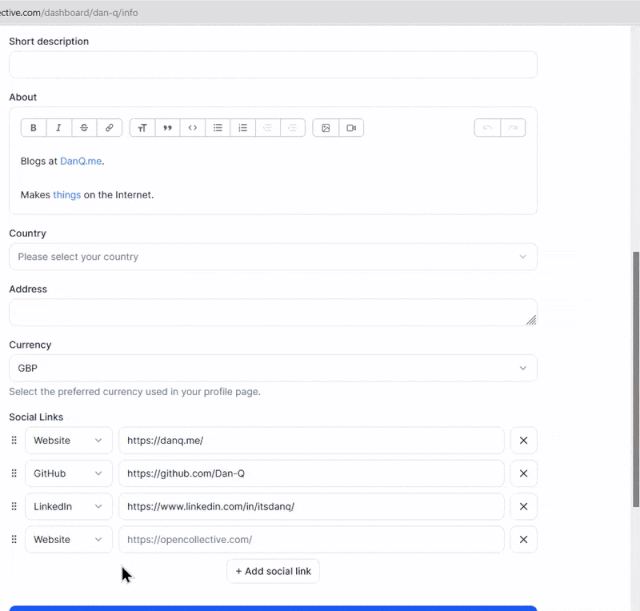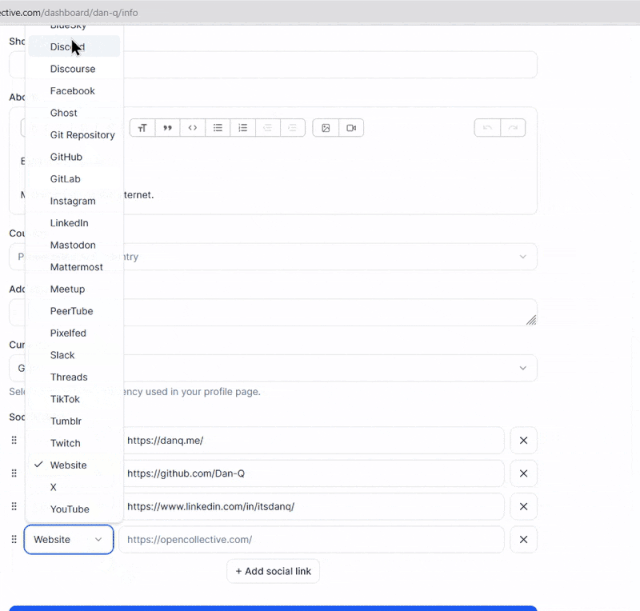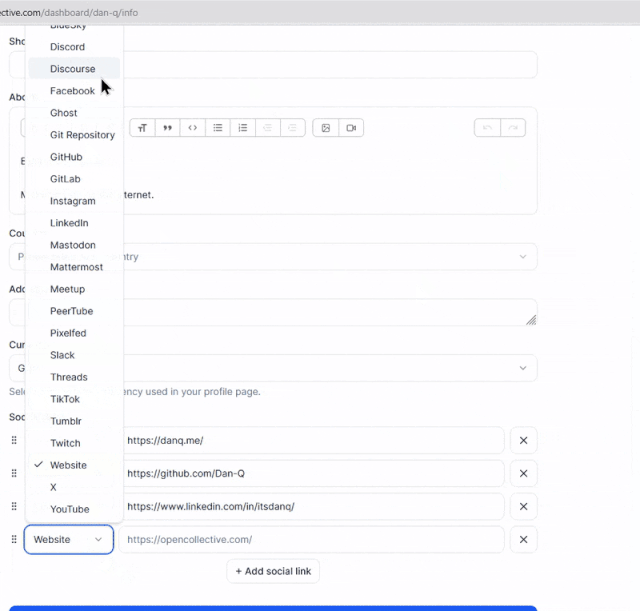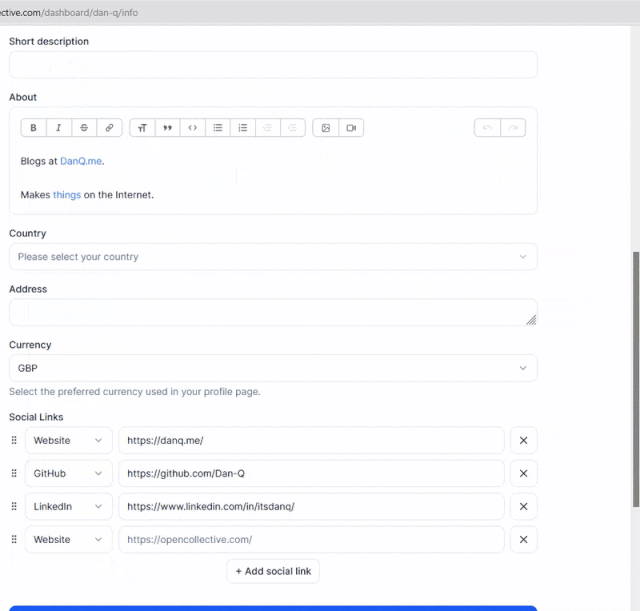
Developers just love to take what the Web gives them for free, throw it away, and replace it with something worse.
Today’s example, from Open Collective, is a dropdown box: standard functionality provided by the <select> element. Except
they’ve replaced it with a JS component that, at some screen resolutions, “goes off the top” of the page… while simultaneously disabling the scrollbars so that you can’t reach it. 🤦♂️
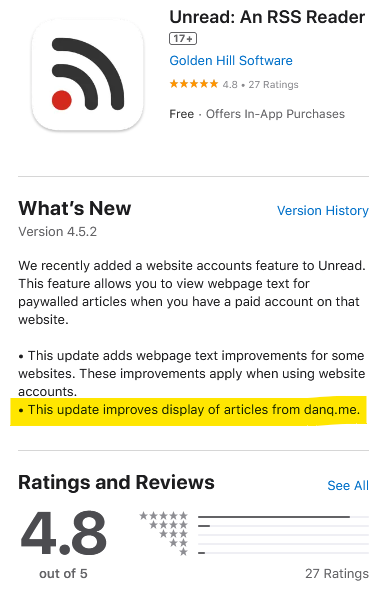
Last month, my friend Gareth observed that the numbered lists in my blog posts “looked wrong” in his feed reader. I checked, and I
decided I was following the standards correctly and it must have been his app that was misbehaving.
So he contacted the authors of Unread, his feed reader, and they fixed it. Pretty fast, I’ve got to say. And I was amused to
see that I’m clearly now a test case because my name’s in their release notes!
A few years ago I implemented a pure HTML + CSS solution for lightbox images, which I’ve been using on my blog ever since. It works by
pre-rendering an invisible <dialog> for each lightboxable image on the page, linking to the anchor of those dialogs, and exploiting the :target selector
to decide when to make the dialogs visible. No Javascript is required, which means low brittleness and high performance!
It works, but it’s got room for improvement.
One thing I don’t like about it is that it that it breaks completely if the CSS fails for any reason. Depending upon CSS is safer than depending upon JS (which breaks all
the time), but it’s still not great: if CSS is disabled in your browser or just “goes wrong” somehow then you’ll see a hyperlink… that doesn’t seem to go anywhere (it’s an
anchor to a hidden element).
A further thing I don’t like about it is it’s semantically unsound. Linking to a dialog with the expectation that the CSS parser will then make that dialog visible isn’t really
representative of what the content of the page means. Maybe we can do better.
🚀 Wired: <details>-based HTML+CSS lightboxes?
Here’s a thought I had, inspired by Patrick Chia’s <details> overlay trick and by
the categories menu in Eevee’s blog: what if we used a <details> HTML element for a lightbox? The thumbnail image would go in the
<summary> and the full image (with loading="lazy" so it doesn’t download until the details are expanded) beneath, which means it “just works” with or
without CSS… and then some CSS enhances it to make it appear like a modal overlay and allow clicking-anywhere to close it again.
