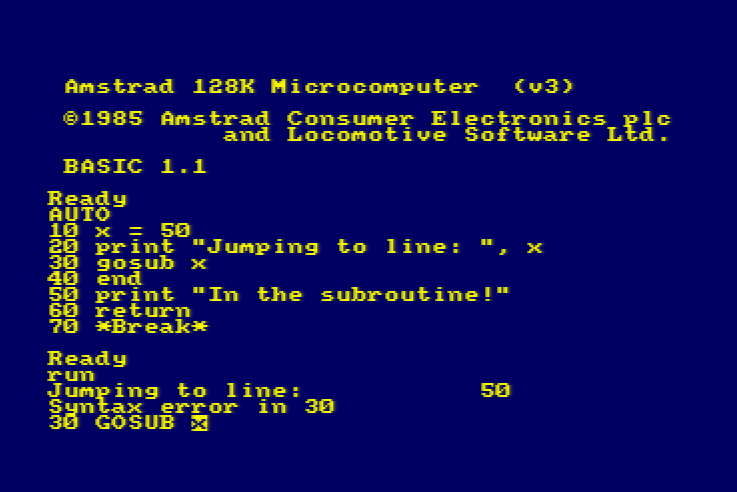
This is what the endgame should be IMO. Some things are better represented as text. Some are best understood visually. We should mix and match what works best on a case-by-case
basis. Don’t try to visualize simple code. Don’t try to write code where a diagram is better.
One of the attempts was Luna. They tried dual representation: everything is code and diagram at the same time, and you can switch between the two:
But this way, you are not only getting benefits of both ways, you are also constrained by both text and visual media at the same time. You can’t do stuff that’s hard to
visualize (loops, recursions, abstractions) AND you can’t do stuff that’s hard to code.
…
Interesting thoughts from Niki (and from Sebastian Bensusan) on how diagrams and code might someday be
intertwined as first class citizens (but not in the gross ways you might have come across in the past when people have tried to sell you on “visual programming”).
As Niki wrote about what he calls levels 2 and 3 of the concept – in which diagrams and code are intrinsically linked I found myself thinking about Twine, a programming language (or framework? or tool?… not sure how best to describe or define it!) intended for making interactive “choose your own
adventure”-style hypertext fiction.
Twine’s sort-of a level 2 implementation of visual programming: the code (scene descriptions) is mostly what’s responsible for feeding the diagram. But that’s not entirely
true: it’s possible to create new nodes in your story graph in a completely visual way, and then dip into them to edit their contents and imply how they link to others.
It’s possible that the IF engine community – who are working to lower the barriers to programming in order to improve accessibility
to people who are fiction authors first, developers second – are ahead of the curve in the area of visual programming. Consider for example how Inform’s automated test framework graphs
the permutations you (or your human testers) try, and allow you to “bless” (turn into assertions) the results so that regression testing becomes visually automated affair:
If you’ve been a programmer or programming-adjacent nerd1
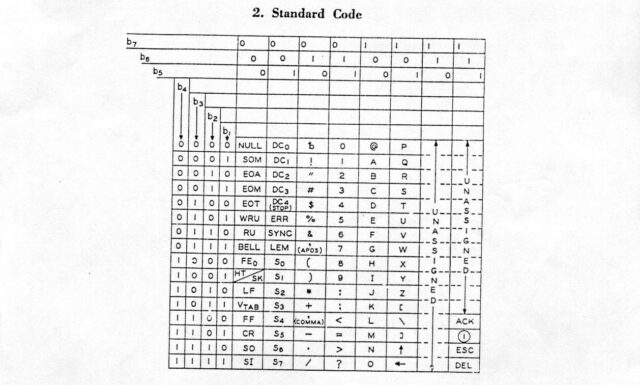
for a while, you’ll have doubtless come across an ASCII table.
An ASCII table is useful. But did you know it’s also beautiful and elegant.
Even non-programmer-adjacent nerds may have a cultural awareness of ASCII thanks to books and
films like The Martian2.
ASCII‘s still very-much around; even if you’re transmitting modern Unicode3 the
most-popular encoding format UTF-8 is specifically-designed to be backwards-compatible with ASCII! If
you decoded this page as ASCII you’d get the gist of it… so long as you ignored the garbage
characters at the end of this sentence! 😁
History
ASCII was initially standardised in X3.4-1963 (which just rolls off the tongue, doesn’t it?) which assigned meanings to 100 of the
potential 128 codepoints presented by a 7-bit4
binary representation: that is, binary values 0000000 through 1111111:
Notably absent characters in this first implementation include… the entire lowercase alphabet! There’s also a few quirks that modern ASCII fans might spot, like the curious “up” and “left” arrows at the bottom of column 101____ and the ACK and ESC control
codes in column 111____.
If you’ve already guessed where I’m going with this, you might be interested to look at the X3.4-1963 table and see that yes, many of the same elegant design choices I’ll be talking
about later already existed back in 1963. That’s really cool!
Table
In case you’re not yet intimately familiar with it, let’s take a look at an ASCII table. I’ve
colour-coded some of the bits I think are most-beautiful:
That table only shows decimal and
hexadecimal values for each character, but we’re going to need some binary too, to really appreciate some of the things that make ASCII sublime and clever.
Control codes
The first 32 “characters” (and, arguably, the final one) aren’t things that you can see, but commands sent between machines to provide additional instructions. You might be
familiar with carriage return (0D) and line feed (0A) which mean “go back to the beginning of this line” and “advance to the next line”,
respectively5.
Many of the others don’t see widespread use any more – they were designed for very different kinds of computer systems than we routinely use today – but they’re all still there.
32 is a power of two, which means that you’d rightly expect these control codes to mathematically share a particular “pattern” in their binary representation with one another, distinct
from the rest of the table. And they do! All of the control codes follow the pattern 00_____: that is, they begin with two zeroes. So when you’re reading
7-bit ASCII6, if it starts with
00, it’s a non-printing character. Otherwise it’s a printing character.
Not only does this pattern make it easy for humans to read (and, with it, makes the code less-arbitrary and more-beautiful); it also helps if you’re an ancient slow computer system
comparing one bit of information at a time. In this case, you can use a decision tree to make shortcuts.
That there’s one exception in the control codes: DEL is the last character in the table, represented by the binary number 1111111. This
is a historical throwback to paper tape, where the keyboard would punch some permutation of seven holes to represent the ones and zeros of each character. You can’t delete
holes once they’ve been punched, so the only way to mark a character as invalid was to rewind the tape and punch out all the holes in that position: i.e. all
1s.
Space
The first printing character is space; it’s an invisible character, but it’s still one that has meaning to humans, so it’s not a control character (this sounds obvious today,
but it was actually the source of some semantic argument when the ASCII standard was first being
discussed).
Putting it numerically before any other printing character was a very carefully-considered and deliberate choice. The reason: sorting. For a computer to sort a list
(of files, strings, or whatever) it’s easiest if it can do so numerically, using the same character conversion table as it uses for all other purposes7.
The space character must naturally come before other characters, or else John Smith won’t appear before Johnny Five in a computer-sorted list as you’d expect him to.
Being the first printing character, space also enjoys a beautiful and memorable binary representation that a human can easily recognise: 0100000.
Numbers
The position of the Arabic numbers 0-9 is no coincidence, either. Their position means that they start with zero at the nice round binary value 0110000
(and similarly round hex value 30) and continue sequentially, giving:
Binary
Hex
Decimal digit (character)
011 0000
30
0
011 0001
31
1
011 0010
32
2
011 0011
33
3
011 0100
34
4
011 0101
35
5
011 0110
36
6
011 0111
37
7
011 1000
38
8
011 1001
39
9
The last four digits of the binary are a representation of the value of the decimal digit depicted. And the last digit of the hexadecimal representation
is the decimal digit. That’s just brilliant!
If you’re using this post as a way to teach yourself to “read” binary-formatted ASCII in your head,
the rule to take away here is: if it begins 011, treat the remainder as a binary representation of an actual number. You’ll probably be
right: if the number you get is above 9, it’s probably some kind of punctuation instead.
Shifted Numbers
Subtract 0010000 from each of the numbers and you get the shifted numbers. The first one’s occupied by the space character already, which is a
shame, but for the rest of them, the characters are what you get if you press the shift key and that number key at the same time.
“No it’s not!” I hear you cry. Okay, you’re probably right. I’m using a 105-key ISO/UK QWERTY keyboard and… only four of the nine digits 1-9 have their shifted variants
properly represented in ASCII.
That, I’m afraid, is because ASCII was based not on modern computer keyboards but on the shifted
positions of a Remington No. 2 mechanical typewriter – whose shifted layout was the closest compromise we could find as a standard at the time, I imagine. But hey, you got to learn
something about typewriters today, if that’s any consolation.
Bonus fun fact: early mechanical typewriters omitted a number 1: it was expected that you’d use the letter I. That’s fine for printed work, but not much help for computer-readable
data.
