This isn’t the guide for you
The Internet is full of guides on easily making your WordPress installation run fast. If you’re looking to speed up your WordPress site, you should go read those, not this.
Those guides often boil down to the same old tips:
- uninstall unnecessary plugins,
- optimise caching (both on the server and, via your headers, on clients/proxies),
- resize your images properly and/or ensure WordPress is doing this for you,
- use a CDN (and use DNS prefetch hints)1,
- tune your PHP installation so it’s got enough memory, keeps a process alive, etc.,
- ensure your server is minifying2 and compressing files, and
- run it on a faster server/behind a faster connection3
The hard way
This article is for people who aren’t afraid to go tinkering in their WordPress codebase to squeeze a little extra (real world!) performance.
It’s for people whose neverending quest for perfection is already well beyond the point of diminishing returns.
But mostly, it’s for people who want to gawp at me, the freak who actually did this stuff just to make his personal blog a tiny bit nippier without spending an extra penny on hosting.
Don’t start with the hard way. Exhaust all the easy solutions – or at least, make a conscious effort which easy solutions to enact or reject – first. Only if you really want to get into the weeds should you actually try doing the things I propose here. They’re not for most sites, and they’re not the for faint of heart.
Performance is a tradeoff. Every performance improvement costs you something else: time, money, DX, UX, etc. What you choose to trade for performance gains depends on your priority of constituencies, which may differ from mine.4
This is not a recipe book. This won’t tell you what code to change or what commands to run. The right answers for your content will be different than the right answers for mine. Also: you shouldn’t change what you don’t understand! But I hope these tips will help you think about what questions you need to ask to make your site blazing fast.
Okay, let’s get started…
1. Backstab the plugins you can’t live without
If there are plugins you can’t remove because you depend upon their functionality, and those plugins inject content (especially JavaScript) on the front-end… backstab them to undermine that functionality.
For example, if you want Jetpack‘s backup and downtime monitoring features, but you don’t want it injecting random <link rel='stylesheet' id='...-jetpack-css' href='...' media='all' />‘s (an
extra stylesheet to download and parse) into your pages: find the add_filter hook it uses and remove_filter it in your theme5.
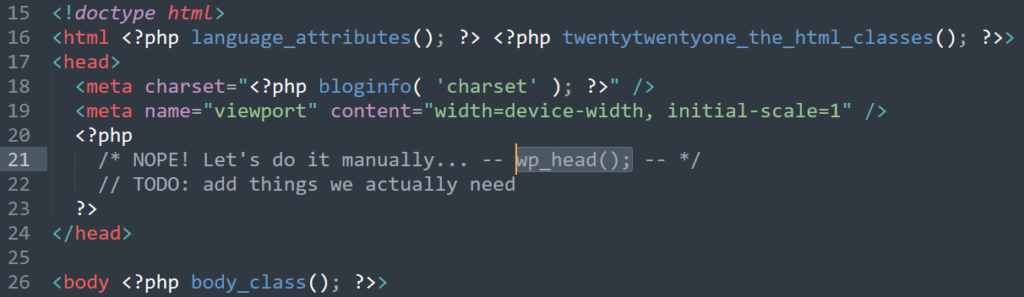
wp_head() and manually reimplement the functionality you actually need. Insert your own joke about “Headless WordPress” here.
Better yet, remove wp_head() from your theme entirely6.
Now, instead of blocking the hooks you don’t want polluting your <head>, you’re specifically allowing only those you want. You’ll want to take care to get
some semi-essential ones like <link rel="canonical" href="...">7.
Now most of your plugins are broken, but in exchange, your theme has reclaimed complete control over what gets sent to the user. You can select what content you actually want delivered, and deliver no more than that. It’s harder work for you, but your site becomes so much lighter.

2. Throw away 100% of your render-blocking JavaScript (and as much as you can of the rest)
The single biggest bottleneck to the user viewing a modern WordPress website is the JavaScript that needs to be downloaded, compiled, and executed before the page can be rendered. Most of that’s plugins, but even on a nearly-vanilla installation you might find a copy of jQuery (eww!) and some other files.
