In a little over a week I’ll be starting my new role at Firstup, who use some of my favourite Web technologies to deliver tools that streamline
employee communication and engagement.
I’m sure there’ll be more to say about that down the line, but for now: let’s look at my recruitment experience, because it’s probably the fastest and most-streamlined technical
recruitment process I’ve ever experienced! Here’s the timeline:
Firstup Recruitment Timeline
Day 0 (Thursday), 21:18 – One evening, I submitted an application via jobs listing site Welcome To The Jungle. For
comparison, I submitted an application for a similar role at a similar company at almost the exact same time. Let’s call them, umm… “Secondup”.
21:42 – I received an automated response to say “Firstup have received your application”. So far, so normal.
21:44 – I received an email from a human – only 26 minutes after my initial application – to invite me to an initial screener interview the following week,
and offering a selection of times (including a reminder of the relative timezone difference between the interviewer and I).
21:55 – I replied to suggest meeting on Wednesday the following week1.
Day 6 (Wednesday), 15:30 – Half-hour screener interview, mostly an introduction, “keyword check” (can I say the right keywords about my qualifications and experience
to demonstrate that, yes, I’m able to do the things they’ll need), and – because it’s 2025 and we live in the darkest timeline – a confirmation that I was a real human being and not
an AI2.
The TalOps person, Talia, says she’d like to progress me to an interview with the person who’d become my team lead, and arranges the interview then-and-there for Friday. She talked me
through all the stages (max points to any recruiter who does this), and gave me an NDA to sign so we could “talk shop” in interviews if applicable.
I only took the initial stages of my Firstup interviews in our library, moving to my regular coding desk for the tech tests, but I’ve got to say it’s a great space for a quiet
conversation, away from the chaos and noise of our kids on an evening!
Day 8 (Friday), 18:30 – My new line manager, Kirk, is on the Pacific Coast of the US, so rather than wait until next week to meet I agreed to this early-evening
interview slot. I’m out of practice at interviews and I babbled a bit, but apparently I had the right credentials because, at a continuing breakneck pace…
21:32 – Talia emailed again to let me know I was through that stage, and asked to set up two live coding “tech test” interviews early the following week. I’ve been
enjoying all the conversations and the vibes so far, so I try to grab the earliest available slots that I can make. This put the two tech test interviews back-to-back, to which
Ruth raised her eyebrows – but to me it felt right to keep riding the energy of this high-speed recruitment process and dive right in to
both!
Day 11 (Monday), 18:30 – Not even a West Coast interviewer this time, but because I’d snatched the earliest possible opportunity I spoke to Joshua early in the
evening. Using a shared development environment, he had me doing a classic data-structures-and-algorithms style assessment: converting a JSON-based logical inference description
sort-of reminiscent of a Reverse Polish Notation tree into something that looked more pseudocode of the underlying
boolean logic. I spotted early on that I’d want a recursive solution, considered a procedural approach, and eventually went with a functional one. It was all going well… until it
wasn’t! Working at speed, I made frustrating early mistake left me with the wrong data “down” my tree and needed to do some log-based debugging (the shared environment didn’t support
a proper debugger, grr!) to get back on track… but I managed to deliver something that worked within the window, and talked at length through my approach every step of the way.
19:30 – The second technical interview was with Kevin, and was more about systems design from a technical perspective. I was challenged to make an object-oriented
implementation of a car park with three different sizes of spaces (for motorbikes, cars, and vans); vehicles can only fit into their own size of space or larger, except vans which –
in the absence of a van space – can straddle three car spaces. The specification called for a particular API that could answer questions about the numbers and types of spaces
available. Now warmed-up to the quirks of the shared coding environment, I started from a test-driven development approach: it didn’t actually support TDD, but I figured I could work
around that by implementing what was effectively my API’s client, hitting my non-existent classes and their non-existent methods and asserting particular responses before going and
filling in those classes until they worked. I felt like I really “clicked” with Kevin as well as with the tech test, and was really pleased with what I eventually delivered.
Day 12 (Tuesday), 12:14 – I heard from Talia again, inviting me to a final interview with Kirk’s manager Xiaojun, the Director of Engineering. Again, I opted for
the earliest mutually-convenient time – the very next day! – even though it would be unusually-late in the day.
Day 13 (Wednesday), 20:00 – The final interview with Xiaojun was a less-energetic affair, but still included some fun technical grilling and, as it happens,
my most-smug interview moment ever when he asked me how I’d go about implementing something… that I’d coincidentally implemented for fun a few weeks earlier! So instead of spending time thinking about an answer to the question, I was able to
dive right in to my most-recent solution, for which I’d conveniently drawn diagrams that I was able to use to explain my architectural choices. I found it harder to read Xiaojun and
get a feel for how the interview had gone than I had each previous stage, but I was excited to hear that they were working through a shortlist and should be ready to appoint somebody
at the “end of the week, or early next week” at the latest.
This. This is how you implement an LRU cache.
Day 14 (Thursday), 00:09 – At what is presumably the very end of the workday in her timezone, Talia emailed me to ask if we could chat at what must be the
start of her next workday. Or as I call it, lunchtime. That’s a promising sign.
13:00 – The sun had come out, so I took Talia’s call in the “meeting hammock” in the garden, with a can of cold non-alcoholic beer next to me (and the dog rolling
around on the grass). After exchanging pleasantries, she made the offer, which I verbally accepted then and there and (after clearing up a couple of quick queries) signed a contract
to a few hours later. Sorted.
Day 23 – You remember that I mentioned applying to another (very similar) role at the same time? This was the day that “Secondup” emailed to ask about my availability
for an interview. And while 23 days is certainly a more-normal turnaround for the start of a recruitment process, I’d already found myself excited by everything I’d learned about
Firstup: there are some great things they’re doing right; there are some exciting problems that I can be part of the solution to… I didn’t need another interview, so I turned down
“Secondup”. Something something early bird.
Wow, that was fast!
With only eight days between the screener interview and the offer – and barely a fortnight after my initial application – this has got to be the absolute fastest I’ve ever seen a tech
role recruitment process go. It felt like a rollercoaster, and I loved it.
Is it weird that I’d actually ride a recruitment-themed rollercoaster?
Footnotes
1 The earliest available slot for a screener interview, on Tuesday, clashed with my 8-year-old’s taekwondo class which I’d promised I’ll go along and join in with it as part of their “dads train free in June” promotion.
This turned out to be a painful and exhausting experience which I thoroughly enjoyed, but more on that some other time, perhaps.
2 After realising that “are you a robot” was part of the initial checks, I briefly
regretted taking the interview in our newly-constructed library because it provides exactly the kind of environment that looks like a fake background.
I was updating my CV earlier this week in anticipation of applying for a handful of interesting-looking roles1
and I was considering quite how many different tech stacks I claim significant experience in, nowadays.
