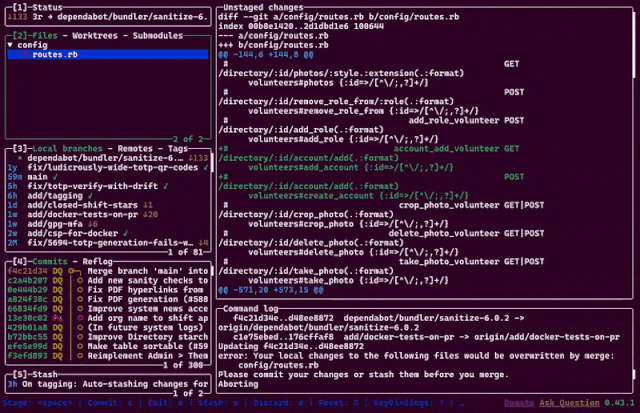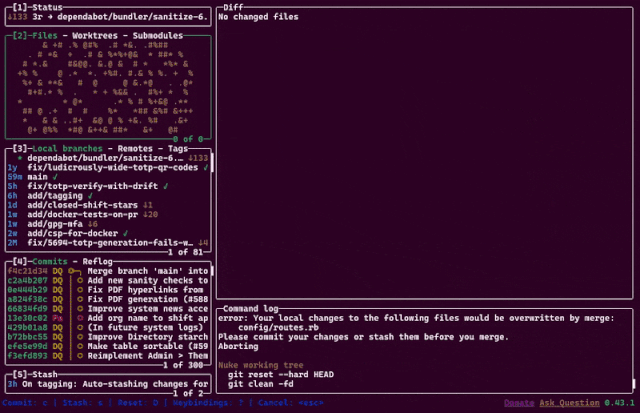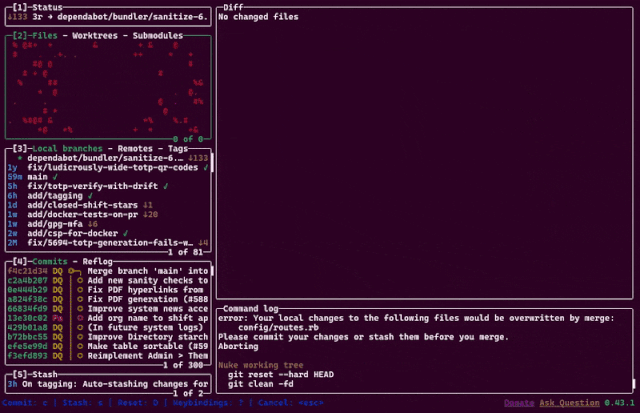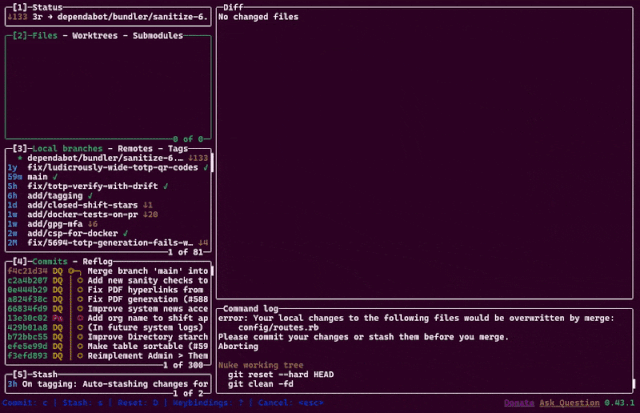
Today was my first day back at work after three months of paid leave1. I’d meant to write about the overall experience of my sabbatical and the things I gained
from it before I returned, but I’m glad I didn’t because one of the lessons only crystallised this morning.
This is about the point on the way back from the school run at which I pull out my phone and see what’s happening in the world or at work. But not today.
My typical work schedule sees me wake up some time before 06:30 so I can check my notifications, formulate my to-do list for the day, and so on, before the kids get up. Then I can focus
on getting them full of breakfast, dressed, and to school, and when I come back to my desk I’ve already got my day planned-out. It’s always felt like a good way to bookend my day, and
it leans into my “early bird” propensities2.
