It’s the year 2101. Corporations have taken over the world. The only way to be free is to join a pirate crew and start plundering the galaxy. The only means of survival is to play
basketball.
Now it’s your turn to go out there and make a name for yourself. Create your crew and start wandering the galaxy in search of worthy basketball opponents.
The game is under heavy development and breaking changes are often introduced. If you can’t continue an old game because the save file is invalid, you probably need to start a new
one or open an issue to check if the save file can be migrated.
…
Just try it out!
Connect via SSH to try the game.
ssh rebels.frittura.org -p 3788
Save files are deleted after 2 days of inactivity.
…
I feel like I’m reading a lot about SSH lately and how it can be used for exotic and unusual tasks. Tarpitting‘s fun, of course, but really what inspires me is all these dinky projects like ssh tiny.christmas that subvert the usual authentication-then-terminal flow that you expect when you connect to an SSH server.
These kinds of projects feel more like connecting to a BBS. And that’s pretty retro (and cool!).
Anyway: Rebels in the Sky is a networked multiplayer terminal-based game about exploring the galaxy with a team of basketball-loving space pirates. I met the main
developer on a forum and they seem cool; I’m interested to see where this quirky little project ends up going!
The fundamental difference between streaming and downloading is what your device does with those frames of video:
Does it show them to you once and then throw them away? Or does it re-assemble them all back into a video file and save it into storage?
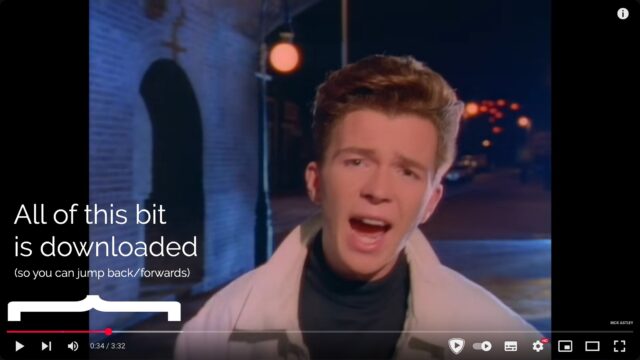
When you’re streaming on YouTube, the video player running on your computer retains a buffer of frames ahead and behind of your current position, so you can skip around easily: the
darker grey part of the timeline shows which parts of the video are stored on – that is, downloaded to – your computer.
Buffering is when your streaming player gets some number of frames “ahead” of where you’re watching, to give you some protection against connection issues. If your WiFi wobbles
for a moment, the buffer protects you from the video stopping completely for a few seconds.
But for buffering to work, your computer has to retain bits of the video. So in a very real sense, all streaming is downloading! The buffer is the part
of the stream that’s downloaded onto your computer right now. The question is: what happens to it next?
All streaming is downloading
So that’s the bottom line: if your computer deletes the frames of video it was storing in the buffer, we call that streaming. If it retains them in a file, we
call that downloading.
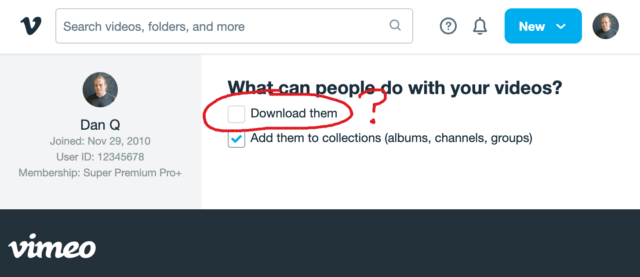
That definition introduces a philosophical problem. Remember that Vimeo checkbox that lets a creator decide whether people can (i.e. are allowed to) download their videos? Isn’t
that somewhat meaningless if all streaming is downloading.
Because if the difference between streaming and downloading is whether their device belonging to the person watching the video deletes the media when they’re done. And in
virtually all cases, that’s done on the honour system.
This kind of conversation happens, over the HTTP protocol, all the time. Probably most of the time the browser is telling the truth, but there’s no way to know for certain.
