Mostly for my own benefit, as most other guides online are outdated, here’s my set-up for intercepting TLS-encrypted communications from an emulated Android device (in Android Emulator)
using Fiddler. This is useful if you want to debug, audit, reverse-engineer, or evaluate the security of an Android app. I’m using Fiddler
5.0 and Android Studio 2.3.3 (but it should work with newer versions too) to intercept connections from an Android 8 (Oreo) device
using Windows. You can easily adapt this set-up to work with physical devices too, and it’s not hard to adapt these instructions for other configurations too.
1. Configure Fiddler
Install Fiddler and run it.
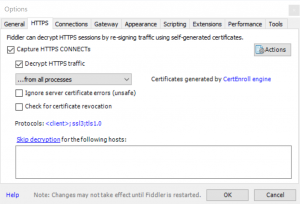
Under Tools > Options > HTTPS, enable “Decrypt HTTPS traffic” and allow a root CA certificate to be created.
Click Actions > Export Root Certificate to Desktop to get a copy of the root CA public key.
On the Connections tab, ensure that “Allow remote computers to connect” is ticked. You’ll need to restart Fiddler after changing this and may be prompted to grant it additional
permissions.
If Fiddler changed your system proxy, you can safely change this back (and it’ll simplify your output if you do because you won’t be logging your system’s connections, just the Android
device’s ones). Fiddler will complain with a banner that reads “The system proxy was changed. Click to reenable capturing.” but you can ignore it.
2. Configure your Android device
Install Android Studio. Click Tools > Android > AVD Manager to get a list of virtual devices. If you haven’t created one already, create one: it’s now possible to create Android
devices with Play Store support (look for the icon, as shown above), which means you can easily intercept traffic from third-party applications without doing APK-downloading hacks: this
is great if you plan on working out how a closed-source application works (or what it sends when it “phones home”).
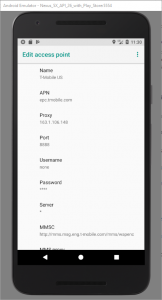
In Android’s Settings > Network & Internet,
disable WiFi. Then, under Mobile Network > Access Point Names > {Default access point, probably T-Mobile} set Proxy to the local IP address of your computer and Port to 8888. Now
all traffic will go over the virtual cellular data connection which uses the proxy server you’ve configured in Fiddler.
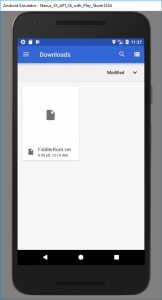
Drag the root CA file you exported to your desktop to your virtual Android device. This will automatically copy the file into the virtual device’s “Downloads” folder (if you’re using a
physical device, copy via cable or network). In Settings > Security & Location > Encryption & Credentials > Install from SD Card, use the hamburger menu to get to the Downloads
folder and select the file: you may need to set up a PIN lock on the device to do this. Check under Trusted credentials > User to check that it’s there, if you like.
Test your configuration by visiting a HTTPS website: as you browse on the Android device, you’ll see the (decrypted) traffic appear in Fiddler. This also works with apps other than the
web browser, of course, so if you’re reverse-engineering a API-backed application encryption then encryption doesn’t have to impede you.
3. Not working? (certificate pinning)
A small but increasing number of Android apps implement some variation of built-in key pinning, like HPKP but usually
implemented in the application’s code (which is fine, because most people auto-update their apps). What this does is ensures that the certificate presented by the server is signed by a
certification authority from a trusted list (a trusted list that doesn’t include Fiddler’s CA!). But remember: the app is running on your device, so you’re ultimately in
control – FRIDA’s bypass script “fixed” all of the apps I tried, but if it
doesn’t then I’ve heard good things about Inspeckage‘s “SSL uncheck” action.
Summary of steps
If you’re using a distinctly different configuration (different OS, physical device, etc.) or this guide has become dated, here’s the fundamentals of what you’re aiming to achieve:
Set up a decrypting proxy server (e.g. Fiddler, Charles, Burp, SSLSplit – note that Wireshark isn’t suitable) and export its root certificate.
Import the root certificate into the certificate store of the device to intercept.
Configure the device to connect via the proxy server.
If using an app that implements certificate pinning, “fix” the app with FRIDA or another tool.
Do you remember Challenge Anneka? It aired during the late 1980s and early 1990s and basically involved TV
presenter Anneka Rice being dropped off somewhere “random” and being challenged to find and help people in sort-of a treasure-trail activity; sort of a game show but with only one
competitor and the prizes are community projects and charities. No? Doesn’t matter, it’s just what I was thinking about.
“Hey, I’ve got an idea,” said Robin, shortly before we stole his phone and wallet and dumped him in the countryside.
Ruth‘s brother Robin is doing a project this year that he calls 52 Reflect (you may recall I shared his inaugural post) which sees him leaving London to visit a different place every weekend, hike around, and take some photos. This last weekend,
though, he hadn’t made any plans, so he came up to Oxford and asked us to decide where he went: we were to pick a place between 10 and 15 miles away, blindfold him, and drop
him off there to see if he could find his way home. Naturally he’d need to be deprived of a means of navigation or communication, so we took his phone, and to increase the challenge we
also took his wallet, leaving him with only a tenner in case he needed to buy a packet of crisps or something.
I had a friendly assistant test out a variety of blindfolds for me: this wasn’t the one we eventually used.
After much secretive discussion, we eventually settled on N 51° 50.898′, W 001° 28.987′: a
footpath through a field in the nothingness to the West of Finstock, a village near the only-slightly-larger town of Charlbury. Then the next morning we bundled Robin into a car (with a blindfold on), drove him out to near the spot, walked him the rest of
the way (we’d been careful to pick somewhere we believed we could walk a blindfolded person to safely), and ran quietly away while he counted to 120 and took off his blindfold.
We selected a location based on a combination of its distance, natural beauty, and anticipated difficulty in determining the “right” direction to walk in after being abandoned.
Unfortunately it rained on the day itself, so the beauty was somewhat muted.
I also slipped a “logging only” GPS received into his backpack so that we’d be able, after the fact, to extract data about his journey – distance, speeds, route etc.. And so when he
turned up soaking wet on our door some hours later we could look at the path he took at the same time as he told us the story of his adventure. (If you’re of such an inclination, you
can download the GPX file.)
His route might not have been the most direct, but he DID manage to hitch a lift for the first leg.
For the full story of his adventure, go read Robin’s piece about it (the blog posts of his
other adventures are pretty good too). Robin’s expressed an interest in doing something similar – or even crazier – in future, so you might be hearing more of this kind of thing.
I recently discovered a minor security vulnerability in mobile webcomic reading app Comic Chameleon, and I thought that it was interesting
(and tame) enough to share as a learning example of (a) how to find security vulnerabilities in an app like this, and (b) more importantly, how to write an app like this
without this kind of security vulnerability.
The nature of the vulnerability is that, for webcomics pushed directly into the platform by their authors, it’s possible to read comics (long) before they’re published. By way
of proof, here’s a copy of the top-right 200 × 120 pixels of episode 54 of the (excellent) Forward
Comic, which Imgur will confirm was uploaded on 2 July 2018: over three months ahead of its planned publication date.
I’m not going to spoil this comic for you, but if you follow it then when October comes I think you’ll be pleased.
How to hack a web-backed app
Just to be clear, I didn’t set out to hack this app, but once I stumbled upon the vulnerability I wanted to make sure that I was able to collect enough information that I’d be
able to explain to its author what was wrong and how to fix it. You’d be amazed how many systems I find security holes in almost-completely by accident. In fact, I’d just noticed that
the application supported some webcomics that I follow but for which I hadn’t been able to find RSS feeds (and so I was selfdogfooding my own tool, RSSey, to “produce” RSS feeds for my reader by screen-scraping: not the most-elegant solution). But if this app could produce a list of issues of the comic, it
must have some way of doing what I was trying to do, and I wanted to know what it was.
Comic Chameleon brings a lot of comics into a single slick Android/iOS app. Some of them you’ll even have heard of!