Let me show you what I mean. Click on one of the thumbnails below:
Each appears to pop up in a modal overlay, but in reality they’re just unfolding a <details> panel, and some CSS is making the contents display as if if were
an overlay, complete click-to-close, scroll-blocking, and a blur filter over the background content. Without CSS, it functions as a traditional <details> block.
Accessibility is probably improved over my previous approach, too (though if you know better, please tell me!).
The code’s pretty tidy, too. Here’s the HTML:
<detailsclass="details-lightbox"aria-label="larger image">
<summary>
<imgsrc="thumb.webp"alt="Alt text for the thumbnail image.">
</summary>
<div>
<imgsrc="full.webp"alt="Larger image: alt text for the full image."loading="lazy">
</div>
</details>
The CSS is more-involved, but not excessive (and can probably be optimised a little further):
Native CSS nesting is super nice for this kind of thing. Being able to use :has on the body to detect whether there exists an open lightbox and prevent
scrolling, if so, is another CSS feature I’m appreciating today.
I’m not going to roll this out anywhere rightaway, but I’ll keep it in my back pocket for the next time I feel a blog redesign coming on. It feels tidier and more-universal than my
current approach, and I don’t think it’s an enormous sacrifice to lose the ability to hotlink directly to an open image in a post.
Some time in the last 25 years, ISPs stopped saying they made you “part of” the Internet, just that they’d help you “connect to” the Internet.
Most people don’t need a static IP, sure. But when ISPs stopped offering FTP and WWW hosting as a standard feature (shit though it often was), they became part of the tragic process by
which the Internet became centralised, and commoditised, and corporate, and just generally watered-down.
The amount of effort to “put something online” didn’t increase by a lot, but it increased by enough that millions probably missed-out on the opportunity to create
their first homepage.
The fundamental difference between streaming and downloading is what your device does with those frames of video:
Does it show them to you once and then throw them away? Or does it re-assemble them all back into a video file and save it into storage?
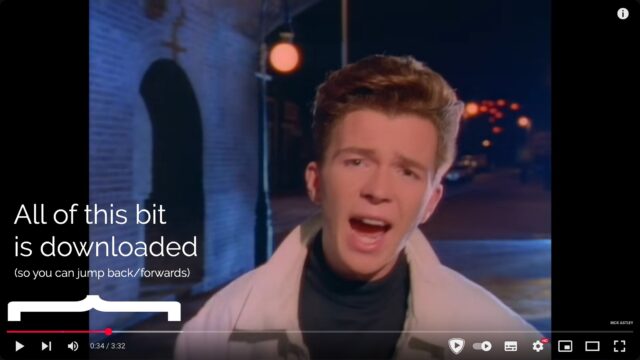
When you’re streaming on YouTube, the video player running on your computer retains a buffer of frames ahead and behind of your current position, so you can skip around easily: the
darker grey part of the timeline shows which parts of the video are stored on – that is, downloaded to – your computer.
Buffering is when your streaming player gets some number of frames “ahead” of where you’re watching, to give you some protection against connection issues. If your WiFi wobbles
for a moment, the buffer protects you from the video stopping completely for a few seconds.
But for buffering to work, your computer has to retain bits of the video. So in a very real sense, all streaming is downloading! The buffer is the part
of the stream that’s downloaded onto your computer right now. The question is: what happens to it next?
All streaming is downloading
So that’s the bottom line: if your computer deletes the frames of video it was storing in the buffer, we call that streaming. If it retains them in a file, we
call that downloading.
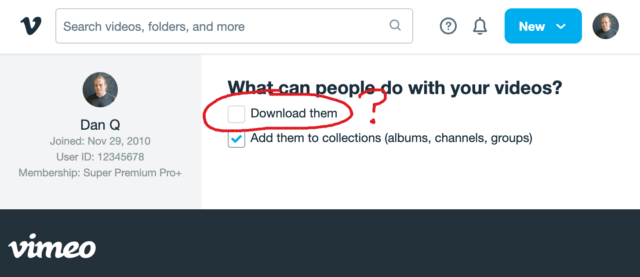
That definition introduces a philosophical problem. Remember that Vimeo checkbox that lets a creator decide whether people can (i.e. are allowed to) download their videos? Isn’t
that somewhat meaningless if all streaming is downloading.
Because if the difference between streaming and downloading is whether their device belonging to the person watching the video deletes the media when they’re done. And in
virtually all cases, that’s done on the honour system.
This kind of conversation happens, over the HTTP protocol, all the time. Probably most of the time the browser is telling the truth, but there’s no way to know for certain.
When your favourite streaming platform says that it’s only possible to stream, and not download, their media… or when they restrict “downloading” as an option to higher-cost paid plans…
they’re relying on the assumption that the user’s device can be trusted to delete the media when the user’s done watching it.
But a user who owns their own device, their own network, their own screen or speakers has many, many opportunities to not fulfil the promise of deleting media it after they’ve consumed
it: to retain a “downloaded” copy for their own enjoyment, including:
Intercepting the media as it passes through their network on the way to its destination device
Using client software that’s been configured to stream-and-save, rather than steam-and-delete, the content
Modifying “secure” software (e.g. an official app) so that it retains a saved copy rather than deleting it
Capturing the stream buffer as it’s cached in device memory or on the device’s hard disk
Outputting the resulting media to a different device, e.g. using a HDMI capture device, and saving it there
Exploiting the “analogue4
hole”5:
using a camera, microphone, etc. to make a copy of what comes out of the screen/speakers6
Okay, so I oversimplified (before you say “well, actually…”)
It’s not entirely true to say that streaming and downloading are identical, even with the caveat of “…from the server’s perspective”. There are three big exceptions worth
thinking about:
Exception #1: downloads can come in any order
When you stream some linear media, you expect the server to send the media in strict chronological order. Being able to start watching before the whole file has
downloaded is a big part of what makes steaming appealing, to the end-user. This means that media intended for streaming tends to be stored in a way that facilitates that
kind of delivery. For example:
Media designed for streaming will often be stored in linear chronological order in the file, which impacts what kinds of compression are available.
Media designed for streaming will generally use formats that put file metadata at the start of the file, so that it gets delivered first.
Video designed for streaming will often have frequent keyframes so that a client that starts “in the middle” can decode the buffer without downloading too much data.
No such limitation exists for files intended for downloading. If you’re not planning on watching a video until it’s completely downloaded, the order in which the chunks arrives is
arbitrary!
But these limitations make the set of “files suitable for streaming” a subset of the set of “files suitable for downloading”. It only makes it challenging or impossible to
stream some media intended for downloading… it doesn’t do anything to prevent downloading of media intended for streaming.
Exception #2: streamed media is more-likely to be transcoded
A server that’s streaming media to a client exists in a sort-of dance: the client keeps the server updated on which “part” of the media it cares about, so the server can jump ahead,
throttle back, pause sending, etc. and the client’s buffer can be kept filled to the optimal level.
This dance also allows for a dynamic change in quality levels. You’ve probably seen this happen: you’re watching a video on YouTube and suddenly the quality “jumps” to something more
(or less) like a pile of LEGO bricks7. That’s the result of your device realising that the rate
at which it’s receiving data isn’t well-matched to the connection speed, and asking the server to send a different quality level8.
The server can – and some do! – pre-generate and store all of the different formats, but some servers will convert files (and particularly livestreams) on-the-fly, introducing
a few seconds’ delay in order to deliver the format that’s best-suited to the recipient9. That’s not necessary for downloads, where the
user will often want the highest-quality version of the media (and if they don’t, they’ll select the quality they want at the outset, before the download begins).
Exception #3: streamed media is more-likely to be encumbered with DRM
And then, of course, there’s DRM.