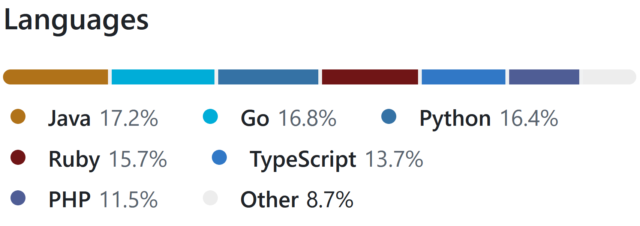
There are languages I’ve been writing in every single week for the last 15+ years, of course, like PHP, Ruby, and JavaScript. And my underlying fundamentals are solid.
But is it really fair for me to be able to claim that I can code in Java, Go, or Python: languages that I’ve not used commercially within the last 5-10 years?
What kind of developer writes the same program six times… for a tech test they haven’t even been asked to do? If you guessed “Dan”, you’d be correct!
Obviously, I couldn’t just let that question lie2.
Let’s find out!
I fished around on Glassdoor for a bit to find a medium-sized single-sitting tech test, and found a couple of different briefs that I mashed together to create this:
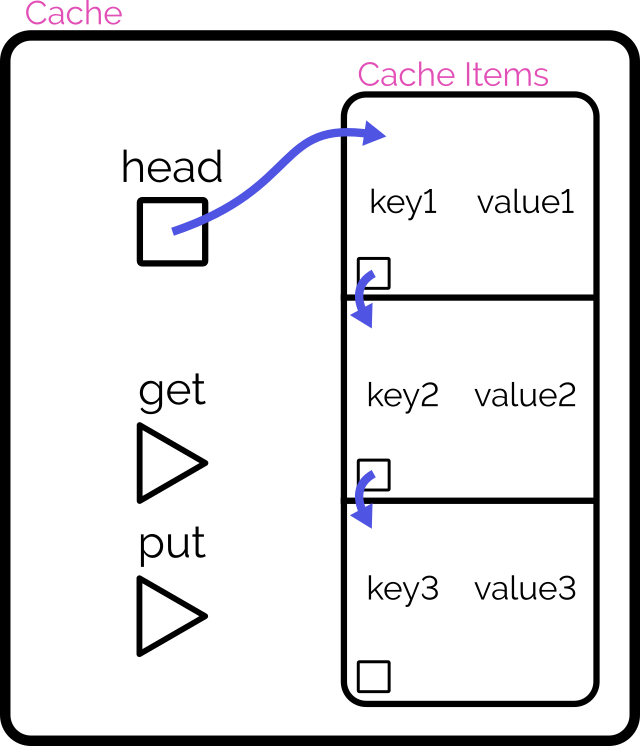
In an object-oriented manner, implement an LRU (Least-Recently Used) cache:
The size of the cache is specified at instantiation.
Arbitrary objects can be put into the cache, along with a retrieval key in the form of a string. Using the same string, you can get the objects back.
If a put operation would increase the number of objects in the cache beyond the size limit, the cached object that was least-recently accessed (by either a
put or get operation) is removed to make room for it.
putting a duplicate key into the cache should update the associated object (and make this item most-recently accessed).
Both the get and put operations should resolve within constant (O(1)) time.
Add automated tests to support the functionality.
My plan was to implement a solution to this challenge, in as many of the languages mentioned on my CV as possible in a single sitting.
But first, a little Data Structures & Algorithms theory:
The Theory
Simple case with O(n) complexity
The simplest way to implement such a cache might be as follows:
Use a linear data structure like an array or linked list to store cached items.
On get, iterate through the list to try to find the matching item.
If found: move it to the head of the list, then return it.
On put, first check if it already exists in the list as with get:
If it already exists, update it and move it to the head of the list.
Otherwise, insert it as a new item at the head of the list.
If this would increase the size of the list beyond the permitted limit, pop and discard the item at the tail of the list.
It’s simple, elegant and totally the kind of thing I’d accept if I were recruiting for a junior or graduate developer. But we can do better.
The problem with this approach is that it fails the requirement that the methods “should resolve within constant (O(1)) time”3.
Of particular concern is the fact that any operation which might need to re-sort the list to put the just-accessed item at the top
4. Let’s try another design:
Achieving O(1) time complexity
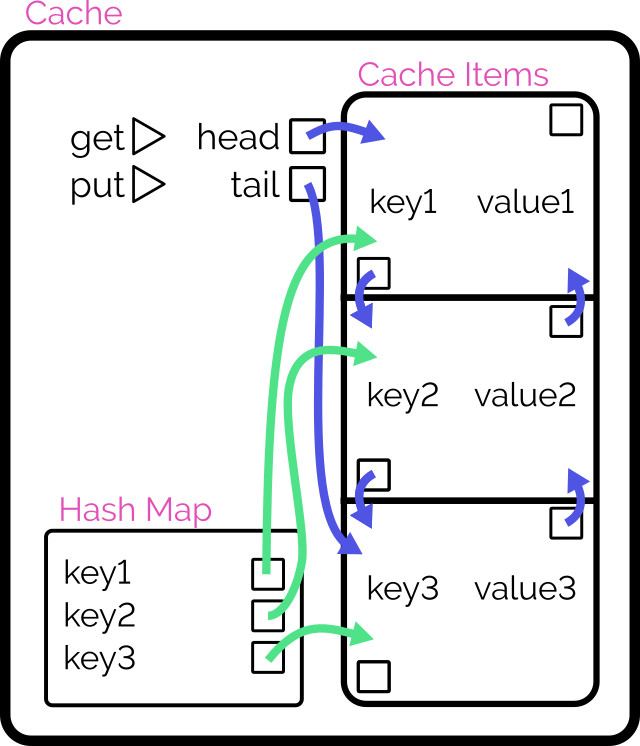
Here’s another way to implement the cache:
Retain cache items in a doubly-linked list, with a pointer to both the head and tail
Add a hash map (or similar language-specific structure) for fast lookups by cache key
On get, check the hash map to see if the item exists.
If so, return it and promote it to the head (as described below).
On put, check the hash map to see if the item exists.
If so, promote it to the head (as described below).
If not, insert it at the head by:
Updating the prev of the current head item and then pointing the head to the new item (which will have the old head item as its
next), and
Adding it to the hash map.
If the number of items in the hash map would exceed the limit, remove the tail item from the hash map, point the tail at the tail item’s prev, and
unlink the expired tail item from the new tail item’s next.
To promote an item to the head of the list:
Follow the item’s prev and next to find its siblings and link them to one another (removes the item from the list).
Point the promoted item’s next to the current head, and the current head‘s prev to the promoted item.
Point the head of the list at the promoted item.
Looking at a plate of pointer-spaghetti makes me strangely hungry.
It’s important to realise that this alternative implementation isn’t better. It’s just different: the “right” solution depends on the use-case5.
The Implementation
That’s enough analysis and design. Time to write some code.
Turns out that if you use enough different languages in your project, GitHub begins to look like itwants to draw a rainbow.
