For instance, at the start of the weekend I received an email from somebody called Phil, who asked:
Could you possibly have an alternative ‘HQ’ version of your feeds which replaces standard/240 with standard/1200 in the URL for each article in the XML?
I am obviously pretty desperate for this feature, hence me reaching out.
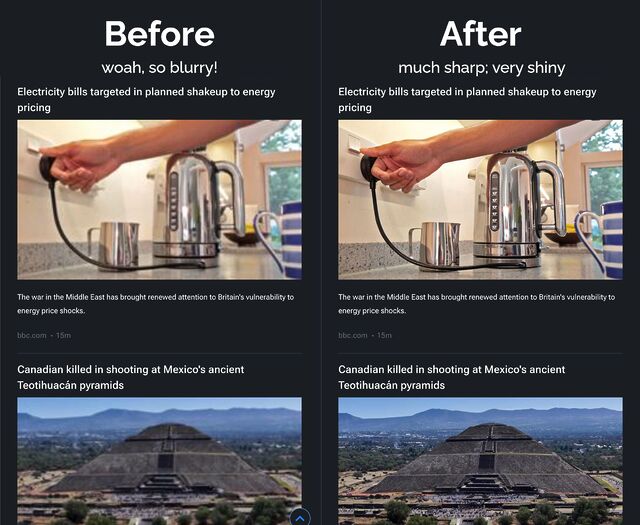
Phil’s right. The BBC News RSS feeds contain thumbnail images that look like this:
You see the /240/ in that URL? If you change it to /1200/ then, as Phil observes, you get a much-higher resolution thumbnail. Naturally you ought
to correct the width and height attributes accordingly, too.
The difference is pretty significant. See:
You’d be forgiven for thinking the left-hand-side of this image was the Lego model of this car.
So I raised Phil’s request as a GitHub issue, like a good maintainer, before realising that – hang on – this would be
a really easy improvement and I should just… do it.
My BBC feeds “improver” leverages one of my very favourite RubyGems, Nokogiri, to perform XML parsing and modification. The code you need to tweak
these URLs is super simple:
# Iterate through each <media:thumbnail> element in the RSS feed:
rss.xpath('//media:thumbnail').eachdo|thumb|# Skip any that don't start the way we expect:nextunlessthumb['url']=~/^https:\/\/ichef.bbci.co.uk\/ace\/(standard|ws)\/240\//# Swap the 240 for 1200 in the url="..." attribute:thumb['url']=thumb['url'].gsub(/\/ace\/(standard|ws)\/240\//,"/ace/\\1/1200/")
# Set width="1200":thumb['width']="1200"# Set the height="..." proportionally (they're not always the same!):thumb['height']=(thumb['height'].to_f/240*1200).round.to_s
end
That really is all there is to it, but look at what a difference it makes in an RSS reader:
I got that merged and the GitHub action that makes the magic happen got started on its usual 20-minute schedule soon afterwards. I didn’t even have to finish waiting for my lunchtime
ramen to cool down before the change was out there and, hopefully, helping people. Phil emailed me again soon afterwards:
You managed to fix something in your lunch break that has been bugging me for well over a decade. The difference in quality is night and day.
Anyway: it pleased me to discover that my software is out there, helping people.
As with most of my open source work, I put little to no effort into tracking any kind of metrics of usage, which means I only get to find out if I’ve done good in the world when people
reach out and tell me. So I was delighted to hear from Phil (as well as to take his suggestion and improve the tool for everybody!).
Footnotes
1 Specifically, the code I’ve written makes a few improvements to the BBC News RSS feeds:
(1) removing duplicate news, (2) removing non-news content such as “nudges” towards the app or to iPlayer content, and (3) optionally removing sports news. If that sounds
like a better version of the BBC News RSS feeds, you should take a look!
Terence Eden, who’s apparently inspiring several posts this week, recently shared a way to attach a hook to WordPress’s
get_the_post_thumbnail() function in order to remove the extraneous “closing mark” from the (self-closing in HTML) <img> element.
By default, WordPress outputs e.g. <img src="..." />, where <img src="..."> would suffice.
It’s an inconsequential difference for most purposes, but apparently it bugs him, so he fixed it… although he went on to observe that he hadn’t managed to successfully tackle
all the instances in which WordPress was outputting redundant closing marks.
This is a problem that I’ve already solved here on my blog. My solution’s slightly hacky… but it works!
There are many things you could say about the HTML produced to make the page you’re reading now. But “it needs fewer />s” isn’t among them.
My Solution: Runing HTMLTidy over WordPress
Tidy is an excellent tool for tiding up HTML! I used to use its predecessor back in
the day for all kind of things, but it languished for a few years and struggled with support for modern HTML features. But
in 2015 it made a comeback and it’s gone from strength to strength ever since.
I run it on virtually all pages produced by DanQ.me (go on, click “View Source” and see for yourself!), to:
Standardise the style of the HTML code and make it easier for humans to read1.
Bring old-style emphasis tags like <i>, in my older posts, into a more-modern interpretation, like <em>.
Hoist any inline <style> blocks to the <head>, and detect any repeated inline style="..."s to convert to classes.
Repair any invalid HTML (browsers do this for you, of course, but doing it server-side makes parsing easier for the
browser, which might matter on more-lightweight hardware).
WordPress isn’t really designed to have Tidy bolted onto it, so anything it likely to be a bit of a hack, but here’s my approach:
Install libtidy-dev and build the PHP bindings to it.
Note that if you don’t do this the code might appear to work, but it won’t actually tidy anything2.
Add a new output buffer to my theme’s header.php3, with a callback function: ob_start('tidy_entire_page').
Without an corresponding ob_flush or similar, this buffer will close and the function will be called when PHP
finishes generating the page.
