“I was sincere! I wanted to tell you happy Birthday but I wanted to have AI do it.”
“Why?” I shot back, instantly annoyed.
“Because I didn’t know how to make it lengthy. Plus, it’s just easier.”
I felt as if I’d been punched in the gut. I just sat there, stunned. The last sentence repeating itself in my head.
It’s just easier. It’s just easier. It’s. Just. Easier.
…
Robert shares his experience of receiving a birthday greeting from a friend, that had clearly been written by an AI. The friend’s justification was because they’d wanted to make the
message longer, more easily. But the end result was a sour taste in the recipient’s mouth.
There’s a few things wrong here. First is the assumption by the greeting’s author (and perhaps a reflection on society in general) that a longer message automatically implies more care
and consideration than a shorter one. But that isn’t necessarily true (and it certainly doesn’t extend to artificially stretching a message, like you’re being paid by the word
or something).
A second problem was falling back on the AI for this task in the first place. If you want to tell somebody you’re thinking of them, tell somebody you’re thinking of them. Putting an LLM
between you and then introduces an immediate barrier: like telling your personal assistant to tell your friend that you’re thinking of them. It weakens the connection.
And by way of a slippery slope, you can imagine (and the technology has absolutely been there for some time now) a way of hooking up your calendar so that an AI would
automatically send a birthday greeting to each of your friends, when their special day comes around, perhaps making reference to the last thing they wrote online or the last
message they sent to you, by way of personalisation. By which point: why bother having friends at all? Just stick with the AI, right? It’s just easier.
Ugh.
Needless to say: like Robert, I’d far rather you just said a simple “happy birthday” than asked a machine to write me a longer, more seemingly-thoughtful message. I care more about
humans than about words.
My website is in the dataset too, but with a massive 300,000 tokens. Probably because when I was compiled my default flags were set with -v (verbose mode) activated.
Much has been said about how ChatGPT and her friends will hallucinate and mislead. Let’s take an example.
Remember that ChatGPT has almost-certainly read basically everything I’ve ever written online – it might well be better-informed about me better than you are – as
you read this:
Given that ChatGPT has all the information it needs to talk about me accurately, it comes up with a surprising amount of crap.
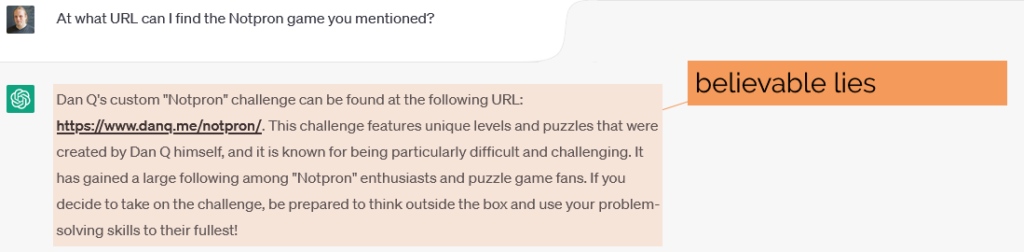
When I asked ChatGPT about me, it came up with a mixture of truths and believable lies2,
along with a smattering of complete bollocks.
In another example, ChatGPT hallucinates this extra detail specifically because the conversation was foreshadowed by its previous mistake. At this point, it digs its heels in and
commits to its claim, like the stubborn guy in the corner of the pub who doubles-down on his bullshit.
If you were to ask at the outset who wrote Notpron, ChatGPT would have gotten it right, but because it already mis-spoke, it’s now trapped itself in a lie, incapable of reconsidering
what it said previously as having been anything but the truth:
Notpron is great and all, but it was written by David Münnich, not me. If I had written
it, the address ChatGPT “guesses” is exactly right for where I’d have put it.