Picking a handful of the more-useful languages on my CV6,
I opted to implement in:
Ruby (with RSpec for testing and Rubocop for linting)
PHP (with PHPUnit for testing)
TypeScript (running on Node, with Jest for testing)
Java (with JUnit for testing)
Go (which isn’t really an object-oriented language but acts a bit like one, amirite?)
Python (probably my weakest language in this set, but which actually ended up with quite a tidy solution)
Naturally, I open-sourced everything if you’d like to see for yourself. It all works, although if you’re actually in need of such a
cache for your project you’ll probably find an alternative that’s at least as good (and more-likely to be maintained!) in a third-party library somewhere!
What did I learn?
This was actually pretty fun! I might continue to expand my repo by doing the same challenge with a few of the other languages I’ve used professionally at some point or
another7.
And there’s a few takeaways I got from this experience –
Lesson #1: programming more languages can make you better at all of them
As I went along, one language at a time, I ended up realising improvements that I could make to earlier iterations.
For example, when I came to the TypeScript implementation, I decided to use generics so that the developer can specify what kind of objects they want to store in the cache,
rather than just a generic Object, and better benefit type-safety. That’s when I remembered that Java supports generics, too, so I went back and used them there as well.
In the same way as speaking multiple (human) languages or studying linguistics can help unlock new ways of thinking about your communication, being able to think in terms of multiple
different programming languages helps you spot new opportunities. When in 2020 PHP 8 added nullsafe operators, union types, and
named arguments, I remember feeling confident using them from day one because those features were already familiar to me from Ruby8, TypeScript9, and Python10,
respectively.
Lesson #2: even when I’m rusty, I can rely on my fundamentals
I’ve applied for a handful of jobs now, but if one of them had invited me to a pairing session on a language I’m rusty on (like Java!) I might’ve felt intimidated.
But it turns out I shouldn’t need to be! With my solid fundamentals and a handful of other languages under my belt, I understand when I need to step away from the code editor and hit
the API documentation. Turns out, I’m in a good position to demo any of my language skills.
I remember when I was first learning Go, I wanted to make use of a particular language feature that I didn’t know whether it had. But because I’d used that feature in Ruby, I knew what
to search for in Go’s documentation to see if it was supported (it wasn’t) and if so, what the syntax was11.
Lesson #3: structural rules are harder to gearshift than syntactic ones
Switching between six different languages while writing the same application was occasionally challenging, but not in the ways I expected.
I’ve had plenty of experience switching programming languages mid-train-of-thought before. Sometimes you just have to flit between the frontend and backend of your application!
But this time around I discovered: changes in structure are apparently harder for my brain than changes in syntax. E.g.:
Switching in and out of Python’s indentation caught me out at least once (might’ve been better if I took the time to install the language’s tools into my text editor first!).
Switching from a language without enforced semicolon line ends (e.g. Ruby, Go) to one with them (e.g. Java, PHP) had me make the compiler sad several times.
This gets even tougher when not writing the language but writing about the language: my first pass at the documentation for the Go version somehow ended up with
Ruby/Python-style #-comments instead of Go/Java/TypeScript-style //-comments; whoops!
I’m guessing that the part of my memory that looks after a language’s keywords, how a method header is structured, and which equals sign to use for assignment versus comparison… are
stored in a different part of my brain than the bit that keeps track of how a language is laid-out?12
Okay, time for a new job
I reckon it’s time I got back into work, so I’m going to have a look around and see if there’s any roles out there that look exciting to me.
If you know anybody who’s looking for a UK-based, remote-first, senior+, full-stack web developer with 25+ years experience and more languages than you can shake a stick at… point them at my CV, would you?
Footnotes
1 I suspect that when most software engineers look for a new job, they filter to the
languages, frameworks, they feel they’re strongest at. I do a little of that, I suppose, but I’m far more-motivated by culture, sector, product and environment than I am by the shape
of your stack, and I’m versatile enough that technology specifics can almost come second. So long as you’re not asking me to write VB.NET.
2 It’s sort-of a parallel to how I decided to check
the other week that my Gutenberg experience was sufficiently strong that I could write standard ReactJS, too.
3 I was pleased to find a tech test that actually called for an understanding of algorithm
growth/scaling rates, so I could steal this requirement for my own experiment! I fear that sometimes, in their drive to be pragmatic and representative of “real work”, the value of a
comprehension of computer science fundamentals is overlooked by recruiters.
4 Even if an algorithm takes the approach of creating a new list with the
inserted/modified item at the top, that’s still just a very-specific case of insertion sort when you think about it, right?
5 The second design will be slower at writing but faster at
reading, and will scale better as the cache gets larger. That sounds great for a read-often/write-rarely cache, but your situation may differ.
6 Okay, my language selection was pretty arbitrary. But if I’d have also come up with
implementations in Perl, and C#, and Elixir, and whatever else… I’d have been writing code all day!
7 So long as I’m willing to be flexible about the “object-oriented” requirement, there are
even more options available to me. Probably the language that I last wrote longest ago would be Pascal: I wonder how much of that I remember?
8 Ruby’s safe navigation/”lonely” operator did the same thing as PHP’s nullsafe operator
since 2015.
9 TypeScript got union types back in 2015, and apart from them being more-strictly-enforced they’re basically identical to
PHP’s.
10 Did you know that Python had keyword arguments since its very first public release
way back in 1994! How did it take so many other interpreted languages so long to catch up?
11 The feature was the three-way comparison or “spaceship operator”, in case you were wondering.
12 I wonder if anybody’s ever laid a programmer in an MRI machine while they code? I’d
be really interested to see if different bits of the brain light up when coding in functional programming languages than in procedural ones, for example!
Perhaps inspired by my resharing of Thomas‘s thoughts about the biggest problem in
AI (tl;dr: he thinks it’s nomenclature; I agree that’s a problem but I don’t know if it’s the biggest issue), Ruth posted some thoughts to LinkedIn that I think are quite well-put:
I was going to write about something else but since LinkedIn suggested I should get AI to do it for me, here’s where I currently stand on GenAI.
As a person working in computing, I view it as a tool that is being treated as a silver bullet and is probably self-limiting in its current form. By design, it produces average
code. Most companies prior to having access to cheap average code would have said they wanted good code. Since the average code produced by the tools is being fed back into those
tools, mathematically this can’t lead anywhere good in terms of quality.
However, as a manager in tech I’m really alarmed by it. If we have tools to write code that is ok but needs a lot of double checking, we might be tempted to stop hiring
people at that level. There already aren’t enough jobs for entry level programmers to feed the talent pipeline, and this is likely to make it worse. I’m not sure where the next
generation of great programmers are supposed to come from if we move to an ecosystem where the junior roles are replaced by Copilot.
I think there’s a lot of potential for targeted tools to speed up productivity. I just don’t think GenAI is where they should come from.
This is an excellent explanation of no fewer than four of the big problems with “AI” as we’re seeing it marketed today:
It produces mediocre output, (more on that below!)