Define the function tidy_entire_page($buffer) Have it instantiate Tidy ($tidy = new tidy) and use $tidy->parseString (with your buffer and Tidy preferences) to tidy the code, then
return $tidy.
Ensure that you’re caching the results!
You don’t want to run this every page load for anonymous users! WP Super Cache on “Expert” mode (with the
requisite webserver configuration) might help.
1 I miss the days when most websites were handwritten and View Source typically looked
nice. It was great to learn from, too, especially in an age before we had DOM debuggers. Today: I can’t justify
dropping my use of a CMS, but I can make my code readable.
2 For a few of its extensions, some PHP developer made the interesting choice to fail silently if the required extension is missing. For example: if you don’t have the
zip extension enabled you can still usePHPto make ZIP files, but they won’t be
compressed. This can cause a great deal of confusion for developers! A similar issue exists with tidy: if it isn’t installed, you can still call all of the
methods on it… they just don’t do anything. I can see why this decision might have been made – to make the language as portable as possible in production – but I’d
prefer if this were an optional feature, e.g. you had to set try_to_make_do_if_you_are_missing_an_extension=yes in your php.ini to enable it, or if
it at least logged that it had done so.
3 My approach probably isn’t suitable for FSE (“block”) themes, sorry.
Dave Winer kindly let me know about a proposed
standard for linking to OPML blogrolls. Given that I added a page
containing my blogroll last year, it was easy enough for me to add a tiny bit of code to the header to add support for automatic detection of my blogroll.
Now all we need is some tools that can do such detection!
(You’ll note I’ve added a title attribute: as I discovered the other day, some browsers including ELinks will show all
<link>s of unknown rel="..." at the top of the page and I wanted this one to make sense!)
Wait, there’s new Far Side content? Yup: it turns out Gary Larson’s dusted off his pen
and started drawing again. That’s awesome! But the last thing I want is to have to go to the website once every few… what: days? weeks? months? He’s not syndicated any more so
he’s not got a deadline to work to! If only there were some way to have my feed reader, y’know, do it for me and let me know whenever he draws something new.
It turns out, there is.
Here’s my setup for getting Larson’s new funnies right where I want them:
Feed URL:https://www.thefarside.com/new-stuff/1
This isn’t a valid address for any of the new stuff, but always seems to redirect to somewhere that is, so that’s nice.
XPath for finding news items://div[@class="swiper-slide"]
Turns out all the “recent” new stuff gets loaded in the HTML and then JavaScript turns it into a slider etc.; some of the
CSS classes change when the JavaScript runs so I needed to View Source rather than use my browser’s inspector to find
everything.
Item title:concat("Far Side #", descendant::button[@aria-label="Share"]/@data-shareable-item)
Ugh. The easiest place I could find a “clean” comic ID number was in a data- attribute of the “share” button, where it’s presumably used for engagement tracking. Still,
whatever works right?
Item content:descendant::figcaption
When Larson captions a comic, the caption is important.
Item link (URL) and item unique ID: concat("https://www.thefarside.com",
./@data-path)
The URLs work as direct links to the content, and because they’re unique, they make a reasonable unique ID too (so long as
their numbering scheme is internally-consistent, this should stop a re-run of new content popping up in your feed reader if the same comic comes around again).
Item thumbnail:concat("https://fox.q-t-a.uk/referer-faker.php?pw=YOUR-SECRET-PASSWORD-GOES-HERE&referer=https://www.thefarside.com/&url=",
descendant::img[@data-src]/@data-src)
The Far Side uses Referer: headers as an anti-hotlinking measure, which prevents us easily loading the images directly in an RSS reader. I use this tiny PHP script as a proxy to
mitigate that. If you don’t have such a proxy set up, you could simply omit the “Item thumbnail” and “Item content” fields and click the link to go to the original page.
Item date:normalize-space(descendant::div[@class="tfs-comic-new__meta"]/*[1])
The date is spread through two separate text nodes, so we get the content of their wrapper and use normalize-space to tidy the whitespace up. The date format then looks
like “Wednesday, March 29, 2023”, which we can parse using a custom date/time format string:
Custom date/time format:l, F j, Y
I promise I’ll stop writing about how awesome FreshRSS + XPath is someday. Today isn’t that day.
Meanwhile: if you used to use a feed reader but gave up when the Web started to become hostile to them and big social media systems started to wall you in, you should really consider
picking one up again. The stuff I write about is complex edge-cases that most folks don’t need to think about in order to benefit from RSS… but it’s super convenient to have the things you care about online (news, blogs, social media, videos, newsletters, comics, search trends…)
collated and sorted for you… without interference from algorithms that want to push “sticky” content, without invasive tracking or advertisements (or cookie banners or privacy popups),
without something “disappearing” simply because you put off reading it for a few days.
The goal: date-ordered, numbered, titled episodes of Forward in my feed reader.
Here’s the settings I came up with –
Feed URL:http://forwardcomic.com/list.php
Type of feed source:HTML + XPath (Web scraping)
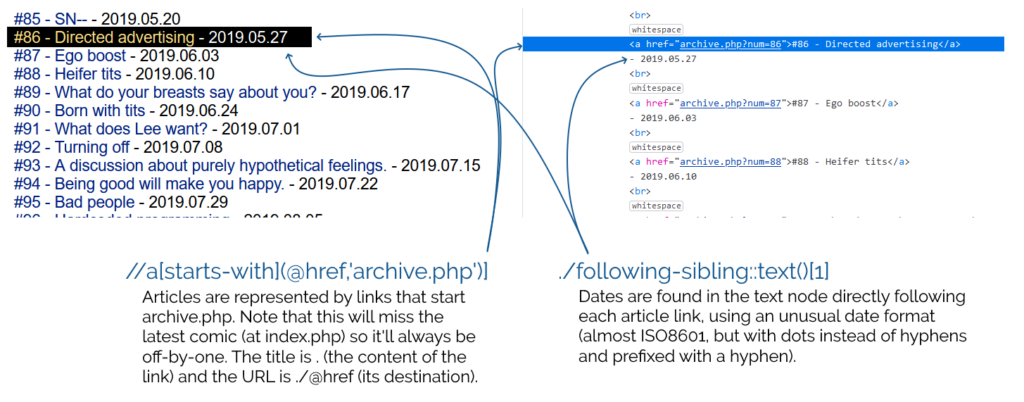
XPath for finding news items://a[starts-with(@href,'archive.php')]
Item title:.
