The surgery had happened at a weirdly transitional point in my life. Only a few days earlier I’d performed improv on stage for the first time (see “Yes And” and “Memory Lane“), I’d changed jobs and was contemplating another move. The scar from the surgery seemed to be part of that too,
and I had an idle thought to have a tattoo done on the scar as a permanent reminder to myself not to let work swallow my life up again.
…
Every time I consider getting a tattoo, I’m stopped by the fact that I’m sufficiently indecisive about what I’d get and where. Somehow, a tattoo would represent a sort of irreversible
permanence that I feel is difficult for me to commit to. (I fully accept that this may seem a strange sentiment to many, coming from a
sterilised-without-breeding man – I didn’t say I was consistent!)
But to add personalisation to a scar, especially one with a personal meaning and message: that I can really get behind. Unfortunately my only likely-permanent scars don’t have any
messages behind them more-significant than, for example, “don’t let Dan play with knives”. Is it possible to get a tattoo on top of an emotional scar instead?
Rendering text, how hard could it be? As it turns out, incredibly hard! To my knowledge, literally no system renders text “perfectly”. It’s all best-effort, although some efforts
are more important than others.
…
Just so you have an idea for how a typical text-rendering pipeline works, here’s a quick sketch:
Styling (parse markup, query system for fonts)
Layout (break text into lines)
Shaping (compute the glyphs in a line and their positions)
Rasterization (rasterize needed glyphs into an atlas/cache)
Composition (copy glyphs from the atlas to their desired positions)
Unfortunately, these steps aren’t as clean as they might seem.
…
Delightful dive into the variety of issues that face developers who have to implement text rendering. Turns out this is, and might always remain, an unsolved issue.
Some years ago, a friend of mine told me about an interview they’d had for a junior programming position. Their interviewer was one of that particular breed who was attached to
programming-test questions: if you’re in the field of computer science, you already know that these questions exist. In any case: my friend was asked to write pseudocode to shuffle a
deck of cards: a classic programming problem that pretty much any first-year computer science undergraduate is likely to have considered, if not done.
Let’s play at writing software. Rather than a computer, we’ll use paper. But to make it sound techy, we’ll call it “pseudocode”.
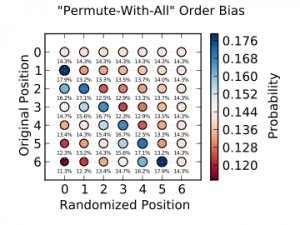
There are lots of wrong ways to programmatically shuffle a deck of cards, such as the classic “swap the card in each position with the card in a randomly-selected position”,
which results in biased
results. In fact, the more that you think in terms of how humans shuffle cards, the less-likely you are to come up with a good answer!
If we shuffled a deck of six cards with this ‘broken’ algorithm, for example, we’d be more-likely to find the card that was originally in second place at the top of the deck than in
any other position. This kind of thing REALLY matters if, for example, you’re running an online casino.
The simplest valid solution is to take a deck of cards and move each card, choosing each at random, into a fresh deck (you can do this as a human, if you like, but it takes a while)…
and that’s exactly what my friend suggested.
The interviewer was ready for this answer, though, and asked my friend if they could think of a “more-efficient” way to do the shuffle. And this is where my friend had a brain fart and
couldn’t think of one. That’s not a big problem in the real world: so long as you can conceive that there exists a more-efficient shuffle, know what to search for, and can
comprehend the explanation you get, then you can still be a perfectly awesome programmer. Demanding that people already know the answer to problems in an interview setting
doesn’t actually tell you anything about their qualities as a programmer, only how well they can memorise answers to stock interview questions (this interviewer should have stopped this
line of inquiry one question sooner).
Writing a program to shuffle a deck takes longer than just shuffling it, but that’s hardly the point, is it?
The interviewer was probably looking for an explanation of the modern form of the Fisher-Yates shuffle algorithm, which does the same thing as my friend suggested but without needing to start a
“separate” deck: here’s a video demonstrating it. When they asked for greater efficiency, the interviewer was probably looking
for a more memory-efficient solution. But that’s not what they said, and it’s certainly not the only way to measure efficiency.
