theimprobable.blog, which I look after on behalf of my partner’s brother after using it to GPS-track his adventures
I think that’s all of them, but it’s hard to be sure…
Footnotes
1 Maybe I’ve finally shaken off my habit of buying a domain name for everything.
Or maybe it’s just that I’ve embraced subdomains for more stuff. Probably the latter.
After brunch, I reckon I can get to and from this hashpoint… Tron-style!
Expedition
I planned a slightly circuitous route to this hashpoint in order to make a Tron achievement possible. I got my bike lightcycle out of
the garage, checked the brakes and tyres, and set off in the opposite direction of the hashpoint! My thinking was I could cut up Tar Lakes Road to Cogges Farm, join the A40 cyclepath at
Witney, follow it all the way to Barnard Gate, and – after passing through the hamlet and hopefully the hashpoint – turn _back_ along the opposite side of A40 (for the section that
doesn’t have a cyclepath) and then cut through South Leigh to get back home.
My first hazard came just three minutes out of my door, where a motorist failed to give way to me at Stanton Harcourt Roundabout, entering the junction even though I was already
half-way across it from the other direction. They had to slam on their brakes to avoid smashing into the side of me, and I’ll admit I may have sworn at them at least a little as they
pulled guiltily away.
The Tar Lakes road remains a delightful route from Stanton Harcourt to Witney, which I’ve enjoyed cycling many times. It was a little busier than usual, perhaps because it’s Sunday and
folks were off to and from the fishing lakes along its path to do some angling or to walk their dogs, but it was still a fast and easy journey. Reaching Cogges, I turned back towards
the hashpoint and joined the A40 cyclepath which, I hoped, would bring me right through it.
Approaching the hashpoint, I was concerned to see that the road was closed ahead, but a sign reassured me that it was still open to pedestrians, so I dismounted my bike. This also
provided an excuse for me to slow down and pay attention to my GPSr as I counted down the metres. I got within the circle of uncertainty at ~3m away, as I leaned over the dyke that
separates Pear Tree Cottage’s garden from the byway.
I snapped the regulation silly grin selfie at 14:44.
Photo taken, I then had to continue to push my bike all the way through the roadworks: the fastest way home would have been to turn around, at this point, but I didn’t want to be robbed
of my shot at the Tron achievement, so I pressed on.
At the far end of Barnard Gate I determined that cycling back along the A40 without the benefit of a cyclepath was perhaps a little too dangerous (especially after my scare earlier), so
I adapted my route to instead head East towards Eynsham, crossing the main road at the Evenlode pub to get onto Old Witney Road, through Eynsham, and back onto the road home.
Returning home, I made sure to cut the corner short as I turned into my driveway so I didn’t cross the path I’d taken as I’d initially exited, an hour earlier. A successful trip, and a
fresh achievement!
Setting up and debugging your FreshRSS XPath Scraper
Okay, so here’s Adam’s blog. I’ve checked, and there’s no RSS feed1, so it’s time to start planning my XPath Scraper. The first thing I want to do is to find some way of identifying the “posts” on the page. Sometimes people use
solid, logical id="..." and class="..." attributes, but I’m going to need to use my browser’s “Inspect Element” tool to check:
If you’re really lucky, the site you’re scraping uses an established microformat like h-feed. No such luck here, though…
The next thing that’s worth checking is that the content you’re inspecting is delivered with the page, and not loaded later using JavaScript. FreshRSS’s XPath Scraper works with the raw
HTML/XML that’s delivered to it; it doesn’t execute any JavaScript2,
so I use “View Source” and quickly search to see that the content I’m looking for is there, too.
New developers are sometimes surprised to see how different View Source and Inspect Element’s output can be3.
This looks pretty promising, though.
Now it’s time to try and write some XPath queries. Luckily, your browser is here to help! If you pop up your debug console, you’ll discover that you’re probably got a predefined
function, $x(...), to which you can path a string containing an XPath query and get back a NodeList of the element.
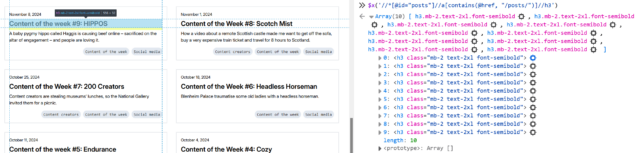
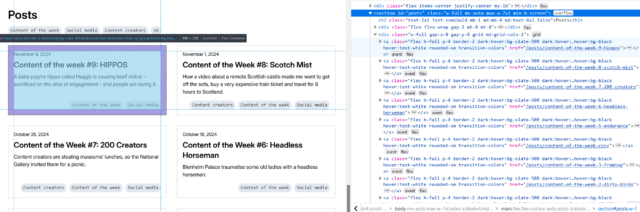
First, I’ll try getting all of the links inside the #posts section by running $x( '//*[@id="posts"]//a' ) –
Once you’ve run a query, you can expand the resulting array and hover over any element in it to see it highlighted on the page. This can be used to help check that you’ve found what
you’re looking for (and nothing else).
