Searched high and low around the obvious hiding place before sitting down to have a think and immediately spotting another even better hiding place she the cache in pain sight: d’oh!
The geopup didn’t want to come all the all the way to it so she waited at the first obvious hiding spot.
Great to see a good sized cache for the environment and in such good condition. FP awarded. Took 4×4 travel bug.
TFTC!
Briefly overshot this one and then failed to get a good GPS fix, but the hint set us right. Gorgeous sun this morning on the poppies peeking up over the corn.
A morning walk for the geohound and I kicked off at this cache, near which we’d parked the car. Long been meaning to explore this loop: let’s see how far we get before the pooch’s tiny
legs give her cause to protest! SL as DQ to save space at this QEF. TFTC!
I was updating my CV earlier this week in anticipation of applying for a handful of interesting-looking roles1
and I was considering quite how many different tech stacks I claim significant experience in, nowadays.
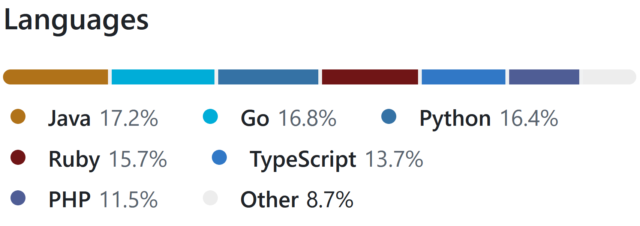
There are languages I’ve been writing in every single week for the last 15+ years, of course, like PHP, Ruby, and JavaScript. And my underlying fundamentals are solid.
But is it really fair for me to be able to claim that I can code in Java, Go, or Python: languages that I’ve not used commercially within the last 5-10 years?
What kind of developer writes the same program six times… for a tech test they haven’t even been asked to do? If you guessed “Dan”, you’d be correct!
Obviously, I couldn’t just let that question lie2.
Let’s find out!
I fished around on Glassdoor for a bit to find a medium-sized single-sitting tech test, and found a couple of different briefs that I mashed together to create this:
