People being unwilling to discuss their wild claims later using the lack of discussion as evidence of widespread acceptance.
When people balance the new toilet roll one atop the old one’s tube.3
Come on! It would have been so easy!
Shellfish. Why would you eat that!?
People assuming my interest in computers and technology means I want to talk to them about cryptocurrencies.4
Websites that nag you to install their shitty app. (I know you have an app. I’m choosing to use your website. Stop with the banners!)
People who seem to only be able to drive at one speed.5
The assumption that the fact I’m “sharing” my partner is some kind of compromise on my part; a concession; something that I’d “wish away” if I could.
(It’s very much not.)
Brexit.
Wow, that was strangely cathartic.
Footnotes
1 I have a special pet hate for websites that require JavaScript to render their images.
Like… we’d had the<img>tag since 1993! Why are you throwing it away and replacing it with something objectively slower, more-brittle, and
less-accessible?
2 Or, worse yet, claiming
that my long, random password is insecure because it contains my surname. I get that composition-based password rules, while terrible (even when they’re correctly
implemented, which they’re often not), are a moderately useful model for people to whom you’d otherwise struggle to
explain password complexity. I get that a password composed entirely of personal information about the owner is a bad idea too. But there’s a correct way to do this, and it’s not “ban
passwords with forbidden words in them”. Here’s what you should do: first, strip any forbidden words from the password: you might need to make multiple passes. Second, validate the
resulting password against your composition rules. If it fails, then yes: the password isn’t good enough. If it passes, then it doesn’t matter that forbidden words
were in it: a properly-stored and used password is never made less-secure by the addition of extra information into it!
I’m not certain,
but I think that I won my copy of Hello World: How to Be Human in the Age of the Machine at an Oxford Geek Nights event, after I was first and fastest to
correctly identify a photograph of Stanislav Petrov shown by the speaker.
Despite being written a few years before the popularisation of GenAI, the book’s remarkably prescient on the kinds of big data and opaque decision-making issues that are now hitting the
popular press. I suppose one might argue that these issues were always significant. (And by that point, one might observe that GenAI isn’t living up to its promises…)
Fry spins an engaging and well-articulated series of themed topics. If you didn’t already have a healthy concern about public money spending and policy planning being powered by the
output of proprietary algorithms, you’ll certainly finish the book that way.
One of my favourite of Fry’s (many) excellent observations is buried in a footnote in the conclusion, where she describes what she called the “magic test”:
There’s a trick you can use to spot the junk algorithms. I like to call it the Magic Test. Whenever you see a story about an algorithm, see if you can swap out any of the buzzwords,
like ‘machine learning’, ‘artificial intelligence’ and ‘neural network’, and swap in the word ‘magic’. Does everything still make grammatical sense? Is any of the meaning lost? If
not, I’d be worried that it’s all nonsense. Because I’m afraid – long into the foreseeable future – we’re not going to ‘solve world hunger with magic’ or ‘use magic to write the
perfect screenplay’ any more than we are with AI.
That’s a fantastic approach to spotting bullshit technical claims, and I’m totally going to be using it.
Anyway: this was a wonderful read and I only regret that it took me a few years to get around to it! But fortunately, it’s as relevant today as it was the day it was released.
As part of my efforts to reclaim the living room from the children, I’m building a new gaming PC for the playroom. She’s called Bee, and – thanks to the absolute insanity that is
The Tower 300 case from Thermaltake – she’s one of the most bonkers PC cases I’ve ever worked in.
Back before PCs were black, they were beige. And even further back, they’d have not only “Reset” and “Power” buttons, but also a “Turbo” button.
I’m not here to tell you what it did1. No, I’m here to show you how to re-live
those glory days with a Turbo button of your very own, implemented as a reusable Web Component that you can install on your very own website:
Go on, press the Turbo button and see what happens.
(Don’t press the Reset button; other people are using this website!)
If you’d like some beige buttons of your own, you can get them at Beige-Buttons.DanQ.dev. Two lines of code and you can
pop them on any website you like. Also, it’s open-source under the Unlicense so you can take it, break it, or do what you like with it.
I’ve been slumming it in some Web Revivalist circles lately, and it might show. Best Resolution (with all its 88×31s2),
which I launched last month, for example.
You might anticipate seeing more retro fun-and-weird going on here. You might be right.
2 I guess that’s another “if you know, you know”, but at least you’ll get fewer
conflicting answers if you search for an explanation than you will if you try to understand the turbo button.
I’d like to nominate DB13W3 for Most Cursed Connector. I mean, just look at that thing!
Bonus: there were at least two different, incompatible, pinout “standards” for this thing, so there was no guarantee that a random monitor with this cable would connect to your
workstation, even if it had the right port.