Item link (URL):./@href
Item date:./following-sibling::text()[1]
Custom date/time format:- Y.m.d
The comic pages themselves do a great thing for accessibility by including a complete transcript of each. But the listing page, which is basically a series of <a>s
separated by <br>s rather than a <ul> and <li>s, for example, leaves something to be desired (and makes it harder to scrape,
too!).
I continue to love this “killer feature” of FreshRSS, but I’m beginning to see how it could go further – I wish I had the free time to contribute to its development!
I’d love to see a mechanism for exporting/importing feed configurations like this so that I could share them more-easily, for example. I’d also be delighted if I could expand on my
XPath rules to load pages referenced by the results and get data from them, too, e.g. so I could use an image found by XPath on the “item link” page as the thumbnail
image! These are things RSSey could do for me, but FreshRSS can’t… yet!
A few yeras ago, I wanted to subscribe to The Far Side‘s “Daily Dose” via my RSS reader. The Far Side doesn’t have an RSS feed, so I implemented a proxy/middleware to bridge the two.
If you’re looking for a more-general instruction on using XPath scraping in FreshRSS, this isn’t it.
The release of version 1.20.0 of my favourite RSS reader FreshRSS provided a new mechanism for subscribing to content from sites that didn’t provide feeds: XPath scraping. I demonstrated the use of this to subscribe to my friend Beverley‘s blog, but this week I figured it was time to have a go at retiring my middleware and subscribing directly to The Far Side from FreshRSS.
It turns out that FreshRSS’s XPath Scraping is almost enough to achieve exactly what I want. The big problem is that the image server on The Far Side website tries to
prevent hotlinking by checking the Referer: header on requests, so we need a proxy to spoof that. I threw together a quick PHP program to act as a proxy (if
you don’t have this, you’ll have to click-through to read each comic), then configured my FreshRSS feed as follows:
Feed URL:https://www.thefarside.com/
The “Daily Dose” gets published to The Far Side‘s homepage each day.
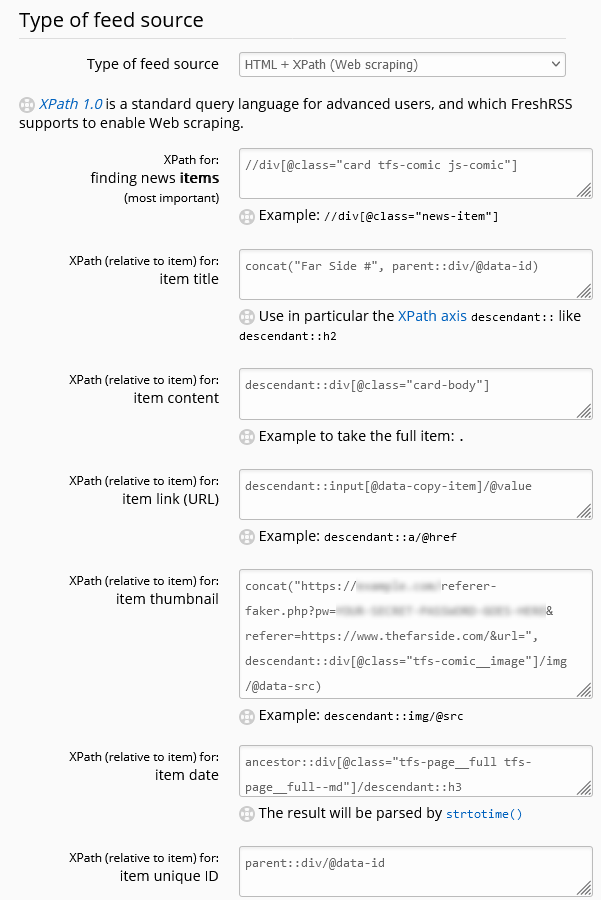
XPath for finding new items://div[@class="card tfs-comic js-comic"]
Finds each comic on the page. This is probably a little over-specific and brittle; I should probably switch to using the contains function at some point. I
subsequently have to use parent:: and ancestor:: selectors which is usually a sign that your screen-scraping is suboptimal, but in this case it’s necessary
because it’s only at this deep level that we start seeing really specific classes.
Item title:concat("Far Side #", parent::div/@data-id)
The comics don’t have titles (“The one with the cow”?), but these seem to have unique IDs in the data-id attribute of the parent <div>, so I’m using
those as a reference.
Item content:descendant::div[@class="card-body"]
Within each item, the <div class="card-body"> contains the comic and its text. The comic itself can’t be loaded this way for two reasons: (1) the <img
src="..."> just points to a placeholder (the site uses JavaScript-powered lazy-loading, ugh – the actual source is in the data-src attribute), and (2) as
mentioned above, there’s anti-hotlink protection we need to work around.
Item link:descendant::input[@data-copy-item]/@value
Each comic does have a unique link which you can access by clicking the “share” button under it. This makes a hidden text <input> appear, which we can
identify by the presence of the data-copy-item attribute. The contents of this textbox is the sharing URL for
the comic.