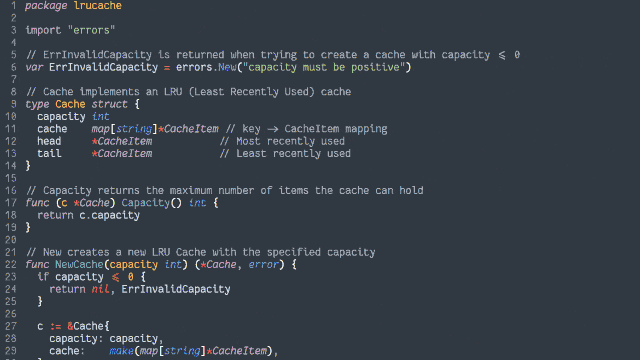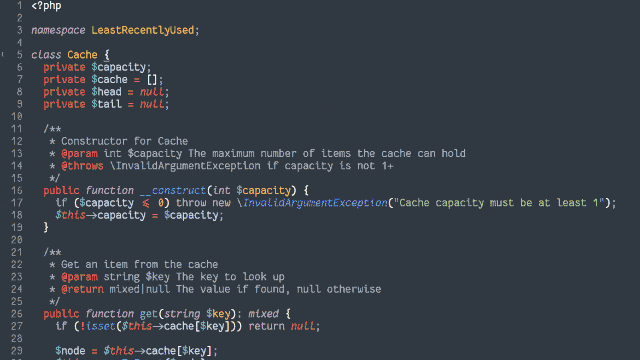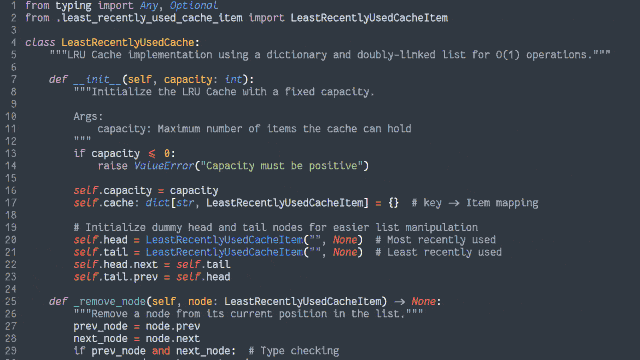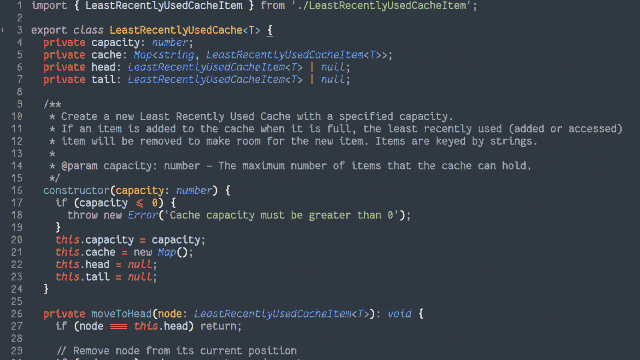
In an object-oriented manner, implement an LRU (Least-Recently Used) cache:
The size of the cache is specified at instantiation.
Arbitrary objects can be put into the cache, along with a retrieval key in the form of a string. Using the same string, you can get the objects back.
If a put operation would increase the number of objects in the cache beyond the size limit, the cached object that was least-recently accessed (by either a
put or get operation) is removed to make room for it.
putting a duplicate key into the cache should update the associated object (and make this item most-recently accessed).
Both the get and put operations should resolve within constant (O(1)) time.
Add automated tests to support the functionality.
My plan was to implement a solution to this challenge, in as many of the languages mentioned on my CV as possible in a single sitting.
But first, a little Data Structures & Algorithms theory:
The Theory
Simple case with O(n) complexity
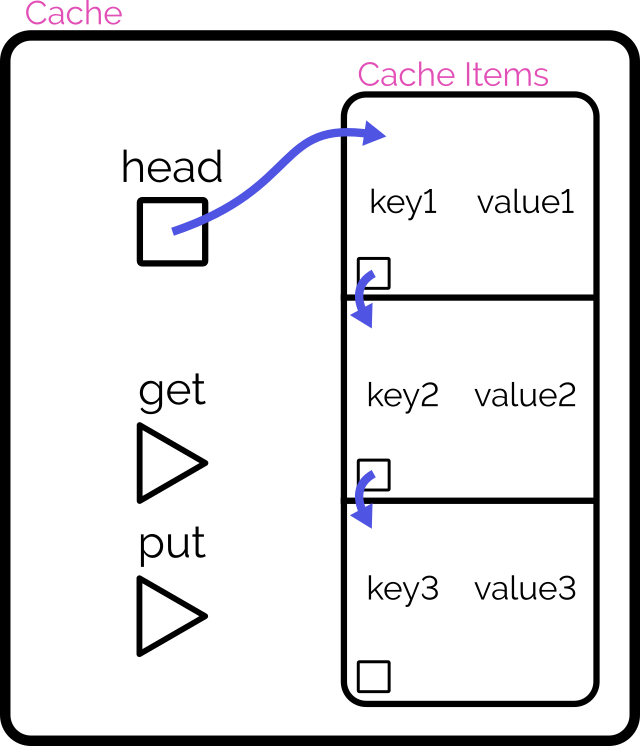
The simplest way to implement such a cache might be as follows:
Use a linear data structure like an array or linked list to store cached items.
On get, iterate through the list to try to find the matching item.
If found: move it to the head of the list, then return it.
On put, first check if it already exists in the list as with get:
If it already exists, update it and move it to the head of the list.
Otherwise, insert it as a new item at the head of the list.
If this would increase the size of the list beyond the permitted limit, pop and discard the item at the tail of the list.
