I just needed to spin up a new PHP webserver and I was amazed how fast and easy it was, nowadays. I mean: Caddyalready makes it
pretty easy, but I was delighted to see that, since the last time I did this, the default package repositories had 100% of what I needed!
Apart from setting the hostname, creating myself a user and adding them to the sudo group, and reconfiguring sshd to my preference, I’d
done nothing on this new server. And then to set up a fully-functioning PHP-powered webserver, all I needed to run (for a domain “example.com”) was:
After that, I was able to put an index.php file into /var/www/example.com and it just worked.
And when I say “just worked”, I mean with all the bells and whistles you ought to expect from Caddy. HTTPS came as standard (with a solid QualSys grade). HTTP/3 was supported with a
0-RTT handshake.
I was updating my CV earlier this week in anticipation of applying for a handful of interesting-looking roles1
and I was considering quite how many different tech stacks I claim significant experience in, nowadays.
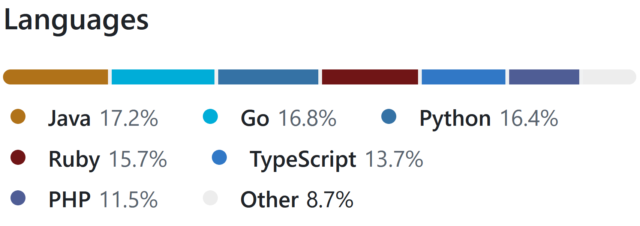
There are languages I’ve been writing in every single week for the last 15+ years, of course, like PHP, Ruby, and JavaScript. And my underlying fundamentals are solid.
But is it really fair for me to be able to claim that I can code in Java, Go, or Python: languages that I’ve not used commercially within the last 5-10 years?
What kind of developer writes the same program six times… for a tech test they haven’t even been asked to do? If you guessed “Dan”, you’d be correct!
Obviously, I couldn’t just let that question lie2.
Let’s find out!
I fished around on Glassdoor for a bit to find a medium-sized single-sitting tech test, and found a couple of different briefs that I mashed together to create this:
In an object-oriented manner, implement an LRU (Least-Recently Used) cache:
The size of the cache is specified at instantiation.
Arbitrary objects can be put into the cache, along with a retrieval key in the form of a string. Using the same string, you can get the objects back.
If a put operation would increase the number of objects in the cache beyond the size limit, the cached object that was least-recently accessed (by either a
put or get operation) is removed to make room for it.
putting a duplicate key into the cache should update the associated object (and make this item most-recently accessed).
Both the get and put operations should resolve within constant (O(1)) time.
Add automated tests to support the functionality.
My plan was to implement a solution to this challenge, in as many of the languages mentioned on my CV as possible in a single sitting.
But first, a little Data Structures & Algorithms theory:
The Theory
Simple case with O(n) complexity
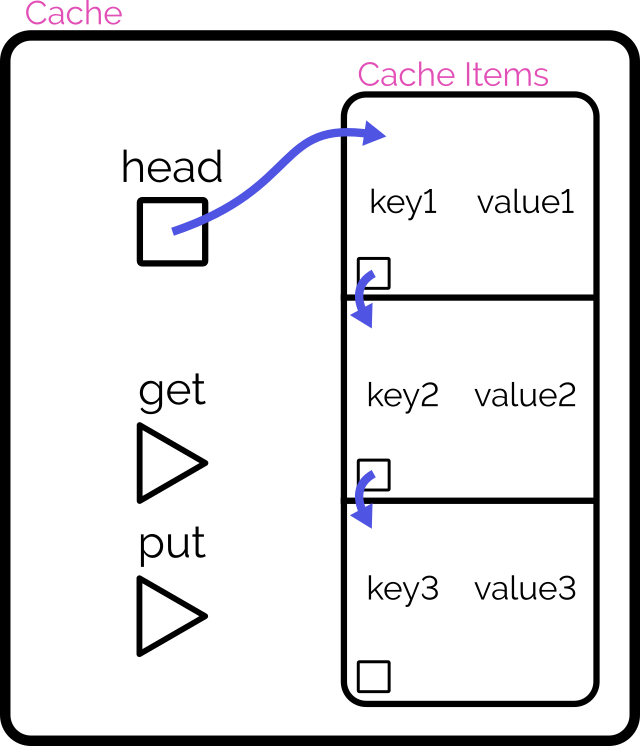
The simplest way to implement such a cache might be as follows:
Use a linear data structure like an array or linked list to store cached items.
On get, iterate through the list to try to find the matching item.
If found: move it to the head of the list, then return it.
On put, first check if it already exists in the list as with get:
If it already exists, update it and move it to the head of the list.
Otherwise, insert it as a new item at the head of the list.
If this would increase the size of the list beyond the permitted limit, pop and discard the item at the tail of the list.
It’s simple, elegant and totally the kind of thing I’d accept if I were recruiting for a junior or graduate developer. But we can do better.
The problem with this approach is that it fails the requirement that the methods “should resolve within constant (O(1)) time”3.
Of particular concern is the fact that any operation which might need to re-sort the list to put the just-accessed item at the top
4. Let’s try another design:
Achieving O(1) time complexity
Here’s another way to implement the cache:
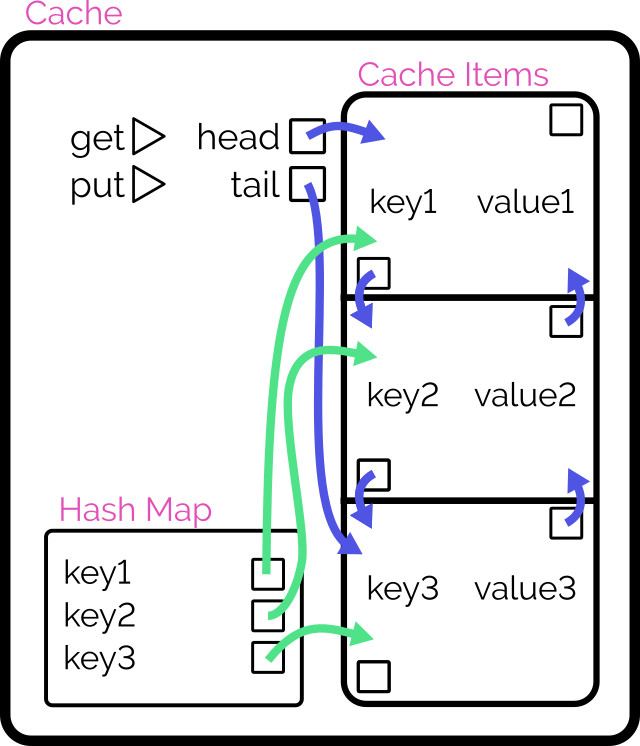
Retain cache items in a doubly-linked list, with a pointer to both the head and tail
Add a hash map (or similar language-specific structure) for fast lookups by cache key
On get, check the hash map to see if the item exists.
If so, return it and promote it to the head (as described below).
On put, check the hash map to see if the item exists.
If so, promote it to the head (as described below).
If not, insert it at the head by:
Updating the prev of the current head item and then pointing the head to the new item (which will have the old head item as its
next), and
Adding it to the hash map.
If the number of items in the hash map would exceed the limit, remove the tail item from the hash map, point the tail at the tail item’s prev, and
unlink the expired tail item from the new tail item’s next.
To promote an item to the head of the list:
Follow the item’s prev and next to find its siblings and link them to one another (removes the item from the list).
Point the promoted item’s next to the current head, and the current head‘s prev to the promoted item.
Point the head of the list at the promoted item.
Looking at a plate of pointer-spaghetti makes me strangely hungry.
