I’m not sure which is the most-hypnotic in this video: the graceful click-clack motion of the finished product or the careful and methodical production steps that precede it. Either
way, this perpetual calendar is brilliant, but if I owned it I’d absolutely spend the entire time playing with it rather than using it for its intended purpose.
When I arrived at this weekend’s IndieWebCamp I still wasn’t sure what it was that I would be
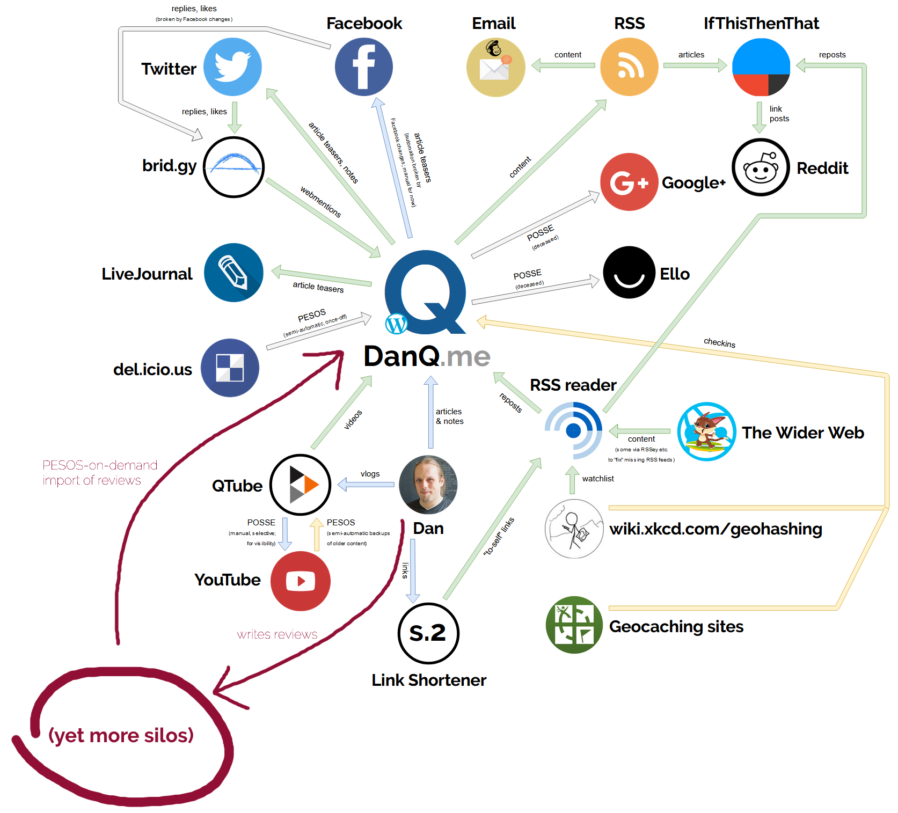
working on. I’d worked recently to better understand the ecosystem surrounding DanQ.me and had a number of half-formed ideas about tightening
it up. But instead, I ended up expanding the reach of my “personal web” considerably by adding reviews as a post type to my site and building
tools to retroactively-reintegrate reviews I’d written on other silos.
The oldest surviving review I found was my grumbling about Windows XP Home edition being just a crippled version of Pro edition. And now it’s immortalised here.
Over the years, I’ve written reviews of products using Amazon and Steam and of places using Google Maps and TripAdvisor. These are silos and my
content there is out of my control and could, for example, be deleted at a moment’s notice. This risk was particularly fresh in my mind as my friend Jen‘s Twitter account was suspended this weekend for allegedly violating the platform’s rules
(though Twitter have so far proven unwilling to tell her which rules she’s broken or even when she did so, and she’s been left completely in the dark).
My mission for the weekend was to:
Come up with a mechanism for the (microformat-friendly) display of reviews on this site, and
Reintegrate my reviews from Amazon, Steam, Google Maps and TripAdvisor
Steam reviews use a “thumbs up/thumbs down” rating system rather than a “5-star” style, but h-review is capable of expressing both and more.