Item thumbnail:concat("https://example.com/referer-faker.php?pw=YOUR-SECRET-PASSWORD-GOES-HERE&referer=https://www.thefarside.com/&url=",
descendant::div[@class="tfs-comic__image"]/img/@data-src)
Here’s where I hook into my special proxy server, which spoofs the Referer: header to work around the anti-hotlinking code. If you wanted you might be able to come up
with an alternative solution using a custom JavaScript loaded into your FreshRSS instance (there’s a plugin for that!), perhaps to load an iframe of the sharing URL? Or you can
host a copy of my proxy server yourself (you can’t use mine, it’s got a password and that password isn’tYOUR-SECRET-PASSWORD-GOES-HERE!)
Item date:ancestor::div[@class="tfs-page__full tfs-page__full--md"]/descendant::h3
There’s nothing associating each comic with the date it appeared in the Daily Dose, so we have to ascend up to the top level of the page to find the date from the heading.
Item unique ID:parent::div/@data-id
Giving FreshRSS a unique ID can help it stop showing duplicates. We use the unique ID we discovered earlier; this way, if the Daily Dose does a re-run of something it already did
since I subscribed, I won’t be shown it again. Omit this if you want to see reruns.
Hurrah; once again I can laugh at repeats of Gary Larson’s best work alongside my other morning feeds.
There’s a moral to this story: when you make your website deliberately hard to consume, fewer people will access it in the way you want!The Far Side‘s website
is actively hostile to users (JavaScript lazy-loading, anti-right click scripts, hotlink protection, incorrect MIME types, no feeds etc.), and an inevitable consequence of that is that people like me will find and share workarounds to that
hostility.
If you’re ad-supported or collect webstats and want to keep traffic “on your site” on this side of 2004, you should make it as easy as possible for people to subscribe to content.
Consider The Oatmeal or Oglaf, for example, which offer RSS feeds that include only a partial thumbnail of each comic and a link through to the full thing. I don’t feel the need to screen-scrape those sites
because they’ve given me a subscription option that works, and I routinely click-through to both of them to enjoy their latest content!
Conversely, the Far Side‘s aggressive anti-subscription technology ultimately means that there are fewer actual visitors to their website… because folks like me work
to circumvent them.
And now you know how I did so.
Update: want the new content that’s being published to The Far Side in FreshRSS, too? I’ve got a recipe for that!
Just when I thought I’d seen every conceivable XML data format with an approved MIME type (!) I discover @mamund‘s Maze+XML, a format for describing orthoganally-connected squares of a maze.
My day usually starts in my feed reader, accessed via the FeedMe app from my mobile (although FreshRSS provides a reasonably good
responsive interface out-of-the-box!)
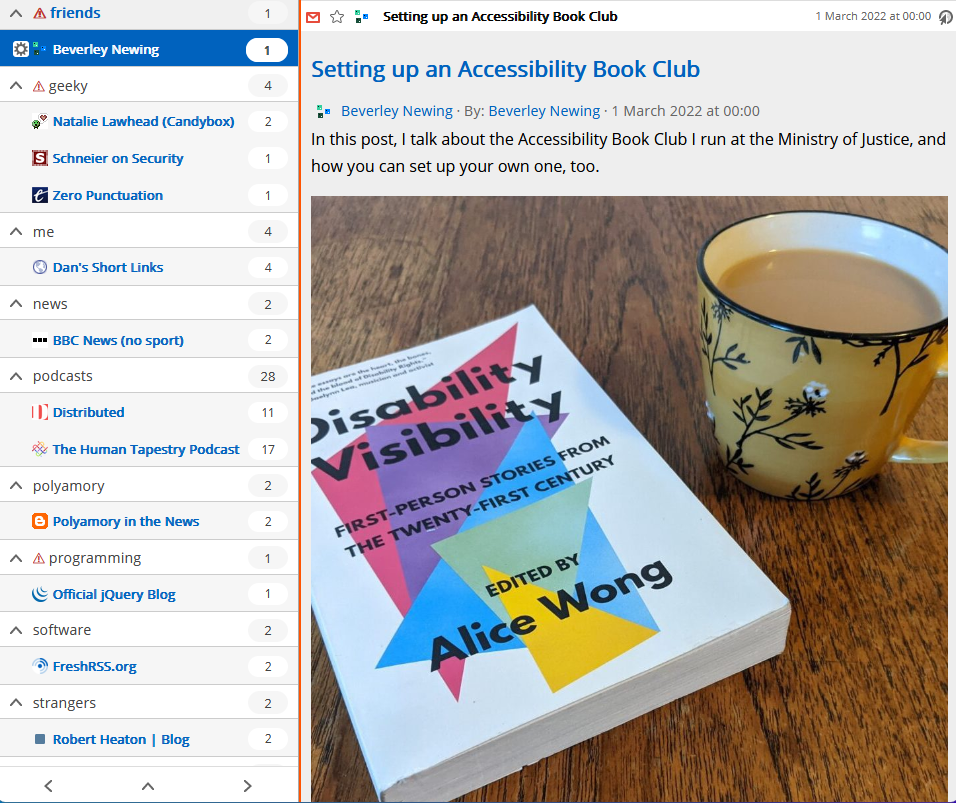
But with FreshRSS 1.20.0, I no longer have to maintain my own tool to get this brilliant functionality, and I’m overjoyed. Let’s look at how it works by re-subscribing to Beverley’s
blog but without a middleware tool.
This post is about to get pretty technical. If you don’t want to learn some XPath but just want to make a feed out of a web page, use a
graphical tool like FetchRSS.
In the latest version of FreshRSS, when you add a new feed to your reader, a new section “Type of feed source” is available. Unfold it, and you can change from the default
(“RSS / Atom”) to the new option “HTML + XPath (Web scraping)”.