It’s important to realise that this alternative implementation isn’t better. It’s just different: the “right” solution depends on the use-case5.
The Implementation
That’s enough analysis and design. Time to write some code.
Turns out that if you use enough different languages in your project, GitHub begins to look like itwants to draw a rainbow.
Picking a handful of the more-useful languages on my CV6,
I opted to implement in:
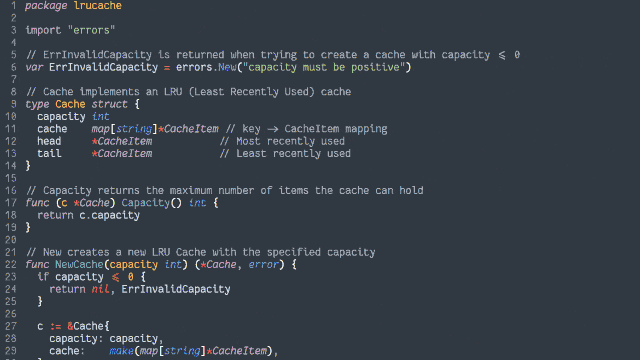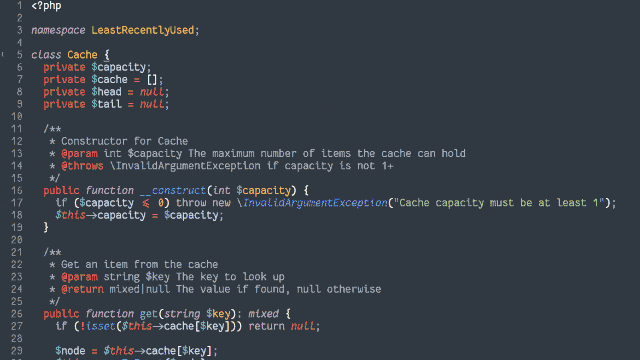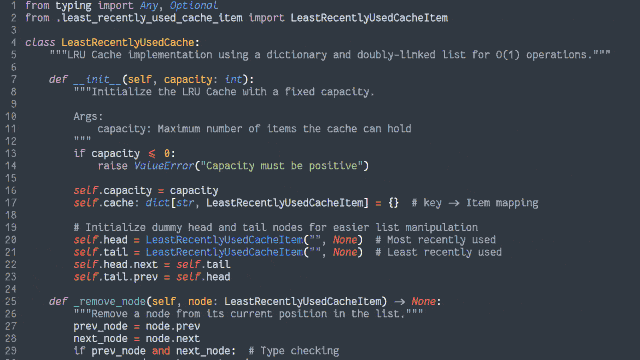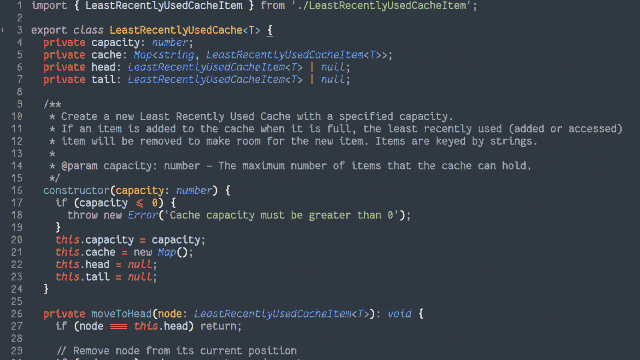
Ruby (with RSpec for testing and Rubocop for linting)
PHP (with PHPUnit for testing)
TypeScript (running on Node, with Jest for testing)
Java (with JUnit for testing)
Go (which isn’t really an object-oriented language but acts a bit like one, amirite?)
Python (probably my weakest language in this set, but which actually ended up with quite a tidy solution)
Naturally, I open-sourced everything if you’d like to see for yourself. It all works, although if you’re actually in need of such a
cache for your project you’ll probably find an alternative that’s at least as good (and more-likely to be maintained!) in a third-party library somewhere!
What did I learn?
This was actually pretty fun! I might continue to expand my repo by doing the same challenge with a few of the other languages I’ve used professionally at some point or
another7.
And there’s a few takeaways I got from this experience –
Lesson #1: programming more languages can make you better at all of them
As I went along, one language at a time, I ended up realising improvements that I could make to earlier iterations.
For example, when I came to the TypeScript implementation, I decided to use generics so that the developer can specify what kind of objects they want to store in the cache,
rather than just a generic Object, and better benefit type-safety. That’s when I remembered that Java supports generics, too, so I went back and used them there as well.
In the same way as speaking multiple (human) languages or studying linguistics can help unlock new ways of thinking about your communication, being able to think in terms of multiple
different programming languages helps you spot new opportunities. When in 2020 PHP 8 added nullsafe operators, union types, and
named arguments, I remember feeling confident using them from day one because those features were already familiar to me from Ruby8, TypeScript9, and Python10,
respectively.
Lesson #2: even when I’m rusty, I can rely on my fundamentals
I’ve applied for a handful of jobs now, but if one of them had invited me to a pairing session on a language I’m rusty on (like Java!) I might’ve felt intimidated.
But it turns out I shouldn’t need to be! With my solid fundamentals and a handful of other languages under my belt, I understand when I need to step away from the code editor and hit
the API documentation. Turns out, I’m in a good position to demo any of my language skills.
I remember when I was first learning Go, I wanted to make use of a particular language feature that I didn’t know whether it had. But because I’d used that feature in Ruby, I knew what
to search for in Go’s documentation to see if it was supported (it wasn’t) and if so, what the syntax was11.
Lesson #3: structural rules are harder to gearshift than syntactic ones
Switching between six different languages while writing the same application was occasionally challenging, but not in the ways I expected.
I’ve had plenty of experience switching programming languages mid-train-of-thought before. Sometimes you just have to flit between the frontend and backend of your application!
But this time around I discovered: changes in structure are apparently harder for my brain than changes in syntax. E.g.:
Switching in and out of Python’s indentation caught me out at least once (might’ve been better if I took the time to install the language’s tools into my text editor first!).
Switching from a language without enforced semicolon line ends (e.g. Ruby, Go) to one with them (e.g. Java, PHP) had me make the compiler sad several times.
This gets even tougher when not writing the language but writing about the language: my first pass at the documentation for the Go version somehow ended up with
Ruby/Python-style #-comments instead of Go/Java/TypeScript-style //-comments; whoops!
I’m guessing that the part of my memory that looks after a language’s keywords, how a method header is structured, and which equals sign to use for assignment versus comparison… are
stored in a different part of my brain than the bit that keeps track of how a language is laid-out?12
Okay, time for a new job
I reckon it’s time I got back into work, so I’m going to have a look around and see if there’s any roles out there that look exciting to me.
If you know anybody who’s looking for a UK-based, remote-first, senior+, full-stack web developer with 25+ years experience and more languages than you can shake a stick at… point them at my CV, would you?
Footnotes
1 I suspect that when most software engineers look for a new job, they filter to the
languages, frameworks, they feel they’re strongest at. I do a little of that, I suppose, but I’m far more-motivated by culture, sector, product and environment than I am by the shape
of your stack, and I’m versatile enough that technology specifics can almost come second. So long as you’re not asking me to write VB.NET.
2 It’s sort-of a parallel to how I decided to check
the other week that my Gutenberg experience was sufficiently strong that I could write standard ReactJS, too.
3 I was pleased to find a tech test that actually called for an understanding of algorithm
growth/scaling rates, so I could steal this requirement for my own experiment! I fear that sometimes, in their drive to be pragmatic and representative of “real work”, the value of a
comprehension of computer science fundamentals is overlooked by recruiters.
4 Even if an algorithm takes the approach of creating a new list with the
inserted/modified item at the top, that’s still just a very-specific case of insertion sort when you think about it, right?