When people ask ineffective interview questions, it annoys me a little. When people ask ineffective interview questions and phrase them ambiguously to boot, that’s just makes
me want to contrive a deliberately-awkward answer.
So: another way to answer the shuffling efficiency question would be to optimise for time-efficiency. If, like my friend, you get a question about improving the efficiency of a
shuffling algorithm and they don’t specify what kind of efficiency (and you’re feeling sarcastic), you’re likely to borrow either of the following algorithms. You won’t find
them any computer science textbook!
Complexity/time-efficiency optimised shuffling
Precompute and store an array of all 52! permutations of a deck of cards. I think you can store a permutation in no more than 226 bits, so I calculate that 2.3 quattuordecillion yottabytes would be plenty sufficient to store such an array. That’s
about 25 sexdecillion times more data than is believed to exist on the Web, so you’re going to need to upgrade your hard drive.
To shuffle a deck, simply select a random number x such that 0 <= x < 52! and retrieve the deck stored at that location.
This converts the O(n) problem that is Fisher-Yates to an O(1) problem, an entire complexity class of improvement.
Sure, you need storage space valued at a few hundred orders of magnitude greater than the world GDP, but if you didn’t specify cost-efficiency, then that’s not what you get.
If you’ve got a thousand galaxies worth of free space you can just fill them with
actual decks of cards – one for each permutation – and physically pick one at random. That sounds convenient, right?
You’re also going to need a really, really good PRNG to ensure that the 226-bit binary number you generate has sufficient entropy. You could always use a real
physical deck of cards to seed it, Solitaire/Pontifex-style, and go full meta, but I
worry that doing so might cause this particular simulation of the Universe to implode, sooo… do it at your own risk?
Perhaps we can do one better, if we’re willing to be a little sillier…
If you live in a universe in which quantum optimised shuffling isn’t possible, the technique below can be adapted to create a universe in which it is.
Assuming the many-worlds interpretation of quantum mechanics is applicable to reality, there’s a
yet-more-efficient way to shuffle a deck of cards, inspired by the excellent (and hilarious) quantum bogosort algorithm:
Create a superposition of all possible states of a deck of cards. This divides the universe into 52! universes; however, the division has no cost, as it happens constantly anyway.
Collapse the waveform by observing your shuffled deck of cards.
The unneeded universes can be destroyed or retained as you see fit.
Let me know if you manage to implement either of these.
Can we solve [the problem of supply-chain attacks] by building trustworthy systems out of untrustworthy parts?
It sounds ridiculous on its face, but the Internet itself was a solution to a similar problem: a reliable network built out of unreliable parts. This was the result of decades of
research. That research continues today, and it’s how we can have highly resilient distributed systems like Google’s network even though none of the individual components are
particularly good. It’s also the philosophy behind much of the cybersecurity industry today: systems watching one another, looking for vulnerabilities and signs of attack.
Security is a lot harder than reliability. We don’t even really know how to build secure systems out of secure parts, let alone out of parts and processes that we can’t trust and
that are almost certainly being subverted by governments and criminals around the world. Current security technologies are nowhere near good enough, though, to defend against these
increasingly sophisticated attacks. So while this is an important part of the solution, and something we need to focus research on, it’s not going to solve our near-term problems.
…
Schneier provides a great summary of the state of play with nation-state supply-chain attacks, using the Huawei 5G controversy as a jumping-off point but with reference to the fact that
China are far from the only country that weaken the security and privacy of the world’s citizens in order to gain an international spying advantage. He goes on to explain what
he sees as the two broad schools of thought are in providing technical solutions to this class of problems, and demonstrates that both are for the time being beyond our reach. The
excerpt above comes from his examination of the second school of thought, and it’s a pretty-compelling illustration of why this is a different class of problem that the ones we’ve used
to build a reliable Internet.
Looks like this cache has been muggled, and its hiding place is no longer usable. I’ll look to see if it can be moved somewhere else in the vicinity and the puzzle updated accordingly.