Over the last few years, I’ve made a habit of pulling out my phone and checking for any new work Slack conversations while on the way back after dropping the kids at school. By this
point it’s about 08:45 which is approximately the time of day that all of my immediate teammates – who span five timezones – have all checked-in. This, of course, required that I was
signed in to work Slack on my personal phone, but I’d come to legitimise this bit of undisciplined work/life-balance interaction by virtue of the fact that, for example, walking the dog
home from the school run was “downtime” anyway. What harm could it do to start doing “work” things ten minutes early?
Here. Here is where work happens (or, y’know, anywhere I take my work laptop to… but the crucial thing is that work has a time and a place, and it doesn’t include “while walking the
dog home after dropping the kids at school”).
But walking the dog isn’t “downtime”. It’s personal time. When I’m looking at your phone and thinking about work I’m actively choosing not to be looking at the
beautiful countryside that I’m fortunate enough to be able to enjoy each morning, and not to be thinking about… whatever I might like to be thinking about! By blurring my
work/life-balance I’m curtailing my own freedom, and that’s bad for both my work and personal lives!
My colleague Kyle recently returned from six months of parental leave and shared some wisdom with me, which I’ll
attempt to paraphrase here:
It takes some time at a new job before you learn all of the optimisations you might benefit from making to your life. This particular workflow. That particular notetaking strategy. By
the time you’ve come up with the best answers for you, there’s too much inertia to overcome for you to meaningfully enact personal change.
Coming back from an extended period of leave provides the opportunity to “reboot” the way you work. You’re still informed by all of your previous experience, but you’re newly blessed
with a clean slate within which to implement new frameworks.
He’s right. I’ve experienced this phenomenon when changing roles within an organisation, but there’s an even stronger opportunity, without parallel, to “reboot” your way of
working when returning from a sabbatical. I’ve got several things I’d like to try on this second chapter at Automattic. But the first one is that I’m not connecting my personal phone to
my work Slack account.
2 Mysteriously, and without warning, at about the age of 30 I switched from being a “night
owl” to being an “early bird”, becoming a fun piece of anecdotal evidence against the idea that a person’s preference is genetic or otherwise locked-in at or soon after
birth. As I’ve put it since: “I’ve become one of those chirpy, energetic ‘morning people’ that I used to hate so much when I was younger.”.
The final weekend of my sabbatical was spent, like the first one, at a Three Rings event. As a side activity to the volunteer work, everybody was asked to put their name on a paper
plate and leave it on a particular table, allowing others to semi-anonymously add compliments, thanks, or kind words about its owner.
Comments on my plate:
* Your my faveriot [sic] brother (gee, I wonder who THAT one was from 😂)
* Always seems to be doing interesting things. A maverick! Thinks outside the box
* Awesome
* Thank you for inventing this (a) system & (b) corporate model!
* Always smiley and excited
* Thanks for always pushing lots of new features!
* Puts up with idiots willingly and patiently
* You literally dreampt this whole thing into existence!
* Quirky
* Innovative solutions!
* Helpful in all ways!
Another book I received at Christmas Eve’s book exchange was We’ll Prescribe You A Cat by Syou Ishida,
translated from the original Japanese by Emmie Madison Shimoda. It’s apparently won all kinds of acclaim and awards and what-have-you, so I was hoping for something pretty spectacular.
It’s… pretty good, I guess? Less a novel, it’s more like a collection of short stories with an overarching theme, within which a deeper plot which spans them all begins to emerge… but
is never entirely resolved.
That repeating theme might be summed up as this: a person goes to visit a clinic – often under the illusion that it’s a psychiatric specialist – where, after briefly discussing their
problems with the doctor, they’re prescribed a dose of “cat” for some number of days. There’s a surprising and fun humour in the prescription, each time: the matter-of-fact way that the
doctor dispenses felines as if they were medications and resulting reactions of his nonplussed patients. Fundamentally, a prescription of cat works, and by the time the cat is returned
to the clinic, its caretaker is cured, albeit not necessarily in the way in which they would have originally expected.