5 The second design will be slower at writing but faster at
reading, and will scale better as the cache gets larger. That sounds great for a read-often/write-rarely cache, but your situation may differ.
6 Okay, my language selection was pretty arbitrary. But if I’d have also come up with
implementations in Perl, and C#, and Elixir, and whatever else… I’d have been writing code all day!
7 So long as I’m willing to be flexible about the “object-oriented” requirement, there are
even more options available to me. Probably the language that I last wrote longest ago would be Pascal: I wonder how much of that I remember?
8 Ruby’s safe navigation/”lonely” operator did the same thing as PHP’s nullsafe operator
since 2015.
9 TypeScript got union types back in 2015, and apart from them being more-strictly-enforced they’re basically identical to
PHP’s.
10 Did you know that Python had keyword arguments since its very first public release
way back in 1994! How did it take so many other interpreted languages so long to catch up?
11 The feature was the three-way comparison or “spaceship operator”, in case you were wondering.
12 I wonder if anybody’s ever laid a programmer in an MRI machine while they code? I’d
be really interested to see if different bits of the brain light up when coding in functional programming languages than in procedural ones, for example!
Ok, I’m NOT an immediate fan of “vibe coding” and overusing LLMs in programming. I have a healthy amount of skepticism
about the use of these tools, mostly related to the maintainability of the code, security, privacy, and a dozen other more factors.
But some arguments I’ve seen from developers about not using the tools because it means they “will lose their coding skills” its just bonkers. Especially in a professional context.
Imagine you go to a carpenter, and they say “this will take 2x the time because I don’t use power tools, they make me feel like I’m losing my competence in manual skills”. It’s your
job to deliver software using the most efficient and accurate methods possible.
Sure, it is essential that you keep your skills sharp, but being purposfully less effective in your job to keep them sharp is a red flag. And in an industry made of abstractions to
increase productivity (we’re no longer coding in Assembly last time I checked), this makes even less sense.
/rant
I’m in two minds on this (as I’ve hinted before). The carpenter analogy doesn’t really hold, because the underlying skill of carpentry
is agnostic to whether or not you use power tools: it’s about understanding the material properties of woods, the shapes of joins, the ways structures are strong and where they are
weak, the mathematics and geometry that make design possible… none of which are taken over by power tools.
25+ years ago I wrote most of my Perl/PHP code without an Internet connection. When you wanted to deploy you’d “dial up”, FTP some files around, then check it had worked. In that
environment, I memorised a lot more. Take PHP’s date formatting strings, for example: I used to have them down by heart! And even when I didn’t, I knew approximately the right spot to
flip the right book open to that I’d be able to look it up quickly.
“Always-on” broadband Internet gradually stole that skill from me. It’s so easy for me to just go to the right page on php.net and have the answer I need right in front of me! Nowadays, I depend
on that Internet connection (I don’t even have the book any more!).
A power tool targets a carpenter’s production speed,
not their knowledge-recovery speed.
Will I experience the same thing from my LLM usage, someday?
As I mentioned in my recent Blog Questions Challenge, I recently switched my blog from WordPress, which it had been running on for over 20 years of its 26 year history, to ClassicPress.1
I’m aware that I’m not the only person for whom ClassicPress might be a better fit
than WordPress2,
so I figured I should share the process by which I undertook the change.
Switching from WordPress to ClassicPress
Switching from WordPress to ClassicPress should be a non-destructive, 100% reversible process, but (even though I’ve got solid backups) I wasn’t ready to
trust that, so I decided to operate on a copy of my site. I’m glad I did, because there were a couple of teething issues I needed to tackle before I could launch.
1. Duplicating the site
I took a simple approach to duplicating the site: (1) I copied the site directory, and (2) I copied the database, and (3) I set up a new subdomain to use for testing. Here’s how I did
each step:
1.1. Copying the site directory
This should’ve been simple, but a du -sh revealed that my /wp-content/uploads directory is massive (I should look into that) and I didn’t want to
clone it. And I didn’t want r need to clone my /wp-content/cache directory either. So I ran:
rsync -av --exclude=wp-content ./old-site-directory/ ./new-site-directory/ to copy everything exceptwp-content, and then
rsync -av --exclude=uploads --exclude=cache ./old-site-directory/wp-content/ ./new-site-directory/wp-content/ to copy wp-contentexcept the
uploads and cache subdirectories, and then finally
ln -s ./old-site-directory/wp-content/uploads ./new-site-directory/wp-content/uploads to symlink the uploads directory, sharing it between the two sites
1.2. Copying the database
I just piped mysqldump into mysql to clone from one database to the other:
mysqldump -uUSERNAME -p --lock-tables=false old-site-database | mysql -uUSERNAME -p new-site-database
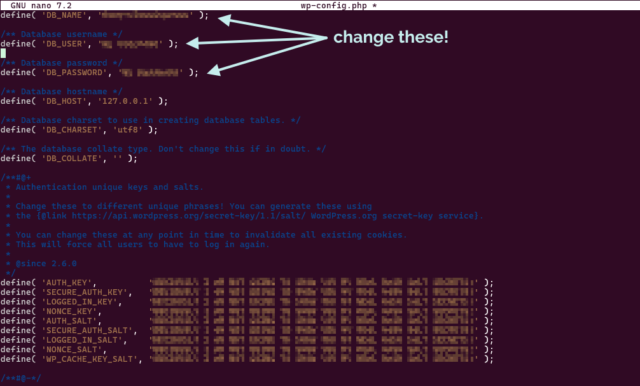
I edited DB_NAME in wp-config.php in the new site’s directory to point it at the new database.
If you’re going to clone your WordPress site before converting to ClassicPress, you’ll want to be comfortable editing your wp-config.php.
1.3. Setting up a new subdomain
My DNS is already configured with a wildcard to point (almost) all *.danq.me subdomains to this server already. I decided to use the name classicpress-testing.danq.me as my
temporary/test domain name. To keep any “changes” to my cloned site to a minimum, I overrode the domain name in my wp-config.php rather than in my database, by adding the
following lines:
Because I use Caddy/FrankenPHP as my webserver3,
configuration was really easy: I just copied the relevant part of my Caddyfile (actually an include), changed the domain name and the root, and it just worked,
even provisioning me out a LetsEncrypt SSL certificate. Magical4.
2. Switching the duplicate to ClassicPress
Now that I had a duplicate copy of my blog running at https://classicpress-testing.danq.me/, it was time to switch it to ClassicPress. I started by switching my wp-admin
colour scheme to a different one in my cloned site, so it’d be immediately visually-obvious to me if I’d accidentally switched and was editing the “wrong” site (I also made sure I was
logged-out of my primary, live site, so I was confident I wouldn’t break anything while I was experimenting!).
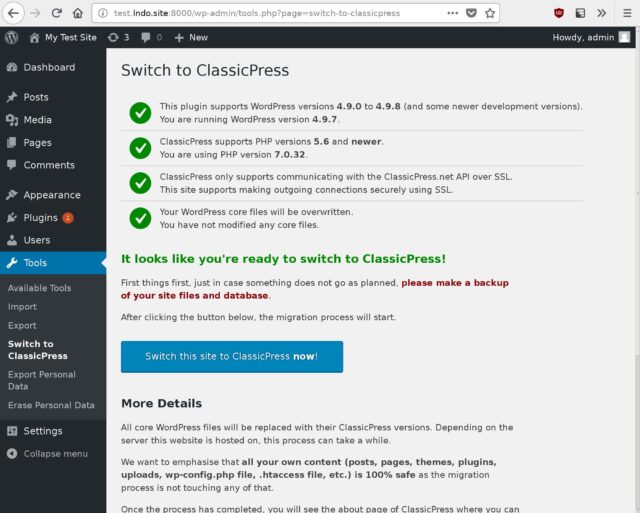
ClassicPress provides a migration plugin which checks for common problems and then switches your site
from WordPress to ClassicPress, so I installed it and ran it. It said that everything was okay except for my (custom) theme and a my self-built plugins, which it understandably couldn’t
check compatibility of. It recommended that I install Twenty Seventeen – the last WordPress default theme to not
require the block editor – but I didn’t do so: I was confident that my theme would work anyway… and if it didn’t, I’d want to fix it rather than switch theme!
