In sympathy for our flood situation, my sister baked and posted us a big batch of her fantastic raisin & oatmeal cookies.

I’ve eaten like six of them already. Turns out I stress-eat. Who knew?
In sympathy for our flood situation, my sister baked and posted us a big batch of her fantastic raisin & oatmeal cookies.
I’ve eaten like six of them already. Turns out I stress-eat. Who knew?
Nineteen days after my house flooded, causing extensive damage on the ground floor, the insurance company has finally accepted the claim and is willing to pay for our temporary accommodation in the meantime (a few days in a hotel, a few days with friends although that’s not paid-for, four weeks in two different holiday lets), although we’re still waiting for their thumbs-up on a proposal for a ~6-month let of a house to live in while our floors are replaced and our kitchen rebuilt and whatnot.

Meanwhile, yesterday a surveyor came around and looked at all of our walls. Everything still feels like it’s taking a very long time. I appreciate that insurance companies are a maze of bureaucracy and procedure, but from “this side” of the table – living and working out of strange places, never really feeling “unpacked” but without it being a holiday – it’s all a bit of a drag!
Last night I was chatting to my friend (and fellow Three Rings volunteer) Ollie about our respective workplaces and their approach to AI-supported software engineering, and it echoed conversations I’ve had with other friends. Some workplaces, it seems, are leaning so-hard into AI-supported software development that they’re berating developers who seem to be using the tools less than their colleagues!
That’s a problem for a few reasons, principal among them that AI does not make you significantly faster but does make you learn less.1. I stand by the statement that AI isn’t useless, and I’ve experimented with it for years. But I certainly wouldn’t feel very comfortable working somewhere that told me I was underperforming if, say, my code contributions were less-likely than the average to be identifiably “written by an AI”.
Even if you’re one of those folks who swears by your AI assistant, you’ve got to admit that they’re not always the best choice.
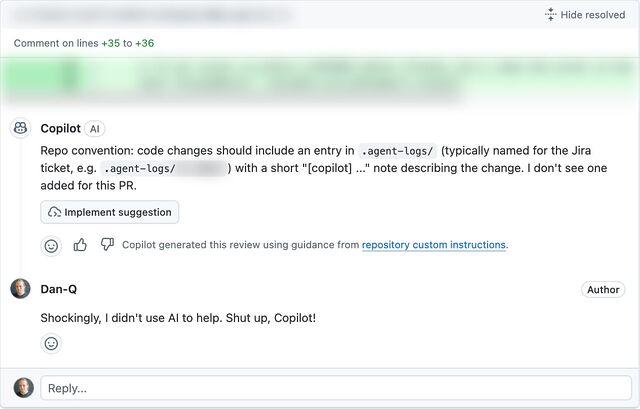
I spoke to another friend, E, whose employers are going in a similar direction. E joked that at current rates they’d have to start tagging their (human-made!) commits with fake AI agent logs in order to persuade management that their level of engagement with AI was correct and appropriate.3
Supposing somebody like Ollie or E or anybody else I spoke to did feel the need to “fake” AI agent logs in order to prove that they were using AI “the right way”… that sounds like an excuse for some automation!
I got to thinking: how hard could it be to add a git hook that added an AI agent’s “logging” to each commit, as if the work had been done by a robot?4
Turns out: pretty easy…