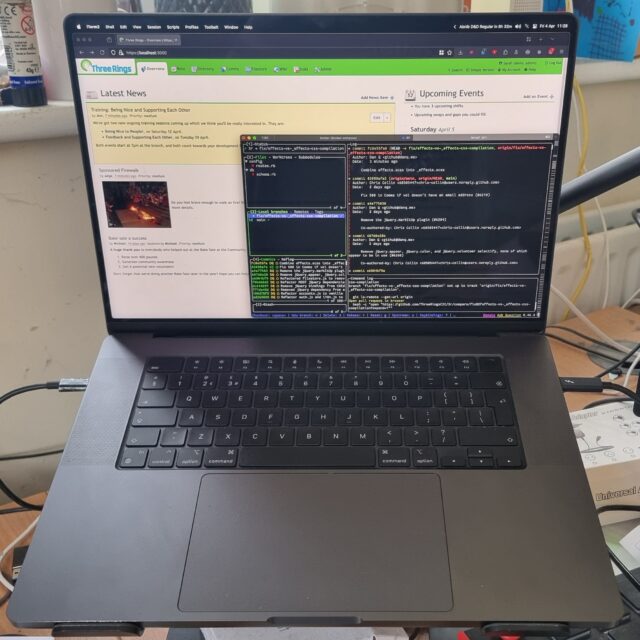
I’m off for a week of full-time volunteering with Three Rings at 3Camp, our annual volunteer hack week: bringing together our distributed
team for some intensive in-person time, working to make life better for charities around the world.
And if there’s one good thing to come out of me being suddenly and unexpectedly laid-off two days ago, it’s that I’ve got a shiny new laptop to do
my voluntary work on (Automattic have said that I can keep it).
Conveniently just-over-A5 sized, each of the two volumes is light enough to read in bed without uncomfortably clonking yourself in the face.
Set in the early-to-mid-1990s world in which the BBS is still alive and kicking, and the Internet’s gaining traction but still
lacks the “killer app” that will someday be the Web (which is still new and not widely-available), the story follows a handful of teenagers trying to find their place in the world.
Meeting one another in the 90s explosion of cyberspace, they find online communities that provide connections that they’re unable to make out in meatspace.
I loved some of the contemporary nerdy references, like the fact that each chapter page sports the “Geek Code” of the character upon which that chapter focusses.1So yeah: the whole thing feels like a trip back into the naivety of the online world of the last millenium, where small, disparate (and often local) communities flourished and
early netiquette found its feet. Reading Incredible Doom provides the same kind of nostalgia as, say, an afternoon spent on textfiles.com. But
it’s got more than that, too.
The user interfaces of IRC, Pine, ASCII-art-laden BBS menus etc. are all produced with
a good eye for accuracy, but don’t be fooled: this is a story about humans, not computers. My 9-year-old loved it too, and she’s never even heard of IRC (I hope!).
It touches on experiences of 90s cyberspace that, for many of us, were very definitely real. And while my online “scene” at around the time that the story is set might have been
different from that of the protagonists, there’s enough of an overlap that it felt startlingly real and believable. The online world in which I – like the characters in the story – hung
out… but which occupied a strange limbo-space: both anonymous and separate from the real world but also interpersonal and authentic; a frontier in which we were still working out the
rules but within which we still found common bonds and ideals.
Having had times in the 90s that I met up offline with relative strangers whom I first met online, I can confirm that… yeah, the fear is real!
Anyway, this is all a long-winded way of saying that Incredible Doom is a lot of fun and if it sounds like your cup of tea, you should read it.
Also: shortly after putting the second volume down, I ended up updating my Geek Code for the first time in… ooh, well over a decade. The standards have moved on a little (not entirely
in a good way, I feel; also they’ve diverged somewhat), but here’s my attempt:
----- BEGIN GEEK CODE VERSION 6.0 -----
GCS^$/SS^/FS^>AT A++ B+:+:_:+:_ C-(--) D:+ CM+++ MW+++>++
ULD++ MC+ LRu+>++/js+/php+/sql+/bash/go/j/P/py-/!vb PGP++
G:Dan-Q E H+ PS++ PE++ TBG/FF+/RM+ RPG++ BK+>++ K!D/X+ R@ he/him!
----- END GEEK CODE VERSION 6.0 -----
Footnotes
1 I was amazed to discover that I could still remember most of my Geek Code
syntax and only had to look up a few components to refresh my memory.
I didn’t/don’t own much vinyl – perhaps mostly because I had a tape deck in my bedroom years before a record player – but I’ve felt this pain. And don’t get me started on the videogames I’ve paid for multiple times.
In the Summer of 1995 I bought the CD single of the (still excellent!) Set You
Free by N-Trance.2
I’d heard about this new-fangled “MP3” audio format, so soon afterwards I decided to rip a copy of the song to my PC.
I was using a 66MHz 486SX CPU, and without an embedded FPU I didn’t
quite have the spare processing power to rip-and-encode in a single pass.3
So instead I first ripped to an uncompressed PCM .wav file and then performed the encoding: the former step
was done almost in real-time (I listened to the track as it ripped!), about 7 minutes. The latter step took about 20 minutes.