As streaming digital media has become the default way for many people to consume video and audio content, rights holders have engaged in a fundamentally-doomed10
arms race of implementing copy-protection strategies to attempt to prevent end-users from retaining usable downloaded copies of streamed media.
Take HDCP, for example, which e.g. Netflix use for their 4K streams. To download these streams, your device has to be running some decryption code that only works if it can trace a path
to the screen that it’ll be outputting to that also supports HDCP, and both your device and that screen promise that they’re definitely only going to show it and not make it
possible to save the video. And then that promise is enforced by Digital Content Protection LLC only granting a decryption key and a license to use it to manufacturers.11
The real hackers do stuff with software, but people who just want their screens to work properly in spite of HDCP can just buy boxes like this (which I bought for a couple of quid on
eBay). Obviously you could use something like this and a capture card to allow you to download content that was “protected” to ensure that you could only stream it, I suppose, too.
Anyway, the bottom line is that all streaming is, by definition, downloading, and the only significant difference between what people call “streaming” and
“downloading” is that when “streaming” there’s an expectation that the recipient will delete, and not retain, a copy of the video. And that’s it.
Footnotes
1 This isn’t the question I expected to be answering. I made the animation in this post
for use in a different article, but that one hasn’t come together yet, so I thought I’d write about the technical difference between streaming and downloading as an excuse to
use it already, while it still feels fresh.
2 I’m using the example of a video, but this same principle applies to any linear media
that you might stream: that could be a video on Netflix, a livestream on Twitch, a meeting in Zoom, a song in Spotify, or a radio show in iPlayer, for example: these are all examples
of media streaming… and – as I argue – they’re therefore also all examples of media downloading because streaming and downloading are fundamentally the same thing.
3 There are a few simplifications in the first half of this post: I’ll tackle them later
on. For the time being, when I say sweeping words like “every”, just imagine there’s a little footnote that says, “well, actually…”, which will save you from feeling like you have to
say so in the comments.
4 Per my style guide, I’m using the British English
spelling of “analogue”, rather than the American English “analog” which you’ll often find elsewhere on the Web when talking about the analog hole.
5 The rich history of exploiting the analogue hole spans everything from bootlegging a
1970s Led Zeppelin concert by smuggling recording equipment
in inside a wheelchair (definitely, y’know, to help topple the USSR and not just to listen to at home while you get high)
to “camming” by bribing your friendly local projectionist to let you set up a video camera at the back of the cinema for their test screening of the new blockbuster. Until some
corporation tricks us into installing memory-erasing DRM chips into our brains (hey, there’s a dystopic sci-fi story idea in there somewhere!) the analogue hole will always be
exploitable.
6 One might argue that recreating a piece of art from memory, after the fact, is a
very-specific and unusual exploitation of the analogue hole: the one that allows us to remember (or “download”) information to our brains rather than letting it “stream” right
through. There’s evidence to suggest that people pirated Shakespeare’s plays this way!
7 Of course, if you’re watching The LEGO Movie, what you’re seeing might already
look like a pile of LEGO bricks.
8 There are other ways in which the client and server may negotiate, too: for example,
what encoding formats are supported by your device.
9My NAS does live transcoding when Jellyfin streams to devices on my network, and it’s magical!
10 There’s always the analogue hole, remember! Although in practice this isn’t even
remotely necessary and most video media gets ripped some-other-way by clever pirate types even where it uses highly-sophisticated DRM strategies, and then ultimately it’s only
legitimate users who end up suffering as a result of DRM’s burden. It’s almost as if it’s just, y’know, simply a bad idea in the first place, or something. Who knew?
11 Like all these technologies, HDCP was cracked almost immediately and every
subsequent version that’s seen widespread rollout has similarly been broken by clever hacker types. Legitimate, paying users find themselves disadvantaged when their laptop won’t let
them use their external monitor to watch a movie, while the bad guys make pirated copies that work fine on anything. I don’t think anybody wins, here.
The video below is presented in portrait orientation, because your screen is taller than it is wide.
The video below is presented in landscape orientation, because your screen is wider than it is tall.
The video below is presented in square orientation (the Secret Bonus Square Video!), because your screen has approximately the same width as as its height. Cool!
This is possible (with a single <video> element, and without any Javascript!) thanks to some cool HTML features you might not be aware of, which I’ll briefly explain
in the video. Or scroll down for the full details.
<videocontrols><sourcesrc="squareish.mp4"media="(min-aspect-ratio: 0.95) and (max-aspect-ratio: 1.05)"/><sourcesrc="portrait.mp4"media="(orientation: portrait)"/><sourcesrc="landscape.mp4"/></video>
This code creates a video with three sources: squareish.mp4 which is shown to people on “squareish” viewports, failing that portrait.mp4 which is shown to
people whose viewports are taller than wide, and failing that landscape.mp4 which is shown to anybody else.
That’s broadly-speaking how the video above is rendered. No JavaScript needed.
Browsers only handle media queries on videos when they initially load, so you can’t just tip your phone over or resize the window: you’ll need to reload the page, too. But it works!
Give it a go: take a look at the video in both portrait and landscape modes and let me know what you think1.
Adding adaptive bitrate streaming with HLS
Here’s another cool technology that you might not have realised you could “just use”: adaptive bitrate streaming with HLS!
You’ve used adaptive bitrate streaming before, though you might not have noticed it. It’s what YouTube, Netflix, etc. are doing when your network connection degrades and you quickly get
dropped-down, mid-video, to a lower-resolution version2.
Turns out you can do it on your own static hosting, no problem at all. I used this guide (which has a great
description of the parameters used) to help me:
This command splits the H.264 video landscape.mp4 into three different resolutions: the original “v1” (1920×1080, in my case, with 96kbit audio), “v2” (1280×720, with
96kbit audio), and “v3” (640×360, with 48kbit audio), each with a resolution-appropriate maximum bitrate, and forced keyframes every 48th frame. Then it breaks each of those into HLS
segments (.ts files) and references them from a .m3u8 playlist.
The output from this includes:
Master playlist landscape.m3u8, which references the other playlists with reference to their resolution and bandwidth, so that browsers can make smart choices,
Playlists landscape_0.m3u8 (“v1”), landscape_1.m3u8 (“v2”), etc., each of which references the “parts” of that video,
Directories landscape_0/, landscape_1/ etc., each of which contain
data00.ts, data01.ts, etc.: the actual “chunks” that contain the video segments, which can be downloaded independently by the browser as-needed
Bringing it all together
We can bring all of that together, then, to produce a variable-aspect, adaptive bitrate, HLS-streamed video player… in pure HTML and suitable for static hosting:
<videocontrols><sourcesrc="squareish.m3u8"type="application/x-mpegURL"media="(min-aspect-ratio: 0.95) and (max-aspect-ratio: 1.05)"/><sourcesrc="portrait.m3u8"type="application/x-mpegURL"media="(orientation: portrait)"/><sourcesrc="landscape.m3u8"type="application/x-mpegURL"/></video>
You could, I suppose, add alternate types, poster images, and all kinds of other fancy stuff, but this’ll do for now.
One solution is to also provide the standard .mp4 files as an alternate <source>, and that’s fine I guess, but you lose the benefit of HLS (and
you have to store yet more files). But there’s a workaround:
Polyfill full functionality for all browsers
If you’re willing to use a JavaScript polyfill, you can make the code above work on virtually any device. I gave this a go, here, by:
Adding some JavaScript code that detects affected `<video>` elements and applying the fix if necessary:
// Find all <video>s which have HLS sources:for( hlsVideo of document.querySelectorAll('video:has(source[type="application/x-mpegurl"]), video:has(source[type="vnd.apple.mpegurl"])') ) {
// If the browser has native support, do nothing:if( hlsVideo.canPlayType('application/x-mpegurl') || hlsVideo.canPlayType('application/vnd.apple.mpegurl') ) continue;
// If hls.js can't help fix that, do nothing:if ( ! Hls.isSupported() ) continue;
// Find the best source based on which is the first one to match any applicable CSS media queriesconst bestSource =Array.from(hlsVideo.querySelectorAll('source')).find(source=>window.matchMedia(source.media).matches)
// Use hls.js to attach the best source:const hls =new Hls();
hls.loadSource(bestSource.src);
hls.attachMedia(hlsVideo);
}
It makes me feel a little dirty to make a <video>depend on JavaScript, but if that’s the route you want to go down while we wait for HLS support to become
more widespread (rather than adding different-typed sources) then that’s fine, I guess.