When your favourite streaming platform says that it’s only possible to stream, and not download, their media… or when they restrict “downloading” as an option to higher-cost paid plans…
they’re relying on the assumption that the user’s device can be trusted to delete the media when the user’s done watching it.
But a user who owns their own device, their own network, their own screen or speakers has many, many opportunities to not fulfil the promise of deleting media it after they’ve consumed
it: to retain a “downloaded” copy for their own enjoyment, including:
Intercepting the media as it passes through their network on the way to its destination device
Using client software that’s been configured to stream-and-save, rather than steam-and-delete, the content
Modifying “secure” software (e.g. an official app) so that it retains a saved copy rather than deleting it
Capturing the stream buffer as it’s cached in device memory or on the device’s hard disk
Outputting the resulting media to a different device, e.g. using a HDMI capture device, and saving it there
Exploiting the “analogue4
hole”5:
using a camera, microphone, etc. to make a copy of what comes out of the screen/speakers6
Okay, so I oversimplified (before you say “well, actually…”)
It’s not entirely true to say that streaming and downloading are identical, even with the caveat of “…from the server’s perspective”. There are three big exceptions worth
thinking about:
Exception #1: downloads can come in any order
When you stream some linear media, you expect the server to send the media in strict chronological order. Being able to start watching before the whole file has
downloaded is a big part of what makes steaming appealing, to the end-user. This means that media intended for streaming tends to be stored in a way that facilitates that
kind of delivery. For example:
Media designed for streaming will often be stored in linear chronological order in the file, which impacts what kinds of compression are available.
Media designed for streaming will generally use formats that put file metadata at the start of the file, so that it gets delivered first.
Video designed for streaming will often have frequent keyframes so that a client that starts “in the middle” can decode the buffer without downloading too much data.
No such limitation exists for files intended for downloading. If you’re not planning on watching a video until it’s completely downloaded, the order in which the chunks arrives is
arbitrary!
But these limitations make the set of “files suitable for streaming” a subset of the set of “files suitable for downloading”. It only makes it challenging or impossible to
stream some media intended for downloading… it doesn’t do anything to prevent downloading of media intended for streaming.
Exception #2: streamed media is more-likely to be transcoded
A server that’s streaming media to a client exists in a sort-of dance: the client keeps the server updated on which “part” of the media it cares about, so the server can jump ahead,
throttle back, pause sending, etc. and the client’s buffer can be kept filled to the optimal level.
This dance also allows for a dynamic change in quality levels. You’ve probably seen this happen: you’re watching a video on YouTube and suddenly the quality “jumps” to something more
(or less) like a pile of LEGO bricks7. That’s the result of your device realising that the rate
at which it’s receiving data isn’t well-matched to the connection speed, and asking the server to send a different quality level8.
The server can – and some do! – pre-generate and store all of the different formats, but some servers will convert files (and particularly livestreams) on-the-fly, introducing
a few seconds’ delay in order to deliver the format that’s best-suited to the recipient9. That’s not necessary for downloads, where the
user will often want the highest-quality version of the media (and if they don’t, they’ll select the quality they want at the outset, before the download begins).
Exception #3: streamed media is more-likely to be encumbered with DRM
And then, of course, there’s DRM.
As streaming digital media has become the default way for many people to consume video and audio content, rights holders have engaged in a fundamentally-doomed10
arms race of implementing copy-protection strategies to attempt to prevent end-users from retaining usable downloaded copies of streamed media.
Take HDCP, for example, which e.g. Netflix use for their 4K streams. To download these streams, your device has to be running some decryption code that only works if it can trace a path
to the screen that it’ll be outputting to that also supports HDCP, and both your device and that screen promise that they’re definitely only going to show it and not make it
possible to save the video. And then that promise is enforced by Digital Content Protection LLC only granting a decryption key and a license to use it to manufacturers.11
The real hackers do stuff with software, but people who just want their screens to work properly in spite of HDCP can just buy boxes like this (which I bought for a couple of quid on
eBay). Obviously you could use something like this and a capture card to allow you to download content that was “protected” to ensure that you could only stream it, I suppose, too.
