As it’s Global Accessibility Awareness, I’m sharing a list of accessibility resources that I regularly refer to. Happy reading, watching and listening!
…
A fabulously-useful concise list of some of the hottest articles, books, and webinars on accessibility in web development; saved for my later convenience.
Actually (cue Adam Conover!)… some people do. They represent about a tenth of a percent (0.1%) of the people who don’t get your JavaScript file, though, and they’ve chosen to browse
the web that way, so let’s ignore them for a second.
I see this argument—that one one disables JS in 2019—as an argument for not bothering to care or worry about progressive enhancement. But it’s wrong!
There are plenty of other reasons why people don’t get your JavaScript.
Your CDN fails
An ad blocker or filewall got a little overly aggressive
A JS error (either in your code or something third-party) stops all of the JS from rendering
The file times out because it’s too big or too slow to parse
Today, I want to focus on that last one.
…
So very much this. Web bloat is becoming a huge issue (incidentally, I was pleased to see that DanQ.me’s homepage Web Bloat Score is in the
region of a nice, clean 0.1, but I’m confident that there’s still plenty I could do to improve it); it’s easy to see how developers on their powerful desktops and laptops and with their
WiFi-connected high-end smartphones might overlook people on older, less-powerful devices and slower, lower-bandwidth connections.
I’m not saying that Javascript is bad: it’s not! I’m saying that where functionality exists in simpler, more-lightweight technologies (like good old-fashioned links and regular
<input> elements, both of which are routinely reimplemented in the front-end), then those technologies should be used in the first instance. If you
want to build on top of that with Javascript, that’s great! But starting from the ground floor when building for the web is the surest way to support the widest
diversity of potential users (and it makes it easier to achieve your accessibility goals, too!)
When I write a blog post, it generally becomes a static thing: its content always
usually stays the same for the rest of its life (which is, in my case, pretty much forever). But sometimes, I go back and make an
amendment. When I make minor changes that don’t affect the overall meaning of the work, like fixing spelling mistakes and repointing broken links, I just edit the page, but for
more-significant changes I try to make it clear what’s changed and how.
This blog post from 2007, for example, was amended after its publication with the insertion of content at the top and the deletion
of content within.
Historically, I’d usually marked up deletions with the HTML <strike>/<s> elements (or
other visually-similar approaches) and insertions by clearly stating that a change had been made (usually accompanied by the date and/or time of the change), but this isn’t a good
example of semantic code. It also introduces an ambiguity when it clashes with the times I use <s> for comedic effect in the Web equivalent of the old caret-notation joke:
Be nice to this fool^H^H^H^Hgentleman, he's visiting from corporate HQ.
Better, then, to use the <ins> and <del> elements, which were designed for exactly this purpose and even accept attributes to specify the date/time
of the modification and to cite a resource that explains the change, e.g. <ins datetime="2019-05-03T09:00:00+00:00"
cite="https://alices-blog.example.com/2019/05/03/speaking.html">The last speaker slot has now been filled; thanks Alice</ins>. I’ve worked to retroactively add such
semantic markup to my historical posts where possible, but it’ll be an easier task going forwards.
Of course, no browser I’m aware of supports these attributes, which is a pity because the metadata they hold may well have value to a reader. In order to expose them I’ve added a little
bit of CSS that looks a little like this, which makes their details (where available) visible as a sort-of tooltip when hovering
over or tapping on an affected area. Give it a go with the edits at the top of this post!
ins[datetime],del[datetime]{position:relative;}ins[datetime]::before,del[datetime]::before{position:absolute;top:-24px;font-size:12px;color:#fff;border-radius:4px;padding:2px6px;opacity:0;transition:opacity0.25s;
hyphens:none;/* suppresses sitewide line break hyphenation rules */white-space:nowrap;/* suppresses extraneous line breaks in Chrome */}ins[datetime]:hover::before,del[datetime]:hover::before{opacity:0.75;}ins[datetime]::before{content:'inserted 'attr(datetime)''attr(cite);background:#050;/* insertions are white-on-green */}del[datetime]::before{content:'deleted 'attr(datetime)''attr(cite);background:#500;/* deletions are white-on-red */}
CSS facilitating the display of <ins>/<del> datetimes and citations on hover or touch.