In step 1 you threw it all away, which is great… but I’m betting you were depending on some of that to make your site work? Let’s put it back, carefully and selectively, while minimising the impact on load time.
That means scripts should be loaded (a) low-down, and/or (b) marked defer (or, better yet, async), so they don’t block page rendering.
If you haven’t already, you might like to View Source on this page. Count my <script> tags. You’ll probably find just two of them: one external file marked
async, and a second block right at the bottom.
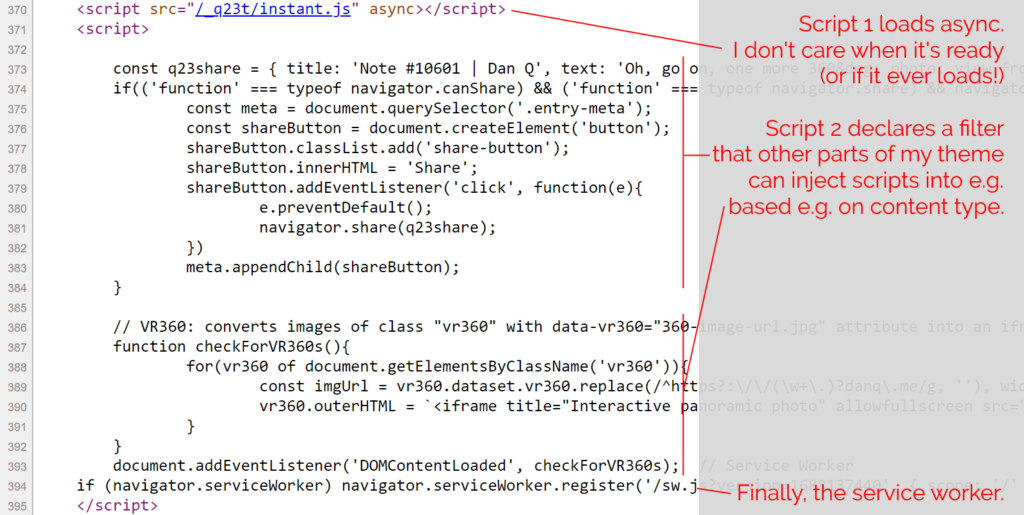
The inline <script> in my footer.php wraps a single line of PHP: which looks a little like
this: <?php echo implode("\n\n", apply_filters( 'danq_footer_js', [] ) ); ?>. For each item in an initially-empty array, it appends to the script tag. When I render
anything that requires JavaScript, e.g. for 360° photography, I can just add to that
(keyed, to prevent duplicates when viewing an archive page) array. Thus, the relevant script gets added exclusively to the pages where it’s needed, not to the entire site.
The only inline script added to every page loads my service worker, which itself aims to optimise caching as well as providing limited “offline” functionality.
While you’re tweaking your JavaScript anyway, you might like to check that any suitable addEventListeners are set to passive mode. Especially
if you’re doing anything with touch or mousewheel events, you can often increase the perceived performance of these interactions by not letting your custom code block the default
browser behaviour.
3. Don’t use a CDN
Wait, what? That’s the opposite of what everybody else recommends. To understand why, you have to think about why people recommend a CDN in the first place. Their reasons are usually threefold:
-
Proximity
Claim: A CDN delivers content geographically-closer to the user.
Retort: Often true. But in step 4 we’re going to make sure that everything critical comes within the first TCP sliding window anyway, so there’s little benefit, and there’s a cost to that extra DNS lookup and fresh handshake. Edge caching your own content may have value, but for most sites it’ll have a much smaller impact than almost everything else on this list. -
Precaching
Claim: A CDN improves the chance resources are precached in the user’s browser.
Retort: Possibly true, especially with fonts (although see step 6) but less than you’d think with JS libraries because there are so many different versions/hosts of each. Yours may well be the only site in the user’s circuit that uses a particular one! -
Power
Claim: A CDN has more resources than you and so can better-withstand spikes of traffic.