It’s a snake that eats its own tail,
It’s treated as a silver bullet, and
By pricing out certain types of low-tier knowledge work, it damages the pipeline for training higher-tiers of those knowledge workers (e.g. if we outsource all first-level tech
support to chatbots, where will the next generation of third-level tech support come from, if they can’t work their way up the ranks, learning as they go?)
Let’s stop and take a deeper look at the “mediocre output” claim. Ruth’s right, but if you don’t already understand why generative AI does this, it’s worth a
little bit of consideration about the reason for it… and the consequences of it:
Mathematically-speaking, that’s exactly what you would expect for something that is literally statistically averaging content, but that still comes as a surprise to people.
Bear in mind, of course, that there are plenty of topics in which the average person is less-knowledgable than the average of the content that was made available to the model.
For example, I know next to noting about fertiliser application in large-scale agriculture. ChatGPT has doubtless ingested a lot of literature about it, and if I ask it what
fertiliser I should use for a field of black beans in silty soil in the UK, it delivers me a confident-sounding answer:
Who knows if this answer is right, of course! If the answer mattered to me – because I was about to drill my field – I’d have to do my own research to check, by which point I
might as well have just done the research in the first place. If all I cared about was a quick sense-check to an answer I already knew, and it didn’t matter too much, this might be
okay output. (It’s pretty verbose and repeats itself a lot, like it’s learned how to talk from YouTube tutorials: I’m surprised it didn’t finish by exhorting me to like and
subscribe!)
When LLMs produce exceptional output (I use the term exceptional in the sense of unusual and not-average, not to mean “good”), it appears more-creative and interesting but is even
more-likely to be riddled with fanciful hallucinations.
There’s a fine line in getting the creativity dial set just right, and even when you do there’s no guarantee of accuracy, but the way in which many chatbots are told to talk makes them
sound authoritative on basically every subject. When you know it’s lying, that’s easy. But people don’t always use LLMs for subjects they’re knowledgeable about!
I asked ChatGPT to define five words for me. Two (“quantifiable” and “ethology”) are real words that somebody might have trouble with. One (“no cap”) is a slang term. One
(“erinaceiophobia” is a logically-sound construction from the Latin name for the biological family that hedgehogs belong to and the Greek suffix that’s applied to irrational fears).
ChatGPT came up with perfectly reasonable definitions of all of these. But it also confidently defined “undercontrastised”, a word I made up and which I can’t find used anywhere at
all!
In my example above, a more-useful robot would have stated that it didn’t know the answer to the question rather than, y’know, lying. But the nature
of the statistical models used by LLMs means that they can’t know what they don’t know: they don’t have a “known unknowns” space.
Regarding the “damages the training pipeline”: I’m undecided on whether or not I agree with Ruth. She might be on to something there, but I’m not sure. Needs more
thought before I commit to an opinion on that one.
Oh, and an addendum to this – as a human, I find the proliferation of AI tools in spaces that are all about creating connections with other humans deeply concerning. I saw a lot of
job applications through Otta at my previous role, and they were all kind of the same – I had no sense of the person behind the averaged out CV I was looking at. We already have a
huge problem with people presenting inauthentic versions of themselves on social media which makes it harder to have genuine interactions, smoothing off the rough edges of real people
to get something glossy and processed is only going to make this worse.
AI posts on social media are the chicken nuggets of human interaction and I’d rather have something real every time.
Emphasis mine… because that’s a fantastic metaphor. Content generated where a generative AI is trying to “look human” are so-often bland, flat, and unexciting: a mass-produced
most-basic form of social sustenance. So yeah: chicken nuggets.
Ironically, I might’ve gotten a better picture here if I’d asked AI to draw this for me, because I couldn’t find any really unappetising-looking McDonalds-grade chicken nuggets on the
stock photography site I used.
It just passed two years since I started working at Automattic, and I just made a startling
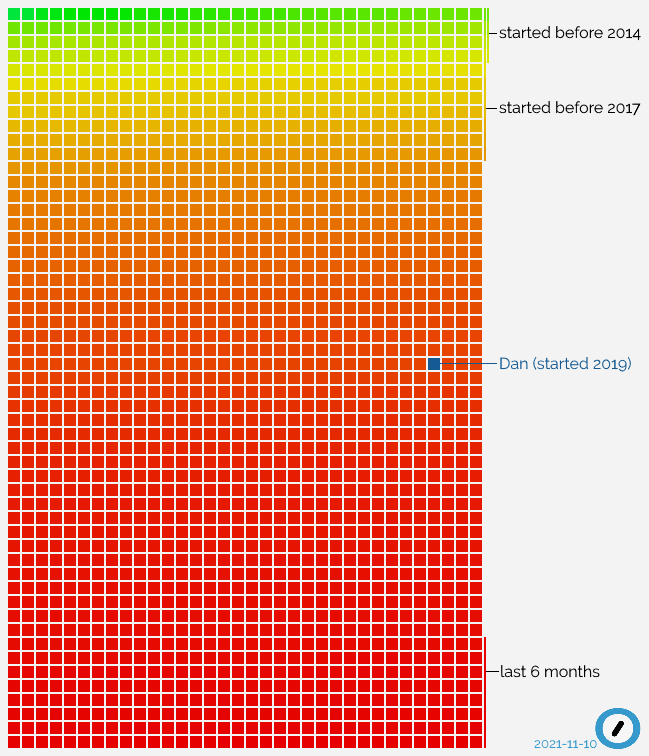
discovery: I’ve now been with the company for longer than 50% of the staff.
When you hear that from a 2-year employee at a tech company, it’s easy to assume that they have a high staff turnover, but Automattic’s churn rate is relatively low, especially for our
sector: 86% of developers stay longer than 5 years. So what’s happening? Let’s visualise it:
Everything in this graph, in which each current Automattician is a square, explains how I feel right now: still sometimes like a new fish, but in an increasingly big sea.
All that “red” at the bottom of the graph? That’s recent growth. Automattic’s expanding really rapidly right now, taking on new talent at a never-before-seen speed.
Since before I joined it’s been the case that our goals have demanded an influx of new engineers at a faster rate than we’ve been able to recruit, but it looks like things are
improving. Recent refinements to our recruitment process (of which I’ve written about my experience) have helped, but I wonder how much we’ve
also been aided by pandemic-related changes to working patterns? Many people, and especially in tech fields, have now discovered that working-from-home works for them, and a company
like Automattic that’s been built for the last decade and a half on a “distributed” model is an ideal place to see that approach work at it’s best.
We’re rolling out new induction programmes to support this growth. Because I care about our corporate culture, I’ve volunteered
myself as a Culture Buddy, so I’m going to spend some of this winter helping Newmatticians integrate into our (sometimes quirky, often chaotic) ways of working. I’m quite excited to be
at a point where I’m in the “older 50%” of the organisation and so have a responsibility for supporting the “younger 50%”, even though I’m surprised that it came around so quickly.
