There’s a perception that a blog is a long-lived, ongoing thing. That it lives with and alongside its author.1
But that doesn’t have to be true, and I think a lot of people could benefit from “short-term” blogging. Consider:
Photoblogging your holiday, rather than posting snaps to social media
You gain the ability to add context, crosslinking, and have permanent addresses (rather than losing eveything to the depths of a feed). You can crosspost/syndicate to your favourite
socials if that’s your poison..
Photoblog your holiday and I might follow it, and I’ll do so at my convenience. Put your snaps on Facebook and I almost certainly won’t bother. Photo courtesy ArtHouse Studio.
Blogging your studies, rather than keeping your notes to yourself
Writing what you learn helps you remember it; writing what you learn in a public space helps others learn too and makes it easy to search for your discoveries later.2
Recording your roleplaying, rather than just summarising each session to your fellow players
My D&D group does this at levellers.blog! That site won’t continue to be updated forever – the party will someday retire or, more-likely, come to a
glorious but horrific end – but it’ll always live on as a reminder of what we achieved.
One of my favourite examples of such a blog was 52 Reflect3 (now integrated into its successor The Improbable Blog). For 52 consecutive weeks my partner‘s brother Robin
blogged about adventures that took him out of his home in London and it was amazing. The project’s finished, but a blog was absolutely the right medium for it because now it’s got a
“forever home” on the Web (imagine if he’d posted instead to Twitter, only for that platform to turn into a flaming turd).
I don’t often shill for my employer, but I genuinely believe that the free tier on WordPress.com is an excellent
way to give a forever home to your short-term blog4.
Did you know that you can type new.blog (or blog.new; both work!) into your browser to start one?
What are you going to write about?
Footnotes
1This blog is, of course, an example of a long-term blog. It’s been going in
some form or another for over half my life, and I don’t see that changing. But it’s not the only kind of blog.
2 Personally, I really love the serendipity of asking a web search engine for the solution
to a problem and finding a result that turns out to be something that I myself wrote, long ago!
4 One of my favourite features of WordPress.com is the fact that it’s built atop the
world’s most-popular blogging software and you can export all your data at any time, so there’s absolutely no lock-in: if you want to migrate to a competitor or even host your own
blog, it’s really easy to do so!
Of all of the videogames I’ve ever played, perhaps the one that’s had the biggest impact on my life1
was: Werewolves and (the) Wanderer.2
This simple text-based adventure was originally written by Tim Hartnell for use in his 1983 book Creating Adventure Games on your Computer. At the time, it
was common for computing books and magazines to come with printed copies of program source code which you’d need to re-type on your own computer, printing being significantly many
orders of magnitude cheaper than computer media.3
Werewolves and Wanderer was adapted for the Amstrad CPC4 by Martin Fairbanks and published in The Amazing Amstrad Omnibus (1985),
which is where I first discovered it.
When I first came across the source code to Werewolves, I’d already begun my journey into computer programming. This started alongside my mother and later – when her
quantity of free time was not able to keep up with my level of enthusiasm – by myself.
I’d been working my way through the operating manual for our microcomputer, trying to understand it all.5
The ring-bound 445-page A4
doorstep of a book quickly became adorned with my pencilled-in notes, the way a microcomputer manual ought to be. It’s strange to recall that there was a time that
beginner programmers still needed to be reminded to press [ENTER] at the end of each line.
And even though I’d typed-in dozens of programs before, both larger and smaller, it was Werewolves that finally helped so many key concepts “click” for me.
In particular, I found myself comparing Werewolves to my first attempt at a text-based adventure. Using what little I’d grokked of programming so far, I’d put together
a series of passages (blocks of PRINT statements6)
with choices (INPUT statements) that sent the player elsewhere in the story (using, of course, the long-considered-harmfulGOTO statement), Choose-Your-Own-Adventure
style.
Werewolves was… better.
By the time I was the model of a teenage hacker, I’d been writing software for years. Most of it terrible.
Werewolves and Wanderer was my first lesson in how to structure a program.
Let’s take a look at a couple of segments of code that help illustrate what I mean (here’s the full code, if you’re interested):
10REM WEREWOLVES AND WANDERER
20GOSUB2600:REM INTIALISE30GOSUB16040IF RO<>11THEN30
50 PEN 1:SOUND 5,100:PRINT:PRINT"YOU'VE DONE IT!!!":GOSUB3520:SOUND 5,80:PRINT"THAT WAS THE EXIT FROM THE CASTLE!":SOUND 5,20060GOSUB352070PRINT:PRINT"YOU HAVE SUCCEEDED, ";N$;"!":SOUND 5,10080PRINT:PRINT"YOU MANAGED TO GET OUT OF THE CASTLE"90GOSUB3520100PRINT:PRINT"WELL DONE!"110GOSUB3520:SOUND 5,80120PRINT:PRINT"YOUR SCORE IS";
130PRINT3*TALLY+5*STRENGTH+2*WEALTH+FOOD+30*MK:FOR J=1TO10:SOUND 5,RND*100+10:NEXT J
140PRINT:PRINT:PRINT:END...2600REM INTIALISE2610 MODE 1:BORDER 1:INK 0,1:INK 1,24:INK 2,26:INK 3,18:PAPER 0:PEN 22620 RANDOMIZE TIME
2630 WEALTH=75:FOOD=02640 STRENGTH=1002650 TALLY=02660 MK=0:REM NO. OF MONSTERS KILLED...3510REM DELAY LOOP3520FOR T=1TO900:NEXT T
3530RETURN
Locomotive BASIC had mandatory line numbering. The spacing and gaps (...) have been added for readability/your convenience.
What’s interesting about the code above? Well…
The code for “what to do when you win the game” is very near the top. “Winning” is the default state. The rest of the adventure exists to obstruct that. In a
language with enforced line numbering and no screen editor7,
it makes sense to put fixed-length code at the top… saving space for the adventure to grow below.
Two subroutines are called (the GOSUB statements):
The first sets up the game state: initialising the screen (2610), the RNG (2620), and player
characteristics (2630 – 2660). This also makes it easy to call it again (e.g. if the player is given the option to “start over”). This subroutine
goes on to set up the adventure map (more on that later).
The second starts on line 160: this is the “main game” logic. After it runs, each time, line 40 checks IF RO<>11 THEN 30. This tests
whether the player’s location (RO) is room 11: if so, they’ve exited the castle and won the adventure. Otherwise, flow returns to line 30 and the “main
game” subroutine happens again. This broken-out loop improving the readability and maintainability of the code.8
A common subroutine is the “delay loop” (line 3520). It just counts to 900! On a known (slow) processor of fixed speed, this is a simpler way to put a delay in than
relying on a real-time clock.
The game setup gets more interesting still when it comes to setting up the adventure map. Here’s how it looks:
Again, I’ve tweaked this code to improve readability, including adding indention on the loops, “modern-style”, and spacing to make the DATA statements form a “table”.
What’s this code doing?
Line 2690 defines an array (DIM) with two dimensions9
(19 by 7). This will store room data, an approach that allows code to be shared between all rooms: much cleaner than my first attempt at an adventure with each room
having its own INPUT handler.
The two-level loop on lines 2700 through 2730 populates the room data from the DATA blocks. Nowadays you’d probably put that data in a
separate file (probably JSON!). Each “row” represents a room, 1 to 19. Each “column” represents the room you end up
at if you travel in a given direction: North, South, East, West, Up, or Down. The seventh column – always zero – represents whether a monster (negative number) or treasure
(positive number) is found in that room. This column perhaps needn’t have been included: I imagine it’s a holdover from some previous version in which the locations of some or all of
the treasures or monsters were hard-coded.
The loop beginning on line 2850 selects seven rooms and adds a random amount of treasure to each. The loop beginning on line 2920 places each of six
monsters (numbered -1 through -6) in randomly-selected rooms. In both cases, the start and finish rooms, and any room with a treasure or monster, is
ineligible. When my 8-year-old self finally deciphered what was going on I was awestruck at this simple approach to making the game dynamic.
Rooms 4 and 16 always receive treasure (lines 2970 – 2980), replacing any treasure or monster already there: the Private Meeting Room (always
worth a diversion!) and the Treasury, respectively.
Curiously, room 9 (the lift) defines three exits, even though it’s impossible to take an action in this location: the player teleports to room 10 on arrival! Again, I assume this is
vestigal code from an earlier implementation.
The “checksum” that’s tested on line 2740 is cute, and a younger me appreciated deciphering it. I’m not convinced it’s necessary (it sums all of the values in
the DATA statements and expects 355 to limit tampering) though, or even useful: it certainly makes it harder to modify the rooms, which may undermine
the code’s value as a teaching aid!
By the time I was 10, I knew this map so well that I could draw it perfectly from memory. I almost managed the same today, aged 42. That memory’s buried deep!
Something you might notice is missing is the room descriptions. Arrays in this language are strictly typed: this array can only contain integers and not strings. But there are
other reasons: line length limitations would have required trimming some of the longer descriptions. Also, many rooms have dynamic content, usually based on random numbers, which would
be challenging to implement in this way.
As a child, I did once try to refactor the code so that an eighth column of data specified the line number to which control should pass to display the room description. That’s
a bit of a no-no from a “mixing data and logic” perspective, but a cool example of metaprogramming before I even knew it! This didn’t work, though: it turns out you can’t pass a
variable to a Locomotive BASIC GOTO or GOSUB. Boo!10
In hindsight, I could have tested the functionality before I refactored with a very simple program, but I was only around 10 or 11 and still had lots to learn!
Werewolves and Wanderer has many faults11.
But I’m clearly not the only developer whose early skills were honed and improved by this game, or who hold a special place in their heart for it. Just while writing this post, I
discovered:
Many, many people commenting on the above or elsewhere about how instrumental the game was in their programming journey, too.
A decade or so later, I’d be taking my first steps as a professional software engineer. A couple more decades later, I’m still doing it.
And perhaps that adventure -the one that’s occupied my entire adult life – was facilitated by this text-based one from the 1980s.
Footnotes
1 The game that had the biggest impact on my life, it might surprise you to hear, is
not among the “top ten videogames that stole
my life” that I wrote about almost exactly 16 years ago nor the follow-up list I published in its incomplete form three years
later. Turns out that time and impact are not interchangable. Who knew?
2 The game is variously known as Werewolves and Wanderer, Werewolves and
Wanderers, or Werewolves and the
Wanderer. Or, on any system I’ve been on, WERE.BAS, WEREWOLF.BAS, or WEREWOLV.BAS, thanks to the CPC’s eight-point-three filename limit.
3 Additionally, it was thought that having to undertake the (painstakingly tiresome)
process of manually re-entering the source code for a program might help teach you a little about the code and how it worked, although this depended very much on how readable the code
and its comments were. Tragically, the more comprehensible some code is, the more long-winded the re-entry process.
5 One of my favourite
features of home microcomputers was that seconds after you turned them on, you could start programming. Your prompt was an interface to a programming language. That magic
had begun to fade by the time DOS came to dominate (sure, you can program using batch files, but they’re
neither as elegant nor sophisticated as any BASIC dialect) and was completely lost by the era of booting directly into graphical operating systems. One of my favourite
features about the Web is that it gives you some of that magic back again: thanks to the debugger in a modern browser, you can “tinker” with other people’s code once more, right from
the same tool you load up every time. (Unfortunately, mobile devices – which have fast become the dominant way for people to use the Internet – have reversed this trend again. Try to
View Source on your mobile – if you don’t already know how, it’s not an easy job!)
6 In particular, one frustration I remember from my first text-based adventure was that
I’d been unable to work around Locomotive BASIC’s lack of string escape sequences – not that I yet knew what such a thing would be called – in order to put quote marks inside a quoted
string!