Put a human-readable page address rather than a feed address into the “Feed URL” field and fill these fields to tell FreshRSS
how to parse the page to get the content you want. Note that it doesn’t matter if the web page isn’t valid XML (e.g. missing
closing tags) because it’s going to get run through PHP’s
DOMDocument anyway which will “correct” for some really sloppy code if needed.
You can use your browser’s debugger to help check your XPath rules: here I’ve run document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() and
got back the first blog post on the page, so I know I’m on the right track.
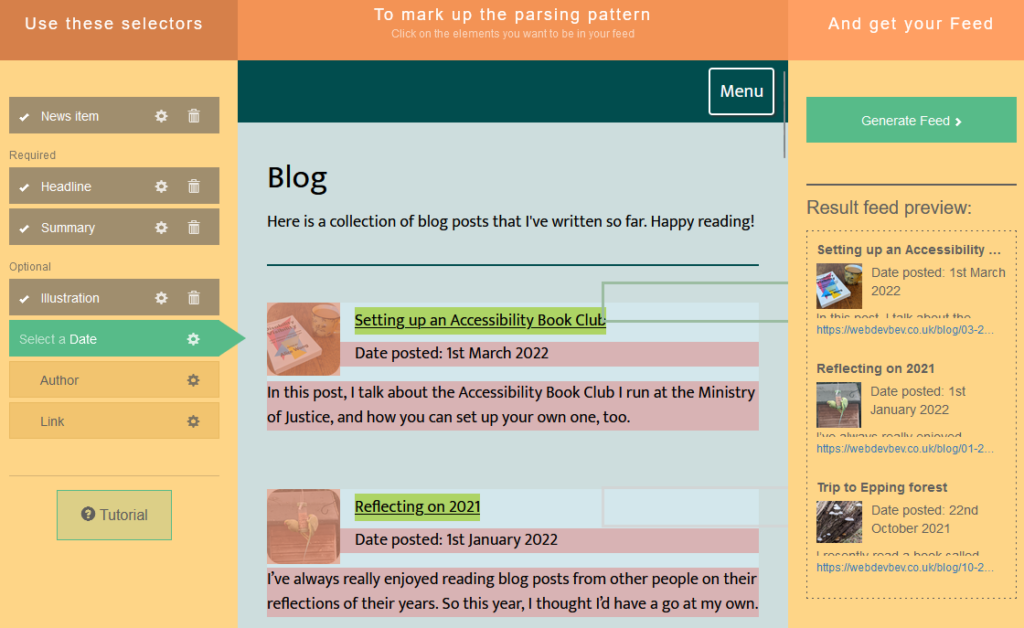
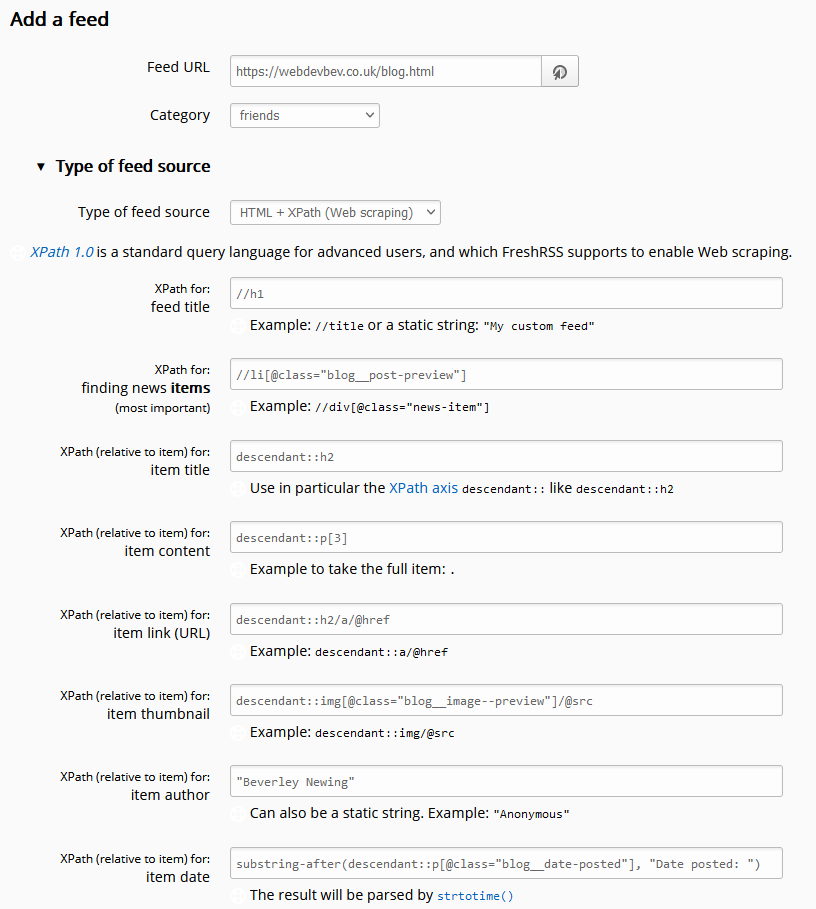
You’ll need to use XPath to express how to find a “feed item” on the page. Here’s the rules I used for https://webdevbev.co.uk/blog.html (many of these fields were optional – I didn’t have to do this much work):
Feed title://h1
I override this anyway in FreshRSS, so I could just have used the a string, but I wanted the XPath practice. There’s only one <h1> on the page, and it can be
considered the “title” of the feed.
