I continue to be sceptical of AI‘s ability to solve 90%+ of the problems that people are trying to solve with it.
But damn, if you’re feeling uninspired as you’re getting ready to start work on a Monday morning, try dumping your to-do list into a songwriting AI like Suno and ask it to write an uplifting song about how you’ll get it finished. It’s like having your very own
cheerleader.
❎ Good ❎ Cheap ☑️ Fast. I guess generative AI is a “choose one” situation, and the one you have to choose is “fast”. But still:
it certainly got me pumped-up and ready to work.
Prompt:uplifting electronic pop about Dan completing his to-do list today: filing his meetup expenses; performance-testing his CircleCI workflow; leading a team
meeting; learning about Full Site Editing
Lyrics:
Filing expenses
Gotta get ’em done
No time to waste
Gotta have some fun
Dan’s on a mission
Gotta stay on track
He’s gonna conquer
Ain’t nothing gonna hold him back
Performance testing
Gonna make it fly
CircleCI workflow
Gonna reach the sky
Dan’s got the focus
He’s in the zone
Gonna make it happen
Gonna make it his own
Leading that team meeting
Gonna show his might
Guiding them forward
Shining so bright
Dan’s a leader
He’s got it all
Inspiring the team
Gonna make ’em stand tall
I think I might be more-prone to nerd sniping when I’m travelling.
Last week, a coworker pointed out an unusually-large chimney on the back of a bus depot and I lost sleep poring over 50s photos of Dutch building sites to try to work out if it was
original.
When a boat tour guide told me that the Netherlands used to have a window tax, I fell down a rabbit hole of how it influenced local architecture and why the influence was different in the UK.
Why does travelling make me more-prone to nerd sniping? Maybe I should see if there’s any likely psychological effect that might cause that…
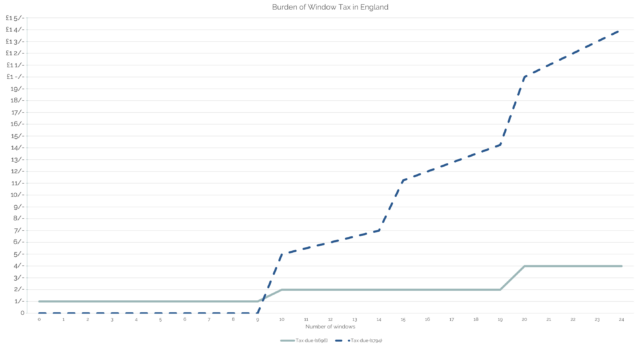
From 1696 until 1851 a “window tax” was imposed in England and Wales1.
Sort-of a precursor to property taxes like council tax today, it used an estimate of the value of a property as an indicator of the wealth of its occupants: counting the number of
windows provided the mechanism for assessment.
The hardest thing about retrospectively graphing the cost of window tax is thinking in “old money”2.
Window tax replaced an earlier hearth tax, following the ascension to the English throne of Mary II and William III of Orange. Hearth tax had come from a similar philosophy: that
you can approximate the wealth of a household by some aspect of their home, in this case the number of stoves and fireplaces they had.
(A particular problem with window tax as enacted is that its “stepping”, which was designed to weigh particularly heavily on the rich with their large houses, was that it similarly
weighed heavily on large multi-tenant buildings, whose landlord would pass on those disproportionate costs to their tenants!)
It’d be temping to blame William and Mary for the window tax, but the reality is more-complex and reflects late renaissance British attitudes to the limits of state authority.
Why a window tax? There’s two ways to answer that:
A window tax – and a hearth tax, for that matter – can be assessed without the necessity of the taxpayer to disclose their income. Income tax, nowadays the most-significant form of
taxation in the UK, was long considered to be too much of an invasion upon personal privacy3.
But compared to a hearth tax, it can be validated from outside the property. Counting people in a property in an era before solid recordkeeping is hard. Counting hearths is
easier… so long as you can get inside the property. Counting windows is easier still and can be done completely from the outside!
If you’re in Britain, finding older buildings with windows bricked-up to save on tax is pretty easy. I took a break from writing this post, walked for three minutes, and found
one.4
There were a few work-related/adjacent activities. But also a table football tournament, among other bits of fun.
One of the things I learned while on this trip was that the Netherlands, too, had a window tax for a time. But there’s an interesting difference.
The Dutch window tax was introduced during the French occupation, under Napoleon, in 1810 – already much later than its equivalent in England – and continued even after he was ousted
and well into the late 19th century. And that leads to a really interesting social side-effect.
My brief interest in 19th century Dutch tax policy was piqued during my team’s boat tour.