Letters
Like the numbers, the letters get a pattern. After the @-symbol at 1000000, the uppercase letters all begin
10, followed by the binary representation of their position in the alphabet. 1 = A = 1000001, 2 = B = 1000010, and so on up to 26 = Z =
1011010. If you can learn the numbers of the positions of the letters in the alphabet, and you can count
in binary, you now know enough to be able to read any ASCII uppercase letter that’s been encoded as
binary8.
And once you know the uppercase letters, the lowercase ones are easy too. Their position in the table means that they’re all exactly 0100000higher than the uppercase variants; i.e. all the lowercase letters begin 11! 1 = a = 1100001, 2 = b = 1100010, and 26 = z =
1111010.
If you’re wondering why the uppercase letters come first, the answer again is sorting: also the fact that the first implementation of ASCII, which we saw above, was put together before it was certain that computer systems would need separate
character codes for upper and lowercase letters (you could conceive of an alternative implementation that instead sent control codes to instruct the recipient to switch case, for
example). Given the ways in which the technology is now used, I’m glad they eventually made the decision they did.
Beauty
There’s a strange and subtle charm to ASCII. Given that we all use it (or things derived from it)
literally all the time in our modern lives and our everyday devices, it’s easy to think of it as just some arbitrary encoding.
But the choices made in deciding what streams of ones and zeroes would represent which characters expose a refined logic. It’s aesthetically pleasing, and littered with
historical artefacts that teach us a hidden history of computing. And it’s built atop patterns that are sufficiently sophisticated to facilitate powerful processing while being coherent
enough for a human to memorise, learn, and understand.
Footnotes
1 Programming-adjacent? Yeah. For example, geocachers who’ve ever had to decode a
puzzle-geocache where the coordinates were presented in binary (by which I mean: a binary representation of ASCII) are “programming-adjacent nerds” for the purposes of this discussion.
2 In both the book and the film, Mark Watney divides a circle around the recovered
Pathfinder lander into segments corresponding to hexadecimal digits 0 through F to allow the rotation of its camera (by operators on Earth) to transmit pairs of 4-bit words.
Two 4-bit words makes an 8-bit byte that he can decode as ASCII, thereby effecting a means to
re-establish communication with Earth.
3 Y’know, so that you can type all those emoji you love so much.
4 ASCII is often thought of as an 8-bit code, but it’s not: it’s 7-bit. That’s why virtually every ASCII message you see starts every octet with a zero. 8-bits is a convenient number for transmission purposes (thanks
mostly to being a power of two), but early 8-bit systems would be far more-likely to use the 8th bit as a parity check, to help
detect transmission errors. Of course, there’s also nothing to say you can’t just transmit a stream of 7-bit characters back to back!
5 Back when data was sent to teletype printers these two characters had a distinct
different meaning, and sometimes they were so slow at returning their heads to the left-hand-side of the paper that you’d also need to send a few null bytes e.g. 0D 0A
00 00 00 00 to make sure that the print head had gotten settled into the right place before you sent more data: printers didn’t have memory buffers at this point! For
compatibility with teletypes, early minicomputers followed the same carriage return plus line feed convention, even when outputting text to screens. Then to maintain backwards
compatibility with those systems, the next generation of computers would also use both a carriage return and a line feed character to mean “next line”. And so,
in the modern day, many computer systems (including Windows most of the time, and many Internet protocols) still continue to use the combination of a carriage return
and a line feed character every time they want to say “next line”; a redundancy build for a chain of backwards-compatibility that ceased to be relevant decades ago but which
remains with us forever as part of our digital heritage.
6 Got 8 binary digits in front of you? The first digit is probably zero. Drop it. Now
you’ve got 7-bit ASCII. Sorted.
7 I’m hugely grateful to section 13.8 of Coded Character Sets, History and
Development by Charles E. Mackenzie (1980), the entire text of which is available freely
online, for helping me to understand the importance of the position of the space character within the ASCII character set. While most of what I’ve written in this blog post were things I already knew, I’d never fully grasped
its significance of the space character’s location until today!
8 I’m sure you know this already, but in case you’re one of today’s lucky 10,000 to discover that the reason we call the majuscule and minuscule letters “uppercase” and “lowercase”, respectively, dates to 19th
century printing, when moveable type would be stored in a box (a “type case”) corresponding to its character type. The “upper” case was where the capital letters would typically be
stored.
We’ve recently had the attics of our house converted, and I moved my bedroom up to one of the newly-constructed rooms.
To make the space my own, I did a little light carpentry up there: starting with a necessary reshaping of the doors, then moving on to shelving
and eventually… a secret cabinet!
I’d love to tell you about how I built it: but first, a disclaimer! I am a software engineer, and with good reason. Letting me near a soldering iron is ill-advised. Letting me
use a table saw is tempting fate.
Letting me teach you anything about how you should use a soldering iron or a table saw is, frankly, asking for trouble.
Knowing that I’d been short on shelf space in my old bedroom, I started work on fitting shelves for my new bedroom before the carpet had even arrived.
Building a secret cabinet wasn’t part of my plan, but came about naturally after I got started. I’d bought a stack of pine planks and – making use of Ruth’s table saw – cut them to squarely fit beneath each of the two dormer windows1.
While sanding and oiling the wood I realised that I had quite a selection of similarly-sized offcuts and found myself wondering if I could find a use for them.
The hardest part of sanding and oiling wood on the hottest day of the year is all the beer breaks you have to take. Such a drag.
I figured I had enough lumber to insert a small cabinet into one of the bookshelves, and that got me thinking… what about if it were a secret cabinet, disguised as books unless
you knew where to look. Or to go one step further: what if it had some kind of electronic locking mechanism that could be triggered from somewhere else in the room2.
There are other ways in which I’ve made my new room distinctly-“mine” – like the pair of magpies – but probably the secret cabinet is the most-distinctive.
Not wanting to destroy a stack of real books, which is the traditional way to get a collection of book spines for the purpose of decorating a “fake bookshelf” panel3,
I looked online and discovered the company that made the fake book spines used at the shop of my former
employer. They looked ideal: carefully shaped and painted panels with either an old-school or contemporary look.
Buuut, they don’t seem to be well-equipped for short runs and are doubtless pricey, so I looked elsewhere and found the eBay
presence of Beatty Lockey Antiques in Lowestoft. They’d acquired a stack of them second-hand from the set of Netflix’s
The School for Good and Evil.4
(By the way: at time of writing they’ve still got a few panels left, if you want to make your own…)
I absolutely must sing the praises of Brad at Beatty Lockey Antiques who, after the first delivery of fake book fronts was partially-damaged in transit, was super quick about helping
me find the closest-available equivalent (I’d already measured-up based on the one I’d thought I was getting) and sent a replacement.
The cabinet is just a few bits of wood glued together and reinforced with L-shaped corner braces, with a trio of thin strips – made from leftover architrave board – attached using small
brass hinges. The fake book fronts are stuck to the strips using double-sided mounting tape left over from installing a bathroom mirror. A simple magnetic clasp holds the door shut when
pushed closed5,
and the hinges are inclined to “want” the door to stand half-open, which means it only needs a gentle push away from the magnetic catch to swing it open.
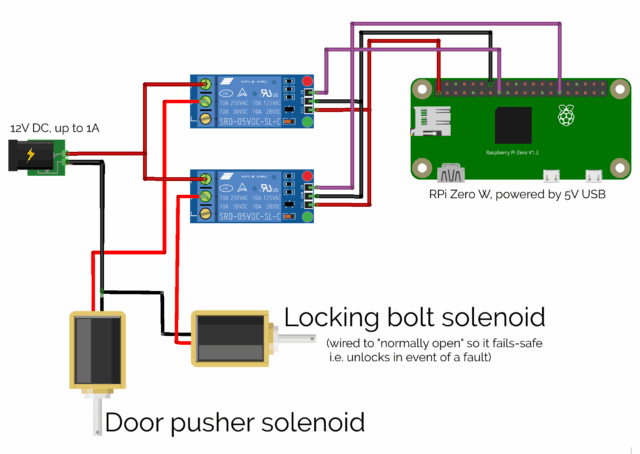
The wiring is uncomplicated enough that even I – a self-confessed software engineer – could manage it. Note the separate power supply: those solenoids can draw a full 1 amp in a
“surge” that’s enough to give a little Raspberry Pi Zero a Bad Day if you try to power it directly from the computer (there might be some capacitor-based black magic that I don’t
understand that could have made this easier, I suppose)!
I mounted a Raspberry Pi Zero W into a rear corner inside the cabinet6, and wired it up via a relay to what was sold to me as a “large push-pull solenoid”, then
began experimenting with the position in which I’d need to mount it to allow it to “kick” open the door, against the force of the magnetic clasp7.
This was, amazingly, the hardest part of the whole project! Putting the solenoid too close to the door didn’t work: it couldn’t “push” it from a standing start. Too far away, and the
natural give of the door took the strain without pushing it open. Just the right distance, and the latch had picked up enough momentum that its weight “kicked” the door away from the
magnet and followed-through to ensure that it kept moving.
