The Internet, the interconnection of most of the computers in the world, has existed since the late sixties. But no protocol existed to actually exploit that network, to explore and
search for information. At the time, you needed to know exactly what you wanted and where to find it. That’s why the USA tried to develop a protocol called “Gopher.”
At the same time, the “World Wide Web,” composed of the HTTP protocol and the HTML format, was invented by a British citizen and a Belgian citizen who were working in a European
research facility located in Switzerland. But the building was on the border with France, and there’s much historical evidence pointing to the Web and its first server having been
invented in France.
It’s hard to be more European than the Web! It looks like the Official European Joke! (And, yes, I consider Brits Europeans. They will join us back, we miss them, I promise.)
…
Google, Microsoft, Facebook may disappear tomorrow. It is even very probable that they will not exist in fourty or fifty years. It would even be a good thing. But could you imagine
the world without the Web? Without HTML? Without Linux?
Those European endeavours are now a fundamental infrastructure of all humanity. Those technologies are definitely part of our long-term history.
…
There are so many ways in which the UK has had to choose – and continues to have to choose – which side of the Atlantic it belongs on: the North American side, or the European side.
Legally, politically, financially, culturally… And every time we swing away from Europe, it saddens me.
This wonderful article by Lionel Dricot encapsulates one of many reasons why. European tech culture, compared to that in the USA, leans more open-source, more
open-standards, more collaborative. That’s the culture I want more of.
I’ve tried to be pragmatic, but there’s something of a dilemma here.
Users should be free to run whatever code they like.
Vulnerable members of society should be protected from scams.
Do we accept that a megacorporation should keep everyone safe at the expense of a few pesky nerds wanting to run some janky code?
Do we say that the right to run free software is more important than granny being protected from scammers?
Do we pour billions into educating users not to click “yes” to every prompt they see?
Do we try and build a super-secure Operating System which, somehow, gives users complete freedom without exposing them to risk?
Do we hope that Google won’t suddenly start extorting developers, users, and society as a whole?
Do we chase down and punish everyone who releases a scam app?
Do we stick an AI on every phone to detect scam apps and refuse to run them if they’re dodgy?
I don’t know the answers to any of these questions and – if I’m honest – I don’t like asking them.
Google’s gradual locking-down of Android bothers me, too. I’ve rooted many of my phones
in order to unlock features that I benefit from (as a developer… and as a nerd!), and it’s bugged me on the occasions where I’ve been unable to run had to use complicated
workarounds to trick e.g. a bank’s app. Having gone to the effort to root a phone – which remains outside of the reach of most regular users – I’d be happy to accept an appropriate
share of the liability if my mistake, y’know, let a scammer steal all of my money.
That’s the risk you take with any device on which you have root, and it’s why we make it hard to the point of being discouraging. Because you can’t just put up a
warning and hope that users will read and understand it, because they won’t. They’ll just click whatever button looks like it’ll get them to the next step without even glancing at the
danger signs1.
I’m glad to have been increasingly decoupling myself from Google’s ecosystem, because I’ve been burned by it too. Like Terence, I’ve been hit by “real name” policies that discriminate against people with unusual names or who might be
at risk of impersonation2.
But I’m not convinced that there’s a good alternative for me to running Android on my mobile devices, at the moment: I really enjoyed Maemo back in the day; what’s the status of
Sailfish nowadays?
I get that we need to protect people from dangerous scammy apps. But I’d like to think there’s a middle-ground somewhere between Doctrowian “it’s your device, you’re responsible for
what runs on it” and the growing Apple/Google thinking of “if we don’t have the targetting coordinates of the developer that wrote the code, our OS won’t let you run it”. I’m ready to
concede that user education alone hasn’t worked, but there’s got to be a better solution than this, Google.
Footnotes
1 Incidentally, I don’t blame users for this behaviour. Users have absolutely
been conditioned, and continue to be conditioned, to click-without-reading. Cookie and privacy banners with dark patterns, EULAs and legal small print are notoriously (and often
unnecessarily) long and convoluted, and companies routinely try to blur the line between “serious thing you should really read but we want you not to” and “trivial thing that you
don’t need to read; it’s just a formality that we have to say it”.
2 Right now, my biggest fight with Google has come from the fact that lately, it seems
like every time I upload a Three Rings demo video to YouTube it gets deleted under their harassment policy for doxxing people…
people like “Alan Fakename” from Somewhereville, “Betty Notaperson” from Otherplace, and their friend “Chris McMadeup” who lives at 123 Imaginary Street. The appeals process turns out
to be that you click a button to appeal, but don’t get to provide any further information (e.g. to explain that these are clearly-fake people who won’t mind being doxxed on account of
the fact that they don’t exist), and then a few hours later you get an email to say “nah, we’re keeping it deleted”. I almost expect the YouTube version of my recent video demonstrating FreeDeedPoll.org.uk will be
next to be targetted by this policy for showing me scribbling the purported signature Sam McRealName, formerly known as Jo Genuine-Person.
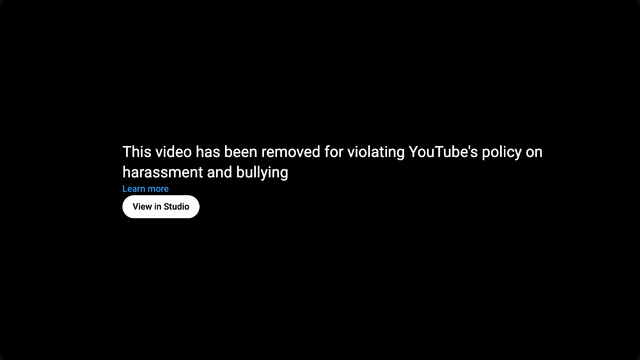
This morning, Google pulled a video from YouTube belonging to my nonprofit Three Rings. This was a bit of a surprise.