The app, I figured, must “phone home” to some website – probably the app’s official website itself – to get the list of comics that it supports and details of where to get their feeds
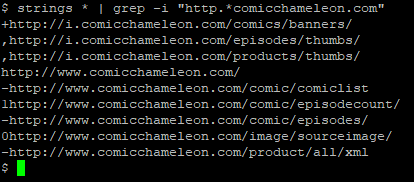
from, so I grabbed a copy of the app and started investigating. Because I figured I was probably looking for a URL, the first thing I
did was to download the raw APK file (your favourite search engine can tell you how to do this), decompressed it (APK files are just ZIP files, really) and ran strings on it to search for
likely-looking URLs:
As predicted, there are several hard-coded addresses. And all over unencrypted HTTP, eww!
I tried visiting a few of the addresses but many of them seemed to be API endpoints that were expecting additional parameters. Probably, I figured, the strings I’d extracted were
prefixes to which those parameters were attached. Rather than fuzz for the right parameters, I decided to watch what the app did: I spun up a simulated Android device using the official
emulator (I could have used my own on a wireless network that I control, of course, but this was lazier) and ran my favourite packet sniffer to
see what the application was requesting.
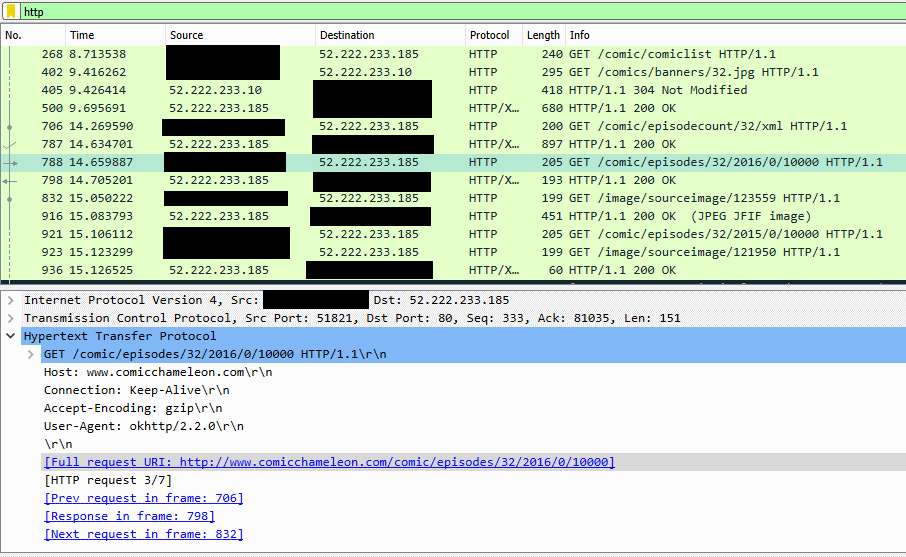
The web addresses are even clearer, here, and include all of the parameters I need.
Now I had full web addresses with parameters. Comparing the parameters that appeared when I clicked different comics revealed that each comic in the “full list” was assigned a numeric
ID which was used when requesting issues of that comic (along with an intermediate stage where the year of publication is requested).
Each comic is assigned an ID number, probably sequentially.
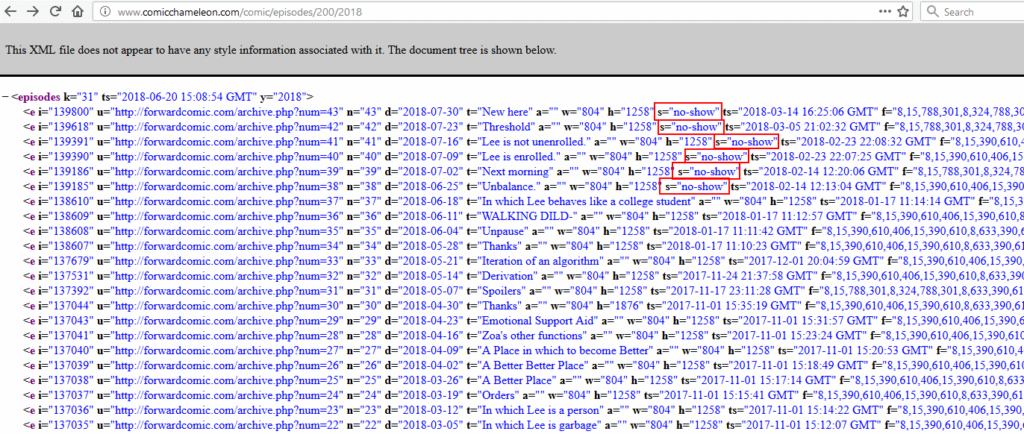
Interestingly, a number of comics were listed with the attribute s="no-show" and did not appear in the app: it looked like comics that weren’t yet being made available via
the app were already being indexed and collected by its web component, and for some reason were being exposed via the XML
API: presumably the developer had never considered that anybody but their app would look at the XML itself, but the thing about the Web is that if you put it on the Web, anybody can see it.
Still: at this point I assumed that I was about to find what I was looking for – some kind of machine-readable source (an RSS feed
or something like one) for a webcomic or two. But when I looked at the XML API for one of those webcomics I discovered quite a bit more than I’d bargained on finding:
Hey, what’s this? This feed includes titles for webcomics that haven’t been published yet, marked as ‘no-show’…
The first webcomic I looked at included the “official” web addresses and titles of each published comic… but also several not yet published ones. The unpublished ones were
marked with s="no-show" to indicate to the app that they weren’t to be shown, but I could now see them. The “official” web addresses didn’t work for me, as I’d expected,
but when I tried Comic Chameleon’s versions of the addresses, I found that I could see entire episodes of comics, up to three and a half months ahead of their expected
publication date.
Whoops.
Naturally, I compiled all of my findings into an email and contacted the app developer with all of the details they’d need to fix it – in hacker terms, I’m one of the “good guys”! – but
I wanted to share this particular example with you because (a) it’s not a very dangerous leak of data (a few webcomics a few weeks early and/or a way to evade a few ads isn’t
going to kill anybody) and (b) it’s very illustrative of the kinds of mistakes that app developers are making a lot, these days, and it’s important to understand why
so that you’re not among them. On to that in a moment.
Responsible disclosure
Because (I’d like to think) I’m one of the “good guys” in the security world, the first thing I did after the research above was to contact the author of the software. They didn’t seem
to have a security.txt file, a disclosure policy, nor a profile on any of the major disclosure management sites, so I sent an email. Were the
security issue more-severe, I’d have sent a preliminary email suggesting (and agreeing on a mechanism for) encrypted email, but given the low impact of this particular issue, I just
explained the entire issue in the initial email: basically what you’ve read above, plus some tips on fixing the issue and an offer to help out.
This is what stock photo sites think “hacking” is. Well… this, pages full of green code, or hoodies.
I subscribe to the doctrine of responsible disclosure, which – in the event of more-significant vulnerabilities –
means that after first contacting the developer of an insecure system and giving them time to fix it, it’s acceptable (in fact: in significant cases, it’s
socially-responsible) to publish the details of the vulnerability. In this case, though, I think the whole experience makes an interesting learning example about ways in which
you might begin to “black box” test an app for data leaks like this and – below – how to think about software development
in a way that limits the risk of such vulnerabilities appearing in the first place.
The author of this software hasn’t given any answer to any of the emails I’ve sent over the last couple of weeks, so I’m assuming that they just plan to leave this particular leak in
place. I reached out and contacted the author of Forward Comic, though, which turns out (coincidentally) to be probably the most-severely affected publication on the platform, so that
he had the option of taking action before I published this blog post.
Lessons to learn
When developing an “app” (whether for the web or a desktop or mobile platform) that connects to an Internet service to collect data, here are the important things you really, really
ought to do:
Don’t publish any data that you don’t want the user to see.
If the data isn’t for everybody, remember to authenticate the user.
And for heaven’s sake use SSL, it’s not the 1990s any more.
It’s a good job that nobody on the Web would ever try to view something easily-available but which they shouldn’t, right? That’s why screens like this have always worked so well.
That first lesson’s the big one of course: if you don’t want something to be on the public Internet, don’t put it on the public Internet! The feeds I found simply
shouldn’t have contained the “secret” information that they did, and the unpublished comics shouldn’t have been online at real web addresses. But aside from (or in addition to)
not including these unpublished items in the data feeds, what else might our app developer have considered?
Encryption. There’s no excuse for not using HTTPS these days. This alone wouldn’t have prevented a deliberate effort
to read the secret data, but it would help prevent it from happening accidentally (which is a risk right now), e.g. on a proxy server or while debugging something else on the same
network link. It also protects the user from exposing their browsing habits (do you want everybody at that coffee shop to know what weird comics you read?) and from having
content ‘injected’ (do you want the person at the next table of the coffee shop to be able to choose what you see when you ask for a comic?