A second solenoid, mounted inside the top of the cabinet, slides into the “loop” part of a large bolt fitting, allowing the cabinet to be electronically “locked”.
I seriously must’ve spent about an hour getting the position of that little “kicker” in the bottom right just right.
Next up came the software. I started with a very simple Python program8
that would run a webserver and, on particular requests, open the lock solenoid and push with the “kicker” solenoid.
#!/usr/bin/python## a basic sample implementation of a web interface for a secret cabinet## setup:# sudo apt install -y python3-flask# wget https://github.com/sbcshop/Zero-Relay/blob/master/pizero_2relay.py## running:# sudo flask --app web run --host=0.0.0.0 --port 80fromflaskimport Flask, redirect, url_for
importpizero_2relayaspizerofromtimeimport sleep
# set up pizero_2relay with the two relays attached to this Pi Zero:
r1 = pizero.relay("R1") # The "kicker" relay
r2 = pizero.relay("R2") # The "locking bolt" relay
app = Flask(__name__)
# GET / - nothing here@app.route("/")
defindex():
return"Nothing to see here."# GET /relay - show a page with "open" and "lock" links@app.route("/relay")
defrelay():
return"<html><head><meta name='viewport' content='width=device-width, initial-scale=1'></head><body><ul><li><a href='/relay/open'>Open</a></li><li><a href='/relay/lock'>Lock</a></li></ul>"# GET /relay/open - open the secret cabinet then return to /relay# This ought to be a POST request in your implementation, and you probably# want to add some security e.g. a @app.route("/relay/open")
defopen():
# Retract the lock:
r2.off()
sleep(0.5)
# Fire the kicker twice:
r1.on()
sleep(0.25)
r1.off()
sleep(0.25)
r1.on()
sleep(0.25)
r1.off()
# Redirect back:return redirect(url_for('relay'))
@app.route("/relay/lock")
deflock():
# Engage the lock:
r2.on()
return redirect(url_for('relay'))
Don’t use this code as-is on any kind of open network, obviously. Follow the comments for some tips on what you’ll need to change.
Once I had something I could trigger from a web browser or with curl, I could start experimenting with trigger mechanisms. I had a few ideas (and prototyped a couple of
them), including:
A mercury tilt switch behind a different book, so you pull it to release the cabinet in the style of a classic movie secret door.
A microphone that listens for a specific pattern of knocks on a nearby surface.
I had far too much fun playing about with crappy prototypes.
An RFID reader mounted underneath another surface, and a tag on the underside of an ornament: moving the ornament to the “right” place on the surface triggers the cabinet (elsewhere
in the room).
The current design, shown in the video above, where a code9 is transmitted to the cabinet for verification.
I think I’m happy with what I’ve got going on with it now. And it’s been a good opportunity to improve my carpentry, electronics, and Python.
Footnotes
1 The two dormer windows, wouldn’t you guarantee it, were significantly different
widths despite each housing a window of the same width. Such are the quirks of extending a building that the previous occupier had previously half-heartedly tried to
extend, I guess.
2 Why yes, I am a big fan of escape rooms. Why do you ask?
3 For one thing, I live with JTA, and
I’m confident that he’d somehow be able to hear the silent screams of whatever trashy novels I opted to sacrifice for the good of the project.
4 As a bonus, my 10-year-old is a big fan of the book series that inspired the film (and a
more-muted fan of the film itself) and she was ever-so excited at my project using real-life parts of the set of the movie… that she’s asked me to make a similar secret cabinet for
her, when we get around to redecorating her room later in the year!
5 If I did it again, I might consider using a low-powered electromagnetic lock to hold the
door shut. In this design, I used a permanent magnet and a pair of latch solenoids: one to operate a bolt, the second to “kick” the door open against the pull of the magnet, and… it
feels a little clumsier than a magnetic lock might’ve.
6 That double-sided mounting tape really came in handy for this project!
7 Props to vlogger Technology Connections, one of whose excellent videos on the
functionality of 1970s pinball tables – maybe this one? – taught me what a latch solenoid was in the first place, last year,
which probably saved me from the embarrassment of trying to do this kind of thing with, I don’t know, a stepper motor or something.
8 I’m not a big fan of Python normally, but the people who made my relays had some up with
a convenience library for them that was written in it, so I figured it would do.
9 Obviously the code isn’t A-B; I changed it temporarily for the video.
RotatingSandwiches.com is a website showcasing animated GIF files of rotating
sandwiches1. But it’s got a problem: 2 of the 51 sandwiches rotate the
wrong way. So I’ve fixed it:
The Eggplant Parm Sub is one of two sandwiches whose rotation doesn’t match the rest.
My fix is available as a userscript on GreasyFork, so you can use your
favourite userscript manager2
to install it and the rotation will be fixed for you too. Here’s the code (it’s pretty simple):
1
2
3
4
5
6
7
8
9
10
11
12
// ==UserScript==// @name Standardise sandwich rotation on rotatingsandwiches.com// @namespace rotatingsandwiches.com.danq.me// @match https://rotatingsandwiches.com/*// @grant GM_addStyle// @version 1.0// @author Dan Q <https://danq.me/>// @license The Unlicense / Public Domain// @description Some sandwiches on rotatingsandwiches.com rotate in the opposite direction to the majority. 😡 Let's fix that.// ==/UserScript==
GM_addStyle('.q23-image-216, .q23-image-217 { transform: scaleX(-1); }');
Unless you’re especially agitated by irregular sandwich rotation, this is perhaps the most-pointless userscript ever created. So why did I go to the trouble?
Fixing Websites
Obviously, I’m telling you this as a vehicle to talk about userscripts in general and why you should be using them.
But the real magic is being able to remix the web your way. With just a little bit of CSS or JavaScript experience you
can stop complaining that a website’s design has changed in some way you don’t like or that some functionality you use isn’t as powerful or convenient as you’d like and you can fix
it.
A website I used disables scrolling until all their (tracking, advertising, etc.) JavaScript loads, and my privacy blocker blocks those files: I could cave and disable my browser’s
privacy tools… but it was almost as fast to add setInterval(()=>document.body.style.overflow='', 200); to a userscript and now it’s fixed.
Don’t want a Sports section on your BBC News homepage (not just the RSS
feed!)? document.querySelector('a[href="/sport"]').closest('main > div').remove(). Sorted.
I’m a huge fan of building your own tools to “scratch your own itch”. Userscripts are a highly accessible introduction to doing so that even beginner programmers can get on board with
and start getting value from. More-advanced scripts can do immensely clever and powerful things, but even if you just use them to apply a few light CSS touches to your favourite websites, that’s still a win.
Footnotes
1 Remember when a website’s domain name used to be connected to what it was for?
RotatingSandwiches.com does.