I opted not to set up an ongoing POSSE nor PESOS process at this point; I’ll do this manually in the short term (I don’t write reviews on third-party sites often). Also out of
scope were some other sites on which I’ve found that I’ve posted reviews, for example BoardGameGeek. These can both be tasks for a future date.
The lovely diagram I drew earlier this year? Here it is with the new loop drawn on.
I used Google Takeout to export my Google Maps reviews, which comprised the largest number of reviews of the sites I targetted and which is the
least screen-scraper friendly. I wrote a bookmarklet-based screen-scraper to get the contents of my reviews on each of the other sites. Meanwhile, I edited by WordPress theme’s functions.php to extended the Post Kinds plugin with an
extra type of post, Review, and designed a content template which wrapped reviews in appropriate microformat markup, using metadata attached to each review post to show e.g. a
rating, embed a h-product (for products) or h-card (for
places). I also leveraged my existing work from last summer’s effort to reintegrate my geo*ing logs to automatically
add a map when I review a “place”. Finally, I threw together a quick WordPress plugin to import the data and create a stack of draft posts for proofing and publication.
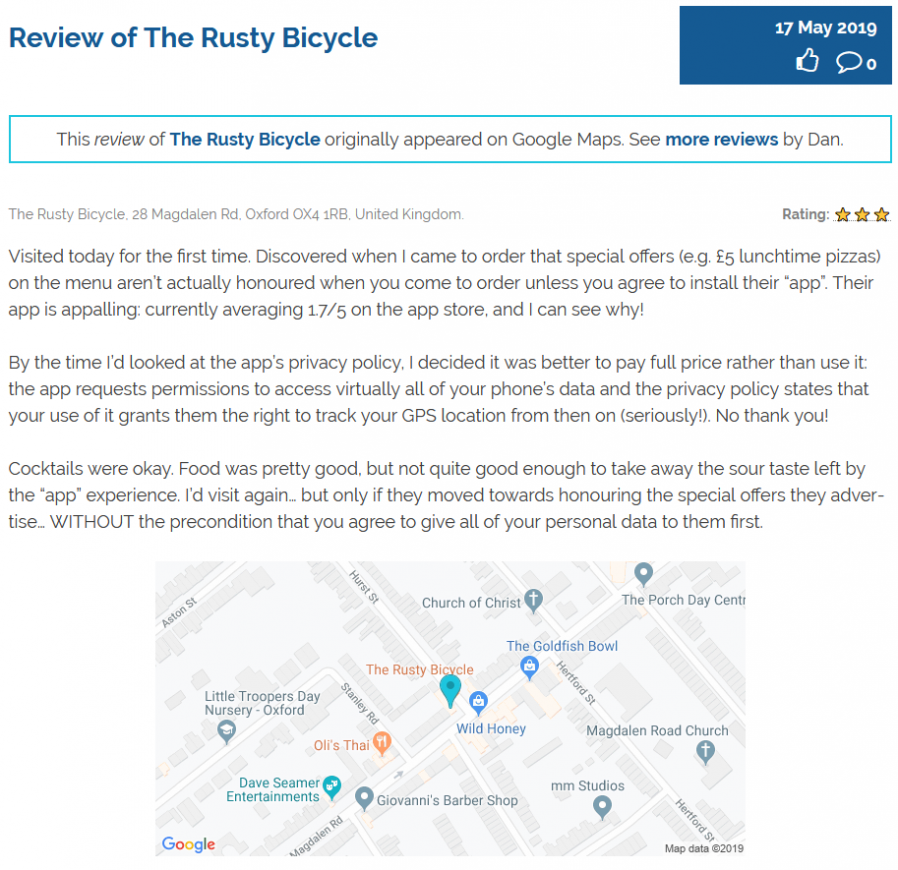
I was moderately unimpressed by Oxford pub The Rusty Bicycle. I originally said so on Google Maps, and now I can say so here, too!
