Highlights of yesterday’s Goodbye Nightline Association party in Manchester:
👨💻 Responded to Three Rings user query in real time by implementing new Directory property while at the event (pictured)
🤝 Met a handful of Nightliners past and present; swapped war stories of fights with students unions, battles for funding, etc. (also got some insights into how they’re using various
tech tools!)
✍️ Did hilariously awful job of drawing ‘Condom Man’, Aberystwyth Nightline’s mascot circa 2000
🤞 Possibly recruited a couple of new Three Rings volunteers
Low points:
😢 It’s a shame NLA’s dying, but I’m optimistic that Nightlines will survive
I’m in Manchester for the day for a social gathering related to a variety of the volunteering activities I’ve been involved with over the last, OMG-I’m-so-old, 26 years or so. After my
train arrived I meandered via OK04B5 (nice to see the OC community alive and well here in Manchester!) to find myself
some lunch, then dropped by this cache on my way to our event venue.
The location was spot on and I saw the cache rightaway, but needed to wait for a couple of Deliveroo drivers to finish chatting and leave before I could get to the container itself.
Soon in hand, though. TFTC!
I’m in Manchester for a volunteering-adjacent social event and, not often seeing OpenCaches pop up on my radar, visited this spot on my way from the station to the venue. So beautiful
to see Manchester acknowledge its part in queer history, and a beautiful memorial to everybody who has died as a result of the AIDS pandemic. TFTC!
Oxford Station. Catching a train to Manchester for a get-together in memory of the Nightline Association, which will sadly be closing this year (although individual Nightlines will
doubtless soldier on just as they did before the Association).
Carrying a big ol’ bag of Three Rings swag to give to basically anybody who expresses even the slightest interest. 😅
Three Rings has been supporting Nightlines since before the Nightline Association and nowadays underpins voluntary work by hundreds of other charities including helplines like
Samaritans and Childline. Feeling sad that the Nightline Association is going away and looking for a new and rewarding way to volunteer? Come chat to me!
This video, which I saw on Nebula but which is also available on YouTube, explores a hypothetical alternate history in which the Schuman Plan/European Coal & Steel Community never happened, and the knock-on effects lead to no EU, a more fragmented Europe,
and an ultimately more-fractured and more-complicated Europe of the late 20th/early 21st century.
Obviously it’s highly-speculative and you could easily come up with your own alternative alternative history! But the Twilight Struggle player in me as well as the alternate
history lover (and, of course, European Union fan) especially loves the way this story is told.
It’s worth remembering that for the last half-millenium or more, the default state of Europe has been to be fighting one another: if not outright war then at least agressive
economic and political rivals. Post-WWII gave Europe perhaps its longest ever period of relative peace, and that’s great enough that all of the other benefits of a harmonised
and cooperative union are just icing on the cake.
EU Made Simple is a fantastic channel in general, and I’d recommend you give it a look. It ties news and history in with its creators
outlook, but it’s always clear which bits are opinion and it’s delightfully bitesized. For Europeans-in-exile in this post-Brexit age, it’s hopeful and happy, and I like it.
While working on something else entirely1,
I had a random thought:
Could the :checked and and :has pseudo-classes and the subsequent-sibling (~) selector be combined to perform interactive filtering
without JavaScript?
Turns out, yes. Have a play with the filters on the side of this. You can either use:
“OR” mode, so you can show e.g. “all mammals and carnivores”, or
“AND” mode, so you can show e.g. “all mammals that are carnivores”.
Filter the animals!
(if it doesn’t work right where you are, e.g. in a feed reader, you can view it “standalone”)
There’s nothing particularly complicated here, although a few of the selectors are a little verbose.
First, we set the initial state of each animal. In “OR” mode, they’re hidden, because each selected checkbox is additive. In “AND” mode, they’re shown, because checking a checkbox can
only ever remove an animal from the result set:
The magic of the :has pseudo-class is that it doesn’t change the scope, which means that after checking whether “AND” or “OR” is checked within the #filters,
the #animals container is still an adjacent element.
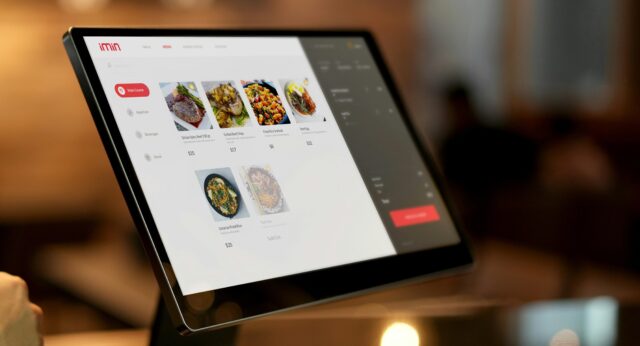
Next time you’re implementing a filter interface, like this restaurant menu, perhaps ask whether you actually need JavaScript.
Then all we need to do is to use daisy-chain :has to show animals with a particular class if that class is checked in “OR” mode, or to hide animals that don’t have a
particular class in “AND” mode. Here’s what that looks like:
It could probably enjoy an animation effect to make it clearer when items are added and removed2, but that’s a consideration
for another day.
Many developers would be tempted to use JavaScript to implement the client-side version of a filter like this. And in some cases, that might be the right option.