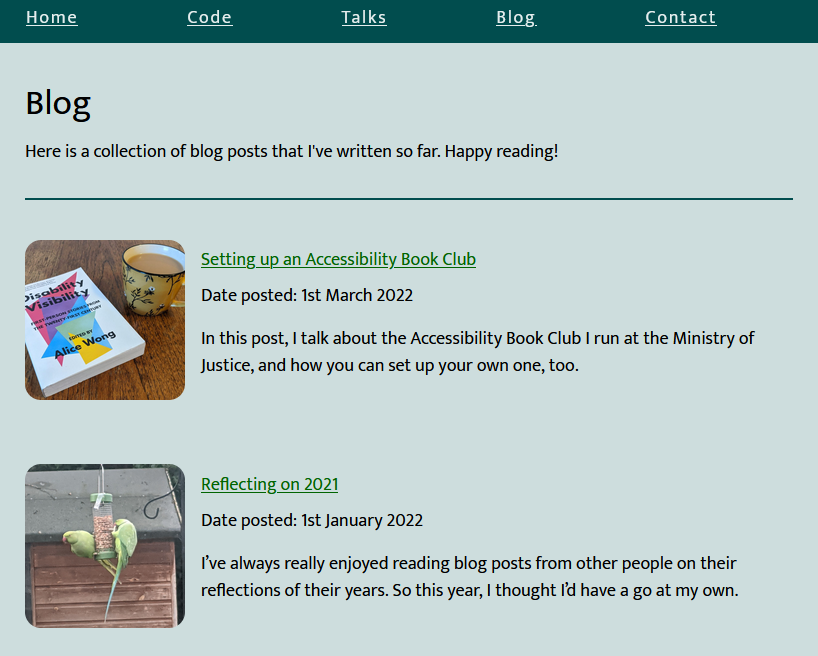
Finding items://li[@class="blog__post-preview"]
Each “post” on the page is an <li class="blog__post-preview">.
Item titles:descendant::h2
Each post has a <h2> which is the post title. The descendant:: selector scopes the search to each post as found above.
Item content:descendant::p[3]
Beverley’s static site generator template puts the post summary in the third paragraph of the <li>, which we can select like this.
Item link:descendant::h2/a/@href
This expects a URL, so we need the /@href to make sure we get the value of the <h2><a
href="...">, rather than its contents.
Item thumbnail:descendant::img[@class="blog__image--preview"]/@src
Again, this expects a URL, which we get from the <img src="...">.
Item author:"Beverley Newing"
Beverley’s blog doesn’t host any guest posts, so I just use a string literal here.
Item date:substring-after(descendant::p[@class="blog__date-posted"], "Date posted: ")
This is the only complicated one: the published dates on Beverley’s blog aren’t explicitly marked-up, but part of a string that begins with the words “Date posted: “, so I use XPath’s
substring-after function to strtip this. The result gets passed to PHP’s
strtotime(), which is pretty tolerant of different date formats (although not of the words “Date posted:” it turns out!).
I’d love one day for FreshRSS to provide some kind of “preview” feature here so you can see what you’ll expect to get back, as you work. That, and support for different input types
(JSON, perhaps?), perhaps other selectors (I find CSS-style
selectors much simpler than XPath), and maybe even an option to execute Javascript on the page before scraping (I use this in my own toolchain, but that’s just because I want to have
my cake and eat it too). But this is still all pretty awesome.
I hope that this is just the beginning for this new killer feature in FreshRSS: there’s so much more it can be and do. But for now, I’m still mighty impressed that I can begin to
phase-out my use of my relatively resource-intensive feed-building middleware and use my feed reader to do more and more of the heavy lifting for which I love it so much.
I also love that this functionally adds h-feed support in by the back door. I’d still prefer there to be a “h-feed” option in the “Type of feed source” drop-down, but at least
I can add such support manually, now!
The finished result: Bev’s blog posts appear directly in my feed reader, even though they don’t have a feed, and now without going through the middleware I’d set up for that
purpose.
Footnotes
1 When I say RSS, I mean feed. Most of the feeds I subscribe to are RSS feeds, but some
are Atom feeds, h-feed, etc. But I can’t get over the old-fashioned name, and I don’t care to try.
As you might know if you were paying close attention in Summer 2019, I run a “URL
shortener” for my personal use. You may be familiar with public URL shorteners like TinyURL
and Bit.ly: my personal URL shortener is basically the same thing, except that only
I am able to make short-links with it. Compared to public ones, this means I’ve got a larger corpus of especially-short (e.g. 2/3 letter) codes available for my personal use. It also
means that I’m not dependent on the goodwill of a free siloed service and I can add exactly the features I want to it.
Little wonder then that my link shortener sat so close to me on my ecosystem diagram the other year.
For the last nine years my link shortener has been S.2, a tool I threw together in Ruby. It stores URLs in a
sequentially-numbered database table and then uses the Base62-encoding of the primary key as the “code” part of the short URL. Aside from the fact that when I create a short link it shows me a QR code to I can
easily “push” a page to my phone, it doesn’t really have any “special” features. It replaced S.1, from which it primarily differed by putting the code at the end of the URL rather than as part of the domain name, e.g. s.danq.me/a0 rather than a0.s.danq.me: I made the switch
because S.1 made HTTPS a real pain as well as only supporting Base36 (owing to the case-insensitivity of domain names).
But S.2’s gotten a little long in the tooth and as I’ve gotten busier/lazier, I’ve leant into using or adapting open source tools more-often than writing my own from scratch. So this
week I switched my URL shortener from S.2 to YOURLS.
YOURLs isn’t the prettiest tool in the world, but then it doesn’t have to be: only I ever see the interface pictured above!
One of the things that attracted to me to YOURLS was that it had a ready-to-go Docker image. I’m not the biggest fan of Docker in general,
but I do love the convenience of being able to deploy applications super-quickly to my household NAS. This makes installing and maintaining my personal URL shortener much easier than it
used to be (and it was pretty easy before!).