So now you can read all of the reviews I’ve ever posted to any of those four sites, right here, alongside any other reviews I subsequently reintegrate and any
I write directly to my blog in the future. The battle to own all of my own content after 25 years of scattering it throughout the Internet isn’t always easy, but it remains worthwhile.
(I haven’t open-sourced my work this time because it’s probably useful only to me and my very-specific set-up, but if anybody wants a copy they can get in
touch.)
Performed routine maintenance at the cache site; everything seems well.
A couple of ‘cachers have reported that the GZ is inaccessible owing to the path being overgrown. The “obvious” path to the cache really is pretty heavily overgrown and I’ll be
increasing the terrain rating from 3 to 3.5 accordingly, but the “obvious” path isn’t the only path! If you need a hint as to the direction from which the alternative path (which is
quite a bit longer, but much more-usable) comes, see my GZ video below:
Very occasionally I get asked how to start blogging by people who would like to create exciting and engaging articles that will build a following by delighting an audience hungry
for more. Perhaps they envision spreading their views far across the face of the web.
To which I always reply, “Have you read my blog? I don’t know about any of those things!”
What I do have are 10 years of logs and some vague observations about beginning a blog.
…
As I’m sat here anyway, helping people get started on the Indieweb, here’s a great (tongue in cheek) look at
how you can expect your new blog Indieweb presence to take off and become the Most Popular Thing Ever. Or rather, not.
But as I and others have said before, my blog is first and foremost for me. If you get something out of it too, that’s great, but
that’s a secondary goal!
A long while ago, inspired by Nick Berry‘s analysis of optimal Hangman strategy, I worked it backwards to find the
hardest words to guess when playing Hangman. This week, I showed these to my colleague Grace – who turns out to be a fan of word puzzles – and our conversation inspired me to go a little deeper. Is it possible, I
thought, for me to make a Hangman game that cheats by changing the word it’s thinking of based on the guesses you make in order to make it as difficult as possible for you to
win?
The principle is this: every time the player picks a letter, but before declaring whether or not it’s found in the word –
Make a list of all possible words that would fit into the boxes from the current game state.
If there are lots of them, still, that’s fine: let the player’s guess go ahead.
But if the player’s managing to narrow down the possibilities, attempt to change the word that they’re trying to guess! The new word must be:
Legitimate: it must still be the same length, have correctly-guessed letters in the same places, and contain no letters that have been declared to be incorrect
guesses.
Harder: after resolving the player’s current guess, the number of possible words must be larger than the number of possible words that would have
resulted otherwise.
Yeah, you’re screwed now.
You might think that this strategy would just involve changing the target word so that you can say “nope” to the player’s current guess. That happens a lot, but it’s not always the
case: sometimes, it’ll mean changing to a different word in which the guessed letter also appears. Occasionally, it can even involve changing from a word in which the guessed
letter didn’t appear to one in which it does: that is, giving the player a “freebie”. This may seem counterintuitive as a strategy, but it sometimes makes sense: if
saying “yeah, there’s an E at the end” increases the number of possible words that it might be compared to saying “no, there are no Es” then this is the right move for a
cheating hangman.
Playing against a cheating hangman also lends itself to devising new strategies as a player, too, although I haven’t yet looked deeply into this. But logically, it seems that the
optimal strategy against a cheating hangman might involve making guesses that force the hangman to bisect the search space: knowing that they’re always going to adapt towards the
largest set of candidate words, a perfect player might be able to make guesses to narrow down the possibilities as fast as possible, early on, only making guesses that they actually
expect to be in the word later (before their guess limit runs out!).
The game is brutally-difficult, but surprisingly fun, and you can have it tell you when and how it cheats so you can begin to understand its strategy.
I also find myself wondering how easily I could adapt this into a “helpful hangman”: a game which would always change the word that you’re trying to guess in order to try to make you
win. This raises the possibility of a whole new game, “suicide hangman”, in which the player is trying to get themselves killed and so is trying to pick letters that can’t
possibly be in the word and the hangman is trying to pick words in which those letters can be found, except where doing so makes it obvious which letters the player must avoid next.
Maybe another day.