In my first attempt, I discovered that I got not only all the posts… but also the “tags” at the top. That’s no good. Inspecting the URLs of each, I noticed that the post URLs all
contained /posts/, so I filtered my query down to $x( '//*[@id="posts"]//a[contains(@href, "/posts/")]' ) which gave me the
expected number of results. That gives me //*[@id="posts"]//a[contains(@href, "/posts/")]
as the XPath query for “news items”:
I like to add the rules I’ve learned to my FreshRSS configuration as I go along, to remind me what I still need to find.
Obviously, this link points to the full post, so that tells me I can put ./@href as the “item link” attribute in FreshRSS.
Next, it’s time to see what other metadata I can extract from each post to help FreshRSS along:
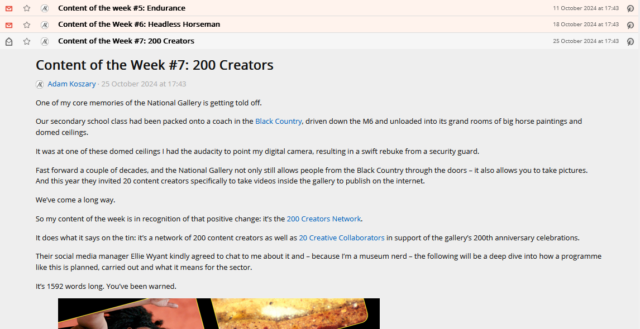
Inspecting the post titles shows that they’re <h3>s. Running $x( '//*[@id="posts"]//a[contains(@href, "/posts/")]//h3' ) gets them.
Within FreshRSS, everything “within” a post is referenced relative to the post, so I convert this to descendant::h3 for my “XPath (relative to item) for Item
Title:” attribute.
I was pleased to see that Adam’s using a good accessible heading cascade. This also makes my XPathing easier!
Inspecting within the post summary content, it’s… not great for scraping. The elements class names don’t correspond to what the content is4: it looks like Adam’s using a utility class library5.
Everything within the <a> that we’ve found is wrapped in a <div class="flex-grow">. But within that, I can see that the date is
directly inside a <p>, whereas the summary content is inside a <p>within a<div class="mb-2">. I don’t want my code to
be too fragile, and I think it’s more-likely that Adam will change the class names than the structure, so I’ll tie my queries to the structure. That gives me
descendant::div/p for the date and descendant::div/div/p for the “content”. All that remains is to tell FreshRSS that Adam’s using F j, Y as his
date format (long month name, space, short day number, comma, space, long year number) so it knows how to parse those dates, and the feed’s good.
If it’s wrong and I need to change anything in FreshRSS, the “Reload Articles” button can be used to force it to re-load the most-recent X posts. Useful if you need to tweak things. In
my case, I’ve also set the “Article CSS selector on original website” field to article so that the full post text can be pulled into my reader rather than having to visit
the actual site. Then I’m done!
Yet another blog I can read entirely from my feed reader, despite the fact that it doesn’t offer a “feed”.
Takeaways
Use Inspect Element to find the elements you want to scrape for.
Use $x( ... ) to test your XPath expressions.
Remember that most of FreshRSS’s fields ask for expressions relative to the news item and adapt accordingly.
If you make a mistake, use “Reload Articles” to pull them again.
2 If you need a scraper than executes JavaScript, you need something more-sophisticated. I
used to use my very own RSSey for this purpose but nowadays XPath Scraping is sufficient so I don’t bother any more, but RSSey might be a
good starting point for you if you really need that kind of power!
3 If you’ve not had the chance to think about it before: View Source shows you the actual
HTML code that was delivered from the web server to your browser. This then gets interpreted by the browser to generate the DOM, which might result in changes to it: for example,
invalid elements might be removed, ambiguous markup will have an interpretation applied, and so on. The DOM might further change as a result of JavaScript code, browser plugins, and
whatever else. When you Inspect Element, you’re looking at the DOM (represented “as if” it were HTML), not the actual underlying HTML
4 The date isn’t in a <time> element nor does it have a class like
.post--date or similar.
5 I’ll spare you my thoughts on utility class libraries for now, but they’re… not
positive. I can see why people use them, and I’ve even used them myself before… but I don’t think they’re a good thing.