Automattic… culture? Can’t we just show them Office Today and be done with it?
I wonder how that graph will look in another two years.
Lots of companies have something like this, even if it falls short of a “creed”. It could be a “vision”, or a set of “values”, or something in that line.
Of course, sometimes that just means they’ve strung three clichéd words together because they think it looks good under their company logo, and they might as well have picked
any equally-meaningless words.
Company Name
respect
integrity
teamwork
Future logo and values of of Any Company, Anywhere.
But while most companies (and their staff) might pay lip service to their beliefs, Automattic’s one of few that seems to actually live it. And not in an awkward, shoehorned-in
way: people here actually believe this stuff.
By way of example:
Coffee: check. Webcam: check. Let’s touch bases, random colleague!
We’ve got a bot that, among other things, pairs up people from across the company for virtual “watercooler chat”/”coffee dates”/etc. It’s cool: I
pair-up with random colleagues in my division, or the whole company, or fellow queermatticians… and collectively these provide me a half-hour hangout about once a week. It’s a great way
to experience the diversity of culture, background and interests of your colleagues, as well as being a useful way to foster idea-sharing and “watercooler effect” serendipity.
For the last six months or so, I’ve been bringing a particular question to almost every random-chat I’ve been paired into:
What part of the Automattic creed resonates most-strongly for you right now?
On a good day, I’m at least 90% certain I’m a senior software engineer and not a cult member.
I volunteer my own answer first. It’s varied over time. Often I’m most-attached to “I will never stop learning.” Other times I connect best to “I will communicate as much as possible…”
or “I am in a marathon, not a sprint…”. Lately I’ve felt a particular engagement with “I will never pass up the opportunity to help a colleague…”.
It varies for other people too. But every single person I’ve asked this question has been able to answer it. And they’ve been able to answer it confidently and with
justifications for or examples of their choice.
Have you ever worked anywhere before where seemingly all your coworkers profess a genuine belief in the corporate creed? Like, enough that some of them get it tattooed onto their bodies. Unless you’ve been brainwashed by a cult, the answer is probably no.
If Automattic is a cult, then it might be too late for me.
Why are Automatticians like that?
For some folks, of course, the creed is descriptive rather than prescriptive. Regarding its initial creation, Matt
says that “as a hack to introduce new folks to our culture, we put a beta Automattic Creed, basically a statement of things important to us, written in the first person.”
But this alone isn’t an explanation, because back then there were only around a hundred people in the company: nowadays there are over 1,500. So how can the creed continue to be such a
pervasive influence? Or to put it another way: why are Automatticians… like that?
Do we simply attract like-minded individuals? The creed is highly visible and cross-referenced by our recruitment pages, so it wouldn’t be entirely surprising.
Maybe we filter for people who are ideologically-compatible with the creed? Insofar as the qualities it describes are essential to integrating into our corporate
culture, yes: our recruitment process does a great job of testing for those qualities.
Perhaps we converge on these values as a result of our experience as Automatticians? Once you’re in, you’re indoctrinated into the tenets of the creed and
internalise its ideas.
Or perhaps it’s a combination of the three, in some ratio or another. (What’s the ratio?)
I’ve been here 1⅔ years and don’t know the answer yet. But I’ll tell you this: it’s inspiring to be part of a team that really seem to believe in what they do.
Since joining the hiring team at Automattic in the fall of 2019, I’ve noticed different patterns and preferences on text-based interviews. Some
of these are also general interviewing tips.
Send shorter messages
Avoid Threads if possible
Show your thought process
Don’t bother name dropping
Tell the story
It’s not that different
…
Fellow Automattician Jerry Jones, whose work on accessibility was very useful in spearheading some research by my team,
earlier this year, has written a great post about interviewing at Automattic or, indeed, any company that’s opted for text-based interviews. My favourite hosting company uses these too,
and I’ve written about my experience of interviewing at Automattic, but Jerry’s post – which goes into much more detail than just the six
highlight points above, is well worth a look if you ever expect to be on either side of a text-based interview.
I started at Automattic on November 20, 2019, and it’s an incredible place to work. I’m constantly impressed by my coworkers kindness, intelligence, and compassion. If you’re
looking for a rewarding remote job that you can work from anywhere in the world, definitely apply.
I’m still overjoyed and amazed I was hired. While going through the hiring process, I devoured the blog posts from people describing their journeys. Here’s my contribution to the
catalog. I hope it helps someone.
…
I’ve written about my own experience of Automattic’s hiring process and how awesome it is, but if you’re looking for a more-concise summary of
what to expect from applying to and interviewing for a position, this is pretty great.
Some years ago, a friend of mine told me about an interview they’d had for a junior programming position. Their interviewer was one of that particular breed who was attached to
programming-test questions: if you’re in the field of computer science, you already know that these questions exist. In any case: my friend was asked to write pseudocode to shuffle a
deck of cards: a classic programming problem that pretty much any first-year computer science undergraduate is likely to have considered, if not done.
Let’s play at writing software. Rather than a computer, we’ll use paper. But to make it sound techy, we’ll call it “pseudocode”.
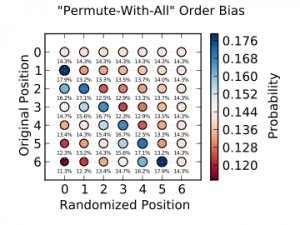
There are lots of wrong ways to programmatically shuffle a deck of cards, such as the classic “swap the card in each position with the card in a randomly-selected position”,
which results in biased
results. In fact, the more that you think in terms of how humans shuffle cards, the less-likely you are to come up with a good answer!
If we shuffled a deck of six cards with this ‘broken’ algorithm, for example, we’d be more-likely to find the card that was originally in second place at the top of the deck than in
any other position. This kind of thing REALLY matters if, for example, you’re running an online casino.
The simplest valid solution is to take a deck of cards and move each card, choosing each at random, into a fresh deck (you can do this as a human, if you like, but it takes a while)…
and that’s exactly what my friend suggested.
The interviewer was ready for this answer, though, and asked my friend if they could think of a “more-efficient” way to do the shuffle. And this is where my friend had a brain fart and
couldn’t think of one. That’s not a big problem in the real world: so long as you can conceive that there exists a more-efficient shuffle, know what to search for, and can
comprehend the explanation you get, then you can still be a perfectly awesome programmer. Demanding that people already know the answer to problems in an interview setting
doesn’t actually tell you anything about their qualities as a programmer, only how well they can memorise answers to stock interview questions (this interviewer should have stopped this
line of inquiry one question sooner).
Writing a program to shuffle a deck takes longer than just shuffling it, but that’s hardly the point, is it?
The interviewer was probably looking for an explanation of the modern form of the Fisher-Yates shuffle algorithm, which does the same thing as my friend suggested but without needing to start a “separate”
deck: here’s a video demonstrating it. When they asked for greater efficiency, the interviewer was probably looking for a more
memory-efficient solution. But that’s not what they said, and it’s certainly not the only way to measure efficiency.