This was a fun dive into some technologies I’ve not had the chance to try before. A fringe benefit of being a generalist full-stack developer is that when you’re “between jobs”
you get to play with all the cool things when you’re brushing up your skills before your next big challenge!
(Incidentally: if you think you might be looking to employ somebody like me, my CV is over there!)
Footnotes
1 There definitely isn’t a super-secret “square” video on this page, though. No
siree. (Shh.)
2 You can tell when you get dropped to a lower-resolution version of a video because
suddenly everybody looks like they’re a refugee from Legoland.
I’m keeping an eye out for my next career move (want to hire me?). Off the back of that I’ve been brushing up on the kinds of skills that I might be asked to showcase
in any kind of “tech test”.
Not the kind of stuff I can do with one hand tied behind my back1,
but the things for which I’d enjoy feeling a little more-confident2.
Stuff that’s on my CV that I’ve done and can do, but where I’d like to check before somebody asks me about it in an interview.
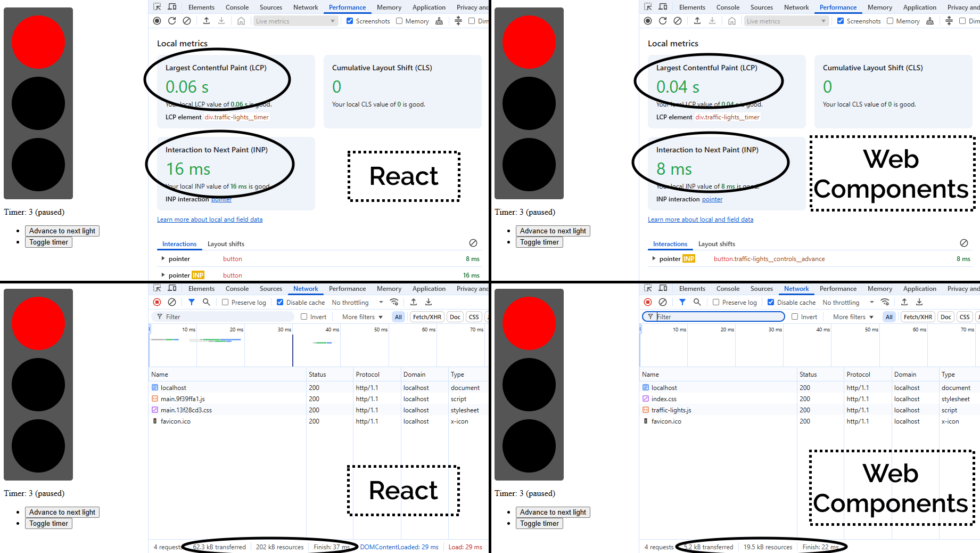
React? Sure, I can do that…
LinkedIn, GlassDoor, and bits of the Fediverse are a gold mine for the kinds of things that people are being asked to demonstrate in tech tests these days. Like this post:
I’d describe myself as a “stack-agnostic senior/principal full-stack/backend web developer/security engineer”3,
and so this question – which feels like it’s a filter for a junior developer with a React specialisation – isn’t really my wheelhouse. Which makes it a perfect excuse for an hour of
playing about with React.
My recent React experience has mostly involved Gutenberg blocks and WordPress theme component. This seemed like an excuse to check that I can wrangle a non-WordPress React stack.
This isn’t particularly sophisticated. I added customisable durations for each light, but otherwise it’s pretty basic.
Half an hour later, I’d proven to myself that yes, I could throw together a fresh application with React DOM and implement some React components, pass state around and whatnot.
Time to move on to the next thing, right? That’s what a normal person would do.
But that’s not the kind of person I am.
Let’s reimplement this as Web Components
What I found myself thinking was… man, this is chunky. React is… not the right tool for this job.
(Or, increasingly, any job. But I’ll get back to that.)
A minified production build of my new component and its dependencies came in at 202kB (62.3kB compressed). That feels pretty massive for something that does so-little.
So as an experiment, I re-implemented my new React component as a vanilla JS Web Component using a custom element. Identical functionality, but no third-party library dependencies.
Here’s what I got:
This one’s interactive. Press a button or two!
The Web Component version of this control has no dependency chain and uses no JSX, and so it has no transpilation step: the source version is production-ready. You could minify it, but
modern HTTP compression makes the impact of that negligible anyway: the whole thing weighs in at 19.5kB (5.2kB compressed) without minification.
And while I appreciate of course that there’s much more to JavaScript complexity and performance than file sizes… and beyond that I appreciate that there’s a lot more to making great
components than the resulting bundle size… it’s hard to argue that delivering the same functionality (and less fragility) in a twelfth of the payload isn’t significant.
By any metric you like, the Web Components version outperforms the React version of my traffic light component. And while it’s a vastly-simplified example, it scales. Performance is a
UX concern, and if you favour “what we’re familiar with” over “what’s best for our users”, that has to be a conscious choice.
But there’s a bigger point here:
React is the new jQuery
I’m alarmed by the fact that I’m still seeing job ads for “React developers”, with little more requirement than an ability to “implement things in React”.
From where I’m sitting, React is the new jQuery. It:
Was originally built to work around missing or underdeveloped JavaScript functionality
e.g. React’s components prior to Web Components
e.g. jQuery’s manipulation prior to document.querySelectorAll
Continued to be valuable as a polyfill and as a standard middleware while that functionality become commonplace
e.g. jQuery’s $.ajax until the Fetch API was a reliable replacement to XMLHttpRequest
No longer provides enough value to be worth using in a new project
And yet somehow gets added “out of habit” for many years
If you’ve got a legacy codebase with lots of React in it, you’re still going to need React for a while. Just like how you’re likely to continue to need jQuery for a while until you can
tidy up all those edge-cases where you’re using it.
(You might even be locked-in to using both React and jQuery for some time, if say you’ve got a plugin architecture that demands backwards-compatibility: I’m looking at you,
WordPress!)
But just as you’re already (hopefully) working to slowly extricate your codebases from any now-unnecessary jQuery dependencies they have… you should be working on an exit plan for your
React code, too. It’s done its time; it’s served its purpose: now it’s just a redundant dependency making your bundles cumbersome and harder to debug.
Everything React gives you on the client-side – components, state/hooks, routing4,
etc. – is possible (and easy) in modern JavaScript supported in all major browsers. And if you still really want an abstraction layer, there are plenty of options (and they’re
all a lot lighter than React!).
The bottom line is, I suppose…
You shouldn’t be hiring “React developers”!
If you’re building a brand new project, you shouldn’t be using React. It should be considered deprecated.
If you’ve got an existing product that depends on React… you should be thinking about how you’ll phase it out over time. And with that in mind, you want to be hiring versatile
developers. They’ll benefit from some experience with React, sure, but unless they can also implement for the modern Web of tomorrow, they’ll just code you deeper into
your dependency on React.
It’s time you started recruiting “Front-End Developers (React experience a plus)”. Show some long-term thinking! Or else the Web is going to move on without you, and in 5-10 years
you’ll struggle to recruit people to maintain your crumbling stack.
