The problem of “needing to be able to hear from two Bluetooth sources at once” is so real for me that I came up with a solution that I genuinely use all the time. You’re not going to
like it, though.
Solution in video (no audio needed; no need to fix your headphones first!):
Known Leaders is an open-source
program that combines WikiData with a random generator to come up with almost-invariably inaccurate but sometimes hilarious facts. Jim Kang came up with it during Recurse Center‘s Never Graduate Week. Go have a play, or read more about how and why he made it.
When geocachers find a geocache, they typically “log” their find both in the cache’s paper logbook and on one of the online listing sites on which the cache’s coordinates can be
found.1
A typical geocacher can find their cache container, logbook, swag, toothbrush, face flannel, soap, tin of biscuits, flask, compass, and most-importantly towel. Hang on, I’ve got my
geekeries crossed again. Photo courtesy cachemania, used under a CC BY-SA license.
I’ve been finding and hiding geocaches for… a long while, so I’ve
seen lots of log entries from people who’ve found my caches (and those of others). And it feels to me like the average length of a
geocaching log entry is getting shorter.
A single emoji is probably the shortest log entry I’ve ever seen. I’m
not claiming that its
cachedeserves a longer log (it’s far from my best work!): just using it as an example of a wider trend towards shorter logs.
“It feels to me like…” isn’t very scientific, though. Let’s see if we can do better.
Getting the data
To test my hypothesis, I needed a decade or so of logs. I didn’t want to compare old caches to new caches (in case people are biased by the logs before them) so I used Geocaching.com’s
own search to open the pages for the 500 caches closest to me that are each at least 10 years old.
My browser hates me right now.
I hacked together a quick
userscript to save all of the logs in a way that was easier than copy-pasting each of them but still didn’t involve hitting Geocaching.com’s API or automating bulk-scraping (which would violate their terms of service). Clicking each of several hundred tabs once every few minutes in
the background while I got on with other things wasn’t as much of an ordeal as you might think… but it did take a while.
Needless to say I only had to go through the cycle a couple of times before I set up a keyboard shortcut.
I mashed that together into a CSV file and for the first time looked at the size of my sample data: ~134,000 log entries,
spanning 20 years. I filtered out everything over 10 years old (because some of the caches might have no logs that old) and stripped out everything that wasn’t a “found it” or “didn’t
find it” log.
That gave me a far more-reasonable ~80,000 records with which I could make Excel cry.2
Results
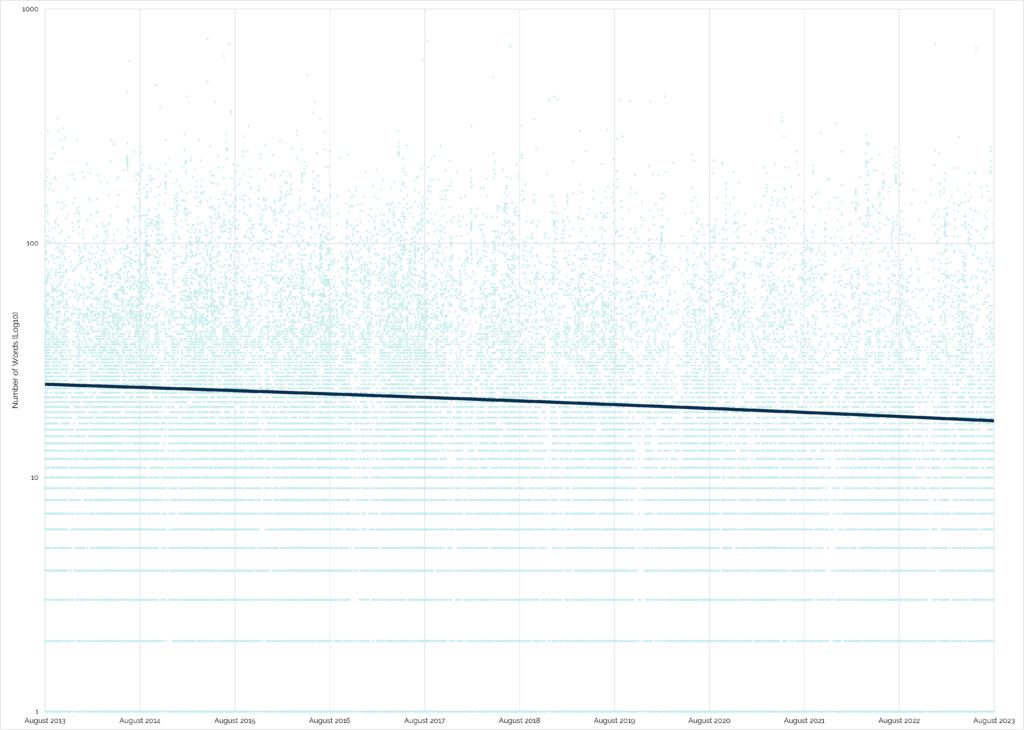
It looks like my hunch is right. The wordcount of “found” logs on traditional and multi-stage caches has generally decreased over time:
“Found” logs are great for cache owner morale: a simple “TFTC” is a lot less-inspiring that hearing about your adventure to get
to that point.