Standing alone, each chapter short story is excellent. The writing is compelling and rich and the characters well-developed, particularly in the short timeframes in which we
get to know each of them. There’s a lot of interesting bits of Japanese culture represented, too, which – as an outsider – piqued my curiosity: whether by the careful work of the author
or her translator it never left me feeling lost, although I suspect there might be a few subtler points I missed as a result of my geographic bias1.
The characters (whether human, feline, or… otherwise…?) and their situations are quirky and amusing, and there are a handful of heart-warming… and heart-wrenching… moments that I
thoroughly enjoyed. But by the time I was half-way through the book, I was becoming invested in a payoff that would never come to be delivered. The nature of the doctor, his
receptionist, and their somewhat-magical clinic is never really resolved, and the interconnections between the patients is close to non-existent, leaving the book feeling like a
collection of tales that are related to… but not connected to… one another. As much as I’d enjoyed every story – and I did! – I nonetheless felt robbed of the opportunity to
wrap up the theme that they belong to.
Instead, we’re given just more unanswered questions: hints at the nature of the clinic and its occupants, ideas that skirt around ideas of magic and ghosts, and no real explanation.
Maybe the author’s planning to address it in the upcoming sequel, but unless I’m confident that’s the case, I’ll probably skip it.
In summary: some beautifully-written short stories with a common theme and a fun lens on Japanese culture, particularly likely to appeal to a cat lover, but with no payoff for getting
invested in the overarching plot.
Footnotes
1 Ishida spends a significant amount of intention describing the regional accents of
various secondary characters, and comparing those to the Kyoto dialect, for example. I’m pretty sure there’s more I could take from this if I had the cultural foothold to better
understand the relevance! But most of the cultural differences are less-mysterious.
This is funny, but I’m confident Wrexham’s potholes have nothing on the Trinbagonian ones I’ve been experiencing all
week, which have sometimes spanned most of the width of a road or been deep enough that dipping a wheel into them would strike the road with your underchassis!
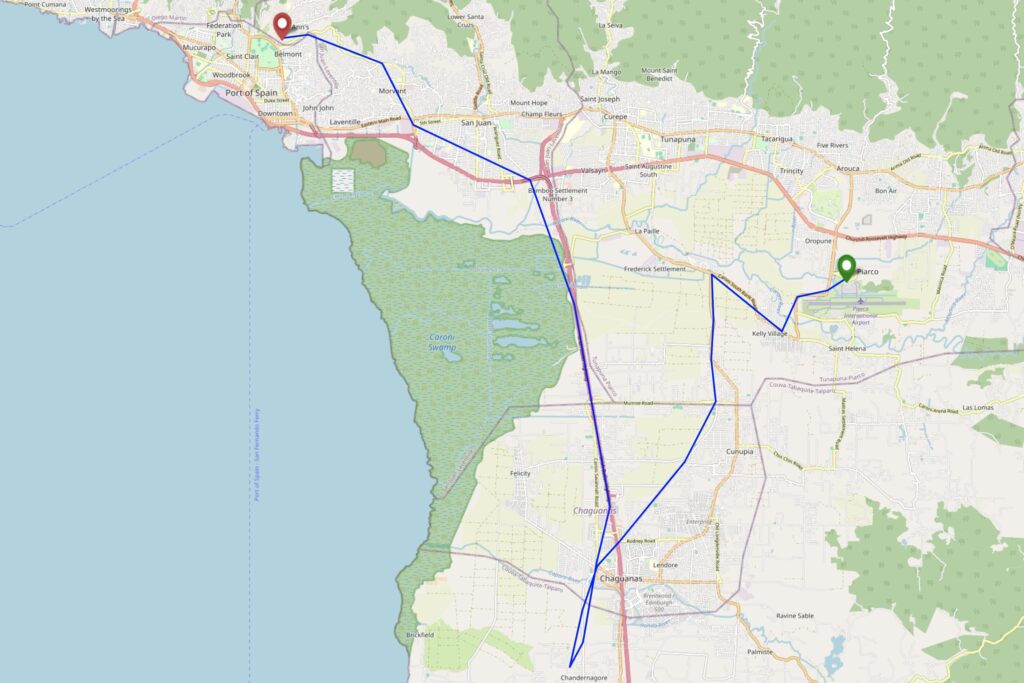
Yesterday, Ruth and I made the first ever attempt at a geohashing expedition in Trinidad & Tobago, successfully finding a hashpoint in Chase Village in the West of Trinidad!