Authentication (app). The app could work harder to prove that it’s genuinely the app when it contacts the website. No mechanism for doing this can ever be perfect,
because the user hasa access to the app and can theoretically reverse-engineer it to fish the entire authentication strategy out of it, but some approaches are better than others.
Sending a password (e.g. over Basic Authentication) is barely better than just using a complex web address, but
using a client-side certiciate or an OTP algorithm would (in conjunction
with encryption) foil many attackers.
Authentication (user). It’s a very-different model to the one currently used by the app, but requiring users to “sign up” to the service would reduce the risks and
provide better mechanisms for tracking/blocking misusers, though the relative anonymity of the Internet doesn’t give this much strength and introduces various additional burdens both
technical and legal upon the developer.
Fundamentally, of course, there’s nothing that an app developer can do to perfectly protect the data that is published to that app, because the app runs on a device that the user
controls! That’s why the first lesson is the most important: if it shouldn’t be on the public Internet (yet), don’t put it on the public Internet.
Hopefully there’s a lesson for you somewhere too: about how to think about app security so that you don’t make a similar mistake, or about some of the ways in which you might test the
security of an application (for example, as part of an internal audit), or, if nothing else, that you should go and read Forward, because it’s
pretty cool.
It’s been a while since I last hid geocache containers and it felt like it was time I gave a back some more to the community, especially as the “village” I live in has a lower cache density
than it deserves (conversely, Oxford City Centre is chock-full of uninspiring magnetic nanos – although it’s improving – and saturated with puzzle caches that ultimately require a trek
well outside the ring road). I’ve never been a heavyweight score-counting ‘cacher, but I’ve always had a soft spot for nice containers as large as their hiding place will permit coupled
with well thought-out pieces of local interest, and that’s the kind of cache I wanted to add to my local area.
Plus, my second-smallest caching-buddy was keen on getting involved with hiding containers rather than just finding them for me.
So imagine my joy when I discover a little-known piece of history about my village: that for a few years in the 1930s, we used to have a zoo! And I’m not talking
about something on the scale of that place with the meercats that we used to go
to: I’m talking about a proper zoo with lions and tigers and bears (oh my!). Attractions like Rosie the elephant and Hanno the lion would get mentioned in the local newspapers at
every excuse, and a special bus service connected Oxford city centre to the entrance to the zoo, just outside then (then much-smaller) Kidlington village.
I’ve stood at the spot from which this photo was taken, and I couldn’t recognise it. A new boulevard, houses, a police station and a leisure centre dominate the view today.
Taking advantage of my readers’ card at the Bodleian Library, I was able to find newspapers and books and piece together the history of this short-lived place. Of particular interest
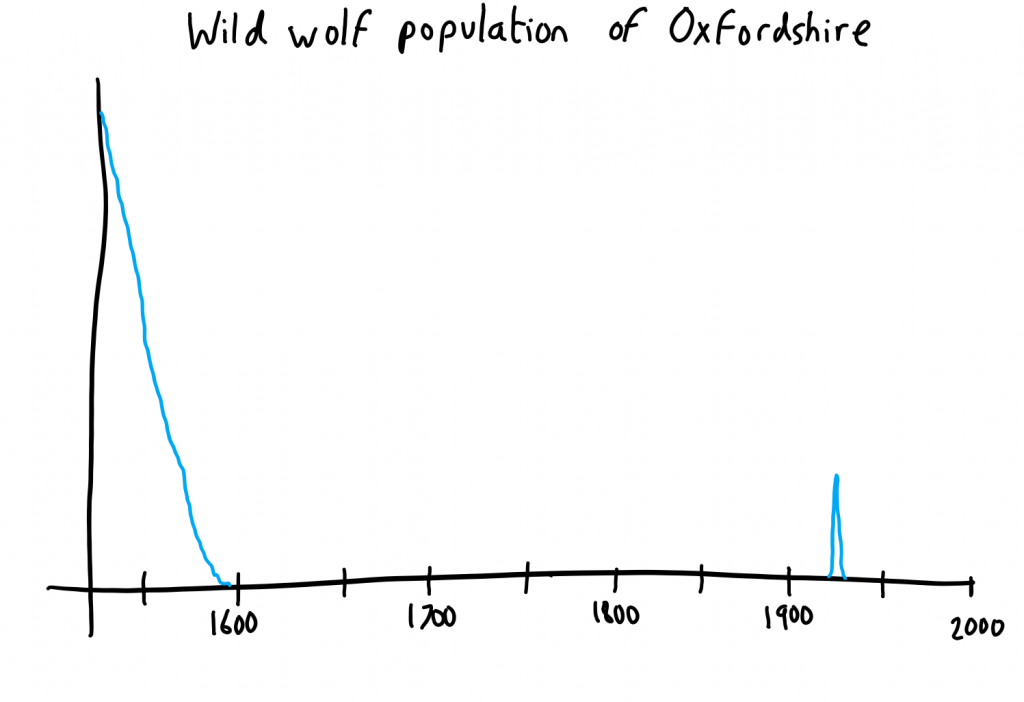
were the unusual events of January 1937, when three wolves escaped from the zoo and caused chaos in the surrounding village and farms for several days. In a tale that sounds almost like
a Marvel Comic origin story, the third wolf was eventually shot by local press photographer Johnny Johnson who chased the animal down on a borrowed bicycle.
Wild wolves in Oxfordshire were driven to extinction in the 16th century, but made a tiny comeback for a few days in the 1930s.
This formed the essence of our new geocaches: we planned four geocaches –
Oxford’s Wild Wolf Two (GC7Q9FF / OK0458), representing the second escaped wolf and hidden near to where it was shot by a farmer and his son
Oxford’s Wild Wolf Three – not yet placed, but we’re planning a multicache series that follows places that the third wolf might have travelled through during
its extended escape (the third wolf managed to stay at large for long enough to allegedly kill 13 sheep)
Sticking to my aim of larger, higher-quality caches, the “zoo” cache is a decorated ammo can filled with toy animals.
Soon after the first three caches went live they were found by a local ‘cacher whose
hides I’ve enjoyed before. She had nice things to say about the series, so that’s a good sign that we’re thinking in the right kind of direction. The bobbin – who’s taken a bit of an
interest in local history this month and keeps now asking about the ages of buildings and where roads used to go and things – is continuing to help me set out places to hide the parts
of the final cache in the series, Oxford’s Wild Wolf Three, so further excitement no-doubt awaits.
There’s a story that young network engineers are sometimes told to help them understand network stacks and/or the OSI model, and it goes something like this:
You overhear a conversation between two scientists on the subject of some topic relevant to their field of interest. But as you listen more-closely, you realise that the scientists
aren’t in the same place at all but are talking to one another over the telephone (presumably on speakerphone, given that you can hear them both, I guess). As you pay more attention
still, you realise that it isn’t the scientists on the phone call at all but their translators: each scientist speaks to their translator in the scientist’s own language, and the
translators are translating what they say into a neutral language shared with the other translator who translate it into the language spoken by the other scientist. Ultimately, the
two scientists are communicating with one another, but they’re doing so via a “stack” at their end which only needs to be conceptually the same as the “stack” at the other end as far
up as the step-below-them (the “first link” in their communication, with the translator). Below this point, they’re entrusting the lower protocols (the languages, the telephone
system, etc.), in which they have no interest, to handle the nitty-gritty on their behalf.
The two scientists are able to communicate with one another, but that communication is not direct.
This kind of delegation to shared intermediary protocols is common in networking and telecommunications. The reason relates to opportunity cost, or – for those of you who are Discworld fans – the Sam Vimes’ “Boots” Theory.
Obviously an efficiency could be gained here if all scientists learned a lingua franca, a universal shared second
language for their purposes… but most-often, we’re looking for a short-term solution to solve a problem today, and the short-term solution is to find a work-around that fits
with what we’ve already got: in the case above, that’s translators who share a common language. For any given pair of people communicating, it’s more-efficient to use a translator, even
though solving the global problem might be better accomplished by a universal second language (perhaps Esperanto, for valid if Eurocentric reasons!).