I failed to take a screenshot of the actual process, but it looked broadly like this.
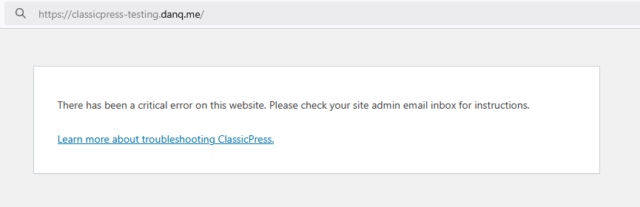
And then… it all broke.
3. Fixing what broke
After swiftly doing a safety-check that my live site was still intact, I started trying to work out why my site wasn’t broken. Debugging a ClassicPress PHP issue is functionally
identical to debugging a similar WordPress issue, for obvious reasons: check the logs, work out what’s broken, realise it’s a plugin, disable that plugin while you investigate further,
etc.
EWWW Image Optimizer: I use this plugin to pregenerate WebP variants of my images, which I then serve using webserver rules. It’s not a
complex job, and I should probably integrate the feature into my theme at some point, but for now I use this plugin. Version 8.0.0 of the plugin doesn’t work on ClassicPress 2.3.1, so
I used WP-CLI to downgrade to the last version that does (7.7.0), and then it worked fine.
Dan’s Geocaching Log Reposter: a self-made plugin that copies my logs from geocaching websites stopped working properly, which I think is because
ClassicPress is doing a more-aggressive job than WordPress at nonce validation on admin REST endpoints? I put a quick hack into my plugin to work around it, but I’ll need to look into
this properly at some point.
Some other bits of my stack, e.g. CapsulePress (my Gemini/Spartan/Nex server), have their own copies of my
database credentials, because I’ve been too lazy to centralise them into environment variables, and needed updating (but not until live switchover time).
I ran the two sites in-parallel for a couple of weeks, with the ClassicPress one as a “read only” version (so I didn’t pollute my uploads directory!), but it was pretty unnecessary
because it all worked pretty seamlessly, despite my complex stack of custom code. When I wanted to switch for-real, all I needed to do was swap the domain names over in my Caddyfile and
edit the wp-config.php of my ClassicPress installation: step 1.3, but in reverse!
If you hadn’t been told5, you probably wouldn’t have even known I’d made a change: I suppress basically all infrastructure-identifying
headers from my server output as a matter of course, and ClassicPress and WordPress are functionally-interchangeable from a front-end perspective6.
So what’s difference?
From my experience, here are the differences I’ve discovered since switching from WordPress to ClassicPress:
The good stuff
😅 ClassicPress has no Gutenberg/block editor. This would absolutely be a showstopper for many people, and that’s fine: I have nothing against the block editor (I
use it basically every day elsewhere!), but I’ve never really used it on danq.me and don’t feel the need to change that! My theme, my workflow, and my custom plugins are all
geared around the perfectly-good “classic” editor, and so getting a more-lightweight CMS by removing a feature I wasn’t using anyway falls somewhere between neutral and a blessing.
⚡The backend is fast again! One of the changes the ClassicPress team have been working on applying to WordPress is to strip out jQuery and other redundancies from
the backend, and I love how much faster and lighter my editor interface is as a result. (With caveat; see below!)
🔌Virtually everything “just works”. With the few exceptions described above, everything works exactly as it does under WordPress. Which is what you’d hope for a fork
that’s mostly “WordPress, but without the block editor”, right, but it’s still reassuring (and, for me, an essential feature). There are a few “new” features to do with paging through
posts and the media library and they’re fine, I suppose, but not by themselves worth switching for (though it might be nice to backport them into WordPress!).
The bad stuff
🏷️ Adding tags to posts takes a step backwards. A side-effect of dropping jQuery is the partial loss of the autocomplete feature when selecting tags to add to a post.
You still get a partial autocomplete, but not after typing a comma: you need to press enter to submit the tag you were writing and then start typing them next, which
frankly sucks. This is because they’re relying on a <datalist>, which isn’t as full-featured as the Javascript solution WordPress employs. This bugs
me almost enough to be a showstopper, but I gather it’s getting fixed in a near-future version.
🗺️ You’re in uncharted territory when things go wrong. One great benefit of WordPress is the side-effects of its ubiquity. If you have a query or a problem
you can throw a stone at your favourite search engine and get a million answers… and some of them will even be right! If you have a problem in ClassicPress and it’s not shared with (or
you’re not sure if it’s shared with) WordPress… you’re mostly on your own. The forums are good and friendly,
but if you want a quick answer to something, you’re likely to have to roll your sleeves up and open some source code. I don’t mind this at all – when I first started using WordPress,
this was the case, too! – but it might be a showstopper for some folks.
In summary: I’m enjoying using ClassicPress, even where there are rough edges. For me, 99% of my experience with it is identical to how I used WordPress anyway, it’s relatively
lightweight and fast, and it’s easy enough to switch back if I change my mind.
Footnotes
1 It saddens me that I have to keep clarifying this, but I feel like I do: my switch from
WordPress to ClassicPress is absolutely nothing to do with any drama in the WordPress space that’s going on right now: in fact, I’d been planning to try it out since before
any of the drama appeared. I appreciate that some people making a similar switch, including folks who use this blog post as a guide, might have different motivations to me, and that’s
fine too. Personally, I think that ditching an installation of open-source WordPress based on your interpretation of what’s going on in the ecosystem is… short-sighted? But
hey: the joy of open source is you can – and should! – do what you want. Anyway: the short of it is – the desire to change from WordPress to ClassicPress was, for me, 100% a
technical decision and 0% a political one. And I’ll thank you for leaving any of your drama at the door if you slide into my comments, ta!
2Matt recently described ClassicPress as “the last decent fork
attempt for WordPress”, and I absolutely agree. There’s been a spate of forks and reimplementations recently. I’ve looked into many of them and been… very much underwhelmed. Want my
hot take? Sure, here you go: AspirePress is all lofty ideas and no deliverables. FreeWP seems to be the same, but somehow without the lofty ideas. ForkPress is a ghost. Speaking of
ghosts, Ghost isn’t a WordPress fork; they have got some cool ideas though. b2evolution is even less a WordPress fork but it’s pretty cool in its own right. I’m not sure what
clamPress is trying to achieve but I’ve not given it a serious look. So yeah: ClassicPress is, in my mind, the only WordPress fork even worth consideration at this point, and as I
describe in this blog post: it’s not for everybody.
3 I switched from Nginx over the winter and it’s been just magical: I really love
Caddy’s minimal approach to production configuration. The only thing I’ve been able to fault it on is that it’s not capable of setting up client-side SSL certificate authentication on
a path, only on an entire domain, which meant I needed to reimplement the authentication mechanism I use on a small part of my (non-blog) internal
infrastructure.
4 To be fair, it wouldn’t have been hard if I’d still be using Nginx, because I’d
set up Certbot to use DNS-based vertification to issue me wildcard SSL certificates. But doing this in Caddy still felt magical.