Retort: Maybe, but they also introduce an additional single-point-of-failure. CDNs aren’t magically immune to downtime nor content-blocking, and if you depend on one you’ve just doubled the number of potential failure points that can make your site instantly useless. Furthermore: in exchange for those resources you’re trading away your users’ privacy and security: if a CDN gets hacked, every site that uses it gets hacked too.
Consider edge-caching your own content only if you think you need it, but ditch jsDeliver, cdnjs, Google Hosted Libraries etc.
Hell: if you can, ditch all JavaScript served from third-parties and slap a Content-Security-Policy: script-src 'self' header on your domain to dramatically reduce
the entire attack surface of your site!8
4. Reduce your HTML and CSS size to <12kb compressed
There’s a magic number you need to know: 12kb. Because of some complicated but fascinating maths (and depending on how your hosting is configured), it can be significantly faster to initially load a web resource of up to 12kb than it is to load one of, say, 15kb. Also, for the same reason, loading a web resource of much less than 12kb might not be significantly faster than loading one only a little less than 12kb.
Exploit this by:
- Making your pages as light as possible9, then
- Inlining as much essential content as possible (CSS, SVGs, JavaScript etc.) to bring you back up to close-to that magic number again!
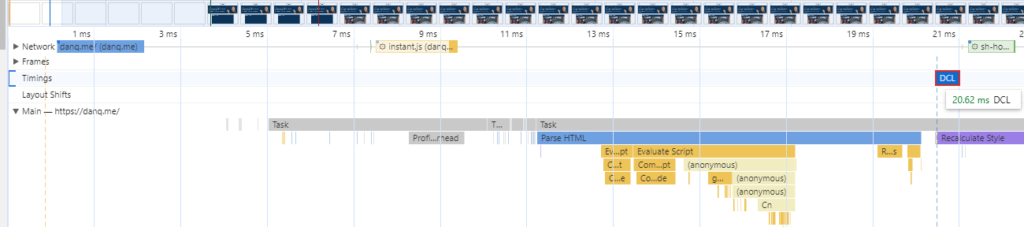
$ curl --compressed -so /dev/null -w "%{size_download}\n" https://danq.me/
10416
Again, this probably flies in the face of everything you were taught about performance. I’m sure you were told that you should <link> to your stylesheets so that they
can be cached across page loads. But it turns out that if you can make your HTML and CSS small enough, the opposite is true and you should inline the stylesheet again: caching styles becomes almost irrelevant if you get all the content in
a single round-trip anyway!
For extra credit, consider optimising your homepage’s CSS so it’s even smaller by excluding directives that only apply to
non-homepage pages, and vice-versa. Assuming you’re using a preprocessor, this shouldn’t be too hard: at simplest, you can have a homepage.css and main.css,
each derived from a set of source files some of which they share (reset/normalisation, typography, colours, whatever) and the rest which is specific only to that part of the site.
Can’t manage to get your HTML and CSS down below the magic
number? Then at least ensure that your HTML alone weighs in at <12kb compressed and you’ll still get some of the
benefits. If you’ve got the headroom, you can selectively include a <style> block containing only the most-crucial CSS, with a particular focus on any that results in layout shifts (e.g. anything that specifies the height: of otherwise dynamically-sized
block elements, or that declares an element position: absolute or position: fixed). These kinds of changes are relatively computationally-expensive because
they cause content to re-flow, so provide hints as soon as possible so that the browser can accommodate for them.
5. Make the first load awesome
We don’t really talk about content being “above the fold” like we used to, because the modern Web has such a diverse array of screen sizes and resolutions that doing so doesn’t make much sense.