In the meantime, you’re welcome to go play the game (and let me know what you think, below!) and, if you’re of such an inclination, read the source code. I’ve used some seriously ugly techniques to make this work, including regular expression metaprogramming (using
regular expressions to write regular expressions), but the code should broadly make sense if you want to adapt it. Have fun!
Update 26 September 2019, 16:23: I’ve now added “helpful mode”, where the computer tries to cheat on your behalf
rather than against you, but it’s not as helpful as you’d think because it assumes you’re playing optimally and have already memorised the dictionary!
Let’s face the truth. We are in an abusive relationship with our phones.
Ask yourself the first three questions that UK non-profit Women’s Aid
suggests to determine if you’re in an abusive relationship:
Has your partner tried to keep you from seeing your friends or family?
Has your partner prevented you or made it hard for you to continue or start studying, or from going to work?
Does your partner constantly check up on you or follow you?
If you substitute ‘phone’ for ‘partner’, you could answer yes to each question. And then you’ll probably blame yourself.
…
A fresh take by an excellent article. Bringing a feminist viewpoint to our connection to our smartphones helps to expose the fact that our relationship with the devices would easily be
classified as abusive were they human. The article goes on to attempt to diffuse the inevitable self-blame that comes from this realisation and move forward to propose a more-utopian
future in which our devices might work for us, rather than for the companies that provide the services for which we use them.
Possibly CGP Grey‘s best video yet: starting with the usual lighthearted and slightly silly look into an interesting piece of history, it quickly
diverges from a straightforward path through the Forest of All Knowledge (remember No Flag Northern Ireland?) and
becomes an epic adventure into fact-checking, healthy scepticism, and demonstrable information literacy. Speaking admittedly as somebody who genuinely loved the Summer of Grey Tesla Road Trip series of vlogs, this more-human-than-average Grey
adventure is well-worth watching to the end.
This afternoon, the kids and I helped with some citizen science as part of the Thames WaterBlitz, a collaborative effort
to sample water quality of the rivers, canals, and ponds of the Thames Valley to produce valuable data for the researchers of today and tomorrow.
Our sampling point was by bridge 228 on the Oxford Canal: the first job was fetching water.
My two little science assistants didn’t need any encouragement to get out of the house and into the sunshine and were eager to go. I didn’t even have to pull out my trump card of
pointing out that there were fruiting brambles along the length of the canal. As I observed in a vlog last year, it’s usually pretty easy to
motivate the tykes with a little foraging.
Some collaboration was undertaken to reach a consensus on the colour of the sample.
The EarthWatch Institute had provided all the chemicals and instructions we needed by post, as well as a mobile app with which to record our results (or paper forms, if we preferred).
Right after lunch, we watched their instructional video and set out to the sampling site. We’d scouted out a handful of sites including some on the River Cherwell as it snakes through
Kidlington but for this our first water-watch expedition we figured we’d err on the safe side and aim to target only a single site: we chose this one both because it’s close to home and
because a previous year’s citizen scientist was here, too, improving the comparability of the results year-on-year.
Lots of nitrates, as indicated by the colour of the left tube. Very few phosphates, as indicated by the lack of colour in the right (although it’s still a minute and a half from
completing its processing time at the point this photo was taken and would darken a tiny bit yet).
Which colour most-resembles the colour of our reagent?
Our results are now online, and we’re already looking forward to seeing the overall
results pattern (as well as taking part in next year’s WaterBlitz!).
One way I’ve found to enhance my nights as Dungeon Master is to call on experiences as an amateur musician and fan, to ramp up the intensity and sense of fantasy with playlists of
tunes from the history of composed and recorded music.
I realised that this might be something I was OK at when I saw our party’s rogue lost in imagination and stabbing to the beat of a bit of Shostakovich.
Over the months some of the collections I’ve curated have picked up a few followers on Spotify and upvotes on Reddit but I thought it was time to put more effort in and start
writing about it.