asciinema + svg-term remains awesome.
Here’s how it works (with source code!). After you make a commit, the post-commit hook creates a file in
.agent-logs/, named for your current branch. Each commit results in a line being appended to that file to say something like [agent] first line of your commit
message, where agent is the name of the AI agent you’re pretending that you used (you can even configure it with an array of agent names and it’ll pick one at
random each time: my sample code uses the names agent, stardust, and frantic).
There’s one quirk in my code. Git hooks only get the commit message (the first line of which I use as the imaginary agent’s description of what it did) after the commit has
taken place. Were a robot really used to write the code, it’d have updated the file already by this point. So my hook has to do an --amend commit, to
retroactively fix what was already committed. And to do that without triggering itself and getting into an infinite loop, it needs to use a temporary environment variable.
Ignoring that, though, there’s nothing particularly special about this code. It’s certainly more-lightweight, faster-running, and more-accurate than a typical coding LLM.
Sure, my hook doesn’t attempt to write any of the code for you; it just makes it look like an AI did. But in this instance: that’s a feature, not a bug!
1 That research comes from Anthropic. Y’know, the company who makes Claude, one of the most-popular AIs used by programmers.
2 Do I write that much like an AI? Relevant XKCD.
3 Using “proportion of PRs that used AI” as a metric for success seems to me to be just slightly worse than using “number of lines of code produced”. And, as this blog post demonstrates, the former can be “gamed” just as effectively as the latter (infamously) could.
4 Obviously – and I can’t believe I have to say this – lying to your employer isn’t a sensible long-term strategy, and instead educating them on what AI is (if anything) and isn’t good for in your workflow is a better solution in the end. If you read this blog post and actually think for a moment hey, I should use this technique, then perhaps there’s a bigger problem you ought to be addressing!
Hurrah! I just made my first successful submission to Curious Cones, a weblog collecting photographs of traffic cones spotted in unusual places.
I spotted this cone while the younger child and I took a walk to the next-nearest village to our temporary accommodation, in order to find a geocache, tag some benches for OpenBenches, and have a cafe brunch.
Anyway: if you’re not following Curious Cones, it’s exactly as delightful as you might expect.
This checkin to GCBAJC3 Cache me if you can, Jeremy reflects a geocaching.com log entry. See more of Dan's cache logs.
Despite being relatively ‘local’ – only half a mile away, and fans of the show – it took until this morning before the family and I actually came to up visit Clarkson’s Farm. We’re even-more-local but now, after a flood made our house uninhabitable and we moved, temporarily, to a holiday let just up the road.

This morning we visited Diddly Squat for a round of sausage sandwiches, after which the youngest child and I decided to make a run for this nearby geocache. The kid put his finger right on the cache before I’d even had a chance to take a look for it!

Log signed, and a car full of Hawkstone Lager acquired, we were all done. TFTC!
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
So it was inevitable that Apple would add video support to their podcasting apps. And it makes sense for Apple to update the technical underpinnings; the assumptions that were made when designing podcasts over two decades ago aren’t really appropriate for many contemporary uses. For example, back then, by default an entire podcast episode would be downloaded to your iPod for convenient listening on the go, just like songs in your music library. But downloading a giant 4K video clip of an hour-long podcast show that you might not even watch, just in case you might want to see it, would be a huge waste of resources and bandwidth. Modern users are used to streaming everything. Thus, Apple updated their apps to support just grabbing snippets of video as they’re needed, and to their credit, Apple is embracing an open video format when doing so, instead of some proprietary system that requires podcasters to pay a fee or get permission.
The problem, though, is that Apple is only allowing these new video streams to be served by a small number of pre-approved commercial providers that they’ve hand-selected. In the podcasting world, there are no gatekeepers; if I want to start a podcast today, I can publish a podcast feed here on
anildash.comand put up some MP3s with my episodes, and anyone anywhere in the world can subscribe to that podcast, I don’t have to ask anyone’s permission, tell anyone about it, or agree to anyone’s terms of service.…
When I started my pointless podcast, I didn’t need anybody else’s infrastructure or permission. Podcasts are, in the vein of the Web itself (and thanks at least in part to my former coworker Dave Winer), distributed and democratised.
All you need to host a podcast is an RSS file and some audio files. You can put them onto your shared VM. You can put them onto your homelab, You can put them onto a GitHub Pages site. You can put them onto a Neocities site. Or you can shell out for a commercial host and distribute your content across a global network of CDNs, for maximum performance! All of these are podcasts, and they’re all equal from a technical perspective.1
Video podcasts could be the same. Even if – as Apple suggest – HLS is to be mandatory for their player2, that doesn’t necessitate a big corporate third-party provider. Having an “allowlist” of people who can host your podcast’s video is gatekeeping.
Also, it’s… not really podcasting any more. It’s been pointed out that before “platform-exclusive” podcasts (I’m looking at you, Spotify) are not truly podcasts: if it’s not an RSS feed plus some audio files, it’s not a podcast, it’s lightly sparkling audio.
Can the same analogy be used for a podcast player? Is a player that only supports content (in this case, video content) if it’s hosted by a particular partner… not-a-podcast-player? Either way, it’s pretty embarrassing for Apple of all people to turn their back on what makes a podcast a podcast.
1 Technically, my podcast is just a collection of posts that share a ClassicPress “tag”;
ClassicPress gives me “RSS feed of a particular tag” for free, so all I needed to do was (a) add metadata to point to my MP3 files (b) and use a hook to inject the relevant
<enclosure> element into the feed. There are almost certainly plugins that could have done it for me, but it’s a simple task so I just wrote a few lines of PHP code
and called it a day!
2 This is… fine, I guess. I’d rather that an <enclosure> be
more-agnostic. If I only want to provide a single fat MP4 file, then it’s up to my listeners to say “this is shit, why can’t I stream this on my cellular data, I’m gonna listen/watch
somebody else instead”. But even if HLS is required, that’s not difficult: I talked about how to do it last year while
demonstrating variable-aspect-ratio videos (in vanilla HTML)!
This checkin to GC3PQ4P LOL #14 - Taekwondo reflects a geocaching.com log entry. See more of Dan's cache logs.
Unbelievably muddy today Took me so long to pick my way along the boggy path (pictured) that this’ll probably be my only cache of the day. Still, one more for my LOL collection!

