The Puzzle
The other day I needed to solve a puzzle1. Here’s the essence of it: there was a grid of 16 words. They needed to be organised into four thematic “groups” of four words each; then each group needed to be sorted alphabetically.
Each item in each group had a two-character code associated with it: these were to be concatenated together into a string and added to a pastebin.com/... URL. The correct
four URLs would each contain a quarter of the answer to the puzzle.
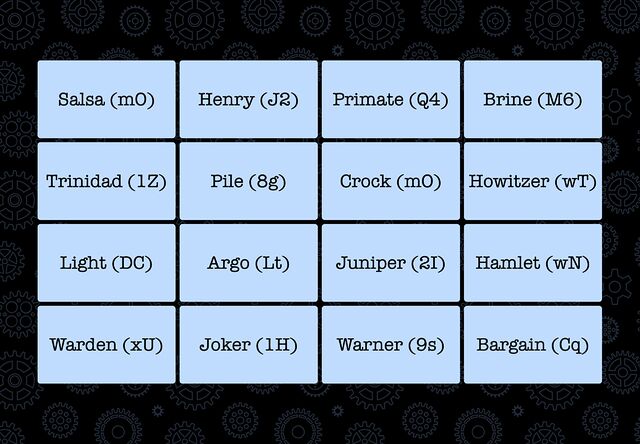
I’m sure I could have solved the puzzle. But I figured it’d be more satisfying to solve a different puzzle, with the same answer: how to write a program that finds the correct URLs for me.
Here’s what I came up with:
#!/usr/bin/env ruby require 'set' require 'net/http' require 'uri' FRAGMENTS = [ 'Salsa|mO', 'Henry|J2', 'Primate|Q4', 'Brine|M6', 'Trinidad|1Z', 'Pile|8g', 'Crock|mO', 'Howitzer|wT', 'Light|DC', 'Argo|Lt', 'Juniper|2I', 'Hamlet|wN', 'Warden|xU', 'Joker|1H', 'Warner|9s', 'Bargain|Cq', ] result = FRAGMENTS.permutation(4).to_a sorted_results = result.map { |combination| combination.sort }.uniq shortened_results = sorted_results.map { |combination| combination.map { |fragment| fragment.split('|').last } } urls = shortened_results.map { |combination| "https://pastebin.com/#{combination.join('')}" } START_AT = 0 urls[START_AT..].each_with_index do |url, idx| uri = URI(url) response = Net::HTTP.get_response(uri) print '.' if response.code != '404' puts "\nHIT at index #{idx + START_AT}: #{url}" end sleep(rand(0..3) * 0.1) end
Here’s how it works:
- It creates an array containing the 43,680 possible permutations of 4 from the 16 words.
- If sorts the permutations and removes duplicates, reducing the set to just 1,820.
- It removes the bit of each that isn’t the two digit code at the end and concatenates them into a URL.
- It tries each URL, with short random gaps between them, listing each one that isn’t a 404 “Not found” response.4
I kicked off the program and got on with some work. Meanwhile, in the background, it permuted the puzzle for me. Within a few minutes, I had four working pastebin URLs, which collectively gave me the geocache’s coordinates. Tada!
Was this cheating?
I still solved a puzzle. It probably took me, as a strong programmer, about as long as it would have taken me to solve the puzzle the conventional way were I a strong… “only connect”-er5. But I adapted the puzzle into a programming puzzle and solved it a completely different way, . Here’s the arguments, as I see them:
- Yes, this was cheating. This wasn’t the way the puzzle author intended it to be solved. Inelegantly brute-forcing a problem isn’t “solving” it, it’s sidestepping it. If everybody did this, there’d be no point in the author putting the time into the puzzle in the first place.
- No, this wasn’t cheating. This solution still required solving a puzzle, just a different one. A bad human player making a lucky guess would be fine. It’s a single-player game; play any way that satisfies you. Implementing software to assist is no worse than asking a friend for help, as others have done.
Click on a 😡 or a 🧠 to let me know whether you think I cheated or not, or drop me a comment if you’ve got a more-nuanced opinion.
Footnotes
1 Okay, okay, it was for a geocache.
2 Don’t try to solve this one; it’s randomly generated.
3 This version of the program is adapted to the fake gameboard I showed earlier. You won’t get any meaningful results by running this program in its current state. But you could quickly adapt it to a puzzle of this format, I suppose.
4 It occurred to me that it could have been more-efficient to eliminate from the list any possibilities that are ruled-out by any existing finds… but efficiency is a balancing act. For a program that you’ll only run once – and in the background, while you do other things, to boot – there’s a tipping point at which it’s better to just get it running than it is to improve its performance.
5 There’s a clear parallel here to the various ways in which I’ve solved jigsaw-puzzle-based geocaches, because I’m far more interested in (a) programming and (b) getting out into the world and finding geocaches in interesting places than I am in doing a virtual jigsaw puzzle!