The opening post from Lute the Bodies, a new blog by my friend Alec. It promises an exploration of enhancing tabletop roleplaying with
music, which is awesome: I’ve occasionally been known to spend longer picking out the music for a given roleplaying event than I have on planning the roleplaying activities themselves!
Looking forward to see where this goes…
I write the integers 1-9999 (inclusive) on a huge chalkboard. Each number is written once.
During the night the board is visited by a series of naughty math elves (it’s a thing!)
Each elf approaches the board, selects two numbers at random, erases them, and replaces them with a new number that is the absolute difference of the two numbers erased.
This vandalism continues all night until there is just one number remaining.
I return to the board the next morning and find the single number of the board. The question is: Is this remaining number odd or even?
…
A fun, lightweight maths puzzle for your amusement. I was able to find the right answer pretty quickly by spotting the pattern; it took me longer to find the words to adequately
explain the pattern.
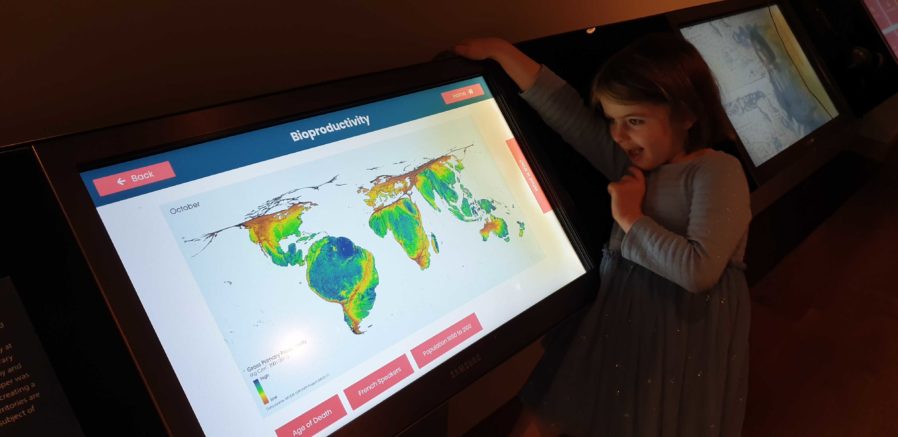
As part of the preparing to leave the Bodleian I’ve been revisiting a lot of the documentation I’ve written over the last eight
years. It occurred to me that I’ve never written publicly about how the Bodleian’s digital signage/interactives actually work; there are possible lessons to learn.
The Bodleian‘s digital signage is perhaps more-diverse, both in terms of technology and audience, than that of most organisations. We’ve got
signs in areas that are exclusively reader-facing to help students and academics find what they’re looking for, signs in publicly accessible rooms that advertise and educate, and signs
in gallery spaces upon which we try to present engaging and often-interactive content to support exhibitions.
Getting an extra touchscreen for the office for prototyping/user testing purposes was great, even when it wasn’t showing MLP: FiM.
Throughout those three spheres, we’ve routinely delivered a diversity of content (let’s just ignore the countdown clock, for now…). Traditional
directional signage, advertisements, games, digital exhibitions, interpretation, feedback surveys…
In the vast majority of cases – and this is where the Bodleian’s been unusual (though certainly not unique) among cultural sector institutions – we’ve created
those in-house rather than outsourcing them.
Using off-the-shelf technology also allows the Bodleian to in-house much of their hardware maintenance, as a secondary part of other job roles. Singing into your screwdriver remains
optional, though.
To do this economically – the volume of work on interactive signage is inconsistent throughout the year – we needed to align the skills required with skills used elsewhere in the
organisation. To do this, we use the web as our medium! Collectively, the Bodleian’s Digital Communications team already had at least some experience in programming, web design, graphic
design, research, user testing, copyediting etc.: the essential toolkit for web application development.
Whether you were playing Pong on the video wall at the back or testing your Middle-earth knowledge on the touchscreen at the front… behind the
scenes you were interacting with a web page I wrote.
By shifting our digital signage platform to lean heavily on web technologies, we were able to leverage talented people we already had to produce things that we might otherwise
have had to outsource. This, in turn, meant that more exhibitions and displays get digital enhancement, on a shorter turnaround.