After a morning of optimising a nonprofit’s reverse proxy configuration, I feel like I’ve earned my lunch! Four cheese, mushroom and jalapeño quesapizzas, mmm…
The feature here is that you can take a color you already have and manipulate its components. Which things you can change vary by the color space you choose, so for an RGB color you
can change the red, green, blue, and alpha channels, for an HSL color you can change hue, saturation, lightness, and alpha, and for
my belovedOKLCH you can change lightness, chroma, hue, and yes, opacity.
The syntax if you wanted to use this and not change anything about the color is:
oklch(fromvar(--color)lch/1)
But of course you can change each component, either swapping them entirely as with this which sets the lightness to 20%:
oklch(fromvar(--color)20%ch/1)
…
This is really something. I was aware that new colour functions were coming to CSS but kinda dropped the ball and didn’t notice that oklch(...) is, for the most
part, usable in any modern browser. That’s a huge deal!
The OKLCH colour model makes more sense than RGB, covers a wider spectrum than HSL, and – on screens that support it – describes a (much) larger spectrum, providing access to a wider
array of colours (with sensible fallbacks where they’re not supported). But more than that, the oklch(...) function provides good colour adaptation.
If you’ve ever used e.g. Sass’s darken(...) function and been disappointed when it seems to have a bigger impact on some colours than others… that’s because simple
mathematical colour models don’t accurately reflect the complexities of human vision: some colours just look brighter, to us, thanks quirks of biochemistry, psychology, and
evolution!
This colour vision curve feels to me a little like how pianos aren’t always tuned to equal-temper – i.e. how the maths of harmonics says that should be – but are instead tuned
so that the lowest notes are tuned slightly flat and the highest notes slightly sharp to compensate for
inharmonicity resulting from the varying stiffness of the strings. This means that their taut length alone doesn’t dictate what note humans think they hear: my understanding is
that at these extremes, the difference in the way the wave propagates within the string results in an inharmonic overtone that makes these notes sound out-of-tune with the rest
of the instrument unless compensated for with careful off-tuning! Humans experience something other than what the simple maths predicts, and so we compensate for it! (The quirk isn’t
unique to the piano, but it’s most-obvious in plucked or struck strings, rather than in bowed strings, and for instruments with a wide range, of which a piano is of course both!)
OKLCH is like that. And with it as a model (and a quick calc(...) function), you can tell your
CSS “make this colour 20% lighter” and get something that, for most humans, will actually look “20% lighter”, regardless of the initial hue. That’s cool.
I spent way too long playing with this colour picker while I understood this concept. And now I want to use it
everywhere!
The first weekend of my sabbatical might have set the tone for a lot of the charity hacking that will follow, being dominated by a Three Rings volunteering weekend.
The first fortnight of my sabbatical has consisted of:
Three Rings CIC’s AGM weekend and lots of planning for the future of the organisation and how we make it a better place to volunteer, and better value for our charity users,
You’d be amazed how many churros these children can put away.
The trip to Spain followed a model for European family breaks that we first tried in Paris last year2,
but was extended to give us a feel for more of the region than a simple city break would. Ultimately, we ended up in three separate locations:
The PortAventura World theme park, whose accommodation was certainly a gear shift after the 5-star hotel we’d come from4 but whose rides kept us and the kids delighted for a
couple of days (Shambhala was a particular hit with the eldest kid and me).
A villa in el Vilosell – a village of only 190 people – at which the kids mostly played in the outdoor pool (despite the
sometimes pouring rain) but we did get the chance to explore the local area a little. Also, of course, some geocaching: some local caches are 1-2 years old and yet had so few finds that
I was able to be only the tenth or even just the third person to sign the logbooks!
I’d known – planned – that my sabbatical would involve a little travel. But it wasn’t until we began to approach the end of this holiday that I noticed a difference that a holiday
on sabbatical introduces, compared to any other holiday I’ve taken during my adult life…
Perhaps because of the roles I’ve been appointed to – or maybe as a result of my personality – I’ve typically found that my enjoyment of the last day or two of a week-long trip are
marred somewhat by intrusive thoughts of the work week to follow.
I’m not saying that I didn’t write code while on holiday. I totally did, and I open-sourced it too.
But programming feels different when your paycheque doesn’t depend on it.
If I’m back to my normal day job on Monday, then by Saturday I’m already thinking about what I’ll need to be working on (in my case, it’s usually whatever I left unfinished right before
I left), contemplating logging-in to work to check my email or Slack, and so on5.
But this weekend, that wasn’t even an option. I’ve consciously and deliberately cut myself off from my usual channels of work communication, and I’ve been very disciplined about not
turning any of them back on. And even if I did… my team aren’t expecting me to sign into work for about another 11 weeks anyway!