7 “Screen editors” is what we initially called what you’d nowadays call a “text editor”:
an application that lets you see a page of text at the same time, move your cursor about the place, and insert text wherever you feel like. It may also provide features like
copy/paste and optional overtyping. Screen editors require more resources (and aren’t suitable for use on a teleprinter) compared to line editors, which preceeded them. Line editors only let you view and edit a single line at a time, which is how most of my first 6
years of programming was done.
8 In a modern programming language, you might use while true or similar for a
main game loop, but this requires pushing the “outside” position to the stack… and early BASIC dialects often had strict (and small, by modern standards) limits on stack height that
would have made this a risk compared to simply calling a subroutine from one line and then jumping back to that line on the next.
9 A neat feature of Locomotive BASIC over many contemporary and older BASIC dialects was
its support for multidimensional arrays. A common feature in modern programming languages, this language feature used to be pretty rare, and programmers had to do bits of division and
modulus arithmetic to work around the limitation… which, I can promise you, becomes painful the first time you have to deal with an array of three or more dimensions!
10 In reality, this was rather unnecessary, because the ON x GOSUB command
can – and does, in this program – accept multiple jump points and selects the one referenced by the
variable x.
11 Aside from those mentioned already, other clear faults include: impenetrable
controls unless you’ve been given instuctions (although that was the way at the time); the shopkeeper will penalise you for trying to spend money you don’t have, except on food,
presumably as a result of programmer laziness; you can lose your flaming torch, but you can’t buy spares in advance (you can pay for more, and you lose the money, but you don’t get a
spare); some of the line spacing is sometimes a little wonky; combat’s a bit of a drag; lack of feedback to acknowledge the command you enterted and that it was successful; WHAT’S
WITH ALL THE CAPITALS; some rooms don’t adequately describe their exits; the map is a bit linear; etc.
The other night, Ruth and I were talking about collective nouns (y’know, like a herd of cows or a flock of sheep) and came
up with the somewhat batty idea of solitary nouns. Like collective nouns, but for a singular subject (one cow, sheep, or whatever).
Then, we tried to derive what the words could be. Some of the results write themselves.1
Mooving right on…
I’d be lion if I said I wasn’t proud of this one.
I’m pollen out all the collective nouns now!
Some of them involve removing one or more letters from the collective noun to invent a shorter word to be the solitary noun.
They stay healthy by working out and getting vaccinated, both of which give them tough anty bodies.
The sound of an oven is a cackling: “When shall I one meet again?”
Eventually it grows up into a star, which are a lot louder.2For others, we really had to stretch the concept by mutating words in ways that “felt right”, using phoenetic spellings, or even inventing collective nouns so that we
could singularise them:
For more goose-related wordplay, take a gander at this blog post from a few years back.
Getting smashed doesn’t have to end with bumps and boozers.3
Blast but not least.
Did I miss any obvious ones?
Footnotes
1 Also consider “parliament of owls” ➔ “politician of owl”, “troop of monkeys” ➔ “soldier
of monkey”, “band of gorillas” ➔ “musician of gorilla”. Hey… is that where that band‘s name come from?
2 Is “cluster of stars” ➔ “luster of star” anything?
3 Ruth enjoyed the singularised “a low of old bollock”, too.
At school, our 9-year-old is currently studying the hsitory of human civilization from the late stone age through to the bronze age. The other week, the class was split into three
groups, each of which was tasked with researching a different piece of megalithic architecture:
One group researched Stonehenge, because it’s a pretty obvious iconic choice
The final group took the least-famous monument, our very own local village henge The Devil’s Quoits
Love me some ancient monuments, even those that are perhaps less authentically-ancient than others.
And so it was that one of our eldest’s classmates was searching on the Web for information about The Devil’s Quoits when they found… my vlog on the subject! One of them recognised me and said, “Hey, isn’t that your Uncle Dan?”1
On the school run later in the day, the teacher grabbed me and asked if I’d be willing to join their school trip to the henge, seeing as I was a “local expert”. Naturally, I said yes,
went along, and told a bunch of kids
what I knew!
I’ve presented to much-larger audiences before on a whole variety of subjects, but this one still might have been the most terrifying.
I was slightly intimidated because the class teacher, Miss Hutchins,
is really good! Coupled with the fact that I don’t feel like a “local expert”2, this became a
kick-off topic for my most-recent coaching session (I’ve mentioned how awesome my coach is before).
I originally thought I might talk to the kids about the Bell Beaker culture people who are believed to have constructed the monument. But when I pitched the idea to our girl she
turned out to know about as much about them as I did, so I changed tack.
I eventually talked to the class mostly about the human geography aspects of the site’s story. The area around the Devil’s Quoits has changed so much over the millenia, and it’s a
fascinating storied history in which it’s been:
A prehistoric henge and a circle of 28 to 36 stones (plus at least one wooden building, at some point).
Medieval farms, from which most of the stones were taken (or broken up) and repurposed.
A brief (and, it turns out, incomplete) archeological survey on the remains of the henge and the handful of stones still-present.
Quarrying operations leaving a series of hollowed-out gravel pits.
More-thorough archeological excavation, backed by an understanding of the cropmarks visible from aircraft that indicate that many prehistoric people lived around this area.
Landfill use, filling in the former gravel pits (except for one, which is now a large lake).
Reconstruction of the site to a henge and stone circle again.3
It doesn’t matter to me that this henge is more a modern reconstruction than a preserved piece of prehistory. It’s still a great excuse to stop and learn about how our ancestors might
have lived.
It turns out that to be a good enough to pass as a “local expert”, you merely have to know enough. Enough to be able to uplift and inspire others, and the humility to know when
to say “I don’t know”.4
That’s a lesson I should take to heart. I (too) often step back from the opportunity to help others learn something new because I don’t feel like I’m that experienced at
whatever the subject is myself. But even if you’re still learning something, you can share what you’ve learned so far and help those behind you to follow the same path.
I’m forever learning new things, and I should try to be more-open to sharing “as I
learn”. And to admit where I’ve still got a long way to go.
Footnotes
1 Of course, I only made the vlog because I was doing a videography course at the time and
needed subject matter, and I’d recently been reading a lot about the Quoits because I was planning on “hiding” a virtual geocache at the site, and then I got carried away. Self-nerdsniped again!
2 What is a local expert? I don’t know, but what I feel like is just a guy who
read a couple of books because he got distracted while hiding a geocache!
3 I’ve no idea what future archeologists will make of this place when they finda
reconstructed stone circle and then, when they dig nearby, an enormous quantity of non-biodegradable waste. What was this strange stone circle for, they’ll ask themselves? Was it a
shrine to their potato-based gods, to whom they left crisp packets as a sacrifice?
4 When we’re talking about people from the neolithic, saying “I don’t know” is pretty
easy, because what we don’t know is quite a lot, it turns out!
I’ve long been a fan of Hugh Howey‘s Wool series of books (especially the first and third;
the second’s a bit weaker); in fact I’ve been enjoying re-reading them as a bedtime story for our eldest!1
Naturally, when I heard that it would become a TV series I was really excited! I’m enjoying
the series so far, especially thanks to its epic casting. It diverges a lot from the books –
sometimes in ways I love, sometimes in ways that confuse me – but that’s not what I wanted to talk about. I wanted to share how cool the opening credits sequence is!
Spoiler warning: even if you’re following the TV series there are likely to be major spoilers below based on my recollection of the books!
We open on the sun shining above a thick layer of all-obscuring clouds, tinted sickly yellow like poison gas, then descend into the darkness below. This hints at the uninhabitability of
the world above, foreshadows Lukas stargazing through gaps in the clouds2,
and foreshadows revelations about the argon gas used to flush the airlocks. The descent feels representative of humanity’s migration from the sunlit surface to the underground silos.
Looking down, we see the silo from above in a desolate landscape, introducing the world and its setting. The area around it is shrouded and hostile, reflecting the residents’ view of
the outside world as unsurvivable, but also masking our view of the other nearby silos that we might otherwise be able to see.
Descending “into” this representation of the silo, we get a view for only a split second that looks distinctly like the platter and spindle of a magnetic hard disk drive, broken-up as
if to represent corruption. This reflects a number of major plot points in the first season relating to the destruction and recovery of secret information from ancient storage devices.
Truly within the silo now, we see the spokes of landings radiating out from the great stairwell. The shape is reminiscient of a cog: a motif we’ll return to later. Humanoid shapes made
of light, like you get in a long exposure, move around, giving both the idea of a surveillance state, and setting us up to think of all such “glowing spots” as people (relevant later in
the credits).
A representation of the stairwell itself appears, with a lit gaseous substance whipping up and down it. Given that we’ve just been shown that this kind of “light” represents people,
it’s easy to see this as showing us the traffic that grinds up and down the silo, but it also feels like looking at part of a great machine, pumping gas through a condenser: notice that
there’s no landings any more: this is all about the never-ending traffic.
A landing appears, and the gaseous forms are now more-clearly humanoid, almost as if they’re ghosts (perhaps pointing to the number of generations who’ve lived before, in this place, or
else a reference to Juliette’s investigation into the lives of those who lived before her).
More swirling gas-people, this time below an empty balconette: perhaps a nod to the source of Juliette’s uncommon name (in the books, it’s taken from Romeo & Juliet, a
possibly-illicit copy of which is retained by the silo and performed prior to Juliette’s birth and for at least a short while afterwards: she writes mechanical notes on the back of a
playscript), or perhaps a reference to George’s death after “falling” from a balcony.
Seen from a different angle, the colour shifts, and the gas/ghosts become white like the argon spray of the airlock. The people are all part of a machine: a machine that sends people
outside to clean and die. But more than that, the blue comes to represent a clean/perfect view of what a silo can be: a blueprint representation of the goals of its creators to
shape the inhabitants into their vision of the future:
We refocus on the shape of the silo itself, but just for a split second the view looks more like an x-ray… of a human spine? As if to remind us that it’s people who upload the
system of the silo, just as its concrtete uploads its physical structure. Also a reminder that the silo is treated (by those who manage it, both within and beyond it) as an
organic thing that can be nurtured, grown, or if necessary killed.
This becomes the structure of the silo, but it almost looks architectural: a “clean” look, devoid of people or signs of life, like a blueprint, perhaps foreshadowing Donald’s role in
designing the structures that will eventually become the silos. The “space” between the arms is emphasised, showing how the social system that this structure imposes serves to separate
and segregate people: classism is a recurring theme in both the books and the TV series, and it eventually becomes apparent that the silos are specifically organised to reduce
communication between interdependent groups.
Returning to the “populated” silo – swirls of gas spiralling away down (or up: it’s no longer clear!), we catch a glimpse of a nautilus shell at the centre. The nautilus is a “living
fossil”, a creature from a bygone era that continues to survive in our modern world, which is an excellent metaphor for the population of the dead world who go on living beneath its
surface. The nautilus shell is a recurring image within the TV series: Gloria’s visions of the world that came before see her clutching one and tracing its shape, for example.
We cut to what appears to be a seed, representing both the eventual conclusion of the story (Juliette, Charlotte and the Silo 18 survivors’ discovery of the cache of supplies that will
allow them to begin rebuilding the world) and also the nature of the silo3. The seed we see initially
appears to fail and degrade, becoming nothing at all, before eventually growing into the beginnings of a strong new plant. This could represent the eventual and inevitable collapse of
silo 18, among others, but the eventual flourishing of those that survive, or on a broader scale the collapse of modern civilization to be replaced by the silos, or even of the silo
system to be replaced with that which follows it after the conclusion of the story. Lots of options!