Perhaps three people will read this essay, including my parents. Despite that, I feel an immense sense of accomplishment. I’ve been sitting on buses for years, but I have more to
show for my last month of bus rides than the rest of that time combined.
Smartphones, I’ve decided, are not evil. This entire essay was composed on an iPhone. What’s evil is passive consumption, in all its forms.
A side-effect of social media culture (repost, reshare, subscribe, like) is that it’s found perhaps the minimum-effort activity that humans can do that still fulfils our need
to feel like we’ve participated in our society. With one tap we can pass on a meme or a funny photo or an outrageous news story. Or we can give a virtual thumbs-up or a heart on a
friend’s holiday snaps, representing the entirety of our social interactions with them. We’re encouraged to create the smallest, lightest content possible: forty words into a Tweet, a
picture on Instagram that we took seconds ago and might never look at again, on Facebook… whatever Facebook’s for these days. The “new ‘netiquette” is complicated.
I, for one, think it’d be a better world if it saw a greater diversity of online content. Instead of many millions of followers of each of a million content creators, wouldn’t it be
nice to see mere thousands of each of billions? I don’t propose to erode the fame of those who’ve achieved Internet celebrity; but I’d love to migrate towards a culture in which we can
all better support one another’s drive to create original content online. And do so ourselves.
The best time to write on your blog is… well, let’s be honest, it was a decade ago. But the second best time is right now. Or if you’d rather draw, or sing, or dance, or make puzzles or
games or films… do that. The barrier to being a content creator has never been lower: publishing is basically free and virtually any digital medium is accessible from even the
simplest of devices. Go make something, and share it with the world.
For the last few months, I’ve been running an alpha test of an email-based subscription to DanQ.me with a handful of handpicked testers. Now, I’d like to open it up to a slightly larger
beta test group. If you’d like to get the latest from this site directly in your inbox, just provide your email address below:
Subscribe by email!
Who’s this for?
Some people prefer to use their email inbox to subscribe to things. If that’s you: great!
What will I receive?
You’ll get a “daily digest”, no more than once per day, summarising everything I’ve published within the last 24 hours. It usually works: occasionally
but not often it misses things. You can unsubscribe with one click at any time.
How else can I subscribe?
You can still subscribe in a variety of other ways. Personally, I recommend using a feed reader which lets you choose exactly which kinds of content
you’re interested in, but there are plenty of options including Facebook and Twitter (for those of such an inclination).
Didn’t you do this before?
Yes, I ran a “subscribe by email” system back in 2007 but didn’t maintain it. Things might be better this time around. Maybe.
I’m not sure which is the most-hypnotic in this video: the graceful click-clack motion of the finished product or the careful and methodical production steps that precede it. Either
way, this perpetual calendar is brilliant, but if I owned it I’d absolutely spend the entire time playing with it rather than using it for its intended purpose.