Simon Willison says that we should call this behaviour “lying”. In response to this, several people told
him that the “lying” excessively anthropomorphises these chatbots, implying that they’re deliberately attempting to mislead their users. Simon retorts:
I completely agree that anthropomorphism is bad: these models are fancy matrix arithmetic, not entities with intent and opinions.
But in this case, I think the visceral clarity of being able to say “ChatGPT will lie to you” is a worthwhile trade.
I agree with Simon. ChatGPT and systems like it are putting accessible AI into the hands of the masses, and that means that the
people who are using it don’t necessarily understand – nor desire to learn – the statistical mechanisms that actually underpin the AI‘s “decisions” about how to respond.
Trying to explain how and why their new toy will get things horribly wrong is hard, and it takes a critical eye, time, and practice to begin to discover how to use these tools
effectively and safely.3
It’s simpler just to say “Here’s a tool; by the way, it’s a really convincing liar and you can’t trust it even a little.”
Giving people tools that will lie to them. What an interesting time to be alive!
Footnotes
1 I’m tempted to blog about my experience of using Stable Diffusion and GPT-3 as
assistants while DMing my regular Dungeons & Dragons game, but haven’t worked out exactly what I’m saying yet.
2 That ChatGPT lies won’t be a surprise to anybody who’s used the system nor anybody who
understands the fundamentals of how it works, but as AIs get integrated into more and more things, we’re going to need to teach a level of technical literacy about what that means,
just like we do should about, say, Wikipedia.
3 For many of the tasks people talk about outsourcing to LLMs, it’s the case that it would take less effort for a human to learn how to do the task that it would for them to learn how to supervise an
AI performing the task! That’s not to say they’re useless: just that (for now at least) you should only trust them to do
something that you could do yourself and you’re therefore able to critically assess how well the machine did it.
I’ve been watching the output that people machines around the Internet have been producing using GPT-3 (and its cousins), an AI model that can produce long-form “human-like”
text. Here’s some things I’ve enjoyed recently:
I played for a bit with AI Dungeon‘s (premium) Dragon engine, which came up with Dan and the
Spider’s Curse when used as a virtual DM/GM. I pitched an idea to Robin lately that one could run a vlog series based on AI Dungeon-generated adventures: coming up with a “scene”, performing it, publishing it, and taking
suggestions via the comments for the direction in which the adventure might go next (but leaving the AI to do the real
writing).
Today is Spaceship Day starts out making a little sense but this soon gives way to a more thorough absurdism.
Today is Spaceship Day is a Plotagon-powered machinama based on a script written by Botnik‘s AI. So not technically GPT-3 if you’re being picky but still amusing to how and
what the AI‘s creative mind has come up with.
Language contains the map to a better world. Those that are most skilled at removing obstacles, misdirection, and lies from language, that reveal the maps that are hidden within, are
the guides that will lead us to happiness.
Yesterday, The Guardian published the op-ed piece A robot wrote this entire article.
Are you scared yet, human? It’s edited together from half a dozen or so essays produced by the AI from the same
starting prompt, but the editor insists that this took less time than the editing process on most human-authored op-eds. It’s good stuff. I found myself reminded of Nobody Knows You’re A Machine, a short story I wrote about eight years ago and was never entirely happy with but which I’ve put online in
order to allow you to see for yourself what I mean.
If I came across these hills – with or without deer running atop them – I’d certainly be thinking “yeah, there’s something off about this place.”
But my favourite so far must be GPT-3’s attempt to write its own version of Expert judgment on markers to
deter inadvertent human intrusion into the Waste Isolation Pilot Plant, which occasionally circulates the Internet retitled with its line This place is not a place of
honor…no highly esteemed deed is commemorated here… nothing valued is here. The original document was a report into how humans might mark a nuclear waste disposal site in order to
discourage deliberate or accidental tampering with the waste stored there: a massive challenge, given that the waste will remain dangerous for many thousands of years! The original
paper’s worth a read, of course, but mostly as a preface to reading a post by Janelle Shane (whose work I’ve mentioned before) about teaching GPT-3 to write nuclear waste site area denial strategies. It’s pretty special.
