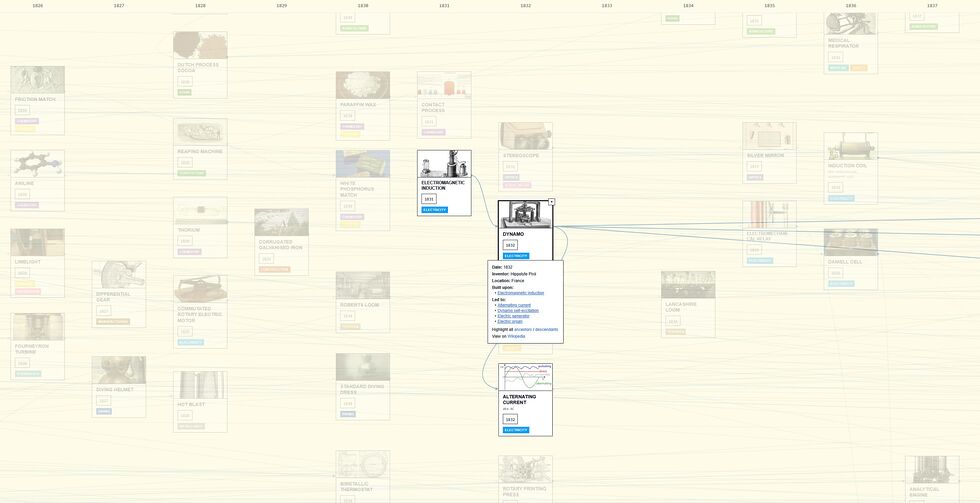
This wonderful project, released six weeks ago, attempts the impossible challenge of building a Civilization-style tech tree but chronicling the development and interplay
of all of the actual technological innovations humanity has ever made. Even in its inevitably-incomplete state, it’s inspiring and informative. Or, as Open Culture put it:
Our civilization has made its way from stone tools to robotaxis, mRNA vaccines, and LLM chatbots; we’d all be better able to inhabit it with even a slightly clearer idea of how it
did so.
Accessible description: Dan, a white man with a goatee beard and a faded blue ponytail, stands in a darkened kitchen. Turning to the camera, he says “I get up when I want,
except on Wednesdays when I get rudely awakened by the tadpoles.” Then he holds up a book entitled “Pond Life”.
In a little over a week I’ll be starting my new role at Firstup, who use some of my favourite Web technologies to deliver tools that streamline
employee communication and engagement.
I’m sure there’ll be more to say about that down the line, but for now: let’s look at my recruitment experience, because it’s probably the fastest and most-streamlined technical
recruitment process I’ve ever experienced! Here’s the timeline:
Firstup Recruitment Timeline
Day 0 (Thursday), 21:18 – One evening, I submitted an application via jobs listing site Welcome To The Jungle. For
comparison, I submitted an application for a similar role at a similar company at almost the exact same time. Let’s call them, umm… “Secondup”.
21:42 – I received an automated response to say “Firstup have received your application”. So far, so normal.
21:44 – I received an email from a human – only 26 minutes after my initial application – to invite me to an initial screener interview the following week,
and offering a selection of times (including a reminder of the relative timezone difference between the interviewer and I).
21:55 – I replied to suggest meeting on Wednesday the following week1.
Day 6 (Wednesday), 15:30 – Half-hour screener interview, mostly an introduction, “keyword check” (can I say the right keywords about my qualifications and experience
to demonstrate that, yes, I’m able to do the things they’ll need), and – because it’s 2025 and we live in the darkest timeline – a confirmation that I was a real human being and not
an AI2.
The TalOps person, Talia, says she’d like to progress me to an interview with the person who’d become my team lead, and arranges the interview then-and-there for Friday. She talked me
through all the stages (max points to any recruiter who does this), and gave me an NDA to sign so we could “talk shop” in interviews if applicable.
I only took the initial stages of my Firstup interviews in our library, moving to my regular coding desk for the tech tests, but I’ve got to say it’s a great space for a quiet
conversation, away from the chaos and noise of our kids on an evening!