It’s also possibly a reflection of the harsh and opaque eugenics/population control mechanism imposed by the “lottery”, which becomes a major plot point in the TV series much earlier
than in the books.
We cut to trees, thriving despite a yellow fog. The sky can’t be seen, which is a reminder that all of humanity’s resources must now be produced underground (trees are especially rare
and prized, leading to a shortage of paper4.
It seems to be deliberately left unclear whether the trees we see are on the surface before the fall of humanity, on the surface after the fall, or grown underground.
A fruit falls from the tree, which links back to the seed we saw geminate earlier but also seems likely to be a representation of the concept of original sin. The grand idea of the
silos was to create a better world on the other side of a man-made catastrophe, but this idea is inherently flawed because the systems that are constructed by the same people who are
complicit in the destruction of the world that came before. The structure that’s put in place through the Pact carries the weight of the sins of its creators: even though the
inhabitants of silo 1 ultimately intend to destroy themselves, they’re unable to create a new world that is both better than the one that came before and free from their
influence: it’s an impossibility.
It’s also possibly a representation of the religious beliefs of some inhabitants that the creators of the silo should be revered as gods. This was a recurring plot point in the books
but has been somewhat muted in the TV series so far.
The metaphor continues when we see that this falling fruit is already beginning to rot, degrading as it tumbles towards the earth. We don’t see it strike the ground: it almost seems to
hover in the air, uncertain and undecided, and reflective of the eventual end when the inhabitants of the silos break free from the shackles of the system that’s been constructed for
them and can choose their own destiny. Or perhaps we don’t see the collision simply because the camera continues to fall down into the earth and below the surface again?
This time, wer’e very deep: all the way down in the depths of Mechanical, at the bottom of the silo: home to our heroine and source of many aspects of the story. In the centre, a shaft
descends, connecting us back to the “spine” of the silo – the great staircase – but it’s harder to see as a wealth of machinery appears to support it, occluding our view. From down here
in Mechanical it appears that the machines keep the silo running, whereas further up it looked like humans pumped through it like blood, which reflects Juliette’s disagreements with
many of those up-top about their priorities during her time as Sheriff and, later, as Mayor.
We see a cloud of steam, like that used to drive the generator that brings life to the silo, and for a moment it’s impossible to differentiate it from the cloud of people we saw
earlier, rushing up and down the stairs. Look closely at the steam, though, and you’ll see that it too contains the ghosts of people.
Deeper still, the cog motif returns and we’re buried in an impossible number of interconnected gears. The machine that they support is impossible to comprehend from within: How big is
it? What is it for? Who made it and why?
The final cog mutates into the staircase again, winding away from us and hammering the point home.
The staircase changes again, first becoming an outline of itself (a callback to the “blueprint” design we saw earlier, reminding us that this thing was designed to be like
this)…
…but this becomes a double-helix, representing the chaos of life. Again, the metaphor is of a perfect idea constructed to achieve a goal, but the unpredictability of humans
leads to a different outcome.
Seen from above, the staircase now looks like an enormous clock, a machine of cogs each turning slower than the one beneath, counting down until the end of the silo experiment in
accordance with the whim of its creators. Except, of course, if something were to break this machine.
Seen from the side, the silo is a hive of activity, but the shape the levels form in this depiction are exactly like the rotors of a steam turbine, and this is reflected by an image of
steam, almost in the shape of a growing tree – passing behind it in the background. The generator and its rotor blades is a significant early plot point in both the books and the TV
series, and the books in particular use engine metaphors to explain Juliette’s interpretation of different situations she finds herself in, even those which are distinctly interpersonal
rather than mechanical.
Looking back up the silo, towards the light, we can now see its shape and structure for what it is: just another cog – a part of an even bigger machine that is the whole Operation Fifty
silo network. The people are the lifeblood of this machine, but they’re as replaceable and interchangable as any other part.
Finally, we crossfade to the title, looking like a stencil. Each letter is more-degraded than the one before it, representing the impossibility of building a perfect system.
The credits sequence is less than 90 seconds long, but so much is packed into it. It’s just great.
Footnotes
1 We’re into the final act of Dust now and it’s been amazing to experience the characters – loveable and hateable – of the series.
2 Curiously, in the TV series Lukas is only ever seen stargazing on clear nights, which is
one of those confusing choices I mentioned. I suspect it’s for aesthetic reasons and to help add some romance to Juliette and Lukas’s courtship.
3 A silo is, of course, a place to store something valuable through the hard times. This
is exactly what the silos in this story are for.
4 The shortage of paper shows up many times in the books but is somewhat glossed-over in
the TV series. I’m not sure how they’ll reconcile that with the impact of the discovery of the Legacy, later.
My second day of the main conference part of WordCamp Europe 2023 was hampered slightly by a late start on my part.
I can’t say for certain why I woke up mildly hungover and with sore knees, but I make an educated guess that it might be related to the Pride party I found myself at last night.
Still, I managed to get to all the things I’d earmarked for my attention, including:
I’m sure I can’t be the only person who’s been asked “why can’t the (or ‘shouldn’t the’) WordPress post editor let multiple people edit post at the same time”. Often, people
will compare it to e.g. Google Docs.
I can’t begin to speculate how often people must ask this supposedly-trivial question of Dawid Urbański, possibly the world’s expert on this
very question.
Dawid summarised the challenging issues in any effort to implement this much-desired feature. Some of them are examples of those unsolved problems that keep rearing their heads in
computer science, like the two generals’ problem, but even the solvable problems are difficult: How does one
handle asynchronous (non-idempotent) commutative operations? How is the order of disparate actions determined? Which node is the source of truth? If a server is used, where is that
server (with a nod to quite how awful the experience of implementing a Websockets server in PHP can be…)? And so on…
Slides showing simplified timelines of parties communicating with one another in ambigous ways
I really appreciated Dawid’s reference to the various bits of academic literature that’s appeared over the last four decades (!) about how these problems might be solved. It’s a strong
reminder that these things we take for granted in live-updating multi-user web applications are not trivial and every question you can answer raises more questions.
There’s some great early proof-of-concepts, so we’re “getting there”, and it’s an exciting time. Personally, I love the idea of the benefits this could provide for offline editing
(perhaps just because I’m still a huge fan of a well-made PWA!).
James Giroux’s goal: that we all become more curious about and more invested in our team’s experiences, from a humanistic standpoint. His experience of companies with organic growth of
software companies is very, very familiar: you make a thing and give it away, then you need more people, then you’ve somehow got a company and it’s all because you just had an idea
once. Sounds like Three Rings!
Financial success is not team success, as Twitter shows, with their current unsustainable and unhappy developer culture, James reminds us.
James was particularly keen to share with us the results of his Team Experience Index research, and I agree that some of the result are
especially exciting, in particularly the willingness of underrepresented groups, especially women, to enagage with the survey: this provides hugely valuable data about the health of
teams working in the WordPress space.
The statistician in me immediately wanted to know how the non-response rate to these (optional) questions varied relative to one another (if they’re very different, putting these pie
charts alongside one another could be disingenuous!), but I’m tentatively excited by the diversity represented anyway.
“We have this project that we work with and contribute to, that we love,” says James, in an attempt to explain the highly-positive feedback that his survey respondents gave when asked
questions about the authenticity of their purpose and satisfaction in their role.
Again, my inner statistician wants to chirp up about the lack of a control group. The data from the survey may well help companies working within the WordPress ecosystem to
identify things we’re doing well and opportunities for growth, but it’d also be cool to compare these metrics to those in companies outside of the WordPress world!
So, what do we do with these findings? How do WordPress-ey companies improve? James recommends that we:
Get better are showing what recognition, celebration, and career growth looks like,
Improve support and training for team leaders to provide them with the tools to succeed and inspire, and
Bridge the gap between leadership and team members with transparent, open dialogue.
Good tips, there.
The Big Photo
A WordCamp tradition is to try to squeeze every willing participant into a photo. Clearly with the size that these events are, nowadays, this requires some wrangling (and, in this case,
the photographers standing atop the roof of a nearby building to get everybody into frame).
Like herding cats, trying to get several hundred people to line up where you want them for a photograph is an exercise in patience.
I’ll have to keep an eye out for the final picture and see if I can find myself in it.
I always find that learning about bleeding edge CSS techniques makes me feel excited and optimistic, perhaps because
CSS lends itself so well towards a progressive enhancement approach to development: often, you can start using a new technique
today and it’ll only benefit, say, people using a beta version of a particular browser (and perhaps only if they opt-in to the applicable feature flag). But if you’ve designed
your site right then the lack of this feature won’t impact anybody else, and eventually the feature will (hopefully) trickle-down into almost everybody’s Web experience.
Anyway, that’s what Fellyph Cintra says too, but he adds that possibly we’ve still not grown out of thinking that browsers take a long
time between versions. 5 years passed between the release of Internet Explorer 6 and Internet Explorer 7, for example! But nowadays most browsers are evergreen with releases each
month! (Assuming we quietly ignore that Apple don’t sent new versions of Safari to old verisons of MacOS, continuing to exacerbate a problem that we used to see with Internet Explorer
on Windows, ahem.)
Fellyph told us about how he introduced <dialog> to his team and they responded with skepticism that they’d be able to use it within the next 5 years. But in fact
it’s already stable in every major browser.
An important new development may come from Baseline, a project to establish a metric of what you can reliably use on the Web today. So a
bit like Can I Use, I guess, but taken from the opposite direction: starting from the browsers and listing the features, rather than the other way
around.
Anyway, Fellyph went on to share some exciting new ideas that we should be using, like:
object-fit and object-position, which can make the contents of any container “act like” a background
aspect-ratio, which I’m already using and I love, but I enjoyed how Fellyph suggested combining the two to crop images to a fluid container on the client side
scroll-behavior: smooth, which I’ve used before; it’s pretty good
clamp, which I use… but I’m still not sure I fully grok it: I always have to load some documentation with examples when I use it
@container queries, which can apply e.g. (max-width: ...) rules to things other than the viewport, which I’ve not found a need for yet but I can see the
value of it
@layers, which grant an additional level of importance in the cascade: for example, you might load a framework into a layer (with @import url(...)
layer(framework)) which is defined as a lower-priority than your override layer, meaning you won’t have to start slapping !important all over the shop
@media (400px <= width <= 600px)-style media queries, which are much easier to understand than min-width: if you’re used to thinking in a
more-procedural programming language (I assume they work in container queries too!)
…
It’s also worth remembering:
@supports, which is badass and I love and use it already (it was especially useful as display: grid began to roll out and I wanted to start using it but
needed to use a fallback method for browsers that didn’t support it yet
:has(), which I’ve long thought is game-changing: styling something based on what it contains is magical; not really suitable for mainstream use yet without
Firefox support, though (it’s still behind a feature flag)! Fellyph sold me on the benefit of :not(:has(...)), though!
Nesting, which again doesn’t have Firefox support yet but provides SCSS-like nesting in CSS, which is awesome
Scroll-driven animations, which can e.g. do parallax effects without JavaScript (right now it’s Canary only, mind…), using e.g. animation-timeline: and
animation-range: to specify that it’s the scroll position within the document that provides the timeline for the animation
And keeping an eye on upcoming things like text-balanced (which I’m already excited by), popover, selectmenu, view transitions (which I’ve been
experimenting with because they’re cool), and scoped style.
For my second workshop, I joined Google’s Adam Silverstein to watch him dissect a few participants’ websites performance using Core Web
Vitals as a metric. I think I already know the basics of Core Web Vitals, but when it comes to improving my score (especially on work-related sites with
unpleasant reliance on heavyweight frameworks like React, in my experience).