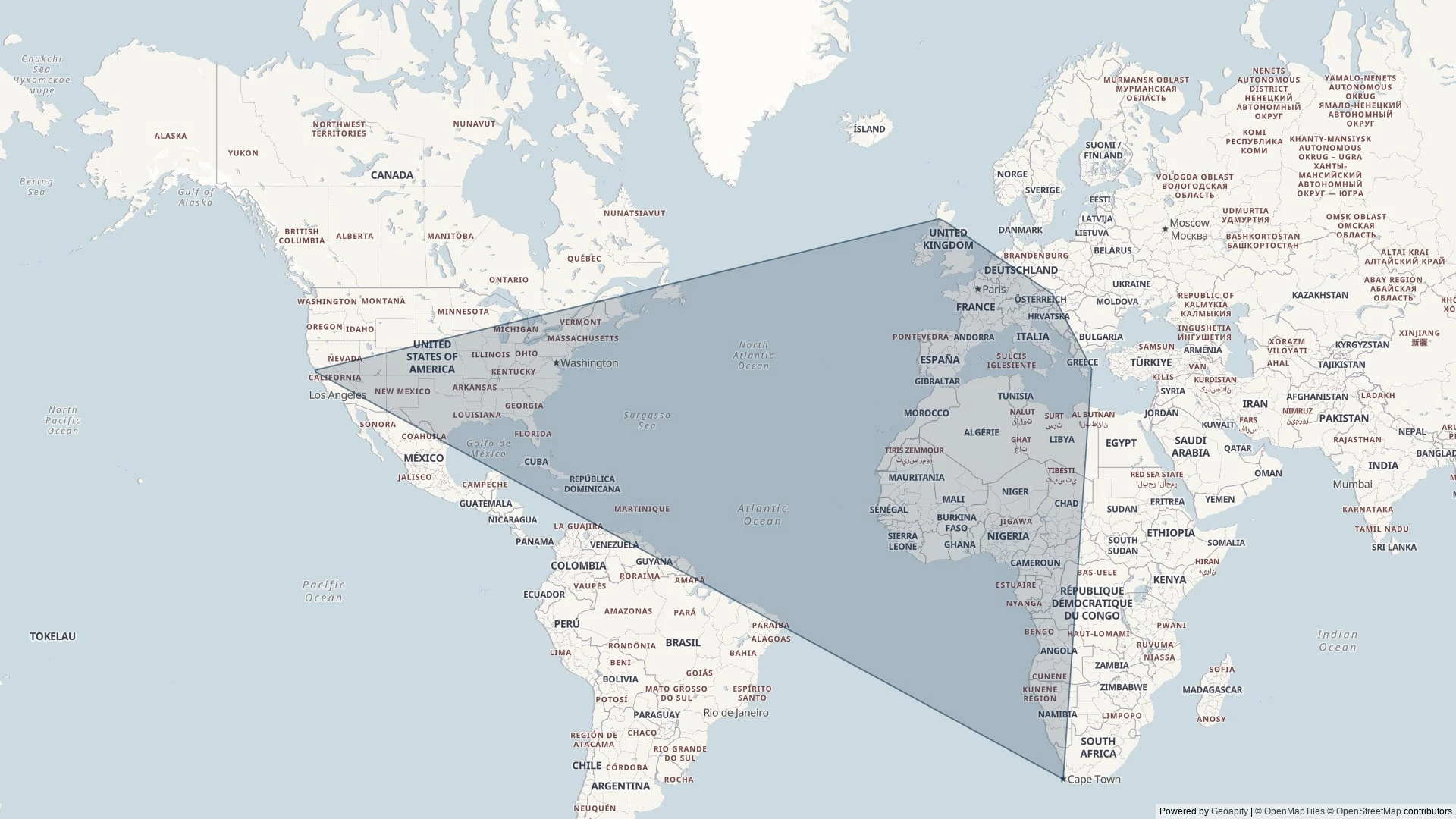
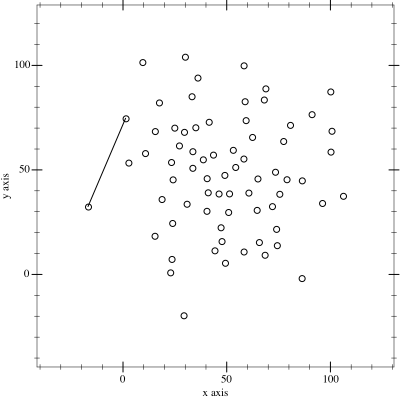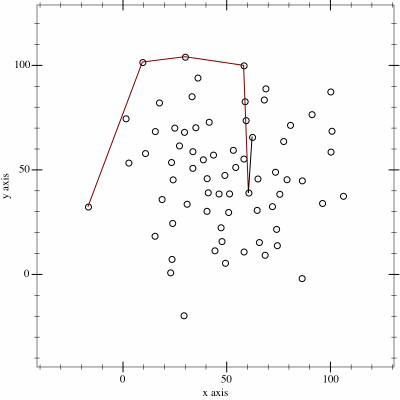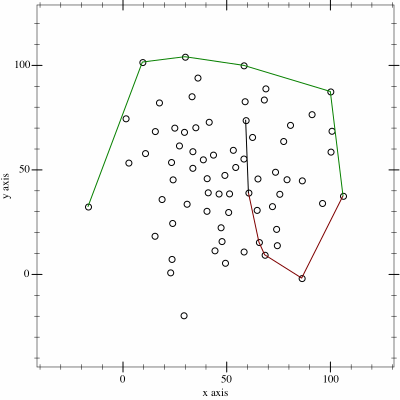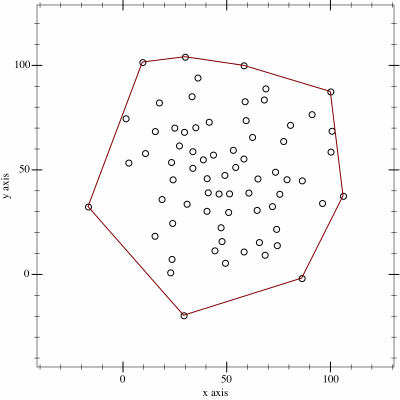
I thought it might be fun to try to map the limits of my geocaching/geohashing. That is, to draw the smallest possible convex polygon that surrounds all of the
geocaches I’ve found and geohashpoints I’ve successfully visited.
Mathematically, such a shape is a convex hull – the smallest polygon encircling a set of points without concavity. Here’s how I made it:
1. Extract all the longitude/latitude pairs for every successful geocaching find and geohashpoint expedition.I keep them in my blog database, so I was able to use some SQL to
fetch them:
SELECTDISTINCT coord_lon.meta_value lon, coord_lat.meta_value lat
FROM wp_posts
LEFTJOIN wp_postmeta expedition_result ON wp_posts.ID = expedition_result.post_id AND expedition_result.meta_key ='checkin_type'LEFTJOIN wp_postmeta coord_lat ON wp_posts.ID = coord_lat.post_id AND coord_lat.meta_key ='checkin_latitude'LEFTJOIN wp_postmeta coord_lon ON wp_posts.ID = coord_lon.post_id AND coord_lon.meta_key ='checkin_longitude'LEFTJOIN wp_term_relationships ON wp_posts.ID = wp_term_relationships.object_id
LEFTJOIN wp_term_taxonomy ON wp_term_relationships.term_taxonomy_id = wp_term_taxonomy.term_taxonomy_id
LEFTJOIN wp_terms ON wp_term_taxonomy.term_id = wp_terms.term_id
WHERE wp_posts.post_type ='post'AND wp_posts.post_status ='publish'AND wp_term_taxonomy.taxonomy ='kind'AND wp_terms.slug ='checkin'AND expedition_result.meta_value IN ('Found it', 'found', 'coordinates reached', 'Attended');
2. Next, I determine the convex hull of these points. There are an interesting variety of
algorithms for this so I adapted the Monotone Chain approach (there are
convenient implementations in many languages). The algorithm seems pretty efficient, although that doesn’t matter much to me because I’m caching the results for a fortnight.
I watched way too many animations of different convex hull algorithms before selecting this one… pretty-much arbitrarily.
An up-to-date (well, no-more than two weeks outdated) version of the map appears on my geo* stats page. I don’t often get to go caching/hashing
outside the bounds already-depicted, but I’m excited to try to find opportunities to push the boundaries outwards as I continue to explore the world!
(I could, I suppose, try to draw a second larger area of places I’ve visited: the difference between the smaller and larger areas would represent all of the opportunities I’d missed to
find a hashpoint!)
I was contacted this week by a geocacher called Dominik who, like me, loves geocaching…. but hates it when the coordinates for a cache are hidden behind a virtual jigsaw puzzle.
A popular online jigsaw tool used by lazy geocache owners is Jigidi: I’ve come up with severaltechniques for bypassing their puzzles or at
least making them easier.
Not just any puzzle; the geocache used an ~1000 piece puzzle! Ugh!
I experimented with a few ways to work-around the jigsaw, e.g. dramatically increasing the “snap range” so dragging a piece any distance would result in it jumping to a
neighbour, and extracting original image URLs from localStorage. All were good, but none were
perfect.
For a while, making pieces “snap” at any range seemed to be the best hacky workaround.
Then I realised that – unlike Jigidi, where there can be a congratulatory “completion message” (with e.g. geocache coordinates in) – in JigsawExplorer the prize is seeing the
completed jigsaw.
You can click a button to see the “box” of a jigsaw, but this can be disabled by the image uploader.
Let’s work on attacking that bit of functionality. After all: if we can bypass the “added challenge” we’ll be able to see the finished jigsaw and, therefore, the geocache
coordinates. Like this:
Hackaround
Here’s how it’s done. Or keep reading if you just want to follow the instructions!
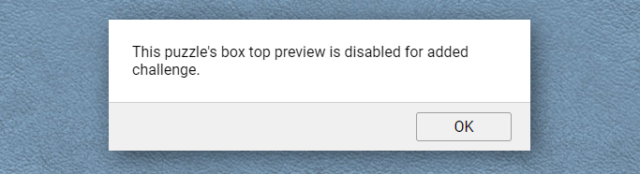
Open a jigsaw and try the “box cover” button at the top. If you get the message “This puzzle’s box top preview is disabled for added challenge.”, carry on.
Open your browser’s debug tools (F12) and navigate to the Sources tab.
Find the jigex-prog.js file. Right-click and select Override Content (or Add Script Override).
In the overridden version of the file, search for the string – e&&e.customMystery?tt.msgbox("This puzzle's box top preview is disabled for added challenge."): –
this code checks if the puzzle has the “custom mystery” setting switched on and if so shows the message, otherwise (after the :) shows the box cover.
Carefully delete that entire string. It’ll probably appear twice.
Reload the page. Now the “box cover” button will work.
The moral, as always, might be: don’t put functionality into the client-side JavaScript if you don’t want the user to be able to bypass it.
Or maybe the moral is: if you’re going to make a puzzle geocache, put some work in and do something clever, original, and ideally with fieldwork rather than yet another low-effort
“upload a picture and choose the highest number of jigsaw pieces to cut it into from the dropdown”.
Yesterday, I wrote the stupidest bit of CSS of my entire career.