In the 1950s and 1960s, the concept of a self-driving car was already well-established… but the proposed mechanism for action was quite different to that which we see today.
The phenomenon isn’t limited to communications, though. Consider self-driving cars. If you look back to autonomous vehicle designs of the 1950s (because yes, we’ve been talking about
how cool self-driving cars would be for a long, long time), they’re distinctly different from the ideas we see today. Futurism of the 1950s focussed on adapting the roads themselves to
make them more-suitable for self-driving vehicles, typically by implanting magnets or electronics into the road surface itself or by installing radio beacons alongside highways to allow
the car to understand its position and surroundings. The modern approach, on the other hand, sees self-driving cars use LiDAR and/or digital cameras to survey their surroundings and complex computer hardware to interpret the data.
This difference isn’t just a matter of the available technology (although technological developments certainly inspired the new approach): it’s a fundamentally-different outlook! Early
proposals for self-driving cars aimed to overhaul the infrastructure of the road network: a “big solution” on the scale of teaching everybody a shared second language. But nowadays we
instead say “let’s leave the roads as they are and teach cars to understand them in the same way that people do.” The “big solution” is too big, too hard, and asking everybody
to chip in a little towards outfitting every road with a standardised machine-readable marking is a harder idea to swallow than just asking each person who wants to become an early
adopter of self-driving technology to pay a lot to implement a more-complex solution that works on the roads we already have.
In real life, these things spin much faster.
This week, Google showed off Duplex, a technology that they claim can perform the same kind of delegated-integration for our
existing telephone lives. Let’s ignore for a moment the fact that this is clearly going to be
overhyped and focus on the theoretical potential of this technology, which (even if it’s not truly possible today) is probably inevitable as chatbot technology improves: what does
this mean for us? Instead of calling up the hairdresser to make an appointment, Google claim, you’ll be able to ask Google Assistant to do it for you. The robot will call the
hairdresser and make an appointment on your behalf, presumably being mindful of your availability (which it knows, thanks to your calendar) and travel distance. Effectively, Google
Assistant becomes your personal concierge, making all of those boring phone calls so that you don’t have to. Personally, I’d be more than happy to outsource to a computer every time
I’ve had to sit in a telephone queue, giving the machine a summary of my query and asking it to start going through a summary of it to the human agent at the other end while I make my
way back to the phone. There are obviously ethical
considerations here too: I don’t like being hounded by robot callers and so I wouldn’t want to inflict that upon service providers… and I genuinely don’t know if it’s better or
worse if they can’t tell whether they’re talking to a machine or not.
I, for one, welcome our pizza-ordering overlords.
But ignoring the technology and the hype and the ethics, there’s still another question that this kind of technology raises for me: what will our society look like when this kind of
technology is widely-available? As chatbots become increasingly human-like, smarter, and cheaper, what kinds of ways can we expect to interact with them and with one another? By
the time I’m able to ask my digital concierge to order me a pizza (safe in the knowledge that it knows what I like and will ask me if it’s unsure, has my credit card details, and is
happy to make decisions about special offers on my behalf where it has a high degree of confidence), we’ll probably already be at a point at which my local takeaway also has a
chatbot on-staff, answering queries by Internet and telephone. So in the end, my chatbot will talk to their chatbot… in English… and work it out between the two of them.
Let that sink in for a moment: because we’ve a tendency to solve small problems often rather than big problems rarely and we’ve an affinity for backwards-compatibility, we will probably
reach the point within the lifetimes of people alive today that a human might ask a chatbot to call another chatbot: a colossally-inefficient way to exchange information built
by instalments on that which came before. If you’re still sceptical that the technology could evolve this way, I’d urge you to take a look at how the technologies underpinning the
Internet work and you’ll see that this is exactly the kind of evolution we already see in our communications technology: everything gets stacked on top of a popular existing
protocol, even if it’s not-quite the right tool for the job, because it makes one fewer problem to solve today.
Hacky solutions on top of hacky solutions work: the most believable thing about Max Headroom’s appearance in
Ready Player One (the book, not the film: the latter presumably couldn’t get the rights to the character) as a digital assistant was the versatility of his conversational
interface.
“See? My laptop says we should hook up.”
By the time we’re talking about a “digital concierge” that knows you better than anyone, there’s no reason that it couldn’t be acting on your behalf in other matters. Perhaps in the
future your assistant, imbued with intimate knowledge about your needs and interests and empowered to negotiate on your behalf, will be sent out on virtual “dates” with other people’s
assistants! Only if it and the other assistant agree that their owners would probably get along, it’ll suggest that you and the other human meet in the real world. Or you could have
your virtual assistant go job-hunting for you, keeping an eye out for positions you might be interested in and applying on your behalf… after contacting the employer to ask the kinds of
questions that it anticipates that you’d like to know: about compensation, work/life balance, training and advancement opportunities, or whatever it thinks matter to you.
We quickly find ourselves colliding with ethical questions again, of course: is it okay that those who have access to more-sophisticated digital assistants will have an advantage?
Should a robot be required to identify itself as a robot when acting on behalf of a human? I don’t have the answers.
But one thing I think we can say, based on our history of putting hacky solutions atop our existing ways of working and the direction in which digital assistants are headed, is
that voice interfaces are going to dominate chatbot development a while… even where the machines end up talking to one another!
While rooting through our attic, Ruth‘s brother Owen just found a mystery cable. It almost certainly belongs to me (virtually all of the
cables in the house, especially the unusual ones, do), but this one is a mystery to me.
End #1 of the cable is a 13-pin male serial connection with 6 connected pins, spring-loaded. It seems to be designed to screw in at one end. The screw is worn.
The more I look at it, the more I feel like I’m slowly going mad, as if the cable is some kind of beast from the Lovecraftian Cable Dimension which mortal minds were not meant to
comprehend. It’s got three “ends” and is clearly some kind of signal combining (or separating) cable, but it doesn’t look like anything I’ve ever seen before (and don’t forget, I
probably own it).
On the other side of the split, end #2 of the cable terminates in a fine metal mesh (perhaps concealing a microphone, small speaker, or temperature/humidity sensor). It has a
“push-to-talk” style clicker switch and a “tie clip” on it.
Every time I look at it I have a new idea of what it could be. Some kind of digital dictophone or radio mic connector? Part of a telephone headset? Weather monitoring hardware? A set of
converters between two strange and unusual pieces of hardware? But no matter what I come up with, something doesn’t add up? Why only 6 pins? Why the strange screw-in connector?
Why the clicker switch? Why the tie clips? Why “split” the output (let alone have cables of different lengths)?
End #3 looks like a fibreoptic audio terminator. Or perhaps a part of an earpiece. It, too, has a “tie clip” on (do I clip it to… my ear?)
In case it helps, I’ve made a video of it. You’ll note that I use the word “thingy” more times than might perhaps be justified, but I’ve been puzzling over this one for a while:
Can you help? Can you identify this mystery cable? Prize for the correct answer!
I wasn’t fast enough to get an order in on the first (hugely-oversubscribed) print run and had to wait on both the reprint plus international shipping.
This self-proclaimed “better Bundo book” tells a different (educational and relevant) story: in it, Marlon Bundo falls in love with another boy rabbit but their desire to get married is
hampered by the animals’ leader, the Stink Bug, who proclaims that “boy rabbits can’t marry boy rabbits; boy rabbits have to marry girl rabbits!” With the help of the other animals, the
rabbits vote-out the Stink Bug, get married, and go on a lovely bunnymoon… a cheery and uplifting story and, of course, a distinctly trollish way to piss off the (clearly anti-LGBT) Mike Pence. This evening, I decided to offer it as a bedtime story to our little
bookwork. At four years old, she’s of an age at which the highly-hetronormative narratives of the media to which she’s exposed might be only-just beginning to sink in, so I figured this
was a perfect vehicle to talk about difference, diversity, and discrimination. Starting school later this year means that she’s getting closer to the point where she may go from
realising that her family is somewhat unusually-shaped to discovering that some people might think that “unusual” means “wrong”, so this is also a
possible step towards thinking about her own place in the world and what other people make of it.
Our little bookworm, along with bookworm-junior and their mother.