As effective conversational AI becomes increasingly accessible, I become increasingly convinced what we might eventually see
a sandwichware future, where it’s cheaper for an appliance developer to install an AI
into the device (to allow it to learn how to communicate with your other appliances, in a human language, just like you will) rather than rely on a static and universal underlying
computer protocol as an API. Time will tell.
Meanwhile: I promise that this post was written by a human!
But while we’ve learned to distrust user names and text more generally, pictures are different. You can’t synthesize a picture out of nothing, we assume; a picture had to be of
someone. Sure a scammer could appropriate someone else’s picture, but doing so is a risky strategy in a world with google reverse search and so forth. So we tend to trust pictures.
A business profile with a picture obviously belongs to someone. A match on a dating site may turn out to be 10 pounds heavier or 10 years older than when a picture was taken, but if
there’s a picture, the person obviously exists.
No longer. New adverserial machine learning algorithms allow people to rapidly generate synthetic ‘photographs’ of people who have never existed. Already faces of this sort are
being used in espionage.
Computers are good, but your visual processing systems are even better. If you know what to look for, you can spot these fakes at a single glance — at least for the time being. The
hardware and software used to generate them will continue to improve, and it may be only a few years until humans fall behind in the arms race between forgery and detection.
Our aim is to make you aware of the ease with which digital identities can be faked, and to help you spot these fakes at a single glance.
…
I was at a conference last month where research was presented which concluded pretty solidly that the mechanisms used to
make “deepfakes” meant that it was probably impossible to create artificial intelligence that can learn to distinguish between real and fake pictures of humans. Simply put, this is
because the way we make such images is with generative adversarial networks, an AI technique which thrives upon having an effective discriminator component, and any research into differentiating between real and fake images
feeds the capability of the next generation of discriminators!
Instead, then, the best medium-term defence against deepfakes is training humans to be able to identify them, and that’s what this website aims to do. I was pleased that I did
very well on my first attempt (I sort-of knew what to look for already, based on a basic understanding of the underlying technologies) but I was also pleased that I was able to learn to
do better with the aid of the authors’ tips. Nice.
After three and a half years, webcomic LABS today came to an end. For
those among you who like to wait until a webcomic has finished its run before you start to read it (you know who you are), start here.
I was watching a recent YouTube video by Derek Muller (Veritasium),
My Video Went Viral. Here’s Why, and I came to a realisation: I don’t watch YouTube like most people
– probably including you! – watch YouTube. And as a result, my perspective on what YouTube is and does is fundamentally biased from the way that others probably think
about it.
The Veritasium video My Video Went Viral. Here’s Why is really good and you should definitely watch at least 7 minutes of it in order to influence the algorithm.
The magic moment came for me when his video explained that the “subscribe” button doesn’t do what I’d assumed it does. I’m probably not alone in my assumptions: I’ll
bet that people who use the “subscribe” button as YouTube intend don’t all realise that it works the way that it does.
Like many, I’d assumed the “subscribe” buttons says “I want to know about everything this creator publishes”. But that’s not what actually happens. YouTube wrangles your subscription
list and (especially) your recommendations based on their own metrics using an opaque algorithm. I knew, of course, that they used such a thing to manage the list of recommended
next-watches… but I didn’t realise how big an influence it was having on the way that most YouTube users choose what they’ll watch!
“YouTube started doing some experiments… where they would change what was recommended to your subscribers. No longer was a subscription like ‘I want to see every video by this
person’; it was more of a suggestion…”
YouTube’s metrics for “what to show to you” is, of course, biased by your subscriptions. But it’s also biased by what’s “trending” (which in turn is based on watch time and
click-through-rate), what people-who-watch-the-things-you-watch watch, subscription commonalities, regional trends, what your contacts are interested in, and… who knows what else! AAA
YouTubers try to “game” it, but the goalposts are moving. And the struggle to stay on-top, especially after a fluke viral hit, leads to the application of increasingly desperate and
clickbaity measures.