I’m aware that the intended use-case of <ins>/<del> is change management, and that the expectation is that the “final” version of a
document wouldn’t be expected to show all of the changes that had been made to it. Such a thing could be simulated, I suppose, by appropriately hiding and styling the
<ins>/<del> blocks on the client-side, and that’s something I might look into in future, but in practice my edits are typically small and rare
enough that nobody would feel inconvenienced by their inclusion/highlighting: after all, nobody’s complained so far and I’ve been doing exactly that, albeit in a non-semantic way, for
many years!
I’m also slightly conscious that my approach to the “tooltip” might cause it to obstruct interactivity with something directly above an insertion or deletion: e.g. making a hyperlink
inaccessible. I’ve tested with a variety of browsers and devices and it doesn’t seem to happen (my line height works in my favour) but it’s something I’ll need to be mindful of if I
change my typographic design significantly in the future.
A final observation: I love the CSS attr() function, and I’ve been using it (and counter()) for all
kinds of interesting things lately, but it annoys me that I can only use it in a content: statement. It’d be amazingly valuable to be able to treat integer-like attribute
values as integers and combine it with a calc() in order to facilitate more-dynamic styling of arbitrary sets of HTML elements. Maybe one day…
For the time being, I’m happy enough with my new insertion/deletion markers. If you’d like to see them in use in their natural environment, see the final paragraph of my 2012 review of The Signal and The Noise.
few weeks back, we were chatting about the architecture of the Individual Electoral Registration web service. We started discussing the pros and cons of an approach that would provide a significantly
different interaction for any people not running JavaScript.
“What proportion of people is that?” an inquisitive mind asked.
Silence.
We didn’t really have any idea how many people are experiencing UK government web services without the enhancement of JavaScript. That’s a bad thing for a team that is evangelical
about data driven design, so I thought we should find out.
The answer is:
1.1% of people aren’t getting Javascript enhancements (1 in 93)
…
This article by the GDS is six years old now, but its fundamental point is still as valid as ever: a small proportion
(probably in the region of 1%) of your users won’t experience some or all of the whizzy Javascript stuff on your website, and it’s not because they’re a power user who disables
Javascript.
There are so many reasons a user won’t run your Javascript, including:
They’re using a browser that doesn’t support Javascript (or doesn’t support the version you’re using)
They, or somebody they share their device with, has consciously turned-off Javascript either wholesale or selectively, in order to for example save bandwidth, improve speed,
reinforce security, or improve compatibility with their accessibility technologies
They’re viewing a locally-saved, backed-up, or archived version of your page (possibly in the far future long after your site is gone)
Their virus scanner mis-classified your Javascript as potentially malicious
One or more of your Javascript files contains a bug which, on their environment, stops execution
One or more of your Javascript files failed to be delivered, for example owing to routing errors, CDN downtime,
censorship, cryptographic handshake failures, shaky connections, cross-domain issues, stale caches…
On their device, your Javascript takes too long to execute or consumes too many resources and is stopped by the browser
Fundamentally, you can’t depend on Javascript and so you shouldn’t depend on it being there, 100% of the time, when it’s possible not to. Luckily, the Web already
gives us all the tools we need to develop the vast, vast majority of web content in a way that doesn’t depend on Javascript. Back in the 1990s we just called it “web
development”, but nowadays Javascript (and other optional/under-continuous-development web technologies like your favourite so-very-2019 CSS hack) is so ubiquitous that we give it the special name “progressive enhancement” and make a whole practice out of it.
The Web was designed for forwards- and backwards-compatibility. When you break that, you betray your users and you make work for yourself.