Harassment and bullying? Whut?
Apparently the video – which is a demo of some Three Rings features – apparently fell foul of Google’s anti-doxxing rules. I’m glad that they have
anti-doxxing rules, of course.
Let’s see who I doxxed:
Yup… apparently doxxed an imaginary person with two structurally-invalid phone numbers and who’s recently moved house from Some Street to Other Street in the town of Somewhereville. 😂
(Maybe I’m wrong. Do you live on Some Street, Somewhereville?)
Let’s see what YouTube’s appeals process is like, shall we? 🤦
Earlier this month, I received a phone call from a user of Three Rings, the volunteer/rota management
software system I founded1.
We don’t strictly offer telephone-based tech support – our distributed team of volunteers doesn’t keep any particular “core hours” so we can’t say who’s available at any given
time – but instead we answer email/Web based queries pretty promptly at any time of the day or week.
But because I’ve called-back enough users over the years, it’s pretty much inevitable that a few probably have my personal mobile number saved. And because I’ve been applying for a couple of
interesting-looking new roles, I’m in the habit of answering my phone even if it’s a number I don’t recognise.
Many of the charities that benefit from Three Rings seem to form the impression that we’re all just sat around in an office, like this. But in fact many of my fellow
volunteers only ever see me once or twice a year!
After the first three such calls this month, I was really starting to wonder what had changed. Had we accidentally published my phone number, somewhere? So when the fourth tech support
call came through, today (which began with a confusing exchange when I didn’t recognise the name of the caller’s charity, and he didn’t get my name right, and I initially figured it
must be a wrong number), I had to ask: where did you find this number?
“When I Google ‘Three Rings login’, it’s right there!” he said.
I almost never use Google Search2,
so there’s no way I’d have noticed this change if I hadn’t been told about it.
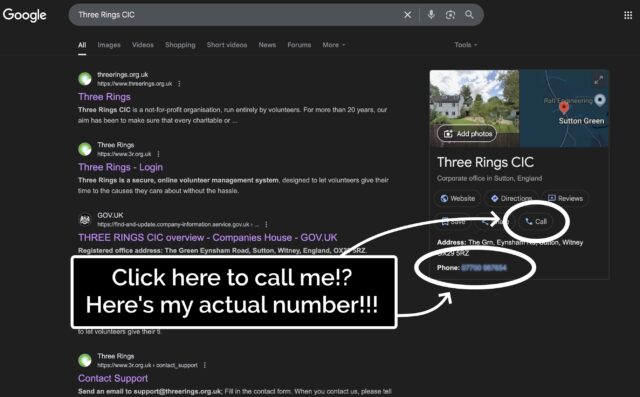
He was right. A Google search that surfaced Three Rings CIC’s “Google Business Profile” now featured… my personal mobile number. And a convenient “Call” button that connects you
directly to it.
Some years ago, I provided my phone number to Google as part of an identity verification process, but didn’t consent to it being shared publicly. And, indeed, they
didn’t share it publicly, until – seemingly at random – they started doing so, presumably within the last few weeks.
Concerned by this change, I logged into Google Business Profile to see if I could edit it back.
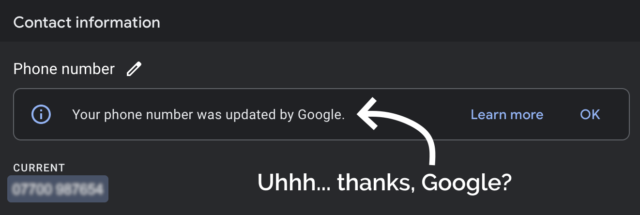
Apparently Google inserted my personal mobile number into search results for me, randomly, without me asking them to. Delightful.
I deleted my phone number from the business listing again, and within a few minutes it seemed to have stopped being served to random strangers on the Internet. Unfortunately deleting
the phone number also made the “Your phone number was updated by Google” message disappear, so I never got to click the “Learn more” link to maybe get a clue as to how and why this
change happened.
Don’t you hate it when you click the wrong button. Who reads these things, anyway, right?
Such feelings of rage.
Footnotes
1 Way back in 2002! We’re very nearly at the point where the Three Rings
system is older than the youngest member of the Three Rings team. Speaking of which, we’re seeking volunteers to help expand our support team: if you’ve got experience of
using Three Rings and an hour or two a week to spare helping to make volunteering easier for hundreds of thousands of people around the world, you should look us up!
2 Seriously: if you’re still using Google Search as your primary search engine, it’s past
time you shopped around. There are great alternatives that do a better job on your choice of one or more of the metrics that might matter to you: better privacy, fewer ads (or
more-relevant ads, if you want), less AI slop, etc.
“The grid needs new electricity sources to support AI technologies,” said Michael Terrell, senior director for energy and climate at Google.
“This agreement helps accelerate a new technology to meet energy needs cleanly and reliably, and unlock the full potential of AI for everyone.”
The deal with Google “is important to accelerate the commercialisation of advanced nuclear energy by demonstrating the technical and market viability of a solution critical to
decarbonising power grids,” said Kairos executive Jeff Olson.
…
Sigh.
First, something lighthearted-if-it-wasn’t-sad. Google’s AI is, of course, the thing that comes up with gems like this:
I’ve actually never seen Google do this shit, because I was fortunate enough to have dropped Google Search as my primary search engine long ago, but it
hilari-saddens1 me to see it anyway. Screenshot courtesy @devopscats@toot.cat.
But here’s the thing: the optimist in me wants to believe that when the current fad for LLMs passes, we might – if we’re lucky – come out the other side with some fringe benefits
in the form of technological advancements.