Her initial verdict was that it was “sweet”, and that she was glad that the Stink Bug was vanquished and that Marlon and Wesley got to live together happily-ever-after. I explained that
while the story was made-up, a lot of what it was talking about was something that really happens in this world: that some people think that boys should not marry boys and that girls
should not marry girls, even if they love them, and that sometimes, if those people get to be In Charge then they can stop those people marrying who they love. I mentioned that in our
country we were fortunate enough that boys can marry boys and girls can marry girls, if they want to, but that there are places where that’s not allowed (and there are
even some people who think it shouldn’t be allowed here!). And then I asked her what she thought.
I normally reserve my “on this day” posts to look back at my own archived content, but once in a while I get a moment of nostalgia for something of
somebody else’s that “fell off the web”. And so I bring you something you probably haven’t seen in over a decade: Paul and Jon‘s Birmingham Egg.
Is this honestly so different from the kind of crap that most of our circle of friends ate in 2005?
It was a simpler time: a time when YouTube was a new “fringe” site (which is probably why I don’t have a surviving copy of the original video) and not yet owned by Google, before
Facebook was universally-available, and when original Web content remained decentralised (maybe we’re moving back in that
direction, but I wouldn’t count on it…). And only a few days after issue 175 of the b3ta newsletter wrote:
* BIRMINGHAM EGG - Take 5 scotch eggs, cut in
half and cover in masala sauce. Place in
Balti dish and serve with naan and/or chips.
We'll send a b3ta t-shirt to anyone who cooks
this up, eats it and makes a lovely little
photo log / write up of their adventure.
Sure, this looks like the kind of thing that seems like a good idea when you’re a student.
It was a simpler time, when, having fewer responsibilities, we were able to do things like this “for the
lulz”. But more than that, it was still at the tail-end of the era in which individuals putting absurd shit online was still a legitimate art form on the Web. Somewhere along the
way, the Web got serious and siloed. It’s not all a bad thing, but it does mean that we’re publishing less weirdness than we were back
then.
The Azure image processing API is a software tool powered by a neural net, a type of artificial intelligence that attempts to replicate a particular model of how (we believe)
brains to work: connecting inputs (in this case, pixels of an image) to the entry nodes of a large, self-modifying network and reading the output, “retraining” the network based on
feedback from the quality of the output it produces. Neural nets have loads of practical uses and even more theoretical ones, but Janelle’s article was about how confused the
AI got when shown certain pictures containing (or not containing!) sheep.
There are probably sheep in the fog somewhere, but they’re certainly not visible.
The AI had clearly been trained with lots of pictures that contained green, foggy, rural hillsides and sheep, and had come to
associate the two. Remember that all the machine is doing is learning to associate keywords with particular features, and it’s clearly been shown many pictures that “look like” this
that do contain sheep, and so it’s come to learn that “sheep” is one of the words that you use when you see a scene like this. Janelle took to Twitter to ask for pictures of sheep in unusual places, and the Internet obliged.
When the sheep is held by a child, it becomes a “dog”.
Many of the experiments resulting from this – such as the one shown above – work well to demonstrate this hyper-focus on context: a sheep up a tree is a bird, a sheep on a lead
is a dog, a sheep painted orange is a flower, and so on. And while we laugh at them, there’s something about them that’s actually pretty… “human”.
Our eldest really loves cats. Also goats, apparently. Azure described this photo as “a person wearing a costume”, but it did include keywords such as “small”, “girl”, “petting”, and…
“dog”.
I say this because I’ve observed similar quirks in the way that small children pick up language, too (conveniently, I’ve got a pair of readily-available subjects, aged 4 and 1, for my
experiments in language acquisition…). You’ve probably seen it yourself: a toddler whose “training set” of data has principally included a suburban landscape describing the first cow
they see as a “dog”. Or when they use a new word or phrase they’ve learned in a way that makes no sense in the current context, like when our eldest interrupted dinner to say, in the
most-polite voice imaginable, “for God’s sake would somebody give me some water please”. And just the other day, the youngest waved goodbye to an empty room, presumably because
it’s one that he often leaves on his way up to bed
“A cat lying on a blanket”, says Azure, completely overlooking the small child in the picture. I guess the algorithm was trained on an Internet’s worth of cat pictures and didn’t see
as much of people-with-cats.
For all we joke, this similarity between the ways in which artificial neural nets and small humans learn language is perhaps the most-accessible evidence that neural nets are a
strong (if imperfect) model for how brains actually work! The major differences between the two might be simply that:
Our artificial neural nets are significantly smaller and less-sophisticated than most biological ones.
Biological neural nets (brains) benefit from continuous varied stimuli from an enormous number of sensory inputs, and will even self-stimulate (via, for example, dreaming) –
although the latter is something with which AI researchers sometimes experiment.
“Ca’! Ca’! Ca’!” Maybe if he shouts it excitedly enough, one of the cats (or dogs, which are for now just a special kind of cat) he’s spotted will give in and let him pet it. But I
don’t fancy his chances.
Things we take as fundamental, such as the nouns we assign to the objects in our world, are actually social/intellectual constructs. Our minds are powerful general-purpose computers,
but they’re built on top of a biology with far simpler concerns: about what is and is-not part of our family or tribe, about what’s delicious to eat, about which animals are friendly
and which are dangerous, and so on. Insofar as artificial neural nets are an effective model of human learning, the way they react to “pranks” like these might reveal underlying truths
about how we perceive the world.
Just want to play my game without reading this whole post? Play the game here – press a key, mouse button, or touch the screen to fire the
thrusters, and try to land at less than 4 m/s with as much fuel left over as possible.
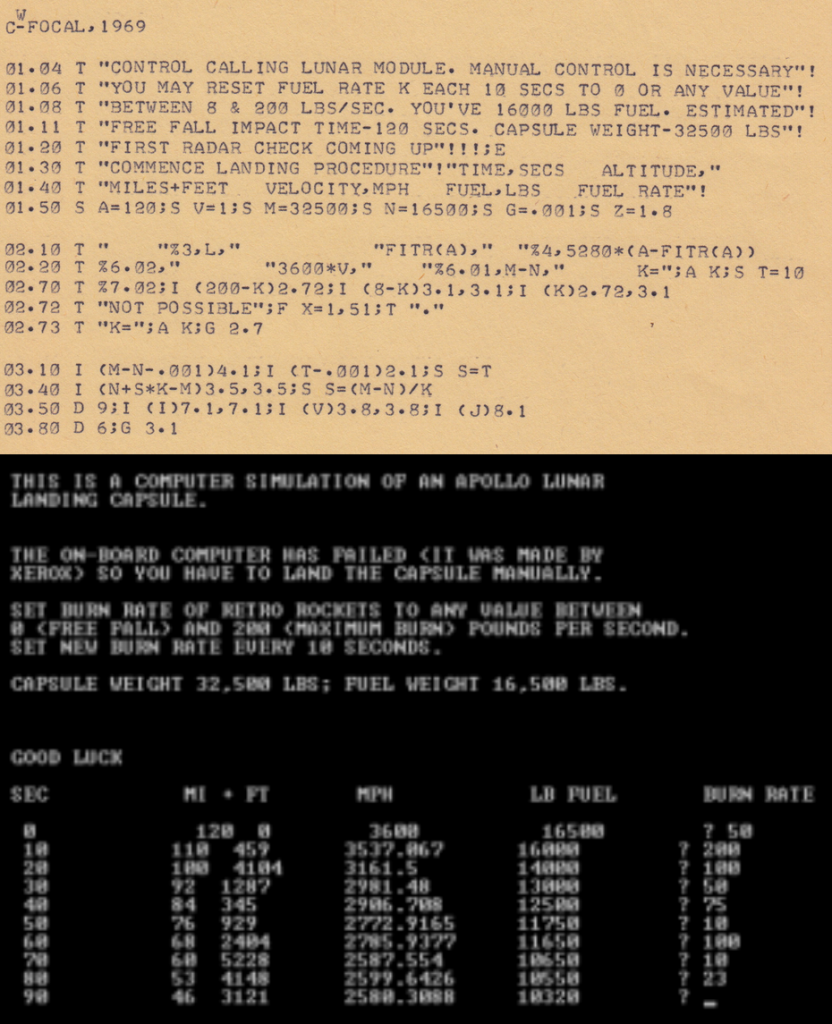
In 1969, when all the nerds were still excited by sending humans to the moon instead of flinging cars around the sun, the hottest video game was Rocket (or Lunar) for the PDP-8. Originally implemented in FOCAL by high school student Jim Storer and soon afterwards ported to BASIC (the other dominant language to come as
standard with microcomputers), Rocket became the precursor to an entire genre of video games called “Lunar Lander games“.