It’s simple, elegant and totally the kind of thing I’d accept if I were recruiting for a junior or graduate developer. But we can do better.
The problem with this approach is that it fails the requirement that the methods “should resolve within constant (O(1)) time”3.
Of particular concern is the fact that any operation which might need to re-sort the list to put the just-accessed item at the top
4. Let’s try another design:
Achieving O(1) time complexity
Here’s another way to implement the cache:
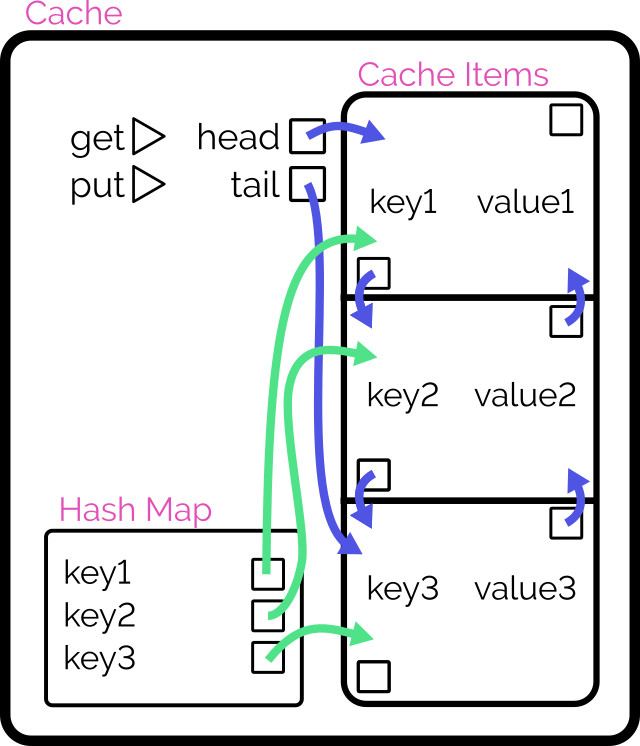
Retain cache items in a doubly-linked list, with a pointer to both the head and tail
Add a hash map (or similar language-specific structure) for fast lookups by cache key
On get, check the hash map to see if the item exists.
If so, return it and promote it to the head (as described below).
On put, check the hash map to see if the item exists.
If so, promote it to the head (as described below).
If not, insert it at the head by:
Updating the prev of the current head item and then pointing the head to the new item (which will have the old head item as its
next), and
Adding it to the hash map.
If the number of items in the hash map would exceed the limit, remove the tail item from the hash map, point the tail at the tail item’s prev, and
unlink the expired tail item from the new tail item’s next.
To promote an item to the head of the list:
Follow the item’s prev and next to find its siblings and link them to one another (removes the item from the list).
Point the promoted item’s next to the current head, and the current head‘s prev to the promoted item.
Point the head of the list at the promoted item.
Looking at a plate of pointer-spaghetti makes me strangely hungry.
It’s important to realise that this alternative implementation isn’t better. It’s just different: the “right” solution depends on the use-case5.
The Implementation
That’s enough analysis and design. Time to write some code.
Turns out that if you use enough different languages in your project, GitHub begins to look like itwants to draw a rainbow.
Picking a handful of the more-useful languages on my CV6,
I opted to implement in:
Ruby (with RSpec for testing and Rubocop for linting)
PHP (with PHPUnit for testing)
TypeScript (running on Node, with Jest for testing)
Java (with JUnit for testing)
Go (which isn’t really an object-oriented language but acts a bit like one, amirite?)
Python (probably my weakest language in this set, but which actually ended up with quite a tidy solution)
Naturally, I open-sourced everything if you’d like to see for yourself. It all works, although if you’re actually in need of such a
cache for your project you’ll probably find an alternative that’s at least as good (and more-likely to be maintained!) in a third-party library somewhere!
What did I learn?