Day 8 (Friday), 18:30 – My new line manager, Kirk, is on the Pacific Coast of the US, so rather than wait until next week to meet I agreed to this early-evening
interview slot. I’m out of practice at interviews and I babbled a bit, but apparently I had the right credentials because, at a continuing breakneck pace…
21:32 – Talia emailed again to let me know I was through that stage, and asked to set up two live coding “tech test” interviews early the following week. I’ve been
enjoying all the conversations and the vibes so far, so I try to grab the earliest available slots that I can make. This put the two tech test interviews back-to-back, to which
Ruth raised her eyebrows – but to me it felt right to keep riding the energy of this high-speed recruitment process and dive right in to
both!
Day 11 (Monday), 18:30 – Not even a West Coast interviewer this time, but because I’d snatched the earliest possible opportunity I spoke to Joshua early in the
evening. Using a shared development environment, he had me doing a classic data-structures-and-algorithms style assessment: converting a JSON-based logical inference description
sort-of reminiscent of a Reverse Polish Notation tree into something that looked more pseudocode of the underlying
boolean logic. I spotted early on that I’d want a recursive solution, considered a procedural approach, and eventually went with a functional one. It was all going well… until it
wasn’t! Working at speed, I made frustrating early mistake left me with the wrong data “down” my tree and needed to do some log-based debugging (the shared environment didn’t support
a proper debugger, grr!) to get back on track… but I managed to deliver something that worked within the window, and talked at length through my approach every step of the way.
19:30 – The second technical interview was with Kevin, and was more about systems design from a technical perspective. I was challenged to make an object-oriented
implementation of a car park with three different sizes of spaces (for motorbikes, cars, and vans); vehicles can only fit into their own size of space or larger, except vans which –
in the absence of a van space – can straddle three car spaces. The specification called for a particular API that could answer questions about the numbers and types of spaces
available. Now warmed-up to the quirks of the shared coding environment, I started from a test-driven development approach: it didn’t actually support TDD, but I figured I could work
around that by implementing what was effectively my API’s client, hitting my non-existent classes and their non-existent methods and asserting particular responses before going and
filling in those classes until they worked. I felt like I really “clicked” with Kevin as well as with the tech test, and was really pleased with what I eventually delivered.
Day 12 (Tuesday), 12:14 – I heard from Talia again, inviting me to a final interview with Kirk’s manager Xiaojun, the Director of Engineering. Again, I opted for
the earliest mutually-convenient time – the very next day! – even though it would be unusually-late in the day.
Day 13 (Wednesday), 20:00 – The final interview with Xiaojun was a less-energetic affair, but still included some fun technical grilling and, as it happens,
my most-smug interview moment ever when he asked me how I’d go about implementing something… that I’d coincidentally implemented for fun a few weeks earlier! So instead of spending time thinking about an answer to the question, I was able to
dive right in to my most-recent solution, for which I’d conveniently drawn diagrams that I was able to use to explain my architectural choices. I found it harder to read Xiaojun and
get a feel for how the interview had gone than I had each previous stage, but I was excited to hear that they were working through a shortlist and should be ready to appoint somebody
at the “end of the week, or early next week” at the latest.
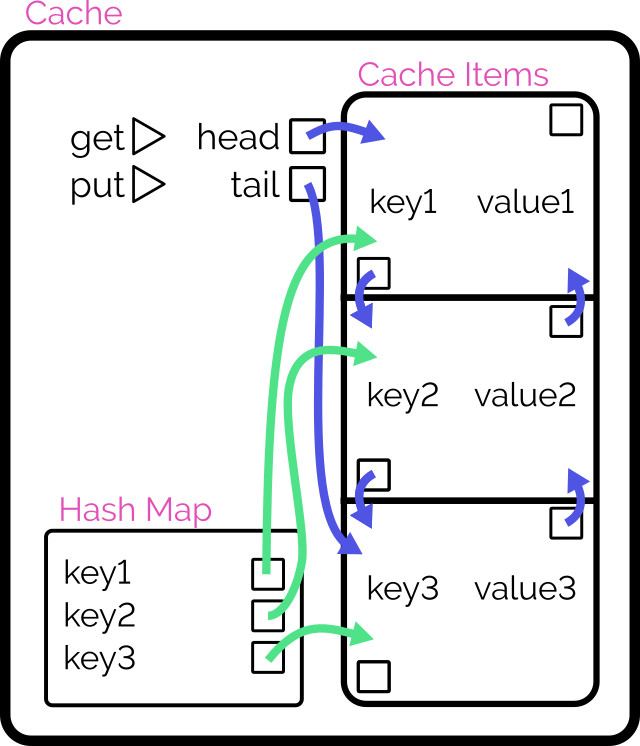
This. This is how you implement an LRU cache.