In an early joke, Adam pointed out that you can reduce JavaScript thread blocking by removing JavaScript from your site. A lot of people laughed, but frankly I think it’s a great
idea.
We talked a lot about render blocking (thanks to JS and CSS in the
<head>), thread blocking (by scripts, especially those reacting to user input), TTFB (relating to actual network
and server performance, or at least server-side processing), TBT (the time between FCP and TTI), and the upcoming change to measure INP rather than FID. That’s a lot of acronyms.
The short of it is that there are three pillars to Core Web Vitals: loading (how long until the page renders), interactivity (how long until the page
responds to user interaction), and stability (how long it takes for the page to cease layout shifts as a result of post-load scripts and stylesheets). I was pleased
that Adam acknowledged the major limitation of lab testing resulting from developers often using superior hardware and Internet connections to typical users, and how if you’re
serious about performance metrics you’ll want to collect RUM data.
The fastest way to improve rendering performance is to put fewer obstacles in the way of rendering.
I came away with a few personalised tips, but they’re not much use for your site: I paid attention to the things that’ll be helpful for the sites I look after. But
I’ll be taking note of his test pages so I can play with some of the tools he demonstrated later on.
I couldn’t liveblog this because I spent too much of the session applauding. A few highlights from memory:
Phase 2 (of 4) of Gutenberg is basically complete, which is cool. Some back-and-forth about the importance of phase 4 (bringing better multilingual support to WordPress) and how it
feels like it’s a long way away.
In the same vein as his 2016 statement that WordPress developers should “learn JavaScript deeply”, Matt leant somewhat into the idea that from today they
should “watch AI carefully”; I’m not 100% convinced, but it’s not been stopping me from getting involved with a diversity of AI experiments (including some WordPress-related ones)
anyway.
Musings about our community being a major part of why WordPress succeeded (and continues to thrive) unlike some other open source projects of its era. I agree that’s a
factor, but I suspect that being in the right place at the right time was also important. Perhaps more on that another time.
Announcement of the next WordCamp Europe location.
This post is basically a live-blog of everything I got up to, and it’s mostly for my own benefit/notetaking. If you don’t read it, nobody will blame you.
Six minutes after workshop registration opened its queue snaked throughout an entire floor of the conference centre.
David Artiss took the courageous step of installing 36 popular plugins onto a fresh WordPress site and was, unsurprisingly, immediately bombarded by a
billion banners on his dashboard. Some were merely unhelpful (“don’t forget to add your API key”), others were annoying (“thanks for installing our plugin”), and plenty more were
commercial advertisements (“get the premium version”) despite the fact that WordPress.org guidelines recommend against this. It’s no surprise that this kind of “aggressive promotion” is
the single biggest annoyance that people reported when David asked around on social media.
Similarly, plugins which attempt to break the standard WordPress look-and-feel by e.g. hoisting themselves to the top of the menu, showing admin popovers, putting settings sections in
places other than the settings submenu, and so on are a huge annoyance to everybody. I get sufficiently frustrated by these common antifeatures of plugins I use that I actually maintain
a plugin for my own use that “fixes” the ones that aggrivate me the most!
David raised lots of other common gripes with WordPress plugins, too: data validation failures, leaving content behind after uninstallation (and “deactivation surveys”, ugh!), and a
failure to account for accessibility.
I’m unconvinced that we can rely on plugin developers to independently fix the kinds of problems that come high on David’s list. I wonder if there’s mileage in WordPress Core
reimplementing the way that the main navigation menu works such that all items in it can be (easily) re-arranged by users to their own preference? This would undermine the perceived
value to plugin developers of “hoisting” their own to the top by allowing users to counteract it, and would provide a valuable feature to allow site admins to streamline their workflow:
use WooCommerce but only in a way that’s secondary to your blog? Move “Products” below “Posts”! Etc.
Why yes, I’m liveblogging this. And yes, I’m not using Gutenberg yet (that’s a whole other story…)
Aaron Reimann from ClockworkWP gave us a tour of how WordPress has changed over the course of its 20-year history, starting even slightly
before I started using WordPress; my blog (previously powered by some hacky PHP, previouslier powered by some hackier Perl, previousliest written in static HTML) switched to WordPress
in 2004, when it hit version 1.2, so it was fun to get the opportunity to see some even older versions
illustrated.
A WordPress site from 2004 would, of course, still be perfectly usable today. How many JS-heavy/API-driven websites of today do you reckon will still function in 20 years time?
It was great to be reminded how far the Core code has come over that time. Early versions of WordPress – as was common among PHP applications at the time! – had very few files
and each could reliably be expected to be a stack of SQL, wrapped in a stack of code, wrapped in what’s otherwise a HTML file: no modularity!
Aaron’s passion for this kind of digital archaeology really shows. I dig it.
There were very few surprises for me in this talk, as you might expect for such an “old hand”, but I really enjoyed the nostalgia of exploring WordPress history through his eyes.
I enjoyed putting him on the spot with a “spicy” question at the end of his talk, by asking him if, alongside everything we’ve gained over the years, whether there’s anything we
lost along the way. He answered well, pointing out that the somewhat bloated stack of plugins that are commonplace on big sites nowadays and the ease with which admins can just
“click and install” more of them. I agree with him, although personally I miss built-in XFN support…
If you’d have told me in advance that hugging a Wapuu would have been a highlight of the day… yeah, that wouldn’t have been a surprise!
Networking And All That
There’s a lot of exhibitors with stands, but I tried to do a circuit or so and pay attention at least to those whose owners I’ve come into contact with in a professional
capacity. Many developers who make extensions for WooCommerce, of course, sell those extensions through WooCommerce.com, which means they come
into routine direct contact with my code (and it can mean that when their extension’s been initially rejected by our security scanners or linters, it’s me their developers first want to
curse!).
After a while, to spare some of that awkward exchange where somebody tries to sell me their product before I explain that I already sell their product for them, I slapped a
“Woo” sticker on my lanyard.
It’s been great to connect with people using WordPress to power the Web in a whole variety of different contexts, but it somehow still feels strange to me that WordPress has such a
commercial following! Even speaking as somebody who’s made their living at least partially out of WordPress for the last decade plus, it still feels to me like its greatest
value comes from its use for personal publishing.
The feel of a WordCamp with its big shiny sponsors is enormously different from, say, the intimacy and individuality of a Homebrew Website
Club meeting, and I think that’s something I still need to come to terms with. WordPress’s success story comes from many different causes, but perhaps chief among them is the fact
that it’s versatile enough to power the website of a government, multinational, or household-name brand… but also to run the smallest personal indie blog. I struggle to comprehend that,
even with my background.
My division of Automattic had a presence, of course.
I was proud of my colleagues for the “gimmick” they were using to attract people to the Woo stand: you could pick up a “credit card” and use it to make a purchase (of Greek olive oil)
using a website, see your order appear on the app at the backend in real-time, and then receive your purchase as a giveaway. The “credit
card” doubles as a business card from the stand, the olive oil is a real product from a real, local producer (who really uses WooCommerce to sell online!), and when you provide an email
address at the checkout you can opt-in to being contacted by the team afterwards. That’s some good joined-up thinking by my buddies in marketing!
Petya Petkova observed that it’s commonplace to take the easy approach and make a website look like… well, every other website. “Web
deja-vu” is a real thing, and it’s fed not only by the ebbs and flows of trends in web design but by the proliferation of indistinct themes that people just install-and-use.
How can we break free from web deja-vu, asks Petya. It almost makes me sad that her slides had been coalesced into the conference’s slidedeck design rather than being her own…
although on second though maybe that just helps enhance the point!
Choice of colours and typography can be used to tell a story, to instil a feeling, to encourage engagement. Scrolling can be used as a metaphor for storytelling (“scrolly-telling”,
Petya calls it). Animation flow can be used to direct a user’s attention and drive focus and encourage interaction.
A lot of the technical concepts she demonstrated – parts of a page that scroll at different speeds, typography that shifts or changes, videos used in a subtle way to accentuate other
content, etc. – can be implemented in the frontend with WebGL, Three.js and the like. Petya observes that moving this kind of content interactivity into the frontend can produce an
illusion of a performance improvement, which is an argument I’ve heard before, but personally I think it’s only valuable if it’s built as a progressive enhancement: otherwise, you’re
always at risk that your site won’t look like you’d hope.
I note, for example, that Petya’s agency’s site shows only an “endless spinner” when viewed in my browser (which blocks the code.jQuery CDN by
default, unless allowlisted for specific sites). All of the content is there, on the page, if you View Source, but it’s completely invisible if an external JavaScript fails to
load. That doesn’t just happen when weirdos like me disable JavaScript in their browsers: it can happen if the browser interacts badly with the script, or if the user’s Internet
connection is ropey, or a malware scanner misfires, or if government censorship blocks the CDN, or in any number of other conditions.
While I agree with Petya about the value of animation and interactivity to make sites awesome, I don’t think it can take second-place to ensuring the most-widespread access and
accessibility for your audience. Otherwise we’d still be making Flash sites, right?
So yeah: uniqueness and creativity are great, and I like what she’s proposing, but not the way she goes about it. The first person to ask a question wisely brought up accessibility, and
Petya answered well that accessibility technologies can bridge the gap, but I’d counter that it’s preferable to build accessible in the first instance: if you have to
use an aria- attribute it’s a good sign that you probably already did something wrong (not always, but it’s certainly a pointer that you ought to take a step back
and check!).
Several other good questions and great answers followed: about how to showcase a preliminary design when they design is dependent upon animation and interactivity (which I’ve witnessed
before!), on the value of server-side rendering of components, and about how to optimise for smaller screens. Petya clearly knows her stuff in all of these areas and had confident
responses.
Oliver Sild is the kind of self-taught hacker, security nerd, and community builder that I love, so I wasn’t going to miss his talk.
The number of security vulnerability reports in the WordPress ecosystem is up +328%, Oliver opened. But the bugs being reported are increasingly old, so we’re not talking
about new issues being created. And only 0.3% of bugs were in WordPress Core (and were patched before they were exploitable).
It’s good news in general in WordPress Security-land… but CSRF is on the up-and-up (overtaking XSS) in the plugin space. That, and all the broken access control we see in the admin area, are things I’ll be keeping in mind next time I’m arguing
with a vendor about the importance of using nonces and security checks in their extension (I have this battle from time to time!).
But an interesting development is the growth of the supply chains in the WordPress plugin ecosystem. Nowadays a plugin might depend upon another plugin which might depend upon a
library… and a patch applied to the latter of those might take time to be propagated through the chain, providing attackers with a growing window of opportunity.
I love a good Sankey chart. Even when it says scary things.
A worrying thought is that while plugin directory administrators will pull and remove plugins that have longstanding unactioned security issues. But that doesn’t help the sites that
already have that plugin installed and are still using it! There’s a proposal to allow WordPress to notify admins if a plugin
used on a site has been dropped for security reasons, but it was opened 9 years ago and hasn’t seen any real movement, soo…
I like that Oliver plugged for security researchers being acknowledged as equal contributors to developers on your software. But then, I would say that, as somebody who breaks into
things once in a while and then tells the affected parties how to fix the problem that allowed me to do so! He also provided a whole wealth of tips for site owners and agencies to try
to keep their sites safe, but little that I wasn’t aware of already.
Still, good to see this talk get as good an audience as it did, given the importance of the topic!
It was about this point in the day, glancing at my schedule and realising that at any given time there were up to four other sessions running simultaneously, that I really got
a feel for the scale of this conference. Awesome. Meanwhile, Oliver was fielding the question that I’m sure everybody was thinking: with Gutenberg blocks powered by JavaScript that are
often backed by a supply-chain of the usual billion-or-so files you find in your .node_modules directory, isn’t the risk of supply chain attacks increasing?