I’ve been on holiday on the islands of Trinidad & Tobago this week. These island nations span graticules that are dominated by the Caribbean and Atlantic Oceans, so it’s little wonder
there’s never been an attempted geohashing expedition in them. So when a hashpoint popped-up in a possibly-accessible location, I had to go for it!
For additional context: Trinidad & Tobago is currently under a state of
emergency as gang warfare and an escalating murder rate has reached a peak. It’s probably ill-advised to go far off the beaten track, especially as somebody who’s clearly a foreign
tourist. The violence and danger is especially prevalent in and around parts of nearby Port of Spain.
As a result, my partner Ruth (wisely) agreed to drive with me to the GZ strictly under the understanding that we’d turn back at a moment’s notice if anything looked remotely sketchy,
and we’d take every precaution on the way to, from, and at the hashpoint area (e.g. keeping car doors locked when travelling and not getting out unless necessary and safe to do so,
keeping valuables hidden out of sight, knowing the location of the nearest police station at any time, etc.).
I don’t have my regular geohashing kit with me, but I’ve got a smartphone, uLogger sending 5-minute GPS location pings (and the ability to send a location when I press a button in the
app, for proof later), and a little bravery, so here we go…
Expedition
Our plane from Tobago landed around 15:20 local time, following an ahead-of-schedule flight assisted by a tailwind from the Atlantic side. We disembarked, collected our bags, and
proceeded to pick up a hire car.
Our Caribbean Airlines aircraft, landed at Piarco airport.
Our original plan for our stay in Trinidad had been to drive up to an AirBnB near 10.743817, -61.514248 on Paramin, one of Tobago’s highest summits. However,
our experience of driving up Mount Dillon on Tobago earlier in the week showed us that the rural
mountain roads around here can be terrifyingly dangerous for non-locals1,
and so we chickened out and investigated the possibility of arranging a last-minute stay at a lodge on the edge of the rainforest in Gran Couva, or else failing that a fallback plan of
a conventional tourist-centric hotel in the North of Port of Spain.
By this point, we’d determined that the hashpoint was in the old sugar growing region of Caroni, in which our originally-intended accommodation at Gran Couva could be found, and so it
seemed feasible that we might be able to safely deviate from our route only a little to get to the hashpoint before reaching our beds. We were particularly keen to be at a place of
known safety before the sun set, here in an unusual part of an unfamiliar country! So when the owner of our proposed lodge in Gran Couva called to say that he couldn’t accept our
last-minute booking on account of ongoing renovations to his property, we had to quickly arrange ourself a room at our backup hotel.
This put us in an awkward position: now the hashpoint really wasn’t anything-like on the way from the airport to where we’d be staying, and we’d doubtless be spending longer
than we’d like to be on the road and increasing the risk that we’d be out after dark. I reassured Ruth, whose appetite for risk is somewhat lower than mine, that if we set out for the
hashpoint and anything seemed “off” we could turn around at any time, and we began our journey.
Putting a brave/excited face on as we set off in our rental car.
Boosted by her experience of driving on Tobago, Ruth continued to show her rapidly-developing Trinbagonian road skills2.
Driving down a network of crisscrossing roads.
Despite increasingly heavy traffic on our minor roads, possibly resulting from a crash that had occurred on the Southbound carriageway of the nearby Uriah Butler Highway which was
causing drivers to seek a shortcut through the suburbs, we made reasonable time, and were soon in the vicinity of the hashpoint: a mixed-use residential/light commercial estate of the
kind that apparently sprung up in places that were, until very late in the 20th century, lands used for sugar cane plantations.