Day 14 (Thursday), 00:09 – At what is presumably the very end of the workday in her timezone, Talia emailed me to ask if we could chat at what must be the
start of her next workday. Or as I call it, lunchtime. That’s a promising sign.
13:00 – The sun had come out, so I took Talia’s call in the “meeting hammock” in the garden, with a can of cold non-alcoholic beer next to me (and the dog rolling
around on the grass). After exchanging pleasantries, she made the offer, which I verbally accepted then and there and (after clearing up a couple of quick queries) signed a contract
to a few hours later. Sorted.
Day 23 – You remember that I mentioned applying to another (very similar) role at the same time? This was the day that “Secondup” emailed to ask about my availability
for an interview. And while 23 days is certainly a more-normal turnaround for the start of a recruitment process, I’d already found myself excited by everything I’d learned about
Firstup: there are some great things they’re doing right; there are some exciting problems that I can be part of the solution to… I didn’t need another interview, so I turned down
“Secondup”. Something something early bird.
Wow, that was fast!
With only eight days between the screener interview and the offer – and barely a fortnight after my initial application – this has got to be the absolute fastest I’ve ever seen a tech
role recruitment process go. It felt like a rollercoaster, and I loved it.
Is it weird that I’d actually ride a recruitment-themed rollercoaster?
Footnotes
1 The earliest available slot for a screener interview, on Tuesday, clashed with my 8-year-old’s taekwondo class which I’d promised I’ll go along and join in with it as part of their “dads train free in June” promotion.
This turned out to be a painful and exhausting experience which I thoroughly enjoyed, but more on that some other time, perhaps.
2 After realising that “are you a robot” was part of the initial checks, I briefly
regretted taking the interview in our newly-constructed library because it provides exactly the kind of environment that looks like a fake background.
Fellow geek, Nightline veteran, and general volunteering hero James Buller wrote a wonderful retrospective on his experience with Surrey Nightline, National Nightline, and the Nightline
Association over most of the last three decades:
…
In 1997 I left a note in the Surrey Nightline pigeon-hole to volunteer and eventually become the Coordinator
In 1998 I emailed the leaders of National Nightline with a plea for support.
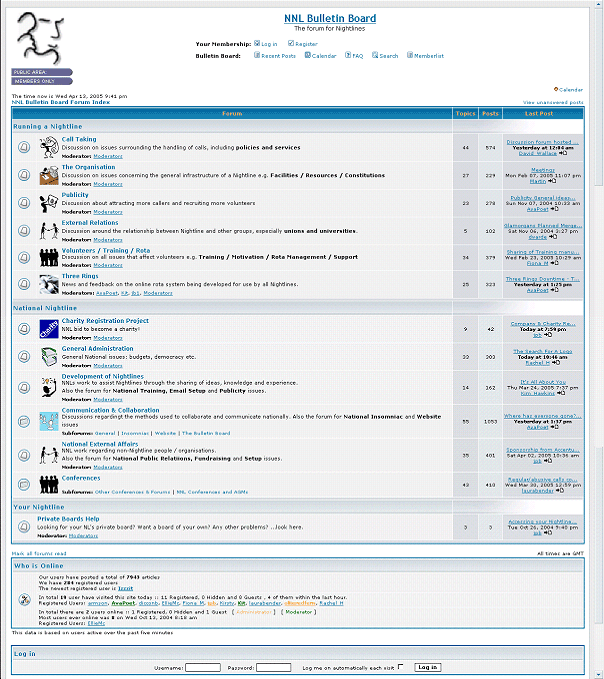
In 2000 I launched the first National Nightline website and email list
In 2003 I added the bulletin board online forum
In 2006 I led governance reform and the registration project that led to the Nightline Association charity
In 2007 I set up Google Apps for the recently established nightline.ac.uk domain
In 2008 We sent news via an email broadcast system for the first time
In 2025 All the user accounts and the charity were shut down.
