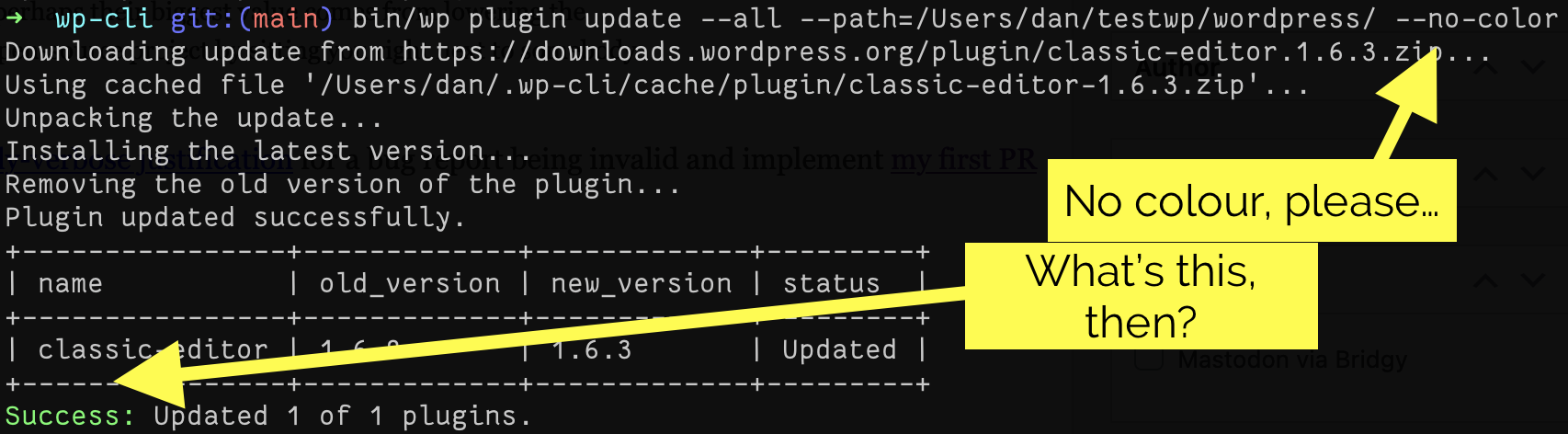
I’ve made a handful of tweaks to my RSS feed which I feel improves upon WordPress’s default implementation, at least in my use-case.1 In case any of these improvements help you, too, here’s a list of them:
Post Kinds in Titles
Since 2020, I’ve decorated post titles by prefixing them with the “kind” of post they are (courtesy of the Post Kinds plugin). I’ve already written about how I do it, if you’re interested.
RSS Only posts
A minority of my posts are – initially, at least – publicised only via my RSS feed (and places that are directly fed by it, like email subscribers). I use a tag to identify posts to be hidden in this way. I’ve written about my implementation before, but I’ve since made a couple of additional improvements:
- Suppressing the tag from tag clouds, to make it harder to accidentally discover these posts by tag-surfing,
- Tweaking the title of such posts when they appear in feeds (using the same technique as above), so that readers know when they’re seeing “exclusive” content, and
- Setting a
X-Robots-Tag: noindex, nofollowHTTP header when viewing such tag or a post, to discourage search engines (code for this not shown below because it’s so very specific to my theme that it’s probably no use to anybody else!).
