FTF! Can’t remember the last time I got one of those; it’s been a while. I woke up this morning thinking about an errand I need to run
today that would take me near Standlake when I saw the notification that new cache had appeared.
Spurred into action, I opted to do my chore first thing… and find this geocache while on the way there. Parked up at the village hall and quickly found the sign and all the requisite
numbers. Spent a little while looking at the wrong host before spotting the other likely candidate, after which the cache was in hand.
Didn’t bring tweezers in my haste to leave the house, and I trimmed my nails just the other day, so retrieving the log book was a bit of a challenge. Eventually I was successful; log
signed and retrieved. So nice to see an empty logbook for once! I’m usually beaten to these things by (CO) muddy legs or Go Catch!
I saw a variation of this email back in the day, which provides a Mad Libs style approach to formulating a country & western
song. When I was reminded of it today, I adapted it for Perchance. Give it a go!
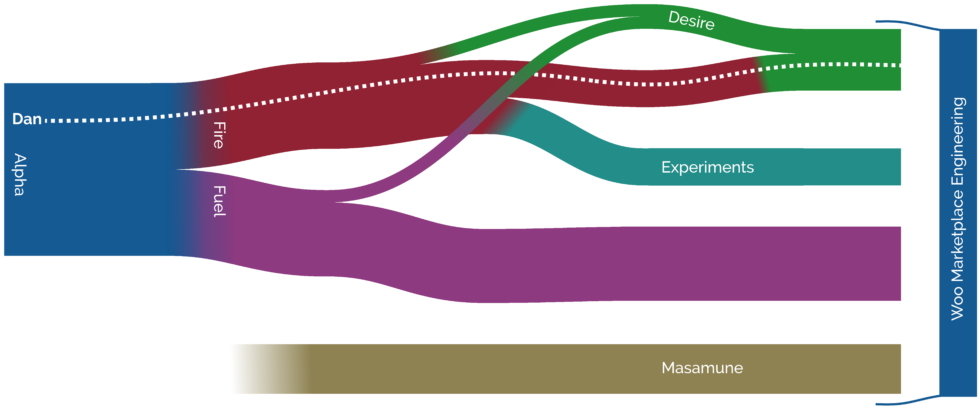
This winter, though, Fire became underpopulated. We lost a few folks to a newly-formed Experiments team, and several individual team members moved to other parts of the company. Once we
got small enough it wasn’t worthwhile being a team in our own right. Our focus areas got split between Desire and Masume, and those of us who were left got absorbed into Team Desire.
That’s where you’ll now find me.
I miss being “on Fire”, because it sounded cool. Maybe I should suggest a patch for our intranet to allow teams to choose the preposition used when referring to their members, e.g.
from “on”, “in”, “of” etc. Then I could be the “Code Magician of Desire”, which is a cool job title once again.
I was initially a bit bummed about the dissolution of my old team3
and struggled to find my place in my new team. The work is similar and the codebases overlap, but even sibling teams can have different rituals and approaches to problems that provide a
learning barrier4.
I think I’ve begun to find my feet now, and next week I’m excited to meet many of my new team in-person for the first time at a Desire-wide meetup in Amsterdam5.
Footnotes
1 Strangely, this isn’t directly related to Automattic’s recent re-organisation, which I’ve written about previously, but is a
result of more-local changes within my division coupled with the natural flow of Automatticians around the company. But it does make it feel from my perspective like a lot of things
are getting jiggled about simultaneously!
2 When Alpha were first discussing the upcoming split, I suggested that we might like to
give our new teams a “pair” of names that linked to one another, and threw out a few ideas to get the ball rolling. One of those ideas was “Fuel and Fire”; I jokingly added that “it
was like the Metallica song, which also gave us ‘Desire’ as a possible third team name should the need arise”. This wasn’t
supposed to be taken seriously, but apparently it was taken seriously enough because my suggestion was the winner and I soon ended up “on Fire”.
3 Many of my old teammates and I did at least manage to get together for one final
(virtual) social event, culminating in a symbolic “extinguishing of fire” as a candle that had been left burning through the meeting was put out at the end.
