StackOverflow‘s one of the most-popular and widely-used resources for software developers. It dominates the search results when you’re looking for answers to techy questions. If you know how to read it, it can be invaluable.
But… I’m not sure what it is about the platform or the culture surrounding it that creates a certain… pattern to the answers that you can expect to receive on StackOverflow. To illustrate, let’s suppose we have a question:
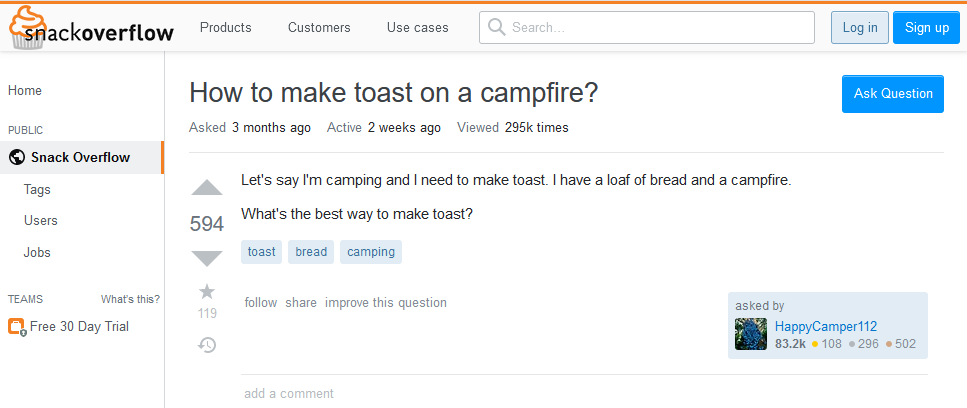
Here are the answers you might see:
The Golden Hammer
The top answer is often somebody answering not the question you asked, but the question they’d like to think you asked.

Never mind that you specifically said that you were using a campfire, the answer suggests that you use a toaster. Look back a few years and you’ll see countless examples of people asking for solutions using “vanilla” JavaScript and being told to use some heavyweight, everything-but-the-kitchen sink jQuery plugin. Now we’re in a more enlightened time, those same people are being told to use some heavyweight, everything-but-the-kitchen-sink npm module. How far we’ve come.
The Belligerent
Far often than you might expect, a perfectly reasonable “how do I do this?” question is met with an aggressive response of “why would you want to do that?”
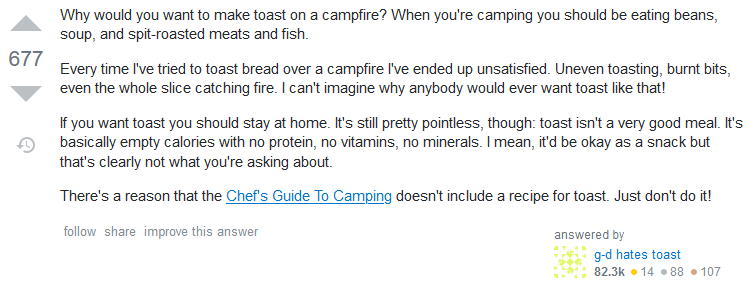
These are particularly infuriating to read when you come to a closed thread and you know that you do want to be doing the “forbidden” thing. You’ve considered the other options, you’ve assessed the situation… and now some arrogant bugger’s telling you that you’re wrong!