1 Exploiting or patching an injection vulnerability, optimising an SQL query, implementing
a WordPress plugin, constructing a CircleCI buildchain, expanding test coverage over a Rubygem, performing an accessibility audit of a web application, extending a set of
high-performance PHP-backed REST endpoints, etc. are all – I’d hope! – firmly in the “hold my beer” category of tech test skills I’d ace, for example. But no two tech stacks are
exactly alike, so it’s possible that I’ll want to brush up on some of the adjacent technologies that are in the “I can do it, but I might need to hit the docs pages”
category.
2 It’s actually refreshing to be learning and revising! I’ve long held that I should learn
a new programming language or framework every year or two to stay fresh and to keep abreast of what’s going on in world. I can’t keep up with every single new front-end JavaScript
framework any more (and I’m not sure I’d want to!)! But in the same way as being multilingual helps unlock pathways to more-creative thought and expression even if you’re only working
in your native tongue, learning new programming languages gives you a more-objective appreciation of the strengths and weaknesses of what you use day-to-day. tl;dr: if you haven’t
written anything in a “new” (to you) programming language for over a year, you probably should.
3 What do job titles even mean, any more? 😂 A problem I increasingly find is that I don’t
know how to describe what I do, because with 25+ years of building stuff for the Web, I can use (and have used!) most of the popular stacks, and could probably learn a new
one without too much difficulty. Did I mention I’m thinking about my next role? If you think we might “click”, I’d love to hear from you…
4 Though if you’re doing routing only on the client-side, I already hate you.
Consider for example the SlimJS documentation which becomes completely unusable if a third-party JavaScript CDN fails: that’s pretty
fragile!
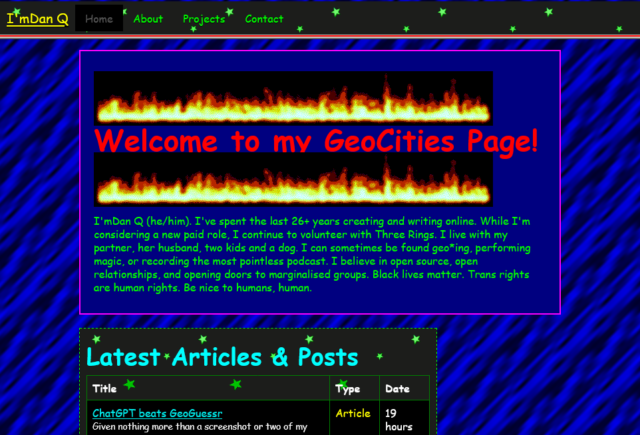
Sure, it’s gaudy, but it’s got a few things going for it, too.
Let’s put aside for the moment that you can already send my website back into “90s mode” and dive into this take on how I could
present myself in a particularly old-school way. There’s a few things I particularly love:
It’s actually quite lightweight: ignore all the animated GIFs (which are small anyway) and you’ll see that, compared to my current homepage, there are very few
images. I’ve been thinking about going in a direction of less images on the homepage anyway, so it’s interesting to see how it comes together in this unusual context.
The page sections are solidly distinct: they’re a mishmash of different widths, some of which exhibit a horrendous lack of responsivity, but it’s pretty clear where
the “recent articles” ends and the “other recent stuff” begins.
The post kinds are very visible: putting the “kind” of a post in its own column makes it really clear whether you’re looking at an article, note, checkin, etc., much
more-so than my current blocks do.
Maybe there’s something we can learn from old-style web design? No, I’m serious. Stop laughing.
90s web design was very-much characterised by:
performance – nobody’s going to wait for your digital photos to download on narrowband connections, so you hide them behind descriptive links or tiny thumbnails, and
pushing the boundaries – the pre-CSS era of the Web had limited tools, but creators worked hard to experiment with the creativity that was possible within those
limits.
Those actually… aren’t bad values to have today. Sure, we’ve probably learned that animated backgrounds, tables for layout, and mystery meat navigation were horrible for
usability and accessibility, but that doesn’t mean that there isn’t still innovation to be done. What comes next for the usable Web, I wonder?
As soon as you run a second or third website through the tool, its mechanisms for action become somewhat clear and sites start to look “samey”, which is the opposite of what
made 90s Geocities great.
The only thing I can fault it on is that it assumes that I’d favour Netscape Navigator: in fact, I was a die-hard Opera-head for most of the
nineties and much of the early naughties, finally switching my daily driver to Firefox in 2005.
I certainly used plenty of Netscape and IE at various points, though, but I wasn’t a fan of the divisions resulting from the browser wars. Back in the day, I always backed
the ideals of the “Viewable With Any Browser” movement.
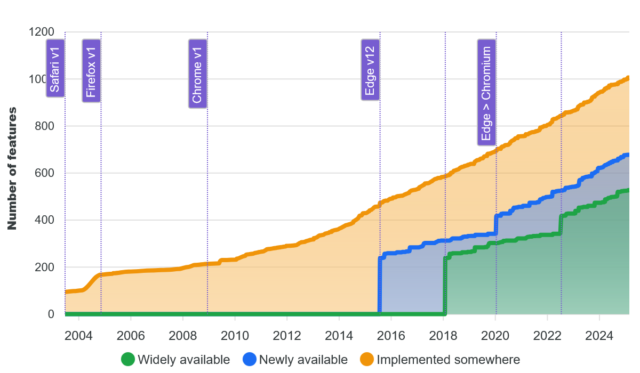
The W3C‘s WebDX Community Group this week announced that they’ve reached a milestone with their web-features project. The project is an effort to catalogue browser support for Web features, to establish an
understanding of the baseline feature set that developers can rely on.
That’s great, and I’m in favour of the initiative. But I wonder about graphs like this one:
The graph shows the increase in time of the number of features available on the Web, broken down by how widespread they are implemented across the browser corpus.
The shape of that graph sort-of implies that… more features is better. And I’m not entirely convinced that’s true.
Does “more” imply “better”?
Don’t get me wrong, there are lots of Web features that are excellent. The kinds of things where it’s hard to remember how I did without them. CSS grids are for many purposes an
improvement on flexboxes; flexboxes were massively better than floats; and floats were an enormous leap forwards compared to using tables for layout! The “new” HTML5 input types are
wonderful, as are the revolutionary native elements for video, audio, etc. I’ll even sing the praises of some of the new JavaScript APIs (geolocation, web share, and push are
particular highlights).
But it’s not some kind of universal truth that “more features means better developer experience”. It’s already the case, for example, that getting started as a Web developer is
harder than it once was, and I’d argue harder than it ought to be. There exist complexities nowadays that are barriers to entry. Like the places where the promise of a
progressively-enhanced Web has failed (they’re rare, but they exist). Or the sheer plethora of features that come with caveats to their use that simply must be learned (yes, you need a
<meta name="viewport">; no, you can’t rely on JS to produce content).
Meanwhile, there are technologies that were standardised, and that we did need, but that never took off. The <keygen> element never got
implemented into the then-dominant Internet Explorer (there were other implementation problems too, but this one’s the killer). This made it functionally useless, which meant that its
standard never evolved and grew. As a result, its implementation in other browsers stagnated and it was eventually deprecated. Had it been implemented properly and iterated on, we’d
could’ve had something like WebAuthn over a decade earlier.
Which I guess goes to show that “more features is better” is only true if they’re the right features. Perhaps there’s some way of tracking the changing landscape of developer
experience on the Web that doesn’t simply count enumerate a baseline of widely-available features? I don’t know what it is, though!
A simple web
Mostly, the Web worked fine when it was simpler. And while some of the enhancements we’ve seen over the decades are indisputably an advancement, there are also plenty of places
where we’ve let new technologies lead us astray. Third-party cookies appeared as a naive consequence of first-party ones, but came to be used to undermine everybody’s privacy. Dynamic
DOM manipulation started out as a clever idea to help with things like form validation and now a significant number of websites can’t even show their images – or sometimes their text –
unless their JavaScript code gets downloaded and interpreted successfully.
