It remains a huge pleasure to receive a postcard from an Internet stranger (or even somebody I already know). It’s so much more tactile, and
thoughtful, and human, and real than most of the other feedback I get.3
I guess there’s sort-of a scale of effort that it takes to react to content online. At the lowest end of the scale, barely above “doing nothing”, is “clicking a reaction
button” (hey, did you see that you can click one below this?). It takes more effort to fill in a contact form. More still to send an
individual email or ping me on Mastodon. But yet more still to write a postcard, find a stamp, go to the postbox… And I really appreciate it when somebody
makes the effort.
Footnotes
1 The surprise is dampened only slightly by the fact that my PO Box provider emails me in
advance to tell me I’ve received something.
2 Remember Web forums? They’re still very much around, and there are some cool communities
if you can find the right one for you.
Late to the party,1 I finally got around to experimentally moving a GitHub Pages-hosted static site to Codeberg. I wanted a low-risk site to try first, so I moved Beige Buttons, the site hosting my “90s PC turbo
button simulator” web component.
Ê
Mostly for my own benefit later, here’s the steps I took and the things I learned along the way:
Codeberg Pages is deployed from the pages branch. If there’s no build step to the static site, all you need to do is rename the
main branch to pages (and probably make it the default branch).2
The default URL is https://username.codeberg.page/repository.
You can use a custom domain by adding a .domains file that lists domains; if migrating from GitHub Pages you can just rename your CNAME file to
.domains.
You’ll need to tweak your DNSCNAME, ALIAS (or,
worst-case, A/AAAA) record to point at Codeberg Pages.3
Change propogation feels slightly slower than GitHub, but perfectly tolerable.
The one thing that’s causing me trouble is that Codeberg Pages’ CORS headers prevent people from hotlinking the Beige Buttons JS, so there are some projects for which this
wouldn’t be a suitable migration (issuesareraised). But for most static sites, it’d probably Just Work and seems to be a great alternative.
The Chicory House’s water meter, found in a cupboard, is so much easier to read than the one at our regular house, which is found down a frequently-flooded manhole on
the busy road outside.
Unfortunately, Thames Water had fucked-up1
and created an account for us already with the wrong information2,
so by the time I’d reached out to them they were already getting themselves into a pickle.
It turns out that, presumably because of some shortsightedness on the part of their software engineers, their computer systems wouldn’t let them change the information to
correct the problem. Nor could they simply delete the account and create a new one3.
Instead, the had to close the account they’d erroneously set up such that the start and end date of the contract was our moving-in date… and then set up
a new account starting from the day after.
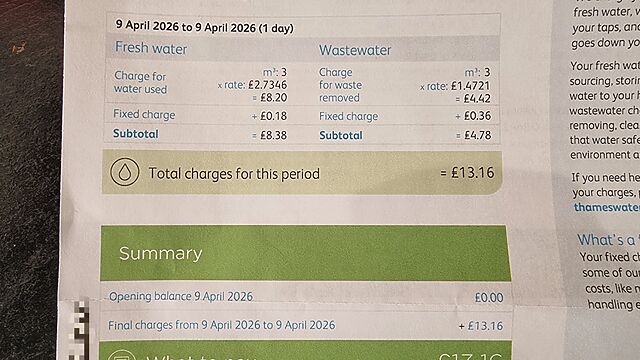
Sigh. Fine! So long as it’s sorted, I didn’t even care. Until, that is, the bill arrived for the one day of the first (incorrectly-created) contract:
This looks pretty low for a metered water bill, until you realise that it covers a period of literally only eleven hours from us moving in (and taking a meter reading) until
the end of that day. And that during most of that time the water was switched-off because a pair of plumbers were installing a new bathroom!
That bill:
is for £13.16.
covers “9 April 2026 through 9 April 2026”, i.e. one day.
(which means that our estimated annual bill would be £4,803.40 (£13.16 × 365) – about eight times
the national average)
states that our account closure was/will be “04/09/2026” – the only date on the letter that’s in “short” date format and which would appear to be 4 September (in UK date format)
even though 9 April would make more sense (but would require interpreting it in US date format, which would make no sense).
Let’s see how that breaks down:
The rates are standard, albeit a little on the high end: Thames Water need to raise funds right now to fix all of the leaks in their pipes, apparently. What’s odd is the volume of
water they claim has been used.
According to this bill, we used three cubic metres of water between collecting the keys (at around 1pm), moving in, and taking a meter reading… and the end of the
day. That’s three thousand litres of water.
Is it possible to achieve that level of water usage in the nine hours of billable time that this bill covers? I guess, if you really tried, you could:
completely fill and then drain our 100-litre bathtub, three times an hour, taking a five-and-a-half minute bath in each before draining it again, for the rest of
the day4;
or
run the kitchen tap – the highest-pressure tap in the house – continuously for six hours and forty minutes; or
repeatedly flush all three toilets, on “full-flush” mode, once every 79 seconds until midnight5, for example.
Some science was involved in the writing of this blog post.
Obviously this is all ridiculous. I’m being ridiculous.
But then again, so is this bill, which claims that three adults spent 11 hours in a house and somehow used the amount of water that’s the recommended amount to drink in a day… by 1,500
adults. Despite the water being shut-off to install a shower and toilet for some of that time.
But then again, so is Thames Water’s computer system, which disallows the correction of mistakes even by their own staff and instead requires the creation of one-day contracts.
And also can’t decide which country’s date format to use. And, possibly, doesn’t allow them to obey data protection laws.
The whole thing’s ridiculous. Which I’ll be letting Thames Water know. Let’s see if they agree.
Footnotes
1 This may be no surprise to anybody who’s ever dealt with Thames Water before, or who
follows the news about their seemingly endless inability to keep clean water in its pipes and raw sewage out of our rivers, for example, while taking out loans in order to pay bonuses
to their self-back-patting executives.
2 They used information provided to them by the estate agent and failed to connect it to
the information they already had for us… which thanks to quirks of their information systems resulted in bigger problems down the line. Amusingly – and for a change! – none
of the problems were related to my unusual name, this time around.