Spoiler: yes. Did you notice earlier in this post I mentioned that I don’t use Gutenberg on this site yet?
When the Jetpack team told me that they’ve been improving their cloud offering, this wasn’t what I expected.
My first “workshop” was run by Giulia Laco, on the topic of readable content and design.
Designers to the left of me, coders to the right: here I am, stuck in the middle with you.
Giulia began by reminding us how short the attention span of Web readers is, and how important the right typographic choices are in ensuring that people actually read your content. I
fully get this – I think that very few people will have the attention span to read this part of this very blog post, for example! – but I loved that she hammered the point home
by presenting every slide of her presentation twice (or more), “improving” the typographic choices as she went along: an excellent and memorable quirk.
Our capacity to read and comprehend a text is affected by a combination of common (distance, lighting, environment, concentration, mood, etc.), personal (age, proficiency, motiviation,
accessibility requirements, etc.), and typographic (face, style, size, line length and spacing, contrast, width, rhythm etc.) factors. To explore the impact of the typographic factors,
the group dived into a pre-prepared Codepen and a shared Figma diagram. (I immediately had a TIL moment over the font-synthesis: CSS property!)
I appreciated that Giulia stressed the importance of a fallback font. Just like the CDN issues I described above while talking about JavaScript dependencies, not specifying a fallback
font puts your design at the mercy of the browser’s defaults. We don’t like to think about what happens when websites partially fail, but they do, and we should.
Things get interesting at the intersection of readability and accessibility. For example, WCAG accessibility requirements demand that you don’t use images of text (we used to
do this a lot back before we could reliably use fonts on the web, and before we could easily have background images on e.g. buttons for navigation). But this accessibility
requirement also aids screen readability when accounting for e.g. “retina” screens with virtual pixel ratios.
Do you remember when a pixel was the size of a pixel? Those days are long gone. True story.
Giulia provided a great explanation of why we may well think in pixels (as developers or digital designers) but we’re unlikely to use them everywhere: I’d internalised
this lesson long ago but I appreciated a well-explained justification. The short of it is: screen zoom (that fancy zoom feature you use in your browser all the time, especially on
mobile) and text zoom (the one you probably don’t use, or don’t use so much) are different things, and setting a pixel-based font size in the root node wrecks the latter, forcing some
people with accessibility needs to use the former, which is likely to result in vertical scrolling. Boo!
I also enjoyed seeing this demo of how the different hyphenation-points in different languages (because of syllable stress) can impact on
your wrapping points/line lengths when content is translated. This can affect any website, of course, because any website can be the target of automatic translation.
Plus, Giulia’s thoughts on the value of serifed fonts (even on digital displays) for improving typographic readability of the letters d, b, p and q which are often mirror- or
rotationally-symmetric to one another in sans-serif fonts. It’s amazing to have something – in this case, a psychological letter transposition – pointed out that I’ve experienced but
never pinned down the reason for, before. Neat!
It was a shame that this workshop took place late in the day, because many of the participants (including me) seemed to have flagging energy levels!
Altogether a great (but intense) day. Boggles my mind that there’s another one like it tomorrow.
Among the many perks of working for a company with a history so tightly-intertwined with that of the open-source WordPress project is that license to attend WordCamps – the biggest WordPress conferences – is basically a
given.
It’s frankly a wonder that this is, somehow, my first WordCamp. As well as using it1 and developing atop
it2,
of course, I’ve been contributing to WordPress since 2004 (albeit only in a tiny way, and not at all for most of the last decade!).
If you already know what WP-CLI is… let’s be friends.
Today is Contributor Day, a pre-conference day in which folks new and old get together in person to hack on WordPress and WordPress-adjacent projects. So I met up with Cem, my Level 4 Dragonslayer friend, and we took an ultra-brief induction into WP-CLI3
before diving in to try to help write some code.
Contributor Days are about many things, but perhaps their biggest value comes from lowering the barrier to becoming a new contributor to an open-source project by sitting you
right next to somebody who already knows it well.
So today, as well as meeting some awesome folks, I got to write an overly-verbose justification for a
bug report being invalid and implement my first PR for WP-CLI: a bugfix for a strange quirk in output formatting.
The bug I fixed is slightly hard to describe (and even harder to explain why it matters), but here’s a summary: when you run a WP-CLI command that first displays a table and
then the result, the result is likely to always appear in colour even if you specify --no-color.
I hope to be able to continue contributing to WP-CLI. I learned a lot about it today, and while I don’t use it as much as I used to in my multisite-management days, I still really
respect its power as a tool.
Did I mention lately how awesome my employers are? I promise my blog’s not always gonna be me shilling for them… but today it is.
Footnotes
1 Even with the monumental stack of custom code woven into DanQ.me, a keen eye will
probably spot that it’s WordPress-powered.
3 WP-CLI is… it’s like Drush but for WordPress, if that makes sense to you? If not: it’s a
multifaceted command-line tool for installing, configuring, maintaining, and managing WordPress installations, and I’ve been in love with it for years.
I just spent a lightweight week in Rome with fellow members of Automattic‘s Team Fire.
Among our goals for the week was an attempt to strengthen the definition of who are team are, what we work on, and how and why we do so. That’s
basically a team-level identity, mission, vision, and values, right?
We were missing two members of our team, but one was able to remote-in (the other’s on parental leave!).
The cards sat on my ‘plane tickets for a fortnight because it was just about the only way I’d remember to pack them.
Normally when you play Dixit, you select a card from your hand – each shows a unique piece of artwork – and try to describe it in a way that’s precise enough that some
of the other players will later be able to pick it out of a line-up, but ambiguous enough that not all the other players will. It’s a delicate balancing act. Even when our old
Geek Night was in full swing we didn’t used to play it often because our well-established group’s cornucopia of in-jokes and references made it trivially easy to “target”
your descriptions at specific players1, but it’s still a solid icebreaker activity.
Can you see your team’s values symbolised in any Dixit cards?
Perhaps it was the fantasy artwork that inspired us or maybe it just says something about how my team sees themselves, but what we came up with had a certain… swords-and-sorcery… even
Dungeons & Dragons… feel to it.
The projects my team are responsible for aren’t actually monsters, but they can be complex, multifaceted, and unintuitive. And have a high AC.
Ou team’s new identity isn’t finalised, but I love the fact that we’ve been able to inject a bit of fun and whimsy into it. At our last draft, my team looks to be defined as comprising:
Gareth, level 62 Pathfinder, leading the way through the wilds
Bero, Level 5 Battlesmith, currently lost in the void
Dan (me!), Level 5 Arcane Trickster, breaking locks and stealing treasure
Cem, Level 4 Dragonslayer, smashing doors and bugs alike
Lae, Level 7 Pirate, seabound rogue with eyes on the horizon
Kyle, Level 5 Apprentice Bard, master of words and magic
Simran, Level 6 Apprentice Code Witch, weaving spells from nature
I think that’s pretty awesome.
Footnotes
1 Also: I don’t own any of the expansion packs and playing with the same cards over and
over again gets a bit samey.
2 The “levels” are simply the number of years each teammate has been an Automattician,
plus one.
Now that travel for work is back on the menu, I’ve been trying to upgrade my “pack light” game.
I’ve been inspired in part by Beau, who I first met during my trip to South Africa in 2019 during my Automattic onboarding. Beau travelled from the US for a two week jaunt with nothing but hand luggage, and it blew my mind.
Gotta flight? Pack light, pack tight. That’s right! Corporate branding is just a bonus.
For my trip to Vienna earlier this year for a divisional meetup, I got by with just a backpack and a laptop bag. Right now, I’m waiting to fly to Rome for a week, and I’ve ditched the
laptop bag in favour of just a single carry-on backpack. About 7kg of luggage, and well within the overhead locker size limit.
I’m absolutely sold on this approach. I get to:
walk past the queues for luggage drop (having checked-in online),
keep the entirety of my luggage with me at all times (which ensures it goes where I do),
breeze through security1,
thanks to smart packing2
walk right out of the airport at the other end without having to wait for the flingers to finish smashing everybody’s luggage into the carousels.
I’ve been working on simplifying my everyday carry, too. My wallet is the Carbon Fibre Liquid Wallet, which is about the size of a deck of playing cards (something I also often carry!) and holds a handful
of cards, a bundle of cash, a bottle opener, and all my regular keys. The hook on the end is for attaching the pendrive with my password
safe for travel.
As somebody who’s travelled “heavy” for most of my life – and especially since the children came along – it’s liberating to migrate to a “pick up a bag and go” mindset. To begin with,
the nagging thought that I must’ve forgotten something essential was challenging, but I think I’ve gotten past that stage now.
Travelling light feels like carefree: like being a kid again, when all you needed was the back on your back and you were ready for an adventure. Once again, I’ve got a bag on my
back3 and I know that everything I need for an adventure
is right here with me4.
Footnotes
1 If you’ve travelled with me before, you might have noticed that I sometimes have trouble
at borders on account of my damn stupid name, as predicted by the Passport
Office. I’ve since learned all the requisite tricks to sidestep these problems, but that’s probably worthy of a post in its own right.
2 A little smart packing goes a long way. In the photo above, you might see my pre-prepared liquids bag in
a side pocket, my laptop slides right out for separate scanning, my wallet and phone just dump out of my pockets, and I’m done.
3 I don’t really have a bag on my back right now. I’m sat in a depature lounge at Gatwick
Airport. But you get the idea.
4 Do I really have everything I need? I’ve not brought a waterproof coat and,
looking at the weather forecast at my destination, this might have been a mistake. But worst case I can buy a cheap poncho at the other end. That’s the kind of freedom that being an
adult gets you, replacing the childlike freedom to get soaked and not care.
Lacking a basis for comparison, children accept their particular upbringing as normal and representative.
“Feed me, Seymour!”
Kit was telling me about how his daughter considers it absolutely normal to live in a house full of
insectivorous plants1, and it got
me thinking about our kids, and then about myself:
I remember once overhearing our eldest, then at nursery, talking to her friend. Our kid had mentioned doing something with her “mummy, daddy, and Uncle Dan” and was incredulous that her friend didn’t have an Uncle Dan that they lived with!
Isn’t having three parents… just what a family looks like?
You don’t have an Uncle Dan? Then where do you nap‽
By the time she was at primary school, she’d learned that her family wasn’t the same shape as most other families, and she could code-switch with incredible ease. While picking her up
from school, I overheard her talking to a friend about a fair that was coming to town. She told the friend that she’d “ask her dad if she could go”, then turned to me and said
“Uncle Dan: can we go to the fair?”; when I replied in the affirmitive, she turned back and said “my dad says it’s okay”. By the age of 5 she was perfectly capable of
translating on-the-fly2 in order to
simultaneously carry out intelligble conversations with her family and with her friends. Magical.
When I started driving, and in particular my first few times on multi-lane
carriageways, something felt “off” and it took me a little while to work out what it was. It turns out that I’d internalised a particular part of the motorway journey experience from
years of riding in cars driven by my father, who was an unrepentant3
and perpetual breaker of speed limits.4
I’d come to associate motorway driving with overtaking others, but almost never being overtaken, but that wasn’t what I saw when I drove for myself.5
It took a little thinking before I realised the cause of this false picture of “what driving looks like”.
How my dad ever managed to speed in this old rustbucket I’ll never know.
The thing is: you only ever notice the “this is normal” definitions that you’ve internalised… when they’re challenged!
It follows that there are things you learned from the quirks of your upbringing that you still think of as normal. There might even be things you’ll never un-learn. And you’ll
never know how many false-normals you still carry around with you, or whether you’ve ever found them all, exept to say that you probably haven’t yet.