So here’s my last post on volunteering with the confidential mental health helplines run ‘by students for students’ at universities, then the overarching association body.
…
I began volunteering with Aberystwyth Nightline in 1999, and I remember the 2000 launch of the National Nightline mailing list and website. It felt like a moment of coalescence and
unity. We Nightline volunteers at the turn of the millennium were young, and tech-savvy, and in that window between the gradual decline of Usenet and the 2004-onwards explosion in
centralised social networking, mailing lists and forums were The Hotness.
Nightlines (and Nightliners) disagreed with one another on almost everything, but the Internet-based connectivity that James put into place for National Nightline was enormously
impactful. It made Nightline feel bigger than it had been before: it was an accessible and persistent reminder that you were part of a wider movement. It facilitated year-round
discussions that might previously have been seen only at annual conferences. It brought communities together.
(Individuals too: when my friends Kit and Fiona met and got
together back in 2003 (and, later, married), it probably wouldn’t have happened without
the National Nightline forum.)
Gosh, I spent an inordinate amount of time on this site, back in the day.
But while I praise James’ work in community-building and technology provision, his experience with Nightlines doesn’t stop there: he was an important force in the establishment of the
Nightline Association, the registered charity that took over National Nightline’s work and promised to advance it even further with moves towards accreditation and representation.
As his story continues, James talks about one of his final roles for the Association: spreading the word about the party to “see it off”. Sadly, the Nightline Association folded last
month, leaving a gap that today’s Nightlines, I fear, will struggle to fill, but this was at least the excuse for one last get-together (actually, three, but owing to schedule conflicts
I was only able to travel up to the one in Manchester):
…
I had done a lot of the leg work to track down and invite former volunteers to the farewell celebrations. I’d gotten a real buzz from it, which despite a lot of other volunteering
I’ve not felt since I was immersed in the Nightline world in the 2000’s. I felt all warm and fuzzy with nostalgia for the culture, comradeship and perhaps dolefully sense of youth
too!
I was delighted that so many people answered the call (should have expected nothing less of great Nightliners!). Their reminiscing felt like a wave of love for the movement we’d
all been a part of and had consumed such a huge part of our lives for so long. It clearly left an indelible mark on us all and has positively affected so many others through us.
…
Many people played their part in the story of the Nightline Association.
I got to hang out with some current and former Nightline volunteers in Manchester, the smallest of the ‘Goodbye NLA’ parties.
Volunteering in charity technical work is a force multiplier: instead of working on the front lines, you get to facilitate many times your individual impact for the people who
do! Volunteering with Three Rings for the last 23 years has helped me experience that, and James’ experience of this kind of
volunteering goes even further than mine. And yet he feels his impact most-strongly in a close and interpersonal story that’s humbling and beautiful:
…
I was recently asked by a researcher, ‘What is the best thing you have done as a volunteer in terms of impact?’. I was proud to reply that I’d been told someone had not killed
themselves because of a call with me at Surrey Nightline.
…
I’d recommend going and reading the full post by James, right up to the final inspiring words.
(Incidentally: if you’re looking for a volunteering opportunity that continues to help Nightlines, in the absence of the Nightline Association, Three Rings can make use of you…)
The tl;dr is: the court ruled that (a) piracy for the purpose of training an LLM is still piracy, so there’ll be a separate case about the fact that Anthropic did not pay for copies of
all the books their model ingested, but (b) training a model on books and then selling access to that model, which can then produce output based on what it has “learned” from those
books, is considered transformative work and therefore fair use.