(by the way: I know I plugged the unpoly framework already, the other day, but you should
really give it a look if you’re just learning how to pull off progressive enhancement)
But as much as we developers hope for it to go away, it just. Won’t. Die. IE8 continues to show up in browser stats, especially outside of the bubble of the Western
world.
…
Sure, you aren’t developing for IE8 any more. But you should be developing with progressive enhancement, and
if you do that right, you get all kinds of compatibility, accessibility, future- and past-proofing built-in. This isn’t just about supporting the (many) African countries where
IE8 usage remains at over 1%… it’s about supporting the Web’s openness and archivibility and following best-practice in
your support of new technologies.
Asynchronous JavaScript in the form of Single Page Applications (SPA) offer an incredible opportunity for improving the user experience of your web
applications. CSS frameworks like Bootstrap enable developers to quickly contribute styling as they’re working on the structure and behaviour of things.
Unfortunately, SPA and CSS frameworks tend to result in relatively complex solutions where traditionally separated concerns – HTML-structure, CSS-style, and JS-behaviour – are blended
together as a matter of course — Counter to the lessons learned by previous generations.
This blending of concerns can prevent entry level developers and valued specialists (Eg. visual design, accessibility, search engine optimization, and internationalization) from
making meaningful contributions to a project.
In addition to the increasing cost of the few developers somewhat capable of juggling
all of these concerns, it can also result in other real world business implications.
…
What is a front-end developer? Does anybody know, any more? And more-importantly, how did we get to the point where we’re actively encouraging young developers into habits like
writing (cough React cough) files containing a bloaty, icky mixture of content, HTML (markup), CSS (style), and Javascript (behaviour)? Yes, I get that the idea is that individual components should be packaged
together (if you’re thinking in a React-like worldview), but that alone doesn’t justify this kind of bullshit antipattern.
It seems like the Web used to have developers. Then it got complex so we started differentiating back-end from front-end developers and described those who, like me, spanned the divide,