Glass manufacturing technique evolved rapidly during the 19th century. At the start of the century, when England’s window tax law was in full swing, glass panes were typically made
using the crown glass process: a bauble of glass would be
spun until centrifugal force stretched it out into a wide disk, getting thinner towards its edge.
The very edge pieces of crown glass were cut into triangles for use in leaded glass, with any useless offcuts recycled; the next-innermost pieces were the thinnest and clearest, and
fetched the highest price for use as windows. By the time you reached the centre you had a thick, often-swirly piece of glass that couldn’t be sold for a high price: you still sometimes
find this kind among the leaded glass in particularly old pub windows5.
They’re getting rarer, but I’ve lived in houses with small original panes of crown glass like these!
As the 19th century wore on, cylinder glass became the norm. This is produced by making an iron cylinder as a mould, blowing glass into it, and then carefully un-rolling the cylinder
while the glass is still viscous to form a reasonably-even and flat sheet. Compared to spun glass, this approach makes it possible to make larger window panes. Also: it scales
more-easily to industrialisation, reducing the cost of glass.
The Dutch window tax survived into the era of large plate glass, and this lead to an interesting phenomenon: rather than have lots of windows, which would be expensive,
late-19th century buildings were constructed with windows that were as large as possible to maximise the ratio of the amount of light they let in to the amount of tax for which
they were liable6.
Look at the size of those windows! If you’re limited in how many you can have, but you’ve got the technology, you’re going to make them as large as you possibly can!
That’s an architectural trend you can still see in Amsterdam (and elsewhere in Holland) today. Even where buildings are renovated or newly-constructed, they tend – or are required by
preservation orders – to mirror the buildings they neighbour, which influences architectural decisions.
Notice how each building has only between one and three windows on the ground floor, letting as much light in while minimising the tax burden.
It’s really interesting to see the different architectural choices produced in two different cities as a side-effect of fundamentally the same economic choice, resulting from slightly
different starting conditions in each (a half-century gap and a land shortage in one). While Britain got fewer windows, the Netherlands got bigger windows, and you can still see the
effects today.
…and social status
But there’s another interesting this about this relatively-recent window tax, and that’s about how people broadcast their social status.
This Google Street Canal (?) View photo shows a house on Keizersgracht, one of the richest parts of Amsterdam. Note the superfluous decorative window above the front door
and the basement-level windows for the servants’ quarters.
In some of the traditionally-wealthiest parts of Amsterdam, you’ll find houses with more windows than you’d expect. In the photo above, notice:
How the window density of the central white building is about twice that of the similar-width building on the left,
That a mostly-decorative window has been installed above the front door, adorned with a decorative
leaded glass pattern, and
At the bottom of the building, below the front door (up the stairs), that a full set of windows has been provided even for the below-ground servants quarters!
When it was first constructed, this building may have been considered especially ostentatious. Its original owners deliberately requested that it be built in a way that would attract a
higher tax bill than would generally have been considered necessary in the city, at the time. The house stood out as a status symbol, like shiny jewellery, fashionable clothes,
or a classy car might today.
I originally wanted to insert a picture here that represented how one might show status through fashion today. But then I remembered I don’t know anything about fashion7. But somehow my stock image search suggested this photo, and I
love it so much I’m using it anyway. You’re welcome.
How did we go wrong? A century and a bit ago the super-wealthy used to demonstrate their status by showing off how much tax they can pay. Nowadays, they generally seem
more-preoccupied with getting away with paying as little as possible, or none8.
Can we bring back 19th-century Dutch social status telegraphing, please?9
Footnotes
1 Following the Treaty of Union the window tax was also applied in Scotland, but
Scotland’s a whole other legal beast that I’m going to quietly ignore for now because it doesn’t really have any bearing on this story.
2 The second-hardest thing about retrospectively graphing the cost of window tax is
finding a reliable source for the rates. I used an archived copy of a guru site about Wolverhampton history.
3 Even relatively-recently, the argument that income tax might be repealed as incompatible
with British values shows up in political debate. Towards the end of the 19th century, Prime Ministers Disraeli and Gladstone could be relied upon to agree with one another on almost
nothing, but both men spoke at length about their desire to abolish income tax, even setting out plans to phase it out… before having to cancel those plans when some
financial emergency showed up. Turns out it’s hard to get rid of.
4 There are, of course, other potential reasons for bricked-up windows – even aesthetic ones – but a bit of a giveaway is if the
bricking-up reduces the number of original windows to 6, 9, 14 or 19, which are thesholds at which the savings gained by bricking-up are the greatest.
