasn’t available.
Still, a wonderful example of what can be done and something I might look at replicating during my next bout of blog redesigning!
Looking forward to the school run starting again next week… so I get a bonus excuses for walks around our beautiful village!