At this point, the maps started to become less and less useful: Google Maps, OpenStreetMap, and Bing Maps completely disagreed as to whether we were driving on Bhagan Trace, Cemetery
Street, or Roy Gobin Fifth Avenue, as well as disagreeing on whether we were driving into a cul-de-sac or whether it was possible to loop around at the end to return back to the main
roads. It was now almost 17:00 and we were greeted by a large number of cars coming out of the narrow street in the opposite direction to us, going in, and squeezing past us: presumably
workers from one of the businesses down here going home for the evening.
There are highways we’d been recommended to avoid because of the safety situation here, but this one was okay.
My GPS flickered as it tried to make sense of the patchwork of streets, and I asked Ruth to slow down and pull over a couple of times until I was sure that we’d gotten as close as we
could, by road. Looking out of my window, I saw the empty lot that I’d scouted from satellite photography, but it was hopelessly overgrown. If the hashpoint was within it, it’d take
hours of work and a machete to cut through. The circle of uncertainty jumped around as I tried to finalise the signal without daring to do the obvious thing of holding my phone outside
the car window. A handful of locals watched us, the strange white folks sitting in a new car, as I poked at my devices in an effort to check if we were within the circle, or at least if
we would be when, imminently, we were forced to park even closer to the side to let a larger vehicle force its way through next to us!
Pulled up at the hashpoint.
At the point at which I thought we’d made it, I hit the “save waypoint” at 17:06 button and instructed Ruth to drive on. We turned in the road and I started navigating us to our hotel,
only thinking to look at the final location I’d tagged later, when we felt safer. We drove back into Port of Spain avoiding Laventille (another zone we’d been particularly recommended
to stay away from) while I resisted the urge to double-check my tracklog, instead focussing on trying to provide solid directions through not-always-signposted streets: we had a wrong
turning at one point when we came off the highway at Bamboo Settlement No. 1 (10.627952, -61.429083) but thankfully this was an easy mistake to course-correct from.
View of the hashpoint again as we turn to go home
It was only when I looked at my tracklog, later, that I discovered that the point I’d tagged was exactly 8.59 metres from the hashpoint, plus or minus a circle of uncertainty of… 9
metres. Amazingly, we’d succeeded without even being certain we’d done so. Having failed to get a silly grin photo at the hashpoint, we sufficed to get one while we drank
celebratory Prosecco and ate tapas on the rooftop bar of our hotel, looking down on the beautiful bay and imposing mountains of this beautiful if intimidating island.
Silly drinky grins atop our hotel North of Port of Spain
Tracklog
I didn’t bring my primary GPSr, but my phone keeps a general-purpose tracklog at ~5min/50m
intervals, and when I prompt it to. Apologies that this makes my route map look “jumpier” than usual, especially when I’m away from the GZ.
Achievements
Footnotes
1 Often, when speaking to locals, they’d ask if it was our first time in Trinidad &
Tobago, and on learning that it was, they’d be shocked to hear that we’d opted to drive for ourselves rather than to hire drivers to take us places: it turns out that the roads are in
very-variable condition, from wonderfully-maintained highways to rural trails barely-driveable without a 4×4, but locals in both drive with the same kind of assertive and sometimes
reckless attitude.
2 tl;dr of driving in Trinidad & Tobago, as somebody who learned to drive in the UK: (1)
if you need to get out of anywhere, don’t wait for anybody to yield because they won’t, even if you theoretically have the right of way: instead, force your way out by obstructing
others, (2) drive in the middle of the road wherever possible to make it easier to dodge potholes and other hazards, which are clustered near the soft verges, and swing to your own
side of the road only at the last second to avoid collisions, and (3) use your horn as often as you like and for any purpose: to indicate that you want to turn, to warn somebody that
you’re there, to tell somebody to move, to say hello to a nearby pedestrian you recognise, or in lieu of turning on your headlights at night, for example. The car horn is a universal
language, it seems.