I wanted a stock image that expressed the concept of how children conceptualise ideas in their mind, but I ended up with this picture of a women offering her kid a tiny human brain in
exchange for her mobile phone back. That’s a normal thing that all families do, right?
It’s amazing and weird to think that there might be objective truths you’re perpetually unable to see as a restult of how, or where, or by whom you were brought up, or by what your
school or community was like, or by the things you’ve witnessed or experienced over your life. I guess that all we can all do is keep questioning everything, and work to help
the next generation see what’s unusual and uncommon in their own lives.
Footnotes
1 It’s a whole thing. If you know Kit, you’re probably completely unsurprised, but spare a
thought for the poor randoms who sometimes turn up and read my blog.
2 Fully billingual children who typically speak a different language at home than they do
at school do this too, and it’s even-more amazing to watch.
3 I can’t recall whether his license was confiscated on two or three separate ocassions,
in the end, but it was definitely more than one. Having a six month period where you and your siblings have to help collect the weekly shop from the supermarket by loading up your
bikes with shopping bags is a totally normal part of everybody’s upbringing, isn’t it?
4 Virtually all of my experience as a car passenger other than with my dad was in Wales,
where narrow windy roads mean that once you get stuck behind something, that’s how you’re going to be spending your day.
5 Unlike my father, I virtually never break the speed limit, to such an extent that when I
got a speeding ticket the other year (I’d gone from a 70 into a 50 zone and re-set the speed limiter accordingly, but didn’t bother to apply the brakes and just coasted down to the
new speed… when the police snapped their photo!), Ruth and JTA both independently reacted to the news with great skepticism.
Last night I had a nightmare about Dungeons & Dragons. Specifically, about the group I DM for on alternate Fridays.
In their last session the
party – somewhat uncharacteristically – latched onto a new primary plot hook rightaway. Instead of rushing off onto some random side quest threw themselves directly into this new
mission.
They flung themselves not only figuratively but also literally into their new quest, leaping from the side of a floating city.
This effectively kicked off a new chapter of their story, so I’ve been doing some prep-work this last week or so. Y’know: making battlemaps, stocking treasure chests with mysterious and
powerful magical artefacts, and inventing a plethora of characters for the party to either befriend or kill (or, knowing this party: both).
I also put together a “cut scene”
video welcoming the party into this new chapter of their adventure.
Anyway: in the dream, I sat down to complete the prep-work I want to get done before this week’s play session. I re-checked my notes about what the adventurers had gotten up to
last time around, and… panicked! I was wrong, they hadn’t thrown themselves off the side of a city floating above the first layer of Hell at all! I’d mis-remembered completely
and they’d actually just ventured into a haunted dungeon. I’d been preparing all the wrong things and now there wasn’t time to correct my mistakes!
Also in my dream – conveniently for my new “haunted dungeon” environment – my favourite encounter size calculator included a tool to compensate for a player character who can cast Turn Undead, when
making an undead encounter.
This is, of course, an example of the “didn’t prepare for the test” trope of dreams. Clearly I’m still feeling underprepared for this week’s game! But probably a bigger reason for the
dream, and remembering it, was that I’ve had a cold and kept waking up to cough.
This is an alternate history of the Web. The premise is true, but the story diverges from our timeline and looks at an alternative “Web that might have been”.
Prehistory
This is the story of P3P, one of the greatest Web standards whose history has been forgotten1, and how the abject failure of its first versions paved the
way for its bright future decades later. But I’m getting ahead of myself…
Drafted in 2002 in the wake of growing concern about the death of privacy on the Internet, P3P 1.0 aimed to make the collection of personally-identifiable data online transparent. Hurrah, right?
Initially, the principle was sound. The specification was weak. The implementation was apalling. But P3P 1.1
could have worked well.
Developers are lazy3 and soon converged on the simplest possible solution: add a garbage HTTP header like P3P: CP="See our website for our privacy policy." and your cookies work just fine! Ignore the problem, ignore the
proposed solution, just do what gets the project shipped.
Without any meaningful enforcement it also perfectly feasible to, y’know, just lie about how well you treat user data. Seeing the way the wind was blowing, Mozilla dropped
support for P3P, and Microsoft’s support – which had always been half-baked and lacked even the most basic user-facing
controls or customisation options – languished in obscurity.
For a while, it seemed like P3P was dying. Maybe, in some alternate timeline, it did die: vanishing into
nothing like VRML, WAP, and XBAP.
But fortunately for us, we don’t live in that timeline.
Revival
In 2009, the European Union revisited the Privacy and Electronic Communications
Directive. The initial regulations, published in 2002, required that Web users be able to opt-out of tracking cookies, but the amendment required that sites ensure that
users opted-in.
As-written, this confusing new regulation posed an
immediate problem: if a user clicked the button to say “no, I don’t want cookies”, and you didn’t want to ask for their consent again on every page load… you had to give them a cookie
(or use some other technique
legally-indistinguishable from cookies). Now you’re stuck in an endless cookie-circle.4
This, and other factors of informed consent, quickly introduced a new pattern among those websites that were fastest to react to the legislative change:
The cookie consent banner, with all its confusing language and dark patterns, looked like it was going to become the new normal for web users in the early 2010s. But thankfully, our
saviour had been waiting in the wings all along.
Web users rebelled. These ugly overlays felt like a regresssion to a time when popup ads and splash pages were commonplace. “If only,” people cried out, “There were a better way to do
this!”
It was Professor Lorie Cranor, one of the original authors of the underloved P3P specification and a respected champion of usable privacy and security, whose rallying cry gave us hope. Her CNET article, “Why
the EU Cookie Directive is a solved problem”5, inspired a new generation of development on what would become known as P3P 2.0.
While maintaining backwards compatibility, this new standard:
deprecated those horrible XML documents in favour of HTTP
headers and <link> tags alone,
removing support for Set-Cookie2: headers, which nobody used anyway, and
added features by which the provenance and purpose of cookies could be stated in a way that dramatically simplified adoption in browsers
Internet Explorer at this point was still used by a majority of Web users. It still supported the older
version of the standard, and – as perhaps the greatest gift that the much-maligned browser ever gave us – provided a reference implementation as well as a stepping-stone to wider
adoption.
Opera, then Firefox, then “new kid” Chrome each adopted P3P 2.0; Microsoft finally got on board with IE 8 SP 1. Now the latest versions of all the mainstream browsers had a solid
implementation6
well before the European data protection regulators began fining companies that misused tracking cookies.
Nowadays, we’ve pretty-well standardised on the address bar being the place where all cookie and privacy information and settings are stored. Can you imagine if things had
gone any other way?
But where the story of P3P‘s successes shine brightest came in 2016, with the passing of the GDPR. The W3C realised that P3P could simplify both the expression and understanding of privacy policies for users, and formed a group to work on version 2.1. And that’s
the version you use today.
When you launch a new service, you probably use one of the many free wizard-driven tools to express your privacy policy and the bases for your data processing, and it spits out a
template privacy policy. You need the human-readable version, of course, since the 2020 German court ruling that you cannot rely on a machine-readable privacy policy alone, but
the real gem is the P3P: 2.1 header version.
Assuming you don’t have any unusual quirks in your data processing (ask your lawyer!), you can just paste the relevant code into your server configuration and you’re good to go. Site
users get a warning if their personal data preferences conflict with your data policies, and can choose how to act: not using your service, choosing which of your
features to opt-in or out- of, or – hopefully! – granting an exception to your site (possibly with caveats, such as sandboxing your cookies or clearing them immediately after closing
the browser tab).
Sure, what we’ve got isn’t perfect. Sometimes companies outright lie about their use of information or use illicit methods to track user behaviour. There’ll always be bad guys out there. That’s what laws are there to deal with.
But what we’ve got today is so seamless, it’s hard to imagine a world in which we somehow all… collectively decided that the correct solution to the privacy problem might have been to
throw endless popovers into users’ faces, bury consent-based choices under dark patterns, and make humans do the work that should from the outset have been done by machines. What a
strange and terrible timeline that would have been.
Footnotes
1 If you know P3P‘s
history, regardless of what timeline you’re in: congratulations! You win One Internet Point.
2 Techbros have been trying to solve political problems using technology since long before
the word “techbro” was used in its current context. See also: (a) there aren’t enough mental health professionals, let’s make an AI app? (b) we don’t have enough ventilators for this
pandemic, let’s 3D print air pumps? (c) banks keep failing, let’s make a cryptocurrency? (d) we need less carbon in the atmosphere or we’re going to go extinct, better hope direct
carbon capture tech pans out eh? (e) we have any problem at all, lets somehow shoehorn blockchain into some far-fetched idea about how to solve it without me having to get out of my
chair why not?
3 Note to self: find a citation for this when you can be bothered.
4 I can’t decide whether “endless cookie circle” is the name of the New Wave band I want
to form, or a description of the way I want to eventually die. Perhaps both.
6 Implementation details varied, but that’s part of the joy of the Web. Firefox favoured
“conservative” defaults; Chrome and IE had “permissive” ones; and Opera provided an ultra-configrable matrix of options by which a user could specify exactly which kinds of cookies to
accept, linked to which kinds of personal data, from which sites, all somehow backed by an extended regular expression parser that was only truly understood by three people, two of
whom were Opera developers.
My website is in the dataset too, but with a massive 300,000 tokens. Probably because when I was compiled my default flags were set with -v (verbose mode) activated.
Much has been said about how ChatGPT and her friends will hallucinate and mislead. Let’s take an example.
Remember that ChatGPT has almost-certainly read basically everything I’ve ever written online – it might well be better-informed about me better than you are – as
you read this:
Given that ChatGPT has all the information it needs to talk about me accurately, it comes up with a surprising amount of crap.
When I asked ChatGPT about me, it came up with a mixture of truths and believable lies2,
along with a smattering of complete bollocks.
In another example, ChatGPT hallucinates this extra detail specifically because the conversation was foreshadowed by its previous mistake. At this point, it digs its heels in and
commits to its claim, like the stubborn guy in the corner of the pub who doubles-down on his bullshit.
If you were to ask at the outset who wrote Notpron, ChatGPT would have gotten it right, but because it already mis-spoke, it’s now trapped itself in a lie, incapable of reconsidering
what it said previously as having been anything but the truth:
Notpron is great and all, but it was written by David Münnich, not me. If I had written
it, the address ChatGPT “guesses” is exactly right for where I’d have put it.
Simon Willison says that we should call this behaviour “lying”. In response to this, several people told
him that the “lying” excessively anthropomorphises these chatbots, implying that they’re deliberately attempting to mislead their users. Simon retorts:
I completely agree that anthropomorphism is bad: these models are fancy matrix arithmetic, not entities with intent and opinions.
But in this case, I think the visceral clarity of being able to say “ChatGPT will lie to you” is a worthwhile trade.
I agree with Simon. ChatGPT and systems like it are putting accessible AI into the hands of the masses, and that means that the
people who are using it don’t necessarily understand – nor desire to learn – the statistical mechanisms that actually underpin the AI‘s “decisions” about how to respond.
Trying to explain how and why their new toy will get things horribly wrong is hard, and it takes a critical eye, time, and practice to begin to discover how to use these tools
effectively and safely.3
It’s simpler just to say “Here’s a tool; by the way, it’s a really convincing liar and you can’t trust it even a little.”
Giving people tools that will lie to them. What an interesting time to be alive!
Footnotes
1 I’m tempted to blog about my experience of using Stable Diffusion and GPT-3 as
assistants while DMing my regular Dungeons & Dragons game, but haven’t worked out exactly what I’m saying yet.