4 A team’s rituals aren’t just about the way they hold their meetings or run their retros;
for example my new team are very disciplined about announcing their appearance on a morning with a friendly greeting in our social channel, which are for some reason generally
responded-to with a barrage of “waving Pikachu” slackmoji. I don’t know why Pikachu is the mascot of our mornings, but I’ve joined in because it’s a fun gesture of the team’s distinct
collective personality. Also it’s a cute GIF: it’s nice to get waved-at by Pikachu on a morning.
5 Doubly-awesome, the destination’s proximity means that I get to travel by Eurostar
rather than having to fly.
Molly White writes, more-eloquently than I would’ve, almost-exactly my experience of LLMs and similar modern generative
AIs:
…
I, like many others who have experimented with or adopted these products, have found that these tools actually can be pretty useful for some tasks. Though AI
companies are prone to making overblown promises that the tools will shortly be able to replace your content writing team or generate feature-length films or develop a video game from
scratch, the reality is far more mundane: they are handy in the same way that it might occasionally be useful to delegate some tasks to an inexperienced and sometimes sloppy intern.
…
Very much this.
I’ve experimented with a handful of generative AIs, such as:
GPT-3.5 / ChatGPT, for proofreading, summarisation, experimental rephrasing when writing, and idea generation. I’ve found it to be moderately good at summarisation
and proofreading and pretty terrible at producing anything novel without sounding completely artificial and/or getting lost in a hallucination.
Bing for coalescing information. I like that it cites its sources. I dislike that it somehow still hallucinates. I might use it, I suppose, to help me
re-phase a search query where I can’t remember the word I’m looking for.
Stable Diffusion for image generation. I’ve found it most-useful in image-to-image mode, for making low-effort concept art in bulk. For example, when running online
roleplaying games for friends I’ve fed it an image of, say, a skeleton warrior and asked it to make me a few dozen more in a similar style, so as to provide a diverse selection of
distinct tokens1.
Its completely-original2 work lands squarely in
the uncanny valley, though.
Github Copilot for code assistance. I’ve not tried its “chat”-powered functionality but I quite enjoy its “autocomplete” tool. When I’m coding and I forget the syntax
of the command I’m typing, or need to stop and think for a moment about “what comes next”, it’s often there with the answer. I’ve even made us of the “write the comment describing
what the code will do, let Copilot suggest the code for you” paradigm (though I’ve been pretty disappointed with the opposite approach: it doesn’t write great comments!). I find
Copilot to be a lot like having an enthusiastic, eager-to-please, very well-read but somewhat naive junior programmer sitting beside me. If I ask them for some pairing assistance,
they’re great, but I can’t trust them to do anything that I couldn’t do for myself!
Surely others besides that I’ve since forgotten.
Most-recently, I’ve played with music-making AI Suno and… it’s not
great.. but like all these others it’s really interesting to experiment with and think about. Here: let me just ask it to write some “vocal trance europop about a woman called
Molly; Molly has a robot friend who is pretty good at doing many tasks, but the one thing she’ll never trust the robot to do is write in her blog” –
AI-generated content:
[Verse]
Molly’s got a robot that she keeps by her side
It’s pretty handy
It can do many things right
But there’s one task she won’t let it touch
It’s true
The robot can’t write in her blog
No
That won’t do
[Verse 2]
This robot can clean the house
Sweep it up real nice
It can even cook a meal
Add some spice
But when it comes to sharing her thoughts on the screen
Molly won’t trust the robot
That’s her routine
[Chorus]
Molly’s robot friend
By her side all day and night
There’s one thing it can’t do
Can’t write her blog right
She’ll keep typing away
Sharing her heart and soul
That’s something the robot can’t do
It has no control
So yes, like Molly:
I’m absolutely a believer than these kinds of AIs have some value,
I’ve been reluctant and slow to say so because they seem to be such a polarising issue that it’s hard to say that you belong to neither “camp”,
I’m not entirely convinced that for the value they provide they’ve yet proven to be worth their cost, and I’m not certain that for general-purpose generation they will be any time
soon, and
I’ve never used AI to write content for my blog, and I can’t see that ever changing.
It’s still an interesting field to follow-along with. Stuff like Sora from OpenAI and VASA-1 from Microsoft are just scary (the latter seems to have little purpose other than for
misinformation-generation3!),
but the genie’s out of the bottle now.