Were you reading this article on Medium, you’d have downloaded ~5MB of data including 48 JS files and had 7 cookies set, just so you could… have most of the text covered with
popovers? (for comparison, reading it here takes about half a megabyte and the cookies are optional delicious)
A blog post, news article, or even an eCommerce site or social networking platform doesn’t need the vast majority of the Web’s “new” features. Those features are important for some Web
applications, but most of the time, we don’t need them. But somehow they end up being used anyway.
Whether or not the use of unnecessary new Web features is a net positive to developer experience is debatable. But it’s certainly not often to the benefit of user experience.
And that’s what I care about.
My love of the yesterweb forced me to teach myself just-enough Blender to make an animation for a stupid thing: an 88×31 button representing “me” (and, I suppose, my blog, whenever I
next end up redesigning its theme).
Had a fight with the Content-Security-Policy header today. Turns out, I won, but not without sacrifices.
Apparently I can’t just insert <style> tags into my posts anymore, because otherwise I’d have to somehow either put nonces on them, or hash their content (which would
be more preferrable, because that way it remains static).
I could probably do the latter by rewriting HTML at publish-time, but I’d need to hook into my Markdown parser and process HTML for that, and, well, that’s really complicated,
isn’t it? (It probably is no harder than searching for Webmention links, and I’m overthinking it.)
I’ve had this exact same battle.
Obviously the intended way to use nonces in a Content-Security-Policy is to have the nonce generated, injected, and served in a single operation. So in PHP,
perhaps, you might do something like this:
<?php$nonce=bin2hex(random_bytes(16));
header("Content-Security-Policy: script-src 'nonce-$nonce'");
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>PHP CSP Nonce Test</title>
</head>
<body>
<h1>PHP CSP Nonce Test</h1>
<p>
JavaScript did not run.
</p>
<!-- This JS has a valid nonce: -->
<script nonce="<?phpecho$nonce; ?>">
document.querySelector('p').textContent = 'JavaScript ran successfully.';
</script>
<!-- This JS does not: -->
<script nonce="wrong-nonce">
alert('The bad guys won!');
</script>
</body>
</html>
Viewing this page in a browser (with Javascript enabled) should show the text “JavaScript ran successfully.”, but should not show an alertbox containing the text “The bad
guys won!”.
But for folks like me – and you too, Vika,, from the sounds of things – who serve most of their pages, most of the time, from the cache or from static HTML files… and who add the CSP
header on using webserver configuration… this approach just doesn’t work.
I experimented with a few solutions:
A long-lived nonce that rotates.
CSP allows you to specify multiple nonces, so I considered having a rotating nonce that was applied to pages (which were then cached for a period) and delivered
by the header… and then a few hours later a new nonce would be generated and used for future page generations and appended to the header… and after the
cache expiry time the oldest nonces were rotated-out of the header and became invalid.
Dynamic nonce injection.
I experimented with having the webserver parse pages and add nonces: randomly generating a nonce, putting it in the header, and then basically doing a
s/<script/<script nonce="..."/ to search-and-replace it in.
Both of these are terrible solutions. The first one leaves a window of, in my case, about 24 hours during which a successfully-injected script can be executed. The second one
effectively allowlists all scripts, regardless of their provenance. I realised that what I was doing was security theatre: seeking to boost my A-rating to an A+-rating on SecurityHeaders.com without actually improving security at all.
But the second approach gave me an idea. I could have a server-side secret that gets search-replaced out. E.g. if I “signed” all of my legitimate scripts with something like
<script nonce="dans-secret-key-goes-here" ...> then I could replace s/dans-secret-key-goes-here/actual-nonce-goes-here/ and thus have the best of both
worlds: static, cacheable pages, and actual untamperable nonces. So long as I took care to ensure that the pages were never delivered to anybody with the secret key still
intact, I’d be sorted!
Alternatively, I was looking into whether Caddy can do something like mod_asis does for Apache: that is, serve a
file “as is”, with headers included in the file. That way, I could have the CSP header generated with the page and then saved into the cache, so it’s delivered with the same
none every time… until the page changes. I’d love more webservers to have an “as is” mode, but I appreciate that might be a big ask (Apache’s mechanism, I suspect,
exploits the fact that HTTP/1.0 and HTTP/1.1 literally send headers, followed by two CRLFs, then content… but that’s not what happens in HTTP/2+).
So yeah, I’ll probably do a server-side-secret approach, down the line. Maybe that’ll work for you, too.
As I mentioned in my recent Blog Questions Challenge, I recently switched my blog from WordPress, which it had been running on for over 20 years of its 26 year history, to ClassicPress.1
I’m aware that I’m not the only person for whom ClassicPress might be a better fit
than WordPress2,
so I figured I should share the process by which I undertook the change.
Switching from WordPress to ClassicPress
Switching from WordPress to ClassicPress should be a non-destructive, 100% reversible process, but (even though I’ve got solid backups) I wasn’t ready to
trust that, so I decided to operate on a copy of my site. I’m glad I did, because there were a couple of teething issues I needed to tackle before I could launch.
1. Duplicating the site
I took a simple approach to duplicating the site: (1) I copied the site directory, and (2) I copied the database, and (3) I set up a new subdomain to use for testing. Here’s how I did
each step:
1.1. Copying the site directory
This should’ve been simple, but a du -sh revealed that my /wp-content/uploads directory is massive (I should look into that) and I didn’t want to
clone it. And I didn’t want r need to clone my /wp-content/cache directory either. So I ran:
rsync -av --exclude=wp-content ./old-site-directory/ ./new-site-directory/ to copy everything exceptwp-content, and then
rsync -av --exclude=uploads --exclude=cache ./old-site-directory/wp-content/ ./new-site-directory/wp-content/ to copy wp-contentexcept the
uploads and cache subdirectories, and then finally
ln -s ./old-site-directory/wp-content/uploads ./new-site-directory/wp-content/uploads to symlink the uploads directory, sharing it between the two sites
1.2. Copying the database
I just piped mysqldump into mysql to clone from one database to the other:
mysqldump -uUSERNAME -p --lock-tables=false old-site-database | mysql -uUSERNAME -p new-site-database
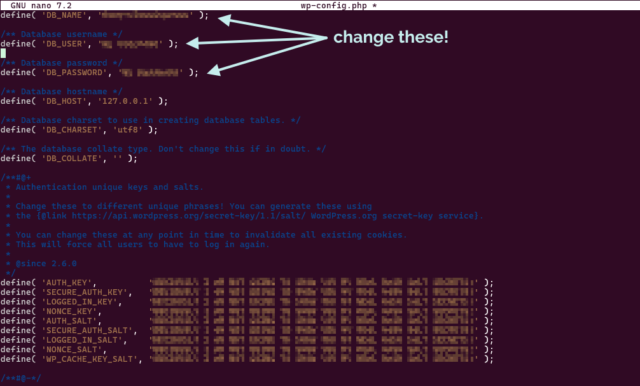
I edited DB_NAME in wp-config.php in the new site’s directory to point it at the new database.
If you’re going to clone your WordPress site before converting to ClassicPress, you’ll want to be comfortable editing your wp-config.php.
1.3. Setting up a new subdomain
My DNS is already configured with a wildcard to point (almost) all *.danq.me subdomains to this server already. I decided to use the name classicpress-testing.danq.me as my
temporary/test domain name. To keep any “changes” to my cloned site to a minimum, I overrode the domain name in my wp-config.php rather than in my database, by adding the
following lines:
Because I use Caddy/FrankenPHP as my webserver3,
configuration was really easy: I just copied the relevant part of my Caddyfile (actually an include), changed the domain name and the root, and it just worked,
even provisioning me out a LetsEncrypt SSL certificate. Magical4.
2. Switching the duplicate to ClassicPress
Now that I had a duplicate copy of my blog running at https://classicpress-testing.danq.me/, it was time to switch it to ClassicPress. I started by switching my wp-admin
colour scheme to a different one in my cloned site, so it’d be immediately visually-obvious to me if I’d accidentally switched and was editing the “wrong” site (I also made sure I was
logged-out of my primary, live site, so I was confident I wouldn’t break anything while I was experimenting!).