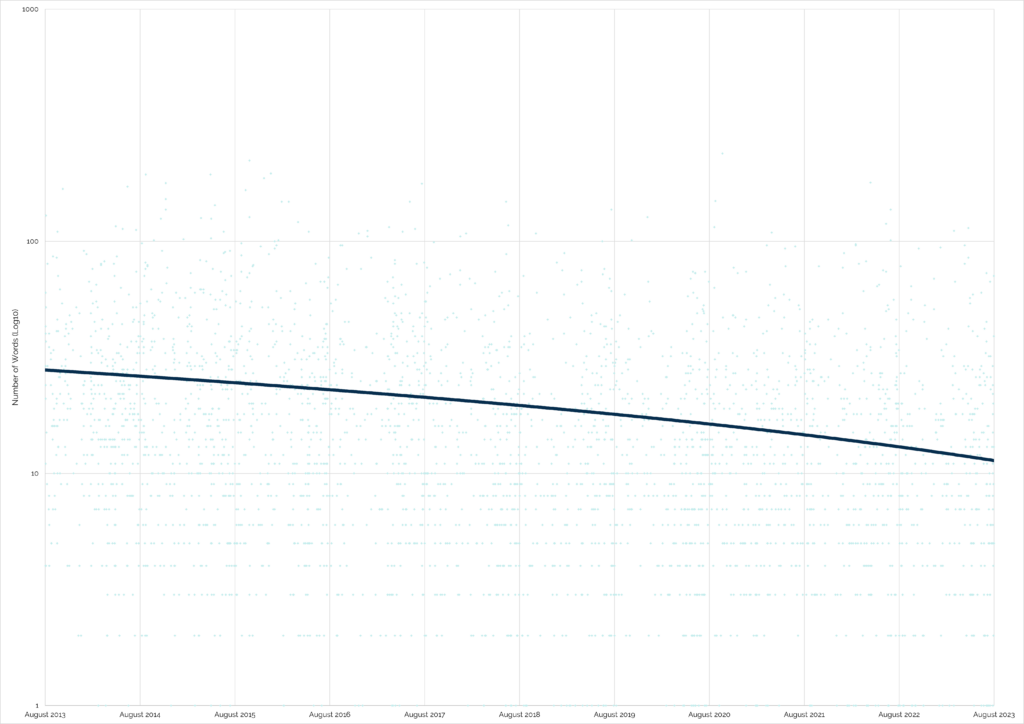
“Did not find” logs, which can be really helpful for cache owners to diagnose problems with their caches, have an even more-pronounced dip:
Geocachers are just typing “Didn’t find it” and moving on. Without an indication of the conditions at the GZ, how long they spent
looking, or an indication of whether the hint was followed, that doesn’t give a cache owner much to work with.