But if loading your full page is still going to take multiple HTTP requests (scripts, images, fonts, whatever), you should still try to deliver the maximum possible value in the first round-trip. That means:
- Making sure all your textual content loads immediately! Unless you’re delivering a huge amount of text, there’s absolutely no excuse for lazy-loading text: it’s usually tiny, compresses well, and it’s fast to parse. It’s also the most-important content of most pages. Get it delivered to the browser so it can be rendered rightaway.
- Lazy-loading images that are “expected” to be below the fold, using the proper HTML mechanism for this (never a JavaScript approach).
- Reserving space for blocks by sizing images appropriately, e.g. using
<img width="..." height="..." ...>or having them load as a background withbackground-size: coverorcontainin a block sized with CSS delivered in the initial payload. This reduces layout shift, which mitigates the need for computationally-expensive content reflows. - If possible (see point 4), move vector images that support basic site functionality, like logos, inline. This might also apply to icons, if they’re “as important” as text content.
- Marking everything up with standard semantic HTML. There’s a trend for component-driven design to go much too far, resulting in JavaScript components being used in place of standard elements like links, buttons, and images, resulting in highly-fragile websites: when those scripts fail (or are very slow to load), the page becomes unusable.
6. Reduce your dependence on downloaded fonts
Fonts are lovely and can be an important part of your brand identity, but they can also add a lot of weight to your web pages.
If you’re ready and able to drop your webfonts and appreciate the beauty and flexibility of a system font stack (I get it: I’m not there quite yet!), you can at least make smarter use of your fonts:
- Every modern browser supports WOFF2, so you can ditch those chunky old formats you’re clinging onto.
- If you’re only using the Latin alphabet, minify your fonts further by dropping the characters you don’t need: tools like Google Webfonts
Helper can help with this, as well as making it easier to selfhost fonts from the most-popular library (is a smart idea for the reasons described under point 3, above!). There are
tools available to further minify fonts if e.g. you only need the capital letters for your title font or something.
-
- Browsers are pretty clever and will work-around it if you make a mistake. Didn’t include an emoji or some obscure mathematical symbol, and then accidentally used them in a post? Browsers will switch to a system font that can fill in the gap, for you.
-
- Make the most-liberal use of the
font-display:CSS directive that you can tolerate!- Don’t use
font-display: block, which is functionally the default in most browsers, unless you absolutely have to. -
font-display: fallbackis good if you’re too cowardly/think your font is too important for you to tryfont-display: optional. -
font-display: optionalis an excellent choice for body text: if the browser thinks it’s worthwhile to download the font (it might choose not to if the operating system indicates that it’s using a metered or low-bandwidth connection, for example), it’ll try to download it, but it won’t let doing so slow things down too much and it’ll fall-back to whatever backup (system) font you specify. -
font-display: swapis also worth considering: this will render any text immediately, even if the right font hasn’t downloaded yet, with no blocking time whatsoever, and then swap it for the right font when it appears. It’s probably better for headings, because large paragraphs of text can be a little disorienting if they change font while a user is looking at them!
- Don’t use
7. Cache pre-compressed static files
It’s possible that by this point you’re saying “if I had to do this much work, I might as well just use a static site generator”. Well good news: that’s what you’re about to do!
Obviously you should make sure all your regular caching improvements (appropriate HTTP headers for caching, a service worker that further improves on that logic based on your content’s update schedule, etc.) first. Again: everything in this guide presupposes that you’ve already done the things that normal people do.
By aggressively caching pre-compressed copies of all your pages, you’re effectively getting the best of both worlds: a website that, for anonymous visitors, is served directly from
.html.gz files on a hard disk or even straight from RAM in memcached10,
but which still maintains all the necessary server-side interactivity to allow it to be used as a conventional Web-based CMS
(including accepting comments if that’s your jam).
WP Super Cache can do the heavy lifting for you for a filesystem-based solution so long as you put it into “Expert” mode and amending your webserver configuration. I’m using Nginx, so I needed a try_files directive like this:
location / {
try_files /wp-content/cache/supercache/$http_host/$wp_super_cache_path/index-https.html $uri $uri/ /index.php?$args;
}
8. Optimise image formats
I’m sure your favourite performance testing tool has already complained at you about your failure to use the best formats possible when serving images to your users. But how can you fix it?