🤯🤯🤯
Monday and Tuesday are going to mostly be split between looking after the children, and voluntary work for Three Rings (gotta fix that new server architecture!). Probably. Wednesday?
Who knows.
That’s my first taste of the magic of a sabbatical, I think. The observation that it’s possible to unplug from my work life and, y’know, not start thinking about it right away
again.
Maybe I can use this as a vehicle to a more healthy work/life balance next year.
Footnotes
1A sabbatical is a perk offered to
Automatticians giving them three months off (with full pay and benefits) after each five years of work. Mine coincidentally came hot on the tail of my last meetup and soon after a whole lot of drama and a major
shake-up, so it was a very welcome time to take a break… although of course it’s been impossible to completely detach from bits of the drama that have spilled out onto the open
Web!
5 I’m fully aware that this is a symptom of poor work/life balance, but I’ve got two
decades of ingrained bad habits working against me now; don’t expect me to change overnight!
If you’ve come across Tony Domenico’s work before it’s probably as a result of web horror video series Petscop.
3D Workers Island… isn’t quite like that (though quick content warning: it does vaugely allude to child domestic
abuse). It’s got that kind of alternative history/”found footage webpage” feel to it that I enjoyed so much about the Basilisk
collection. It’s beautifully and carefully made in a way that brings its world to life, and while I found the overall story slightly… incomplete?… I enjoyed the application of
its medium enough to make up for it.
Best on desktop, but tolerable on a large mobile in landscape mode. Click each “screenshot” to advance.
Any system where users can leave without pain is a system whose owners have high switching costs and whose users have none. An owner who makes a bad call – like
removing the block function say, or opting every user into AI training – will lose a lot of users. Not just those users who price these downgrades highly enough that they
outweigh the costs of leaving the service. If leaving the service is free, then tormenting your users in this way will visit in swift and devastating pain upon you.
…
There’s a name for this dynamic, from the world of behavioral economics. It’s called a “Ulysses Pact.” It’s named for the ancient hacker Ulysses, who ignored the normal protocol for
sailing through the sirens’ sea. While normie sailors resisted the sirens’ song by filling their ears with wax, Ulysses instead had himself lashed to the mast, so that he could hear
the sirens’ song, but could not be tempted into leaping into the sea, to be drowned by the sirens.
Whenever you take a measure during a moment of strength that guards against your own future self’s weakness, you enter into a Ulysses Pact – think throwing away the Oreos when you
start your diet.
…
Wise words from Cory about why he isn’t on Bluesky, which somewhat echo my own experience. If you’ve had the experience in recent memory of abandoning an enshittified Twitter (and if
you didn’t yet… why the fuck not?), TikTok, or let’s face it Reddit… and you’ve looked instead to services like Bluesky or arguably Threads… then you haven’t learned your lesson at all.
Freedom to exit is fundamental, and I’m a big fan of systems with a built-in Ulysses Pact. In non-social or unidirectionally-social software it’s sufficient for the tools to be open
source: this allows me to host a copy myself if a hosted version falls to enshittification. But for bidirectional social networks, it’s also necessary for them to be federated,
so that I’m not disadvantaged by choosing to drop any particular provider in favour of another or my own.
Bluesky keeps promising a proper federation model, but it’s not there yet. And I’m steering clear until it is.
I suppose I also enjoyed this post of Cory’s because it helped remind me of where I myself am failing to apply the Ulysses Pact. Right now, Three Rings is highly-centralised, and while I and everybody else involved with it know our exit strategy should the project have to fold (open
source it, help charities migrate to their own instances, etc.) right now that plan is less “tie ourselves to the mast” than it is “trust one another to grab us if we go chasing
sirens”. We probably ought to fix that.
My family and I are staying in El Vilosell, so this morning I borrowed a bike to take the trail over the hill from there to here. The ride was beautiful, and the easy downhill rides
between cliffs and terraces more than made up for the tiring and bumpy sections of uphill pedalling. At the highest point, I met a fox, on his way to bed I guess as the sun crested the
hilltops.
Despite the recent heavy rain the Set riverbed was almost dry: just a trickle of a stream. From the description, I was initially worried that the cache might be underneath, which looked
challenging, but a peep at the hint reassured me that there were more-likely hiding spots.
A little finger-work and the cache was in hand. Nice spot! That’s when I discovered that there was a hole in my pocket and my pen had escaped! Oh no! I hope a photolog will be
sufficient to show that I found this cache.











![A browser's debug console executes $x('//*[@id="posts"]//a') , and gets 14 results.](/_q23u/2024/11/adam-k-xpath-1-640x188.png)