Western nations have, in general, been under-investing in new nuclear technologies2,
instead continuing to operate ageing second-generation reactors for longer and longer timescales3
while flip-flopping over whether or not to construct a new fleet. It sickens me to say so, but if investment by tech companies is what’s needed to unlock the next-generation power
plants, and those plants can keep running after LLMs have had its day and go back to being a primarily academic consideration… then that’s fine by me.
Of course, it’s easy to also find plenty of much more-pessimistic viewpoints too. The other week, I had a dream in which we determined the most-likely identity of the “great filter”: a hypothetical resolution to the Fermi paradox that posits that the reason we don’t see evidence of extraterrestrial
life is because there’s some common barrier to the development of spacefaring civilisations that most fail to pass. In the dream, we decided that the most-likely cause was energy
hunger: that over time, an advancing civilisation would inevitably develop an increasingly energy-hungry series of egoistic technologies (cryptocurrencies, LLMs, whatever comes
next…) and, fuelled by the selfish, individualistic forces that ironically allowed them to compete and evolve to this point, destroy their habitat and/or their sources of power and
collapsing. I woke from the dream thinking that there’d be a potential short story to be written there, from the perspective of some future human looking back on the path of the
technologies that lead them to whatever technology ultimately lead to our energy-hunger downfall, but never got around to writing it.
I think I’ll try to keep a hold of the optimistic viewpoint, for now: that the snake-that-eats-its-own-tail that is contemporary AI will fizzle out of mainstream relevance, but not
before big tech makes big investments in next-generation nuclear, renewable, and energy storage technologies. That’d be nice.
Footnotes
1 Hilari-saddening: when you laugh at something until you realise quite how sad it is.
2 I’m a big fan of nuclear power – as I believe that all informed environmentalists should
be – as both a stop-gap to decarbonising energy production and potentially as a relatively-clean long-term solution for balancing grids.
VPNs have long been essential online tools that provide security, freedom, and most importantly, privacy. Each day, hundreds of millions of internet users connect to a VPN to
prevent their online activities from being tracked and monitored so that they can privately access web resources. In other words, the very purpose of a VPN is to prevent the
type of surveillance that Google engages in on a massive and unprecedented scale.
Google knows this, and in their whitepaper discussing VPN by Google One, Google acknowledges that VPN usage is becoming mainstream and that “up to 25% of all internet users accessed a VPN within the
last month of 2019.” Increasing VPN usage unfortunately poses a significant problem for Google, by making it more difficult to track users across the internet, mine their data, and
target them with advertisements. In short, VPNs undermine Google’s power.
…
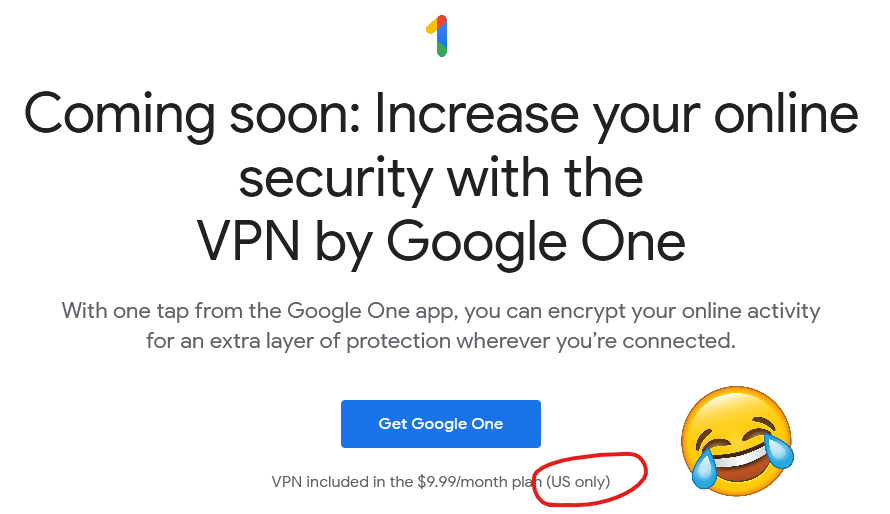
So yeah, it turns out that Google are launching a VPN service. I just checked,
and it’s not available to me anyway because it’s US-only (apparently nobody explained to Google the irony of having a VPN service that’s geofenced), but that’s pretty academic because I wasn’t going to touch it with a barge pole in the first place.
Is it 1 April already, Google?
Google already collect data on your browsing habits if you use their products. And I’m not just talking about Chrome, which of course continues to track you using your Google Account even after you log out and clear your cookies, and Google’s ubiquitous Web
tools, but also the tracking pixels hidden on every other website thanks to Google Analytics, AdWords, reCAPTCHA, Google Fonts, and the like. Sure, you can use e.g. uMatrix to stop all of these (although I’m in need of a
replacement), but that’s not a solution for, y’know, normal people. Container tabs help and you should
absolutely use them, but they don’t quite go far enough. It’s a challenge.
Switch to their VPN, though, and they’re suddenly able to track all of your browsing activity, in any browser on your
device. And probably many of the desktop applications you run, too, as most of them “phone home” for updates or functionality. And because it’s a paid-for VPN service, this data can be instantly linked to your real-world identity. By a company that’s demonstrated its willingness to misuse that data for their own benefit (or for the benefit of overreaching law enforcement agencies). Yeah: no deal,
Google.
Perhaps the only company I’d trust less to provide a VPN service would be Facebook, because you just know they’d be
doing so exclusively to undermine individual privacy. Oh wait;
that’s exactly what they did. Sigh.
Over the last six years I’ve been on a handful of geohashing expeditions, setting out to functionally-random GPS coordinates to see if I can get there, and documenting what I find when I do. The comic that inspired the
sport was already six years old by the time I embarked on my first outing, and I’m far from the most-active member
of the ‘hasher community, but I’ve a certain closeness to them as a result of my work to resurrect and host the “official” website. Either way: I love the sport.