Two new visual elements and one textual one will make it clear where a product’s placement in the marketplace is sponsored.
Owners of online shops powered by WooCommerce can optionally “connect” their stores back to Woo.com. This enables them to manage their subscriptions to
any extensions they use to enhance their store1. They can also browse a
marketplace of additional extensions they might like to consider, which is somewhat-tailored to them based on e.g. their geographical location2
In the future, we’ll be adding sponsored products to the marketplace listing, but we want to be transparent about it so yesterday I was working on some code that would determine from
the appropriate API whether an extension was sponsored and then style it differently to make this clear. I took
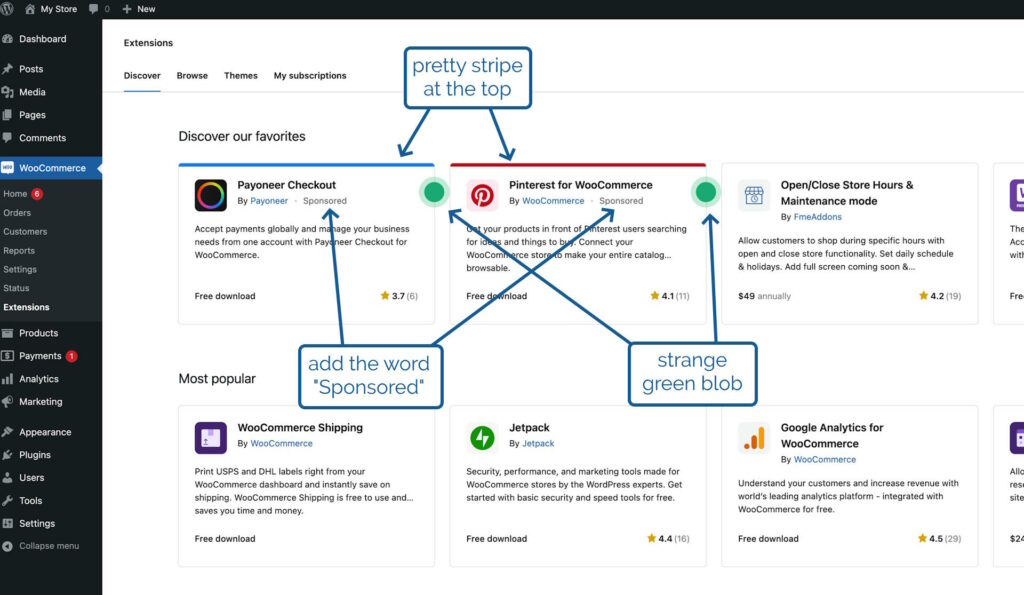
a look at the proposal from the designer attached to the project, which called for
the word “Sponsored” to appear alongside the name of the extension’s developer,
a stripe at the top in the brand colour of the extension, and
a strange green blob alongside it
That third thing seemed like an odd choice, but I figured that probably I just didn’t have the design or marketing expertise to understand it, and I diligently wrote some appropriate code.3
I even attached to my PR a video demonstrating how my code reviewers could test it without spoofing actual sponsored
extensions.
After some minor tweaks, my change was approved. The designer even swung by and gave it a thumbs-up. All I needed to do was wait for the automated end-to-end tests to complete, and I’d
be able to add it to WooCommerce ready to be included in the next-but-one release. Nice.
In the meantime, I got started on my next bit of work. This one also included some design work by the same designer, and wouldn’t you know it… this one also had a little green
blob on it?
I’m almost embarrassed to admit that my first thought was that this must be part of some wider design strategy to put little green blobs everywhere.
Then it hit me. The blobs weren’t part of the design at all, but the designer’s way of saying “look at this bit, it’s important!”. Whoops!
So I got to rush over to my (already-approved, somehow!) changeset and rip out
the offending CSS: the stupidest bit of CSS of my entire career.
Not bad code per se, but reasonable code resulting from a damn-stupid misinterpretation of a designer’s wishes. Brilliant.
3 A fun side-effect of working on open-source software is that my silly mistake gets
immortalised somewhere where you can go and see it any time you like!
I used to have a single minor niggle with the BBC News RSS feed: that it included sports news, which I didn’t care
about. So I wrote a script that downloaded it, stripped
sports news, and re-exported the feed for me to subscribe to. Magic.
Lately my BBC News feed has caused me some annoyance and frustration.
But lately – presumably as a result of technical changes at the Beeb’s side – this feed has found two fresh ways to annoy me:
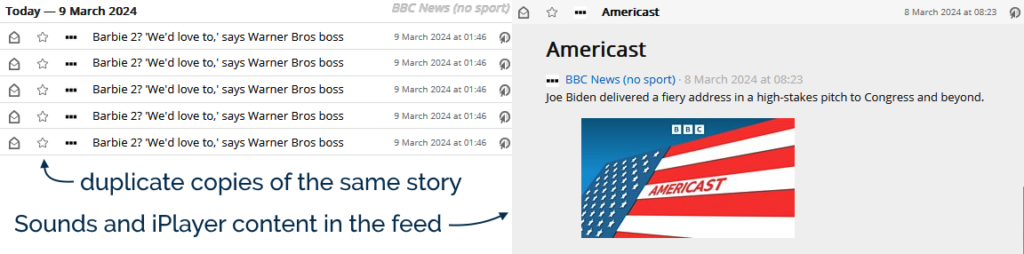
The feed now re-publishes a story if it gets re-promoted to the front page… but with a different<guid> (it appears to get a #0 after it
when first published, a #1 the second time, and so on). In a typical day the feed reader might scoop up new stories about once an hour, any by the time I get to reading them the
same exact story might appear in my reader multiple times. Ugh.
They’ve started adding iPlayer and BBC Sounds content to the BBC News feed. I don’t follow BBC News in my feed reader because I want to watch or listen to things. If
you do, that’s fine, but I don’t, and I’d rather filter this content out.
Luckily, I already have a recipe for improving this feed, thanks to my prior work. Let’s look at my newly-revised script (also available on GitHub):
#!/usr/bin/env rubyrequire'bundler/inline'# # Sample crontab:# # At 41 minutes past each hour, run the script and log the results# */20 * * * * ~/bbc-news-rss-filter-sport-out.rb > ~/bbc-news-rss-filter-sport-out.log 2>>&1# Dependencies:# * open-uri - load remote URL content easily# * nokogiri - parse/filter XML
gemfile do
source 'https://rubygems.org'
gem 'nokogiri'endrequire'open-uri'# Regular expression describing the GUIDs to reject from the resulting RSS feed# We want to drop everything from the "sport" section of the website, also any iPlayer/Sounds linksREJECT_GUIDS_MATCHING=/^https:\/\/www\.bbc\.co\.uk\/(sport|iplayer|sounds)\//# Load and filter the original RSS
rss =Nokogiri::XML(open('https://feeds.bbci.co.uk/news/rss.xml?edition=uk'))
rss.css('item').select{|item| item.css('guid').text =~REJECT_GUIDS_MATCHING }.each(&:unlink)
# Strip the anchors off the <guid>s: BBC News "republishes" stories by using guids with #0, #1, #2 etc, which results in duplicates in feed readers
rss.css('guid').each{|g|g.content=g.content.gsub(/#.*$/,'')}
File.open( '/www/bbc-news-no-sport.xml', 'w' ){ |f| f.puts(rss.to_s) }
It’s amazing what you can do with Nokogiri and a half dozen lines of Ruby.
That revised script removes from the feed anything whose <guid> suggests it’s sports news or from BBC Sounds or iPlayer, and also strips any “anchor” part of the
<guid> before re-exporting the feed. Much better. (Strictly speaking, this can result in a technically-invalid feed by introducing duplicates, but your feed reader
oughta be smart enough to compensate for and ignore that: mine certainly is!)
You’re free to take and adapt the script to your own needs, or – if you don’t mind being tied to my opinions about what should be in BBC News’ RSS feed – just subscribe to my copy at:https://fox.q-t-a.uk/bbc-news-no-sport.xml
Update: nowadays, the best place to get this feed and more like it is at bbc-feeds.danq.dev.
This feels disappointingly like the prompt from day 2, but I’m gonna pivot it by letting my answer from three weeks ago only cover
one of the five points:
Code
Magic
Piano
Play
Learn
Let’s take a look at each of those, briefly.
Code
Code is poetry. Code is fun. Code is a many-splendoured thing.
When I’m not coding for work or coding as a volunteer, I’m often caught
coding for fun. Sometimes I write WordPress-ey things. Sometimes I write other random things. I tend to open-source almost everything I write, most
of it via my GitHub account.
Magic
Now I don’t work in the city centre nor have easy access to other magicians, I don’t perform as much magic as I used to. But I still try to keep my hand in and occasionally try new
things; I enjoy practicing sleights when I’m doing work-related things that don’t require my hands (meetings, code reviews, waiting for the damn unit tests to run…), a tip I learned
from fellow magician Andy.