So… about half an hour in total, to rip a single song.
Progress bar, you say? I’ll just sit here and wait then, I guess. Actual contemporary-ish photo.
Creating a (what would now be considered an apalling) 32kHz mono-channel file, this meant that I briefly stored both a 27MB wave file and the final ~4MB MP3 file. 31MB
might not sound huge, but I only had a total of 145MB of hard drive space at the time, so 31MB consumed over a fifth of my entire fixed storage! Even after deleting the intermediary wave file I was left with a single song consuming around 3% of my space,
which is mind-boggling to think about in hindsight.
But it felt like magic. I called my friend Gary to tell him about it. “This is going to be massive!” I said. At the time, I meant for techy
people: I could imagine a future in which, with more hard drive space, I’d keep all my music this way… or else bundle entire artists onto writable CDs in this new format, making albums obsolete. I never considered that over the coming decade or so the format would enter the public consciousness, let
alone that it’d take off like it did.
If you’re thinking of Gary and I as the kind of reprobates who helped bring on the golden age of music piracy… I’d like to distract you with a bigger show of yobbish behaviour in the
form of this photo from the day we played at dropping half-bricks onto starter pistol ammunition.
The MP3 file I produced had a fault. Most of the way through the encoding process, I got bored and ran another program, and this
must’ve interfered with the stream because there was an audible “blip” noise about 30 seconds from the end of the track. You’d have to be listening carefully to hear it, or else know
what you were looking for, but it was there. I didn’t want to go through the whole process again, so I left it.
But that artefact uniquely identified that copy of what was, in the end, a popular song to have in your digital music collection. As the years went by and I traded MP3 files in bulk at LAN parties or on CD-Rs or, on at least one ocassion, on an Iomega Zip disk (remember those?), I’d ocassionally see
N-Trance - (Only Love Can) Set You Free.mp34 being passed around and play it, to see if it was “my”
copy.
Sometimes the ID3 tags had been changed because for example the previous owner had decided it deserved to be considered Genre: Dance instead of Genre: Trance5. But I could still identify that file because
of the audio fingerprint, distinct to the first MP3 I ever created.
I still had that file when I went to university (where it occupied a smaller proportion of my hard drive space) and hearing that
distinctive “blip” would remind me about the ordeal that was involved in its creation. I don’t have it any more, but perhaps somebody else still does.
Footnotes
1 I might never have told this story on my blog, but eagle-eyed readers may remember that
I’ve certainly hinted at it before now.
2 Rewatching that music video, I’m struck by a recollection of how crazy popular
crossfades were on 1990s dance music videos. More than just a transition, I’m pretty sure that most of the frames of that video are mid-crossfade: it feels like I’m watching
Kelly Llorenna hanging out of a sunroof but I accidentally left one of my eyeballs in a smoky nightclub and can still see out of it as well.
3 I initially tried to convert directly from red book format to an MP3 file, but the encoding process was
too slow and the CD drive’s buffer filled up and didn’t get drained by the processor, which was still presumably bogged down with
framing or fourier-transforming earlier parts of the track. The CD drive reasonably assumed that it wasn’t actually being used and
spun-down the drive motor, and this caused it to lose its place in the track, killing the whole process and leaving me with about a 40 second recording.
4 Yes, that filename isn’t quite the correct title. I was wrong.
Plus many, many things that were new to me and that I’ve loved learning about these last few days.
It’s definitely not a competition; it’s a learning opportunity wrapped up in the weirdest bits of the field. Have an explore and feed your inner computer science geek.
Needed new UPS batteries.
Almost bought from @insight_uk but they require registration to checkout.
Purchased from @SourceUPSLtd instead.
Moral: having no “guest checkout” costs you business.
As always seems to happen when I move house, a piece of computer hardware broke for me during my recent house move. It’s always
exactly one piece of hardware, like it’s a symbolic recognition by the universe that being lugged around, rattling around and butting up against one another, is not the natural
state of desktop computers. Nor is it a comfortable journey for the hoarder-variety of geek nervously sitting in front of them, tentatively turning their overloaded vehicle around each
and every corner. UserFriendly said it right in this comic from 2003.
This time around, it was one of the hard drives in Renegade, my primary Windows-running desktop, that failed. (At least I didn’t break
myself, this time.)
Here’s the victim of my latest move. Rest in pieces.