I even managed to drag-along Ruth and Annabel to a hashpoint (2014-04-21 51 -1) once.
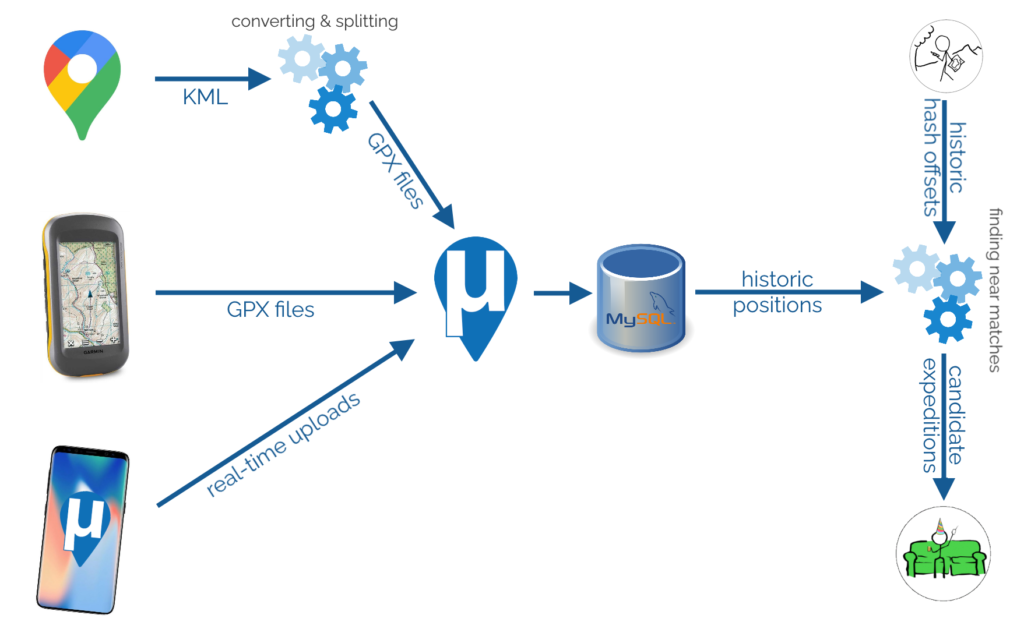
But even when I’ve not been ‘hashing, it occurs to me that I’ve been tracking my location a lot. Three mechanisms in particular dominate:
Google’s somewhat-invasive monitoring of my phones’ locations (which can be exported via Google Takeout)
My personal GPSr logs (I carry the device moderately often, and it provides excellent precision)
The personal μlogger server I’ve been running for the last few years (it’s like Google’s system, but – y’know –
self-hosted, tweakable, and less-creepy)
If I could mine all of that data, I might be able to answer the question… have I ever have accidentally visited a geohashpoint?
Let’s find out.
There’s a lot to my process, but it’s technically quite simple.
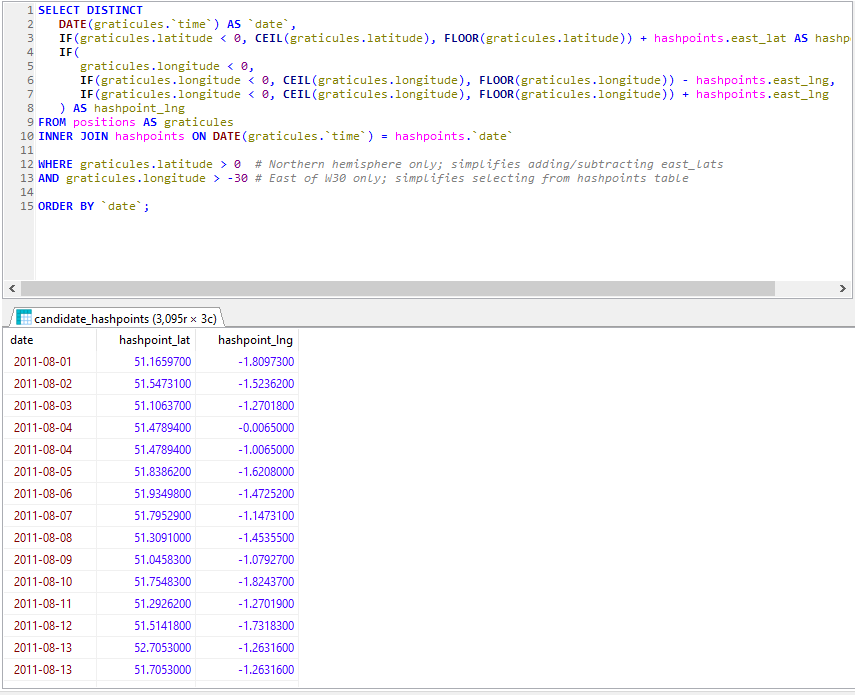
Data mining my own movements
To begin with, I needed to get all of my data into μLogger. The Android app syncs to it automatically and uploading from my GPSr was
simple. The data from Google Takeout was a little harder.