2 That ChatGPT lies won’t be a surprise to anybody who’s used the system nor anybody who
understands the fundamentals of how it works, but as AIs get integrated into more and more things, we’re going to need to teach a level of technical literacy about what that means,
just like we do should about, say, Wikipedia.
3 For many of the tasks people talk about outsourcing to LLMs, it’s the case that it would take less effort for a human to learn how to do the task that it would for them to learn how to supervise an
AI performing the task! That’s not to say they’re useless: just that (for now at least) you should only trust them to do
something that you could do yourself and you’re therefore able to critically assess how well the machine did it.
Wait, there’s new Far Side content? Yup: it turns out Gary Larson’s dusted off his pen
and started drawing again. That’s awesome! But the last thing I want is to have to go to the website once every few… what: days? weeks? months? He’s not syndicated any more so
he’s not got a deadline to work to! If only there were some way to have my feed reader, y’know, do it for me and let me know whenever he draws something new.
It turns out, there is.
Here’s my setup for getting Larson’s new funnies right where I want them:
Feed URL:https://www.thefarside.com/new-stuff/1
This isn’t a valid address for any of the new stuff, but always seems to redirect to somewhere that is, so that’s nice.
XPath for finding news items://div[@class="swiper-slide"]
Turns out all the “recent” new stuff gets loaded in the HTML and then JavaScript turns it into a slider etc.; some of the
CSS classes change when the JavaScript runs so I needed to View Source rather than use my browser’s inspector to find
everything.
Item title:concat("Far Side #", descendant::button[@aria-label="Share"]/@data-shareable-item)
Ugh. The easiest place I could find a “clean” comic ID number was in a data- attribute of the “share” button, where it’s presumably used for engagement tracking. Still,
whatever works right?
Item content:descendant::figcaption
When Larson captions a comic, the caption is important.
Item link (URL) and item unique ID: concat("https://www.thefarside.com",
./@data-path)
The URLs work as direct links to the content, and because they’re unique, they make a reasonable unique ID too (so long as
their numbering scheme is internally-consistent, this should stop a re-run of new content popping up in your feed reader if the same comic comes around again).
Item thumbnail:concat("https://fox.q-t-a.uk/referer-faker.php?pw=YOUR-SECRET-PASSWORD-GOES-HERE&referer=https://www.thefarside.com/&url=",
