tl;dr? Just want instructions on how to solve Jigidi puzzles really fast with the help of your browser’s dev tools? Skip to that bit.
This approach doesn’t work any more. Want to see one that still does (but isn’t quite so automated)? Here you go!
I don’t enjoy jigsaw puzzles
I enjoy geocaching. I don’t enjoy jigsaw puzzles. So mystery caches that require you to solve an online jigsaw puzzle in order to get the coordinates really don’t do it for me. When I’m geocaching I want to be outdoors exploring, not sitting at my computer gradually dragging pixels around!

Many of these mystery caches use Jigidi to host these jigsaw puzzles. An earlier version of Jigidi was auto-solvable with a userscript, but the service has continued to be developed and evolve and the current version works quite hard to make it hard for simple scripts to solve. For example, it uses a WebSocket connection to telegraph back to the server how pieces are moved around and connected to one another and the server only releases the secret “you’ve solved it” message after it detects that the pieces have been arranged in the appropriate relative configuration.
If there’s one thing I enjoy more than jigsaw puzzles – and as previously established there are about a billion things I enjoy more than jigsaw puzzles – it’s reverse-engineering a computer system to exploit its weaknesses. So I took a dive into Jigidi’s client-side source code. Here’s what it does:
- Get from the server the completed image and the dimensions (number of pieces).
- Cut the image up into the appropriate number of pieces.
- Shuffle the pieces.
- Establish a WebSocket connection to keep the server up-to-date with the relative position of the pieces.
- Start the game: the player can drag-and-drop pieces and if two adjacent pieces can be connected they lock together. Both pieces have to be mostly-visible (not buried under other pieces), presumably to prevent players from just making a stack and then holding a piece against each edge of it to “fish” for its adjacent partners.
Looking at that process, there’s an obvious weak point – the shuffling (point 3) happens client-side, and before the WebSocket sync begins. We could override the shuffling function to lay the pieces out in a grid, but we’d still have to click each of them in turn to trigger the connection. Or we could skip the shuffling entirely and just leave the pieces in their default positions.

And what are the default positions? It’s a stack with the bottom-right jigsaw piece on the top, the piece to the left of it below it, then the piece to the left of that and son on through the first row… then the rightmost piece from the second-to-bottom row, then the piece to the left of that, and so on.
That’s… a pretty convenient order if you want to solve a jigsaw. All you have to do is drag the top piece to the right to join it to the piece below that. Then move those two to the right to join to the piece below them. And so on through the bottom row before moving back – like a typewriter’s carriage return – to collect the second-to-bottom row and so on.
How can I do this?
If you’d like to cheat at Jigidi jigsaws, this approach works as of the time of writing. I used Firefox, but the same basic approach should work with virtually any modern desktop web browser.
- Go to a Jigidi jigsaw in your web browser.
- Pop up your browser’s developer tools (F12, usually) and switch to the Debugger tab. Open the file
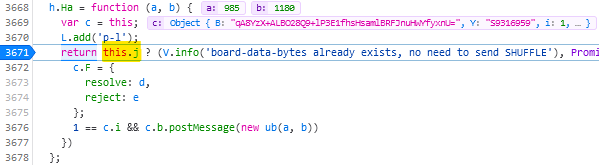
game/js/release.jsand uncompress it by pressing the {} button, if necessary. - Find the line where the code considers shuffling; right now for me it’s like 3671 and looks like this:
return this.j ? (V.info('board-data-bytes already exists, no need to send SHUFFLE'), Promise.resolve(this.j)) : new Promise(function (d, e) {
I spent some time tracing call stacks to find this line… only to discover that it’s one of only four lines to actually contain the word “shuffle” and I could have just searched for it… - Set a breakpoint on that line by clicking its line number.
- Restart the puzzle by clicking the restart button to the right of the timer. The puzzle will reload but then stop with a “Paused on breakpoint” message. At this point the
application is considering whether or not to shuffle the pieces, which normally depends on whether you’ve started the puzzle for the first time or you’re continuing a saved puzzle from
where you left off.

- In the developer tools, switch to the Console tab.
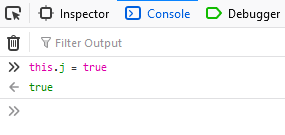
- Type:
this.j = true(this ensures that the ternary operation we set the breakpoint on will resolve to the true condition, i.e. not shuffle the pieces).
- Press the play button to continue running the code from the breakpoint. You can now close the developer tools if you like.
- Solve the puzzle as described/shown above, by moving the top piece on the stack slightly to the right, repeatedly, and then down and left at the end of each full row.
Update 2021-09-22: Abraxas observes that Jigidi have changed
their code, possibly in response to this shortcut. Unfortunately for them, while they continue to perform shuffling on the client-side they’ll always be vulnerable to this kind of
simple exploit. Their new code seems to be named not release.js but given a version number; right now it’s 14.3.1977. You can still expand it in the same way,
and find the shuffling code: right now for me this starts on line 1129:

Put a breakpoint on line 1129. This code gets called twice, so the first time the breakpoint gets hit just hit continue and play on until the second time. The second time it gets hit,
move the breakpoint to line 1130 and press continue. Then use the console to enter the code d = a.G and continue. Only one piece of jigsaw will be shuffled; the rest will
be arranged in a neat stack like before (I’m sure you can work out where the one piece goes when you get to it).
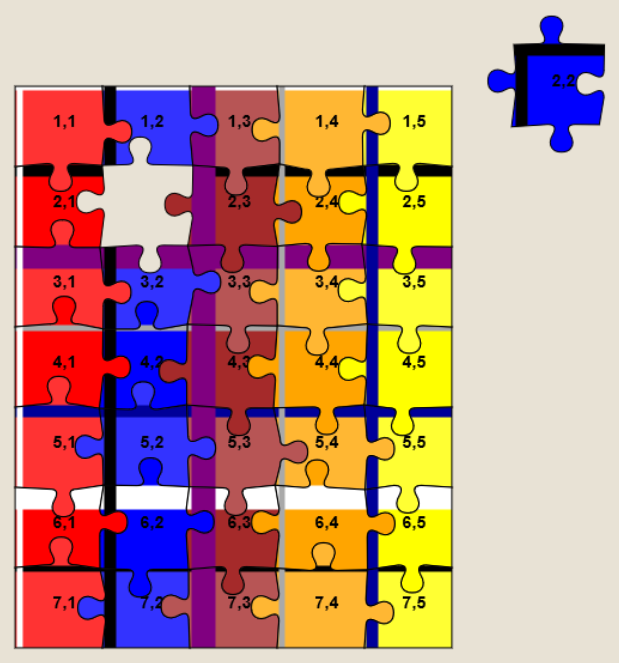
Update 2023-03-09: I’ve not had time nor inclination to re-“break” Jigidi’s shuffler, but on the rare ocassions I’ve needed to solve a Jigidi, I’ve come up with a technique that replaces a jigsaw’s pieces with ones that each show the row and column number they belong to, as well as colour-coding the rows and columns and drawing horizontal and vertical bars to help visual alignment. It makes the process significantly less-painful. It’s still pretty buggy code though and I end up tweaking it each and every time I use it, but it certainly works and makes jigsaws that lack clear visual markers (e.g. large areas the same colour) a lot easier.