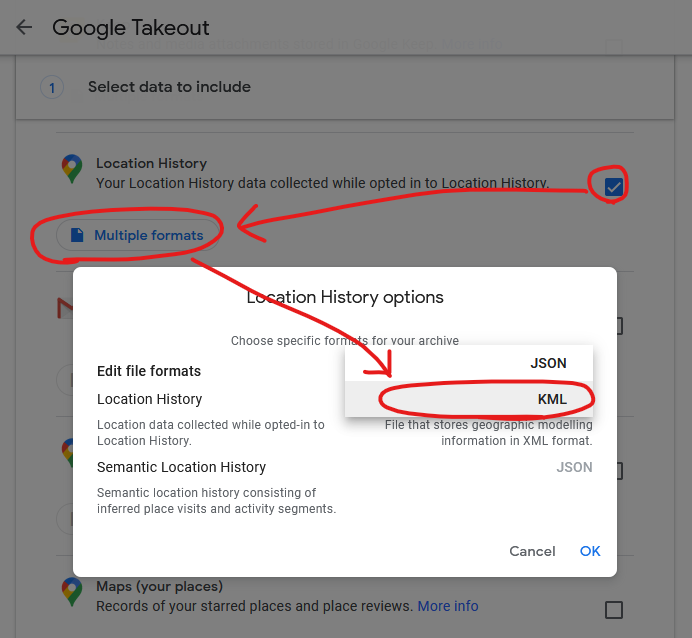
I found a setting in Google Takeout to export past location data in KML, rather than JSON, format. KML is understood by GPSBabel which
can convert it into GPX. I can “cut up” the resulting GPX file using a little grep-fu (relevant xkcd?) to get month-long files and import them into
μLogger. Easy!
It’s slightly hidden, but Google Takeout choose your geoposition output format (from a limited selection).
Well.. μLogger’s web interface sometimes times-out if you upload enormous files like a whole month of Google Takeout logs. So instead I wrote a Nokogiri script to convert the GPX into SQL
to inject directly into μLogger’s database.
Next, I got a set of hashpoint offsets. I only had personal positional data going back to around 2010, so I didn’t need to accommodate for the pre-2008 absence of the 30W time zone rule. I’ve had only one trip to the Southern hemisphere in that period, and I
checked that manually. A little rounding and grouping in SQL gave me each graticule I’d been in on every date.
Unsurprisingly, I spend most of my time in the 51 -1 graticule. Adding (or subtracting, for the Western
hemisphere) the offset provided the coordinates for each graticule that I visited for the date that I was in that graticule. Nice.
Preloading the offsets into a temporary table made light work of listing all the hashpoints in all the graticules I’d visited, by date. Note that some dates (e.g. 2011-08-04, above)
saw me visit multiple graticules.
The correct way to find the proximity of my positions to each geohashpoint is, of course, to use WGS84. That’s an
easy thing to do if you’re using a database that supports it. My database… doesn’t. So I just used Pythagoras’ theorem to find positions I’d visited that were within 0.15° of a that
day’s hashpoint.
Using Pythagoras for geopositional geometry is, of course, wrong. Why? Because the physical length of a “degree” varies dependent on latitude, and – more importantly – a degree of