As part of our trip to the two-island republic of Trinidad & Tobago, Ruth and I decided we’d love to take a
trip out to Buccoo Reef, off the coast of the smaller island. The place we’ve been staying
during the Tobago leg of our visit made a couple of phone calls for us and suggested that we head on down to the boardwalk at nearby Buccoo the next morning where we’d apparently be
able to meet somebody from Pops Tours who’d be able to take us out1.
I could have shown you a picture of the fun ‘I ♥️ Buccoo’ sign from the boardwalk, but I got distracted by a Magnificent Frigatebird circling overhead2.
At the allotted time, we found somebody from Pops Tours, who said that he was still waiting for their captain to get there3
and asked us to go sit under the almond tree down the other end of the boardwalk and he’d meet us there.
It was only after we left to follow the instructions that I remembered that I don’t know how to identify an almond tree. So we opted to sit under a tree near a chicken teaching her
chicks how to eat a coconut4. I still don’t know if that was right, but the boaters found us in the
end so it can’t have been too far off.
We’d previously clocked that one of the many small boats moored in the bay was Cariad, and found ourselves intensely curious. All of the other
boats we’d seen had English-language names of the kinds you’d expect: a well-equipped pleasure craft optimistically named Fish Finder, a small dual-motorcraft with the moniker
Bounty, a brightly-coloured party boat named Cool Runnings, and so on. To travel a third of the way around the world to find a boat named in a familiar Welsh word felt
strange.
Either you’re an extremely long way from home, boat, or else somebody around here has a surprising interest in the Welsh language.
So imagine our delight when the fella we’d been chatting to came over, explained that their regular tour boat (presumably the one pictured on their website) was in the shop, and said
that his cousin would be taking us out in his boat instead… and that cousin came over piloting… the Cariad!
As we climbed aboard, we spotted that he was wearing a t-shirt with a Welsh dragon on it, and a sticker on the side of the helm carried a Welsh flag. What strange coincidence is this,
that Ruth and I – who met while living in Wales and come for a romantic getaway to the Caribbean – should happen to find ourselves aboard a literal “love” boat named in Welsh.
Long shallow sandbars and reefs almost surround the islands of Trinidad and Tobago, leaving enormous areas accessible only to low-draft boats (and helping to protect the islands from
some of the worst of the weather that the Caribbean can muster).
There probably aren’t many boats on Earth that fly both the colours of Trinidad & Tobago and of Wales, so we naturally had to ask: did you name this boat?, and why? It
turns out that yes, our guide for the day has a love of and fascination with Wales that we never quite got to the bottom of. He’d taken a holiday to Swansea just last year, and would be
returning to Wales again later this year.
It’s strange to think that anybody might deliberately take a holiday from a tropical island paradise to come to drizzly cold Wales, but there you have it. It sounds like he was
into his football and that might have had an impact on his choice of destination, but choose to believe that maybe there’s a certain affinity between parts of the world that have
experienced historical oppression at the hands of a colonial English mindset? Like: perhaps Nigerians would enjoy India as a getaway destination, or Guyanans would dig Mauritius as a
holiday spot, too?5
I wrote previously about visiting the Nylon Pool, an waist-deep bit of ocean on a sandbar a full half a mile offshore.
We took a dip at the Nylon Pool, snorkelled around parts of Buccoo Reef (replete with tropical fish of infinite variety and colour), spotted sea turtles zipping around the boat, and
took a walk along No Man’s Land (a curious peninsula, long and thin and cut-off from the mainland by mangrove swamps, so-named
because Trinidadian law prohibits claiming ownership of any land within a certain distance of the high tide mark… and this particular beach spot consists entirely of such land,
coast-to-coast, on account of its extreme narrowness. All in all, it was a delightful boating adventure.
(And for the benefit of the prospective tourist who stumbles upon this blog post in years to come, having somehow hit the right combination of keywords: we paid $400 TTD6
for the pair of us: that’s about £48 GBP at today’s exchange rate, which felt like exceptional value for an amazing experience given that we got the expedition entirely to ourselves.)