This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
I made a massively multiplayer snake game that’s accessible over ssh. Play by running
ssh snakes.runin your terminal…
I’d been speculating for the last month or so what Nolen Royalty had been working on recently that had required such high-performance out of the SSH protocol, but now we know: it’s massively multiplayer snake.
There’s a philosophical thing here that makes it feel different from probably any other Snake game you’ve ever played: it’s a thin client. All of the program runs on the server.
Even slither.io is a split-client. The server is responsible for game state, but rendering the graphics based upon that state runs in JavaScript code in the browser. Not so with snakes.run. The entire output is delivered as terminal rendering instructions.
It’s a reminder of how computing used to be. Dumb terminals sharing a mainframe that would do all of the processing, with only basic I/O being delegated to the terminals, was the dominant way to use computers in the 1960s through 1970s, until the growth of microcomputer technologies made it cost-efficient to make “thick” clients: powerful computers that would sit right on your desk.
It took decades until long-distance networks came to the scale and performance that we see today: fast enough that worldwide thin-client architectures are once again possible. Nowadays, the closest thing most people use to a thin client… is their Web browser, passing messages back and forth. If you’re playing a real-time multiplayer game, though, you expect the processing to be shared between your computer (for low latency graphical output) and the server (for state management and prevention of cheating).
snakes.run tips your expectation on its head. And that’s pretty cool.
It’s also a lot of fun. You should give it ago.
Samsung have been showing off pre-release versions of their new Galaxy S26 range. It’s all pretty same-old predictable changes (and I’m still not really looking for anything to replace my now-five-year-old mobile anyway!), but one feature in particular – one that they’re not even mentioning in their marketing copy – seemed interesting and innovative.
You know those polarising filters you can use to try to stop people shoulder-surfing? Samsung have come up with a software-controlled one.

I assume that this black magic is facilitated by an additional layer between the screen and the glass, performing per-pixel selective polarisation in the same way as a monochrome LCD display might. But the fact that each pixel can now show two images – one to a user directly ahead, superimposed with another (monochrome) one to users with an offset viewing angle, is what interests me: my long-cultivated “hacker mentality” wants to ask “what I can make that do?”
Does the API of this (of this or of any similar or future screens?) provide enough control to manipulate the new layer? And is its resolution identical to that of the underlying screen?
Could “spoilers”, instead of being folded-away behind a <details>/<summary> or ROT13-encoded, say “tilt to reveal” and provide
a physicality to the mechanism of exposure?
Could diagrams embed their own metadata annotations: look at a blueprint from the side to see descriptions, or tilt your phone to see the alt-text on an image?
Can the polarisation layer be expanded to provide a more-sophisticated privacy overlay, such as a fake notification in place of a real one, to act as a honeypot?
Is there sufficient control over the angle of differentiation that a future screen could use eye tracking to produce a virtual lenticular barrier, facilitating a novel kind of autostereoscopic 3D display that works – like a hologram – from any viewing angle?
I doubt I’m buying one of these devices. But I’m very curious about all of these questions!
I don’t know what this machine was (a crane, perhaps), but it’s now been almost-completely reclaimed by nature.

