Today’s Hide And Seek With The Kids is brought to you by the Bishop’s Palace, St. David’s, Wales.

Today’s Hide And Seek With The Kids is brought to you by the Bishop’s Palace, St. David’s, Wales.
Cwm-yr-Eglwys, on the West coast of Wales. Time for a (bracing) swim!

I was happy to get out of the traffic jam and get some fresh air, but the dog is REALLY happy! Running, rolling, sniffing, jumping… so excited to be able to move around!

Off to Pembrokeshire on holiday I’ve had to stop near Cardiff to put some more charge into the car… which provides the perfect opportunity for the doggo and I to explore a nearby sports field and take in All. The. Smells. 🐶

This post is also available as a podcast. Listen here, download for later, or subscribe wherever you consume podcasts.
Earlier this month, I received a phone call from a user of Three Rings, the volunteer/rota management software system I founded1.
We don’t strictly offer telephone-based tech support – our distributed team of volunteers doesn’t keep any particular “core hours” so we can’t say who’s available at any given time – but instead we answer email/Web based queries pretty promptly at any time of the day or week.
But because I’ve called-back enough users over the years, it’s pretty much inevitable that a few probably have my personal mobile number saved. And because I’ve been applying for a couple of interesting-looking new roles, I’m in the habit of answering my phone even if it’s a number I don’t recognise.

After the first three such calls this month, I was really starting to wonder what had changed. Had we accidentally published my phone number, somewhere? So when the fourth tech support call came through, today (which began with a confusing exchange when I didn’t recognise the name of the caller’s charity, and he didn’t get my name right, and I initially figured it must be a wrong number), I had to ask: where did you find this number?
“When I Google ‘Three Rings login’, it’s right there!” he said.
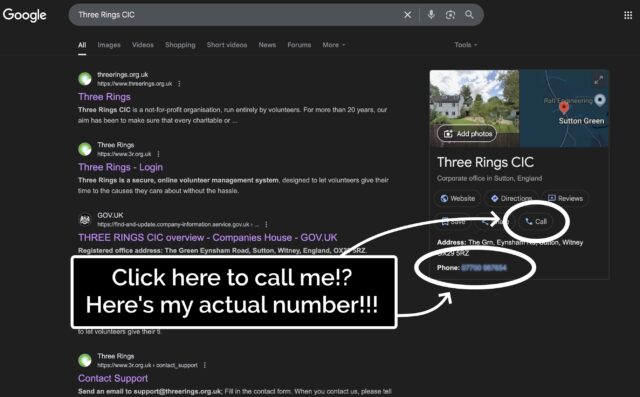
He was right. A Google search that surfaced Three Rings CIC’s “Google Business Profile” now featured… my personal mobile number. And a convenient “Call” button that connects you directly to it.

Some years ago, I provided my phone number to Google as part of an identity verification process, but didn’t consent to it being shared publicly. And, indeed, they didn’t share it publicly, until – seemingly at random – they started doing so, presumably within the last few weeks.
Concerned by this change, I logged into Google Business Profile to see if I could edit it back.
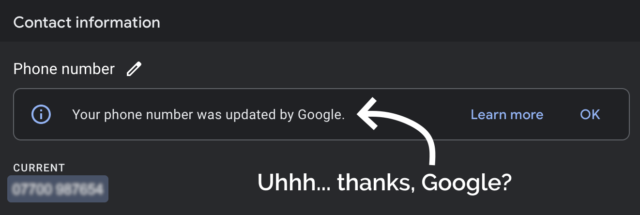
I deleted my phone number from the business listing again, and within a few minutes it seemed to have stopped being served to random strangers on the Internet. Unfortunately deleting the phone number also made the “Your phone number was updated by Google” message disappear, so I never got to click the “Learn more” link to maybe get a clue as to how and why this change happened.
Last month, high-street bank Halifax posted the details of a credit agreement I have with them to two people who aren’t me. Twice in two months seems suspicious. Did I accidentally click the wrong button on a popup and now I’ve consented to all my PII getting leaked everywhere?
Such feelings of rage.
1 Way back in 2002! We’re very nearly at the point where the Three Rings system is older than the youngest member of the Three Rings team. Speaking of which, we’re seeking volunteers to help expand our support team: if you’ve got experience of using Three Rings and an hour or two a week to spare helping to make volunteering easier for hundreds of thousands of people around the world, you should look us up!
2 Seriously: if you’re still using Google Search as your primary search engine, it’s past time you shopped around. There are great alternatives that do a better job on your choice of one or more of the metrics that might matter to you: better privacy, fewer ads (or more-relevant ads, if you want), less AI slop, etc.
This checkin to GCB4434 A Road Anarchy - A40 TB Hotel reflects a geocaching.com log entry. See more of Dan's cache logs.
On a diversion from my cycle from Witney to Eynsham I came along the A40 cyclepath to find this cache. And what a cache! An excellent container perfectly suited to it’s hiding place. SL, TNLN, FP awarded for a large and well maintained container, TFTC.