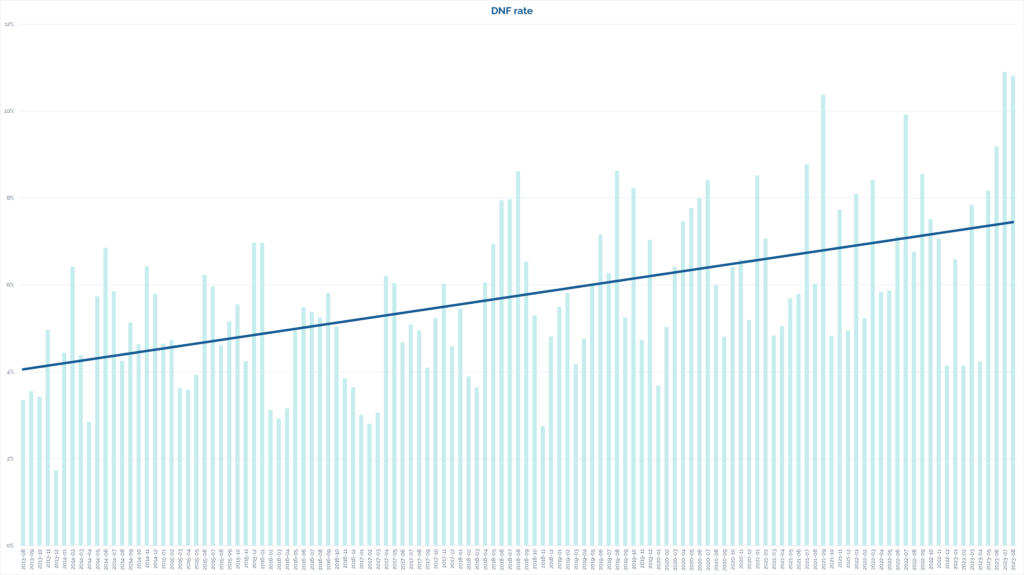
When I first saw that deep dip on the average length of “did not find” logs, my first thought was to wonder whether the sample might not be representative because the did-not-find rate
itself might have fallen over time. But no: the opposite is true:
A higher proportion than ever of geocachers are logging that they couldn’t find the cache, but they’re simultaneously saying less than ever about it.
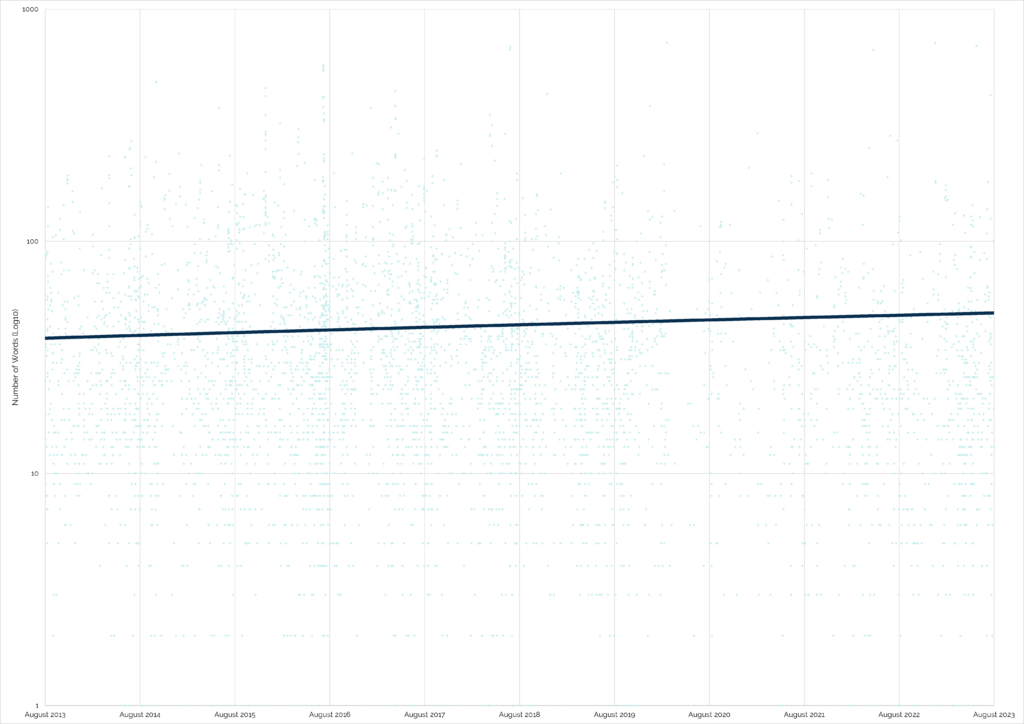
Strangely, the only place that the trend is reversed is in “found” logs of virtual caches, which have seen a slight increase in verbosity.
I initially assumed that this resulted from “virtual
rewards” from 2017 onwards3
but this doesn’t make any sense because all of the caches in my study are 10+ years old: none of them can be “virtual rewards”.
Conclusion
Within the limitations of my research (80,000 logs from 500 caches each 10+ years old, near me), there are a handful of clear trends over the last decade:
Geocachers are leaving increasingly concise logs when they find geocaches.
That phenomenon is even more-pronounced when they don’t find them.