My favourite go-to trick with an untampered deck of cards is my variant of the Ambitious Classic; here’s a bit from the middle of the trick from the last time I performed it in a
video meeting.
You’ll usually find a few decks of cards on my desk at any given time, mostly Bikes.1
Piano
I started teaching myself piano during the Covid lockdowns as a distraction from not being able to go anywhere (apparently I’m not the only one), and as an effort to do more of what I’m bad at.2
Since then, I’ve folded about ten minutes of piano-playing3,
give or take, into my routine virtually every day.
This is what piano playing looks like. But perhaps only barely.
I fully expect that I’ll never be as accomplished at it as, say, the average 8-year-old on YouTube, but that’s not what it’s about. If I take a break from programming, or meetings, or
childcare, or anything, I can feel that playing music exercises a totally different part of my mind. I’d heard musicians talk about such an experience before,
but I’d assumed that it was hyperbole… but from my perspective, they’re right: practicing an instrument genuinely does feel like using a part of your brain than you use for anything
else, which I love!
A lot of my
RPG-gaming takes place online, via virtual tabletops, and is perhaps the most obvious “playtime” play activities I routinely engage
in.
At the weekend I dusted off Vox Populi, my favourite mod for Civilization V, my favourite4
entry in the Civilization series, which in turn is one of my favourite video game series5. I don’t
get as much time for videogaming as I might like, but that’s probably for the best because a couple of hours disappeared on Sunday evening before I even blinked! It’s addictive
stuff.
Learn
As I mentioned back on day 3 of bloganuary, I’m a lifelong learner. But even when I’m not learning in an academic setting, I’m
doubtless learning something. I tend to alternate between fiction and non-fiction books on my bedside table. I often get lost on deep-dives through the depths of the Web after
a Wikipedia article makes me ask “wait, really?” And just sometimes, I set out to learn some kind of new skill.
In short: with such a variety of fun things lined-up, I rarely get the opportunity to be bored6!
Footnotes
1 I like the feel of Bicycle cards and the way they fan. Plus: the white border – which is
actually a security measure on playing cards designed to make bottom-dealing more-obvious and thus make it harder for people to cheat at e.g. poker – can actually be turned to work
for the magician when doing certain sleights, including one seen in the mini-video above…
2 I’m not strictly bad at it, it’s just that I had essential no music tuition or
instrument experience whatsoever – I didn’t even have a recorder at primary school! – and so I was starting at square zero.
3 Occasionally I’ll learn a bit of a piece of music, but mostly I’m trying to improve my
ability to improvise because that scratches an itch in a part of my brain in a way that I find most-interesting!
4 Games in the series I’ve extensively played include: Civilization,
CivNet, Civilization II (also Test of Time), Alpha Centauri (a game so good I paid for it three times, despite having previously pirated
it), Civilization III, Civilization IV, Civilization V, Beyond Earth (such a disappointment compared to SMAC) and Civilization VI, plus all their expansions except for the very latest one for VI. Also spinoffs/clones
FreeCiv, C-Evo, and both Call to Power games. Oh, and at least two of the board games. And that’s just the ones I’ve played enough to talk in detail about:
I’m not including things like Revolution which I played an hour of and hated so much I shan’t touch it again, nor either version of Colonization which I’m
treating separately…
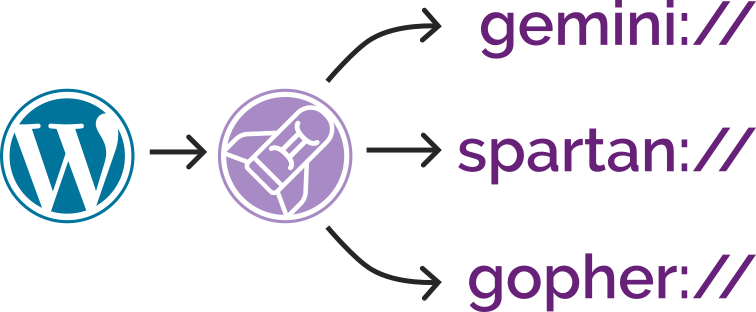
Now I’ve added support for Spartan3 too and, seeing as the implementations shared functionality, I’ve
combined all three – Gemini, Spartan, and Gopher – into a single package: CapsulePress.
CapsulePress is a Gemini/Spartan/Gopher to WordPress bridge. It lets you use WordPress as a CMS for any or all of
those three non-Web protocols in addition to the Web.
For example, that means that this post is available on all of:
It’s also possible to write posts that selectively appear via different media: if I want to put something exclusively on my gemlog, I can, by assigning metadata that
tells WordPress to suppress a post but still expose it to CapsulePress. Neat!
Using Gemini and friends in the 2020s make me feel like the dream of the Internet of the nineties and early-naughties is still alive. But with fewer banner ads.
I’ve open-sourced the whole thing under a super-permissive license, so if you want your own WordPress blog to “feed” your Gemlog… now you can. With a few caveats:
It’s hard to use. While not as hacky as the disparate piles of code it replaced, it’s still not the cleanest. To modify it you’ll need a basic comprehension of all
three protocols, plus Ruby, SQL, and sysadmin skills.
It’s super opinionated. It’s very much geared towards my use case. It’s improved by the use of templates. but it’s still probably only suitable for this
site for the time being, until you make changes.
It’s very-much unfinished. I’ve got a growing to-do list, which should
be a good clue that it’s Not Finished. Maybe it never will but. But there’ll be changes yet to come.
Whether or not your WordPress blog makes the jump to Geminispace4, I hope you’ll came take a look at mine at one of the URLs linked above,
and then continue to explore.
If you’re nostalgic for the interpersonal Internet – or just the idea of it, if you’re too young to remember it… you’ll find it there. (That Internet never actually went away,
but it’s harder to find on today’s big Web than it is on lighter protocols.)
This post is also available as an article. So if you'd
rather read a conventional blog post of this content, you can!
This video accompanies a blog post of the same title. The content is mostly the same; the blog post contains a few extra elements (especially in
the footnotes!). Enjoy whichever one you choose.
Of all of the videogames I’ve ever played, perhaps the one that’s had the biggest impact on my life1
was: Werewolves and (the) Wanderer.2
This simple text-based adventure was originally written by Tim Hartnell for use in his 1983 book Creating Adventure Games on your Computer. At the time, it
was common for computing books and magazines to come with printed copies of program source code which you’d need to re-type on your own computer, printing being significantly many
orders of magnitude cheaper than computer media.3
Werewolves and Wanderer was adapted for the Amstrad CPC4 by Martin Fairbanks and published in The Amazing Amstrad Omnibus (1985),
which is where I first discovered it.
When I first came across the source code to Werewolves, I’d already begun my journey into computer programming. This started alongside my mother and later – when her
quantity of free time was not able to keep up with my level of enthusiasm – by myself.
I’d been working my way through the operating manual for our microcomputer, trying to understand it all.5
The ring-bound 445-page A4
doorstep of a book quickly became adorned with my pencilled-in notes, the way a microcomputer manual ought to be. It’s strange to recall that there was a time that
beginner programmers still needed to be reminded to press [ENTER] at the end of each line.
And even though I’d typed-in dozens of programs before, both larger and smaller, it was Werewolves that finally helped so many key concepts “click” for me.
In particular, I found myself comparing Werewolves to my first attempt at a text-based adventure. Using what little I’d grokked of programming so far, I’d put together
a series of passages (blocks of PRINT statements6)
with choices (INPUT statements) that sent the player elsewhere in the story (using, of course, the long-considered-harmfulGOTO statement), Choose-Your-Own-Adventure
style.
Werewolves was… better.
By the time I was the model of a teenage hacker, I’d been writing software for years. Most of it terrible.
Werewolves and Wanderer was my first lesson in how to structure a program.
Let’s take a look at a couple of segments of code that help illustrate what I mean (here’s the full code, if you’re interested):
10REM WEREWOLVES AND WANDERER
20GOSUB2600:REM INTIALISE30GOSUB16040IF RO<>11THEN30
50 PEN 1:SOUND 5,100:PRINT:PRINT"YOU'VE DONE IT!!!":GOSUB3520:SOUND 5,80:PRINT"THAT WAS THE EXIT FROM THE CASTLE!":SOUND 5,20060GOSUB352070PRINT:PRINT"YOU HAVE SUCCEEDED, ";N$;"!":SOUND 5,10080PRINT:PRINT"YOU MANAGED TO GET OUT OF THE CASTLE"90GOSUB3520100PRINT:PRINT"WELL DONE!"110GOSUB3520:SOUND 5,80120PRINT:PRINT"YOUR SCORE IS";
130PRINT3*TALLY+5*STRENGTH+2*WEALTH+FOOD+30*MK:FOR J=1TO10:SOUND 5,RND*100+10:NEXT J
140PRINT:PRINT:PRINT:END...2600REM INTIALISE2610 MODE 1:BORDER 1:INK 0,1:INK 1,24:INK 2,26:INK 3,18:PAPER 0:PEN 22620 RANDOMIZE TIME
2630 WEALTH=75:FOOD=02640 STRENGTH=1002650 TALLY=02660 MK=0:REM NO. OF MONSTERS KILLED...3510REM DELAY LOOP3520FOR T=1TO900:NEXT T
3530RETURN
Locomotive BASIC had mandatory line numbering. The spacing and gaps (...) have been added for readability/your convenience.