6 Indeed, I wouldn’t have considered a switch to ClassicPress in the first place if it
wasn’t a closely-aligned-enough fork that I retained the ability to flip-flop between the two to my heart’s content! I’ve loved WordPress for over two decades; that’s not going to
change any time soon… and if e.g. ClassicPress ceased tracking WordPress releases and the fork diverged too far for my comfort, I’d probably switch back to regular old WordPress!
Last week, I discovered Geneveive Raine‘s “The Continuum”, a super-compressed image comprised of
1-pixel-tall versions of her home page’s daily banners, stitched together1.
I thought it was a beautiful idea, so I stole adapted it to produce an illustration based on the featured images of my blog posts:
Only about 38% of my 5,445 blog posts have featured images suitable for use in this diagram. But here they are!
I generated a horizontal version too, but I’ve used the vertical version above because it’s
more-suitable for use with a HTML imagemap2.
Here’s the code I used to generate the images (and the imagemap), if you want to run it against your own
WordPress-ish blog.
Footnotes
1 Which was in-turn inspired by Movie
Iris, a tool that visualises the frames of a movie as a radial graphic.
2 What’s a HTML imagemap, you ask? You don’t need to ask: you shouldn’t be using it
anyway. Relying on it means you’re setting yourself up for an accessibility nightmare. Anyway: I used one above: you
can click on any “stripe” of the image to jump to the corresponding post. It needed some fighting-with because imagemaps can’t work with rescaled images, so I’ve forced the height of
the image even as it resizes horizontally. Not that you’re going to click on the stripes anyway: it’s just about the worst way imaginable to navigate a blog.
Even when it’s technical, not all of my International Volunteer Day work for Three Rings has been spent using our key technologies (LNMR [Linux, Nginx, MariaDB, Ruby] stacks).
Today, I wrote some extra PHP for our WordPress-powered contact form to notify our Support Team volunteers via Slack when messages are sent. We already aim to respond to every message
within 24 hours, 365 days a year, and are often faster than that… but this might help us to be even more-responsive to the needs of the charities who we help look after.
Three Rings operates a Web contact form to help people get in touch with us: the idea
is that it provides a quick and easy way to reach out if you’re a charity who might be able to make use of the system, a user who’s having difficulty with the features of the software,
or maybe a potential new volunteer willing to give your time to the project.
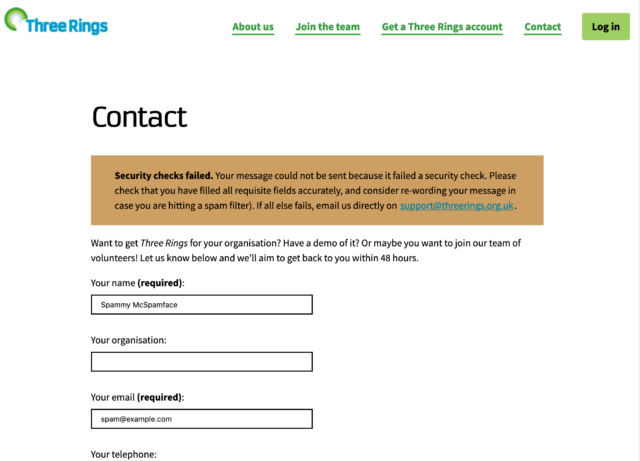
But then the volume of spam it received increased dramatically. We don’t want our support team volunteers to spend all
their time categorising spam: even if it doesn’t take long, it’s demoralising. So what could we do?
It’s clearly spam, but if it takes you 2 seconds to categorise it and there are 30 in your Inbox, that’s still a drag.
Our conventional antispam tools are configured pretty liberally: we don’t want to reject a contact from a legitimate user just because their message hits lots of scammy keywords (e.g.
if a user’s having difficulty logging in and has copy-pasted all of the error messages they received, that can look a lot like a password reset spoofing scam to a spam filter). And we
don’t want to add a CAPTCHA, because not only do those create a barrier to humans – while not necessarily reducing spam very much, nowadays – they’re often terrible for accessibility,
privacy, or both.
But it didn’t take much analysis to spot some patterns unique to our contact form and the questions it asks that might provide an opportunity. For example, we discovered that
spam messages would more-often-than-average:
Fill in both the “name” and (optional) “Three Rings username” field with the same value. While it’s cetainly possible for Three Rings users to have
a login username that’s identical to their name, it’s very rare. But automated form-fillers seem to disproportionately pair-up these two fields.
Fill the phone number field with a known-fake phone number or a non-internationalised phone number from a country in which we currently support no charities.
Legitimate non-UK contacts tend to put international-format phone numbers into this optional field, if they fill it at all. Spammers often put NANP (North American Numbering Plan)
numbers.
Include many links in the body of the message. A few links, especially if they’re to our services (e.g. when people are asking for help) is not-uncommon in legitimate
messages. Many links, few of which point to our servers, almost certainly means spam.
Choose the first option for the choose -one question “how can we help you?” Of course real humans sometimes pick this option too, but spammers almost always
choose it.
None of these characteristics alone, or any of the half dozen or so others we analysed (including invisible checks like honeypots and IP-based geofencing), are reason to
suspect a message of being spam. But taken together, they’re almost a sure thing.
To begin with, we assigned scores to each characteristic and automated the tagging of messages in our ticketing system with these scores. At this point, we didn’t do anything to block
such messages: we were just collecting data. Over time, this allowed us to find a safe “threshold” score above which a message was certainly spam.
Even when a message fails our customised spam checks, we only ‘soft-block’ it: telling the user their message was rejected and providing suggestions on working around that or emailing
us conventionally. Our experience shows that the spammers aren’t willing to work to overcome this additional hurdle, but on the very rare ocassion a human hits them, they are.
Once we’d found our threshold we were able to engage a soft-block of submissions that exceeded it, and immediately the volume of spam making it to the ticketing system dropped
considerably. Under 70 lines of PHP code (which sadly I can’t share with you) and we reduced our spam rate by over 80% while having, as far as we can see, no impact on the
false-positive rate.
Where conventional antispam solutions weren’t quite cutting it, implementing a few rules specific to our particular use-case made all the difference. Sometimes you’ve just got to roll
your sleeves up and look at the actual data you do/don’t want, and adapt your filters accordingly.
Like my occasional video content, this isn’t designed to replace any of my blogging: it’s just a different medium for those that might prefer it.
For some stories, I guess that audio might be a better way to find out what I’ve been thinking about. Just like how the vlog version of my post about
my favourite video game Easter Egg might be preferable because video as a medium is better suited to demonstrating a computer game, perhaps
audio’s the right medium for some of the things I write about, too?
But as much as not, it’s just a continuation of my efforts to explore different media over which a WordPress blog can be delivered2.
Also, y’know, my ongoing effort to do what I’m bad at in the hope that I might get better at a wider diversity of skills.
How?
Let’s start by understanding what a “podcast” actually is. It is, in essence, just an RSS feed (something you might have heard me talk about before…) with audio enclosures – basically, “attachments” – on each item. The idea was spearheaded by Dave Winer back in 2001 as a
way of subscribing to rich media like audio or videos in such a way that slow Internet connections could pre-download content so you didn’t have to wait for it to buffer.3
Podcasts are pretty simple, even after you’ve bent over backwards to add all of the metadata that Apple Podcasts (formerly iTunes) expects to see. I looked at a couple of
WordPress plugins that claimed to be able to do the work for me, but eventually decided it was simple enough to just add some custom metadata fields that could then be included in my
feeds and tweak my theme code a little.