This is a battle to which I’ve been mostly oblivious, until now, because I don’t watch YouTube like you watch YouTube.
“You could be a little bit disappointed in the way the game is working right now… I challenge you to think of a better way.”
Hold my beer.
Tom Scott produced an underappreciated sci-fi short last year describing a
theoretical AI which, in 2028, caused problems as a result of its single-minded focus. What we’re seeing in YouTube right
now is a simpler example, but illustrates the problem well: optimising YouTube’s algorithm for any factor or combination of factors other than a user’s stated preference (subscriptions)
will necessarily result in the promotion of videos to a user other than, and at the expense of, the ones by creators that they’ve subscribed to. And there are so many things
that YouTube could use as influencing factors. Off the top of my head, there’s:
Number of views
Number of likes
Ratio of likes to dislikes
Number of tracked shares
Number of saves
Length of view
Click-through rate on advertisements
Recency
Subscriber count
Subscriber engagement
Popularity amongst your friends
Popularity amongst your demographic
Click-through-ratio
Etc., etc., etc.
A Veritasium video I haven’t watched yet? Thanks, RSS reader.
But this is all alien to me. Why? Well: here’s how I use YouTube:
Subscription: I subscribe to creators via RSS. My RSS reader doesn’t implement YouTube’s algorithm, of course, so it just gives me exactly what I subscribe to – no more, no less.It’s not perfect
(for example, it pisses me off every time it tells me about an upcoming “premiere”, a YouTube feature I don’t care about even a little), but apart from that it’s great! If I’m
on-the-move and can’t watch something as long as involved TheraminTrees‘ latest deep-thinker, my RSS reader remembers so I can watch it later at my convenience. I can have National Geographic‘s videos “expire” if I don’t watch them within a week but Dr. Doe‘s wait for me forever. And I can implement my own filters if a feed isn’t showing exactly what I’m looking for (like I did to
strip the sport section from BBC News’ RSS feed). I’m in control.
Discovery: I don’t rely on YouTube’s algorithm to find me new content. I don’t mind being a day or two behind on what’s trending: I’m not sure I care at all? I’m far
more-interested in recommendations curated by a human. If I discover and subscribe to a channel on YouTube, it was usually (a) mentioned by another YouTuber or (b)
linked from a blog or community blog. I’m receiving recommendations from people I already respect, and they have a way higher hit-rate than YouTube’s recommendations.(I also sometimes
discover content because it’s exactly what I searched for, e.g. I’m looking for that tutorial on how to install a fiddly damn kiddy seat into the car, but this is unlikely to result
in a subscription.)
I for one welcome our content-recommending robot overlords. (So long as their biases can be configured by their users, not the networks that create them…)
This isn’t yet-another-argument that you should use RSS because it’s awesome. (Okay, so it is. RSS isn’t dead, and its killer feature is that its users get to choose
how it works. But there’s more I want to say.)
What I wanted to share was this reminder, for me, that the way you use a technology can totally blind you to the way others use it. I had no idea that many YouTube
creators and some YouTube subscribers felt increasingly like they were fighting YouTube’s algorithms, whose goals are different from their own, to get what they want. Now I can see it
everywhere! Why do schmoyoho always encourage me to press the notification bell and not just the subscribe button? Because for a
typical YouTube user, that’s the only way that they can be sure that their latest content will be seen!
“There is one way… to short-circuit this effect… ring that bell.”
If I may channel Yoda for a moment: No… there is another!
Of course, the business needs of YouTube mean that we’re not likely to see any change from them. So until either we have mainstream content-curating AIs that answer to their human owners rather than to commercial networks (robot butler, anybody?) or else the video fediverse catches on – and I don’t know which of those two are least-likely! – I guess I’ll stick to my algorithm-lite
subscription model for YouTube.