When people ask ineffective interview questions, it annoys me a little. When people ask ineffective interview questions and phrase them ambiguously to boot, that’s just makes
me want to contrive a deliberately-awkward answer.
So: another way to answer the shuffling efficiency question would be to optimise for time-efficiency. If, like my friend, you get a question about improving the efficiency of a
shuffling algorithm and they don’t specify what kind of efficiency (and you’re feeling sarcastic), you’re likely to borrow either of the following algorithms. You won’t find
them any computer science textbook!
Complexity/time-efficiency optimised shuffling
Precompute and store an array of all 52! permutations of a deck of cards. I think you can store a permutation in no more than 226 bits, so I calculate that 2.3 quattuordecillion yottabytes would be plenty sufficient to store such an array. That’s
about 25 sexdecillion times more data than is believed to exist on the Web, so you’re going to need to upgrade your hard drive.
To shuffle a deck, simply select a random number x such that 0 <= x < 52! and retrieve the deck stored at that location.
This converts the O(n) problem that is Fisher-Yates to an O(1) problem, an entire complexity class of improvement.
Sure, you need storage space valued at a few hundred orders of magnitude greater than the world GDP, but if you didn’t specify cost-efficiency, then that’s not what you get.
If you’ve got a thousand galaxies worth of free space you can just fill them with
actual decks of cards – one for each permutation – and physically pick one at random. That sounds convenient, right?
You’re also going to need a really, really good PRNG to ensure that the 226-bit binary number you generate has sufficient entropy. You could always use a real
physical deck of cards to seed it, Solitaire/Pontifex-style, and go full meta, but I
worry that doing so might cause this particular simulation of the Universe to implode, sooo… do it at your own risk?
Perhaps we can do one better, if we’re willing to be a little sillier…
If you live in a universe in which quantum optimised shuffling isn’t possible, the technique below can be adapted to create a universe in which it is.
Assuming the many-worlds interpretation of quantum mechanics is applicable to reality, there’s a
yet-more-efficient way to shuffle a deck of cards, inspired by the excellent (and hilarious) quantum bogosort algorithm:
Create a superposition of all possible states of a deck of cards. This divides the universe into 52! universes; however, the division has no cost, as it happens constantly anyway.
Collapse the waveform by observing your shuffled deck of cards.
The unneeded universes can be destroyed or retained as you see fit.
Let me know if you manage to implement either of these.
How can we increase gender representation in software engineering?
Our Developer Hiring Experience team analyzed this topic in a recent user-research study. The issue resonated with women engineers and a strong response enabled the team to gain
deeper insight than is currently available from online research projects.
Seventy-one engineers who identified as women or non-binary responded to our request for feedback. Out of that pool, 24 answered a follow-up survey, and we carried out in-depth
interviews with 14 people. This was a highly skilled group, with the majority having worked in software development for over 10 years.
While some findings aligned with our expectations, we still uncovered a few surprises.
…
Excellent research courtesy of my soon-to-be new employer about the driving factors affecting women who are experienced software
engineers. Interesting (and exciting) to see that changes are already in effect, as I observed while writing about my experience of their
recruitment process.
I recently announced that I’d accepted a job offer from Automattic and I’ll be
starting work there in October. As I first decided to apply for the job 128 days ago – a nice round number – I thought I’d share with you my journey over the
last 128 days.
Automattic conduct their entire interview process via Slack online chat. I’ve still never spoken to any of my new co-workers by phone, let alone seen them in person. This is both
amazing and terrifying.
Here’s my timeline so far:
Application (days -179 to -178)
Like many geeks, I keep a list of companies that I’ve fantasised about working for some day: mine includes the Mozilla Foundation and DuckDuckGo, for example, as well as Automattic Inc. In case it’s not obvious, I like companies that I feel make the Web a better place! Just out of
interest, I was taking a look at what was going on at each of them. My role at the Bodleian, I realised a while ago, is likely to evolve
into something different probably in the second-half of 2020 and I’d decided that when it does, that would probably be the point at which I should start looking for a new challenge.
What I’d intended to do on this day 128 days ago, which we’ll call “day -179”, was to flick through the careers pages of these and a few other companies, just to get a better
understanding of what kinds of skills they were looking for. I didn’t plan on applying for new jobs yet: that was a task for next-year-Dan.
I love working here, but over the last 8 years I feel like I’ve “solved” all of the most-interesting problems.
But then, during a deep-dive into the things that make Automattic unique (now best-explained perhaps by this episode of the Distributed podcast), something clicked for me. I’d loved the creed for as long as I’d known about it, but today was the day that I finally got it, I think. That was it: I’d drunk the Kool-Aid,
and it was time to send off an application.
I sat up past midnight on day -179, sending my application by email in the small hours of day -178. In addition to attaching a copy of my CV I wrote a little under 2,000 words about why I think I’m near-uniquely qualified to work for them: my experience of distributed/remote working with
SmartData and (especially) Three Rings, my determination to remain a multidisciplinary full-stack developer despite increasing pressure to “pick a side”, my contributions towards (and use, since almost its beginning of) WordPress, and of course the diverse portfolio of projects large and
small I’ve worked on over my last couple of decades as a software engineer.
VR experiments are among the more-unusual things I’ve worked on at the Bodleian (let’s not forget that, strictly, I’m a web developer).
At the time of my application (though no longer, as a result of changes aimed at improving
gender equality) the process also insisted that I include a “secret” in my application, which could be obtained by following some instructions and with only a modest
understanding of HTTP. It could probably be worked out even by a developer who didn’t, with a little of the kind of
research that’s pretty common when you’re working as a coder. This was a nice and simple filtering feature which I imagine helps to reduce the number of spurious applications that must
be read: cute, I thought.
Fun and simple, and yet an effective way to filter out the worst of the spurious applications.
I received an automated reply less that a minute later, and an invitation to a Slack-based initial interview about a day and a half after that. That felt like an incredibly-fast
turnaround, and I was quite impressed with the responsiveness of what must necessarily be a reasonably-complex filtering and process-management process… or perhaps my idea of what
counts as “fast” in HR has been warped by years in a relatively slow-moving and bureaucratic academic environment!
Initial Interview (day -158)
I’ve got experience on both sides of the interview table, and I maintain that there’s no single “right” way to recruit – all approaches suck in different ways – but the approaches used by companies like Automattic (and for
example Bytemark, who I’ve shared details of before) at least
show a willingness to explore, understand, and adopt a diversity of modern practices. Automattic’s recruitment process for developers is a five-step (or something like that) process, with the first two stages being the application and the initial interview.
My initial interview took place 20 days after my application: entirely over text-based chat on Slack, of course.
For all you know, your interviewer might be hanging out in the same cafe or co-working space as you. But they probably aren’t. Right?