as full-stack developers We gradually became a minority as more and more new developers, deprived of the opportunity to learn each new facet organically in this newly-complicated
landscape, but that’s fine. But then… we started treating the front-end as the only end, and introducing all kinds of problems as a result… and most people don’t seem to have
noticed, yet, exactly how much damage we’re doing to Web applications’ security, maintainability, future-proofibility, archivability, addressibility…
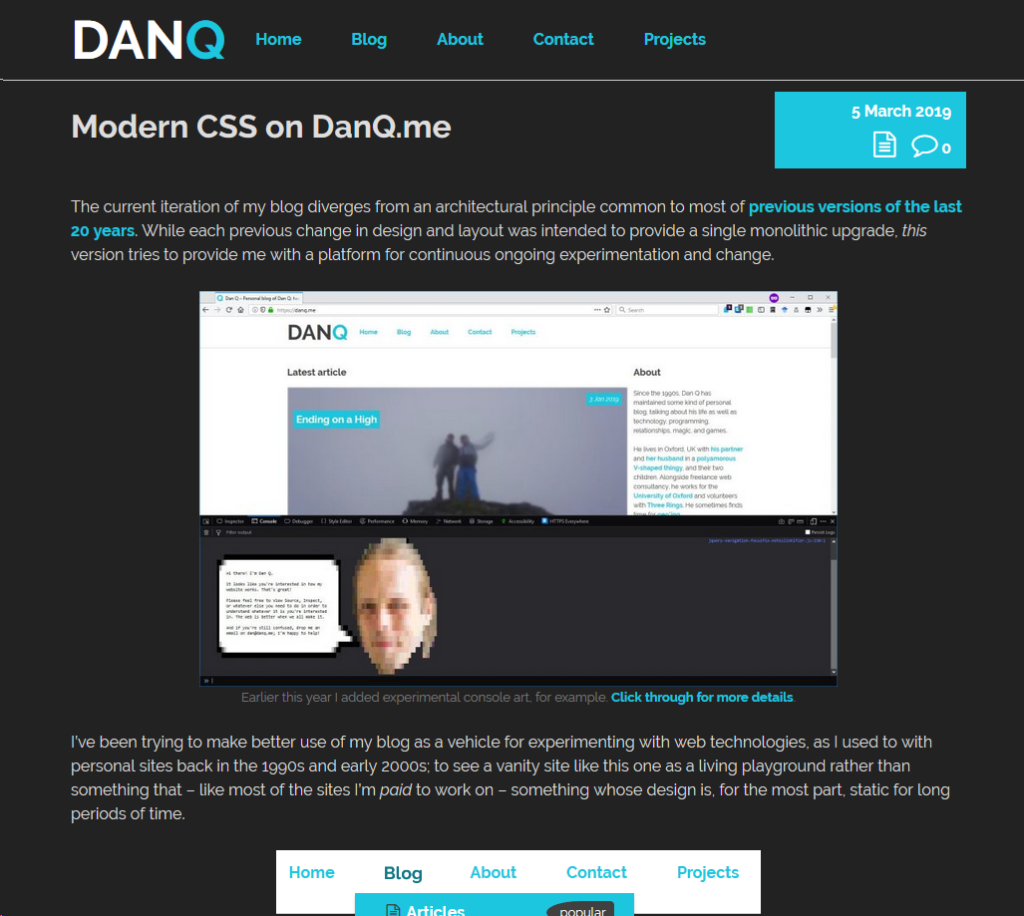
The current iteration of my blog diverges from an architectural principle common to most of previous versions of the last 20 years. While
each previous change in design and layout was intended to provide a single monolithic upgrade, this version tries to provide me with a platform for continuous ongoing
experimentation and change.
I’ve been trying to make better use of my blog as a vehicle for experimenting with web technologies, as I used to with personal sites back in the 1990s and early 2000s; to see a vanity
site like this one as a living playground rather than something that – like most of the sites I’m paid to work on – something whose design is, for the most part, static for
long periods of time.
The “popular” flag and associated background colour in the “Blog” top-level menu became permanent after a period of A/B testing. Thanks, unwitting testers!
I’m not entirely happy with the design of these boxes, but that’s a job for another day.
The grid of recent notes, shares, checkins and videos on my
homepage is powered by the display: grid; CSS directive. The number of columns varies by screen width from six
on the widest screens down to three or just one on increasingly small screens. Crucially, grid-auto-flow: dense; is used to ensure an even left-to-right filling of the
available space even if one of the “larger” blocks (with grid-column: span 2; grid-row: span 2;) is forced for space reasons to run onto the next line. This means that
content might occasionally be displayed in a different order from that in which it is written in the HTML (which is reverse
order of publication), but in exchange the items are flush with both sides.
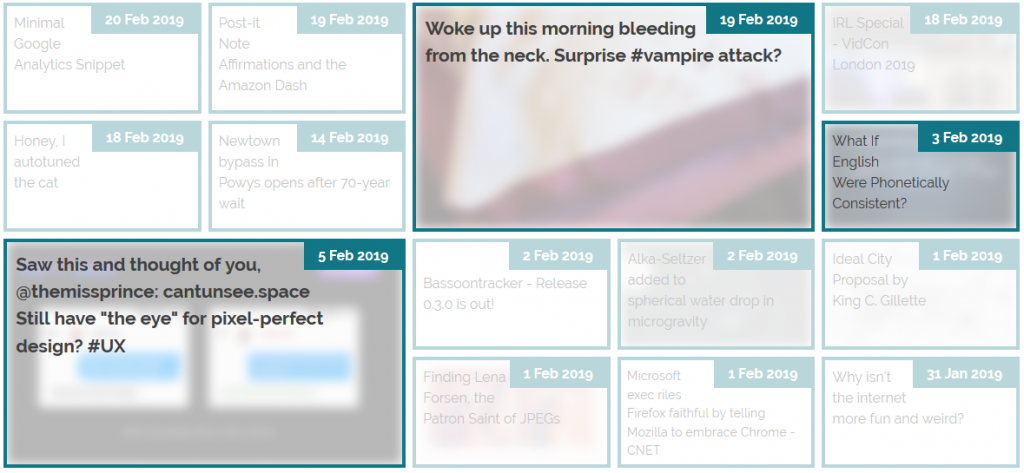
The large “5 Feb” item in this illustration should, reverse-chronologically, appear before the “3 Feb” item, but there isn’t room for it on the previous line. grid-auto-flow:
dense; means that the “3 Feb” item is allowed to bubble-up and fill the gap, appearing out-of-order but flush with the edge.