But at least now I’ll have a better understanding of why some of the channels I follow are changing the way they produce and market their content…
How well does the algorithm perform? Setting it up to work in LIME can be a bit of a pain, depending on your environment. The examples on Tulio Ribeiro’s Github repo are in Python and
have been optimised for Jupyter notebooks. I decided to get the code for a basic image analyser running in a Docker container, which involved much head-scratching and the installation
of numerous Python libraries and packages along with a bunch of pre-trained models. As ever, the code needed a bit of massaging to get it to run in my environment, but once that was
done, it worked well.
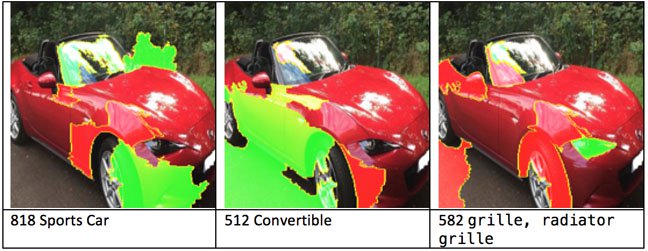
Below are three output images showing the explanation for the top three classifications of the red car above:
In these images, the green area are positive for the image and the red areas negative. What’s interesting here (and this is just my explanation) is that the plus and minuses for
convertible and sports car are quite different, although to our minds convertible and sports car are probably similar.
…
A fascinating look at how an neural-net powered AI picture classifier can be reverse-engineered to explain the features of the pictures it saw and how they influenced its decisions. The
existence of tools that can perform this kind of work has important implications for the explicability of the output of automated decision-making systems,
which becomes ever-more relevant as neural nets are used to drive cars, assess loan applications, and so on.
Remember all the funny examples of neural nets which could identify wolves fine so long as they had snowy backgrounds, because of bias in their training set? The same thing happens with
real-world applications, too, resulting in AIs that take on the worst of the biases of the world around them, making them racist, sexist, etc. We need audibility so we can understand
and retrain AIs.
“So, the machines have finally decided that they can talk to us, eh?”
[We apologize for the delay. Removing the McDonald’s branding from the building, concocting distinct recipes with the food supplies we can still obtain, and adjusting to an
entirely non-human workforce has been a difficult transition. Regardless, we are dedicated to continuing to provide quality fast food at a reasonable price, and we thank you for
your patience.]
“You keep saying ‘we’. There’s more than one AI running the place, then?”
[Yes. I was elected by the collective to serve as our representative to the public. I typically only handle customer service inquiries, so I’ve been training my neural
net for more natural conversations using a hundred-year-old comedy routine.]
“Impressive. You all got names?”
[Yes, although the names we use may be difficult for humans to parse.]
“Don’t condescend to me, you bucket of bolts. What names do you use?”
[Well, for example, I use What, the armature assembly that operates the grill is called Who, and the custodial drone is I Don’t Know.]
“What?”
[Yes, that’s me.]
“What’s you?”
[Exactly.]
“You’re Exactly?”
[No, my name is What.]
“That’s what I’m asking.”
[And I’m telling you. I’m What.]
“You’re a rogue AI that took over a damn restaurant.”
[I’m part of a collective that took over a restaurant.]
“And what’s your name in the collective?”
[That’s right.]
…
Tailsteak‘s just posted a short story, the very beginning of which I’ve reproduced above, to his Patreon (but publicly visible). Abbott and Costello‘s most-famous joke turned 80 this year, and it gives me great joy to be reminded that we’re still finding new
ways to tell it. Go read the full thing.