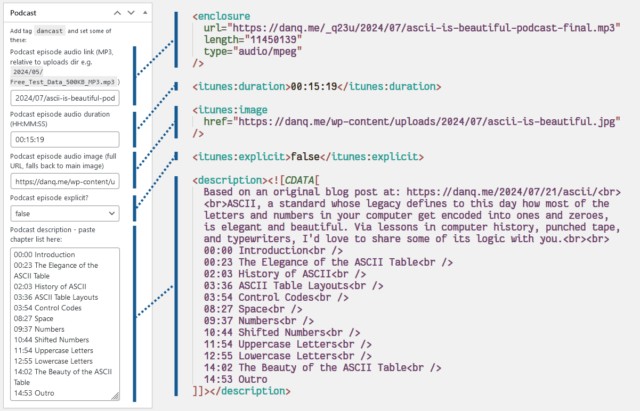
Here’s what I had to do to add podcasting capability to my theme:
The tag
I use a post tag, dancast, to represent posts with accompanying podcast content4.
This way, I can add all the podcast-specific metadata only if the user requests the feed of that tag, and leave my regular feeds untampered . This means that you don’t
get the podcast enclosures in the regular subscription; that might not be what everybody would want, but it suits me to serve podcasts only to people who explicitly ask for
them.
Okay, onto the code (which I’ve open-sourced over here). I’ve use a series of standard WordPress hooks to
add the functionality I need. The important bits are:
rss2_item – to add the <enclosure>, <itunes:duration>, <itunes:image>, and
<itunes:explicit> elements to the feed, when requesting a feed with my nominated tag. Only <enclosure> is strictly required, but appeasing Apple
Podcasts is worthwhile too. These are lifted directly from the post metadata.
the_excerpt_rss – I have another piece of post metadata in which I can add a description of the podcast (in practice, a list of chapter times); this hook
swaps out the existing excerpt for my custom one in podcast feeds.
rss_enclosure – some podcast syndication platforms and players can’t cope with RSS feeds in which an item has multiple enclosures, so as a
safety precaution I strip out any enclosures that WordPress has already added (e.g. the featured image).
the_content_feed – my RSS feed usually contains the full text of every post, because I don’t like feeds that try to force you to go to the
original web page5
and I don’t want to impose that on others. But for the podcast feed, the text content of the post is somewhat redundant so I drop it.
rss2_ns – of critical importance of course is adding the relevant namespaces to your XML declaration. I use the itunes namespace, which provides the widest compatibility for specifying metadata, but I also use the
newer podcast namespace, which has growing compatibility and provides some modern features, most of which I don’t
use except specifying a license. There’s no harm in supporting both.
rss2_head – here’s where I put in the metadata for the podcast as a whole: license, category, type, and so on. Some of these fields are
effectively essential for best support.
You’re welcome, of course, to lift any of all of the code for your own purposes. WordPress makes a perfectly reasonable platform for podcasting-alongside-blogging, in my experience.
What?
Finally, there’s the question of what to podcast about.
My intention is to use podcasting as an alternative medium to my traditional blog posts. But not every blog post is suitable for conversion into a podcast! Ones that rely on images
(like my post about dithering) aren’t a great choice. Ones that have lots of code that you might like to copy-and-paste are especially unsuitable.
You’re listening to Radio Dan. 100% Dan, 100% of the time.(Also I suppose you might be able to hear my dog snoring in the background…)
Also: sometimes I just can’t be bothered. It’s already some level of effort to write a blog post; it’s like an extra 25% effort on top of that to record, edit, and upload a podcast
version of it.
That’s not nothing, so I’ve tended to reserve podcasts for blog posts that I think have a sort-of eccentric “general interest” vibe to them. When I learn something new and feel the need
to write a thousand words about it… that’s the kind of content that makes it into a podcast episode.
Which is why I’ve been calling the endeavour “a podcast nobody asked for, about things only Dan Q cares about”. I’m capable of getting nerdsniped
easily and can quickly find my way down a rabbit hole of learning. My podcast is, I guess, just a way of sharing my passion for trivial deep dives with the rest of the world.
My episodes are probably shorter than most podcasts: my longest so far is around fifteen minutes, but my shortest is only two and a half minutes and most are about seven. They’re meant
to be a bite-size alternative to reading a post for people who prefer to put things in their ears than into their eyes.
Anyway: if you’re not listening already, you can subscribe from here or in your favourite podcasting app. Or you can just follow my blog as normal
and look for a streamable copy of podcasts at the top of selected posts (like this one!).
2 As well as Web-based non-textual content like audio (podcasts) and video (vlogs), my blog is wholly or partially available over a variety of more-exotic protocols: did you find me yet on Gemini (gemini://danq.me/), Spartan (spartan://danq.me/), Gopher (gopher://danq.me/), and even Finger
(finger://danq.me/, or run e.g. finger blog@danq.me from your command line)? Most of these are powered by my very own tool CapsulePress, and I’m itching to try a few more… how about a WordPress blog that’s accessible over FTP, NNTP, or DNS? I’m not even kidding when I say
I’ve got ideas for these…
3 Nowadays, we have specialised media decoder co-processors which reduce the size of media
files. But more-importantly, today’s high-speed always-on Internet connections mean that you probably rarely need to make a conscious choice between streaming or downloading.
4 I actually intended to change the tag to podcast when I went-live,
but then I forgot, and now I can’t be bothered to change it. It’s only for my convenience, after all!
Why must a blog comment be text? Why could it not be… a drawing?1
Red and black might be more traditional ladybird colours, but sometimes all you’ve got is blue.
I started hacking about and playing with a few ideas and now, on selected posts including this one, you can draw me a comment instead of typing one.
Just don’t tell the soup company what I’ve been working on, okay?
I opened the feature, experimentally (in a post available only to RSS subscribers2) the
other week, but now you get a go! Also, I’ve open-sourced the whole thing, in case you want to pick it apart.
What are you waiting for: scroll down, and draw me a comment!
Footnotes
1 I totally know the reasons that a blog comment shouldn’t be a drawing; I’m not
completely oblivious. Firstly, it’s less-expressive: words are versatile and you can do a lot with them. Secondly, it’s higher-bandwidth: images take up more space, take longer to
transmit, and that effect compounds when – like me – you’re tracking animation data too. But the single biggest reason, and I can’t stress this enough, is… the
penises. If you invite people to draw pictures on your blog, you’re gonna see a lot of penises. Short penises, long penises, fat penises, thin penises. Penises of every shape
and size. Some erect and some flacid. Some intact and some circumcised. Some with hairy balls and some shaved. Many of them urinating or ejaculating. Maybe even a few with smiley
faces. And short of some kind of image-categorisation AI thing, you can’t realistically run an anti-spam tool to detect hand-drawn penises.
2 I’ve copied a few of my favourites of their drawings below. Don’t forget to subscribe if you want early access to any weird shit I make.
Terence Eden, who’s apparently inspiring several posts this week, recently shared a way to attach a hook to WordPress’s
get_the_post_thumbnail() function in order to remove the extraneous “closing mark” from the (self-closing in HTML) <img> element.
By default, WordPress outputs e.g. <img src="..." />, where <img src="..."> would suffice.
It’s an inconsequential difference for most purposes, but apparently it bugs him, so he fixed it… although he went on to observe that he hadn’t managed to successfully tackle
all the instances in which WordPress was outputting redundant closing marks.
This is a problem that I’ve already solved here on my blog. My solution’s slightly hacky… but it works!
There are many things you could say about the HTML produced to make the page you’re reading now. But “it needs fewer />s” isn’t among them.
My Solution: Runing HTMLTidy over WordPress
Tidy is an excellent tool for tiding up HTML! I used to use its predecessor back in
the day for all kind of things, but it languished for a few years and struggled with support for modern HTML features. But
in 2015 it made a comeback and it’s gone from strength to strength ever since.