There are some great plugins for improving your images automatically and/or in bulk – I use EWWW Image Optimizer – but
to really make the most of them you’ll want to reconfigure your webserver to detect clients that Accept:
image/webp and attempt to dynamically serve them .webp variants, for example. Or if you’re ready to give up on legacy formats and replace all your .pngs
with .webps, that’s probably fine too!

https://danq.me/_q23u/2023/11/dynamic.png is probably an image/webp. But if your browser doesn’t support WebP, you’ll get an
image/png instead!
Assuming you’ve got curl and Imagemagick‘s identify, you can see this in action:
-
curl -s https://danq.me/_q23u/2023/11/dynamic.png -H "Accept: image/webp" | identify -
(Will give you a WebP image) -
curl -s https://danq.me/_q23u/2023/11/dynamic.png -H "Accept: image/png" | identify -
(Will give you a PNG image, even though the URL is the same)
9. Simplify, simplify, simplify
The single biggest impact you can have upon the performance of your WordPress pages is to make them less complex.
I’m not necessarily saying that everybody should follow in my lead and co-publish their WordPress sites on the Gemini protocol. But you’ve got to admit: the simplicity of the Gemini protocol and the associated Gemtext format makes both lightning fast.
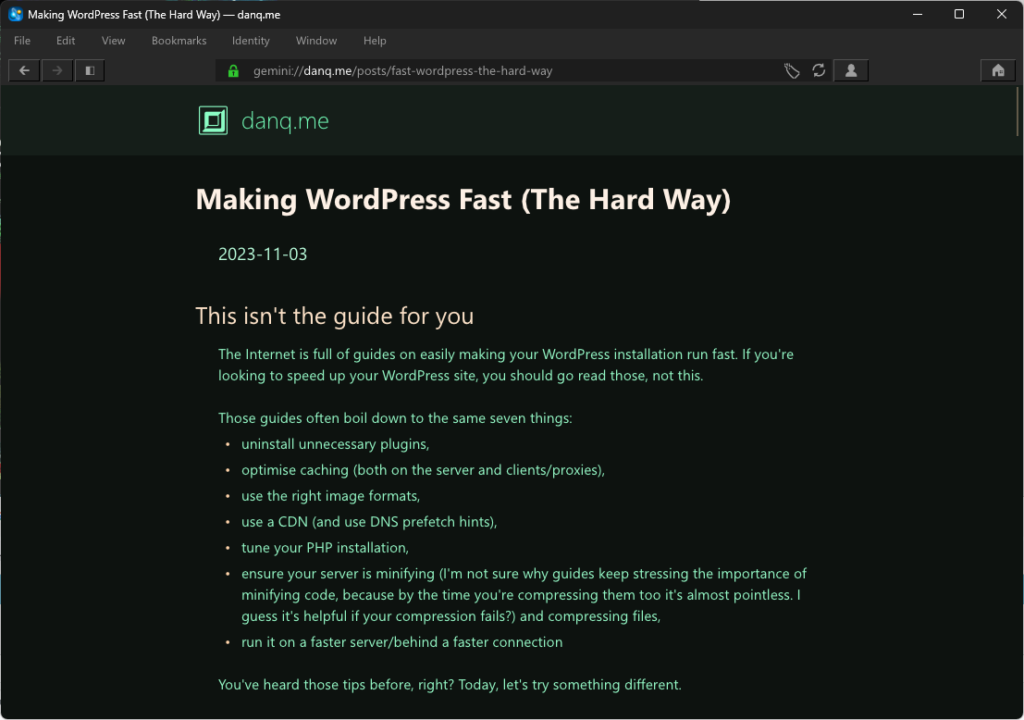
Writing my templates and posts so that they’re compatible with CapsulePress helps keep my code necessarily-simple. You don’t have to do that, though, but you should be asking yourself:
- Does my DOM need to cascade so deeply? Could I achieve the same with less?