This was actually pretty fun! I might continue to expand my repo by doing the same challenge with a few of the other languages I’ve used professionally at some point or
another7.
And there’s a few takeaways I got from this experience –
Lesson #1: programming more languages can make you better at all of them
As I went along, one language at a time, I ended up realising improvements that I could make to earlier iterations.
For example, when I came to the TypeScript implementation, I decided to use generics so that the developer can specify what kind of objects they want to store in the cache,
rather than just a generic Object, and better benefit type-safety. That’s when I remembered that Java supports generics, too, so I went back and used them there as well.
In the same way as speaking multiple (human) languages or studying linguistics can help unlock new ways of thinking about your communication, being able to think in terms of multiple
different programming languages helps you spot new opportunities. When in 2020 PHP 8 added nullsafe operators, union types, and
named arguments, I remember feeling confident using them from day one because those features were already familiar to me from Ruby8, TypeScript9, and Python10,
respectively.
Lesson #2: even when I’m rusty, I can rely on my fundamentals
I’ve applied for a handful of jobs now, but if one of them had invited me to a pairing session on a language I’m rusty on (like Java!) I might’ve felt intimidated.
But it turns out I shouldn’t need to be! With my solid fundamentals and a handful of other languages under my belt, I understand when I need to step away from the code editor and hit
the API documentation. Turns out, I’m in a good position to demo any of my language skills.
I remember when I was first learning Go, I wanted to make use of a particular language feature that I didn’t know whether it had. But because I’d used that feature in Ruby, I knew what
to search for in Go’s documentation to see if it was supported (it wasn’t) and if so, what the syntax was11.
Lesson #3: structural rules are harder to gearshift than syntactic ones
Switching between six different languages while writing the same application was occasionally challenging, but not in the ways I expected.
I’ve had plenty of experience switching programming languages mid-train-of-thought before. Sometimes you just have to flit between the frontend and backend of your application!
But this time around I discovered: changes in structure are apparently harder for my brain than changes in syntax. E.g.:
Switching in and out of Python’s indentation caught me out at least once (might’ve been better if I took the time to install the language’s tools into my text editor first!).
Switching from a language without enforced semicolon line ends (e.g. Ruby, Go) to one with them (e.g. Java, PHP) had me make the compiler sad several times.
This gets even tougher when not writing the language but writing about the language: my first pass at the documentation for the Go version somehow ended up with
Ruby/Python-style #-comments instead of Go/Java/TypeScript-style //-comments; whoops!
I’m guessing that the part of my memory that looks after a language’s keywords, how a method header is structured, and which equals sign to use for assignment versus comparison… are
stored in a different part of my brain than the bit that keeps track of how a language is laid-out?12
Okay, time for a new job
I reckon it’s time I got back into work, so I’m going to have a look around and see if there’s any roles out there that look exciting to me.
If you know anybody who’s looking for a UK-based, remote-first, senior+, full-stack web developer with 25+ years experience and more languages than you can shake a stick at… point them at my CV, would you?
Footnotes
1 I suspect that when most software engineers look for a new job, they filter to the
languages, frameworks, they feel they’re strongest at. I do a little of that, I suppose, but I’m far more-motivated by culture, sector, product and environment than I am by the shape
of your stack, and I’m versatile enough that technology specifics can almost come second. So long as you’re not asking me to write VB.NET.
2 It’s sort-of a parallel to how I decided to check
the other week that my Gutenberg experience was sufficiently strong that I could write standard ReactJS, too.
3 I was pleased to find a tech test that actually called for an understanding of algorithm
growth/scaling rates, so I could steal this requirement for my own experiment! I fear that sometimes, in their drive to be pragmatic and representative of “real work”, the value of a
comprehension of computer science fundamentals is overlooked by recruiters.
4 Even if an algorithm takes the approach of creating a new list with the
inserted/modified item at the top, that’s still just a very-specific case of insertion sort when you think about it, right?