Not all web browsers support display: grid; and while that’s often only one of design and not of readability because these browsers will fall back to usually-very-safe
default display modes like block and inline, as appropriate, sometimes there are bigger problems. In Internet Explorer 11, for example, I found (with thanks to
@_ignatg) a problem with my directives specifying the size of these cells (which are actually <li> elements because, well,
semantics matter). Because it understood the directives that ought to impact the sizing of the list items but not
the one that redeclared its display type, IE made… a bit of a mess of things…
Thanks, Internet Explorer. That’s totally what I was looking for.
Do websites need to look the same in every browser? No. But the content should be readable
regardless, and here my CSS was rendering my content unreadable. Given that Internet Explorer users represent a little
under 0.1% of visitors to my site I don’t feel the need to hack it to have the same look-and-feel: I just need it to have the same content readability. CSS Feature Queries to the rescue!
CSS Feature Queries – the @supports selector – make it possible to apply parts of your stylesheet if and only if
the browser supports specific CSS features, for example grids. Better yet, using it in a positive manner (i.e. “apply these
rules only if the browser supports this feature”) is progressive enhancement, because browsers that don’t understand the @supports selector act in
the same way as those that understand it but don’t support the specified feature. Fencing off the relevant parts of my stylesheet in a @supports (display: grid) { ... }
block instructed IE to fall back to displaying that content as a boring old list: exactly what I needed.
It isn’t pretty, but it’s pretty usable!
Reduced-motion support
I like to put a few “fun” features into each design for my blog, and while it’s nowhere near as quirky as having my head play peek-a-boo when you
hover your cursor over it, the current header’s animations are in the same ballpark: hover over or click on some of the items in the header menu to see for yourself..
I’m most-pleased with the playful “bounce” of the letter Q when you hover over my name.
These kinds of animations are fun, but they can also be problematic. People with inner ear disorders (as well as people who’re just trying to maximise the battery life on their portable
devices!) might prefer not to see them, and web designers ought to respect that choice where possible. Luckily, there’s an emerging standard to acknowledge that: prefers-reduced-motion. Alongside its cousins inverted-colors, prefers-reduced-transparency, prefers-contrast and
prefers-color-scheme (see below for that last one!), these new CSS tools allow developers to optimise based on the accessibility
features activated by the user within their operating system.
In Windows you turn off animations while in MacOS you turn on not-having animations, but the principle’s the same.
If you’ve tweaked your accessibility settings to reduce the amount of animation your operating system shows you, this website will respect that choice as well by not animating the
contents of the title, menu, or the homepage “tiles” any more than is absolutely necessary… so long as you’re using a supported browser, which right now means Safari or Firefox (or the
“next” version of Chrome). Making the change itself is pretty simple: I just added a @media screen and (prefers-reduced-motion: reduce) { ... } block to disable or
otherwise cut-down on the relevant animations.
Dark-mode support
…
Similarly, operating systems are beginning to
support “dark mode”, designed for people trying to avoid eyestrain when using their computer at night. It’s possible for your browser to respect this and try to “fix” web pages for
you, of course, but it’s better still if the developer of those pages has anticipated your need and designed them to acknowledge your choice for you. It’s only supported in Firefox and
Safari so far and only on recent versions of Windows and MacOS, but it’s a start and a helpful touch for those nocturnal websurfers out there.
Come to the dark side, Luke. Or just get f.lux, I suppose.