Anyway, the bottom line is that all streaming is, by definition, downloading, and the only significant difference between what people call “streaming” and
“downloading” is that when “streaming” there’s an expectation that the recipient will delete, and not retain, a copy of the video. And that’s it.
Footnotes
1 This isn’t the question I expected to be answering. I made the animation in this post
for use in a different article, but that one hasn’t come together yet, so I thought I’d write about the technical difference between streaming and downloading as an excuse to
use it already, while it still feels fresh.
2 I’m using the example of a video, but this same principle applies to any linear media
that you might stream: that could be a video on Netflix, a livestream on Twitch, a meeting in Zoom, a song in Spotify, or a radio show in iPlayer, for example: these are all examples
of media streaming… and – as I argue – they’re therefore also all examples of media downloading because streaming and downloading are fundamentally the same thing.
3 There are a few simplifications in the first half of this post: I’ll tackle them later
on. For the time being, when I say sweeping words like “every”, just imagine there’s a little footnote that says, “well, actually…”, which will save you from feeling like you have to
say so in the comments.
4 Per my style guide, I’m using the British English
spelling of “analogue”, rather than the American English “analog” which you’ll often find elsewhere on the Web when talking about the analog hole.
5 The rich history of exploiting the analogue hole spans everything from bootlegging a
1970s Led Zeppelin concert by smuggling recording equipment
in inside a wheelchair (definitely, y’know, to help topple the USSR and not just to listen to at home while you get high)
to “camming” by bribing your friendly local projectionist to let you set up a video camera at the back of the cinema for their test screening of the new blockbuster. Until some
corporation tricks us into installing memory-erasing DRM chips into our brains (hey, there’s a dystopic sci-fi story idea in there somewhere!) the analogue hole will always be
exploitable.
6 One might argue that recreating a piece of art from memory, after the fact, is a
very-specific and unusual exploitation of the analogue hole: the one that allows us to remember (or “download”) information to our brains rather than letting it “stream” right
through. There’s evidence to suggest that people pirated Shakespeare’s plays this way!
7 Of course, if you’re watching The LEGO Movie, what you’re seeing might already
look like a pile of LEGO bricks.
8 There are other ways in which the client and server may negotiate, too: for example,
what encoding formats are supported by your device.
9My NAS does live transcoding when Jellyfin streams to devices on my network, and it’s magical!
10 There’s always the analogue hole, remember! Although in practice this isn’t even
remotely necessary and most video media gets ripped some-other-way by clever pirate types even where it uses highly-sophisticated DRM strategies, and then ultimately it’s only
legitimate users who end up suffering as a result of DRM’s burden. It’s almost as if it’s just, y’know, simply a bad idea in the first place, or something. Who knew?
11 Like all these technologies, HDCP was cracked almost immediately and every
subsequent version that’s seen widespread rollout has similarly been broken by clever hacker types. Legitimate, paying users find themselves disadvantaged when their laptop won’t let
them use their external monitor to watch a movie, while the bad guys make pirated copies that work fine on anything. I don’t think anybody wins, here.
I use a tool called Sonarr to, uhh1, keep track of when new episodes of television
shows are released, regardless of what platform they’re on (Netflix, Prime, iPlayer, whatever) and notify me so I remember to watch it.
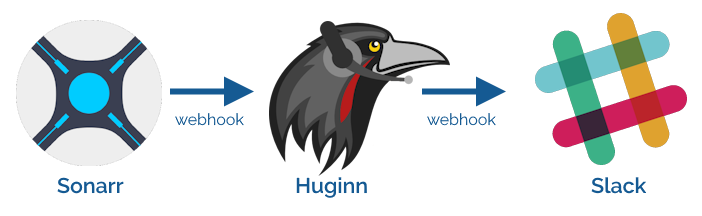
For several years, I’ve used IFTTT as the intermediary, receiving webhooks from Sonarr and
translating them for Slack:
This worked for years, but it’s time to retire it.