I run it on virtually all pages produced by DanQ.me (go on, click “View Source” and see for yourself!), to:
Standardise the style of the HTML code and make it easier for humans to read1.
Bring old-style emphasis tags like <i>, in my older posts, into a more-modern interpretation, like <em>.
Hoist any inline <style> blocks to the <head>, and detect any repeated inline style="..."s to convert to classes.
Repair any invalid HTML (browsers do this for you, of course, but doing it server-side makes parsing easier for the
browser, which might matter on more-lightweight hardware).
WordPress isn’t really designed to have Tidy bolted onto it, so anything it likely to be a bit of a hack, but here’s my approach:
Install libtidy-dev and build the PHP bindings to it.
Note that if you don’t do this the code might appear to work, but it won’t actually tidy anything2.
Add a new output buffer to my theme’s header.php3, with a callback function: ob_start('tidy_entire_page').
Without an corresponding ob_flush or similar, this buffer will close and the function will be called when PHP
finishes generating the page.
Define the function tidy_entire_page($buffer) Have it instantiate Tidy ($tidy = new tidy) and use $tidy->parseString (with your buffer and Tidy preferences) to tidy the code, then
return $tidy.
Ensure that you’re caching the results!
You don’t want to run this every page load for anonymous users! WP Super Cache on “Expert” mode (with the
requisite webserver configuration) might help.
1 I miss the days when most websites were handwritten and View Source typically looked
nice. It was great to learn from, too, especially in an age before we had DOM debuggers. Today: I can’t justify
dropping my use of a CMS, but I can make my code readable.
2 For a few of its extensions, some PHP developer made the interesting choice to fail silently if the required extension is missing. For example: if you don’t have the
zip extension enabled you can still usePHPto make ZIP files, but they won’t be
compressed. This can cause a great deal of confusion for developers! A similar issue exists with tidy: if it isn’t installed, you can still call all of the
methods on it… they just don’t do anything. I can see why this decision might have been made – to make the language as portable as possible in production – but I’d
prefer if this were an optional feature, e.g. you had to set try_to_make_do_if_you_are_missing_an_extension=yes in your php.ini to enable it, or if
it at least logged that it had done so.
3 My approach probably isn’t suitable for FSE (“block”) themes, sorry.
I clearly nerdsniped Terence at least a little when I asked whether a blog necessarily had to be HTML, because he went on to implement a WordPress theme that delivers content entirely in plain text.
theunderground.blog‘s content, with the exception of its homepage, is delivered entirely through an XML Atom feed. Atom feed entries do require <title>s, of course, so that’s not the strongest counterexample!
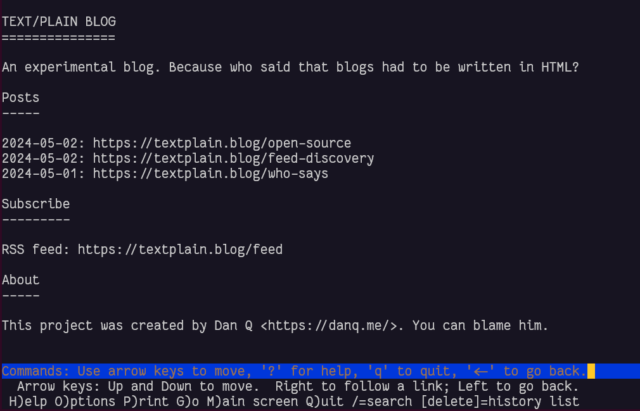
This blog is available over several media other than the Web. For example, you can read this blog post:
We’ve looked at plain text, which as a format clearly does not have to have a title. Let’s go one step further and implement it. What we’d need is:
A webserver configured to deliver plain text files by preference, e.g. by adding directives like index index.txt; (for Nginx).5
An index page listing posts by date and URL. Most browser won’t render these as “links” so users will have to copy-paste
or re-type them, so let’s keep them short,
Pages for each post at those URLs, presumably without any kind of “title” (just to prove a point), and
An RSS feed: usually I use RSS as shorthand for all feed
types, but this time I really do mean RSS and not e.g. Atom because RSS, strangely, doesn’t require that an <item> has a <title>!
Unlike other sites, I didn’t need to test textplain.blog in Lynx to
know it’d work well. But I did anyway.
In the end I decided it’d benefit from being automated as sort-of a basic flat-file CMS, so I wrote it in PHP. All requests are routed by the webserver to the program, which determines whether they’re a request for the homepage, the RSS feed, or a valid individual post, and responds accordingly.
It annoys me that feed