3 Curiously, these initial mistakes on the part of Thames Water left them processing
personal information about me – an email address – that I’d never given to them, and allegedly unable to delete or correct it for six months after being asked to. This is the kind of
thing that normally gives me an excuse for a field day of DPA2018-related letter writing, but this time around I’ve been too busy dealing with the bigger problems they’ve
created to have a chance to stop and think about that: that’s how much of a mess they’ve made.
4 It’s only barely possible to repeatedly fill the bath this quickly, you need to use both
hot and cold water: the cold inlet alone doesn’t have the pressure to fill it fast enough, but the hot water tank has its own separate inlet which makes all the difference.
Also, a cold bath would suck, even if you’re only allowed five minutes in it before it’s time to drain the tub and start filling it again.
5 I once had a really rough night after a particularly dodgy curry, but I’ve never needed
to be flushing a toilet twice a minute for eleven hours.
Folks at work have been encouraging to make more use of generative AI in my workflow1;
going beyond my current “fancy autocomplete” use and giving my agents more autonomy. My experience of such “vibe coding” so far has been… mixed2,
but I promised I’d revisit it.
One thing that these models are usually effective at is summarisation3. This is valuable if you’re faced with a large and unfamiliar
codebase and you’re looking to trace a particular thing but you’re not certain where it is or what it’ll be called. While they’re not always fast, these tools can
at least work in the background, which allows the developer to get on with something else while the agent trawls logs, code, and configuration to find and explain a
fuzzily-defined thing.
Recently, I had a moment which I thought might be such an instance… but it didn’t turn out quite the way I expected. Here’s the story4:
The broken dev env
I’d been drafted into an established and ongoing project to provide more hands, following a coworker’s departure last week. This project touches parts of our (sprawling,
microsevices-based) infrastructure that I hadn’t looked at before, so there was a lot I didn’t yet know.
I picked an issue that had belonged to my former colleague that QA had rejected and set out to retrace their steps: to replicate the problem that the QA engineers had identified and in
doing so learn more about the underlying process. I spun up my development environment and tried to follow the steps.
The process failed… but much earlier than QA had said it would. Clearly my development environment was at fault, or at least not representative of their setup.
But I couldn’t even get as far as their problem before my frontend barfed out an error message. Sigh! Probably there’s some configuration I’ve missed somewhere in the myriad
microservices, or else the data I’m testing with isn’t a fair reflection on what they’re doing as-standard.
Following some staff changes, I have no teammates on this side of the Atlantic who could help me decipher this: a “quick question on Slack” wouldn’t solve this one until hours
from now. It was time to start debugging!
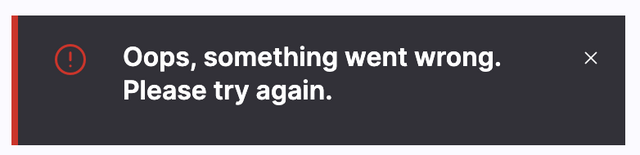
But… maybe Claude could help? It’s got access to almost all the same code, logs, tools and browser windows I do. I started typing:
✨ What’s up next, Dan?
In my development environment for https://service.dev/asset/new, when I click “Save”, I see the error “Oops, something went wrong.”
Why?
Context is key
It’s quite possible that Claude would have gone away, had a “think”, done some tests, and then come back to me with a believable answer. It might even have been correct, and I’d have
been able to short-cut my way back to productivity (and I’d have time to make a mug of coffee and finish reading my emails while it did so). Then, I’d just have to check that it was
right, make the change, and get on with things.
But I realised that it’d probably work faster (and cheaper, and using less energy) if it had slightly more context from the get-go, so I elaborated. The first thing I’d
want to know if I were debugging this is what was actually happening behind the scenes. I dipped into my browser’s Network debugger and extracted the relevant output, adding it to my
prompt:
✨ What’s up next, Dan?
In my development environment for https://service.dev/asset/new, when I click “Save”, I see
the error “Oops, something went wrong.” Why?The payload POSTed to the server is { content: 'test1', audience: [ 'one' ], status: 'draft' } and
the response is a HTTP 500 with the following stack trace: pasted 94 lines
That’s more like it, now I could let it get on with its work. But wait…
Rubberducking
There’s a concept in computer programming called “rubberducking”. The name comes from an anecdote in The Pragmatic Programmer about a developer who, when stuck on a problem, would
explain the code line-by-line to a rubber duck. The thinking is that talking-through a problem, even to someone (or something) who doesn’t understand it, can lead the speaker to
insights they were otherwise missing.
I’ve done it myself many, many times: recruiting a convenient colleague or friend and talking them through the technical problem I was faced with, and inviting them to ask me to go
into greater detail if I seemed to be skimming over anything, and I can promise that it can work.
The panel above is part of a series in which a sorceress called Cepper who’s
coerced by her university into using Avian Intelligence (“AI”) – a robotic parrot5 that her headmaster insists is the future of magic. She experiments with it, finds it
occasionally useful but more-often frustrating, attempts to implement her own local version but find that troublesome in different ways, and eventually settles on using
an inanimate rubber duck instead. I get it, Cepper!
Let’s put that distraction aside for a moment and get back to the story of my broken development environment.
Clues in the stack trace
The top entry in the stack trace was an unsuccessful call to a different microservice, so I figured I’d pull its logs too, in order to further help direct
the AI in the right direction6:
✨ What’s up next, Dan?
In my development environment for https://service.dev/asset/new, when I click “Save”, I see
the error “Oops, something went wrong.” Why?The payload POSTed to the server is { content: 'test1',
audience: [ 'one' ], status: 'draft' } and the response is a HTTP 500 with the following stack trace: pasted 94 linesThe stack
trace suggests that a call is being made to the dojo backend service, where the following error log looks relevant: pasted 9
lines
I haven’t tried it, but I’m pretty confident that the LLM, after much number-crunching and a little warming-up of some datacentre somewhere, would get to the answer. But again, I found
something niggling inside me: the second-from top line in the dojo logs suggested that a connection was being made to a further, deeper microservice.