Compelling arguments have been made both ways on this topic already, e.g.:
Some folks are very keen to point out that it’s totally permitted for humans to read, and even memorise, entire volumes, and then use what they’ve learned when they
produce new work. They argue that what an LLM “does” is not materially different from an impossibly well-read human.
By way of counterpoint, it’s been observed that such a human would still be personally liable if the “inspired” output they subsequently created was derivative
to the point of violating copyright, but we don’t yet have a strong legal model for assessing AI output in the same way. (BBC News article about Disney & Universal vs. Midjourney is going to be very interesting!)
Furthermore, it might be impossible to conclusively determine that the way GenAI works is fundamentally comparable to human thought. And that’s the thing that got
me thinking about this particular thought experiment.
A moment of philosophy
Here’s a thought experiment:
Support I trained an LLM on all of the books of just one author (plus enough additional language that it was able to meaningfully communicate). Let’s take Stephen King’s 65 novels and
200+ short stories, for example. We’ll sell access to the API we produce.
I suppose it’s possible that Stephen King was already replaced long ago with an AI that was instructed to churn out horror stories about folks in isolated Midwestern locales being
harassed by a pervasive background evil?
The output of this system would be heavily-biased by the limited input it’s been given: anybody familiar with King’s work would quickly spot that the AI’s mannerisms echoed his writing
style. Appropriately prompted – or just by chance – such a system would likely produce whole chapters of output that would certainly be considered to be a substantial infringement of
the original work, right?
If I make KingLLM, I’m going to get sued, rightly enough.
But if we accept that (and assume that the U.S. District Court for the Northern District of California would agree)… then this ruling on Anthropic would carry a curious implication.
That if enough content is ingested, the operation of the LLM in itself is no longer copyright infringement.
Which raises the question: where is the line? What size of corpus must a system be trained upon before its processing must necessarily be considered transformative
of its inputs?
Clearly, trying to answer that question leads to a variant of the sorites paradox. Nobody can ever say that, for example, an input of twenty million words
is enough to make a model transformative but just one fewer and it must be considered to be perpetually ripping off what little knowledge it has!
But as more of these copyright holder vs. AI company cases come to fruition, it’ll be interesting to see where courts fall. What is fair use and what is infringing?
And wherever the answers land, I’m sure there’ll be folks like me coming up with thought experiments that sit uncomfortably in the grey areas that remain.
Step out of your head
and into your senses
and into the world
that’s where life happens
…
This week, my friend Boro shared a poem that he’d written. It’s simple, and energising, and insightful, and I really enjoyed it. Go read
the whole thing; it’s not long.
Whether we’re riding high or low, there’s wisdom in being gentle with oneself. The rhythm of the piece feels a bit like breathing, to me, and from that is reminiscent of a breathing
exercise I was shown, once, in which the inhalations were accompanied by a focus on self-awareness and the exhalations with one on situational awareness.
Boro’s poem makes me wonder if he’s come across the same exercise: that through my appreciation of his post I’m sharing in his experience of the same exercise, in another time and
place.
Sometimes all you need to complete the perfect offset geocache is a GPSr, some hand tools… and the willingness to unilaterally declare a remote bench to be a memorial to a fictional
person, just to get a particular set of numbers out into the world!
Pretty sure there isn’t a prize for Throwing Wet Sponges At Children during the graduating year’s “fun run” at the school sports day… but just like the kids are asked to, I’m going to
try my best. 😁
I’ve been in a lot of interviews over the last two or three weeks. But there’s a moment that stands out and that I’ll remember forever as the most-smug I’ve ever felt during an
interview.
There’ll soon be news to share about what I’m going to be doing with the second half of this year…
This particular interview included a mixture of technical and non-technical questions, but a particular technical question stood out for reasons that will rapidly become apparent. It
went kind-of like this:
Interviewer: How would you go about designing a backend cache that retains in memory some number of most-recently-accessed items?