5 You’ve probably heard about how glass remains partially-liquid forever and how this
explains why old windows are often thicker at the bottom. You’ve probably also already had it explained to you that this is complete bullshit. I only mention it here to preempt any discussion in the comments.
6 This is even more-pronounced in cities like Amsterdam where a width/frontage tax forced
buildings to be as tall and narrow and as close to their neighbours as possible, further limiting opportunities for access to natural light.
7 Yet I’m willing to learn a surprising amount about Dutch tax law of the 19th century. Go
figure.
I’ve got a (now four-year-old) Unraid NAS called Fox and I’m a huge fan. I particularly love the fact that Unraid can work not only as a NAS, but also as a fully-fledged Docker appliance, enabling me to easily install and maintain all manner of applications.
There isn’t really a generator attached to Fox, just a UPS battery backup. The sign was liberated from our shonky home electrical system.
I was chatting this week to a colleague who was considering getting a similar setup, and he seemed to be taking notes of things he might like to install, once he’s got one. So I figured
I’d round up five of my favourite things to install on an Unraid NAS that:
Don’t require any third-party accounts (low dependencies),
Don’t need any kind of high-powered hardware (low specs), and
Provide value with very little set up (low learning curve).
It’d have been cooler if I’d have secretly written this blog post while sitting alongside said colleague (shh!). But sadly it had to wait until I was home.
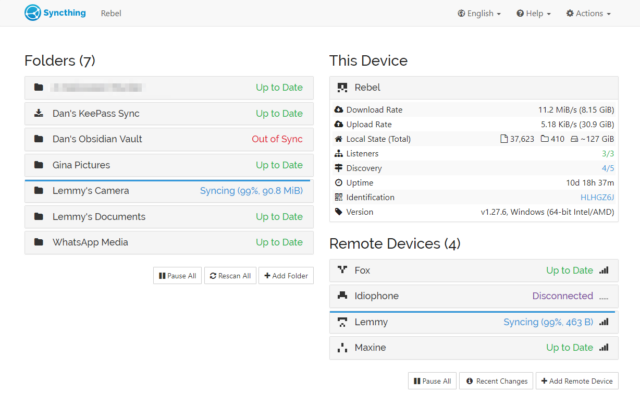
Syncthing’s just an awesome piece of set-and-forget software that facilitates file synchronisation between all of your devices and can also form part of a backup strategy.
Here’s the skinny: you install Syncthing on several devices, then give each the identification key of another to pair them. Now you can add folders on each and “share” them with the
others, and the two are kept in-sync. There’s lots of options for power users, but just as a starting point you can use this to:
Manage the photos on your phone and push copies to your desktop whenever you’re home (like your favourite cloud photo sync service, but selfhosted).
Keep your Obsidian notes in-sync between all your devices (normally costs $4/month).1
Get a copy of the documents from all your devices onto your NAS, for backup purposes (note that sync’ing alone, even with
versioning enabled, is not a good backup: the idea is that you run an actual backup from your NAS!).
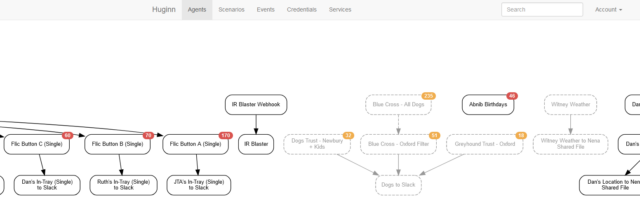
You know IFTTT? Zapier? Services that help you to “automate” things based on inputs and outputs. Huginn’s like that, but selfhosted.
Also: more-powerful.
When we first started looking for a dog to adopt (y’know, before we got this derper), I set up Huginn watchers to monitor the websites of several
rescue centres, filter them by some of our criteria, and push the results to us in real-time on Slack, giving us an edge over other prospective puppy-parents.
The learning curve is steeper than anything else on this list, and I almost didn’t include it for that reason alone. But once you’ve learned your way around its idiosyncrasies and
dipped your toe into the more-advanced Javascript-powered magic it can do, you really begin to unlock its potential.
It couples well with Home Assistant, if that’s your jam. But even without it, you can find yourself automating things you never expected to.
Many of these suggested apps benefit well from you exposing them to the open Web rather than just running them on your LAN,
and an RSS reader is probably the best example (you want to read your news feeds when you’re out and about, right?). What you
need for that is a reverse proxy, and there are lots of guides to doing it super-easily, even if you’re not on a static IP
address.2.
Alternatively you can just VPN in to your home: your router might be able to arrange this, or else Unraid can do it for you!