I should pull its logs too, I figured.
The final puzzle piece
As an aide mémoire – in a way I’ve taken to doing when taking notes or when talking to AI – I first typed what I was going to provide. This is
useful if, for example, somebody distracts me at a key moment: it means you’ve got a jumping-off point predefined by my past self:
✨ What’s up next, Dan?
In my development environment for https://service.dev/asset/new, when I click “Save”, I see
the error “Oops, something went wrong.” Why?The payload POSTed to the server is { content: 'test1',
audience: [ 'one' ], status: 'draft' } and the response is a HTTP 500 with the following stack trace: pasted 94 linesThe stack
trace suggests that a call is being made to the dojo backend service, where the following error log looks relevant: pasted 9
lines. It’s calling osiris, which says:
I dipped into the directory for
osiris, and before I even got to the logs I spotted a problem: that microservice was on an old feature branch. How odd! I switched to the main branch and… everything
started working.
The entire event took only a few minutes. I’d find some information, type it into Claude’s input field, realise that more information could be valuable, and repeat.
By the time I’d finished describing the problem, I’d discovered the solution. That’s the essence of successful rubberducking. I didn’t need the AI at all.
All I needed was the illusion of something that might be able to help if I just talked through what I was thinking.
I don’t know what the moral is, here.
I wonder if I’d have been as effective had I just typed into my text editor. I suppose I would have, but I wonder if I’d have been motivated to do so in the first place? I’ve tried
rubberducking before by talking to an imaginary person, but I’ve never tried typing to one7; maybe I should start?
Footnotes
1 I’m pretty sure every engineering department nowadays has it’s rabid fanboys, but I’m
pleased that for the most part my colleagues take a more-pragmatic and realistic outlook: balancing the potential benefits of LLM-assisted coding with its many shortfalls,
downsides, and risks.
3 So long as what you’ve got them summarising is something you can later verify!
4 I’ve taken huge liberties with the strict factual accuracy to make this more-readable as
well as to to not-expose things I probably oughtn’t. So before you swoop in to criticise my prompt-fu (not that I asked you, but I know there’s somebody out there who’s thinking about
doing this right now), please note that none of the text in this page are what I actually wrote to the AI; it’s a figurative example.
6 I’d had an experience just the previous week in which it’d gone off on completely the
wrong track, attempting to change code in order to “fix” what was ultimately a configuration or data problem, and so I thought it might be useful to give it some rails to follow, to
start with.
7 Except insofar as this AI agent is an “imaginary person”, which it possibly already a
step-too-far in implying personhood for my liking!
For instance, at the start of the weekend I received an email from somebody called Phil, who asked:
Could you possibly have an alternative ‘HQ’ version of your feeds which replaces standard/240 with standard/1200 in the URL for each article in the XML?
I am obviously pretty desperate for this feature, hence me reaching out.
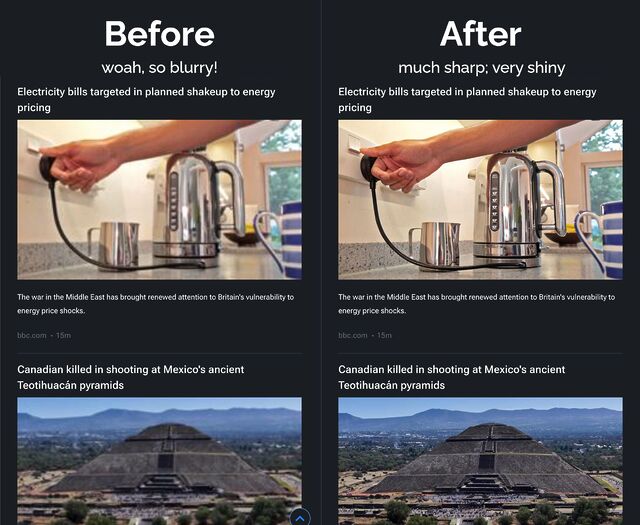
Phil’s right. The BBC News RSS feeds contain thumbnail images that look like this:
You see the /240/ in that URL? If you change it to /1200/ then, as Phil observes, you get a much-higher resolution thumbnail. Naturally you ought
to correct the width and height attributes accordingly, too.
The difference is pretty significant. See:
You’d be forgiven for thinking the left-hand-side of this image was the Lego model of this car.
So I raised Phil’s request as a GitHub issue, like a good maintainer, before realising that – hang on – this would be
a really easy improvement and I should just… do it.
My BBC feeds “improver” leverages one of my very favourite RubyGems, Nokogiri, to perform XML parsing and modification. The code you need to tweak
these URLs is super simple:
# Iterate through each <media:thumbnail> element in the RSS feed:
rss.xpath('//media:thumbnail').eachdo|thumb|# Skip any that don't start the way we expect:nextunlessthumb['url']=~/^https:\/\/ichef.bbci.co.uk\/ace\/(standard|ws)\/240\//# Swap the 240 for 1200 in the url="..." attribute:thumb['url']=thumb['url'].gsub(/\/ace\/(standard|ws)\/240\//,"/ace/\\1/1200/")
# Set width="1200":thumb['width']="1200"# Set the height="..." proportionally (they're not always the same!):thumb['height']=(thumb['height'].to_f/240*1200).round.to_s
end
That really is all there is to it, but look at what a difference it makes in an RSS reader:
I got that merged and the GitHub action that makes the magic happen got started on its usual 20-minute schedule soon afterwards. I didn’t even have to finish waiting for my lunchtime
ramen to cool down before the change was out there and, hopefully, helping people. Phil emailed me again soon afterwards:
You managed to fix something in your lunch break that has been bugging me for well over a decade. The difference in quality is night and day.
Anyway: it pleased me to discover that my software is out there, helping people.
As with most of my open source work, I put little to no effort into tracking any kind of metrics of usage, which means I only get to find out if I’ve done good in the world when people
reach out and tell me. So I was delighted to hear from Phil (as well as to take his suggestion and improve the tool for everybody!).