It also means that there’s a tighter integration between exhibition content and content for web and social media: it’s easier for us to re-use content across multiple platforms.
Sometimes we’ve even made our digital interactives, or adapted version of them, available directly online, allowing our exhibitions to reach people that can’t get to our physical spaces
at all.
Because we’re able to produce our own content on-demand, even our smaller, shorter-duration displays can have hands-on digital interactives associated with them.
On to the technology! We’re using a real mixture of tech: when it’s donated or reclaimed from previous projects (and when the bidding and acquisition processes are, well… as you’d
expect at the University of Oxford), you learn not to say no to freebies. Our fleet includes:
Samsung Android tablets with freestanding kiosk frames. We run the excellent-value Kiosk Browser Lockdown app on
these, which loads on boot and prevents access to anything but a specified website.
OnelanNTBs connected to a mixture of
touch and non-touch screens, wall-mounted or in kiosk frames. We use Onelan’s standard digital signage features as well as – for interactive content – their built-in touch-capable web
browser.
Dell PCs of the standard variety supplied by University IT services, connected to wall-mounted touch screens, running Google Chrome in Kiosk Mode. More on this below.
The browsers’ responsive simulators are invaluable when we’re targeting signage at five (!) different resolutions.
When you’re developing content for a very small number of browsers and a limited set of screen sizes, you quickly learn to throw a lot of “best practice” web development out of the
window. You’ll never come across a text browser or screen reader, so alt-text doesn’t matter. You’ll never have to rescale responsively, so you might as well absolutely-position almost
everything. The devices are all your own, so you never need to ask permission to store cookies. And because you control the platform, you can get away with making configuration tweaks
to e.g. allow autoplaying videos with audio. Coming from a conventional web developer background to producing digital signage content makes feels incredibly lazy.
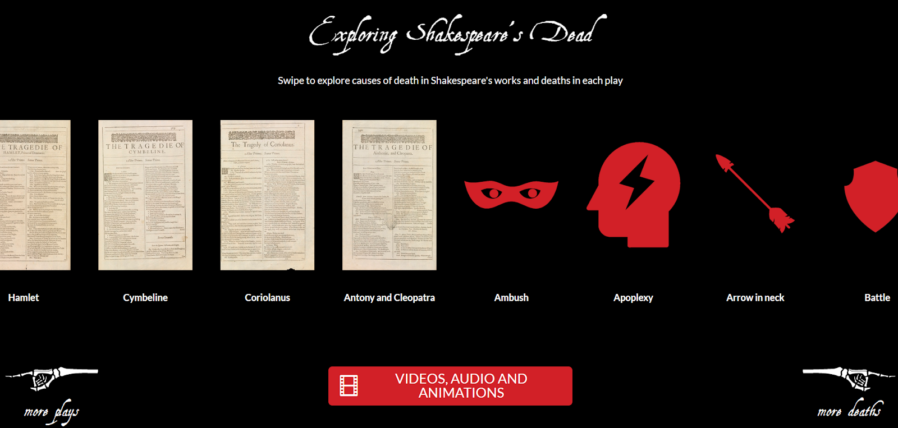
Helping your users see your interactive as “app-like” rather than “web-like” encourages them to feel comfortable engaging with it in ways uncharacteristic of web pages. In our Shakespeare’s Dead interactive, for example, we started the experience in the middle of a long horizontally-scrolling “page”, which might
feel very unusual in a conventional browser.
Using Chrome to run digital signage requires, in the Bodleian’s case, a couple of configuration tweaks and the right command-line switches. We use:
chrome://flags/#overscroll-history-navigation – disabling this prevents users from triggering “back”/”forward” by swiping with two fingers
chrome://flags/#pull-to-refresh – disabling this prevents the user from triggering a “refresh” by scrolling up beyond the top of the page (this only happens on some
kinds of devices)
chrome://flags/#system-keyboard-lock – we don’t use attached keyboards, but if you do, you might want to set this flag so you can use the keyboard.lock()
API to intercept e.g. ALT+F4 so users can’t escape the application
running on startup with e.g. chrome --kiosk --noerrdialogs --allow-file-access-from-files --disable-touch-drag-drop --incognito https://example.com/some/url
Kisok mode makes the browser run fullscreen and prevents e.g. opening additional tabs, giving an instant “app-like” experience. As we don’t have keyboards attached to our
digital signage, this also prevents visitors from closing Chrome.