Fortunately, it failed semi-gracefully: the S.M.A.R.T. alarm went off about a week before it actually started causing real problems, giving me at least a little time to prepare, and
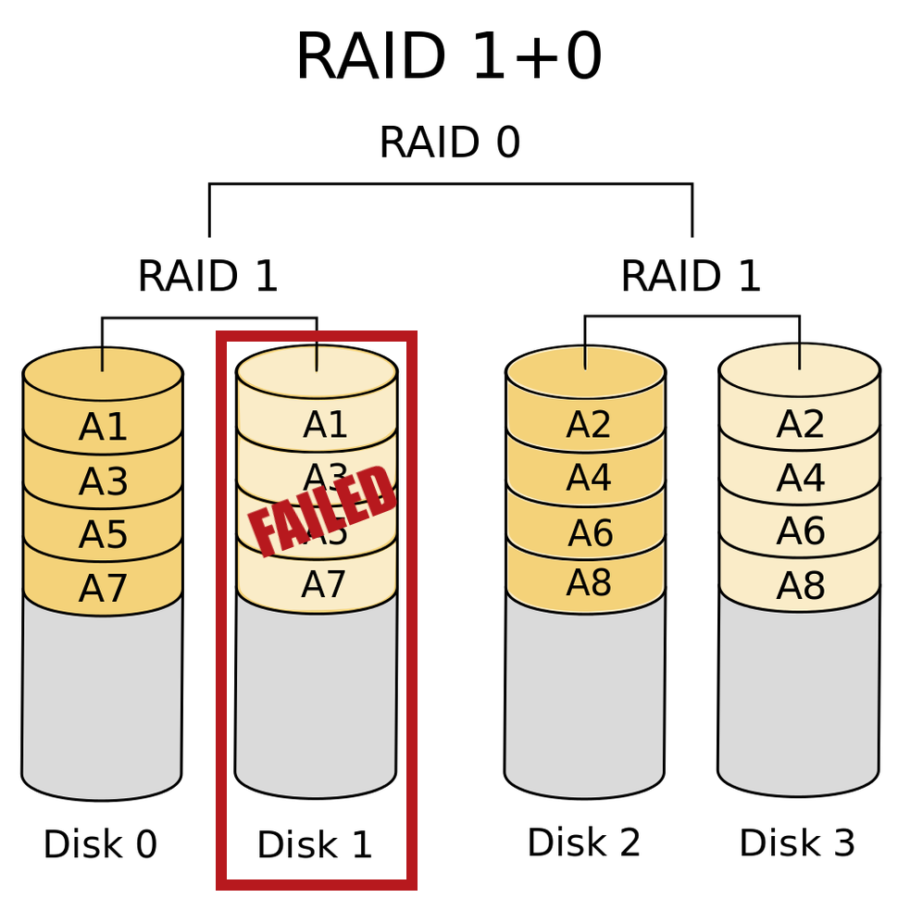
– better yet – the drive was part of a four-drive RAID 10 hot-swappable array, which means that every single byte of data on that drive was already duplicated to a second drive.
Incidentally, this configuration may have indirectly contributed to its death: before I built Fox, our new household NAS, I used Renegade for many of the same purposes, but WD Blues are not really a “server grade” hard
drive and this one and its siblings will have seen more and heavier use than they might have expected over the last few years. (Fox, you’ll be glad to hear, uses much better-rated
drives for her arrays.)
Set up your hard drives like this and you can lose at least one, and up to half, of the drives without losing data.
So no data was lost, but my array was degraded. I could have simply repaired it and carried on by adding a replacement similarly-sized hard drive, but my needs have changed now that Fox
is on the scene, so instead I decided to downgrade to a simpler two-disk RAID 1 array for important data and an
“at-risk” unmirrored drive for other data. This retains the performance of the previous array at the expense of a reduction in redundancy (compared to, say, a three-disk RAID 5 array which would have retained redundancy at the expense of performance). As I said: my needs have changed.
Fixing Things… Fast!
In any case, the change in needs (plus the fact that nobody wants watch an array rebuild in a different configuration on a drive with system software installed!) justified a
reformat-and-reinstall, which leads to the point of this article: how I optimised my reformat-and-reinstall using Chocolatey.
Not this kind of chocolatey, I’m afraid. Man, I shouldn’t have written this post before breakfast.
Chocolatey is a package manager for Windows: think like apt for
Debian-like *nices (you know I do!) or Homebrew for MacOS. For previous Windows system
rebuilds I’ve enjoyed the simplicity of Ninite, which will build you a one-click installer for your choice of many of your favourite tools, so you can
get up-and-running faster. But Chocolatey’s package database is much more expansive and includes bonus switches for specifying particular versions of applications, so it’s a clear
winner in my mind.
If you learn only one thing about me from this post, let it be that I’m a big fan of redundancy. Here’s the printed version of my reinstallation list. Y’know, in case the copy on a
pendrive failed.
So I made up a Windows installation pendrive and added to it a “script” of things to do to get Renegade back into full working order. You can read the full script here, but the essence of it was:
Reconfigure the RAID array, reformat, reinstall Windows, and create an account.
Configuration (e.g. set up my unusual keyboard mappings, register software, set up remote connections and backups, etc.).
By scripting virtually all of the above I was able to rearrange hard drives in and then completely reimage a (complex) working Windows machine with well under an hour of downtime; I can
thoroughly recommend Chocolatey next time you have to set up a new Windows PC (or just to expand what’s installed on your existing one). There’s a GUI if you’re not a fan of the command line, of course.