Footnotes
1 Specifically, the code I’ve written makes a few improvements to the BBC News RSS feeds:
(1) removing duplicate news, (2) removing non-news content such as “nudges” towards the app or to iPlayer content, and (3) optionally removing sports news. If that sounds
like a better version of the BBC News RSS feeds, you should take a look!
With its few-columns and large hit-areas, the game’s well-optimised for mobile play.
The premise is simple enough:
5-column solitaire game with 1-5 suits.
23 cards dealt out into those columns; only the topmost ones face-up.
2 “reserve” cards retained at the bottom.
Stacks can be formed atop any suit based on value-adjacency (in either order, even mixing the ordering within a stack)
Individual cards can always be moved, but stacks can only be moved if they share a value-adjacency chain and are all the same suit.
Aim is to get each suit stacked in order at the top.
Well this looks like a suboptimal position…
One of the things that stands out to me is that the game comes with over five thousand pre-shuffled decks to play, all of which guarantee that they are “winnable”.
Playing through these is very satisfying because it means that if you get stuck, you know that it’s because of a choice that you made2,
and not (just) because you get unlucky with the deal.
After giving us 5,105 pregenerated ‘decks’, author Zach Gage probably thinks we’ll never run out of playable games. Some day, I might prove him wrong.
Every deck is “winnable”?
When I first heard that every one of FlipFlop‘s pregenerated decks were winnable, I misinterpreted it as claiming that every conceivable shuffle for a game
of FlipFlop was winnable. But that’s clearly not the case, and it doesn’t take significant effort to come up with a deal that’s clearly not-winnable. It only takes a
single example to disprove a statement!
If you think you’ve found a solution to this deal – for example, by (necessarily) dealing out all of the cards, then putting both reserve kings out and stacking everything else on top
of them in order to dig down to the useful cards, bear in mind that (a) the maximum stack depth of 20 means you can get to a 6, or a 5, but not both, and (b) you can’t then move any
of those stacks in aggregate because – although it’s not clear in my monochrome sketch – the suits cycle in a pattern to disrupt such efforts.
That it’s possible for a fairly-shuffled deck of cards to lead to an “unwinnable” game of FlipFlop Solitaire means the author must have necessarily had some
mechanism to differentiate between “winnable” (which are probably the majority) and “unwinnable” ones. And therein lies an interesting problem.
If the only way to conclusively prove that a particular deal is “winnable” is to win it, then the developer must have had an algorithm that they were using to test that a given
deal was “winnable”: that is – a brute-force solver.
So I had a go at making one3.
The code is pretty hacky (don’t judge me) and, well… it takes a long, long time.
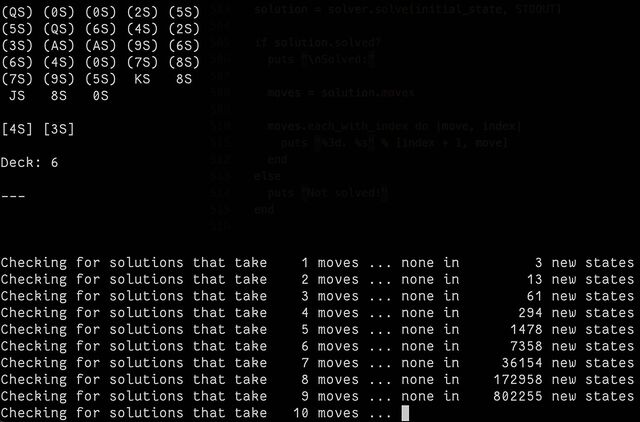
This isn’t an animation, but it might as well be! By the time you’ve permuted all possible states of the first ten moves of this starting game, you’re talking about having somewhere
in the region of three million possible states. Solving a game that needs a minimum of 80 moves takes… a while.
Partially that’s because the underlying state engine I used, BfsBruteForce, is a breadth-first optimising algorithm. It aims to
find the absolute fewest-moves solution, which isn’t necessarily the fastest one to find because it means that it has to try all of the “probably stupid” moves it
finds4
with the same priority as the the “probably smart” moves5.
If you pull off a genuinely random shuffle, then – statistically-speaking – you’ve probably managed to put that deck into an order that no deck of cards has never been in
before!6
And sure: the rules of the game reduce the number of possibilities quite considerably… but there’s still a lot of them.
So how are “guaranteed winnable” decks generated?
I think I’ve worked out the answer to this question: it came to me in a dream!
Show this puzzle to any smarter-than-average child and they’ll quickly realise that the fastest way to get the solution is not to start from each programmer and trace
their path… but to start from the laptop and work backwards!
The trick to generating “guaranteed winnable” decks for FlipFlop Solitaire (and, probably, any similar game) is to work backwards.
Instead of starting with a random deck and checking if it’s solvable by performing every permutation of valid moves… start with a “solved” deck (with all the cards stacked
up neatly) and perform a randomly-selected series of valid reverse-moves! E.g.:
The first move is obvious: take one of the kings off the “finished” piles and put it into a column.
For the next move, you’ll either take a different king and do the same thing, or take the queen that was exposed from under the first king and place it either in an empty
column or atop the first king (optionally, but probably not, flipping the king face down).
With each subsequent move, you determine what the valid next-reverse-moves are, choose one at random (possibly with some kind of weighting), and move on!
In computational complexity theory, you just transformed an NP-Hard problem7
into a P problem.
Once you eliminate repeat states and weight the randomiser to gently favour moving “towards” a solution that leaves the cards set-up and ready to begin the game, you’ve created a
problem that may take an indeterminate amount of time… but it’ll be finite and its complexity will scale linearly. And that’s a big improvement.
I started implementing a puzzle-creator that works in this manner, but the task wasn’t as interesting as the near-impossible brute-force solver so I gave up, got distracted,
and wrote some even more-pointless code instead.
If you go ahead and make an open source FlipFlop deck generator, let me know: I’d be interested to play with it!