Footnotes
1 Visually-distinct tokens adds depth to the world and helps players communicate with one
another: “You distract the skinny cultist, and I’ll try to creep up on the ugly one!”
2 I’m going to gloss right over the question of whether or not these tools are capable of
creating anything truly original. You know what I mean.
Like much of the UK, there are local elections where I live next month. After coming home from a week of Three Rings volunteering I found my poll card on the doormat. Can you spot the bleeding-obvious mistake?
Also interesting was that this year the poll card came in a tamper-evidence tear-to-open envelope rather than just being a piece of card. Does the government now think that postal
workers are routinely stealing voter identities? Cohabitees?
This’ll be the first election for which I’ve needed to bring photographic ID to the polling station. That shouldn’t be a problem: I have a passport and driving license and whatnot.
But just to be absolutely certain, I had the local council – the same people who issued me the polling card! – supply me with a voter authority certificate:
Note that this document, also issued by West Oxfordshire District Council, spells my name correctly.
So now I’m in a pickle. West Oxfordshire District Council are asking me to produce photo ID in the wrong name when I turn up at a polling station next month. It doesn’t even
match the name on the photo ID that they themselves issued me.
This would be less-infuriating were it not for the fact that they had my name wrong in the same way on an electoral roll form they sent me in August 20221.
When I contacted them to have them fix it, they promised that the underlying problem was solved2
so this very thing wouldn’t happen.
And yet here we are.
Hopefully they’ll be able to fix their records promptly or else I guess I’ll have to apply for a proxy vote, to allow the ballot of my imaginary friend “Dan Que” to be cast by me, Dan
Q, instead.
And if that isn’t the most bizarre form of election fraud you’ve ever heard of, I don’t know what is.
Update: True to their word, the council had managed to
correct their records by the time I reached the polling station this morning. It’s still a little annoying that they somehow mucked it up in the first place, but I appreciate the
efficiency with which they corrected their mistake.
Footnotes
1 They’d had my name right before August 2022, including on previous poll cards;
I can only assume that some human operator “corrected” it to the wrong thing at some point.
2 They didn’t fix the problem immediately in August 2022. Initially, they
demanded that I produce proof of my change of name from “Dan Que” (which has, of course, never been my name!) to “Dan Q”, and only later backed down and admitted that they’d
made a mistake and would correct the PII they were holding about me.
The younger child and I had an initially fruitless search in, under and around the nearby bridge before we had the sense to insert our babel fishes, after which the hint item became
clear to us. A short search later the cache was in hand. SL, TNLN, TFTC!
The second of two caches found on a morning walk from the nearby Cambridge Belfry Hotel, where some fellow volunteers and I met yesterday for a meeting. This cache looked so close, but
being on the other side of the A428 meant that my route to get from one to the other side of the trunk road necessitated a long and circuitous route around half a dozen (ill-maintained)
pegasus crossings around the perimeter of two large roundabouts! Thankfully traffic was quiet at this point if a Saturday morning.
Cache itself was worth the effort though. Feels like it’s increasingly rare to find a large, appropriately-camouflaged, well looked-after cache in a nice location, so FP awarded. TFTC!
Even early on a Saturday morning, after a volunteering event the previous day at the hotel across the road, this highly-exposed GZ made me
feel vulnerable! It’s not as though anybody were actually watching me as I stood around nonchalantly at the GZ waiting for an opportunity
to make a search: a couple of shop workers setting up, maybe, and a handful of drivers going past… but what got me was that every time I looked up from my rummaging I spotted, in the
corner of my eye, a police officer standing to attention just on the other side of the car park, staring intently in my direction!
The copper in question, of course, was nothing more than a cardboard cut-out designed to spook shoplifters, but man that’s a chilling thing to spot in your peripheral vision when you’re
rooting around in the bushes for a concealed container in a quiet car park!
Signed the log and took a selfie with my law enforcement friend (attached) before getting back to my day. TFTC!
The elder child and I are staying nearby and couldn’t resist coming to a nearby cache with so many FPs. The name gave us a bit of a clue what we would be looking for but nothing could
have prepared us for for this imaginative and unusual container! FP awarded. Attached is very non-spoiler photo of us with our very own Incy
Wincies. Greetings from Oxfordshire!