It’s pretty simple to implement. In my case, I just stacked some overrides into a @media (prefers-color-scheme: dark) { ... } block, inverting the background and primary
foreground colours, softening the contrast, removing a few “bright” borders, and darkening rather than lightening background images used on homepage tiles. And again, it’s an example of
progressive enhancement: the (majority!) of users whose operating systems and/or browsers don’t yet support this feature won’t be impacted by its inclusion in my stylesheet, but those
who can make use of it can appreciate its benefits.
This isn’t the end of the story of CSS experimentation on my blog, but it’s a part of the it that I hope you’ve enjoyed.
One of the most common and effective ways to manage the caching of your assets is via the Cache-Control HTTP header. This header applies to
individual assets, meaning everything on our pages can have a very bespoke and granular cache policy. The amount of control we’re granted makes for very intricate and powerful caching
strategies.
A Cache-Control header might look something like this:
Cache-Control: public, max-age=31536000
Cache-Control is the header, and each of public and max-age=31536000 are directives. The Cache-Control header can accept one or more directives, and it is these
directives, what they really mean, and their optimum use-cases that I want to cover in this post.
…
A great reference for configuring your HTTP caching headers.
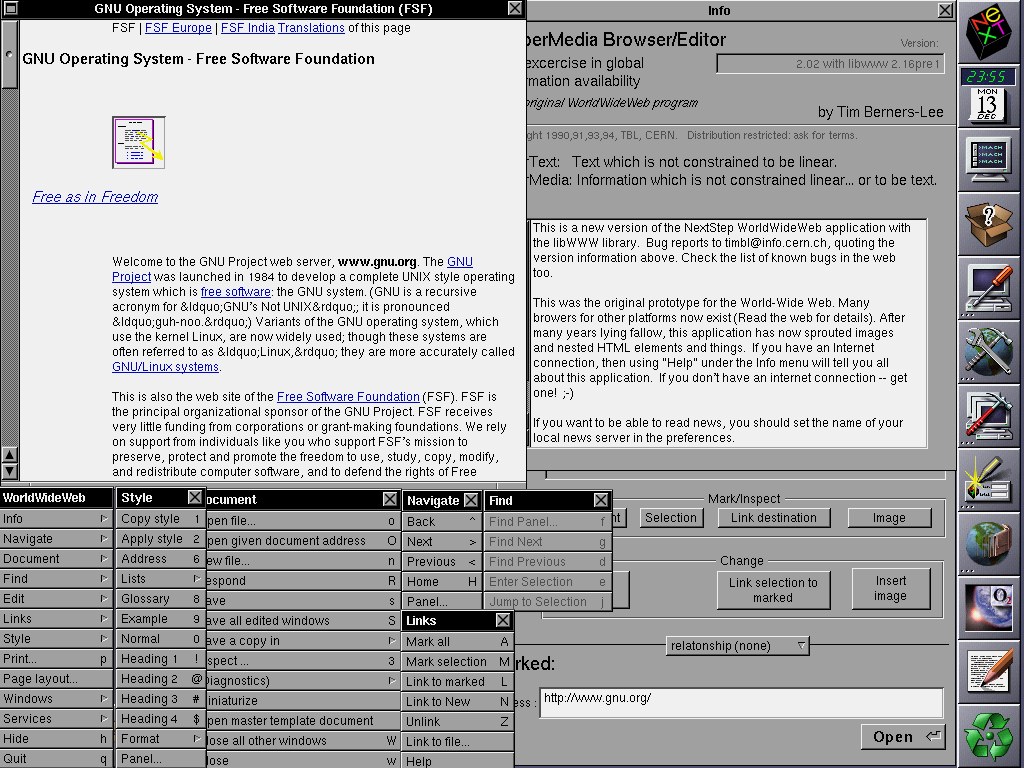
This month, a collection of some of my favourite geeks got invited to CERN in Geneva to
participate in a week-long hackathon with the aim of reimplementing WorldWideWeb –
the first web browser, circa 1990-1994 – as a web application. I’m super jealous, but I’m also really pleased with what they managed
to produce.