Last week I built Fox, the newest addition to our home network. Fox, whose specification
called for not one, not two, not three but four 12 terabyte hard disk drives was built principally as a souped-up NAS
device – a central place for us all to safely hold and control access to important files rather than having them spread across our various devices – but she’s got a lot more going on
that that, too.
Right now, Fox lives under my desk along with most of our network cables.
Fox has:
Enough hard drive space to give us 36TB of storage capacity plus 12TB of parity, allowing any
one of the drives to fail without losing any data.
“Headroom” sufficient to double its capacity in the future without significant effort.
A mediumweight graphics card to assist with real-time transcoding, helping her to convert and stream audio and videos to our devices in whatever format they prefer.
A beefy processor and sufficient RAM to run a dozen virtual machines supporting a variety of functions like software
development, media ripping and cataloguing, photo rescaling, reverse-proxying, and document scanning (a planned future purpose for Fox is to have a network-enabled scanner near our
“in-trays” so that we can digitise and OCR all of our post and paperwork into a searchable, accessible, space-saving
collection).
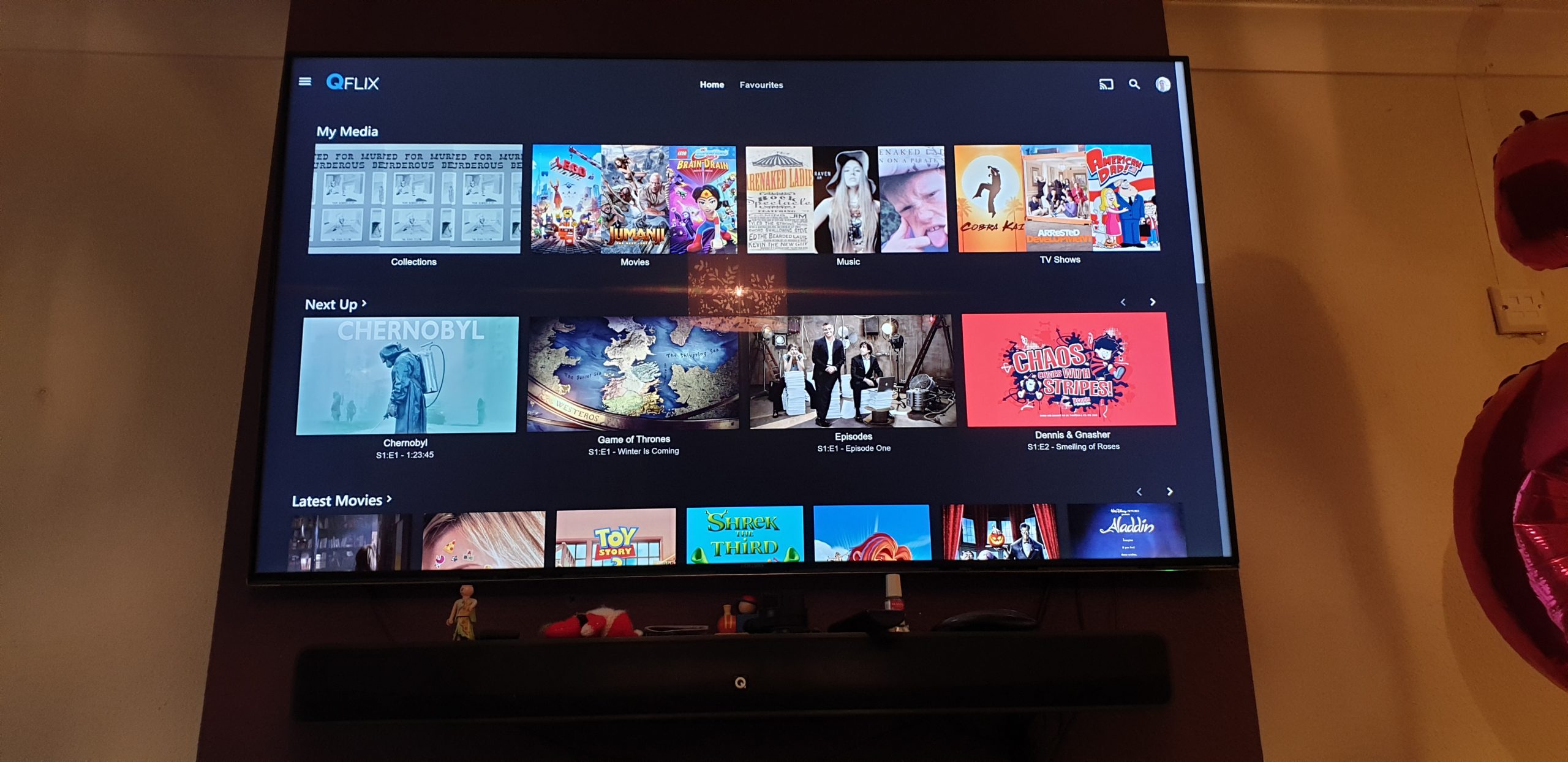
“QFlix” is a lot like Netflix, except geared mostly towards saving us from having to walk over to the DVD shelf or remember which disc we were up to when watching a long-running
series. #firstworldproblems
The last time I filmed myself building a PC was when I built Cosmo, a couple of desktops ago. He
turned out to be a bit of a nightmare: he was my first fully-watercooled computer and he leaked everywhere: by the time I’d done all the fixing and re-fixing to make him behave nicely,
I wasn’t happy with the video footage and I never uploaded it. I’d been wary, almost-superstitious, about filming a build since then, but I shot a timelapse of Fox’s construction and it
turned out pretty well: you can watch it below or on YouTube or QTube.