5 The second design will be slower at writing but faster at
reading, and will scale better as the cache gets larger. That sounds great for a read-often/write-rarely cache, but your situation may differ.
6 Okay, my language selection was pretty arbitrary. But if I’d have also come up with
implementations in Perl, and C#, and Elixir, and whatever else… I’d have been writing code all day!
7 So long as I’m willing to be flexible about the “object-oriented” requirement, there are
even more options available to me. Probably the language that I last wrote longest ago would be Pascal: I wonder how much of that I remember?
8 Ruby’s safe navigation/”lonely” operator did the same thing as PHP’s nullsafe operator
since 2015.
9 TypeScript got union types back in 2015, and apart from them being more-strictly-enforced they’re basically identical to
PHP’s.
10 Did you know that Python had keyword arguments since its very first public release
way back in 1994! How did it take so many other interpreted languages so long to catch up?
11 The feature was the three-way comparison or “spaceship operator”, in case you were wondering.
12 I wonder if anybody’s ever laid a programmer in an MRI machine while they code? I’d
be really interested to see if different bits of the brain light up when coding in functional programming languages than in procedural ones, for example!
It’s so emblematic of the moment we’re in, the Who Cares Era, where completely disposable things are shoddily produced for people to mostly ignore.
…
In the Who Cares Era, the most radical thing you can do is care.
In a moment where machines churn out mediocrity, make something yourself. Make it imperfect. Make it rough. Just make it.
At a time where the government’s uncaring boot is pressing down on all of our necks, the best way to fight back is to care. Care loudly. Tell others. Get going.
…
Smart words, well-written by Dan Sinker.
I like the fact that he correctly identifies that the “Who Cares Era” – illustrated by the bulk creation of low-effort, low-quality media, for a disheartened audience that no longer has
a reason to give a damn – isn’t about AI.
I mean… AI’s certainly not helping! AI slop dominates social media (especially in right-wing
spaces, for retrospectively-obvious reasons) and bleeds out into the mainstream. LLM-generated content, lacking even the slightest human input, is becoming painfully ubiquitous.
It’s pretty sad out there.
So while the “Who Cares Era” might be exemplified by the proliferation of AI slop… it’s much bigger than that. It’s a sociological change, tied perhaps to a growing dissatisfaction with
our governments and the increasing feeling of powerlessness to change the unjust social systems we’re locked into?
I don’t know how to fix it. I don’t even know if it’s fixable. But I agree with Dan’s argument that a great starting point is to care.
And I, for one, am going to continue to create things I care about, giving them the time and attention they deserve. And maybe if enough of us can do that, just that, then
maybe that’ll make the difference.
I’m applying for a few roles that might be the next step in my career. And to my surprise, updating my CV and tweaking my portfolio is doing a world of good for my
feelings of self-worth!
Seriously: looking back over the last ~25 years of my career and enumerating the highlights is giving me a better “big picture” view of everything I’ve achieved than I ever got from the
near-focus of daily work. I should do this more often!
I don’t want to withdraw any of our children from sec [sic] education lessons.
However they’re spelled, they’re a great idea, and I’m grateful to live in a part of the world where their existence isn’t the target of religious politics.
But if I can withdraw consent to receiving emails about sex education in Comic Sans then that’d be great, thanks. 😅
Fellow Abnibbers and I, who see each other extraordinary infrequently in our diaspora, have a tradition of sharing a group selfie when we happen to
coincide. I forgot to take one when @garethbowker@infosec.exchange and I met today, and by way of penance I tried to draw what I
should have done.
Unfortunately I can’t draw. He looks much less like a potato in real life! Think I got his dog right, though.