This represents a huge leap forward from their last similar project, which aimed to recreate the line mode browser: the first web browser that
didn’t require a NeXT computer to run it and so a leap forward in mainstream appeal. In some ways, you might expect
reimplementing WorldWideWeb to be easier, because its functionality is more-similar that of a modern browser, but there were doubtless some challenges too: this early browser predated the concept of the DOM and so there are distinct
processing differences that must be considered to get a truly authentic experience.
It’s just like any other hackathon, if you ignore the enormous particle collider underneath it.
Among their outputs, the team also produced a cool timeline of the Web, which – thanks to some careful authorship – is as legible in WorldWideWeb as it is in a modern browser (if, admittedly, a little less pretty).
When Sir Tim took this screenshot, he could never have predicted the way the Web would change, technically, over the next
25-30 years. But I’m almost more-interested in how it’s stayed the same.
In an age of increasing Single Page Applications and API-driven sites and “apps”, it’s nice to be reminded that if you develop right for the Web, your content will be visible
(sort-of; I’m aware that there are some liberties taken here in memory and processing limitations, protocols and negotiation) on machines 30 years old, and that gives me hope that
adherence to the same solid standards gives us a chance of writing pages today that look just as good in 30 years to come. Compare that to a proprietary technology like Flash whose heyday 15 years ago is overshadowed by its imminent death (not to
mention Java applets or ActiveX <shudders>), iOS apps which stopped working when the operating system went 64-bit, and websites which only work
in specific browsers (traditionally Internet Explorer, though as I’ve complained before we’re getting more and more Chrome-only sites).
The Web is a success story in open standards, natural and by-design progressive enhancement, and the future-proof archivability of human-readable code. Long live the Web.
The meteoric rise of front-end frameworks like React, Angular, Vue.js, Elm, etc. has made single-page applications ubiquitous on the web. For many developers, these have become part
of their ‘default’ toolset. When they start a new project, they grab the tools they know already: a REST API on the backend, and a React/Angular/Vue/Elm frontend.
Is there something wrong with these tools? Absolutely not. In fact, I love working with them. However, I would only choose this architecture when an actual requirement is pushing me
in that direction. If there are no specific reasons to build a single-page application, I will go with a traditional server-rendered architecture every day of the week. It is simpler
and allows you to move faster.
…
There’s been an increasing trend towards delivering web applications as SPAs backed by an API. I can see the attraction: disposing of the browser’s navigation cycle lets you develop that coveted “app-like” interaction experience,
pushing only data around lets you implement multiple clients backed by the same single middleware, and it results in a development workflow that fits tightly with many of the hippest
frameworks (go jamstack, backendless, Node-backed, or whatever). I love REST and all, but I feel that it works
best when it’s used to deliver multiformat results (whether by content negotiation or whatever): web pages for the humans, JSON or whatever for the computers.
For an increasing number of developers, SPAs are a golden hammer.
Let’s fix that.
In the days before the web was mainstream, it was a place of creation. First for education, then for every random idea that any creator had!
As the web transitioned from a network of educational institutions to the consumer force it is today, the early adopters were technologists… AKA geeks!
A hallmark of geek culture is fandom – a deep knowledge of whatever topic interests them. This could be about a book, TV show, movie or band. With this passion comes a desire to share
it with the world. Before the internet, there was no clear path. After the web started gaining traction, it was the biggest and easiest megaphone you could want.
It wasn’t always easy to be found, though. There was no search algorithm. Google was not ubiquitous with search. To be found, you needed to be listed on a site that aggregated other
sites about your topic.
…
There was always a certain joy to a well-kept webring, back in the day. I’d love to see a return to this kind of “Indieweb dream”, but I don’t think that just wishing for it nor even
telling people to go out and do it goes far enough, alone. Hopefully Bryan’s post will help nudge a few people in the right direction, though.