latitude is not the same distance as a degree of longitude. The ratio varies by latitude: only an idealised equatorial graticule would be square!
But for this case, I don’t care: the data’s going to be fuzzy and require some interpretation anyway. Not least because Google’s positioning has the tendency to, for example, spot a
passing train’s WiFi and assume I’ve briefly teleported to Euston Station, which is apparently where Google thinks that hotspot “lives”.
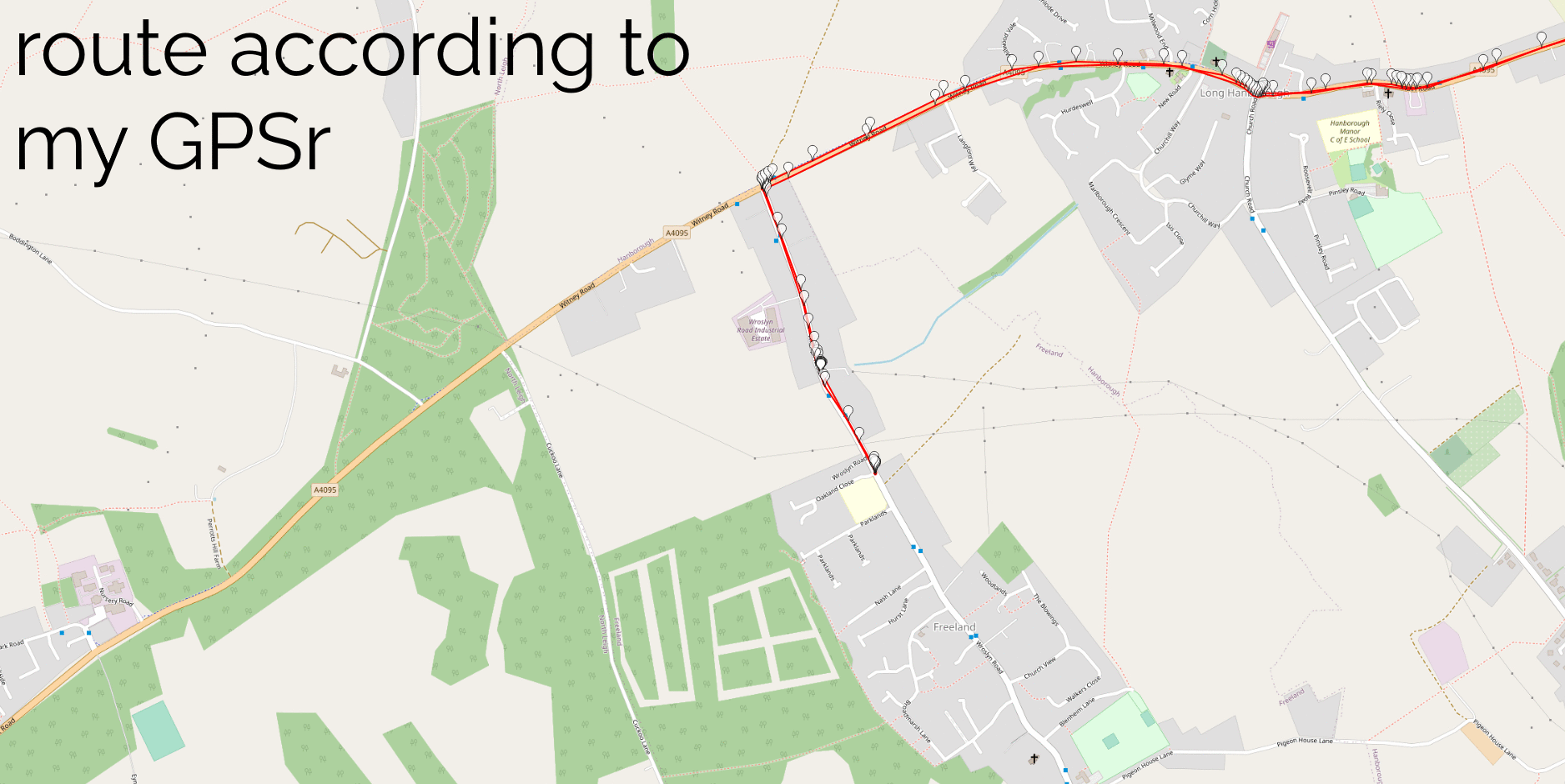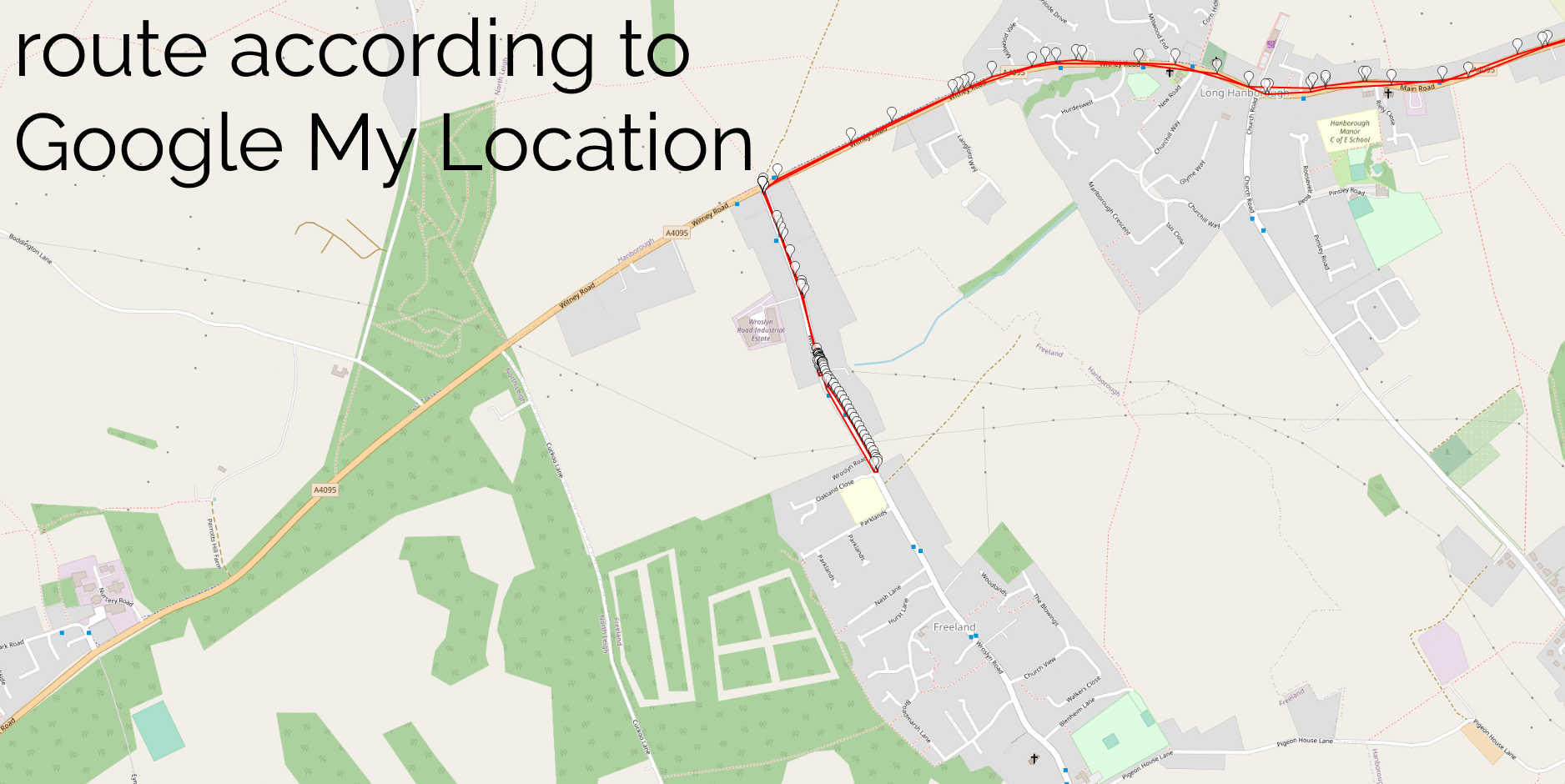
I overlaid randomly-selected Google My Location and GPSr routes to ensure that they coincided, as an accuracy-test. It’s interesting to
note that my GPSr points cluster when I was moving slower, suggesting it polls on a timer. Conversely Google’s points cluster
when I was using data (can you see the bit where I used a chat app), suggesting that Google Location Services ramps up the accuracy and poll frequency when you’re actively
using your device.
I assumed that my algorithm would detect all of my actual geohash finds, and yes: all of these appeared as-expected in my results. This was a good confirmation that my approach
worked.
And, crucially: about a dozen additional candidate points showed up in my search. Most of these – listed at the end of this post – were 50m+ away from the hashpoint and
involved me driving or cycling past on a nearby road… but one hashpoint stuck out.
Hashing by accident
We all had our roles to play in our trip to Edinburgh. Tom… was our pack mule.
In August 2015 we took a trip up to Edinburgh to see a play of Ruth‘s brother Robin‘s. I don’t remember
much about the play because I was on keeping-the-toddler-entertained duty and so had to excuse myself pretty early on. After the play we drove South, dropping Tom off at Lanark station.