This checkin to GCAARWW Green All Around reflects a geocaching.com log entry. See more of Dan's cache logs.
After cycling into Witney on an errand, put a slight diversion in my return route to find this cache. Didn’t see anything at the coordinates so hit the hint, and there’s been enough fresh green growth here that effect even then it took me a while to find the hint object! It probably used to be more visible! Once I’d found it (a few metres North if the GZ) the cache was found soon after. TFTC.

Shower thought for the morning was: why is cream cheese spread ‘Philadelphia’ called that? Is it from Philadelphia? (My box isn’t, of course: it came from Ireland.)

Nope, it turns out that it was originally invented in New York in the 19th century and named for Philadelphia because Philadelphia, PA was at that point famous for its dairy industry. Just another bit of parasitic branding leveraging a borrowed association, like the Quaker Oats guy or the Rolls Razor. Now I’m wondering how many other examples I can find!
Off to London. BRB!

Paraphrased from a conversation in a Manchester pub last night –
Them: Your [dyed blue] hair is queer-coded, right? Like… you’re telegraphing you’re queer?
Me: I mean… I’m also wearing a pride rainbow t-shirt and my watch strap is a ‘bi pride’ flag. I don’t feel like I’m being
subtle.
Them: Nah. The hair’s the giveaway.

This checkin to OK0063 Stella's on a mission reflects an opencache.uk log entry. See more of Dan's cache logs.
A quick diversion from my walk back to to train station to snap a selfie at the GZ while waving a rainbow handkerchief. TFTC!

This checkin to GCAF1WK KT 132 - Just a number 1 reflects a geocaching.com log entry. See more of Dan's cache logs.
My sneaky hunt was interrupted when the fire alarm went off in a nearby building and its occupants spilled out into the street! Maybe another time.
This checkin to GC2MTTV Power to the People reflects a geocaching.com log entry. See more of Dan's cache logs.
Not too busy here this morning so I was able to mount a proper search for the cache. No sign of the container, so providing a photo log in accordance with CO’s instructions. TFTC.

My GPSr puts the hint item about 9m South of the posted coordinates, with strong signal, BTW.
This checkin to GC84F1A Manchester Central Library reflects a geocaching.com log entry. See more of Dan's cache logs.
What a truly spectacular cache. FP awarded, without hesitation. I’ve seen a similar kind in a library before but never with such depth, such a story, so voluminous a container, nor – let’s be honest – so beautiful a building!
The Wolfson room was packed, presumably with people studying for their upcoming exams, but I found a seat there to work out the final location. Once there, I made my way up and found it without difficulty. No trouble with the numbers from me.

I’m going to try to tag one or two more Manchester caches before I catch my train home, but I can’t imagine any will hold a candle to this. TFTC!
This checkin to GC66Z2H Yesterday, When I Was Mad reflects a geocaching.com log entry. See more of Dan's cache logs.

Of the three candidate hiding places, somehow it was the one I searched third that turned out to be correct. SL, TFTC.