descendant::img[@data-src]/@data-src)
The Far Side uses Referer: headers as an anti-hotlinking measure, which prevents us easily loading the images directly in an RSS reader. I use this tiny PHP script as a proxy to
mitigate that. If you don’t have such a proxy set up, you could simply omit the “Item thumbnail” and “Item content” fields and click the link to go to the original page.
Item date:normalize-space(descendant::div[@class="tfs-comic-new__meta"]/*[1])
The date is spread through two separate text nodes, so we get the content of their wrapper and use normalize-space to tidy the whitespace up. The date format then looks
like “Wednesday, March 29, 2023”, which we can parse using a custom date/time format string:
Custom date/time format:l, F j, Y
I promise I’ll stop writing about how awesome FreshRSS + XPath is someday. Today isn’t that day.
Meanwhile: if you used to use a feed reader but gave up when the Web started to become hostile to them and big social media systems started to wall you in, you should really consider
picking one up again. The stuff I write about is complex edge-cases that most folks don’t need to think about in order to benefit from RSS… but it’s super convenient to have the things you care about online (news, blogs, social media, videos, newsletters, comics, search trends…)
collated and sorted for you… without interference from algorithms that want to push “sticky” content, without invasive tracking or advertisements (or cookie banners or privacy popups),
without something “disappearing” simply because you put off reading it for a few days.


![Scan of a ring-bound page from a technical manual. The page describes the use of the "INPUT" command, saying "This command is used to let the computer know that it is expecting something to be typed in, for example, the answer to a question". The page goes on to provide a code example of a program which requests the user's age and then says "you look younger than [age] years old.", substituting in their age. The page then explains how it was the use of a variable that allowed this transaction to occur.](https://bcdn.danq.me/_q23u/2023/07/cpc664-manual-input-command.png)

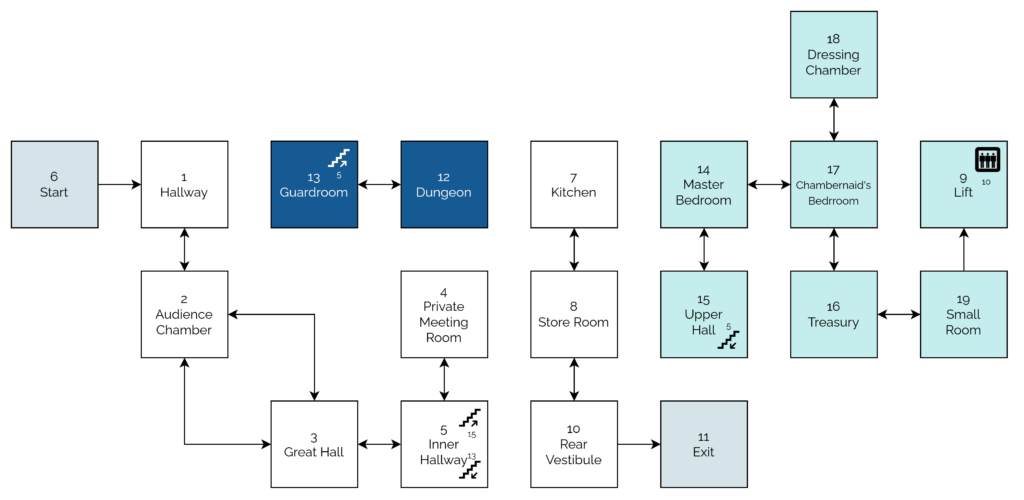
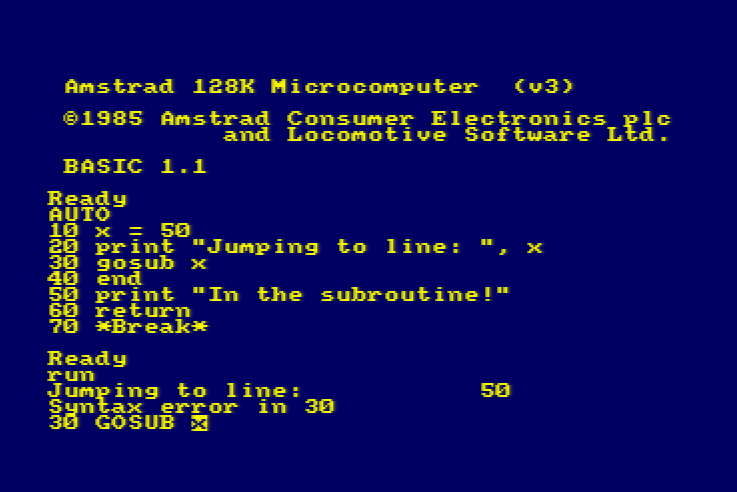






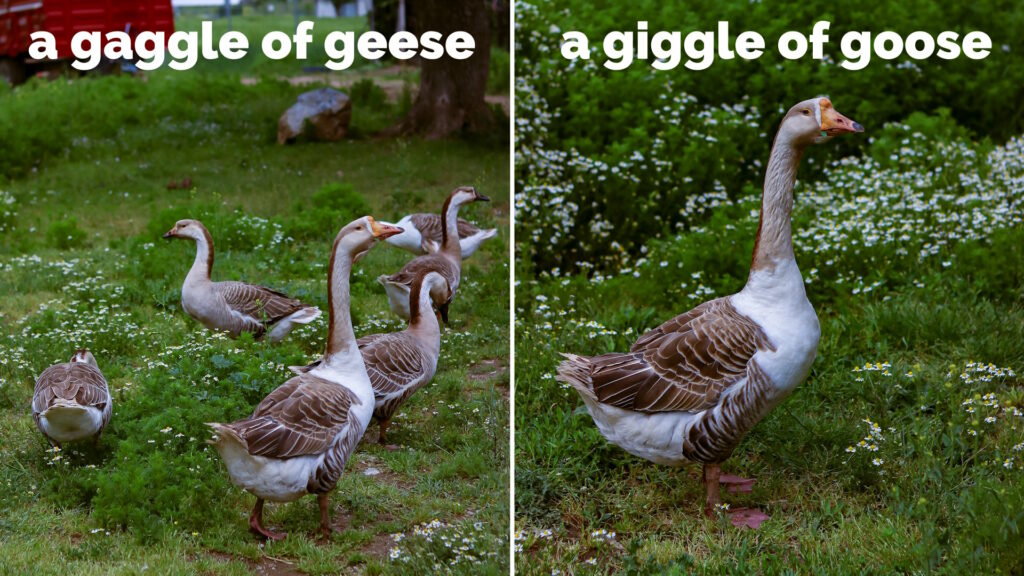


























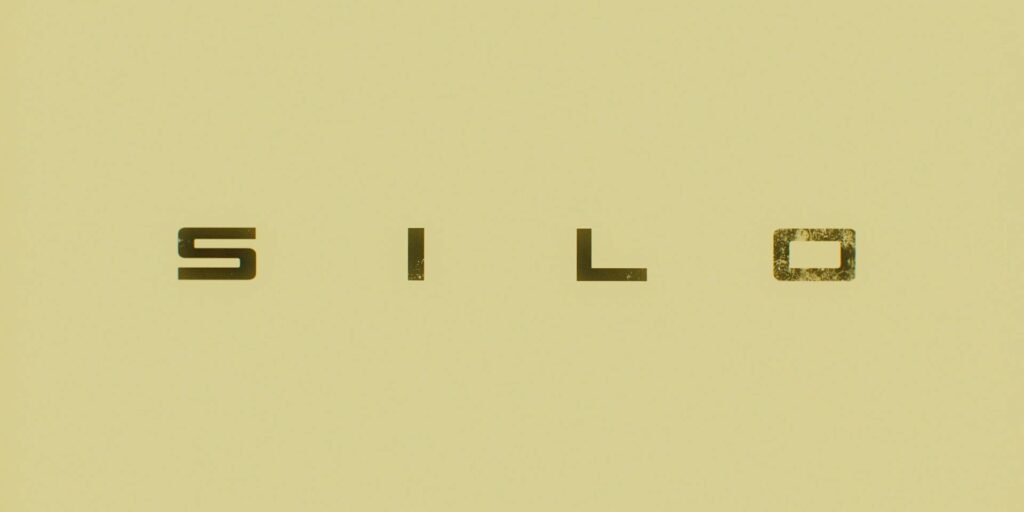


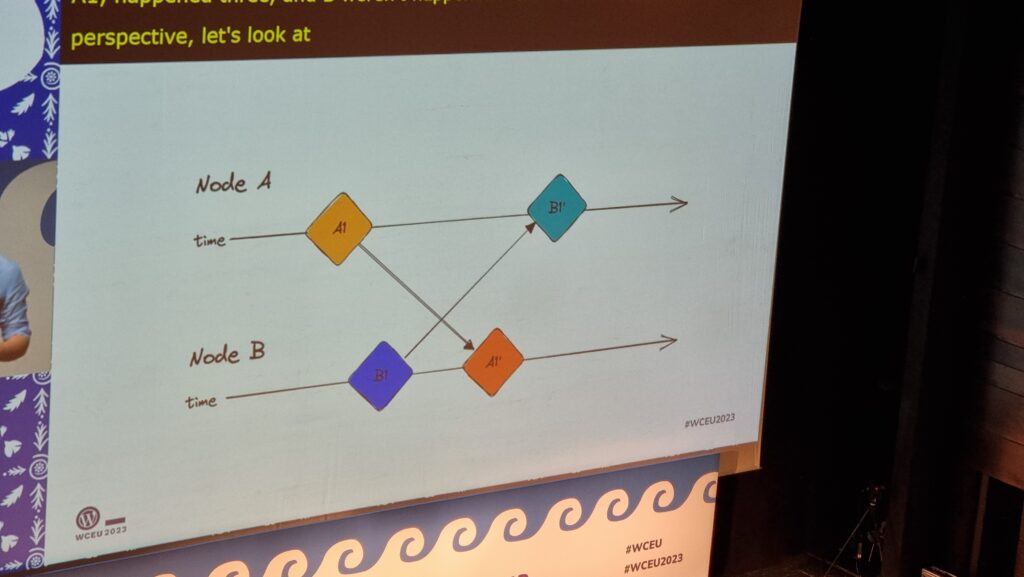

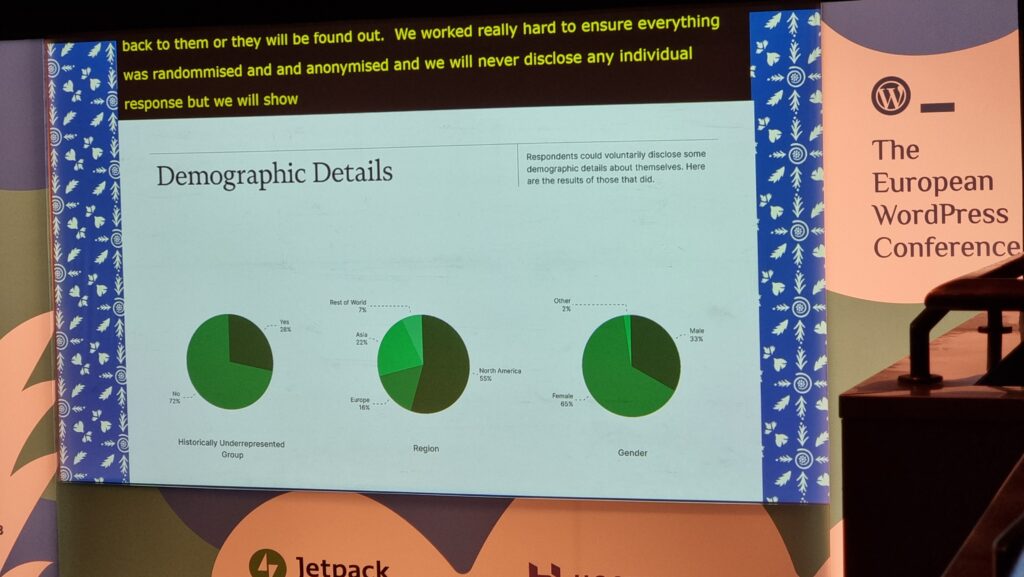





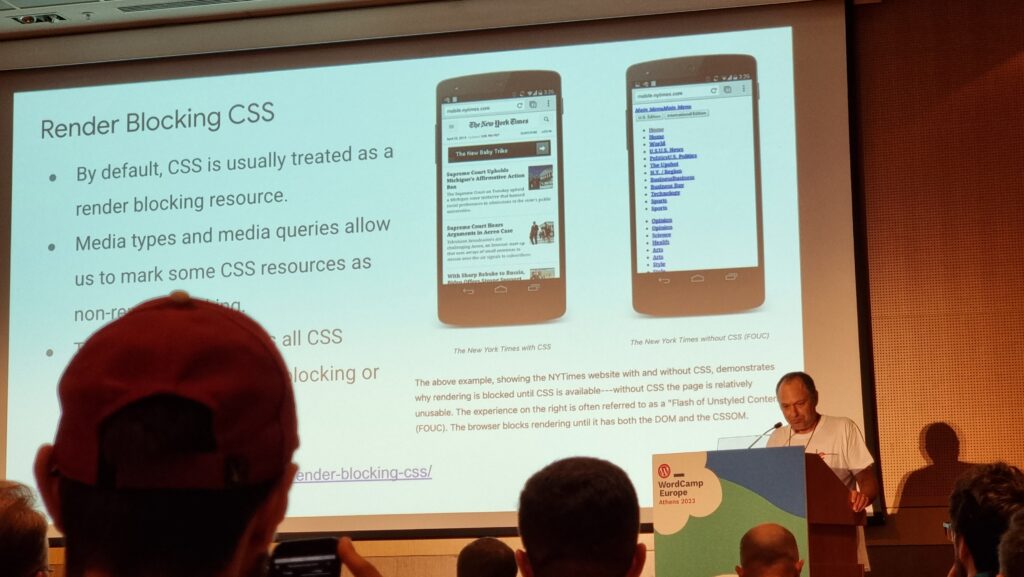

















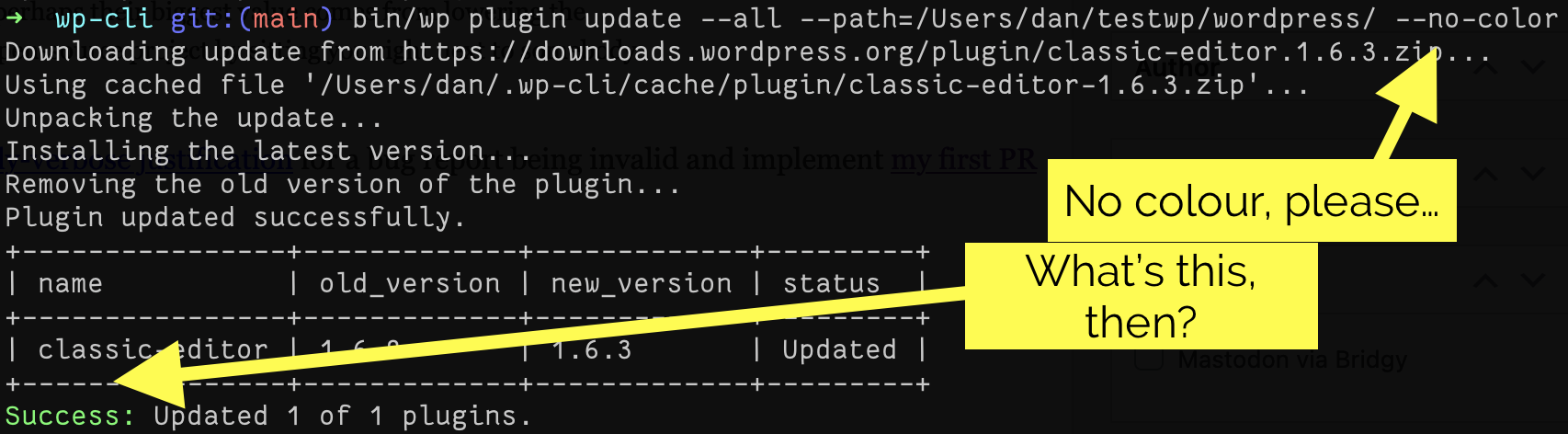












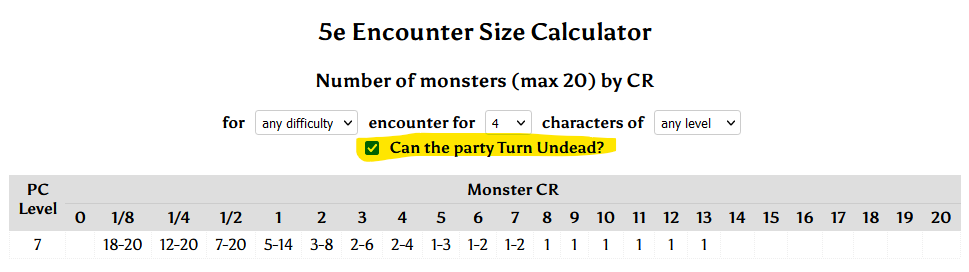
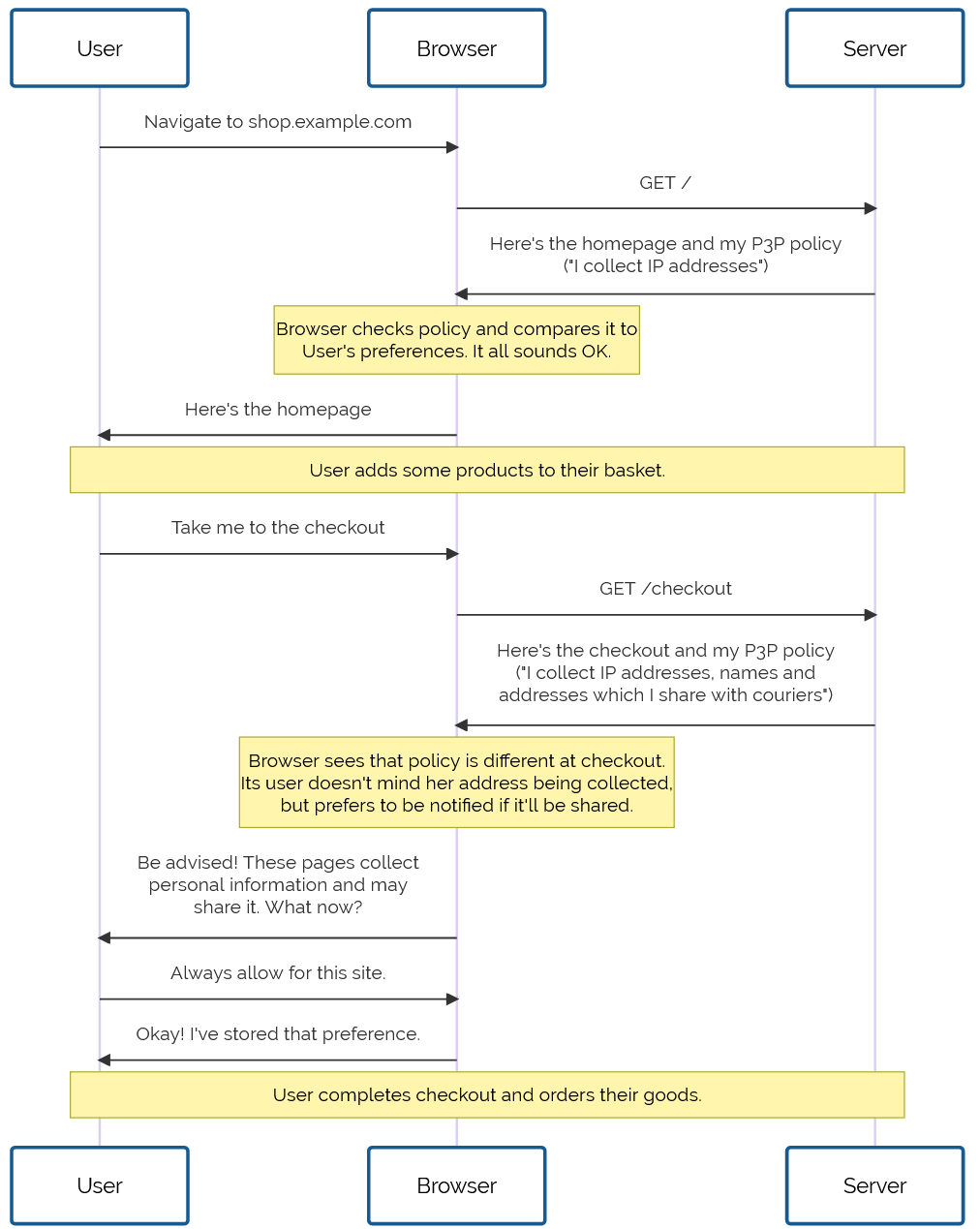



{kind=link}