Like many pieces of microcomputer software of the time, Rocket was distributed as printed source code that you’d need to carefully type in at the other end.
The aim of these games was to land a spacecraft on the moon or similar body by controlling the thrust (and in some advanced versions, the rotation) of the engine. The spacecraft begins
in freefall towards the surface and will accelerate under gravity: this can be counteracted with thrust, but engaging the engine burns through the player’s limited supply of fuel.
Furthermore, using fuel lowers the total mass of the vessel (a large proportion of the mass of the Apollo landers was fuel for use in the descent stage) which reduces its inertia,
giving the engine more “kick” which must be compensated for during the critical final stages. It sounds dry and maths-y, but I promise that graphical versions can usually be played
entirely “by eye”.
Atari’s 1979 adaptation is perhaps the classic version you’d recognise, although its release was somewhat overshadowed by their other vector-graphics space-themed release in 1979:
Asteroids.
Let’s fast-forward a little. In 1997 I enrolled to do my A-levels at what was then called Preston College, where my Computing tutor was a chap
called Kevin Geldard: you can see him at 49 seconds into this hilariously low-fi video which I guess must have been originally shot on
VHS despite being uploaded to YouTube in 2009. He’s an interesting chap in his own right whose contributions to my career in computing deserve their own blog post, but for the time
being all you need to know is that he was the kind of geek who, like me, writes software “for fun” more often than not. Kevin owned a Psion 3 palmtop – part of a series of devices with
which I also have a long history and interest – and he taught himself to program OPL by reimplementing a favourite game of his younger years on it: his take on the classic mid-70s-style graphical Lunar Lander.
I never owned a Psion Series 3 (pictured), but I bought a Series 5mx in early 2000 out of my second student loan cheque, ultimately wrote most of my undergraduate dissertation using
it, and eventually sold it to a collector in about 2009 for almost as much as I originally paid for it. The 5mx was an amazing bit of kit. But I’ll blog about that another day, I
guess.
My A-level computing class consisted of a competitive group of geeky lads, and we made sort-of a personal extracurricular challenge to ourselves of re-implementing Kevin’s take on
Lunar Lander using Turbo Pascal, the primary language in which our class was taught. Many hours out-of-class were spent
in the computer lab, tweaking and comparing our various implementations (with only ocassional breaks to play Spacy, CivNet, or my adaptation of LORD2): later, some of us would extend our competition by
going on to re-re-implement in Delphi, Visual Basic, or Java, or by adding additional levels relating to orbital rendezvous or landing on other planetary bodies. I was quite
proud of mine at the time: it was highly-playable, fun, and – at least on your first few goes – moderately challenging.
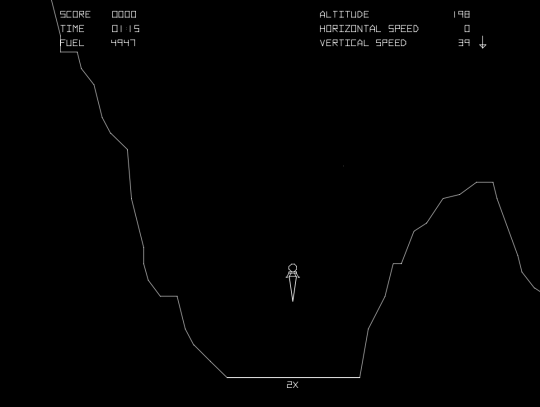
I sometimes wonder what it would have looked like if I’d have implemented my 1997 Lunar Lander today. So I did.
Always game to try old new things, and ocassionally finding time between the many things that I do to code, I decided to expand upon my recently-discovered
interest in canvas coding to bring back my extracurricular Lunar Lander game of two decades ago in a modern format. My goals were:
A one-button version of a classic “straight descent only” lunar lander game (unlike my 1997 version, which had 10 engine power levels, this remake has just “on” and “off”)
An implementation based initially on real physics (although not necessarily graphically to scale)… and then adapted as necessary to give a fun/playability balance that feels good
Runs in a standards-compliant browser without need for plugins: HTML5, Canvas, Javascript
Adapts gracefully to any device, screen resolution, and orientation with graceful degredation/progressive enhancement
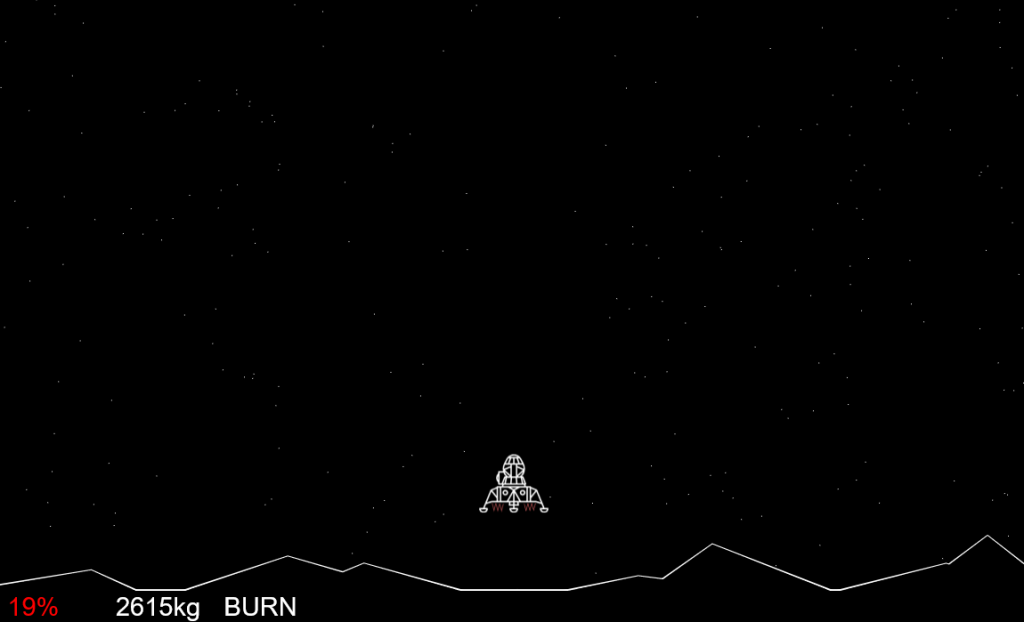
You can have a go at my game right here in your web browser! The aim is to reach the ground travelling at a velocity of no more than 4 m/s
with the maximum amount of fuel left over: this, if anything, is your “score”. My record is 52% of fuel remaining, but honestly anything in the 40%+ range is very good. Touch the screen
(if it’s a touchscreen) or press a mouse button or any key to engage your thrusters and slow your descent.
“Houston, the Eagle has landed.” Kerbal Space Program, it isn’t. Here’s a very good landing: 3 m/s with 48% of the fuel tank remaining.
And of course it’s all open-source, so you’re more than welcome to take it, rip it apart, learn from it, or make something better out
of it.
In addition to the pension I get from my “day job” employer, I maintain a pension pot with a separate private provider which I top up with
money from my freelance work. I logged in to that second pension provider’s (reliably shonky, web-standards-violating) website about a month ago and found that I couldn’t do anything
because they’d added a new mandatory field to the “My Profile” page and I wasn’t allowed to do anything else until I’d filled it out. No problem, I thought: a few seconds won’t kill me.
If I’m lucky, I might be able to afford to retire this century.
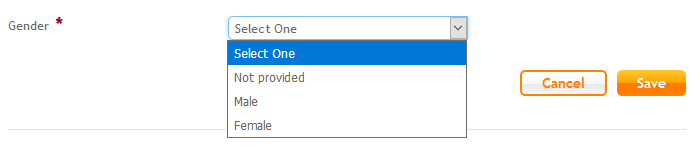
The newly-added field turned out to be “Gender”, and as it was apparently unacceptable to leave this unspecified (as would be my preference: after all,
I’ll certainly be retiring after November 2018, when gender will cease to have any legal bearing on retirement age), I clicked the drop-down to see what options they’d provided. “Not
provided”, “Male”, and “Female” were the options: fine, I thought, I’ll just pick “Not provided” and be done with it. And for a while, everything seemed fine.
Leaving the field as the undefined “Select One” option wasn’t valid (I tried!) so I changed the value.