IFTTT‘s move to kill its Legacy Pro plan2 – which
I was on – gave me reason to re-assess this configuration. It turns that the only Pro feature I was using was an IFTTT “filter” to
convert the Sonarr webhooks to a Slack-friendly-format.
Given that I’m running an installation of Huginn on my home network anyway, I resolved to re-implement this flow in Huginn and
cancel my IFTTT subscription.
Raven-powered automation is the new hotness.
This turned out to be so easy I wonder why I never did it before.
First, I created a Webhook Agent and gave the URL to Sonarr.
Then I connected that to a Slack Agent with the following configuration:
I’ve omitted my Slack webhook URL so you don’t spam me. I tried for far too long to get the pluralize filter to
work so it’d say “episode” or “episodes” as appropriate before realising I didn’t care enough and gave up.
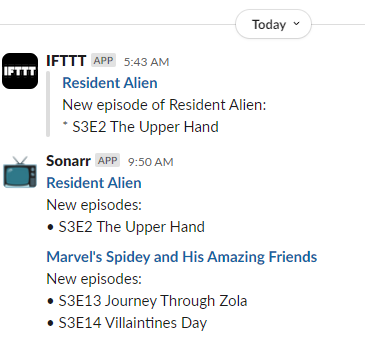
Then all I needed to do was re-emit some of the previous webhooks to test it:
As a bonus, I swapped out the IFTTT logo for Slackmoji’s :tv: icon and added the “Sonarr” username, as shown in my code sample.
Now I’ll continue to know when there’s new television to watch3!
I love the power and flexibility that Huginn provides to help automate your life. It does many of the things that I used to do with a handful of cron jobs and shell scripts, but all in
one convenient place.
Footnotes
1 I’ve heard there are other uses for the tool. Your mileage may vary. Don’t forget to pay
for your content, if possible.
3 It’s especially useful when you’re between seasons or a show is on hiatus to be reminded
that it’s back and I should go and watch it. Hey, there’s a thought: I wonder if I can extract the subtitles from shows and run them through a summarising LLM to give me a couple of paragraphs reminding me “what happened last series” if the show’s been on a long break?
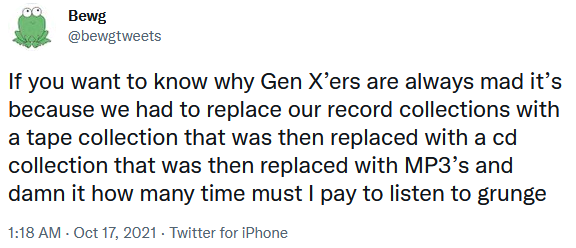
I didn’t/don’t own much vinyl – perhaps mostly because I had a tape deck in my bedroom years before a record player – but I’ve felt this pain. And don’t get me started on the videogames I’ve paid for multiple times.
In the Summer of 1995 I bought the CD single of the (still excellent!) Set You
Free by N-Trance.2
I’d heard about this new-fangled “MP3” audio format, so soon afterwards I decided to rip a copy of the song to my PC.
I was using a 66MHz 486SX CPU, and without an embedded FPU I didn’t
quite have the spare processing power to rip-and-encode in a single pass.3
So instead I first ripped to an uncompressed PCM .wav file and then performed the encoding: the former step
was done almost in real-time (I listened to the track as it ripped!), about 7 minutes. The latter step took about 20 minutes.
So… about half an hour in total, to rip a single song.
Progress bar, you say? I’ll just sit here and wait then, I guess. Actual contemporary-ish photo.
Creating a (what would now be considered an apalling) 32kHz mono-channel file, this meant that I briefly stored both a 27MB wave file and the final ~4MB MP3 file. 31MB
might not sound huge, but I only had a total of 145MB of hard drive space at the time, so 31MB consumed over a fifth of my entire fixed storage! Even after deleting the intermediary wave file I was left with a single song consuming around 3% of my space,
which is mind-boggling to think about in hindsight.
But it felt like magic. I called my friend Gary to tell him about it. “This is going to be massive!” I said. At the time, I meant for techy
people: I could imagine a future in which, with more hard drive space, I’d keep all my music this way… or else bundle entire artists onto writable CDs in this new format, making albums obsolete. I never considered that over the coming decade or so the format would enter the public consciousness, let
alone that it’d take off like it did.