What’s interesting about the code above? Well…
The code for “what to do when you win the game” is very near the top. “Winning” is the default state. The rest of the adventure exists to obstruct that. In a
language with enforced line numbering and no screen editor7,
it makes sense to put fixed-length code at the top… saving space for the adventure to grow below.
Two subroutines are called (the GOSUB statements):
The first sets up the game state: initialising the screen (2610), the RNG (2620), and player
characteristics (2630 – 2660). This also makes it easy to call it again (e.g. if the player is given the option to “start over”). This subroutine
goes on to set up the adventure map (more on that later).
The second starts on line 160: this is the “main game” logic. After it runs, each time, line 40 checks IF RO<>11 THEN 30. This tests
whether the player’s location (RO) is room 11: if so, they’ve exited the castle and won the adventure. Otherwise, flow returns to line 30 and the “main
game” subroutine happens again. This broken-out loop improving the readability and maintainability of the code.8
A common subroutine is the “delay loop” (line 3520). It just counts to 900! On a known (slow) processor of fixed speed, this is a simpler way to put a delay in than
relying on a real-time clock.
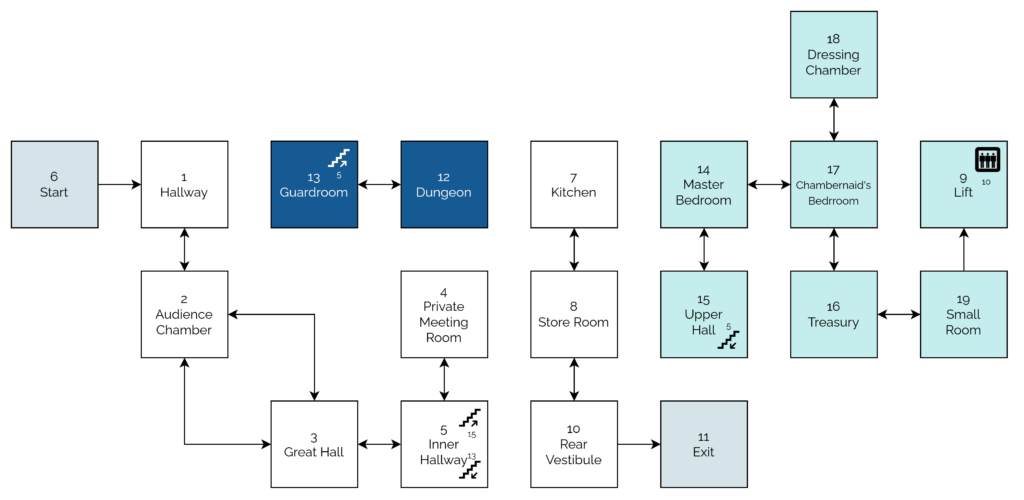
The game setup gets more interesting still when it comes to setting up the adventure map. Here’s how it looks:
Again, I’ve tweaked this code to improve readability, including adding indention on the loops, “modern-style”, and spacing to make the DATA statements form a “table”.
What’s this code doing?
Line 2690 defines an array (DIM) with two dimensions9
(19 by 7). This will store room data, an approach that allows code to be shared between all rooms: much cleaner than my first attempt at an adventure with each room
having its own INPUT handler.
The two-level loop on lines 2700 through 2730 populates the room data from the DATA blocks. Nowadays you’d probably put that data in a
separate file (probably JSON!). Each “row” represents a room, 1 to 19. Each “column” represents the room you end up
at if you travel in a given direction: North, South, East, West, Up, or Down. The seventh column – always zero – represents whether a monster (negative number) or treasure
(positive number) is found in that room. This column perhaps needn’t have been included: I imagine it’s a holdover from some previous version in which the locations of some or all of
the treasures or monsters were hard-coded.
The loop beginning on line 2850 selects seven rooms and adds a random amount of treasure to each. The loop beginning on line 2920 places each of six
monsters (numbered -1 through -6) in randomly-selected rooms. In both cases, the start and finish rooms, and any room with a treasure or monster, is
ineligible. When my 8-year-old self finally deciphered what was going on I was awestruck at this simple approach to making the game dynamic.
Rooms 4 and 16 always receive treasure (lines 2970 – 2980), replacing any treasure or monster already there: the Private Meeting Room (always
worth a diversion!) and the Treasury, respectively.
Curiously, room 9 (the lift) defines three exits, even though it’s impossible to take an action in this location: the player teleports to room 10 on arrival! Again, I assume this is
vestigal code from an earlier implementation.
The “checksum” that’s tested on line 2740 is cute, and a younger me appreciated deciphering it. I’m not convinced it’s necessary (it sums all of the values in
the DATA statements and expects 355 to limit tampering) though, or even useful: it certainly makes it harder to modify the rooms, which may undermine
the code’s value as a teaching aid!
By the time I was 10, I knew this map so well that I could draw it perfectly from memory. I almost managed the same today, aged 42. That memory’s buried deep!
Something you might notice is missing is the room descriptions. Arrays in this language are strictly typed: this array can only contain integers and not strings. But there are
other reasons: line length limitations would have required trimming some of the longer descriptions. Also, many rooms have dynamic content, usually based on random numbers, which would
be challenging to implement in this way.
As a child, I did once try to refactor the code so that an eighth column of data specified the line number to which control should pass to display the room description. That’s
a bit of a no-no from a “mixing data and logic” perspective, but a cool example of metaprogramming before I even knew it! This didn’t work, though: it turns out you can’t pass a
variable to a Locomotive BASIC GOTO or GOSUB. Boo!10
In hindsight, I could have tested the functionality before I refactored with a very simple program, but I was only around 10 or 11 and still had lots to learn!
Werewolves and Wanderer has many faults11.
But I’m clearly not the only developer whose early skills were honed and improved by this game, or who hold a special place in their heart for it. Just while writing this post, I
discovered:
Many, many people commenting on the above or elsewhere about how instrumental the game was in their programming journey, too.
A decade or so later, I’d be taking my first steps as a professional software engineer. A couple more decades later, I’m still doing it.
And perhaps that adventure -the one that’s occupied my entire adult life – was facilitated by this text-based one from the 1980s.
Footnotes
1 The game that had the biggest impact on my life, it might surprise you to hear, is
not among the “top ten videogames that stole
my life” that I wrote about almost exactly 16 years ago nor the follow-up list I published in its incomplete form three years
later. Turns out that time and impact are not interchangable. Who knew?
2 The game is variously known as Werewolves and Wanderer, Werewolves and
Wanderers, or Werewolves and the
Wanderer. Or, on any system I’ve been on, WERE.BAS, WEREWOLF.BAS, or WEREWOLV.BAS, thanks to the CPC’s eight-point-three filename limit.
3 Additionally, it was thought that having to undertake the (painstakingly tiresome)
process of manually re-entering the source code for a program might help teach you a little about the code and how it worked, although this depended very much on how readable the code
and its comments were. Tragically, the more comprehensible some code is, the more long-winded the re-entry process.
5 One of my favourite
features of home microcomputers was that seconds after you turned them on, you could start programming. Your prompt was an interface to a programming language. That magic
had begun to fade by the time DOS came to dominate (sure, you can program using batch files, but they’re
neither as elegant nor sophisticated as any BASIC dialect) and was completely lost by the era of booting directly into graphical operating systems. One of my favourite
features about the Web is that it gives you some of that magic back again: thanks to the debugger in a modern browser, you can “tinker” with other people’s code once more, right from
the same tool you load up every time. (Unfortunately, mobile devices – which have fast become the dominant way for people to use the Internet – have reversed this trend again. Try to
View Source on your mobile – if you don’t already know how, it’s not an easy job!)
6 In particular, one frustration I remember from my first text-based adventure was that
I’d been unable to work around Locomotive BASIC’s lack of string escape sequences – not that I yet knew what such a thing would be called – in order to put quote marks inside a quoted
string!
7 “Screen editors” is what we initially called what you’d nowadays call a “text editor”:
an application that lets you see a page of text at the same time, move your cursor about the place, and insert text wherever you feel like. It may also provide features like
copy/paste and optional overtyping. Screen editors require more resources (and aren’t suitable for use on a teleprinter) compared to line editors, which preceeded them. Line editors only let you view and edit a single line at a time, which is how most of my first 6
years of programming was done.
8 In a modern programming language, you might use while true or similar for a
main game loop, but this requires pushing the “outside” position to the stack… and early BASIC dialects often had strict (and small, by modern standards) limits on stack height that
would have made this a risk compared to simply calling a subroutine from one line and then jumping back to that line on the next.