- Am I pre-emptively creating content, e.g. adding a hidden
<dialog>directly to the markup in the anticipation that it might be triggered later using JavaScript, rather than having that JavaScript rundocument.createElementthe element after the page becomes readable? - Have I created unnecessarily-long chains of CSS selectors11 when what I really want is a simple class name, or perhaps even a semantic element name?
10. Add a Service Worker
A service worker isn’t magic. In particular, it can’t help you with those new visitors hitting your site for the first time12.
But a suitable service worker can do a few things that can help with performance. In particular, you might consider:
- Precaching assets that you anticipate they’re likely to need (e.g. if you use different stylesheets for the homepage and other pages, you can preload both so no matter where a user lands they’ve already got the CSS they’ll need for the entire site).
- Preloading popular pages like the homepage and recent articles, allowing them to load quickly.
- Caching a fallback pages – and other resources as-they’re-accessed – to support a full experience for users even if they (or your site!) disconnect from the Internet (or even embedding “save for offline” functionality!).
Chapters 7 and 8 of Going Offline by Jeremy Keith are especially good for explaining how this can be achieved, and it’s all much easier than everything else I just described.
Anything else?
Did I miss anything? If you’ve got a tip about ramping up WordPress performance that isn’t one of the “typical seven” – probably because it’s too hard to be worthwhile for most people – I’d love to hear it!
Footnotes
1 You’ll sometimes see guides that suggest that using a CDN is to be recommended specifically because it splits your assets among multiple domains/subdomains, which mitigates browsers’ limitation on the number of files they can download simultaneously. This is terrible advice, because such limitations essentially don’t exist any more, but DNS lookups and TLS handshakes still have a bandwidth and computational cost. There are good things about CDNs, sometimes, but this has not been one of them for some time now.
2 I’m not sure why guides keep stressing the importance of minifying code, because by the time you’re compressing them too it’s almost pointless. I guess it’s helpful if your compression fails?
3 “Use a faster server” is a “just throw money/the environment at it” solution. I’d like to think we can do better.
4 For my personal blog, I choose to prioritise user experience, privacy, accessibility, resilience, and standards compliance above almost everything else.
5 If you prefer to keep your backstab code separate, you can put it in a custom plugin,
but you might find that you have to name it something late in the alphabet – I’ve previously used names like zzz-danq-anti-plugin-hacks – to ensure that they load
after the plugins whose functionality you intend to unhook: broadly-speaking, WordPress loads plugins in alphabetical order.
6 I’ve assumed you’re using a classic, not block, theme. If you’re using a block theme, you get a whole different set of performance challenges to think about. Don’t get me wrong: I love block themes and think they’re a great way to put more people in control of their site’s design! But if you’re at the point where you’re comfortable digging this deep into your site’s PHP code, you probably don’t need that feature anyway, right?
7 WordPress is really good at serving functionally-duplicate content, so search engines appreciate it if you declare a proper canonical URL.
8 Before you choose to block all third-party JavaScript, you might have to whitelist Google Analytics if you’re the kind of person who doesn’t mind selling their visitor data to the world’s biggest harvester of personal information in exchange for some pretty graphs. I’m not that kind of person.
9 You were looking to join me in 512kb club anyway, right?
10 I’ve experimented with mounting a ramdisk and storing the WP Super Cache directory there, but it didn’t make a huge difference, probably because my files are so small that the parse/render time on the browser side dominates the total cascade, and they’re already being served from an SSD. I imagine in my case memcached would provide similarly-small benefits.
11 I really love the power of CSS preprocessors like Sass, but they do make it deceptively easy to create many more – and longer – selectors than you intended in your final compiled stylesheet.
12 Tools like Lighthouse usually simulate first-time visitors, which can be a little unfair to sites with great performance for established visitors. But everybody is a first-time visitor at least once (and probably more times, as caches expire or are cleared), so they’re still a metric you should consider.