Stopped at the pub nearby for an incredibly late lunch and to recharge the electric car on my journey from Pembrokeshire to Oxfordshire, because I’d much rather get off the motorway and
find somewhere nice to sit while the electrons do their thing. Spotted this nearby cache in the yard of this beautiful church, which made for a lovely walk as the well-tended flowerbeds
were wonderfully fragrant. Followed a geotrail to find the cache. Amazing, loved finding this so much. SL, TNLN, TFTC, FP awarded.
Out for a dog walk this morning along the Nevern Estuary, I spotted this brave fellow rowing his way (at least) half naked across the bay, on a route that pitted him against the wind,
rain, and tide!
The geopup and I took a walk from the Parrog to Newport Sands and back, this morning, and I’m glad we opted to find geocaches on the way back, rather than the way out, because it made
this particular cache extraordinarily easy. The rocks that ought to have concealed it were absent and I was able to make out the familiar shape of this kind of container from the path,
no searching required!
Had I approached from this direction, I might still be searching.
Returning it to its spot, I attempted to reconceal it with the help of some nearby slabs if slate. But given how much of an obvious magnet to playful children this entire structure is
(I’m pretty sure mine had a go at dismantling it on a previous visit, predating this cache, circa 2019!) I’m not sure how long it’ll remain!
I tried to find this cache back in 2016 without success. I’m confident I’d have looked in the place it’s now
hidden – which was today basically the first place I looked! – so maybe fast previous visit was during one of the cache’s periods of absencennIn any case, I returned today and brought
my faithful geohound on a morning walk from Parrog to Newport Sands and back, finding this cache on our return leg. She wasn’t much help, but fortunately I didn’t need her to be! TFTC.
I’d like to nominate DB13W3 for Most Cursed Connector. I mean, just look at that thing!
Bonus: there were at least two different, incompatible, pinout “standards” for this thing, so there was no guarantee that a random monitor with this cable would connect to your
workstation, even if it had the right port.
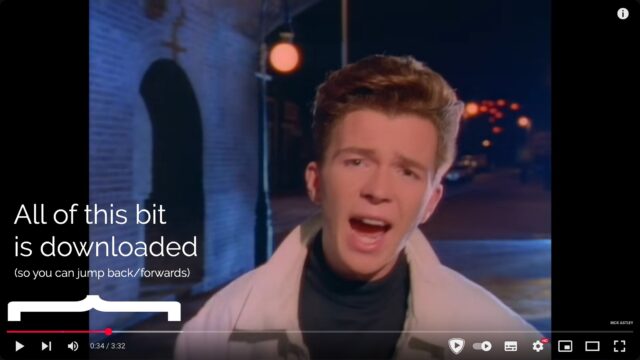
The fundamental difference between streaming and downloading is what your device does with those frames of video:
Does it show them to you once and then throw them away? Or does it re-assemble them all back into a video file and save it into storage?
When you’re streaming on YouTube, the video player running on your computer retains a buffer of frames ahead and behind of your current position, so you can skip around easily: the
darker grey part of the timeline shows which parts of the video are stored on – that is, downloaded to – your computer.
Buffering is when your streaming player gets some number of frames “ahead” of where you’re watching, to give you some protection against connection issues. If your WiFi wobbles
for a moment, the buffer protects you from the video stopping completely for a few seconds.
But for buffering to work, your computer has to retain bits of the video. So in a very real sense, all streaming is downloading! The buffer is the part
of the stream that’s downloaded onto your computer right now. The question is: what happens to it next?
All streaming is downloading
So that’s the bottom line: if your computer deletes the frames of video it was storing in the buffer, we call that streaming. If it retains them in a file, we
call that downloading.
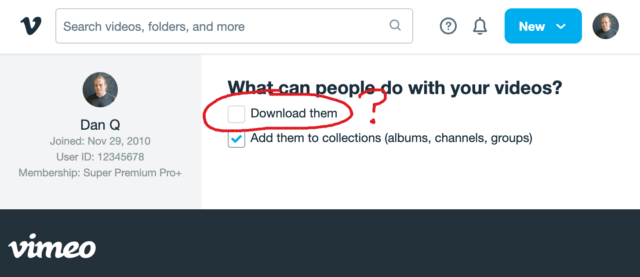
That definition introduces a philosophical problem. Remember that Vimeo checkbox that lets a creator decide whether people can (i.e. are allowed to) download their videos? Isn’t
that somewhat meaningless if all streaming is downloading.