RotatingSandwiches.com is a website showcasing animated GIF files of rotating
sandwiches1. But it’s got a problem: 2 of the 51 sandwiches rotate the
wrong way. So I’ve fixed it:
The Eggplant Parm Sub is one of two sandwiches whose rotation doesn’t match the rest.
My fix is available as a userscript on GreasyFork, so you can use your
favourite userscript manager2
to install it and the rotation will be fixed for you too. Here’s the code (it’s pretty simple):
1
2
3
4
5
6
7
8
9
10
11
12
// ==UserScript==// @name Standardise sandwich rotation on rotatingsandwiches.com// @namespace rotatingsandwiches.com.danq.me// @match https://rotatingsandwiches.com/*// @grant GM_addStyle// @version 1.0// @author Dan Q <https://danq.me/>// @license The Unlicense / Public Domain// @description Some sandwiches on rotatingsandwiches.com rotate in the opposite direction to the majority. 😡 Let's fix that.// ==/UserScript==
GM_addStyle('.q23-image-216, .q23-image-217 { transform: scaleX(-1); }');
Unless you’re especially agitated by irregular sandwich rotation, this is perhaps the most-pointless userscript ever created. So why did I go to the trouble?
Fixing Websites
Obviously, I’m telling you this as a vehicle to talk about userscripts in general and why you should be using them.
But the real magic is being able to remix the web your way. With just a little bit of CSS or JavaScript experience you
can stop complaining that a website’s design has changed in some way you don’t like or that some functionality you use isn’t as powerful or convenient as you’d like and you can fix