Footnotes
1 I don’t get much time to play videogames, nowadays, but I sometimes find that I’ve got
time for a round or two of a simple “droppable” puzzle game while I’m waiting for a child to come out of school or similar. FlipFlop Solitaire is one of only three games I
have installed on my phone for this purpose, the other two – both much less frequently-played – being Battle of Polytopia and the
buggy-but-enjoyable digital version of Twilight Struggle.
2 Okay, it feels slightly frustrating when you make a series of choices that are
perfectly logical and the most-rational decision under the circumstances. But the game has an “undo” button, so it’s not that bad.
4 An example of a “probably stupid” move would be splitting a same-suit stack in order to
sit it atop a card of a different suit, when this doesn’t immediately expose any new moves. Sometimes – just sometimes – this is an optimal strategy, but normally it’s a pretty bad
idea.
5 Moving a card that can go into the completed stacks at the top is usually a good idea…
although just sometimes, and especially in complex mid-game multi-suit scenarios, it can be beneficial to keep a card in play so that you can use it as an anchor for something else,
thereby unblocking more flexible play down the line.
6 Fun fact: shuffling a deck of cards is a sufficient source of entropy that you can use
it to generate cryptographic keystreams, as Bruce Schneier demonstrated in 1999.
7 I’ve not thought deeply about it, but determining if a given deck of cards will result
in a winnable game probably lies somewhere between the travelling salesman and the halting problem, in terms of complexity, right? And probably not something a right-thinking person
would ask their desktop computer to do for fun!
Jeremy Keith posted his salary history last week. I absolutely agree with him that employers exploit
the information gap created by opaque salary advertisement, and I think that our industry of software engineering is especially troublesome for this.
So I’m joining him (and others) in choosing to share my salary history. I’ve set up a new page for that purpose, but here’s the summary of its
initial state:
Understand
A few understandings and caveats:
For most of my career I’ve described myself as a “Full-Stack Web Applications Developer”, but I’ve worked outside of every one of those words and my job titles have often been more
like “CMS Developer” or “Senior Engineer (Security)”.
My specialisms and “hot areas” are security engineering, web standards, performance, and accessibility.
When I worked multiple roles in a year, I’ve tried to capture that, but there’ll be some fuzziness around the edges.
The salaries are rounded slightly to make nice readable numbers.
I’ve not always worked full-time; all salaries are translated into “full-time equivalent”1.
I’ve only included jobs that fit into my software engineering career2.
If the table below looks out-of-date then I’ve probably just forgotten to update it. Let me know!
Ad-hoc and hard to estimate.
Alongside full-time study.
What does that look like?
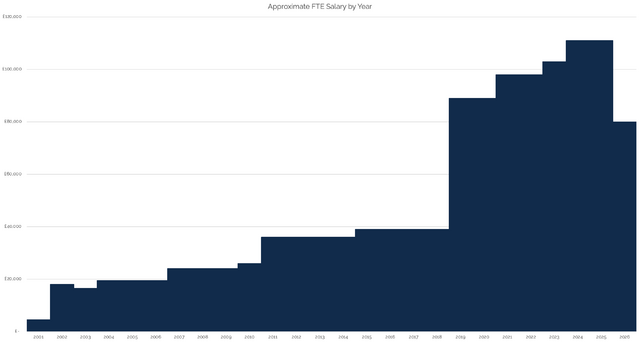
I drew a graph, but I don’t like it. Mostly because I don’t see my salary as a “goal” to aim for or some kind of “score”.
It’s gone up; it’s gone down; but I’ve always been more-motivated by what I’m working on, with whom, and for what purpose than I have been on how much I get paid for it3.
But if you want to see:
I’m not sure to what degree my career looks typical or not. But I guess I also don’t care! My motivations are probably different than most (a little-more idealistic, a little-less
capitalistic), I’d guess.
Footnotes
1 i.e. what I’d have earned if I had worked full-time
2 That summer back in college that I worked in a factory building striplight fittings
doesn’t appear, for example!
3 Pro-tip if you’re looking at my CV and pitching me an opportunity:
mention what you expect to pay, sure, but if you’re trying to win me over then tell me about the problems I’ll be solving and how that’ll make the world a better
place. That’s how you motivate me to accept your offer!
Towards the end of last week we picked up the keys to the Chicory House.1 We’ve now officially moved in to
the place we’ll be calling home for the next six months or so, while we wait for our Actual House to be repaired following our catastrophic flood in February.2
As part of my efforts to travel light, I use a pretty small
wallet – a lump of carbon fibre about the size of a deck of cards3 that contains my ID, bank cards, and – in pocket at the back – my essential keys.
Typically that’s my front door key and my bike lock key.
The keys tuck in around the back, but there’s a “hook” on the end to which additional keys can be ringed. Sometimes I hook up a second-factor hardware token to it when I’m travelling
with one.
And so when I received my front door key to the Chicory House, I had to decide: where does this key belong?
The obvious answer would have been to remove the front door key for my actual home from its special place within my wallet and replace it with the Chicory House’s front
door key. That’s the one I’ll need most-often for the foreseeable future, right? My regular front door key can move to the supplementary hook, on a ring, and/or be removed entirely and
taken with me only when I need to visit my uninhabitable home.
But that’s not what I did.
I didn’t even think about what I was doing until I noticed, afterwards, that I’d chosen to put the Chicory House key on the “supplementary keys” hook rather than in the “primary keys”
spot.
This made sense as an instinctive move: it’s where I’d clip on the key to any of the half-dozen or so AirBnBs I’ve lived in for the last couple of months, after all! But for a house I’m
going to live in for half a year or more it doesn’t seem so rational.
But I haven’t put it back. I think I’m keeping it this way. My regular key gets to keep its special spot because it represents the lost status quo and the aspiration to return. Sure,
it’s less-practical for me to keep it there, but its position is symbolic, not sensible.