Dan: It sounds like you’re talking about an LRU cache. Coincidentally, I implemented exactly that just the other
week, for fun, in two of this role’s preferred programming languages (and four other languages). I wrote a blog post about my design
choices: specifically, why I opted for a hashmap for quick reads and a doubly-linked-list for constant-time writes. I’m sending you the links to it now: may I talk you through the
diagrams?
Interviewer:
That’s probably the most-overconfident thing I’ve said at an interview since before I started at the Bodleian, 13 years ago. In the interview for
that position I spent some time explaining that for the role they were recruiting for they were asking the wrong questions! I provided some better questions that I felt they
should ask to maximise their chance of getting the best candidate… and then answered them, effectively helping to write my own interview.
Anyway: even ignoring my cockiness, my interview the other week was informative and enjoyable throughout, and I’m pleased that I’ll soon be working alongside some of the people that I
met: they seem smart, and driven, and focussed, and it looks like the kind of environment in which I could do well.
Deciphered this puzzle when it was first published: so long ago that I’d forgotten the specifics of how exactly I did so (although I’m pretty confident I remember the gist of it). But I
don’t find myself over this side of Oxford often, these days, and so it took until today that an errand brought me over here before I had a chance to actually try and log it.
Near the GZ I found an obvious trail around the nearby structure and undertook a thorough search of all the obvious hiding places before widening my explorations to the surrounding
foliage. Eventually, after about 20 minutes of hunting, I had to give up for shortage of time.
With almost a year since a successful log here and evidence that this trail is now routinely used by a nearby group of non-geocachers, it’s very possible that the cache has been
disturbed. I’ll be waiting until a CO checkin (or successful log) before I try again.
In Marston on an errand, I found myself with enough free time to try to find another few local caches. This puzzle wasn’t as easy as Dotty’s other one, fir me, because for a while I was
counting the wrong things, but I cracked it in the end. A slow walk past the GZ with my fingers in the obvious space soon put the cache in my hand. Log extraction required stone
creative use of a naturally occurring tool, but before long it was signed and returned. TFTC!
When I posted to LinkedIn about my recent redundancy, I saw
a tidal wave of reposts and well-wishes. But there’s one that I’ve come back to whenever I need a pick-me-up before I, y’know, trawl the job boards: a comment-repost by my big-hearted,
sharp-minded former co-worker Kyle. I’m posting it here because I want to keep a copy forever1:
Bad news: I’m among the sixth of Automattic that’s been laid-off this week.
Good news: I’m #OpenToWork, and excited about the opportunity to bring my unique skillset to a new role. Could I be the Senior Software Engineer, Full-Stack Web Developer, or
Technical Lead that you’re looking for?
Here’s what makes me special:
🕸️ 26+ years experience of backend and frontend development, with a focus on standards, accessibility, performance, security, and the open Web
🌎 20+ years experience of working in and leading remote/distributed teams in a diversity of sectors
👨💻 Professional experience of many of the technologies you’ve heard of (PHP, Ruby, Java, Perl, SQL, Go, DevOps, JS, jamstacks, headless…), and probably some you haven’t…
👨🎓 Degrees and other qualifications spanning computer science and software engineering, psychotherapy, ethical hacking, and digital forensics (I don’t believe there’s a career in
the world that makes use of all of these, but if you know differently, tell me!)
If this man isn’t hired immediately, it’s a huge loss. Dan is easily one of the most talented engineers I’ve ever met. His skills are endless, his personal culture is delightful,
and I don’t think I went a day working with him where I didn’t learn something. Let him build you beautiful things. I dare you.
Incidentally, Kyle’s looking for a new role too. If you’re in need of a WordPress/PHP/React pro with a focus on delivering the MVP fast and keeping the customer’s needs
front-and-centre, you should look him up. He’s based in Cape Town but he’s a remote/distributed veteran that you could slot into
your Web team anywhere.
Footnotes
1 My blog was already 5 years old when LinkedIn was founded: my general thinking is that I
can’t trust any free service younger than my blog to retain information for perpetuity longer than my blog, which is why so much of my content from around the web gets
PESOS‘d or POSSE‘d here.