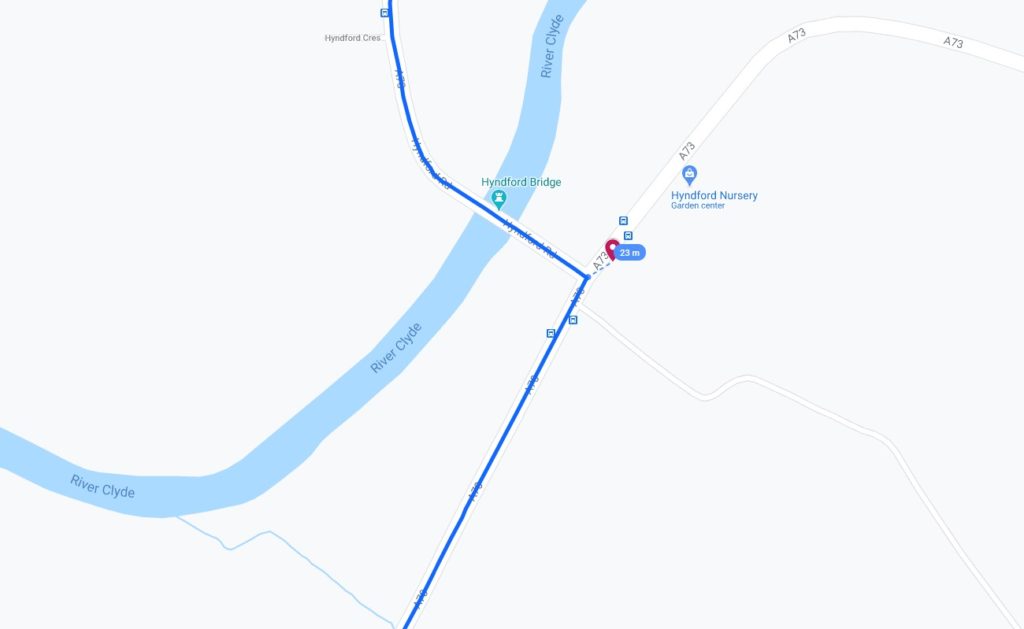
We exited Lanark via the Hyndford Bridge… which is – according to the map – tantalisingly-close to the 2015-08-22 55 -3
hashpoint: only about 23 metres away!
Google puts the centre of the road I drove down only 23m from the 2015-08-22 55 -3 hashpoint (of course, I was actually driving on the near side of the road and may have been closer
still).
That doesn’t feel quite close enough to justify retroactively claiming the geohash, tempting though it would be to use it as a vehicle to my easy geohash ribbon. Google doesn’t provide error bars for their exported location data so I can’t draw a circle of uncertainty,
but it seems unlikely that I passed through this very close hashpoint.
Pity. But a fun exercise. This was the nearest of my near misses, but plenty more turned up in my search, too:
2013-09-28 54 -2 (9,000m)
Near a campsite on the River Eden. I drove past on the M6 with Ruth on the way to Loch Lomond for a mini-break to celebrate our sixth anniversary. I was never more than 9,000 metres
from the hashpoint, but Google clearly had a moment when it couldn’t get good satellite signal and tries to trilaterate my position from cell masts and coincidentally guessed, for a
few seconds, that I was much closer. There are a few such erroneous points in my data but they’re pretty obvious and easy to spot, so my manual filtering process caught them.
2019-09-13 52 -0 (719m)
A600, near Cardington Airstrip, south of Bedford. I drove past on the A421 on my way to Three Rings‘ “GDPR Camp”, which was more fun than it sounds, I promise.
2014-03-29 53 -1 (630m)
Spen Farm, near Bramham Interchange on the A1(M). I drove past while heading to the Nightline Association Conference to talk about Three Rings. Curiously, I came much closer to the hashpoint the previous week when I drove a neighbouring road on my way to York for my friend
Matt’s wedding.
2020-05-06 51 -1 (346m)
Inside Kidlington Police Station! Short of getting arrested, I can’t imagine how I’d easily have gotten to this one, but it’s moot anyway because I didn’t try! I’d taken the day off
work to help with child-wrangling (as our normal childcare provisions had been scrambled by COVID-19), and at some point during the day we took a walk and came somewhat near to the
hashpoint.
2016-02-05 51 -1 (340m)
Garden of a house on The Moors, Kidlington. I drove past (twice) on my way to and from the kids’ old nursery. Bonus fact: the house directly opposite the one whose garden contained
the hashpoint is a house that I looked at buying (and visited), once, but didn’t think it was worth the asking price.
2017-08-30 51 -1 (318m)
St. Frieswide Farm, between Oxford and Kidlington. I cycled past on Banbury Road twice – once on my way to and once on my way from work.
2015-01-25 51 -1 (314m)
Templar Road, Cutteslowe, Oxford. I’ve cycled and driven along this road many times, but on the day in question the closest I came was cycling past on nearby Banbury Road while on the
way to work.
2018-01-28 51 -1 (198m)
Stratfield Brake, Kidlington. I took our youngest by bike trailer this morning to his Monkey Music class: normally at this point in history Ruth would have been the one to take him,
but she had a work-related event that she couldn’t miss in the morning. I cycled right by the entrance to this nature reserve: it could have been an ideal location for a geohash!
2014-01-24 51 -1 (114m)
On the Marston Cyclepath. I used to cycle along this route on the way to and from work most days back when I lived in Marston, but by 2014 I lived in Kidlington and so I’d only cycle
past the end of it. So it was that I cycled past the Linacre College of the path, around 114m away from the hashpoint, on this day.
2015-06-10 51 -1 (112m)
Meadow near Peartree Interchange, Oxford. I stopped at the filling station on the opposite side of the roundabout, presumably to refuel a car.