Because if the difference between streaming and downloading is whether their device belonging to the person watching the video deletes the media when they’re done. And in
virtually all cases, that’s done on the honour system.
This kind of conversation happens, over the HTTP protocol, all the time. Probably most of the time the browser is telling the truth, but there’s no way to know for certain.
When your favourite streaming platform says that it’s only possible to stream, and not download, their media… or when they restrict “downloading” as an option to higher-cost paid plans…
they’re relying on the assumption that the user’s device can be trusted to delete the media when the user’s done watching it.
But a user who owns their own device, their own network, their own screen or speakers has many, many opportunities to not fulfil the promise of deleting media it after they’ve consumed
it: to retain a “downloaded” copy for their own enjoyment, including:
Intercepting the media as it passes through their network on the way to its destination device
Using client software that’s been configured to stream-and-save, rather than steam-and-delete, the content
Modifying “secure” software (e.g. an official app) so that it retains a saved copy rather than deleting it
Capturing the stream buffer as it’s cached in device memory or on the device’s hard disk
Outputting the resulting media to a different device, e.g. using a HDMI capture device, and saving it there
Exploiting the “analogue4
hole”5:
using a camera, microphone, etc. to make a copy of what comes out of the screen/speakers6
Okay, so I oversimplified (before you say “well, actually…”)
It’s not entirely true to say that streaming and downloading are identical, even with the caveat of “…from the server’s perspective”. There are three big exceptions worth
thinking about:
Exception #1: downloads can come in any order
When you stream some linear media, you expect the server to send the media in strict chronological order. Being able to start watching before the whole file has
downloaded is a big part of what makes steaming appealing, to the end-user. This means that media intended for streaming tends to be stored in a way that facilitates that
kind of delivery. For example:
Media designed for streaming will often be stored in linear chronological order in the file, which impacts what kinds of compression are available.
Media designed for streaming will generally use formats that put file metadata at the start of the file, so that it gets delivered first.
Video designed for streaming will often have frequent keyframes so that a client that starts “in the middle” can decode the buffer without downloading too much data.
No such limitation exists for files intended for downloading. If you’re not planning on watching a video until it’s completely downloaded, the order in which the chunks arrives is
arbitrary!
But these limitations make the set of “files suitable for streaming” a subset of the set of “files suitable for downloading”. It only makes it challenging or impossible to
stream some media intended for downloading… it doesn’t do anything to prevent downloading of media intended for streaming.
Exception #2: streamed media is more-likely to be transcoded
A server that’s streaming media to a client exists in a sort-of dance: the client keeps the server updated on which “part” of the media it cares about, so the server can jump ahead,
throttle back, pause sending, etc. and the client’s buffer can be kept filled to the optimal level.
This dance also allows for a dynamic change in quality levels. You’ve probably seen this happen: you’re watching a video on YouTube and suddenly the quality “jumps” to something more
(or less) like a pile of LEGO bricks7. That’s the result of your device realising that the rate
at which it’s receiving data isn’t well-matched to the connection speed, and asking the server to send a different quality level8.
The server can – and some do! – pre-generate and store all of the different formats, but some servers will convert files (and particularly livestreams) on-the-fly, introducing
a few seconds’ delay in order to deliver the format that’s best-suited to the recipient9. That’s not necessary for downloads, where the
user will often want the highest-quality version of the media (and if they don’t, they’ll select the quality they want at the outset, before the download begins).
Exception #3: streamed media is more-likely to be encumbered with DRM
And then, of course, there’s DRM.