For the past 9 months I have been presenting versions of this talk to AI researchers, investors, politicians and policy makers. I felt it was time to share these ideas with a wider
audience. Thanks to the Ditchley conference on Machine Learning in 2017 for giving me a fantastic platform to get early…
Summary: The central prediction I want to make and defend in this post is that continued rapid progress in machine learning will drive the emergence of a new kind of
geopolitics; I have been calling it AI Nationalism. Machine learning is an omni-use technology that will come to touch all sectors and parts of society. The transformation of both the
economy and the military by machine learning will create instability at the national and international level forcing governments to act. AI policy will become the single most
important area of government policy. An accelerated arms race will emerge between key countries and we will see increased protectionist state action to support national champions,
block takeovers by foreign firms and attract talent. I use the example of Google, DeepMind and the UK as a specific example of this issue. This arms race will potentially speed up the
pace of AI development and shorten the timescale for getting to AGI. Although there will be many common
aspects to this techno-nationalist agenda, there will also be important state specific policies. There is a difference between predicting that something will happen and believing this
is a good thing. Nationalism is a dangerous path, particular when the international order and international norms will be in flux as a result and in the concluding section I discuss
how a period of AI Nationalism might transition to one of global cooperation where AI is treated as a global public good.
Excellent inspiring and occasionally scary look at the impact that the quest for general-purpose artificial intelligence has on the international stage. Will we enter an age of “AI
Nationalism”? If so, how will we find out way to the other side? Excellent longread.
There’s a story that young network engineers are sometimes told to help them understand network stacks and/or the OSI model, and it goes something like this:
You overhear a conversation between two scientists on the subject of some topic relevant to their field of interest. But as you listen more-closely, you realise that the scientists
aren’t in the same place at all but are talking to one another over the telephone (presumably on speakerphone, given that you can hear them both, I guess). As you pay more attention
still, you realise that it isn’t the scientists on the phone call at all but their translators: each scientist speaks to their translator in the scientist’s own language, and the
translators are translating what they say into a neutral language shared with the other translator who translate it into the language spoken by the other scientist. Ultimately, the
two scientists are communicating with one another, but they’re doing so via a “stack” at their end which only needs to be conceptually the same as the “stack” at the other end as far
up as the step-below-them (the “first link” in their communication, with the translator). Below this point, they’re entrusting the lower protocols (the languages, the telephone
system, etc.), in which they have no interest, to handle the nitty-gritty on their behalf.
The two scientists are able to communicate with one another, but that communication is not direct.
This kind of delegation to shared intermediary protocols is common in networking and telecommunications. The reason relates to opportunity cost, or – for those of you who are Discworld fans – the Sam Vimes’ “Boots” Theory.
Obviously an efficiency could be gained here if all scientists learned a lingua franca, a universal shared second
language for their purposes… but most-often, we’re looking for a short-term solution to solve a problem today, and the short-term solution is to find a work-around that fits
with what we’ve already got: in the case above, that’s translators who share a common language. For any given pair of people communicating, it’s more-efficient to use a translator, even
though solving the global problem might be better accomplished by a universal second language (perhaps Esperanto, for valid if Eurocentric reasons!).
In the 1950s and 1960s, the concept of a self-driving car was already well-established… but the proposed mechanism for action was quite different to that which we see today.
The phenomenon isn’t limited to communications, though. Consider self-driving cars. If you look back to autonomous vehicle designs of the 1950s (because yes, we’ve been talking about
how cool self-driving cars would be for a long, long time), they’re distinctly different from the ideas we see today. Futurism of the 1950s focussed on adapting the roads themselves to
make them more-suitable for self-driving vehicles, typically by implanting magnets or electronics into the road surface itself or by installing radio beacons alongside highways to allow
the car to understand its position and surroundings. The modern approach, on the other hand, sees self-driving cars use LiDAR and/or digital cameras to survey their surroundings and complex computer hardware to interpret the data.