Swapping the two over would feel like giving in: like caving to the inevitability of us being out of our home for an extended period. Keeping the key where it is means that every time I
put my hand in my pocket I’m reminded that the current arrangement is temporary; things will go back to normal. And that’s nice.4
2 The flood was exactly two months ago today, which makes today “F-Day plus 60”. We’ve
spent most of the intervening time hopping from AirBnB to AirBnB.
3 As somebody who often carries a deck of cards, this is a pretty-convenient size to me!
4 That said, the Chicory House is way better than most of the AirBnB’s we’ve
been living in, and I’m especially loving being able to sleep on my own familiar mattress again! While I wouldn’t want to live here forever like I’d be happy to in
the place we’ve called home since 2020, it’ll certainly suffice for the
immediate future. A stepping-stone back towards the lives we’d built before.
Mike Cook wrote a provocative blog post this weekend; an
anti-preservationist argument for video games. The essence of his arguments seem to boil down to:
Emphasising creation over preservation is liberating, as demonstrated by the imagination in the livecoding community.
Archiving without intensive curation is building an emotional or intellectual safety net you never expect to be used.
Digital preservation is a lossy process: effort spent on accurately preserving some media is at the expense of other media, whose lossy preservation paints in inaccurate picture of
what is lost.
Recreation, rather than strict preservation, ensures the continuity of the most culturally-important parts of games
Art is important for culture, and it’s important for nostalgia, but it’s hard to draw the line between where one purpose ends and the other begins.
He concludes to say:
60 games are released on Steam every day.
There are 294 game jams active on Steam as I write this.
Preserve nothing. Make more.
To make is to preserve.
Let games die.
Digital preservationism
Philosophically-speaking, there’s no doubt that I am a digital preservationist. I argue against unnecessary URI changes. I donate to
The Internet Archive. Back at the Bodleian, I used to carve out free time from project work to spend time making sure the University’s “older”
exhibition websites could be made to survive1. My approach to running out of hard drive space is to buy more hard drives. Even my blog retains
content going back into the last millennium2!
My reimplementation of Pong had several distinct differences from the original… but to a layperson – for whom Pong are the target audience! – those differences are
irrelevant. To what level fidelity matters depends on many factors, and the biggest problem is that we don’t know what those factors are until it’s time to retrieve these historical
media.
This screenshot isn’t from the original site but from my homage to it. More on that later.
This makes it seem like I’m very much on the side of recreation, rather than preservation, but that’s not the case. In both of these projects I started by disassembling the
original works.
That I chose to make them accessible to a modern audience by reimplementation rather than by emulation was an artistic choice. I opted for lower fidelity by making something
mildly-transformative. I chose to appeal to the widest possible audience, at the expense of presenting an experience that was totally in-keeping with the original.
But I couldn’t have done that without access to the originals. Had I recreated Pong from memory rather than from re-playing it, I’d have doubtless introduced
inconsistencies that would have “felt wrong” to people whose memories of the game, while fundamentally accurate, differed from mine. Had I recreated Axe Feather without
first coming up with a mechanism to extract and reformat the video clips in the original I’d have failed to tap into the specific nostalgia of some of its users, which was tied to the
specific actor who performed in it3.
So I guess it’s important to me that somebody is preserving these things. So that I can use them to create new things. I stand for preservation for culture’s
sake, so that I personally can enjoy the benefits for nostalgia’s sake.
For all that I feel like I’m making the case for “preserve everything; work out what’s important later”, Mike’s argument gives me an uncomfortable cognitive dissonance. Because
I’ve also come to discover a joy in the ephemeral, too.
I don’t know who’ll preserve ARCC, with its permanently-capped 500-playerbase limit, but I’m happy that I’ll probably always hold
the highscore on driving/racing minigame M1.
Increasingly, I’m okay with just taking the experience of something with me. It bothers me that my memory is fallible and that I can’t necessarily recreate a digital
experience whose technology has been lost to time, but I am, for the most part, okay with it.
Some of the best gaming experiences I’ve ever had are impossible to “capture” in an archive anyway. They were conversations over the tabletop roleplaying table, or moments of tension
resulting from a videogame’s emergent gameplay, or random occurrences unlikely to be replicated. Those get preserved in my memory alone, retold as stories with
gradually-decreasing accuracy as new memories take their place.
That said…
Who decides what games get preserved?
I feel like the decision about what to preserve and how should be in the hands of the audience of a piece of art, not its creators. If a videogame (or film, or book, or
whatever) is culturally-significant enough to warrant a high-fidelity preservation, it ought to be ultimately up to the members of that culture to make that decision!
Transport Tycoon Deluxe met that bar, and it’s possible to play both faithful recreations or modern reimplementations (the latter having excellent new features)
courtesy of the OpenTTD project4.
But modern videogames are, perhaps, getting harder to preserve. Always-online features, insidious DRM, digital distribution, live updates, and games-as-a-service streaming
all shift the balance of power more-firmly into the hands of publishers5
rather than players. It’s already hard to play a randomly-selected thirty-year-old videogame today; I reckon it’ll be almost impossible to do the same thirty years
hence.
Saying “let games die” feels a bit like giving up to that inevitability. Like saying to the slimier publishers “it’s okay, we didn’t care about keeping that anyway” when they shut down
servers or remotely kill games. I know that’s not what Mike’s saying, but it could be wilfully misinterpreted that way.
Anyway: I don’t have a nice conclusion to any of this. Just a lot of mixed-up feelings.
2 Even where those writings don’t really represent me well any more.
3 It turns out that, for a significant number of folks who are mostly younger-than-me,
this advertisement represented a kind of sexual awakening, based on some of the comments and emails I’ve received about it!
4 Which I’ve also donated too. Turns out I’m happy to invest in both pure
preservation and in spiritual-successor reimplementation!
5 Supposing that Sonic Rumble Party somehow wasn’t a catastrophic
pay-to-win nightmare and somehow was deemed culturally-significant… how would you go about archiving it? Without Sega/Sonic Team’s consent, you’d be totally out of luck.