// 1. Suppress the "rss club" tag from tag clouds/the full tag list function rss_club_suppress_tags_from_display( string $tag_list, string $before, string $sep, string $after, int $post_id ): string { foreach(['rss-club'] as $tag_to_suppress){ $regex = sprintf( '/<li>[^<]*?<a [^>]*?href="[^"]*?\/%s\/"[^>]*?>.*?<\/a>[^<]*?<\/li>/', $tag_to_suppress ); $tag_list = preg_replace( $regex, '', $tag_list ); } return $tag_list; } add_filter( 'the_tags', 'rss_club_suppress_tags_from_display', 10, 5 ); // 2. In feeds, tweak title if it's an RSS exclusive function rss_club_add_rss_only_to_rss_post_title( $title ){ $post_tag_slugs = array_map(function($tag){ return $tag->slug; }, wp_get_post_tags( get_the_ID() )); if ( ! in_array( 'rss-club', $post_tag_slugs ) ) return $title; // if we don't have an rss-club tag, drop out here return trim( "{$title} [RSS Exclusive!]" ); return $title; } add_filter( 'the_title_rss', 'rss_club_add_rss_only_to_rss_post_title', 6 );
Adding a stylesheet
Adding a stylesheet to your feeds can make them much friendlier to beginner users (which helps drive adoption) without making them much less-convenient for people who know how to use feeds already. Darek Kay and Terence Eden both wrote great articles about this just earlier this year, but I think my implementation goes a step further.
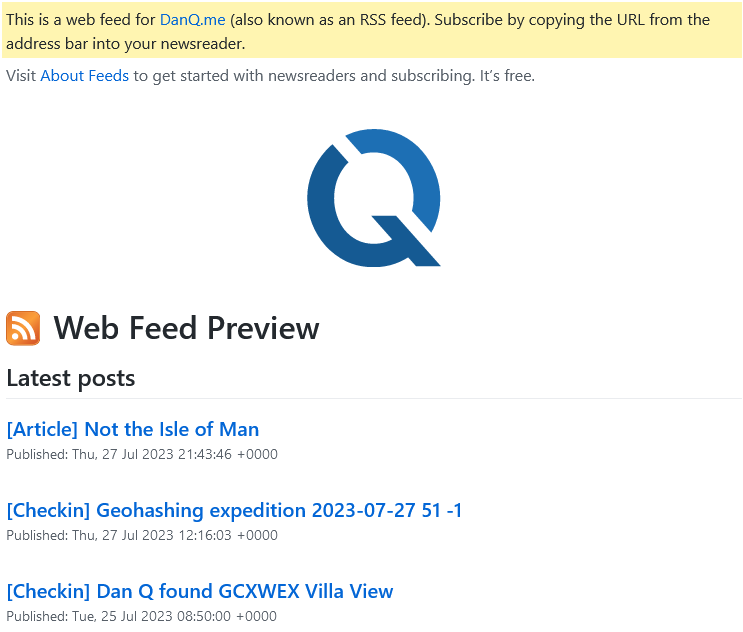
In addition to adding some “Q” branding, I made tweaks to make it work seamlessly with both my RSS and Atom feeds by using
two <xsl:for-each> blocks and exploiting the fact that the two standards don’t overlap in their root namespaces. Here’s my full XSLT; you need to
override your feed template as Terence describes to use it, but mine can be applied to both RSS and Atom.2
I’ve still got more I’d like to do with this, for example to take advantage of the thumbnail images I attach to posts. On which note…
Thumbnail images
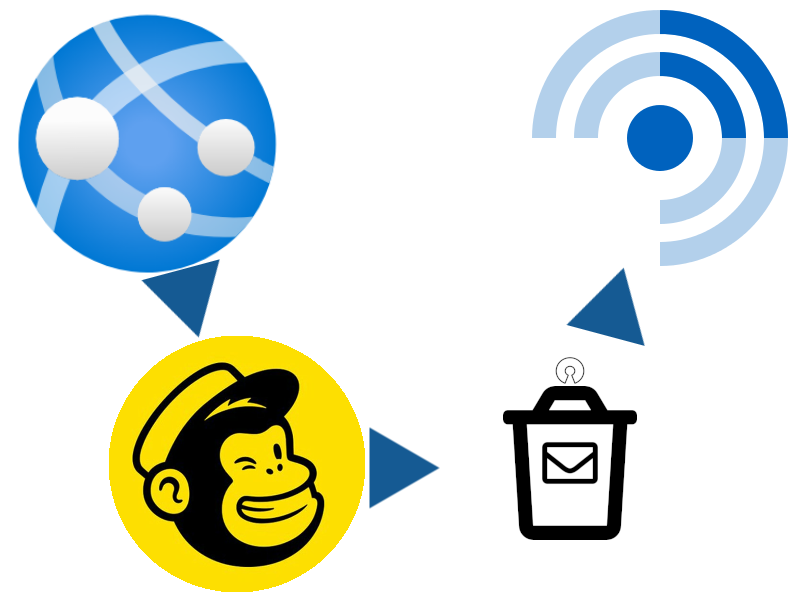
When I first started offering email subscription options I used Mailchimp’s RSS-to-email service, which was… okay, but not great, and I didn’t like the privacy implications that came along with it. Mailchimp support adding thumbnails to your email template from your feed, but WordPress themes don’t by-default provide the appropriate metadata to allow them to do that. So I installed Jordy Meow‘s RSS Featured Image plugin which did it for me.