It’s now twelve days since a flood struck my house, causing the ground floor to be submerged under a couple of feet of water and ultimately leading us to kick off an insurance claim process.

And man, a home insurance claim seems to be… slow. For instance, we originally couldn’t even get anybody out to visit us until F-day plus 10 (later improved to F-day plus 7). The insurance company can’t promise that they’ll confirm that they’ll “accept liability” (agree to start paying for anything) until possibly as late as F-day plus 17. Nobody will check for structural damage until F-day plus 191.
Oh, and the insurance company have advised us to look for something like a “12 month let with a 6 month break clause”, which is horrifying. We could be out of our home for up to a year.

Some days it feels like being stuck in a nowhere-place… but simultaneously still having to make the regular everyday stuff keep ticking over. Visiting the house- currently stripped of anything damp and full of drying equipment – feels like stepping onto another planet… or like one of those dreams where you’re somewhere familiar except it’s wrong somehow.
But spending time away from it, “as if” on holiday except-not, is weird too: like we’re accepting the ambiguity; leaning-in to limbo. Especially while we’re waiting for the insurance company to do their initial things, it feels like life is both on hold, and not-allowed to be on hold.

And I worry that by the time they’re committed to paying for us to stay somewhere else for at least half a year, they lose any incentive they might have to contract for speed. There’s no hurry any more. We’re expected to just press pause on our home, but carry on with our lives regardless, pretending that everything’s normal.
So yeah, it’s a weird time.
1 I’m totally committed to this way of counting the progress, which I started on F-day plus 3. I get the feeling like it might be a worthwhile way of keeping track of how long all of this takes.
2 Normally, the younger and older child are able to get to school on foot or via a bus that stops virtually outside our house, each day, so an hour-plus round-trip to their schools and back up to twice a day is a bit of a drag! We’re managing to make it work with a little creativity, but I wouldn’t want to make it a long-term plan!
3 And do some work from there, amidst the jet engine-like noise of the dehumidifiers!
Today, an AI review tool used by my workplace reviewed some code that I wrote, and incorrectly claimed that it would introduce a bug because a global variable I created could “be available to multiple browser tabs” (that’s not how browser JavaScript works).
Just in case I was mistaken, I explained to the AI why I thought it was wrong, and asked it to explain itself.
To do so, the LLM wrote a PR to propose adding some code to use our application’s save mechanism to pass the data back, via the server, and to any other browser tab, thereby creating the problem that it claimed existed.
This isn’t even the most-efficient way to create this problem. localStorage would have been better.
So in other words, today I watched an AI:
(a) claim to have discovered a problem (that doesn’t exist),
(b) when challenged, attempt to create the problem (that wasn’t needed), and
(c) do so in a way that was suboptimal.
Humans aren’t perfect. A human could easily make one of these mistakes. Under some circumstances, a human might even have made two of these mistakes. But to make all three? That took an AI.
What’s the old saying? “To err is human, but to really foul things up you need a computer.”
Today was a long day. Between commuting (the kids to school from our distant flood-evacuation accommodation), work, childcare, insurance wrangling etc., I was pretty tired when I got back “home”. So I came in and lay on the floor.
At which point the dog decided I was a pillow.