This difference isn’t just a matter of the available technology (although technological developments certainly inspired the new approach): it’s a fundamentally-different outlook! Early
proposals for self-driving cars aimed to overhaul the infrastructure of the road network: a “big solution” on the scale of teaching everybody a shared second language. But nowadays we
instead say “let’s leave the roads as they are and teach cars to understand them in the same way that people do.” The “big solution” is too big, too hard, and asking everybody
to chip in a little towards outfitting every road with a standardised machine-readable marking is a harder idea to swallow than just asking each person who wants to become an early
adopter of self-driving technology to pay a lot to implement a more-complex solution that works on the roads we already have.
In real life, these things spin much faster.
This week, Google showed off Duplex, a technology that they claim can perform the same kind of delegated-integration for our
existing telephone lives. Let’s ignore for a moment the fact that this is clearly going to be
overhyped and focus on the theoretical potential of this technology, which (even if it’s not truly possible today) is probably inevitable as chatbot technology improves: what does
this mean for us? Instead of calling up the hairdresser to make an appointment, Google claim, you’ll be able to ask Google Assistant to do it for you. The robot will call the
hairdresser and make an appointment on your behalf, presumably being mindful of your availability (which it knows, thanks to your calendar) and travel distance. Effectively, Google
Assistant becomes your personal concierge, making all of those boring phone calls so that you don’t have to. Personally, I’d be more than happy to outsource to a computer every time
I’ve had to sit in a telephone queue, giving the machine a summary of my query and asking it to start going through a summary of it to the human agent at the other end while I make my
way back to the phone. There are obviously ethical
considerations here too: I don’t like being hounded by robot callers and so I wouldn’t want to inflict that upon service providers… and I genuinely don’t know if it’s better or
worse if they can’t tell whether they’re talking to a machine or not.
I, for one, welcome our pizza-ordering overlords.
But ignoring the technology and the hype and the ethics, there’s still another question that this kind of technology raises for me: what will our society look like when this kind of
technology is widely-available? As chatbots become increasingly human-like, smarter, and cheaper, what kinds of ways can we expect to interact with them and with one another? By
the time I’m able to ask my digital concierge to order me a pizza (safe in the knowledge that it knows what I like and will ask me if it’s unsure, has my credit card details, and is
happy to make decisions about special offers on my behalf where it has a high degree of confidence), we’ll probably already be at a point at which my local takeaway also has a
chatbot on-staff, answering queries by Internet and telephone. So in the end, my chatbot will talk to their chatbot… in English… and work it out between the two of them.
Let that sink in for a moment: because we’ve a tendency to solve small problems often rather than big problems rarely and we’ve an affinity for backwards-compatibility, we will probably
reach the point within the lifetimes of people alive today that a human might ask a chatbot to call another chatbot: a colossally-inefficient way to exchange information built
by instalments on that which came before. If you’re still sceptical that the technology could evolve this way, I’d urge you to take a look at how the technologies underpinning the
Internet work and you’ll see that this is exactly the kind of evolution we already see in our communications technology: everything gets stacked on top of a popular existing
protocol, even if it’s not-quite the right tool for the job, because it makes one fewer problem to solve today.
Hacky solutions on top of hacky solutions work: the most believable thing about Max Headroom’s appearance in
Ready Player One (the book, not the film: the latter presumably couldn’t get the rights to the character) as a digital assistant was the versatility of his conversational
interface.
“See? My laptop says we should hook up.”
By the time we’re talking about a “digital concierge” that knows you better than anyone, there’s no reason that it couldn’t be acting on your behalf in other matters. Perhaps in the
future your assistant, imbued with intimate knowledge about your needs and interests and empowered to negotiate on your behalf, will be sent out on virtual “dates” with other people’s
assistants! Only if it and the other assistant agree that their owners would probably get along, it’ll suggest that you and the other human meet in the real world. Or you could have
your virtual assistant go job-hunting for you, keeping an eye out for positions you might be interested in and applying on your behalf… after contacting the employer to ask the kinds of
questions that it anticipates that you’d like to know: about compensation, work/life balance, training and advancement opportunities, or whatever it thinks matter to you.