9 A neat feature of Locomotive BASIC over many contemporary and older BASIC dialects was
its support for multidimensional arrays. A common feature in modern programming languages, this language feature used to be pretty rare, and programmers had to do bits of division and
modulus arithmetic to work around the limitation… which, I can promise you, becomes painful the first time you have to deal with an array of three or more dimensions!
10 In reality, this was rather unnecessary, because the ON x GOSUB command
can – and does, in this program – accept multiple jump points and selects the one referenced by the
variable x.
11 Aside from those mentioned already, other clear faults include: impenetrable
controls unless you’ve been given instuctions (although that was the way at the time); the shopkeeper will penalise you for trying to spend money you don’t have, except on food,
presumably as a result of programmer laziness; you can lose your flaming torch, but you can’t buy spares in advance (you can pay for more, and you lose the money, but you don’t get a
spare); some of the line spacing is sometimes a little wonky; combat’s a bit of a drag; lack of feedback to acknowledge the command you enterted and that it was successful; WHAT’S
WITH ALL THE CAPITALS; some rooms don’t adequately describe their exits; the map is a bit linear; etc.
A year and a half ago I came up with a technique for intercepting the “shuffle” operation
on jigsaw website Jigidi, allowing players to force the pieces to appear in a consecutive “stack” for ludicrously easy solving. I did this
partially because I was annoyed that a collection of geocaches near me used Jigidi puzzles as a barrier to their coordinates1…
but also because I enjoy hacking my way around artificially-imposed constraints on the Web (see, for example, my efforts last week to circumvent region-blocking on radio.garden).
My solver didn’t work for long: code changes at Jigidi’s end first made it harder, then made it impossible, to use the approach I suggested. That’s fine by me – I’d already got what I
wanted – but the comments thread on that post suggests that there’s
a lot of people who wish it still worked!2
And so I ignored the pleas of people who wanted me to re-develop a “Jigidi solver”. Until recently, when I once again needed to solve a jigsaw puzzle in order to find a geocache’s
coordinates.
Making A Jigidi Helper
Rather than interfere with the code provided by Jigidi, I decided to take a more-abstract approach: swapping out the jigsaw’s image for one that would be easier.
This approach benefits from (a) having multiple mechanisms of application: query interception, DNS hijacking, etc., meaning that if one stops working then another one can be easily
rolled-out, and (b) not relying so-heavily on the structure of Jigidi’s code (and therefore not being likely to “break” as a result of future upgrades to Jigidi’s platform).
It’s not as powerful as my previous technique – more a “helper” than a “solver” – but it’s good enough to shave at least half the time off that I’d otherwise spend solving a Jigidi
jigsaw, which means I get to spend more time out in the rain looking for lost tupperware. (If only geocaching were even the weirdest of my hobbies…)
How To Use The Jigidi Helper
To do this yourself and simplify your efforts to solve those annoying “all one colour” or otherwise super-frustrating jigsaw puzzles, here’s what you do:
Visit a Jigidi jigsaw. Do not be logged-in to a Jigidi account.
Open your browser’s debug tools (usually F12). In the Console tab, paste it and press enter. You can close your debug tools again (F12) if you like.
Press Jigidi’s “restart” button, next to the timer. The jigsaw will restart, but the picture will be replaced with one that’s easier-to-solve than most, as described below.
Once you solve the jigsaw, the image will revert to normal (turn your screen around and show off your success to a friend!).
What makes it easier to solve?
The replacement image has the following characteristics that make it easier to solve than it might otherwise be:
Every piece has written on it the row and column it belongs in.
Every “column” is striped in a different colour.
Striped “bands” run along entire rows and columns.
To solve the jigsaw, start by grouping colours together, then start combining those that belong in the same column (based on the second digit on the piece). Join whole or partial
columns together as you go.
I’ve been using this technique or related ones for over six months now and no code changes on Jigidi’s side have impacted upon it at all, so it’s probably got better longevity than the
previous approach. I’m not entirely happy with it, and you might not be either, so feel free to fork my code and improve it: the legiblity of the numbers is sometimes suboptimal, and
the colour banding repeats on larger jigsaws which I’d rather avoid. There’s probably also potential to improve colour-recognition by making the colour bands span the gaps
between rows or columns of pieces, too, but more experiments are needed and, frankly, I’m not the right person for the job. For the second time, I’m going to abandon a tool
that streamlines Jigidi solving because I’ve already gotten what I needed out of it, and I’ll leave it up to you if you want to come up with an improvement and share it with the
community.
Footnotes
1 As I’ve mentioned before, and still nobody believes me: I’m not a fan of jigsaws! If you
enjoy them, that’s great: grab a bucket of popcorn and a jigsaw and go wild… but don’t feel compelled to share either with me.
2 The comments also include asuper-helpful person called Rich who’s been manually
solving people’s puzzles for them, and somebody called Perdita
who “could be my grandmother” (except: no) with whom I enjoyed a
conversation on- and off-line about the ethics of my technique. It’s one of the most-popular comment threads my blog has ever seen.
Just in time for Robin Sloan to give up on Spring ’83, earlier this month I finally got aroud to launching STS-6 (named for the first mission of the Space Shuttle Challenger in Spring 1983), my experimental Spring ’83 server. It’s
been a busy year; I had other things to do. But you might have guessed that something like this had been under my belt when I open-sourced a keygenerator for the protocol the other day.
If you’ve not played with Spring ’83, this post isn’t going to make much sense to you. Sorry.
My server is, as far as I can tell, very different from any others in a few key ways:
It does not allow third-party publishing at all. Some might argue that this undermines the aim of the exercise, but I disagree. My IndieWeb inclinations lead me to
favour “self-hosted” content, shared from its owners’ domain. Also: the specification clearly states that a server must implement a denylist… I guess my denylist simply includes all keys that are
not specifically permitted.
It’s geared towards dynamic content.My primary board self-publishes whenever I produce a new blog post, listing the most recent blog posts published. I have
another half-implemented which shows a summary of the most-recent post, and another which would would simply use a WordPress page as its basis – yes, this was content
management, but published over Spring ’83.
It provides helpers to streamline content production. It supports internal references to other boards you control using the format {{board:123}}which are
automatically converted to addresses referencing the public key of the “current” keypair for that board. This separates the concept of a board and its content template from that
board’s keypairs, making it easier to link to a board. To put it another way, STS-6 links are self-healing on the server-side (for local boards).
It helps automate content-fitting. Spring ’83 strictly requires a maximum board size of 2,217 bytes. STS-6 can be configured to fit a flexible amount of dynamic
content within a template area while respecting that limit. For my posts list board, the number of posts shown is moderated by the size of the resulting board: STS-6 adds more and
more links to the board until it’s too big, and then removes one!
It provides “hands-off” key management features. You can pregenerate a list of keys with different validity periods and the server will automatically cycle through
them as necessary, implementing and retroactively-modifying <link rel="next"> connections to keep them current.
I’m sure that there are those who would see this as automating something that was beautiful because it was handcrafted; I don’t know whether or not I agree, but had Spring ’83
taken off in a bigger way, it would always only have been a matter of time before somebody tried my approach.
From a design perspective, I enjoyed optimising an SVG image of my header so it could meaningfully fit into the board. It’s
pretty, and it’s tolerably lightweight.
If you want to see my server in action, patch this into your favourite Spring ’83 client:
https://s83.danq.dev/10c3ff2e8336307b0ac7673b34737b242b80e8aa63ce4ccba182469ea83e0623
A dead end?
Without Robin’s active participation, I feel that Spring ’83 is probably coming to a dead end. It’s been a lot of fun to play with and I’d love to see what ideas the experience of it
goes on to inspire next, but in its current form it’s one of those things that’s an interesting toy, but not something that’ll make serious waves.
In his last lab essay Robin already identified many of the key issues with the system (too complicated, no interpersonal-mentions, the challenge of keys-as-identifiers, etc.) and while
they’re all solvable without breaking the underlying mechanisms (mentions might be handled by Webmention, perhaps, etc.), I
understand the urge to take what was learned from this experiment and use it to help inform the decisions of the next one. Just as John Postel’s Quote of the Day protocol doesn’t see much use any more (although maybe if my
finger server could support QotD?) but went on to inspire the direction of many subsequent “call-and-response” protocols,
including HTTP, it’s okay if Spring ’83 disappears into obscurity, so long as we can learn what it did
well and build upon that.
Meanwhile: if you’re looking for a hot new “like the web but lighter” protocol, you should probably check out Gemini. (Incidentally, you
can find me at gemini://danq.me, but that’s something I’ll write about another day…)














![Scan of a ring-bound page from a technical manual. The page describes the use of the "INPUT" command, saying "This command is used to let the computer know that it is expecting something to be typed in, for example, the answer to a question". The page goes on to provide a code example of a program which requests the user's age and then says "you look younger than [age] years old.", substituting in their age. The page then explains how it was the use of a variable that allowed this transaction to occur.](https://bcdn.danq.me/_q23u/2023/07/cpc664-manual-input-command.png)