And they’re failing-to-find caches and giving up with significantly greater frequency.
Are these trends a sign of shortening attention spans? Increased use of mobile phones for logging? Use of emoji and acronyms to pack more detail into shorter messages? I don’t know.
I’d love to see some wider research, perhaps by somebody at Geocaching.com HQ (who has database access and is thus able to easily extract
enough data for a wider analysis!). I’m also very interested in whether the identity of the cache finder has an impact on log length: is it impacted by how long ago they
started ‘caching? Whether or not they have hidden caches of their own? How many caches they’ve found?
But personally, I’m just pleased to have been able to have a question in the back of my mind and – through a little bit of code and a little bit of data-mashing – have a pretty good go
at answering it.
Footnotes
1 I have a dream that someday cache logging could be powered by Webmentions or ActivityPub or some similar decentralised-Web technology, so that cachers can log their finds on any site on which a cache is listed or
even on their own site and have all the dots joined-up… but that’s pretty far-fetched I’m afraid. It’s not stopping some of us from experimenting with possible future standards,
though…
2 Just for fun, try asking Excel to extrapolate a second-order polynomial trendline across
80,000 pairs of datapoints. Just don’t do it if you’re hoping to use your computer for anything in the next quarter hour.
3 With stricter guidelines on how a “virtual rewards” virtual caches should work than
existed for original pre-2005 virtuals, these new virtuals are more-likely than their predecessor to encourage or require longer logs.
<link rel="alternate" type="application/rss+xml"> is fine, but I feel like there should be a standard for a site, not a page, to share a “list of
feeds associated with a site”.
Last night, I dreamed about a way to achieve that: ./well-known/feeds as an OPML document. Here’s mine, and here’s a draft spec.
Enjoyed solving this puzzle, although possibly not 100% in the way the author intended (I spotted some mathematical quirks that gave me a shortcut/cut down the number of possibilities
for matching first and surnames!). Now I just need to find an excuse to get over to the GZ and find it! (No idea how soon that’ll be,
though!)
No luck here this morning for the geopup and I. The undergrowth has come through incredibly thick your summer, and we had to work hard to hunt in likely locations. (The hint didn’t help
much, as it wasn’t entirely clear which direction it assumed we were coming from, but the GPSr good looked good so I figure we were on the
right spot.) Strangely, we did find a bauble (pictured) – did somebody decorate these woods for Christmas, I wonder?
Easy find while out on a dog walk. Not been out this side of the wood before! Might have struggled to find the GZ were it not for the
remnants of a “geo trail” through the dense undergrowth, which was thick enough that the pooch’s little legs couldn’t take her the last 5 metres and I had to press on alone. Soon,
though, the cache was in hand and I was able to return to my four-legged furry friend and continue on our way. TFTC!
I find myself in Cropredy but once a year, at most, and for the obvious reason. The festival atmosphere, not to mention the hordes of revellers, does not in general bode well for a
successful geocaching expedition! But I’ve persisted, mostly by virtue of being an early riser than most of the partygoers and inclined towards a swift morning constitutional (as mentioned here), and I’ve gradually picked off each of the local caches bar this one and a multi that’s somewhat incompatible with the festival.
This time last year I came very near to this GZ while hunting for GC9GK2V “Mr
Impossible”, but it was coming close to the time I anticipated that the kids would wake up and demand breakfast, so I turned around before reaching “Leslie”. This year I’ve pressed
directly on to this cache, thankful for the cool damp air through which my brisk walk took me compared to last year’s saunalike heat.
As others have noted, the cache container has seen better days but it’s still just about holding together (insert your own joke about aging folk rockers here). Regardless, a delightful
morning walk before a day of music. SL, TFTC.
I managed to log most of the local geocaches during last year’s Fairport by getting up early each morning (1, 2, 3, 4, 5, 6, 7),
while the other revellers were still nursing their hangovers, but I wasn’t able to retrieve this muddle-laden one. This year I had better luck and the kids, dog and I soon had it in
hand. SL, TNLN, TFTC!
In his latest Last Month video, TomSka took the “is a hot dog a sandwich” argument into a whole new arena by saying:
I’m a firm believer that the sauce and toppings should go under the dog. And that way, I don’t have to put it all in my moustache when I eat it.
My initial reaction was: What the hell are you doing‽ They’re toppings, not… bottomings, I guess?