As streaming digital media has become the default way for many people to consume video and audio content, rights holders have engaged in a fundamentally-doomed10
arms race of implementing copy-protection strategies to attempt to prevent end-users from retaining usable downloaded copies of streamed media.
Take HDCP, for example, which e.g. Netflix use for their 4K streams. To download these streams, your device has to be running some decryption code that only works if it can trace a path
to the screen that it’ll be outputting to that also supports HDCP, and both your device and that screen promise that they’re definitely only going to show it and not make it
possible to save the video. And then that promise is enforced by Digital Content Protection LLC only granting a decryption key and a license to use it to manufacturers.11
The real hackers do stuff with software, but people who just want their screens to work properly in spite of HDCP can just buy boxes like this (which I bought for a couple of quid on
eBay). Obviously you could use something like this and a capture card to allow you to download content that was “protected” to ensure that you could only stream it, I suppose, too.
Anyway, the bottom line is that all streaming is, by definition, downloading, and the only significant difference between what people call “streaming” and
“downloading” is that when “streaming” there’s an expectation that the recipient will delete, and not retain, a copy of the video. And that’s it.
Footnotes
1 This isn’t the question I expected to be answering. I made the animation in this post
for use in a different article, but that one hasn’t come together yet, so I thought I’d write about the technical difference between streaming and downloading as an excuse to
use it already, while it still feels fresh.
2 I’m using the example of a video, but this same principle applies to any linear media
that you might stream: that could be a video on Netflix, a livestream on Twitch, a meeting in Zoom, a song in Spotify, or a radio show in iPlayer, for example: these are all examples
of media streaming… and – as I argue – they’re therefore also all examples of media downloading because streaming and downloading are fundamentally the same thing.
3 There are a few simplifications in the first half of this post: I’ll tackle them later
on. For the time being, when I say sweeping words like “every”, just imagine there’s a little footnote that says, “well, actually…”, which will save you from feeling like you have to
say so in the comments.
4 Per my style guide, I’m using the British English
spelling of “analogue”, rather than the American English “analog” which you’ll often find elsewhere on the Web when talking about the analog hole.
5 The rich history of exploiting the analogue hole spans everything from bootlegging a
1970s Led Zeppelin concert by smuggling recording equipment
in inside a wheelchair (definitely, y’know, to help topple the USSR and not just to listen to at home while you get high)
to “camming” by bribing your friendly local projectionist to let you set up a video camera at the back of the cinema for their test screening of the new blockbuster. Until some
corporation tricks us into installing memory-erasing DRM chips into our brains (hey, there’s a dystopic sci-fi story idea in there somewhere!) the analogue hole will always be
exploitable.
6 One might argue that recreating a piece of art from memory, after the fact, is a
very-specific and unusual exploitation of the analogue hole: the one that allows us to remember (or “download”) information to our brains rather than letting it “stream” right
through. There’s evidence to suggest that people pirated Shakespeare’s plays this way!
7 Of course, if you’re watching The LEGO Movie, what you’re seeing might already
look like a pile of LEGO bricks.
8 There are other ways in which the client and server may negotiate, too: for example,
what encoding formats are supported by your device.
9My NAS does live transcoding when Jellyfin streams to devices on my network, and it’s magical!
10 There’s always the analogue hole, remember! Although in practice this isn’t even
remotely necessary and most video media gets ripped some-other-way by clever pirate types even where it uses highly-sophisticated DRM strategies, and then ultimately it’s only
legitimate users who end up suffering as a result of DRM’s burden. It’s almost as if it’s just, y’know, simply a bad idea in the first place, or something. Who knew?
11 Like all these technologies, HDCP was cracked almost immediately and every
subsequent version that’s seen widespread rollout has similarly been broken by clever hacker types. Legitimate, paying users find themselves disadvantaged when their laptop won’t let
them use their external monitor to watch a movie, while the bad guys make pirated copies that work fine on anything. I don’t think anybody wins, here.