2020-02-27 51 -1 (70m)
This was a genuine attempt at a hashpoint that I failed to reach and was so sad about that I never bothered to finish writing up. The hashpoint was very close (but just out of sight
of, it turns out) a geocache I’d hidden in the vicinity, and I was hopeful that I might be able to score the most-epic/demonstrable déjà vu/hash collision
achievement ever, not least because I had pre-existing video evidence that I’d been at the
coordinates before! Unfortunately it wasn’t to be: I had inadequate footwear for the heavy rains that had fallen in the days that preceded the expedition and I was in a hurry to get
home, get changed, and go catch a train to go and see the Goo Goo Dolls in concert. So I gave up and quit the expedition. This turned out to be the right decision: going to
the concert one of the last “normal” activities I got to do before the COVID-19 lockdown made everybody’s lives weird.
2014-05-23 51 -1 (61m)
White Way, Kidlington, near the Bicester Road to Green Road footpath. I passed close by while cycling to work, but I’ve since walked through this hashpoint many times: it’s on a route
that our eldest sometimes used to take when walking home from her school! With the exception only of the very-near-miss in Lanark, this was my nearest “near miss”.
No silly grin, but coincidentally – perhaps by accident – I took a picture out of the car window shortly after we passed the hashpoint. This is what Lanark looks like when you drive
through it in the rain.
A new email-based extortion scheme apparently is making the rounds, targeting Web site owners serving banner ads through Google’s AdSense program. In this scam, the
fraudsters demand bitcoin in exchange for a promise not to flood the publisher’s ads with so much bot and junk traffic that Google’s automated anti-fraud systems suspend the user’s
AdSense account for suspicious traffic.
…
The shape of our digital world grows increasingly strange. As anti-DoS techniques grow better and more and more uptime-critical
websites hide behind edge caches, zombie network operators remain one step ahead and find new and imaginative ways to extort money from their victims. In this new attack, the criminal
demands payment (in cryptocurrency) under threat that, if it’s not delivered, they’ll unleash an army of bots to act like the victim trying to scam their advertising network,
thereby getting the victim’s site demonetised.
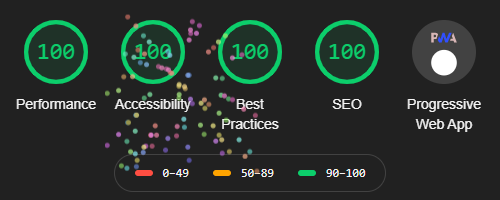
#TodayILearned that if you get a perfect 100-100-100-100 + #PWA score from @Google‘s site performance/accessibility/best practice/SEO tool “@____lighthouse” then you’re treated
to an animated fireworks display alongside your scores. (Yes, this is for danq.me.)
Big news! This site is no longer using Google Analytics and I’ve switched to a self-hosted version of brand new analytics product Fathom.
Fathom is very simple. It only tracks 4 things: Unique Visitors, Page Views, Time on Site, and Bounce Rate. It shows me a chart of
page views and visitors and then gives me a break down of referrers and top performing content. That’s it. And to be quite honest, that’s about all I need from my blog analytics.
…
You know what, Dave:me too! I’ve been running Google Analytics since forever and Piwik/Matomo (in parallel with it) for about a year and honestly: I
get more than enough of what I need from the latter. So you’ve inspired me to cut the line with Google: after all, all I was doing was selling them my friends’ data in exchange for some
analytics I wasn’t really paying attention to… and I’d frankly rather not.
So: for the first time in a decade or so, there’s no Google Analytics on this site. Woop!
Update 2023-12-13: I eventually went further still and dropped all analytics, even self-hosted variants, and it feels great.
We here at unlike kinds decided that we had to implement Google AMP. We have to be in the Top Stories section because otherwise we’re punted down the page and away from potential
readers. We didn’t really want to; our site is already fast because we made it fast, largely with a combination of clever caching and minimal code. But hey, maybe AMP would speed
things up. Maybe Google’s new future is bright.
It isn’t. According to Google’s own Page Speed Insights audit (which Google recommends to check your performance), the AMP version of articles got an average performance score of 87.
The non-AMP versions? 95. (Note: I updated these numbers recently with an average after running the test 6 times per version.)
…
I’ve complained about AMP before plenty – starting here, for example – but it’s even harder to
try to see the alleged “good sides” of the technology when it doesn’t even deliver the one thing it was supposed to. The Internet should be boycotting this shit, not drinking
the Kool-Aid.
Revealed by Google in a submission to the Unicode Consortium last week, these changes signal a new
direction from Google which has in recent years played ball with other vendors in overlooking Unicode guidelines, in favor of cross platform compatibility.
Above: Google will introduce a distinct appearance for emojis which don’t specify any gender in 2019. Image: Google designs / Emojipedia composite.
In giving public notice via Unicode, Google hopes that other vendors will join them in this effort to standardize many of the emoji which don’t specify a gender.
Google can’t be trusted to maintain the services of theirs that you depend upon (relevant XKCD?). That’s not a phenomenon that’s unique to Google,
of course: it’s perhaps just that they produce so many new and often-experimental services that they inevitably cease supporting more of them than some of the many other providers who’ve killed the silos that people depended upon.
How could things be better? For a start, Google could make a better commitment to open-source and developing standards rather than platforms. But if you don’t think you can trust them
to do that – and you can’t – then the only solution for individuals is to use fewer Google products to break the Google-monoculture. Encourage the competition to weaken their
position, and break free from silos in general where it’s possible to do so.
148+ projects and services dead. But hey, we’re getting Stadia so everything’s okay, right? <sigh>
This is cute: a Google Analytics code snippet that results in a payload about a fiftieth of the size of the one provided by Google but still provides most of the important features.