This kind of response is among the most annoying, second only to…
The Kindred Spirit
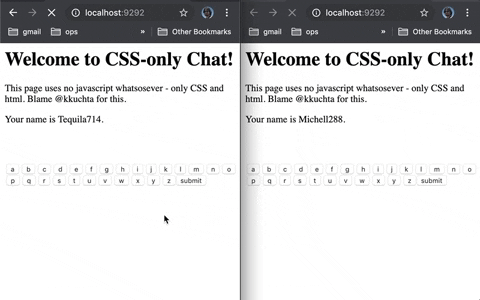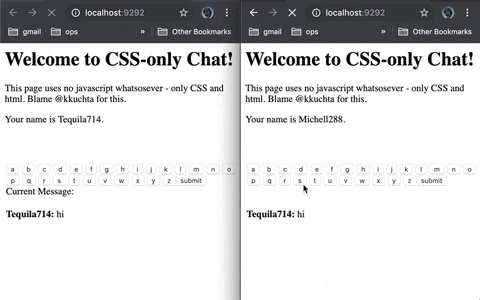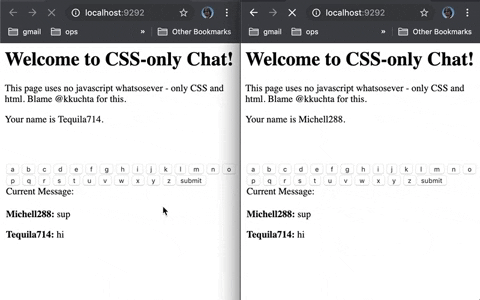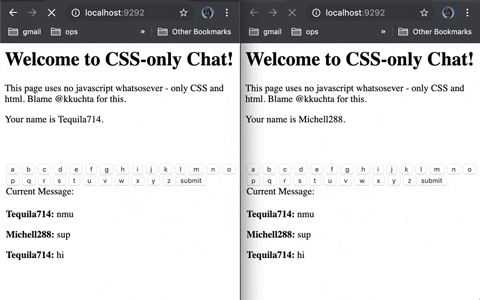
You’re getting a strange and inexplicable error message. You search for it and get exactly one result. Reading the thread, after hours of tearing your hair out, you suddenly feel a sense of relief: you’ve found another soul in this crazy world that’s suffering in precisely the same way as you are. Every word you read reconfirms for you that you and they have the same issue. At last, a solution is in reach!
 Nope.
Nope.
Not only have you not got a solution, but the saviour you thought you’d found? They do have a solution, but they were thinking only about themselves when they got it, so they didn’t share it.
I get it: when you’re deep in focus on a problem you forget that the forum you’re on will receive search traffic indefinitely. But “NM, I’ve worked it out” is the most infuriating sentence on the Internet. When you solve a tough problem that you’d talked about online, for the love of God put the solution online too.
The Expert
There’s always somebody who answers the question but in a way you’d need a PhD to comprehend.

StackOverflow is often used by beginners. Make your answer beginner-friendly if possible.
The Hero We Don’t Need
Like the Golden Hammer, the Hero We Don’t Need answers the question that they know the answer to rather than the question you actually asked. Unlike the Golden Hammer, the question they answer isn’t even remotely related to the question you asked.
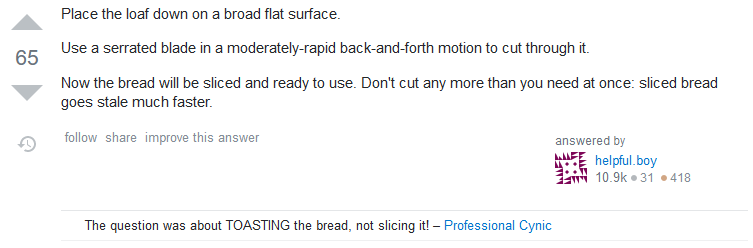
Perhaps some future site visitor who chose their search terms badly might benefit from this out-of-the-box look at a completely different problem. But I wouldn’t count on it.
The Correct Answer
Eventually, if you’re lucky, somebody will provide the actual answer to the question. You’ll often have to scroll about this far down the page to find it.
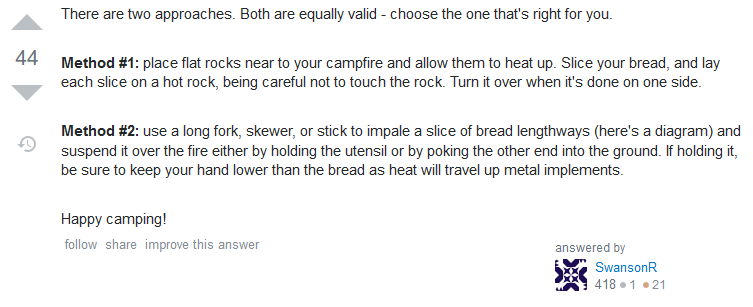 Still, at least there’s an answer. And it only took four
hours between posting the question and it appearing. Sometimes that’s what it takes, and at least the answer will be there for the next person, assuming that they, too, scroll down far
enough.
Still, at least there’s an answer. And it only took four
hours between posting the question and it appearing. Sometimes that’s what it takes, and at least the answer will be there for the next person, assuming that they, too, scroll down far
enough.
Unfortunately hundreds of novice developers will have no way to tell that this alone is the correct answer amongst the endless stream of bullshit in which it resides.
The Echo
And finally, there’s always some idiot who repeats one of the same (useless) answers from before. Just to keep the noise-to-signal ratio up, I guess.
StackOverflow’s given me so many useful answers to so many questions, over the years. But it’s also been a great source of frustration for me at the hands of six of these seven archetypes. Did I miss any?