But on the other hand:
Previews of other movies you might like to see are still called trailers, even though nowadays they’re normally shown before the film.
This actually looks like it might be good for preventing onions falling off, which is my biggest problem when I eat hot dogs (I don’t mind moustache toppings: they’re a treat for
later on).
So yeah, I might try doing this. But if I do, I’m definitely going to start calling them “bottomings”.
The week before last, Katie shared with me that article from last month, Who killed Google Reader? I’d read it before so I
didn’t bother clicking through again, but we did end up chatting about RSS a bit1.
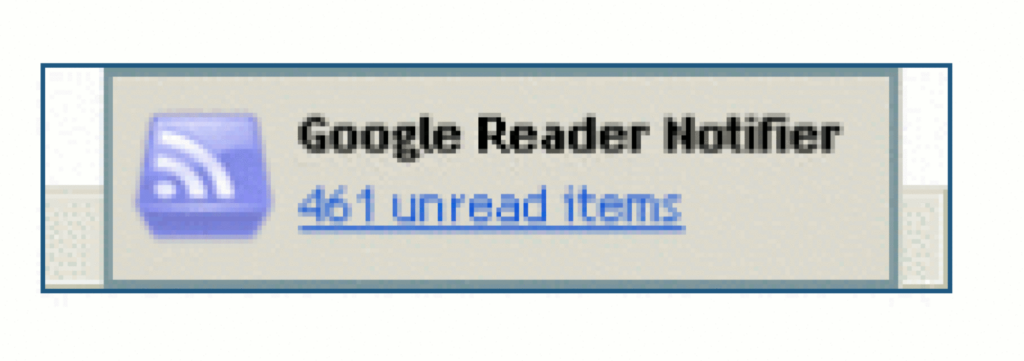
I ditched Google Reader several years before its untimely demise, but I can confirm “461 unread items” was a believable message.
Katie “abandoned feeds a few years ago” because they were “regularly ending up with 200+ unread items that felt overwhelming”.
Conversely: I think that dropping your feed reader because there’s too much to read is… solving the wrong problem.
About half way through editing this image I completely forgot what message I was trying to convey, but I figured I’d keep it anyway and let you come up with your own
interpretation.
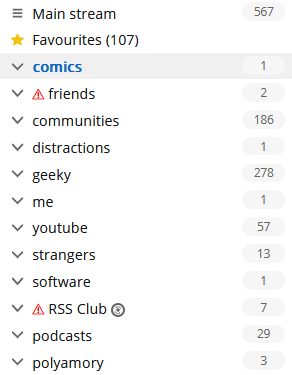
I think that he, like Katie, might be looking at his reader in a different way than I do mine.
At time of writing, I’ve got 567 unread items. And that’s fine.
RSS is not email!
I’ve been in the position that Katie and David describe: of feeling overwhelmed by the sheer volume of unread items. And I know others have, too. So let me share something I’ve learned
sooner:
There’s nothing special about reaching Inbox Zero in your feed reader.
It’s not noble nor enlightened to get to the bottom of your “unread” list.
Your 👏 feed 👏 reader 👏 is 👏 not 👏 an 👏 email 👏 client. 👏
The idea of Inbox Zero as applied to your email inbox is about productivity. Any message in your email might be something that requires urgent action, and you
won’t know until you filter through and categorise .
But your RSS reader doesn’t (shouldn’t?) be there to add to your to-do list. Your RSS reader is a list of things you might like to read. In an ideal world, reaching “RSS Zero” would mean that you’ve seen everything on the Internet that you might
enjoy. That’s not enlightened; that’s sad!
Google Reader understood this, although the word “congratulations” was misplaced.
Use RSS for joy
My RSS reader is a place of joy, never of stress. I’ve tried to boil down the principles that makes it so, and here they are:
Zero is not the target.
The numbers are to inspire about how much there is “out there” for you, not to enumerate how much work need have to do.
Group your feeds by importance.
Your feed reader probably lets you group (folder, tag…) your feeds, so you can easily check-in on what you care about and leave other feeds for a rainy day.2 This is good.
Don’t read every article.
Your feed reader gives you the convenience of keeping content in one place, but you’re not obligated to read every single one. If something doesn’t interest you, mark it
as read and move on. No judgement.
Keep things for later.
Something you want to read, but not now? Find a way to “save for later” to get it out of your main feed so you. Don’t have to scroll past it every day! Star it or tag
it3 or push it to your link-saving or note-taking app. I use a
link shortener which then feeds back into my feed reader into a “for later” group!