You know how sometimes you need to give somebody your email address but you don’t actually want to. Like: sure, I’d like you to email me a verification code for this download, but I
don’t trust you not to spam me later! What you need is a disposable email address.3
How do you feel about having infinite email addresses that you can make up on-demand (without even having access to a computer), subscribe to by RSS, and never have to see unless you specifically want to.
You just need to install Open Trashmail, point the MX records of a few domain names or subdomains (you’ve got some spare domain names
lying around, right? if not; they’re pretty cheap…) at it, and it will now accept email to any address on those domains. You can make up addresses off the top of your head,
even away from an Internet connection when using a paper-based form, and they work. You can check them later if you want to… or ignore them forever.
Couple it with an RSS reader, or Huginn, or Slack, and you can get a notification or take some action when an email arrives!
Need to give that escape room your email address to get a copy of your “team photo”? Give them a throwaway, pick up the picture when you get home, and then forget you ever gave it
to them.
Company give you a freebie on your birthday if you sign up their mailing list? Sign up 366 times with them and write a Huginn workflow that puts “today’s” promo code into your
Obsidian notetaking app (Sync’d over Syncthing) but filters out everything else.
Suspect some organisation is selling your email address on to third parties? Give them a unique email address that you only give to them and catch them in a honeypot.
It isn’t pretty, but… it doesn’t need to be! Nobody actually sees the admin interface except you anyway.
Plus, it’s just kinda cool to be able to brand your shortlinks with your own name, right? If you follow only one link from this post, let it be to watch this video
that helps explain why this is important: danq.link/url-shortener-highlights.
I run many, many other Docker containers and virtual machines on my NAS. These five aren’t even the “top five” that I
use… they’re just five that are great starters because they’re easy and pack a lot of joy into their learning curve.
And if your NAS can’t do all the above… consider Unraid for your next NAS!
Footnotes
1 I wrote the beginnings of this post on my phone while in the Channel Tunnel and then
carried on using my desktop computer once I was home. Sync is magic.
2 I can’t share or recommend one reverse proxy guide in particular because I set my own up
because I can configure Nginx in my sleep, but I did a quick search and found several that all look good so I imagine you can do the same. You don’t have to do it on day one, though!
An easy find. Didn’t take nor leave any books, but briefly skimmed the Borland JBuilder 2 Getting Started guide, because it was familiar/nostalgic. Pretty sure I used this tool… about
25 years ago!
An easy find. As a approached I thought that a couple cuddling here might be in my way, but they were just getting ready to leave as I arrived! SL (love
the long thin logbook!), TFTC. Now to make my way back to the station!
Eww. Had to put my hand into two gross holes before finding the (correct) third gross hole I needed to put my hand into. Worth it in the end for a happy smiley face. Thanks for bringing
me to this place and teaching me its history. TFTC!
TFTC! I’m not carrying any tickets for UK transport, but I’ve got a (mildly
defaced) British banknote and I found a tram (the number 13, which connected me to my hotel this week) and a ferry (which I then went and caught to go find some more caches!).
Cash? Not carrying much of that. But my credit card sits at the front of my minimalist wallet and, as a bonus, shows my geocaching username (which is the same as my actual name) without
showing the actual card number. TFTC!
No luck here despite an extended search, the hint, and the spoiler image. Confident I’ve found the right host but no sign in the cache. I wonder if another geocacher is holding it right
now, sitting somewhere nearby to sign the log? Or else it’s probably gone missing. 😢
Love the monument, delighted to see it. Took me a long, long time to find the cache though! Started by looking near the coordinates but couldn’t find anything likely to host the cache.
Spotted a likely host by the waterside and, evert though the coordinates seemed off, gave a good search there before giving up.
Then went to a nearby stall to buy a souvenir of my trip when I realised another possible route to the coordinates. Turns out there’s a big van parked right now blocking access to the
cache! (Looks like they’re setting up for an event, maybe for King’s Day?) Squeezed past and used my phone in selfie mode as a mirror to scan the place I thought the cache might be.
Success! Retrieved cache, signed log, and returned.
Thanks for bringing me here, and for a well-hidden cache. Greetings from Oxfordshire, UK!
After a lot of walking so far this morning I was glad of the opportunity to stop and take a rest nearby while I signed the log. TFTC, and
greetings from Oxfordshire, UK.
Hiding place is a bit damp and grimy but a bit of digging through leaf litter soon revealed the cache. The nearby climbing frame is epic: my kids would love it! Greetings from
Oxfordshire, UK. TFTC.





















{kind=link}