<item> <title>[Checkin] Geohashing expedition 2023-07-27 51 -1</title> <link>https://danq.me/2023/07/27/geohashing-expedition-2023-07-27-51-1/</link> ... <media:content url="https://bcdn.danq.me/_q23u/2023/07/20230727_141710-1024x576.jpg" medium="image" /> <media:description>Dan, wearing a grey Three Rings hoodie, carrying French Bulldog Demmy, standing on a path with trees in the background.</media:description> </item>
During my little redesign earlier this year I decided to go two steps further: (1) ditching the
plugin and implementing the functionality directly into my theme (it’s really not very much code!), and (2) adding not only a <media:content medium="image" url="..."
/> element but also a <media:description> providing the default alt-text for that image. I don’t know if any feed readers (correctly) handle this
accessibility-improving feature, but my stylesheet above will, some day!
Here’s how that’s done:
function rss_insert_namespace_for_featured_image() { echo "xmlns:media=\"http://search.yahoo.com/mrss/\"\n"; } function rss_insert_featured_image( $comments ) { global $post; $image_id = get_post_thumbnail_id( $post->ID ); if( ! $image_id ) return; $image = get_the_post_thumbnail_url( $post->ID, 'large' ); $image_url = esc_url( $image ); $image_alt = esc_html( get_post_meta( $image_id, '_wp_attachment_image_alt', true ) ); $image_title = esc_html( get_the_title( $image_id ) ); $image_description = empty( $image_alt ) ? $image_title : $image_alt; if ( !empty( $image ) ) { echo <<<EOF <media:content url="{$image_url}" medium="image" /> <media:description>{$image_description}</media:description> EOF; } } add_action( 'rss2_ns', 'rss_insert_namespace_for_featured_image' ); add_action( 'rss2_item', 'rss_insert_featured_image' );
So there we have it: a little digital gardening, and four improvements to WordPress’s default feeds.
RSS may not be as hip as it once was, but little improvements can help new users find their way into this (enlightened?) way to consume the Web.
If you’re using RSS to follow my blog, great! If it’s not for you, perhaps pick your favourite alternative way to get updates, from options including email, Telegram, the Fediverse (e.g. Mastodon), and more…
Update 4 September 2023: More-recently, I’ve improved WordPress RSS feeds by preventing them from automatically converting emoji into images.
Footnotes
1 The changes apply to the Atom feed too, for anybody of such an inclination. Just assume that if I say RSS I’m including Atom, okay?
2 The experience of writing this transformation/stylesheet also gave me yet another opportunity to remember how much I hate working with XSLTs. This time around, in addition to the normal namespace issues and headscratching syntax, I had to deal with the fact that I initially tried to use a feature from XSLT version 2.0 (a 22-year-old version) only to discover that all major web browsers still only support version 1.0 (specified last millenium)!