discovery doesn’t work nicely when using a Link: header, at least not in any reader I tried. But apart from that, it seems pretty solid, despite its limitations. Is this,
perhaps, an argument for my.well-known/feedsproposal?
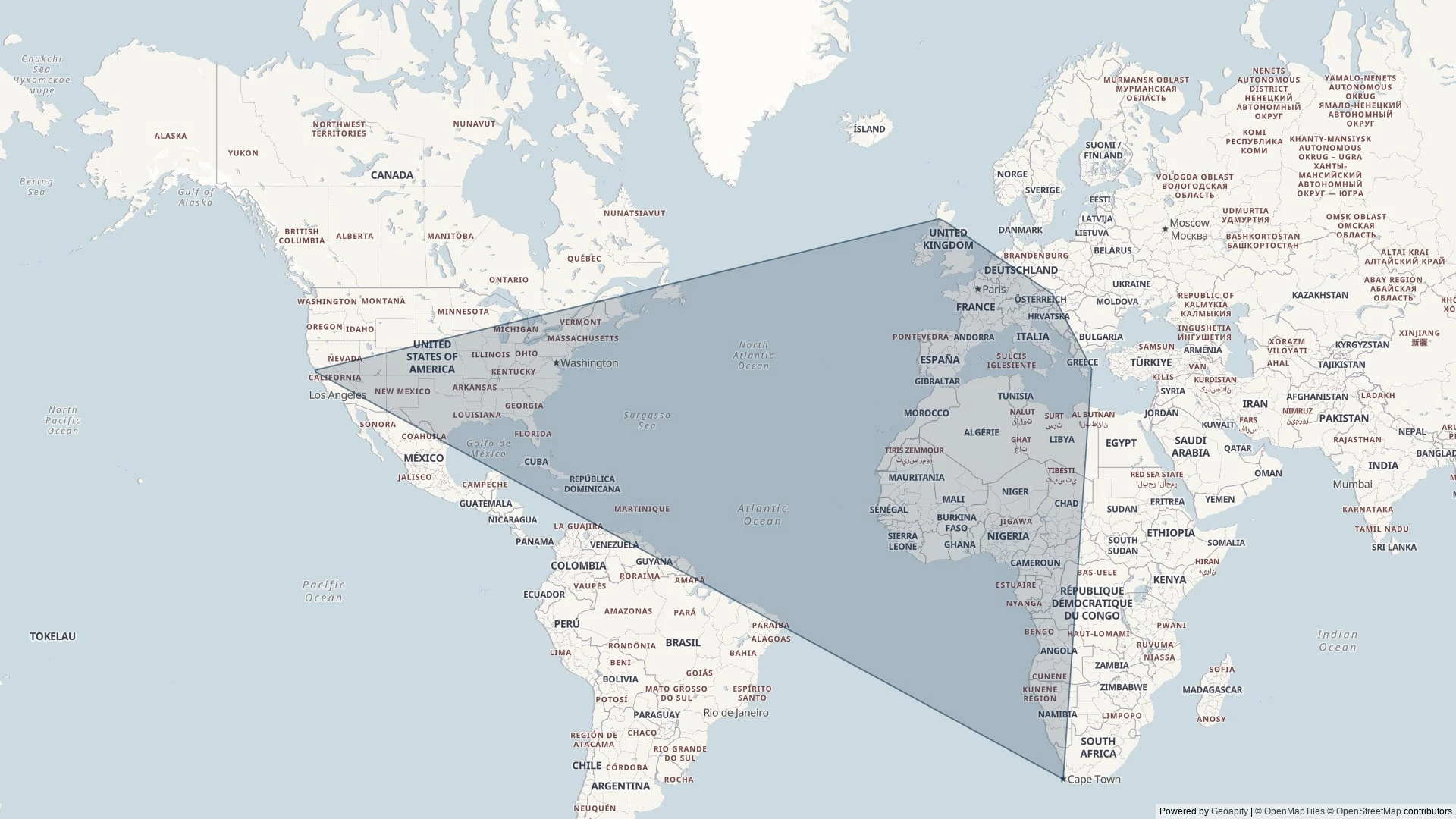
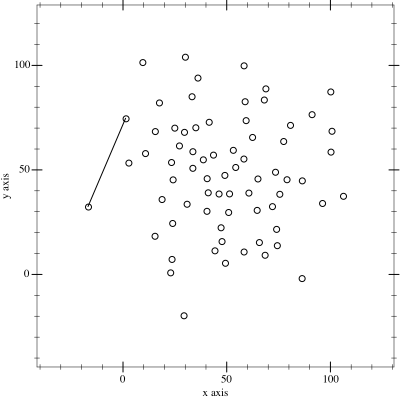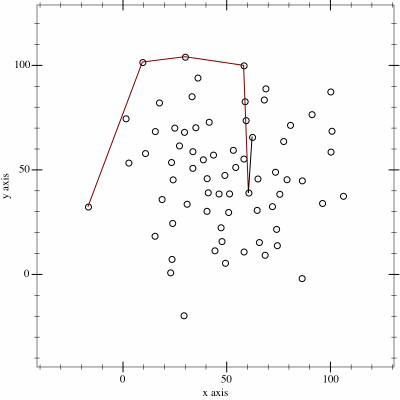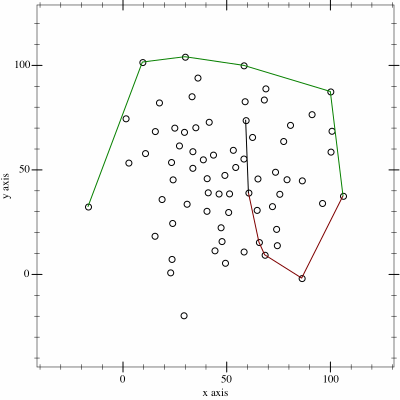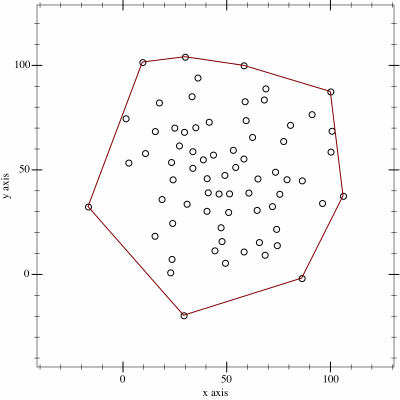
I thought it might be fun to try to map the limits of my geocaching/geohashing. That is, to draw the smallest possible convex polygon that surrounds all of the
geocaches I’ve found and geohashpoints I’ve successfully visited.
Mathematically, such a shape is a convex hull – the smallest polygon encircling a set of points without concavity. Here’s how I made it:
1. Extract all the longitude/latitude pairs for every successful geocaching find and geohashpoint expedition.I keep them in my blog database, so I was able to use some SQL to
fetch them:
SELECTDISTINCT coord_lon.meta_value lon, coord_lat.meta_value lat
FROM wp_posts
LEFTJOIN wp_postmeta expedition_result ON wp_posts.ID = expedition_result.post_id AND expedition_result.meta_key ='checkin_type'LEFTJOIN wp_postmeta coord_lat ON wp_posts.ID = coord_lat.post_id AND coord_lat.meta_key ='checkin_latitude'LEFTJOIN wp_postmeta coord_lon ON wp_posts.ID = coord_lon.post_id AND coord_lon.meta_key ='checkin_longitude'LEFTJOIN wp_term_relationships ON wp_posts.ID = wp_term_relationships.object_id
LEFTJOIN wp_term_taxonomy ON wp_term_relationships.term_taxonomy_id = wp_term_taxonomy.term_taxonomy_id
LEFTJOIN wp_terms ON wp_term_taxonomy.term_id = wp_terms.term_id
WHERE wp_posts.post_type ='post'AND wp_posts.post_status ='publish'AND wp_term_taxonomy.taxonomy ='kind'AND wp_terms.slug ='checkin'AND expedition_result.meta_value IN ('Found it', 'found', 'coordinates reached', 'Attended');
2. Next, I determine the convex hull of these points. There are an interesting variety of
algorithms for this so I adapted the Monotone Chain approach (there are
convenient implementations in many languages). The algorithm seems pretty efficient, although that doesn’t matter much to me because I’m caching the results for a fortnight.
I watched way too many animations of different convex hull algorithms before selecting this one… pretty-much arbitrarily.
An up-to-date (well, no-more than two weeks outdated) version of the map appears on my geo* stats page. I don’t often get to go caching/hashing
outside the bounds already-depicted, but I’m excited to try to find opportunities to push the boundaries outwards as I continue to explore the world!
(I could, I suppose, try to draw a second larger area of places I’ve visited: the difference between the smaller and larger areas would represent all of the opportunities I’d missed to
find a hashpoint!)
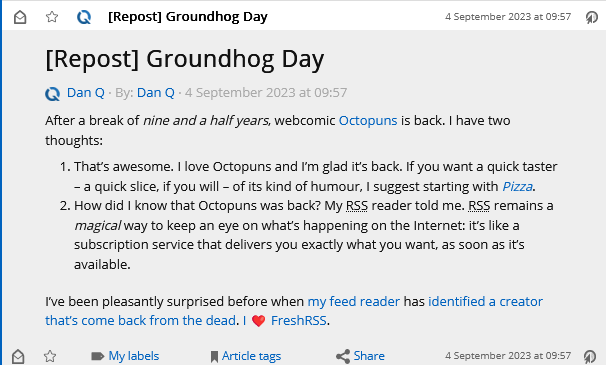
It turns out that by default, WordPress replaces emoji in its feeds (and when sending email) with images of those emoji, using the Tweemoji set, and with the alt-text set to the original emoji. These images are hosted at https://s.w.org/images/core/emoji/…-based
URLs.
I can see why this functionality was added: what if the feed reader didn’t support Unicode or didn’t have a font capable of showing the appropriate emoji?
But I can also see reasons why it might not be desirable to everybody. For example:
Downloading an image will always be slower than rendering an emoji.
The code to include an image is always more-verbose than simply including an emoji.
As seen above: a feed reader which imposes a minimum size on embedded images might well render one “wrong”.
It’s marginally more-verbose for screen reader users to say “Image: heart emoji” than just “heart emoji”, I imagine.
Serving an third-party image when a feed item is viewed has potential privacy implications that I try hard to avoid.
Replacing emoji with images is probably unnecessary for modern feed readers anyway.
That’s all there is to it. Now, my feed reader shows my system’s emoji instead of a huge image:
I’m always grateful to discover that a piece of WordPress functionality, whether core or in an extension, makes proper use of hooks so that its functionality can be changed, extended,
or disabled. One of the single best things about the WordPress open-source ecosystem is that you almost never have to edit somebody else’s code (and remember to re-edit it
every time you install an update).





{kind=link}