it.
A website I used disables scrolling until all their (tracking, advertising, etc.) JavaScript loads, and my privacy blocker blocks those files: I could cave and disable my browser’s
privacy tools… but it was almost as fast to add setInterval(()=>document.body.style.overflow='', 200); to a userscript and now it’s fixed.
Don’t want a Sports section on your BBC News homepage (not just the RSS
feed!)? document.querySelector('a[href="/sport"]').closest('main > div').remove(). Sorted.
I’m a huge fan of building your own tools to “scratch your own itch”. Userscripts are a highly accessible introduction to doing so that even beginner programmers can get on board with
and start getting value from. More-advanced scripts can do immensely clever and powerful things, but even if you just use them to apply a few light CSS touches to your favourite websites, that’s still a win.
Footnotes
1 Remember when a website’s domain name used to be connected to what it was for?
RotatingSandwiches.com does.
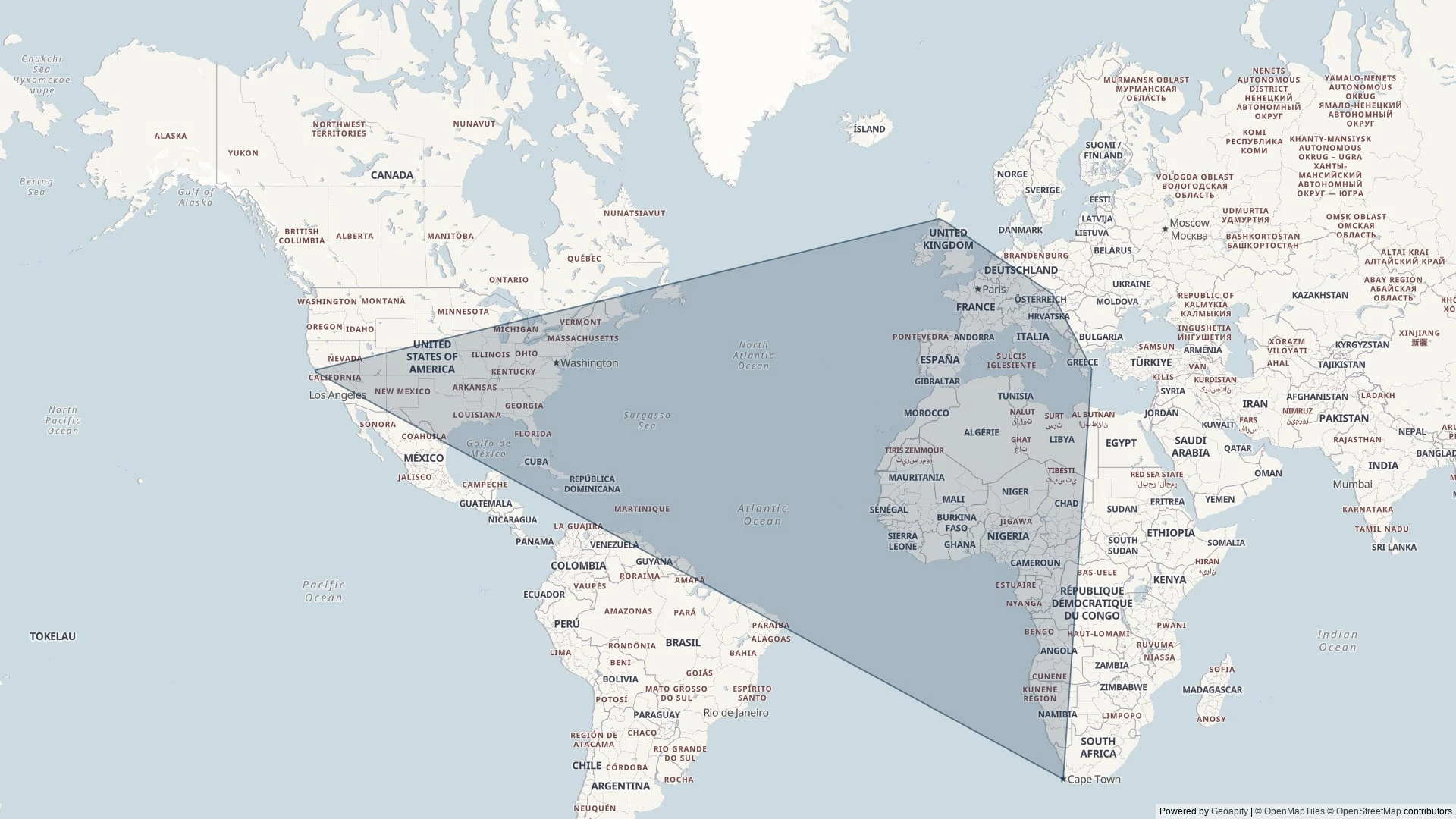
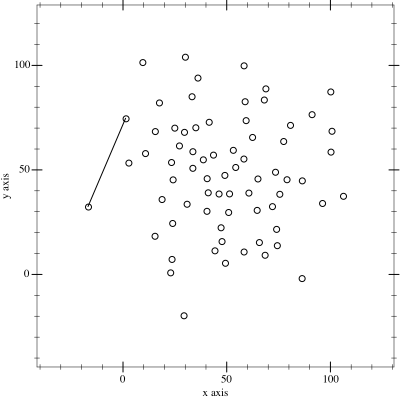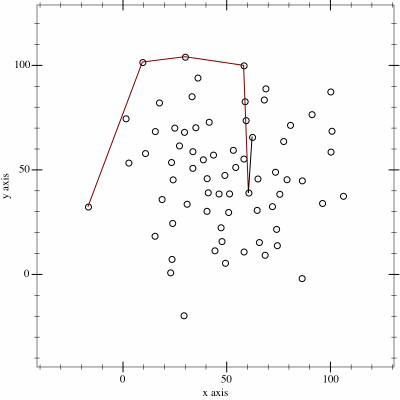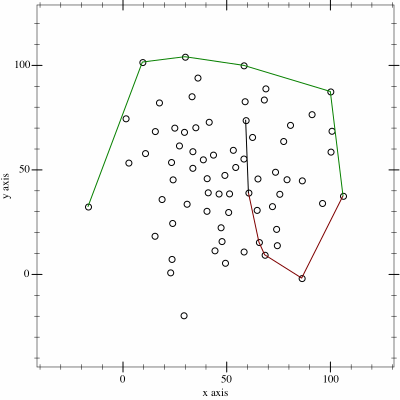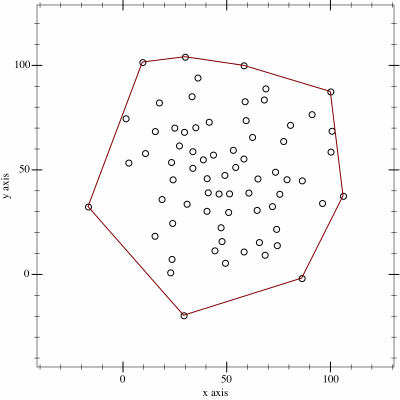
I thought it might be fun to try to map the limits of my geocaching/geohashing. That is, to draw the smallest possible convex polygon that surrounds all of the
geocaches I’ve found and geohashpoints I’ve successfully visited.