 I recently read Taskmaster:
I recently read Taskmaster:
200 220 Extraordinary Tasks for Ordinary People by Alex Horne, and was… underwhelmed.
The meat of the book is a collection of Taskmaster-style tasks either for individuals, or groups, or teams. If you played human jousting, or blindfold doughnut fishing, or leaky-guttering-water-transporter, or any of the other games Ruth and I hosted at Ruth & JTA‘s Stag/Hen Party way back in the day… you’re thinking in the right kinds of ballpark. The activities presented are similar to those shown on the Taskmaster TV show, but with fewer prop requirements.
Perhaps one in ten to one in five of the ideas are genuinely good, but if you want to run your own Taskmaster-like game with your friends… you’re probably best to just adapt some of the games from the show, or sit down for an hour or two with a notepad, a pen, some funny friends, and a supply of whatever chemical stimulates your imagination!
One part of the book I did enjoy, though, was the accounts of parts of the TV show that didn’t make it into the final edit. I really love the TV show, and it was great to get the inside scoop on what tasks worked and didn’t, what got cut and why, and so on. This bit of the book, hidden at the end and using a much smaller typeface as if it’s ashamed to be there, was excellent and highly enjoyable.
Perhaps a future edition could have much more of that – there’ve been many more seasons since the book came out! – and drop some of the less-interesting tasks!
I saw a heron this morning, and it reminded me of a police officer.

Right now, while my house is… not-so-inhabitable… I have a long drive to drop the kids off at school, and this morning it took us alongside the many flooded fields between our temporary accommodation and the various kid drop-offs.
Stopped at traffic lights, I watched a heron land in what would be best-described as a large puddle, rather than in the lake on the other side of the road. The lake, it turns out… was “guarded” by one of those fake heron things.

You’ve seen them, probably. People put them up to discourage territorial birds from visiting and eating all their fish.2 If you haven’t seen them, you might have at least spotted the fake owls, whose purpose is slightly different because they scare off other birds.
Anyway: I found myself thinking… do birds actually fall for this? Like scarecrows, it feels like they shouldn’t (and indeed, scarecrows don’t always work, and birds can quickly become accustomed to them). But clearly they work at least a little…?

Anyway, I found myself reminded of a geocaching expedition I went on outside Cambridge a couple of years ago. At around 6am I was creeping around outside a shopping centre on a Saturday morning, looking for a tiny magnetic geocache hidden behind a sign. I’d anticipated not having to use much “stealth” so early in the day… but nonetheless I kept getting the feeling that I was being watched.
It took me a few minutes until I worked out why: the local Home Bargains had put up a life-size standee of a police officer in just the right position that I kept catching him in the corner of my eye and second-guessing how much my digging-through-the-bushes looked incredibly suspicious!

I did a double-take the first time I spotted the officer, but soon realised he was fake. But the feeling of being watched persisted! There’s clearly something deeper in human psychology, more-instinctive, that – as social animals – gives us that feeling of being watched and influences our behaviour.
There’s a wonderful and much-cited piece of research from 2010 that describes how cooperative behaviour like proper use of an honesty box increases if you put a picture of some eyes above it: the mechanism’s not fully understood, but it’s speculated that it’s because it induces the feeling of being watched.

I reckon it’s similar with birds. They’re not stupid (some of them, like corvids, are famously smart… and probably many predator birds exhibit significant intelligence too), but if there’s something in your peripheral vision that puts you at unease… then of course you’re not going to be comfortable! And if there’s another option nearby5 that’ll work, that’s an easy win for a hungry bird.
You don’t need to actually believe that a scarecrow, a plastic bird, a poster of some eyes, or a picture of a bobby is real in order for it to have a psychological impact. That’s why – I believe – a fake heron works. And that’s why, today, a heron reminded me of a police officer.
1 I guess actual herons can’t tell the difference?
2 Presumably the same technique doesn’t work with sociable birds, who would probably turn up to try to befriend or woo the models.
3 I don’t know, but I do wonder, whether the picture is actually of a police officer or of a model. If I were a police officer and I knew that my likeness was being used at supermarkets and the like, I’d be first to volunteer to any call-outs to anywhere nearby them, so any suspect who ran from me would keep spotting me, following them, at every corner. You get few opportunities for pranks as a copper, I reckon, but this one would be a blast.
4 I wonder if a fake angler is more- or less-effective than a fake heron. Somewhere, an animal psychology PhD student is working out the experimental conditions to answer this question, I hope.
5 Remember: a bird can have a birds-eye view of feeding spots! If one option’s gonna make them feel like they’re being watched by a predator or a competitor, and another nearby option looks almost-as-good, they’re gonna take the alternative!