This week I’m at Three Rings‘ annual “3Camp” event. Owing to Some Plot, we had a gap in the cooking rota, and, seeing that there was a pizza
oven in the back garden, I figured… I can make a couple of dozen pizzas to feed everyone, right?
There was no mixing bowl large enough to accommodate the 4.5kg of flour so I just dumped it onto a surface, added some salt and sugar, made a well in the middle, and introduced my oil,
water and rehydrated yeast right into the middle of it.
Minus a few minor spills, it broadly worked as a technique.
We weren’t able to find the woodpile at the house we’re staying at, so I eventually had to seek a volunteer to go and forage to B&Q to buy a couple of sacks of wood. I
can’t wait to hear our treasurer’s response to this unusual expenses claim!
After an initial rise I knocked-back the dough and separated it into balls, and got started on building the fire.
I own a small, portable Ooni pizza oven that’s fired by woodchips, and I find it pretty challenging to use. It eats fuel pretty quickly and loses
heat through its thin walls just as fast, and so it’s hard to maintain a consistent temperature while simultaneously maintaining the supply of wood and cooking pizza.
This brick-built oven, though, was a different kind of beast.
Compared to my small metal oven, this brick oven took a lot longer – on the region of an hour – to get up to temperature… but once hot, it maintained the heat much
better.
I set up a prep station nearby and had Three Rings volunteers “build their own” pizzas: stretching or rolling the dough, adding sauce and cheese and other toppings, etc. And then I
rotated them through the oven, up to two at a time.
My arms were already tired from the workout of hand-kneading the enormous pile of dough, and it was hot and tiring work to keep making, moving, and turning pizzas… but it was also…
amazingly fun.
Lookin’ hot, there. (The oven, that is.)
As the pizzas started to come out, Three Rings volunteers did too, gathering around the fire pit and in the covered dining areas of the garden, glasses in hand, to enjoy freshly-baked
hot slices of crispy pizza, while they talked about volunteering, history, the future, and a diversity of other random topics beside (space travel, politics, music, teaching…).
Awesome.
Ruth took this photo to show me that I had a floury handprint on my butt. She claims she’s not responsible for it, but I’m not so sure.
So yeah… now I really want to build a brick pizza oven of my very own.
Obviously I’ve got other priorities right now (like having somewhere to live following the house-wrecking flood), but maybe that’s something I
could look at in a future year.
The first pizza out of the oven was probably the ugliest, but it was also the one I remembered to photograph.
3Camp remains an annual tradition that I love dearly: the camaraderie, the doing-good-in-the-world, the opportunity to work alongside so many kind and talented volunteers, the chance to
play with exciting technology, and whole experience… but the pizzas on the penultimate evening have got to go down as a special highlight this year.
I was pretty ill yesterday. It’s probably a combination of post-flood stress and my shitty lungs’ ability to take a sore throat and turn it into something that leaves me lying in bed
and groaning.
I spent most of the morning in and out of a fitful sleep, during which I dreamed up the most-bizarre application: a GPS tracker app that, after being told your destination and what you
were eating, reported your journey progress to social media by describing where you were going and how much of your food was left1.
The “eating progress” could either be updated to the status itself or overlaid onto a map of the route.
I should be clear that in the dream, I wasn’t the one that invented this concept; in fact, I didn’t even understand it at first (maybe I still don’t!). In the dream I was
at some kind of unconference event with a variety of “make art with the Web” types, and I missed a session by falling asleep2. I woke
(within the dream) right before the session ended and rushed in to see what was being presented, and only got the tail-end of the explanation of how a project – this
project – worked, after which I felt rushed to try to understand it before somebody inevitably tried to talk to me about it.
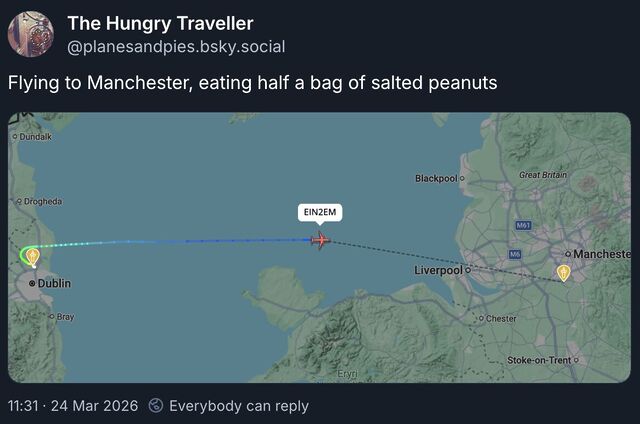
For times you’re disconnected or otherwise unable to self-track, tools like FlightRadar could step in.
I’m probably not going to implement this. It is, in the end, the kind of stupidity that could (should?) only appear in the dreams of somebody who’s got a bad head cold.
But if you manage to take this idea and turn it into something… actually good?… let me know!
Or if you’ve just got a cool, “Web 2.0-ey” idea for the name of an app that tracks both your journey progress and your meal consumption, I’d love to hear that too.
Footnotes
1 Under the assumption that its consumption would be evenly distributed throughout the
journey. Because everybody does that, right? Counting the number of steps they make before taking another equal-sized bite. Right?
2 Even in my dreams, I can dream of falling asleep. And, sometimes, of dreaming. A fever
probably helps.
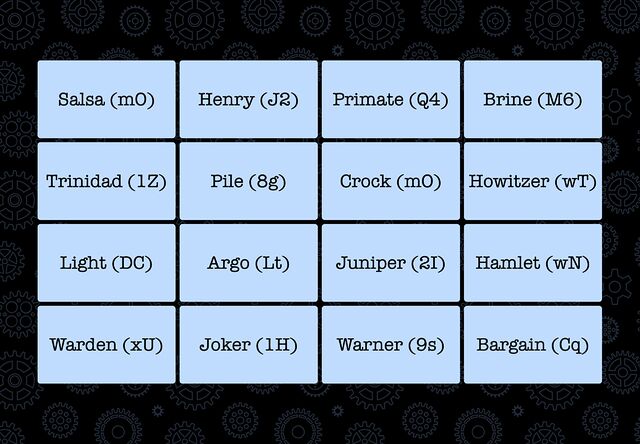
The other day I needed to solve a puzzle1. Here’s the essence of it: there was a grid of 16 words. They needed to be organised into four thematic “groups” of four words each;
then each group needed to be sorted alphabetically.