Mathematically, such a shape is a convex hull – the smallest polygon encircling a set of points without concavity. Here’s how I made it:
1. Extract all the longitude/latitude pairs for every successful geocaching find and geohashpoint expedition.I keep them in my blog database, so I was able to use some SQL to
fetch them:
SELECTDISTINCT coord_lon.meta_value lon, coord_lat.meta_value lat
FROM wp_posts
LEFTJOIN wp_postmeta expedition_result ON wp_posts.ID = expedition_result.post_id AND expedition_result.meta_key ='checkin_type'LEFTJOIN wp_postmeta coord_lat ON wp_posts.ID = coord_lat.post_id AND coord_lat.meta_key ='checkin_latitude'LEFTJOIN wp_postmeta coord_lon ON wp_posts.ID = coord_lon.post_id AND coord_lon.meta_key ='checkin_longitude'LEFTJOIN wp_term_relationships ON wp_posts.ID = wp_term_relationships.object_id
LEFTJOIN wp_term_taxonomy ON wp_term_relationships.term_taxonomy_id = wp_term_taxonomy.term_taxonomy_id
LEFTJOIN wp_terms ON wp_term_taxonomy.term_id = wp_terms.term_id
WHERE wp_posts.post_type ='post'AND wp_posts.post_status ='publish'AND wp_term_taxonomy.taxonomy ='kind'AND wp_terms.slug ='checkin'AND expedition_result.meta_value IN ('Found it', 'found', 'coordinates reached', 'Attended');
2. Next, I determine the convex hull of these points. There are an interesting variety of
algorithms for this so I adapted the Monotone Chain approach (there are
convenient implementations in many languages). The algorithm seems pretty efficient, although that doesn’t matter much to me because I’m caching the results for a fortnight.
I watched way too many animations of different convex hull algorithms before selecting this one… pretty-much arbitrarily.
An up-to-date (well, no-more than two weeks outdated) version of the map appears on my geo* stats page. I don’t often get to go caching/hashing
outside the bounds already-depicted, but I’m excited to try to find opportunities to push the boundaries outwards as I continue to explore the world!
(I could, I suppose, try to draw a second larger area of places I’ve visited: the difference between the smaller and larger areas would represent all of the opportunities I’d missed to
find a hashpoint!)
Anyway, here’s the best printer for 2024: a Brother laser printer. You can just pick any one you like; I have one with a sheet feeder and one without a sheet feeder. Both of them have
reliably printed return labels and random forms and pictures for my kid to color for years now, and I have never purchased replacement toner for either one. Neither has fallen off the
WiFi or insisted I sign up for an ink-related hostage situation or required me to consider the ongoing schemes of HP executives who seem determined to make people hate a legendary
brand with straightforward cash grabs and weird DRM ideas.
…
It’s sort-of alarming that Brother are the only big player in the printer space who subscribe to a philosophy of “don’t treat the customers like
livestock”. Presumably all it’d take is a board-level decision to flip the switch from “not evil” to “evil” and we’d lose something valuable. Thankfully, for now at least, they still
clearly see the value of the positive marketing the world gives them. Positive marketing like like this article.
The article is excellent, by the way. I know that I’m “supposed” to stir up hatred about the fact that its conclusion is written by an AI but… well, just read it for yourself and you’ll see why I don’t mind even one bit. Top notch reporting. Consider following the links within it to
stories about how other printer manufacturers continue to show exactly how shitty they can be.
I recommended a Brother printer to the Vagina Museum the other month. I assume it ‘s still working out fine for them (and not ripping them off, spying on them, and/or contributing to the
destruction of the the planet).
If you lack the imagination to understand how a game like this could have dozens of possible endings, you desperately need to play it. My favourite path so far through the game was to
add a teabag, then hot water, then remove the teabag, then add some milk, then add a second teabag, then drink it.
Genuinely can’t stop laughing at this masterpiece.