Turning off error dialogs reduces the risk that an error will result in an unslightly message to the user.
Enabling “file access from files” allows content hosted at file:// addresses to access content at other file:// addresses, which makes it possible to write “offline” sites
(sometimes useful where we’re serving large videos or on previous occasions when WiFi has been shaky) that can still take advantage of features like the Fetch API.
Unless you need drag-and-drop, it’s simpler to disable it; this prevents a user long-press-and-dragging an image around the screen.
Incognito mode ensures that the browser doesn’t remember what site was showing last time it ran; our computers often end up switched off at the wall at the end of the day, and
without this the browser will offer to load the site it had open last time, when it runs.
We usually host our interactives directly on the web, at “secret” addresses, and this is generally preferable to us as we can more-easily make on-the-fly adjustments to
content (plus it makes it easier to hook up analytic tools).
Be sure to test the capabilities of your hardware! Our Onelan NTBs, unlike your desktop PCs, can’t handle multitouch input, which
affects the design of our user interfaces for these devices.
Meanwhile, in the application’s CSS code, we set * { user-select: none; } to prevent the user from highlighting
text by selecting it with their finger. We also make heavy use of absolutely-sized/positioned, overflow: hidden blocks to ensure that scrollbars never appear, and
CSS animations to make content feel dynamic and to draw attention to particular elements.
There’s no substitute for good testing. And there’s no stress-testing quite like letting a 5 year-old loose on your work.
Altogether, this approach gives the Bodleian the capability to produce engaging interactive content at low cost and using the existing skills of their digital and exhibitions teams.
It’s not an approach that would work for every cultural institution: in particular, some of the Bodleian’s sister institutions already
outsource the technical parts of their web work, and so don’t have the expertise in-house to share with a web-powered digital signage solution.
A few minor CSS tweaks to make the buttons finger-friendly and our Halloween game Shadows Out Of
Time, which I’d already made web-friendly, was touchscreen-ready too. I wonder if they’ll get this one out again, this
Halloween?
But for those museums that can fit into this model – or can adapt to do so in future – using the web to produce interactive digital content and digital signage is a highly
cost-effective way to engage with visitors, even (or especially!) when dealing with short-lived and/or rotating displays.
It’s also been among my favourite parts of my job at the Bod these last 8½ years, and I’m sure I’ll miss it!
This adventure took a lot of planning. It’s 350 miles from where I live to Glasgow. I have a Honda CG 125cc, and my maximum range in one day is around 200 miles – if I have the full
day for travelling, which I wouldn’t have, most days. I figured if I was going to have a road trip, I’d have to make stop offs at various parts of the UK, to break it up. This
actually worked out really well, as there are lots of parts of the UK that I wanted to visit.
…
After booking the series of hotel rooms, I started to think about the actual riding. It was two weeks before the trip. I didn’t have enough thermals, or a bike suit that was
protective enough. I also didn’t have a way of storing luggage on my bike, or keeping it dry (and two laptops would be in the bags). There was also an issue with the chain on my
bike that needed fixing. Not exactly a trivial to do list! So the next two weeks turned into a bit of an eBay and Amazon frenzy, with a trip down to see my dad in Kent to get the
bike chain fixed, and rummage around for my old waterproofs in my grandparent’s attic. It was pretty close: the final item arrived the day before the trip. I got ridiculously lucky
on eBay with my new, more visible, better padded, comfy bike suit though, which I love to bits. In hindsight, more time for all of this would have been helpful!
…
My friend Bev wrote about their motorcycling adventure up and down the UK; it’s pretty awesome.

 a
a body
body canvas
canvas