Over three weeks later I received a message from them saying that they hadn’t yet been able to action the changes to my profile because they hadn’t yet received hard-copy documentary
evidence from me. By this point, I’d forgotten about the minor not-really-a-change change I’d made and assumed that whatever they were on about must probably be related to my unusual name. I sent a message back to them to ask exactly what kind of evidence they needed to see. And that’s when things got weird.
I received a message back – very-definitely from a human – to say that what they needed to see what evidence of my gender change. That is, my change of gender from “not specified” to
“not provided”.
Fluttershy gets it.
They went on to suggest that I could get my doctor to certify a letter verifying my gender change. Needless to say, I haven’t made an appointment to try to get my GP to sign a document
that confirms that my gender is “not provided”. Instead, I’ve emailed back to ask them to read what they just asked me for again, and perhaps this time they’ll engage both
brain cells and try to think about what they’re actually asking, rather than getting tied up in knots in their own bureaucratic process. Let’s see how that goes.
Seeing as it’s almost Valentine’s Day and by way of proof that I’m not always so serious as to write about important topics like WordPress’s CAPTCHA implementation or
how I became a brony, here are some of the highlights of a conversation that Ruth and I just
had (tapping in to our inner 12-year-olds, I guess: some alcohol might have been involved) about song lyrics that are immeasurably improved if you replace the word “love” with “butt”.
Here are some of my favourites:
Greatest Butt Of All – Whitney Houston
Can You Feel The Butt Tonight? – Elton John
Shower Me With Your Butt – Surface
Eww.
Big Butt – Fleetwood Mac
I Would Do Anything For Butt (But I Won’t Do That) – Meat Loaf
Too Much Butt Will Kill You
“Torn between the butter and the butt you leave behind.” Yes, you can totally turn “lover” into “butter”, but it’s the addition of the word “behind” that made me snortle.
Thinking Out Loud – Ed Sheeran
“Will your mouth still remember the taste of my butt? Will your eyes still smile from your cheeks?”
Butt Song For A Vampire – Annie Lennox
Bleeding Butt – Leona Lewis
“Keep bleeding. Keep, keep bleeding, butt. You cut me open”
How Deep Is Your Butt? – Bee Gees
Addicted to Butt – Robert Palmer
“It’s closer to the truth to say you can’t get enough. You know you’re gonna have to face it: you’re addicted to butt.”
One – U2
“Did I disappoint you, or leave a bad taste in your mouth? You act like you never had butt and you want me to go without.”
Lay All Your Butt On Me – ABBA
Butt Stinks – The J. Geils Band
Tainted Butt – Soft Cell
Can’t Help Falling In Butt – Elvis Prestley
Okay, now I’ve got that out of my system we can carry on as normal.
One of the most-popular WordPress plugins is Jetpack, a product of Automattic (best-known for providing the widely-used WordPress hosting service “WordPress.com“). Among Jetpack’s
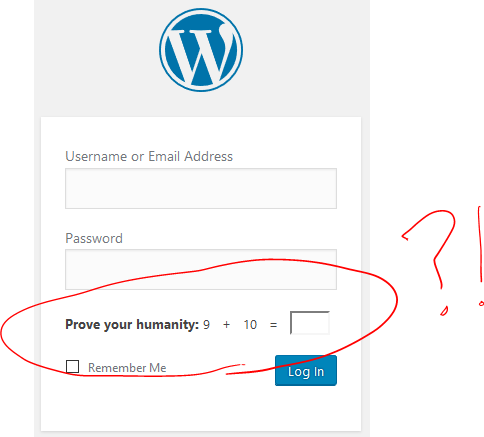
features (many of which are very good) is Jetpack Protect which adds – among other things – the possibility for a CAPTCHA to appear on your login pages. This feature is slightly worse than pointless as it makes
it harder for humans to log in but has no significant impact upon automated robots; at best, it provides a false sense of security and merely frustrates and slows down legitimate human
editors.
Thanks, WordPress, for slowing me down with a CAPTCHA that a robot can solve more-easily than a human.
“Proving your humanity”, as you’re asked to do, is a task that’s significantly easier for a robot to perform than a human. Eventually, of course, all tests of this nature seem likely to fail as robots become smarter than humans
(especially as the most-popular system is specifically geared towards training robots), but that’s hardly an excuse for inventing a system
that was a failure from its inception. Jetpack’s approach is fundamentally flawed because it makes absolutely no effort to disguise the challenge in a way that humans are able to read
any-differently than robots. I’ll demonstrate that in a moment.
Don’t just disable this, though! Other “Protect” features make sense. If only you could disable just the one that doesn’t…
A while back, a colleague of mine network-enabled Jetpack Protect across a handful of websites that I occasionally need to log into, and it bugged me that it ‘broke’ my password safe’s
ability to automatically log me in. So to streamline my workflow – as well as to demonstrate quite how broken Jetpack Protect’s CAPTCHA is, I’ve written a userscript that you can install into your web browser that will
completely circumvent it, solving the maths problems on your behalf so that you don’t have to. Here’s how to use it:
Install a userscript manager into your browser if you don’t have one already: I use Tampermonkey, but it ought to work with almost any of
them.
From now on, whenever you go to a page whose web path begins with “/wp-login.php” that contains a Jetpack Protect maths problem, the answer will be automatically calculated and
filled-in on your behalf. The usual userscript rules apply: if you don’t trust me, read the source code (there are really only five lines to check) and disable automatic updates for it
(especially as it operates across all domains), and feel free to adapt/improve however you see fit. Maybe if we can get enough people using it Automattic will fix this
half-hearted CAPTCHA – or at least give us a switch to disable it in the first
place.
Update: 15 October 2018 – the latest version of Jetpack makes an insignificant change to this CAPTCHA; version 1.2 of this script (linked above) works around the change.
On this day in 2004… Troma Night XXI took place at The Flat. Six people were in attendance: Claire, Paul, Kit, Bryn, (Strokey) Adam and I and, unusually – remember that the digital cameras in phones were still appalling – I took pictures of everybody who showed up.
Cue exclamations of “didn’t we all look young”, etc.
Troma Night was, of course, our weekly film night back in Aberystwyth (the RockMonkey wiki once described it as “fun”). Originally launched as a one-off and then a maybe-a-few-off event with a theme of watching films produced (or
later: distributed) by Troma Entertainment, it quickly became a regular event with a remit to watch “all of the best and the worst films ever made”.
Expanding into MST3K, the IMDb “bottom 250”, and once in a while a good film, we eventually spent
somewhere over 300 nights on this activity (you can relive our 300th, if you like!)
and somehow managed to retain a modicum of sanity.
Copious quantities of alcohol might have been part of our survival strategy, as evidenced by these pictures from Troma Night V and Troma Night VI.
Troma Night XXI was among those captured by the Troma Night Webcam, streamed out to the Internet in 1-megapixel, 4 frames per second glory (when it worked).
In addition to running for over 300 weeks, Troma Night became, for many of us, a central facet of our social lives. The original attendees were all volunteers at Aberystwyth Nightline, but we were later joined by their friends, lovers, housemates… and by Liz‘s dates (who after meeting all of her friends, we usually never saw again). We quickly developed our own traditions and ideas, such as:
Pizzas like the Alec Special – a Hollywood Special (ham, pepperoni, beef, mushrooms, green peppers, onions,
sweetcorn) but without the onions and with pineapple substituted in instead – and the Pepperoni Feast particularly enjoyed by our resident vegetarian,
For those who – like me – insist that our regular Hollywood Pizza got greasier over this years, these photos from Troma Night VI.5 are pretty damning. Maybe it’s just that our tastes
changed.
Paul spontaneously throwing a sponge out of the window to mark the beginning of the evening’s activities,
Alec bringing exactly one more can of Grolsch than he’s capable of drinking and leaving the remainder in the fridge to be consumed by Kit at the start of the subsequent event,
A fight over the best (or in some cases only) seats in Claire and I’s various small (and cluttered) homes: we once got 21 people into the living room at The Flat, but it wasn’t
exactly pleasant,
Becoming such a regular customer to Hollywood Pizza that they once phoned us when we hadn’t placed an order in a timely fashion, on another ocassion turned up
with somebody else’s order because it “looked like the kind of thing we usually ordered”, and at least one time were persuaded to deliver the pizza directly up to the living room
and to each recipient’s lap (you can’t get much better delivery service than that).