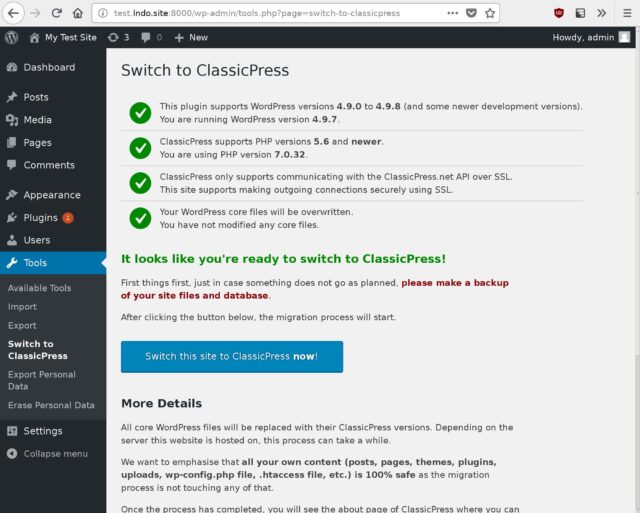
ClassicPress provides a migration plugin which checks for common problems and then switches your site
from WordPress to ClassicPress, so I installed it and ran it. It said that everything was okay except for my (custom) theme and a my self-built plugins, which it understandably couldn’t
check compatibility of. It recommended that I install Twenty Seventeen – the last WordPress default theme to not
require the block editor – but I didn’t do so: I was confident that my theme would work anyway… and if it didn’t, I’d want to fix it rather than switch theme!
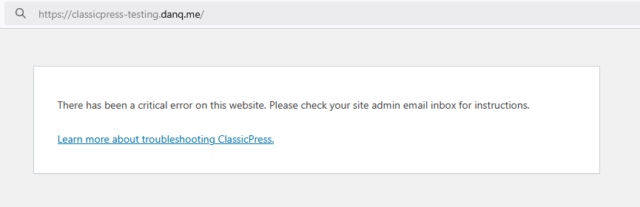
I failed to take a screenshot of the actual process, but it looked broadly like this.
And then… it all broke.
3. Fixing what broke
After swiftly doing a safety-check that my live site was still intact, I started trying to work out why my site wasn’t broken. Debugging a ClassicPress PHP issue is functionally
identical to debugging a similar WordPress issue, for obvious reasons: check the logs, work out what’s broken, realise it’s a plugin, disable that plugin while you investigate further,
etc.
EWWW Image Optimizer: I use this plugin to pregenerate WebP variants of my images, which I then serve using webserver rules. It’s not a
complex job, and I should probably integrate the feature into my theme at some point, but for now I use this plugin. Version 8.0.0 of the plugin doesn’t work on ClassicPress 2.3.1, so
I used WP-CLI to downgrade to the last version that does (7.7.0), and then it worked fine.
Dan’s Geocaching Log Reposter: a self-made plugin that copies my logs from geocaching websites stopped working properly, which I think is because
ClassicPress is doing a more-aggressive job than WordPress at nonce validation on admin REST endpoints? I put a quick hack into my plugin to work around it, but I’ll need to look into
this properly at some point.
Some other bits of my stack, e.g. CapsulePress (my Gemini/Spartan/Nex server), have their own copies of my
database credentials, because I’ve been too lazy to centralise them into environment variables, and needed updating (but not until live switchover time).
I ran the two sites in-parallel for a couple of weeks, with the ClassicPress one as a “read only” version (so I didn’t pollute my uploads directory!), but it was pretty unnecessary
because it all worked pretty seamlessly, despite my complex stack of custom code. When I wanted to switch for-real, all I needed to do was swap the domain names over in my Caddyfile and
edit the wp-config.php of my ClassicPress installation: step 1.3, but in reverse!
If you hadn’t been told5, you probably wouldn’t have even known I’d made a change: I suppress basically all infrastructure-identifying
headers from my server output as a matter of course, and ClassicPress and WordPress are functionally-interchangeable from a front-end perspective6.
So what’s difference?
From my experience, here are the differences I’ve discovered since switching from WordPress to ClassicPress:
The good stuff
😅 ClassicPress has no Gutenberg/block editor. This would absolutely be a showstopper for many people, and that’s fine: I have nothing against the block editor (I
use it basically every day elsewhere!), but I’ve never really used it on danq.me and don’t feel the need to change that! My theme, my workflow, and my custom plugins are all
geared around the perfectly-good “classic” editor, and so getting a more-lightweight CMS by removing a feature I wasn’t using anyway falls somewhere between neutral and a blessing.
⚡The backend is fast again! One of the changes the ClassicPress team have been working on applying to WordPress is to strip out jQuery and other redundancies from
the backend, and I love how much faster and lighter my editor interface is as a result. (With caveat; see below!)
🔌Virtually everything “just works”. With the few exceptions described above, everything works exactly as it does under WordPress. Which is what you’d hope for a fork
that’s mostly “WordPress, but without the block editor”, right, but it’s still reassuring (and, for me, an essential feature). There are a few “new” features to do with paging through
posts and the media library and they’re fine, I suppose, but not by themselves worth switching for (though it might be nice to backport them into WordPress!).
The bad stuff
🏷️ Adding tags to posts takes a step backwards. A side-effect of dropping jQuery is the partial loss of the autocomplete feature when selecting tags to add to a post.
You still get a partial autocomplete, but not after typing a comma: you need to press enter to submit the tag you were writing and then start typing them next, which
frankly sucks. This is because they’re relying on a <datalist>, which isn’t as full-featured as the Javascript solution WordPress employs. This bugs
me almost enough to be a showstopper, but I gather it’s getting fixed in a near-future version.
🗺️ You’re in uncharted territory when things go wrong. One great benefit of WordPress is the side-effects of its ubiquity. If you have a query or a problem
you can throw a stone at your favourite search engine and get a million answers… and some of them will even be right! If you have a problem in ClassicPress and it’s not shared with (or
you’re not sure if it’s shared with) WordPress… you’re mostly on your own. The forums are good and friendly,
but if you want a quick answer to something, you’re likely to have to roll your sleeves up and open some source code. I don’t mind this at all – when I first started using WordPress,
this was the case, too! – but it might be a showstopper for some folks.
In summary: I’m enjoying using ClassicPress, even where there are rough edges. For me, 99% of my experience with it is identical to how I used WordPress anyway, it’s relatively
lightweight and fast, and it’s easy enough to switch back if I change my mind.
Footnotes
1 It saddens me that I have to keep clarifying this, but I feel like I do: my switch from
WordPress to ClassicPress is absolutely nothing to do with any drama in the WordPress space that’s going on right now: in fact, I’d been planning to try it out since before
any of the drama appeared. I appreciate that some people making a similar switch, including folks who use this blog post as a guide, might have different motivations to me, and that’s
fine too. Personally, I think that ditching an installation of open-source WordPress based on your interpretation of what’s going on in the ecosystem is… short-sighted? But
hey: the joy of open source is you can – and should! – do what you want. Anyway: the short of it is – the desire to change from WordPress to ClassicPress was, for me, 100% a
technical decision and 0% a political one. And I’ll thank you for leaving any of your drama at the door if you slide into my comments, ta!
2Matt recently described ClassicPress as “the last decent fork
attempt for WordPress”, and I absolutely agree. There’s been a spate of forks and reimplementations recently. I’ve looked into many of them and been… very much underwhelmed. Want my
hot take? Sure, here you go: AspirePress is all lofty ideas and no deliverables. FreeWP seems to be the same, but somehow without the lofty ideas. ForkPress is a ghost. Speaking of
ghosts, Ghost isn’t a WordPress fork; they have got some cool ideas though. b2evolution is even less a WordPress fork but it’s pretty cool in its own right. I’m not sure what
clamPress is trying to achieve but I’ve not given it a serious look. So yeah: ClassicPress is, in my mind, the only WordPress fork even worth consideration at this point, and as I
describe in this blog post: it’s not for everybody.