If you’re thinking of Gary and I as the kind of reprobates who helped bring on the golden age of music piracy… I’d like to distract you with a bigger show of yobbish behaviour in the
form of this photo from the day we played at dropping half-bricks onto starter pistol ammunition.
The MP3 file I produced had a fault. Most of the way through the encoding process, I got bored and ran another program, and this
must’ve interfered with the stream because there was an audible “blip” noise about 30 seconds from the end of the track. You’d have to be listening carefully to hear it, or else know
what you were looking for, but it was there. I didn’t want to go through the whole process again, so I left it.
But that artefact uniquely identified that copy of what was, in the end, a popular song to have in your digital music collection. As the years went by and I traded MP3 files in bulk at LAN parties or on CD-Rs or, on at least one ocassion, on an Iomega Zip disk (remember those?), I’d ocassionally see
N-Trance - (Only Love Can) Set You Free.mp34 being passed around and play it, to see if it was “my”
copy.
Sometimes the ID3 tags had been changed because for example the previous owner had decided it deserved to be considered Genre: Dance instead of Genre: Trance5. But I could still identify that file because
of the audio fingerprint, distinct to the first MP3 I ever created.
I still had that file when I went to university (where it occupied a smaller proportion of my hard drive space) and hearing that
distinctive “blip” would remind me about the ordeal that was involved in its creation. I don’t have it any more, but perhaps somebody else still does.
Footnotes
1 I might never have told this story on my blog, but eagle-eyed readers may remember that
I’ve certainly hinted at it before now.
2 Rewatching that music video, I’m struck by a recollection of how crazy popular
crossfades were on 1990s dance music videos. More than just a transition, I’m pretty sure that most of the frames of that video are mid-crossfade: it feels like I’m watching
Kelly Llorenna hanging out of a sunroof but I accidentally left one of my eyeballs in a smoky nightclub and can still see out of it as well.
3 I initially tried to convert directly from red book format to an MP3 file, but the encoding process was
too slow and the CD drive’s buffer filled up and didn’t get drained by the processor, which was still presumably bogged down with
framing or fourier-transforming earlier parts of the track. The CD drive reasonably assumed that it wasn’t actually being used and
spun-down the drive motor, and this caused it to lose its place in the track, killing the whole process and leaving me with about a 40 second recording.
4 Yes, that filename isn’t quite the correct title. I was wrong.
[this post was lost during a server failure on Sunday 11th July 2004; it was partially recovered on 21st March 2012]
If you haven’t already read it, take a look at The Right To Read, a very short story written in 1997 and updated in 2002 –
it’ll only take you a few minutes to read; it’s not ‘techie’ (anybody would understand it!), and it is relevant. The kind of things that are expressed in the story – while
futuristic (and facist) sounding now, are being put into effect… slowly, quietly… by companies such as Sony, Phillips, Apple, and Microsoft: not to mention the manufactors of CDs and
DVDs.
It’s been circulating the ‘net for years, but recent events such as InterTrust’s Universal Digital Rights Management
System(report: The Register), which they claim will be ready within 6 months, and Microsoft’s ongoing work on the
‘Palladium’ project(report: BBC News) – topical events which mark the beginning of what could be the most important thing ever to happen in the history of copyright law,
computing, and freedom of information.
So, go on – go read… [the remainder of this post, and three comments, have been lost]
Cool And Interesting Thing Of The Day To Do At The University Of Wales, Aberystwyth, #12:
Download the entirety of that fantastic film, The Matrix, on to your hard drive, and watch it, wondering why your PC is running so slow until you realise that the film is occupying
1.4GB of the remaining 1.5GB of your capacity. Whoops.
The ‘cool and interesting things’ were originally published to a location at which my “friends back home” could read them, during the first few months of my time at the University
of Wales, Aberystwyth, which I started in September 1999. It proved to be particularly popular, and so now it is immortalised through the medium of my weblog.