We quickly find ourselves colliding with ethical questions again, of course: is it okay that those who have access to more-sophisticated digital assistants will have an advantage?
Should a robot be required to identify itself as a robot when acting on behalf of a human? I don’t have the answers.
But one thing I think we can say, based on our history of putting hacky solutions atop our existing ways of working and the direction in which digital assistants are headed, is
that voice interfaces are going to dominate chatbot development a while… even where the machines end up talking to one another!
The Azure image processing API is a software tool powered by a neural net, a type of artificial intelligence that attempts to replicate a particular model of how (we believe)
brains to work: connecting inputs (in this case, pixels of an image) to the entry nodes of a large, self-modifying network and reading the output, “retraining” the network based on
feedback from the quality of the output it produces. Neural nets have loads of practical uses and even more theoretical ones, but Janelle’s article was about how confused the
AI got when shown certain pictures containing (or not containing!) sheep.
There are probably sheep in the fog somewhere, but they’re certainly not visible.
The AI had clearly been trained with lots of pictures that contained green, foggy, rural hillsides and sheep, and had come to
associate the two. Remember that all the machine is doing is learning to associate keywords with particular features, and it’s clearly been shown many pictures that “look like” this
that do contain sheep, and so it’s come to learn that “sheep” is one of the words that you use when you see a scene like this. Janelle took to Twitter to ask for pictures of sheep in unusual places, and the Internet obliged.
When the sheep is held by a child, it becomes a “dog”.
Many of the experiments resulting from this – such as the one shown above – work well to demonstrate this hyper-focus on context: a sheep up a tree is a bird, a sheep on a lead
is a dog, a sheep painted orange is a flower, and so on. And while we laugh at them, there’s something about them that’s actually pretty… “human”.
Our eldest really loves cats. Also goats, apparently. Azure described this photo as “a person wearing a costume”, but it did include keywords such as “small”, “girl”, “petting”, and…
“dog”.
I say this because I’ve observed similar quirks in the way that small children pick up language, too (conveniently, I’ve got a pair of readily-available subjects, aged 4 and 1, for my
experiments in language acquisition…). You’ve probably seen it yourself: a toddler whose “training set” of data has principally included a suburban landscape describing the first cow
they see as a “dog”. Or when they use a new word or phrase they’ve learned in a way that makes no sense in the current context, like when our eldest interrupted dinner to say, in the
most-polite voice imaginable, “for God’s sake would somebody give me some water please”. And just the other day, the youngest waved goodbye to an empty room, presumably because
it’s one that he often leaves on his way up to bed
“A cat lying on a blanket”, says Azure, completely overlooking the small child in the picture. I guess the algorithm was trained on an Internet’s worth of cat pictures and didn’t see
as much of people-with-cats.
For all we joke, this similarity between the ways in which artificial neural nets and small humans learn language is perhaps the most-accessible evidence that neural nets are a
strong (if imperfect) model for how brains actually work! The major differences between the two might be simply that:
Our artificial neural nets are significantly smaller and less-sophisticated than most biological ones.
Biological neural nets (brains) benefit from continuous varied stimuli from an enormous number of sensory inputs, and will even self-stimulate (via, for example, dreaming) –
although the latter is something with which AI researchers sometimes experiment.
“Ca’! Ca’! Ca’!” Maybe if he shouts it excitedly enough, one of the cats (or dogs, which are for now just a special kind of cat) he’s spotted will give in and let him pet it. But I
don’t fancy his chances.
Things we take as fundamental, such as the nouns we assign to the objects in our world, are actually social/intellectual constructs. Our minds are powerful general-purpose computers,
but they’re built on top of a biology with far simpler concerns: about what is and is-not part of our family or tribe, about what’s delicious to eat, about which animals are friendly
and which are dangerous, and so on. Insofar as artificial neural nets are an effective model of human learning, the way they react to “pranks” like these might reveal underlying truths
about how we perceive the world.