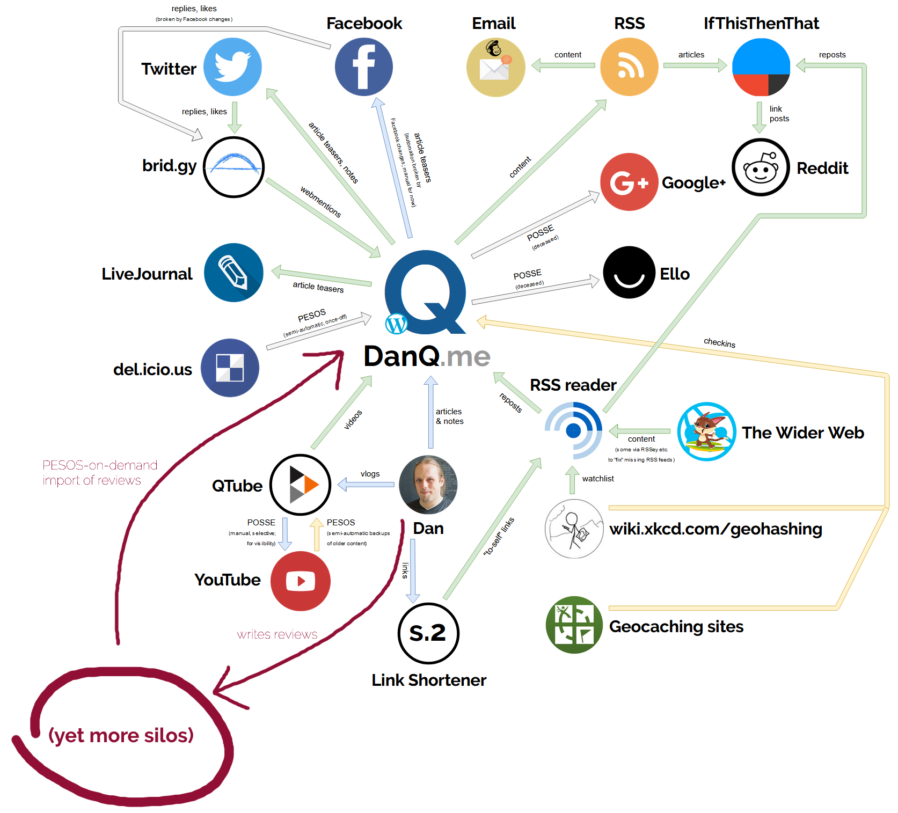
When I arrived at this weekend’s IndieWebCamp I still wasn’t sure what it was that I would be
working on. I’d worked recently to better understand the ecosystem surrounding DanQ.me and had a number of half-formed ideas about tightening
it up. But instead, I ended up expanding the reach of my “personal web” considerably by adding reviews as a post type to my site and building
tools to retroactively-reintegrate reviews I’d written on other silos.
The oldest surviving review I found was my grumbling about Windows XP Home edition being just a crippled version of Pro edition. And now it’s immortalised here.
Over the years, I’ve written reviews of products using Amazon and Steam and of places using Google Maps and TripAdvisor. These are silos and my
content there is out of my control and could, for example, be deleted at a moment’s notice. This risk was particularly fresh in my mind as my friend Jen‘s Twitter account was suspended this weekend for allegedly violating the platform’s rules
(though Twitter have so far proven unwilling to tell her which rules she’s broken or even when she did so, and she’s been left completely in the dark).
My mission for the weekend was to:
Come up with a mechanism for the (microformat-friendly) display of reviews on this site, and
Reintegrate my reviews from Amazon, Steam, Google Maps and TripAdvisor
Steam reviews use a “thumbs up/thumbs down” rating system rather than a “5-star” style, but h-review is capable of expressing both and more.
I opted not to set up an ongoing POSSE nor PESOS process at this point; I’ll do this manually in the short term (I don’t write reviews on third-party sites often). Also out of
scope were some other sites on which I’ve found that I’ve posted reviews, for example BoardGameGeek. These can both be tasks for a future date.
The lovely diagram I drew earlier this year? Here it is with the new loop drawn on.
I used Google Takeout to export my Google Maps reviews, which comprised the largest number of reviews of the sites I targetted and which is the
least screen-scraper friendly. I wrote a bookmarklet-based screen-scraper to get the contents of my reviews on each of the other sites. Meanwhile, I edited by WordPress theme’s functions.php to extended the Post Kinds plugin with an
extra type of post, Review, and designed a content template which wrapped reviews in appropriate microformat markup, using metadata attached to each review post to show e.g. a
rating, embed a h-product (for products) or h-card (for
places). I also leveraged my existing work from last summer’s effort to reintegrate my geo*ing logs to automatically
add a map when I review a “place”. Finally, I threw together a quick WordPress plugin to import the data and create a stack of draft posts for proofing and publication.