Let topical content expire.
Have topical/time-dependent feeds (general news media, some social media etc.)? Have reader “purge” unread articles after a time. I have my subscription to BBC News headlines expire after 5 days: if I’ve taken that long to
read a headline, it might as well disappear.4
Use your feed reader deliberately.
You don’t need popup notifications (a new article’s probably already up to an hour stale by the time it hits your reader). We’re all already slaves to
notifications! Visit your reader when it suits you. I start and end every day in mine; most days I hit it again a couple
of other times. I don’t need a notification: there’s always new content. The reader keeps track of what I’ve not looked at.
It’s not just about text.
Don’t limit your feed reader to just text. Podcasts are nothing more than RSS feeds with
attached audio files; you can keep track in your reader if you like. Most video platforms let you subscribe to a feed of new videos on a channel or playlist basis, so you can e.g.
get notified about YouTube channel updates without having to fight with The
Algorithm. Features like XPath Scraping in FreshRSS let you subscribe to services that
don’t even have feeds: to watch the listings of dogs on local shelter websites when you’re looking to adopt, for example.
Do your reading in your reader.
Your reader respects your preferences: colour scheme, font size, article ordering, etc. It doesn’t nag you with newsletter signup popups, cookie notices, or ads. Make
the most of that. Some RSS feeds try to disincentivise this by providing only summary content, but a good feed reader can
work around this for you, fetching actual content in the background.5
Use offline time to catch up on your reading.
Some of the best readers support offline mode. I find this fantastic when I’m on an aeroplane, because I can catch up on all of the interesting articles I’d not
had time to yet while grounded, and my reading will get synchronised when I touch down and disable flight mode.
Make your reader work foryou.
A feed reader is a tool that works for you. If it’s causing you pain, switch to a different tool6,
or reconfigure the one you’ve got. And if the way you find joy from RSS is different from me, that’s fine: this is
a personal tool, and we don’t have to have the same answer.
2 If your feed reader doesn’t support any kind of grouping, get a better reader.
3 If your feed reader doesn’t support any kind of marking/favouriting/tagging of articles,
get a better reader.
4 If your feed reader doesn’t support customisable expiry times… well that’s not too
unusual, but you might want to consider getting a better reader.
5 FreshRSS calls the feature that fetches actual post content from the resulting page
“Article CSS selector on original website”, which is a bit of a mouthful, but you can see what it’s doing. If your feed reader doesn’t support fetching full content… well, it’s
probably not that big a deal, but it’s a good nice-to-have if you’re shopping around for a reader, in my opinion.
6 There’s so much choice in feed readers, and migrating between them is (usually)
very easy, so everybody can find the best choice for them. Feedly, Inoreader, and The Old Reader are popular, free, and easy-to-use if you’re looking to get started. I prefer a selfhosted tool so I use the amazing FreshRSS (having migrated from Tiny Tiny RSS). Here’s some more tips on getting started. You might prefer a desktop or mobile tool, or even something
exotic: part of the beauty of RSS feeds is they’re open and interoperable, so if for example you love using Slack, you can use Slack to push feed updates to you and get almost all the features you need to do everything in my list,
including grouping (using channels) and saving for later (using Slackbot/”remind me about this”). Slack’s a perfectly acceptable feed reader for some people!
I’ve made a handful of tweaks to my RSS feed which I feel improves upon
WordPress’s default implementation, at least in my use-case.1 In case any of these improvements help
you, too, here’s a list of them:
Post Kinds in Titles
Since 2020, I’ve decorated post titles by prefixing them with the “kind” of post they are (courtesy of the Post Kinds
plugin). I’ve already written about how I do it, if you’re
interested.
Identifying post kinds is particularly useful for people who subscribe by
email (the emails are generated off the RSS feed either daily or weekly: subscriber’s choice), who might want to see
articles and videos but not care about for example checkins and reposts.
RSS Only posts
A minority of my posts are – initially, at least – publicised only via my RSS feed (and places that are directly fed
by it, like email subscribers). I use a tag to identify posts to be hidden in this way. I’ve
written about my implementation before, but I’ve since made a couple of additional improvements:
Suppressing the tag from tag clouds, to make it harder to accidentally discover these posts by tag-surfing,
Tweaking the title of such posts when they appear in feeds (using the same technique as above), so that readers know when they’re seeing “exclusive” content, and
Setting a X-Robots-Tag: noindex, nofollow HTTP header when viewing such tag or a post, to discourage
search engines (code for this not shown below because it’s so very specific to my theme that it’s probably no use to anybody else!).