But it’s always worth remembering that:
A CSS solution is almost-always more-performant than a JS one.
A JS solution is usually less-resilient than a CSS one: a CDN failure, unsupported API, troublesome content-blocker or syntax error will typically have a much larger
impact on JavaScript.
For the absolutely maximum compatibility, consider what you can do in plain HTML, or on the server-side, and treat anything on the client-side as progressive
enhancement.
Footnotes
1 The thing I was actually working on when I got distracted was an OAuth provider
implementation for Three Rings, connected with work that took place at this weekend’s hackathon to
(eventually) bring single-sign-on “across” Three Rings CIC’s products. Eventually being the operative word.
2 Such an animation should, of course, be wrapped in a @media
(prefers-reduced-motion: no-preference) media query!
Never underestimate the power of people who are motivated by the good they can do in the world.
Today I was in awe of this team of unpaid volunteers who, having already given up their bank holiday weekend, worked through dinner and into the night to ensure the continued uptime of
a piece software that enables the listening service of emotional support and suicide helplines.
I’m spending the weekend volunteering for a nonprofit I founded (it’s almost as old as geocaching, at 23). We’re staying in a hotel at N 52°
36.184′ W 001° 53.869′. I’ve also gotten out to find a couple of localgeocaches.
But guess which room number the hotel have given me…
Found following a short hunt and a brief rummage after walking up the nearby footpath, with the help of a previous log which talked about crossing a fence (which I didn’t need to do, having come up
the correct way in the first place).
Some fellow volunteers and I are meeting at a hotel to the West of here for a weekend of making
software to help charities. When we meet up, I have a tradition of getting up early and finding a geocache or two before breakfast. Having exhausted the very-local supply of caches
on previous visits, and not wishing to miss out on the tradition on this, geocaching’s 25th birthday, I decided it was time to come further afield (and to finally solve this puzzle!…
I’m still stumped by its sibling, though!).
Nice container. Log slightly damp, but still usable. TFTC, and FP awarded for the enjoyable (once I spotted a pattern!) puzzle.
Woke early, as usual, for the first day of a weekend of volunteering, while staying at nearby Fairlawns. I’ve already tapped out the most-local caches to that hotel on previous stays, so for this morning’s walk I came further afield to find
this (and one of the two puzzle caches not too far away; that’s next, hopefully!)
This nice (topical!) container was an easy find once I poked my head into the right place. TFTC!
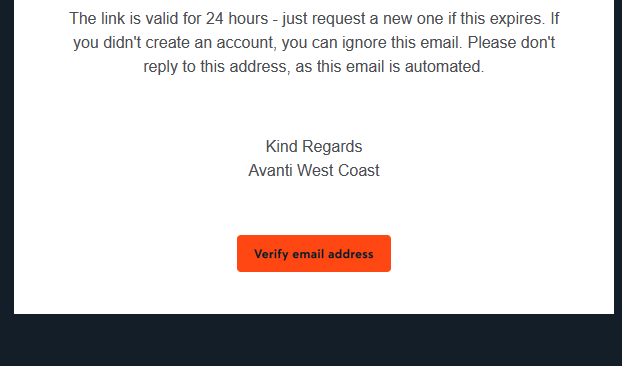
Clearly that certificate only applies to their website, though, and not to e.g. their emails. When you sign up an account with them, you need to verify your email address. They send you
a (HTML-only) email with a link to click. Here’s what that link looks like to a sighted person:
So far, so good. But here’s the HTML code they’re using to create that button. Maybe you’ll spot
the problem:
Despite specifying the font to use three times, they don’t actually have any alt text. So for somebody who can’t see that image, the link is
completely unusable1.
This made me angry enough that I gave up on my transaction and bought my train tickets from LNER instead.
Accessibility matters. And that includes emails. Do better, Avanti.
Footnotes
1 Incidentally, this also makes the email unusable for privacy-conscious people who, like
me, don’t routinely load remote images in emails. But that’s a secondary concern, really.







 Alpaca
Alpaca
 Anteater
Anteater
 Bat
Bat
 Beetle
Beetle
 Butterfly
Butterfly
 Camel
Camel
 Cat
Cat
 Chameleon
Chameleon
 Cobra
Cobra
 Cow
Cow
 Crab
Crab
 Crocodile
Crocodile
 Dog
Dog
 Duck
Duck
 Elephant
Elephant
 Elk
Elk
 Fish
Fish
 Frog
Frog
 Giraffe
Giraffe
 Hippo
Hippo
 Husky
Husky
 Kangaroo
Kangaroo
 Lion
Lion
 Macaw
Macaw
 Manatee
Manatee
 Monkey
Monkey
 Mouse
Mouse
 Octopus
Octopus
 Ostrich
Ostrich
 Owl
Owl
 Panda
Panda
 Pelican
Pelican
 Penguin
Penguin
 Pig
Pig
 Rabbit
Rabbit
 Raccoon
Raccoon
 Ray
Ray
 Rhino
Rhino
 Rooster
Rooster
 Shark
Shark
 Sheep
Sheep
 Sloth
Sloth
 Snake
Snake
 Spider
Spider
 Squirrel
Squirrel
 Swan
Swan
 Tiger
Tiger
 Toucan
Toucan
 Turtle
Turtle
 Whale
Whale