MySpace inspired a generation of teenagers to learn how to code. We have Dark Mode now, but where did all the glitter go?
During the internet of 2006, consumer products let anyone edit CSS. It was a beautiful mess. As the internet grew up, consumer products stopped trusting their users, and the internet
lost its soul.
…
I agree entirely with Jarred: in discouraging people from having their own web presences and in locking-down our shared social spaces online, we’re making the Web feel increasingly
flat, soulless, and – dare I say is – joyless. MDX seems really cool, but I’m not yet convinced that it alone solves the underlying problem of
content creators feeling that they should (or must) use dry, boring silos for the things they produce rather than their own space (in which they’d be able to express their personalities
and the personality of the things they were sharing). It may well lower the barrier to producing interactive personal sites a little (as well as having other applications, I’m sure!),
but we’re going to need more than that to drag people away from Facebook, Medium, Twitter and the like.
Even if you love Chrome, adore Gmail, and live in Google Docs or Analytics, no single company, let alone a user-tracking advertising giant, should control the internet.
…
Diversity is as good for the web as it is for society. And it starts with us.
Yet more fallout from the Microsoft announcement that Edge will switch to Chromium, which I discussed earlier. This one’s pretty inspirational, and gives a good reminder about what our responsibilities are to the Web, as its
developers.
If something I want to do with JavaScript can be done with CSS instead, use CSS.
CSS parses and renders faster.
For things like animations, it more easily hooks into the browser’s refresh rate cycle to provide silky smooth animations (this can be done in JS, too, but CSS just makes it so damn
easy).
And it fails gracefully.
A JavaScript error can bring all of the JS on a page to screeching halt. Mistype a CSS property or miss a semicolon? The browser just skips the property and moves on. Use an
unsupported feature? Same thing.
…
This exactly! If you want progressive enhancement (and you should), performance, and the cleanest separation of behaviour and presentation, the pages you deliver to your users
(regardless of what technology you use on your server) should consist of:
HTML, written in such a way that that they’re complete and comprehensible alone – from an information science perspective, your pages shouldn’t “need” any more than this (although
it’s okay if they’re pretty ugly without any more)
CSS, adding design, theme, look-and-feel to your web page
Javascript, using progressive enhancement to add functionality in-the-browser (e.g. validation on the client-side in addition to the server side validation, for speed and
ease of user experience) and, where absolutely necessary, to add functionality not possible any other way (e.g. if you’re looking to tap into the geolocation API, you’re going
to need Javascript… but it’s still desirable to provide as much of the experience as possible without)
Developers failing to follow this principle is making the Web more fragile and harder to archive. It’s not hard to do things “right”: we
just need to make sure that developers learn what “right” is and why it’s important.
Incidentally, I just some enhancements to the header of this site, including some CSS animations on the logo and menu (none of them necessary, but all useful) and some
Javascript to help ensure that users of touch-capable devices have an easier time. Note that neither Javascript nor CSS are required to use this site; they just add value… just
the way the Web ought to be (where possible).
Last week, I attended W3C TPAC as well as the CSS Working Group meeting there. Various changes were made to specifications, and discussions had which I feel are of interest to web
designers and developers. In this article, I’ll explain a little bit about what happens at TPAC, and show some examples and demos of the things we discussed at TPAC for CSS in
particular.
…
This article describes proposals for the future of CSS, some of which are really interesting. It includes mention of:
CSS scrollbars – defining the look and feel of scrollbars. If that sounds familiar, it’s because it’s not actually new: Internet Explorer 5.5 (and
contemporaneous version of Opera) supported a proprietary CSS extension that did the same thing back in 2000!
Aspect ratio units – this long-needed feature would make it possible to e.g. state that a box is square
(or 4:3, or whatever), which has huge value for CSS grid layouts: I’m excited by this one.
:where() – although I’ll be steering clear until they decide whether the related :matches() becomes :is(), I can see a million uses for this (and its widespread
existence would dramatically reduce the amount that I feel the need to use a preprocessor!).