Another thing I liked about YOURLS is that it, like S.2, uses Base62 encoding. This meant that migrating my links from S.2 into YOURLS could be done with a simple cross-database
INSERT... SELECT statement:
One of S.1/S.2’s features was that it exposed an RSS feed at a secret URL for my reader to ingest. This was great, because it meant I could “push” something to my RSS reader to read or repost to my blog later. YOURLS doesn’t have such a feature, and I couldn’t find anything in the (extensive) list of plugins that would do it for me. I needed to write my own.
In some ways, subscribing “to yourself” is a strange thing to do. In other ways… shut up, I’ll do what I like.
I could have written a YOURLS plugin. Or I could have written a stack of code in Ruby, PHP, Javascript or
some other language to bridge these systems. But as I switched over my shortlink subdomain s.danq.me to its new home at danq.link, another idea came to me. I
have direct database access to YOURLS (and the table schema is super simple) and the command-line MariaDB client can output XML… could I simply write an XML
Transformation to convert database output directly into a valid RSS feed? Let’s give it a go!
I wrote a script like this and put it in my crontab:
mysql --xml yourls -e \"SELECT keyword, url, title, DATE_FORMAT(timestamp, '%a, %d %b %Y %T') AS pubdate FROM yourls_url ORDER BY timestamp DESC LIMIT 30"\
| xsltproc template.xslt - \
| xmllint --format - \
> output.rss.xml
The first part of that command connects to the yourls database, sets the output format to XML, and executes an
SQL statement to extract the most-recent 30 shortlinks. The DATE_FORMAT function is used to mould the datetime into
something approximating the RFC-822 standard for datetimes as required by
RSS. The output produced looks something like this:
<?xml version="1.0"?><resultsetstatement="SELECT keyword, url, title, timestamp FROM yourls_url ORDER BY timestamp DESC LIMIT 30"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><row><fieldname="keyword">VV</field><fieldname="url">https://webdevbev.co.uk/blog/06-2021/perfect-is-the-enemy-of-good.html</field><fieldname="title"> Perfect is the enemy of good || Web Dev Bev</field><fieldname="timestamp">2021-09-26 17:38:32</field></row><row><fieldname="keyword">VU</field><fieldname="url">https://webdevlaw.uk/2021/01/30/why-generation-x-will-save-the-web/</field><fieldname="title">Why Generation X will save the web Hi, Im Heather Burns</field><fieldname="timestamp">2021-09-26 17:38:26</field></row><!-- ... etc. ... --></resultset>
We don’t see this, though. It’s piped directly into the second part of the command, which uses xsltproc to apply an XSLT to it. I was concerned that my XSLT
experience would be super rusty as I haven’t actually written any since working for my former employer SmartData back in around 2005! Back then, my coworker Alex and I spent many hours doing XML
backflips to implement a system that converted complex data outputs into PDF files via an XSL-FO intermediary.
I needn’t have worried, though. Firstly: it turns out I remember a lot more than I thought from that project a decade and a half ago! But secondly, this conversion from MySQL/MariaDB
XML output to RSS turned out to be pretty painless. Here’s the
template.xslt I ended up making:
<?xml version="1.0"?><xsl:stylesheetxmlns:xsl="http://www.w3.org/1999/XSL/Transform"version="1.0"><xsl:templatematch="resultset"><rssversion="2.0"xmlns:atom="http://www.w3.org/2005/Atom"><channel><title>Dan's Short Links</title><description>Links shortened by Dan using danq.link</description><link> [ MY RSS FEED URL ]</link><atom:linkhref=" [ MY RSS FEED URL ] "rel="self"type="application/rss+xml"/><lastBuildDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</lastBuildDate><pubDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</pubDate><ttl>1800</ttl><xsl:for-eachselect="row"><item><title><xsl:value-ofselect="field[@name='title']"/></title><link><xsl:value-ofselect="field[@name='url']"/></link><guid>https://danq.link/<xsl:value-ofselect="field[@name='keyword']"/></guid><pubDate><xsl:value-ofselect="field[@name='pubdate']"/> UTC</pubDate></item></xsl:for-each></channel></rss></xsl:template></xsl:stylesheet>
That uses the first (i.e. most-recent) shortlink’s timestamp as the feed’s pubDate, which makes sense: unless you’re going back and modifying links there’s no more-recent
changes than the creation date of the most-recent shortlink. Then it loops through the returned rows and creates an <item> for each; simple!
The final step in my command runs the output through xmllint to prettify it. That’s not strictly necessary, but it was useful while debugging and as the whole command takes
milliseconds to run once every quarter hour or so I’m not concerned about the overhead. Using these native binaries (plus a little configuration), chained together with pipes, had
already resulted in way faster performance (with less code) than if I’d implemented something using a scripting language, and the result is a reasonably elegant “scratch your
own itch”-type solution to the only outstanding barrier that was keeping me on S.2.
All that remained for me to do was set up a symlink so that the resulting output.rss.xml was accessible, over the web, to my RSS reader. I hope that next time I’m tempted to write a script to solve a problem like this I’ll remember that sometimes a chain of piped *nix
utilities can provide me a slicker, cleaner, and faster solution.
Update: Right as I finished writing this blog post I discovered that somebody had already solved this
problem using PHP code added to YOURLS; it’s just not packaged as a plugin so I didn’t see it earlier! Whether or not I
use this alternate approach or stick to what I’ve got, the process of implementing this YOURLS-database ➡ XML
➡ XSLT ➡ RSS chain was fun and
informative.