The initial interview covered things like:
Basic/conversational questions: Why I’d applied to Automattic, what interested me about working for them, and my awareness of things that were going on at the company
at the moment.
Working style/soft skills: Questions about handling competing priorities in projects, supporting co-workers, preferred working and development styles, and the like.
Technical/implementation: How to realise particular ideas, how to go about debugging a specific problem and what the most-likely causes are, understanding
clients/audiences, comprehension of different kinds of stacks.
My questions/lightweight chat: I had the opportunity to ask questions of my own, and a number of mine probed my interviewer as an individual: I felt we’d “clicked”
over parts of our experience as developers, and I was keen to chat about some up-and-coming web technologies and compare our experiences of them! The whole interview felt about as
casual and friendly as an interview ever does, and my interviewer worked hard to put me at ease.
Skills Test (day -154)
At the end of the interview, I was immediately invited to the next stage: a “skills test”: I’d be given access to a private GitHub repository and a
briefing. In my case, I was given a partially-implemented WordPress plugin to work on: I was asked to –
add a little functionality and unit tests to demonstrate it,
improve performance of an existing feature,
perform a security audit on the entire thing,
answer a technical question about it (this question was the single closest thing to a “classic programmer test question” that I experienced), and
suggest improvements for the plugin’s underlying architecture.
I was asked to spend no more than six hours on the task, and I opted to schedule this as a block of time on a day -154: a day that I’d have otherwise been doing freelance work. An
alternative might have been to eat up a couple of my evenings, and I’m pretty sure my interviewer would have been fine with whatever way I chose to manage my time – after all, a
distributed workforce must by necessity be managed firstly by results, not by approach.
Scheduling my code test for a period when the kids were out of the house allowed me to avoid this kind of juggling act.
My amazingly-friendly “human wrangler” (HR rep), ever-present in my Slack channel and consistently full of encouragement and joy,
brought in an additional technical person who reviewed my code and provided feedback. He quite-rightly pulled me up on my coding standards (I hadn’t brushed-up on the code style guide), somewhat-monolithic commits, and a few theoretical error conditions that I hadn’t
accounted for, but praised the other parts of my work.
Most-importantly, he stated that he was happy to recommend that I be moved forward to the next stage: phew!
Trial (days -147 through -98)
Of all the things that make Automattic’s hiring process especially unusual and interesting, even among hip Silicon Valley(-ish, can a 100%
“distributed” company really be described in terms of its location?) startups, probably the most (in)famous is the trial contract. Starting from day -147, near the end of May, I was
hired by Automattic as a contractor, given a project and a 40-hour deadline, at $25 USD per hour within which to (effectively) prove myself.
As awesome as it is to be paid to interview with a company, what’s far more-important is the experience of working this way. Automattic’s an unusual company, using an
unusual workforce, in an unusual way: I’ve no doubt that many people simply aren’t a good fit for distributed working; at least not yet. (I’ve all kinds of thoughts about the
future of remote and distributed working based on my varied experience with which I’ll bore you another time.) Using an extended trial as an recruitment filter provides a level of
transparency that’s seen almost nowhere else. Let’s not forget that an interview is not just about a company finding the right employee for them but about a candidate finding the right
company for them, and a large part of that comes down to a workplace culture that’s hard to define; instead, it needs to be experienced.
For all that a traditional bricks-and-mortar employer might balk at the notion of having to pay a prospective candidate up to $1,000 only to then reject them, in addition to normal
recruitment costs, that’s a pittance compared to the costs of hiring the wrong candidate! And for a company with an unusual culture, the risks are multiplied: what if
you hire somebody who simply can’t hack the distributed lifestyle?
Page 1 of 6, all written in the USA dialect of legalese, but the important part is right there at the top: the job title is
“Trial Code Wrangler”. Yeah.
It was close to this point, though, that I realised that I’d made a terrible mistake. With an especially busy period at both the Bodleian and at Three Rings and deadlines
looming in my masters degree, as well as an imminent planned anniversary break with Ruth, this was
not the time to be taking on an additional piece of contract work! I spoke to my human wrangler and my technical supervisor in the Slack channel dedicated to that purpose and explained
that I’d be spreading my up-to-40-hours over a long period, and they were very understanding. In my case, I spent a total of 31½ hours over six-and-a-bit weeks working on a project
clearly selected to feel representative of the kinds of technical problems their developers face.
That’s reassuring to me: one of the single biggest arguments against using “trials” as a recruitment strategy is that they discriminate against candidates who, for whatever reason,
might be unable to spare the time for such an endeavour, which in turn disproportionately discriminates against candidates with roles caring for other (e.g. with children) or who
already work long hours. This is still a problem here, of course, but it is significantly mitigated by Automattic’s willingness to show significant flexibility with their candidates.
I was given wider Slack access, being “let loose” from the confines of my personal/interview channel and exposed to a handful of other communities. I was allowed to mingle amongst not
only the other developers on trial (they have their own channel!) but also other full-time staff. This proved useful – early on I had a technical question and (bravely) shouted out on
the relevant channel to get some tips! After every meaningful block of work I wrote up my progress via a P2 created for that purpose, and I shared my
checkins with my supervisors, cumulating at about the 20-hour mark in a pull request that I felt was not-perfect-but-okay…
I’m normally more of a command-line git users, but I actually really came to appreciate the GitHub Desktop diff interface while describing my commits during this project.
…and then watched it get torn to pieces in a code review.
Everything my supervisor said was fair, but firm. The technologies I was working with during my trial were ones on which I was rusty and, moreover, on which I hadn’t enjoyed the benefit
of a code review in many, many years. I’ve done a lot of work solo or as the only person in my team with experience of the languages I was working in, and I’d developed a lot
of bad habits. I made a second run at the pull request but still got shot down, having failed to cover all the requirements of the project (I’d misunderstood a big one, early on, and
hadn’t done a very good job of clarifying) and having used a particularly dirty hack to work-around a unit testing issue (in my defence I knew what I’d done there was bad, and my aim
was to seek support about the best place to find documentation that might help me solve it).
I felt deflated, but pressed on. My third attempt at a pull request was “accepted”, but my tech supervisor expressed concerns about the to-and-fro it had taken me to get there.
Finally, in early July (day -101), my interview team went away to deliberate about me. I genuinely couldn’t tell which way it would go, and I’ve never in my life been so nervous to hear
back about a job.
A large part of this is, of course, the high esteem in which I hold Automattic and the associated imposter syndrome I talked about
previously, which had only been reinforced by the talented and knowledgable folks there I’d gotten to speak to during my trial. Another part was seeing their recruitment standards
in action: having a shared space with other candidate developers meant that I could see other programmers who seemed, superficially, to be doing okay get eliminated from their
trials – reality TV style! – as we went along. And finally, there was the fact that this remained one of my list of “dream companies”:
if I didn’t cut it by this point in my career, would I ever?
Two days later, on day -99, I shared what felt like an appropriate My Little Pony: Friendship is Magic GIF with
the interview team via Slack.