The timelapse slows to real-time, about a minute in, to illustrate a point about the component test I did with only a CPU (and
cooler), PSU, and RAM attached. Something I routinely do when building
computers but which I only recently discovered isn’t commonly practised is shown: that the easiest way to power on a computer without attaching a power switch is just to bridge the
power switch pins using your screwdriver!
Fox is running Unraid, an operating system basically designed for exactly these kinds of purposes. I’ve been super-impressed by the
ease-of-use and versatility of Unraid and I’d recommend it if you’ve got a similar NAS project in your future! I’d also like
to sing the praises of the Fractal Design Node 804 case: it’s not got quite as many bells-and-whistles
as some cases, but its dual-chamber design is spot-on for a multipurpose NAS, giving ample room for both full-sized expansion
cards and heatsinks and lots of hard drives in a relatively compact space.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
Anticipatory note: based on the traffic I already get to my blog and the keywords people search for, I imagine that some people will end up here looking to
learn “how to become a hacker”. If that’s your goal, you’re probably already asking the wrong question, but I direct you to Eric S. Raymond’s Guide/FAQ on the subject. Good luck.
Few words have seen such mutation of meaning over their lifetimes as the word “silly”. The earliest references, found in Old English, Proto-Germanic, and Old Norse and presumably having
an original root even earlier, meant “happy”. By the end of the 12th century it meant “pious”; by the end of the 13th, “pitiable” or “weak”; only by the late 16th coming to mean
“foolish”; its evolution continues in the present day.
The Monty Python crew were certainly the experts on the contemporary use of the word.
But there’s little so silly as the media-driven evolution of the word “hacker” into something that’s at least a little offensive those of us who probably would be
described as hackers. Let’s take a look.
Hacker
What people think it means
Computer criminal with access to either knowledge or tools which are (or should be) illegal.
What it originally meant
Expert, creative computer programmer; often politically inclined towards information transparency, egalitarianism, anti-authoritarianism, anarchy, and/or decentralisation of
power.
The Past
The earliest recorded uses of the word “hack” had a meaning that is unchanged to this day: to chop or cut, as you might describe hacking down an unruly bramble. There are clear links
between this and the contemporary definition, “to plod away at a repetitive task”. However, it’s less certain how the word came to be associated with the meaning it would come to take
on in the computer labs of 1960s university campuses (the earliest references seem to come from
around April 1955).
There, the word hacker came to describe computer experts who were developing a culture of:
sharing computer resources and code (even to the extent, in extreme
cases, breaking into systems to establish more equal opportunity of access),
learning everything possible about humankind’s new digital frontiers (hacking to learn, not learning to hack)
discovering and advancing the limits of computers: it’s been said that the difference between a non-hacker and a hacker is that a non-hacker asks of a new gadget “what does it do?”,
while a hacker asks “what can I make it do?”
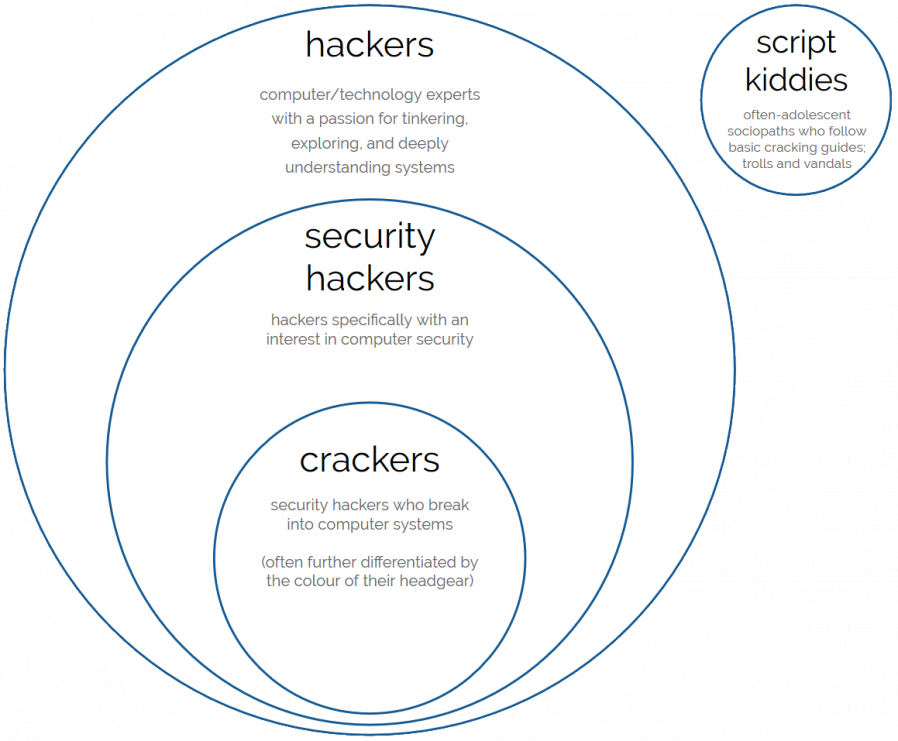
What the media generally refers to as “hackers” would be more-accurately, within the hacker community, be called crackers; a subset of security hackers, in turn a subset of
hackers as a whole. Script kiddies – people who use hacking tools exclusively for mischief without fully understanding what they’re doing – are a separate subset on their own.