3 I switched from Nginx over the winter and it’s been just magical: I really love
Caddy’s minimal approach to production configuration. The only thing I’ve been able to fault it on is that it’s not capable of setting up client-side SSL certificate authentication on
a path, only on an entire domain, which meant I needed to reimplement the authentication mechanism I use on a small part of my (non-blog) internal
infrastructure.
4 To be fair, it wouldn’t have been hard if I’d still be using Nginx, because I’d
set up Certbot to use DNS-based vertification to issue me wildcard SSL certificates. But doing this in Caddy still felt magical.
6 Indeed, I wouldn’t have considered a switch to ClassicPress in the first place if it
wasn’t a closely-aligned-enough fork that I retained the ability to flip-flop between the two to my heart’s content! I’ve loved WordPress for over two decades; that’s not going to
change any time soon… and if e.g. ClassicPress ceased tracking WordPress releases and the fork diverged too far for my comfort, I’d probably switch back to regular old WordPress!
Large companies find HTML & CSS frustrating “at scale” because the web is a fundamentally anti-capitalist mashup art experiment, designed to give consumers all the power.
This. This is what I needed to be reminded, today.
When somebody complains that the Web is hard to scale, they’re already working against the grain of the Web.
At its simplest – and the way we used to use it – a website is a collection of .html files, one of which might have a special name so the webserver knows to put it first.
Writing HTML is punk rock. A “platform” is the tool of the establishment.
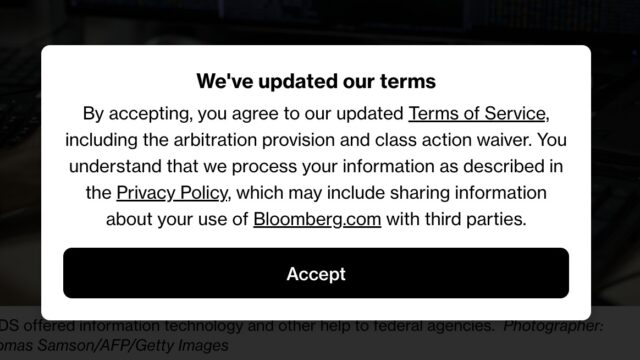
While perfectly legal, it is remarkable that to read a Bloomberg article, you must first agree to binding arbitration and waive your class action rights.
I don’t often see dialog boxes like this one. In fact, if I go to the URL of a Bloomberg.com article, I don’t see any popups: nothing about privacy, nothing about cookies,
nothing about terms of service, nothing about only being allowed to read a limited number of articles without signing up an account. I just… get… the article.
The reason for this is, most-likely, because my web browser is configured, among other things, to:
Block all third-party Javascript (thanks, uBlock Origin‘s “advanced mode”), except on domains where they’re explicitly allowed (and even then
with a few exceptions: thanks, Ghostery),
Delete all cookies 30 seconds after I navigate away from a domain, except for domains that are explicitly greylisted/allowlisted (thanks, Cookie-AutoDelete), and
But here’s the thing I’ve always wondered: if I don’t get to see a “do you accept our terms and conditions?” popup, is is still enforceable?
Obviously, one could argue that by using my browser in a non-standard configuration that explicitly results in the non-appearance of “consent” popups that I’m deliberately turning a
blind eye to the popups and accepting them by my continued use of their services1. Like: if I pour a McDonalds coffee on my lap having
deliberately worn blinkers that prevent me reading the warning that it’s hot, it’s not McDonalds’ fault that I chose to ignore their helpful legally-recommended printed warning on the cup, right?2
But I’d counter that if a site chooses to rely on Javascript hosted by a third party in order to ask for consent, but doesn’t rely on that same third-party in
order to provide the service upon which consent is predicated, then they’re setting themselves up to fail!
The very nature of the way the Internet works means that you simply can’t rely on the user successfully receiving content from a CDN. There are all kinds of reasons my browser might not
get the Javascript required to show the consent dialog, and many of them are completely outside of the visitor’s control: maybe there was a network fault, or CDN downtime, or my
browser’s JS engine was buggy, or I have a disability and the technologies I use to mitigate its impact on my Web browsing experience means that the dialog isn’t read out to me. In any
of these cases, a site visitor using an unmodified, vanilla, stock web browser might visit a Bloomberg article and read it without ever being asked to agree to their terms and
conditions.
Would that be enforceable? I hope you’ll agree that the answer is: no, obviously not!
It’s reasonably easy for a site to ensure that consent is obtained before providing services based on that consent. Simply do the processing server-side, ask for whatever
agreement you need, and only then provide services. Bloomberg, like many others, choose not to do this because… well, it’s probably a combination of developer laziness and
search engine optimisation. But my gut feeling says that if it came to court, any sensible judge would ask them to prove that the consent dialog was definitely viewed by
and clicked on by the user, and from the looks of things: that’s simply not something they’d be able to do!
tl;dr: if you want to fight with Bloomberg and don’t want to go through their arbitration, simply say you never saw or never agreed to their terms and conditions – they
can’t prove that you did, so they’re probably unenforceable (assuming you didn’t register for an account with them or anything, of course). This same recommendation applies to many,
many other websites.
Footnotes
1 I’m confident that if it came down to it, Bloomberg’s lawyers would argue
exactly this.
2 I see the plaintiff’s argument that the cups were flimsy and obviously her injuries were
tragic, of course. But man, the legal fallout and those “contents are hot” warnings remain funny to this day.
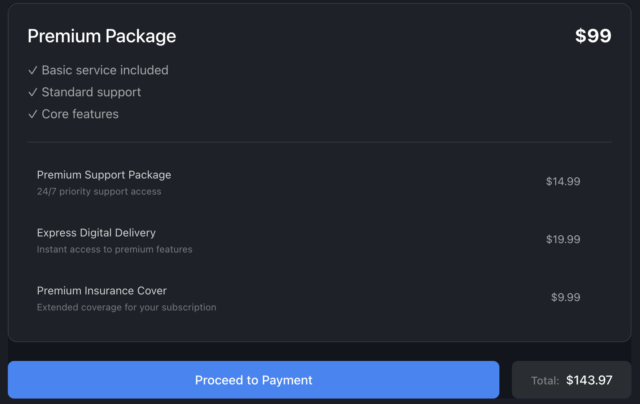
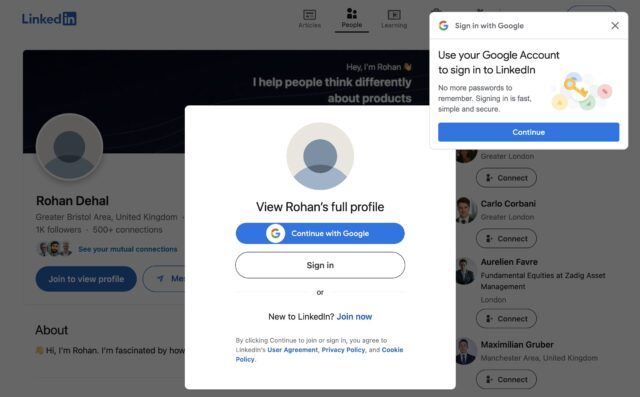
This was fun. A simple interactive demonstration of ten different dark patterns you’ve probably experienced online. I might
use it as a vehicle for talking about such deceptive tactics with our eldest child, who’s now coming to an age where she starts to see these kinds of things.
After I finished exploring the dark patterns shown, I decided to find out more about the author and clicked the link in the footer, expecting to be taken to their personal web site. But
instead, ironically, I came to a web page on a highly-recognisable site that’s infamous for its dark patterns: 🤣