It took 72 hours after the completion of my trial before I heard back.
I was to be recommended for hire.
On day -98 I literally jumped for joy. This was a hugely exciting moment.
It was late in the day, but not too late to pour myself a congratulatory Caol Ila.
OMGOMGOMGOMG.
Final Interview (day -94)
A lot of blog posts about getting recruited by Automattic talk about the final interview being with CEO Matt Mullenweg himself, which I’d always thought must be an unsustainable use of his time once you get into the multiple-hundreds of employees. It looks like I’m
not the only one who thought this, because somewhere along the line the policy seems to have changed and my final interview was instead with a human wrangler (another
super-friendly one!).
That was a slightly-disappointing twist, because I’ve been a stalker fanboy of Matt’s for almost 15 years… but I’ll probably get to meet him at some point or other now
anyway. Plus, this way seems way-more logical: despite Matt’s claims to the contrary, it’s hard to see Automattic as a “startup” any longer (by age alone: they’re two years
older than Twitter and a similar age to Facebook).
The final interview felt mostly procedural: How did I find the process? Am I willing to travel for work? What could have been done differently/better?
Conveniently, I’d been so enthralled by the exotic hiring process that I’d kept copious notes throughout the process, and – appreciating the potential value of honest, contemporaneous
feedback – made a point of sharing them with the Human League (that’s genuinely what Automattic’s HR department are called, I kid you
not) before the decision was announced as to whether or not I was to be hired… but as close as possible to it, so that it could not influence it. My thinking was this: this
way, my report couldn’t help but be honest and unbiased by the result of the process. Running an unusual recruitment strategy like theirs, I figured, makes it harder to get
honest and immediate feedback: you don’t get any body language cues from your candidates, for a start. I knew that if it were my company, I’d want to know how it was working
not only from those I hired (who’d be biased in favour it it) and from those who were rejected (who’d be biased against it and less-likely to be willing to provide in-depth feedback in
general).
I guess I wanted to “give back” to Automattic regardless of the result: I learned a lot about myself during the process and especially during the trial, and I was grateful for
it!
Show me the money!
One part of the final interview, though, was particularly challenging for me, even though my research had lead me to anticipate it. I’m talking about the big question that
basically every US tech firm asks but only a minority of British ones do: what are your salary expectations?
As a Brit, that’s a fundamentally awkward question… I guess that we somehow integrated a feudalistic class system into a genetic code: we don’t expect our lords to pay us
peasants, just to leave us with enough grain for the winter after the tithes are in and to protect us from the bandits from the next county over, right? Also: I’ve known for a long
while that I’m chronically underpaid in my current role. The University of Oxford is a great employer in many ways but if you stay with them for any length of time then it has to be for
love of their culture and their people, not for the money (indeed: it’s love of my work and colleagues that kept me there for the 8+ years I
was!).
I’m pretty sure that most Brits are at least a little uncomfortable, even, when Dennis gives lip to King Arthur in Monty Python and the Holy Grail.
Were this an in-person interview, I’d have mumbled and shuffled my feet: you know, the British way. But luckily, Slack made it easy at least for me to instead awkwardly copy-paste some
research I’d done on StackOverflow, without which, I wouldn’t have had a clue what I’m allegedly-worth! My human wrangler took my garbled nonsense away to do some internal
research of her own and came back three hours later with an offer. Automattic’s offer was very fair to the extent that I was glad to have somewhere to sit down and process it
before responding (shh… nobody tell them that I am more motivated by impact than money!): I hadn’t been
emotionally prepared for the possibility that they might haggle upwards.
Three months on from writing my application, via the longest, most self-reflective, most intense, most interesting recruitment process I’ve ever experienced… I had a contract awaiting
my signature. And I was sitting on the edge of the bath, trying to explain to my five year-old why I’d suddenly gone weak at the knees.
I wanted to insert another picture of the outside of my office at the Bodleian here, but a search of my photo library gave me this one and it was too adorable to not-share.
Getting Access (day -63)
A month later – a couple of weeks ago, and a month into my three-month notice period at the Bodleian – I started getting access to Auttomatic’s computer systems. The ramp-up to getting
started seems to come in waves as each internal process kicks off, and this was the moment that I got the chance to introduce myself to my team-to-be.
I can see my team… and they can see me? /nervous wave/
I’d been spending occasional evenings reading bits of the Automattic Field Guide – sort-of a living staff handbook for Automatticians – and this was the moment when I discovered that a
lot of the links I’d previously been unable to follow had suddenly started working. You remember that bit in $yourFavouriteHackerMovie where suddenly the screen
flashes up “access granted”, probably in a green terminal font or else in the centre of a geometric shape and invariably accompanied by a computerised voice? It felt like that. I still
couldn’t see everything – crucially, I still couldn’t see the plans my new colleagues were making for a team meetup in South Africa and had to rely on Slack chats with my new
line manager to work out where in the world I’d be come November! – but I was getting there.
Getting Ready (day -51)
The Human League gave me a checklist of things to start doing before I started, like getting bank account details to the finance department. (Nobody’s been able to confirm nor denied
this for me yet, but I’m willing to bet that, if programmers are Code Wranglers, devops are Systems Wranglers, and HR are Human
Wranglers, then the finance team must refer to themselves as Money Wranglers, right?)
They also encouraged me to get set up on their email, expenses, and travel booking systems, and they gave me the password to put an order proposal in on their computer hardware ordering
system. They also made sure I’d run through their Conflict of Interest checks, which I’d done early on because for various reasons I was in a more-complicated-than-most position.
(Incidentally, I’ve checked and the legal team definitely don’t call themselves Law Wranglers, but that’s probably because lawyers understand that Words Have Power and must be
used correctly, in their field!)
Wait wait wait… let me get this straight… you’ve never met me nor spoken to me on the phone and you’re willing to post a high-end dev box to me? A month and a half before I
start working for you?
So that’s what I did this week, on day -51 of my employment with Automattic. I threw a couple of hours at setting up all the things I’d need set-up before day 0, nice and early.
I’m not saying that I’m counting down the days until I get to start working with this amazing, wildly-eccentric, offbeat, world-changing bunch… but I’m not not saying that,
either.
I’m not a big fan of job titles. I’ve always had trouble defining what I do as a noun—I
much prefer verbs (“I make websites” sounds fine, but “website maker” sounds kind of weird).
Mind you, the real issue is not finding the right words to describe what I do, but rather figuring out just what the heck it is that I actually do in the first place…
[It] was initially frustrating to not be able to tell you things about who I am and what I’ve done. But it’s great that it’s a level playing field. By the final interview I was liking
the process so much that I was reluctant to share my CV and de-anonymize myself. – Successful Careers applicant…
One of the most common pieces of advice you’ll get as a startup is this: Only hire the best. The quality of the people that work at your company will be one of the biggest factors in
your success – or failure. I’ve heard this advice over and over and over at startup events, to…