// 1. Suppress the "rss club" tag from tag clouds/the full tag listfunctionrss_club_suppress_tags_from_display( string $tag_list, string $before, string $sep, string $after, int $post_id ): string {
foreach(['rss-club'] as$tag_to_suppress){
$regex=sprintf( '/<li>[^<]*?<a [^>]*?href="[^"]*?\/%s\/"[^>]*?>.*?<\/a>[^<]*?<\/li>/', $tag_to_suppress );
$tag_list=preg_replace( $regex, '', $tag_list );
}
return$tag_list;
}
add_filter( 'the_tags', 'rss_club_suppress_tags_from_display', 10, 5 );
// 2. In feeds, tweak title if it's an RSS exclusivefunctionrss_club_add_rss_only_to_rss_post_title( $title ){
$post_tag_slugs=array_map(function($tag){ return$tag->slug; }, wp_get_post_tags( get_the_ID() ));
if ( !in_array( 'rss-club', $post_tag_slugs ) ) return$title; // if we don't have an rss-club tag, drop out herereturn trim( "{$title} [RSS Exclusive!]" );
return$title;
}
add_filter( 'the_title_rss', 'rss_club_add_rss_only_to_rss_post_title', 6 );
Adding a stylesheet
Adding a stylesheet to your feeds can make them much friendlier to beginner users (which helps drive adoption) without making them much less-convenient for people who know how
to use feeds already. Darek Kay and Terence Eden both wrote great articles about this just
earlier this year, but I think my implementation goes a step further.
In addition to adding some “Q” branding, I made tweaks to make it work seamlessly with both my RSS and Atom feeds by using
two<xsl:for-each> blocks and exploiting the fact that the two standards don’t overlap in their root namespaces. Here’s my full XSLT; you need to
override your feed template as Terence describes to use it, but mine can be applied to both RSS and Atom.2
I’ve still got more I’d like to do with this, for example to take advantage of the thumbnail images I attach to posts. On which note…
Thumbnail images
When I first started offering email subscription options I used Mailchimp’s RSS-to-email service, which was… okay,
but not great, and I didn’t like the privacy implications that came along with it. Mailchimp support adding thumbnails to your email template from your feed, but WordPress themes don’t
by-default provide the appropriate metadata to allow them to do that. So I installed Jordy Meow‘s RSS Featured Image plugin which did it for me.
<item><title>[Checkin] Geohashing expedition 2023-07-27 51 -1</title><link>https://danq.me/2023/07/27/geohashing-expedition-2023-07-27-51-1/</link>
...
<media:contenturl="https://bcdn.danq.me/_q23u/2023/07/20230727_141710-1024x576.jpg"medium="image"/><media:description>Dan, wearing a grey Three Rings hoodie, carrying French Bulldog Demmy, standing on a path with trees in the background.</media:description></item>
Media attachments for RSS feeds are perhaps most-popular for podcasts, but they’re also great for post thumbnail images.
During my little redesign earlier this year I decided to go two steps further: (1) ditching the
plugin and implementing the functionality directly into my theme (it’s really not very much code!), and (2) adding not only a <media:content medium="image" url="..."
/> element but also a <media:description> providing the default alt-text for that image. I don’t know if any feed readers (correctly) handle this
accessibility-improving feature, but my stylesheet above will, some day!
So there we have it: a little digital gardening, and four improvements to WordPress’s default feeds.
RSS may not be as hip as it once was, but little improvements can help new users find their way into this (enlightened?) way
to consume the Web.
If you’re using RSS to follow my blog, great! If it’s not for you, perhaps pick your favourite alternative way to get updates, from options including email, Telegram, the Fediverse (e.g. Mastodon), and more…
1 The changes apply to the Atom
feed too, for anybody of such an inclination. Just assume that if I say RSS I’m including Atom, okay?
2 The experience of writing this transformation/stylesheet also gave me yet another opportunity to remember how much I hate
working with XSLTs. This time around, in addition to the normal namespace issues and headscratching
syntax, I had to deal with the fact that I initially tried to use a feature from XSLT version 2.0 (a
22-year-old version) only to discover that all major web browsers still only support version 1.0 (specified last millenium)!