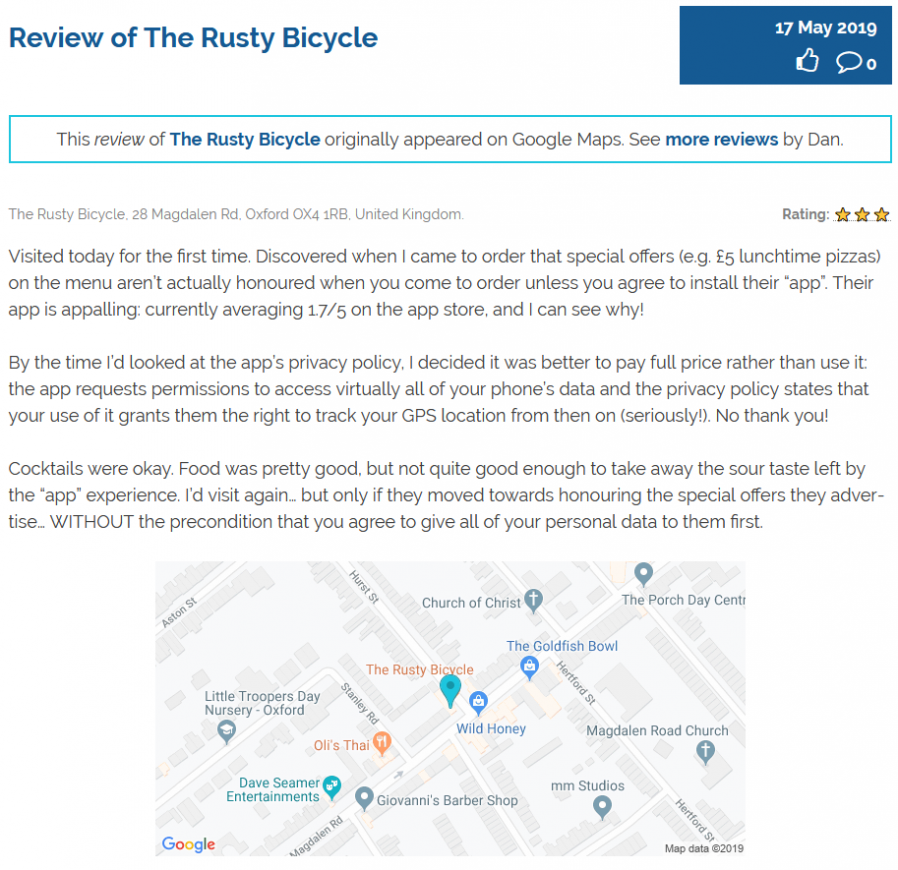
I was moderately unimpressed by Oxford pub The Rusty Bicycle. I originally said so on Google Maps, and now I can say so here, too!
So now you can read all of the reviews I’ve ever posted to any of those four sites, right here, alongside any other reviews I subsequently reintegrate and any
I write directly to my blog in the future. The battle to own all of my own content after 25 years of scattering it throughout the Internet isn’t always easy, but it remains worthwhile.
(I haven’t open-sourced my work this time because it’s probably useful only to me and my very-specific set-up, but if anybody wants a copy they can get in
touch.)
Performed routine maintenance at the cache site; everything seems well.
A couple of ‘cachers have reported that the GZ is inaccessible owing to the path being overgrown. The “obvious” path to the cache really is pretty heavily overgrown and I’ll be
increasing the terrain rating from 3 to 3.5 accordingly, but the “obvious” path isn’t the only path! If you need a hint as to the direction from which the alternative path (which is
quite a bit longer, but much more-usable) comes, see my GZ video below:
Very occasionally I get asked how to start blogging by people who would like to create exciting and engaging articles that will build a following by delighting an audience hungry
for more. Perhaps they envision spreading their views far across the face of the web.
To which I always reply, “Have you read my blog? I don’t know about any of those things!”
What I do have are 10 years of logs and some vague observations about beginning a blog.
…
As I’m sat here anyway, helping people get started on the Indieweb, here’s a great (tongue in cheek) look at
how you can expect your new blog Indieweb presence to take off and become the Most Popular Thing Ever. Or rather, not.
But as I and others have said before, my blog is first and foremost for me. If you get something out of it too, that’s great, but
that’s a secondary goal!





 a
a body
body canvas
canvas