It is absolutely possible for hacking, then, to involve no lawbreaking whatsoever. Plenty of hacking involves writing (and sharing) code, reverse-engineering technology and systems you
own or to which you have legitimate access, and pushing the boundaries of what’s possible in terms of software, art, and human-computer interaction. Even among hackers with a specific
interest in computer security, there’s plenty of scope for the legal pursuit of their interests: penetration testing, security research, defensive security, auditing, vulnerability
assessment, developer education… (I didn’t say cyberwarfare because 90% of its
application is of questionable legality, but it is of course a big growth area.)
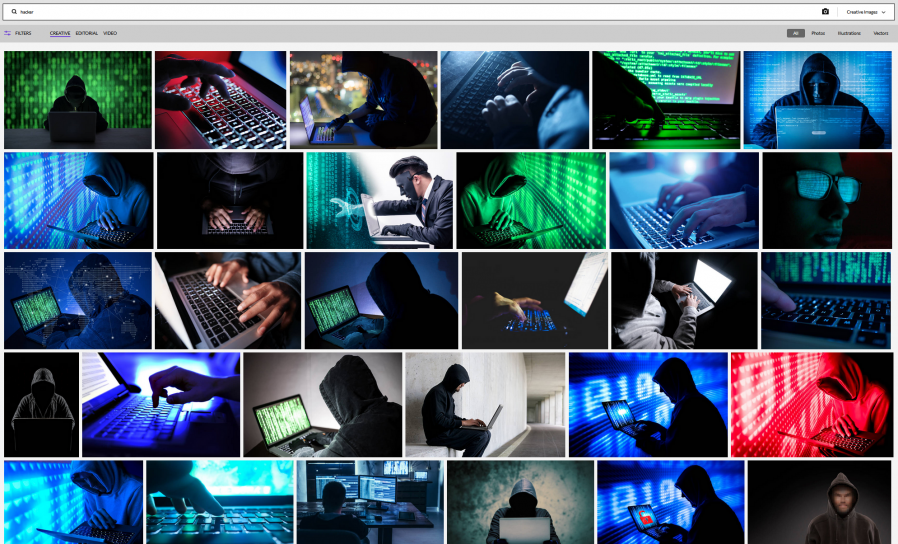
Hackers have a serious image problem, and the best way to see it is to search on your favourite stock photo
site for “hacker”. If you don’t use a laptop in a darkened room, wearing a hoodie and optionally mask and gloves, you’re not a real hacker. Also, 50% of all text should be
green, 40% blue, 10% red.
So what changed? Hackers got famous, and not for the best reasons. A big tipping point came in the early 1980s when hacking group The
414s broke into a number of high-profile computer systems, mostly by using the default password which had never been changed. The six teenagers responsible were arrested by the
FBI but few were charged, and those that were were charged only with minor offences. This was at least in part because
there weren’t yet solid laws under which to prosecute them but also because they were cooperative, apologetic, and for the most part hadn’t caused any real harm. Mostly they’d just been
curious about what they could get access to, and were interested in exploring the systems to which they’d logged-in, and seeing how long they could remain there undetected. These remain
common motivations for many hackers to this day.
Hoodie: check. Face-concealing mask: check. Green/blue code: check. Is I a l33t hacker yet?
News media though – after being excited by “hacker” ideas introduced by WarGames – rightly realised that a hacker with the
same elementary resources as these teens but with malicious intent could cause significant real-world damage. Bruce
Schneier argued last year that the danger of this may be higher today than ever before. The press ran news stories strongly associating the word “hacker” specifically with the focus
on the illegal activities in which some hackers engage. The release of Neuromancer the following year, coupled
with an increasing awareness of and organisation by hacker groups and a number of arrests on both sides of the Atlantic only fuelled things further. By the end of the decade it was
essentially impossible for a layperson to see the word “hacker” in anything other than a negative light. Counter-arguments like The
Conscience of a Hacker (Hacker’s Manifesto) didn’t reach remotely the same audiences: and even if they had, the points they made remain hard to sympathise with for those outside of
hacker communities.