Long ago, I used desktop RSS readers. I was only subscribed to my friends’ blogs back then anyway, so it didn’t matter that I could only read them from my home computer. But then RSS
feeds started appearing on news sites, and tech blogs started appearing about things related to my work. And smartphones took over the world, and I wanted to be able to synchronise my
reading list everywhere. There were a few different services that competed for my attention, but Google Reader was the best. It was simple, and fast, and easy, and it Just Worked in
that way that Google products often do.
I put up with the occasional changes to the user interface. Hey, it’s a beta, and it’s still the best thing out there. Hey, it’s free, what can you say? I put up with the fact that from
time to time, they changed the site in ways that were sometimes quite hostile to Opera, my web
browser of choice. I put up with the fact that it had difficulty with unsigned HTTPS certificates (it’s fine now) and that it didn’t provide a mechanism to authenticate against services
like LiveJournal (it still doesn’t). I even worked around the latter, releasing my own tool and updatingit a few times until LiveJournal blocked it (twice) and I had to instead recommend that people switched to rival service FreeMyFeed.
The new Google Reader (with my annotations - click to embiggen). It sucks quite a lot.
I know that they’re ever-so-proud of the Google+ user interface, but rebranding all of the other services to look like
it just isn’t working. It’s great for Google+, not-bad for Search, bad for GMail (but at least you can turn it off!), and fucking awful for Reader. I like
distinct borders between my items. I don’t like big white spaces and buttons that eat up half the screen.
The sharing interface is completely broken. After a little while, I worked out that I still can share things with other people, but I can’t any longer see what other
people are sharing without clicking over to Google+. This sucks a lot. No longer can I keep track of which shared items I have and haven’t read, and no longer can I read the interesting
RSS feeds my friends have shared in the same place as I read (and share) my own.
So that’s the last straw. Today, I switched everything over to Tiny Tiny RSS.
Tiny Tiny RSS - it's simple, clean, and (in an understated way) beautiful.
Originally I felt that I was being pushed “away” from Google Reader, but the more I’ve played with it, the more I’ve realised that I’m being drawn “towards” Tiny Tiny, and wishing that
I’d made the switch further. The things that have really appealed are:
It’s self-hosted. Tiny Tiny RSS is a free, open-source solution that you host for yourself (or I suppose you can use a shared host; there are a few around). I know
that this is a downside to most people, but to me, it’s a serious selling point: now, I’m in control of what updates are applied, when, and if I don’t like the
functionality of a part of the system, I can change it – I’m in control.
It’s simple and clean. It’s got a great user interface, in an understated and simplistic way. It’s somewhat reminiscent of desktop email clients,
replacing the “stream of feeds” idea with a two- or three-pane view (your choice). That sounds like it’d be a downside, until you realise…
…with great keyboard controls. Tiny Tiny RSS is great for keyboard lovers like me. The default key-commands (which are of course customisable) are based on
Emacs, so if that’s your background then it’s easy to be right at home in minutes and browsing feeds faster than ever.
Plus: it’s got a stack of nice features. I’m loving the “fresh” filter, that helps me differentiate between the stuff I’ve “saved for later” reading and the
stuff that’s actually new and interesting. I’m also impressed by the integrated authentication, which removes my dependency on FreeMyFeed-like services and (because it’s self-hosted)
lets me keep my credentials securely under my own control. It supports authentication using SSL certificates, a beautiful and underused technology. It allows you to customise the
update frequency of your feeds, so I can stalk by friends’ blogs at lightning-quick rates and stall my weekly update subscriptions so they don’t get checked so frequently. And unlike
Google Reader, it actually tells me when feeds break, so I don’t just “get no updates” for a while before I think to check the site (and it’ll even let me change the
URLs when this happens, rather than unsubscribing and resubscribing).
Put simply: all of my major gripes with Google Reader over the last few years have been answered all at once in this wonderful little program. If people are interested in how I set up
Tiny Tiny RSS and and made the switchover as simple and painless as possible, I’ll write a blog post to talk you through it.
I’ve had just one problem: it’s not quite so tolerant of badly-formed XML as Google Reader. There’s one feed in my list which, it turns out, has (very) invalid XML in it’s
feed, that Google Reader managed to ignore and breeze over, but Tiny Tiny RSS chokes on. I’ve contacted the site owner to try to get it fixed, but if they don’t, I might have to hack
some code to try to make a workaround. Not ideal, and not something that everybody would necessarily want to deal with, so be aware!
If, like me, you’ve become dissatisfied by Google Reader this week, you might also like to look at rssLounge, the
other worthy candidate I considered as a replacement. I had a quick play but didn’t find it quite as suitable for my needs, but it might be to your taste: take a look.
The new sidebar, showing what I'm reading in my RSS reader lately.
Oh, and one more thing: if you used to “follow” me on Google Reader (or even if you didn’t) and you want to continue to subscribe to the stuff I “share”, then
you’ll want to subscribe to this new RSS feed of “my shared stuff”, instead: it can also be found syndicated in
the right-hand column of my blog.
Update:this guy’s made a
bookmarklet that makes the new Google Reader theme slightly less hideous. Doesn’t fix the other problems, though, but if you’re not quite pissed-off enough to jump ship, it
might make your experience more-bearable.
Update 2: others in the blogosphere are saying good things about Reader rival NewsBlur, which recently turned one year old. If you’re looking for a hosted
service, rather than something “roll-your-own” like Tiny Tiny RSS, perhaps it’s the tool for you?
This morning, I got an instant message from a programmer who’s getting deeply into their Ajax recently. The conversation went something like this (I paraphrase and dramatise at least a little):
Morning! I need to manipulate a JSON feed so that [this JSON parser] will recognise it.




![Browser debugger running document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() on Beverley's weblog and getting the first blog entry.](https://bcdn.danq.me/_q23u/2022/09/debugger-select-from-xpath-1024x256.png)



. It sucks quite a lot.")
 beautiful.")