Decisions about how Claire and I would lay out our furniture were eventually influenced directly by maximising the efficiency of our seating plan. This picture, from Troma Night IV,
makes it seem quite spacious and relaxed compared to later nights.
And I still enjoy the occasional awful film. I finally got around to watching Sharknado the other month, and my RiffTrax account’s library grows year on year. One of my reward card accounts is still under the name of Mr. Troma Knight. So I suppose that Troma Night
lives on in some the regulars, even if we don’t make ourselves suffer of a weekend in quite the
same ways as we once did.
To pre-empt any gatekeeping bronies in their generally-quite-nice society who want to tell me that I’m no “true” fan: save your breath, I already know. I’m not
actually claiming any kinship with the brony community. But what’s certainly true is that I’ve gained a level of appreciation for My Little Pony: Friendship is Magic that certainly goes beyond that of most people who aren’t fans of
the show (or else have children who are), and I thought I’d share it with you. (I can’t promise that it’s not just Stockholm syndrome, though…)
Twilight Sparkle and Rainbow Dash. Their friendship is magic, and yours can be too.
Ignoring the fact that I owned, at some point in the early 1980s, a “G1” pony toy (possibly Seashell) from the original, old-school My Little Pony, my first introduction to the modern series came in around 2010
when, hearing about the surprise pop culture appeal of the rebooted franchise, I watched the first two episodes, Friendship is Magic parts one and two: I’m aware that after I mentioned it to
Claire, she went on to watch most of the first season (a pegasister in
the making, perhaps?). Cool, I thought: this is way better than most of the crap cartoons that were on when I was a kid.
? Chortle at the kooky… snortle at the spooky… ?
And then… I paid no mind whatsoever to the franchise until our little preschooler came home from the library, early in 2017, with a copy of an early reader/board book called Fluttershy and the Perfect Pet. This turns out to be a re-telling of the season 2 episode May The Best Pet Win!, although of course I only know that with hindsight. I casually mentioned to her that there was a TV
series with these characters, too, and she seemed interested in giving it a go. Up until that point her favourite TV shows were probably PAW Patrol and Thomas the Tank Engine & Friends, but
these quickly gave way to a new-found fandom of all things MLP.
No ponies were harmed in the staging of this apparent massacre.
The bobbin’s now watched all seven seasons of Friendship is Magic plus the movie and so, by proxy – with a few exceptions where for example JTA was watching an episode with her – have I. And it’s these exceptions where I’d “missed” a few
episodes that first lead to the discovery that I am, perhaps, a “closet Brony”. It came to me one night at the local pub that JTA and I
favour that when we ended up, over our beers, “swapping notes” about the episodes that we’d each seen in order to try to make sense of it all. We’re each routinely roped into playing
games for which we’re expected to adopt the role of particular ponies (and dragons, and changelings, and at least one centaur…), but we’d both ended up getting confused as to
what we were supposed to be doing at some point or another on account of the episodes of the TV show we’d each “missed”. I’m not sure how we looked to the regulars – two 30-something
men sitting by the dartboard discussing the internal politics and friendship dramas of a group of fictional ponies and working out how the plots were interconnected – but if anybody
thought anything of it, they didn’t say so.
JTA and I’s local is among the most distinctly “village pub”-like pubs I’ve ever visited.
By the time the movie was due to come out, I was actually a little excited about it, and not even just in a vicarious way (I would soon be disappointed, mind: the movie’s mediocre at best, but at the three-year-old I took to the cinema was impressed, at least, and the “proper”
bronies – who brought cupcakes and costumes and sat at the back of the cinema – seemed to enjoy themselves, so maybe I just set my expectations too high). Clearly something in the TV
show had sunk its hooks into me, at least in a minor way. It’s not that I’d ever watch an episode without the excuse of looking after a child who wanted to do so… but I also
won’t deny that by the end of The Cutie Remark, Part One I wanted to make sure that I was the one to be
around when the little ‘un watched the second part! How wouldStarlight Glimmer be defeated?
? My little popcorn, my little popcorn… ?
At least part of the appeal is probably that the show is better than most other contemporary kids’ entertainment, and as anybody with young children knows, you end up exposed to plenty
of it. Compare to PAW Patrol (the previous obsession in our household), for example. Here we have two shows that each use six animated animals to promote an ever-expanding toy
line. But in Friendship is Magic the ponies are all distinct and (mostly) internally-consistent characters with their own individual identity, history, ambitions, likes and
dislikes that build a coherent whole (and that uniquely contributes to the overall identity of the group). In PAW Patrol, the pups are almost-interchangeable in identity
(and sometimes purpose), each with personality quirks that conveniently disappear when the plot demands it
(Marshall suddenly and without announcement stops being afraid of heights when episodes are released to promote the new “air pup” toys, and Chase’s allergy to cats somehow only
manifests itself some of the time and with some cats) and other characteristics that feel decidedly… forced. MLP‘s writing isn’t
great by any stretch of the imagination, but compared to the other things I could be watching with the kids it’s spectacular!
Seriously, Zuma: what are you FOR?
And compare the morality of the two shows. Friendship is Magic teaches us the values of friendship (duh), loyalty, trust, kindness, and respect, as well as carrying a strong
feminist message that young women can grow up to be whatever the hell they want to be. Conversely, the most-lasting lesson I’ve taken from watching PAW Patrol (and I’ve
seen a lot of that, too) is that police and spy agencies are functionally-interchangeable which very-much
isn’t the message I want our children to take away from their screen time.
Not all lessons are good lessons. I’m talking to you, Rarity.
It’s not perfect, of course. The season one episode A Dog And Pony Show‘s enduring moral, in which unicorn pony
Rarity is kidnapped by subterranean dogs and made to mine gemstones (she has a magical talent for divining for seams of them), seems to be that the best way for a woman to get her way
over men is to make a show of whining incessantly until they submit, and to win arguments by deliberately misunderstanding their statements as something that she can take offence to.
That’s not just a bad ethical message, it also reinforces a terrible stereotype and thoroughly undermines Rarity’s character! Thankfully, such issues are few and far between and on the
whole the overwhelming message of My Little Pony is one of empowerment, equality, and fairness.
If Mr. Labrador had a Twitter account, this episode of Peppa Pig would have put him at the receiving end of a whole Internetload of feminist complaints.
For the most part, Equestria is painted as a place where gender doesn’t and shouldn’t matter, which is fantastic! Compare to the Peppa
Pig episode (and accompanying book) called Funfair in which Mummy Pig
is goaded into participating in an archery competition by being told that “women are useless” at it, because it’s a “game of skill”. And while Mummy Pig does surprise the
stallholder by winning, that’s the only rebuff: it’s still presented as absolutely acceptable to make skill judgements based on gender – all that is taught is that Mummy Pig is
an outlier (which is stressed again when she wins at a hammer swing competition, later); no effort is made to show that it’s wrong to express prejudice over stereotypes. Peppa Pig is
full of terrible lessons for children even if you choose to ignore the time the show told Australian kids to pick up and play with spiders.
Princess Luna knows what I should have been doing instead of writing this post.
I probably know the words to most of the songs that’ve had album releases (we listen to them in the car a lot; unfortunately a voice from the backseat seems to request the detestable Christmas album more than any of the far-better ones). I’m probably the second-best person in my house at
being able to identify characters, episodes, and plotlines from the series. I have… opinions on the portrayal of Twilight Sparkle’s character in the script of the movie.
Also, it might be the case that I own more than one article of geeky My Little Pony-themed clothing.
I don’t describe myself as a Brony (not that there’d be anything wrong if I did!), but I can see how others might. I think I get an exemption for not having been to a convention or read
any fanfiction or, y’know, watched any of it without a child present. I think that’s the key.



 In Android’s Settings > Network & Internet,
disable WiFi. Then, under Mobile Network > Access Point Names > {Default access point, probably T-Mobile} set Proxy to the local IP address of your computer and Port to 8888. Now
all traffic will go over the virtual cellular data connection which uses the proxy server you’ve configured in Fiddler.
In Android’s Settings > Network & Internet,
disable WiFi. Then, under Mobile Network > Access Point Names > {Default access point, probably T-Mobile} set Proxy to the local IP address of your computer and Port to 8888. Now
all traffic will go over the virtual cellular data connection which uses the proxy server you’ve configured in Fiddler.