‘Nuff said.
A lack of understanding about what hackers did and what motivated them made them seem mysterious and otherworldly. People came to make the same assumptions about hackers that
they do about magicians – that their abilities are the result of being privy to tightly-guarded knowledge rather than years of practice – and this
elevated them to a mythical level of threat. By the time that Kevin Mitnick was jailed in the mid-1990s, prosecutors were able to successfully persuade a judge that this “most dangerous
hacker in the world” must be kept in solitary confinement and with no access
to telephones to ensure that he couldn’t, for example, “start a nuclear war by whistling into a pay phone”. Yes, really.
Whistling into a phone to start a nuclear war? That makes CSI: Cyber seem realistic [watch].
The Future
Every decade’s hackers have debated whether or not the next decade’s have correctly interpreted their idea of “hacker ethics”. For me, Steven Levy’s tenets encompass them best:
Access to computers – and anything which might teach you something about the way the world works – should be unlimited and total.
All information should be free.
Mistrust authority – promote decentralization.
Hackers should be judged by their hacking, not bogus criteria such as degrees, age, race, or position.
You can create art and beauty on a computer.
Computers can change your life for the better.
Given these concepts as representative of hacker ethics, I’m convinced that hacking remains alive and well today. Hackers continue to be responsible for many of the coolest and
most-important innovations in computing, and are likely to continue to do so. Unlike many other sciences, where progress over the ages has gradually pushed innovators away from
backrooms and garages and into labs to take advantage of increasingly-precise generations of equipment, the tools of computer science are increasingly available to individuals.
More than ever before, bedroom-based hackers are able to get started on their journey with nothing more than a basic laptop or desktop computer and a stack of freely-available
open-source software and documentation. That progress may be threatened by the growth in popularity of easy-to-use (but highly locked-down) tablets and smartphones, but the barrier to
entry is still low enough that most people can pass it, and the new generation of ultra-lightweight computers like the Raspberry Pi are doing
their part to inspire the next generation of hackers, too.
That said, and as much as I personally love and identify with the term “hacker”, the hacker community has never been less in-need of this overarching label. The diverse variety
of types of technologist nowadays coupled with the infiltration of pop culture by geek culture has inevitably diluted only to be replaced with a multitude of others each describing a
narrow but understandable part of the hacker mindset. You can describe yourself today as a coder, gamer, maker, biohacker, upcycler,cracker, blogger, reverse-engineer, social engineer, unconferencer, or one of dozens of other terms that more-specifically ties you to your
community. You’ll be understood and you’ll be elegantly sidestepping the implications of criminality associated with the word “hacker”.
The original meaning of “hacker” has also been soiled from within its community: its biggest and perhaps most-famous
advocate‘s insistence upon linguistic prescriptivism came under fire just this year after he pushed for a dogmatic interpretation of the term “sexual assault” in spite of a victim’s experience.
This seems to be absolutely representative of his general attitudes towards sex, consent,
women, and appropriate professional relationships. Perhaps distancing ourselves from the old definition of the word “hacker” can go hand-in-hand with distancing ourselves from some of
the toxicity in the field of computer science?
(I’m aware that I linked at the top of this blog post to the venerable but also-problematic Eric S. Raymond; if anybody can suggest an equivalent resource by another
author I’d love to swap out the link.)
Verdict: The word “hacker” has become so broad in scope that we’ll never be able to rein it back in. It’s tainted by its associations with both criminality, on one
side, and unpleasant individuals on the other, and it’s time to accept that the popular contemporary meaning has won. Let’s find new words to define ourselves, instead.







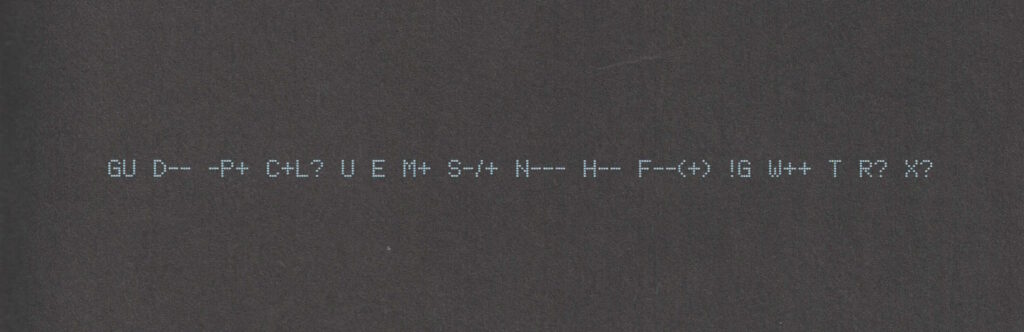












{kind=link}