Any worries I might have had about the seaworthiness of our vessel as its owner repeatedly bailed out the back of the boat with a small bucket were quickly assuaged when I realised
that I could probably walk most of the way back to shore, should I need to! (sadly not visible: the Welsh dragon on front of his t-shirt)
But aside from the fantastic voyage we got to go on, this expedition was noteworthy in particular for Cariad and her cymruphile captain. It feels like a special kind of
small-world serendipity to discover such immediate and significant common ground with a stranger on the other side of an ocean… to coincide upon a shared interest in a culture and place
less-foreign to you than to your host.
An enormous diolch yn fawr7 is due to Pops Tours for this remarkable experience.
Footnotes
1 Can I take a moment to observe how much easier it was to charter a boat in Tobago than
it was in Ireland, where I left several answerphone messages but never even got a response? Although in the Irish boat
owners’ defence, I was being creepy and mysterious by asking them to take me to random coordinates off the coast.
2 It’s possible that I’ve become slightly obsessed with frigatebirds since arriving here.
I first spotted them from our ferry ride from Trinidad to Tobago, noticing their unusually widely-forked tails, striking white (in the case of the
females) chests, and relatively-effortless (for a seabird) thermal-chasing flight. But they’re really cool! They’re a seabird… that isn’t waterproof and can’t swim… if they land in
the water, they’re at serious risk of drowning! (Their lack of water-resistant feathers helps with their agility, most-likely.) Anyway – while they can snatch
shallow-swimming prey out of the water, they seem to prefer to (and get at least 40% of their food from) stealing it from other birds, harassing them in-flight and snatching it from
their bills, or else attacking them until they throw up and grabbing their victim’s vomit as it falls. Nature is weird and amazing.
3 Time works differently here. If you schedule something, it’s more a guideline than it is
a timetable. When Ruth and I would try paddleboarding a few days later we turned up at the rental shack at their published opening time and hung out on the beach for most of an hour
before messaging the owners via the number on their sign. After 15 minutes we got a response that said they’d be there in 10 minutes. They got there 20 minutes later and opened their
shop. I’m not complaining – the beach was lovely and just lounging around in the warm sea air with a cold drink from a nearby bar was great – but I learned from the experience that if
you’re planning to meet somebody at a particular time here, you might consider bringing a book. (Last-minute postscript: while trying to arrange our next accommodation, alongside
writing this post, I was told that I’d receive a phone call “in half an hour” to arrange payment: that was over an hour ago…)
4 Come for the story of small-world serendipity; stay for the copious candid bird photos,
I guess?
6 Exceptionally-geeky footnote time. The correct currency symbol for the Trinidad & Tobago
Dollar is an S-shape with two vertical bars through it, which is not quite the same as the conventional S-shape with a single vertical bar that you’re probably used to seeing
when referring to e.g. American, Canadian, or Australian dollars. Because I’m a sucker for typographical correctness, I decided that I’d try to type it “the right way” here in my blog
post, and figured that Unicode had solved this problem for me: the single-bar dollar sign that’s easy to type on your keyboard inherits its codepoint from ASCII, I guessed, so the
double-bar dollar sign would be elsewhere in Unicode-space, right? Like how Unicode defines single-bar (pound) and double-bar (lira) variants of the “pound sign”. But it turns out this isn’t the case: the double-bar dollar sign, sometimes called
cifrão (from Portugese), and the single-bar dollar sign are treated as allographs: they
share the same codepoint and only the choice of type face differentiates between them. I can’t type a double-bar dollar sign for you without forcing an additional font upon
you, and even if I did it wouldn’t render “correctly” for everybody. Unicode is great, but it’s not perfect.
7 “Thank you very much”, in Welsh, but you probably knew that already.
After driving 300 (vertical) metres up a terrifyingly winding road, we find ourself at ‘Top if the World’, one of Tobago’s highest points. Being able to look down the steep sides of
this long-extinct volcano to the sea on both sides is quite spectacular, and the Caribbean and Atlantic horizons seem so far away that you can almost believe you’re seeing the Earth
curve.
The Nylon Pool is a sandbar in the Buccoo Reef, off the coast of Tobago. Despite the distance from the shore, it’s only about waist-deep. Truly mind-boggling.