Each item in each group had a two-character code associated with it: these were to be concatenated together into a string and added to a pastebin.com/... URL. The correct
four URLs would each contain a quarter of the answer to the puzzle.
Apparently this puzzle format is called “Only Connect” and is based on a TV show?2
I’m sure I could have solved the puzzle. But I figured it’d be more satisfying to solve a different puzzle, with the same answer: how to write a program
that finds the correct URLs for me.
I’m confident that this approach was faster.3
Or rather: it would have been if it hadn’t been for the fact that I felt the need to subsequently write a blog post about it.
Here’s how it works:
It creates an array containing the 43,680 possible permutations of 4 from the 16 words.
If sorts the permutations and removes duplicates, reducing the set to just 1,820.
It removes the bit of each that isn’t the two digit code at the end and concatenates them into a URL.
It tries each URL, with short random gaps between them, listing each one that isn’t a 404 “Not found” response.4
I kicked off the program and got on with some work. Meanwhile, in the background, it permuted the puzzle for me. Within a few minutes, I had four working pastebin URLs, which
collectively gave me the geocache’s coordinates. Tada!
Was this cheating?
I still solved a puzzle. It probably took me, as a strong programmer, about as long as it would have taken me to solve the puzzle the conventional way were I a strong… “only
connect”-er5.
But I adapted the puzzle into a programming puzzle and solved it a completely different way, . Here’s the arguments, as I see them:
Yes, this was cheating. This wasn’t the way the puzzle author intended it to be solved. Inelegantly brute-forcing a problem isn’t “solving” it, it’s sidestepping
it. If everybody did this, there’d be no point in the author putting the time into the puzzle in the first place.
No, this wasn’t cheating. This solution still required solving a puzzle, just a different one. A bad human player making a lucky guess would be fine. It’s
a single-player game; play any way that satisfies you. Implementing software to assist is no worse than asking a friend for help, as others have done.
Click on a 😡 or a 🧠 to let me know whether you think I cheated or not, or drop me a comment if you’ve got a more-nuanced opinion.
2 Don’t try to solve this one; it’s randomly generated.
3 This version of the program is adapted to the fake gameboard I showed earlier. You won’t
get any meaningful results by running this program in its current state. But you could quickly adapt it to a puzzle of this format, I suppose.
4 It occurred to me that it could have been more-efficient to eliminate from the list any
possibilities that are ruled-out by any existing finds… but efficiency is a balancing act. For a program that you’ll only run once – and in the background, while you do other things,
to boot – there’s a tipping point at which it’s better to just get it running than it is to improve its performance.
5 There’s a clear parallel here to the various ways in which I’ve
solved jigsaw-puzzle-based geocaches, because I’m far more interested in (a) programming and (b) getting out into the world and finding geocaches in interesting places than I am
in doing a virtual jigsaw puzzle!
People being unwilling to discuss their wild claims later using the lack of discussion as evidence of widespread acceptance.
When people balance the new toilet roll one atop the old one’s tube.3
Come on! It would have been so easy!
Shellfish. Why would you eat that!?
People assuming my interest in computers and technology means I want to talk to them about cryptocurrencies.4
Websites that nag you to install their shitty app. (I know you have an app. I’m choosing to use your website. Stop with the banners!)
People who seem to only be able to drive at one speed.5
The assumption that the fact I’m “sharing” my partner is some kind of compromise on my part; a concession; something that I’d “wish away” if I could.
(It’s very much not.)
Brexit.
Wow, that was strangely cathartic.
Footnotes
1 I have a special pet hate for websites that require JavaScript to render their images.
Like… we’d had the<img>tag since 1993! Why are you throwing it away and replacing it with something objectively slower, more-brittle, and
less-accessible?
2 Or, worse yet, claiming
that my long, random password is insecure because it contains my surname. I get that composition-based password rules, while terrible (even when they’re correctly
implemented, which they’re often not), are a moderately useful model for people to whom you’d otherwise struggle to
explain password complexity. I get that a password composed entirely of personal information about the owner is a bad idea too. But there’s a correct way to do this, and it’s not “ban
passwords with forbidden words in them”. Here’s what you should do: first, strip any forbidden words from the password: you might need to make multiple passes. Second, validate the
resulting password against your composition rules. If it fails, then yes: the password isn’t good enough. If it passes, then it doesn’t matter that forbidden words
were in it: a properly-stored and used password is never made less-secure by the addition of extra information into it!
It’s F-Day plus 31 – a whole month (and a bit; thanks February) since our house filled with water and rendered us kinda-homeless.
We continue to live out of a series of AirBnB-like accommodations, flitting from place to place after a week or fortnight. I can’t overstate how much this feels like a hundred tiny
inconveniences, piling up in front of me all at once and making it hard to see “past” them.
Our current two-week stint is spent at a place that’s perfectly delightul… but it’s not home.
They’re all small potatoes compared to the bigger issue of, y’know… our house being uninhabitable. But they’re still frustrating.
I’m talking about things like discovering your spare toothbrush heads are at the “wrong” house. Or having to take extra care to plan who’s going to use which car to go to the office
because the kids and the dog need dropping off (because our lives were all optimised for our local walking and bus routes). It’s a level of cognitive load that, frankly, I could do
without.
I’m trying to look on the bright side. One particular highlight was JTA and I discovering the epic pizza restaurant inside the brewery that’s about four minutes walk from where we’re living, right now.
Meanwhile, any relief is slow to come. We’re still without a medium-term plan for somewhere to live, because even though the insurance company has pulled their finger out
and agreed to pay for say six months of rental of a place, we’re struggling to find a suitable property whose landlord is open to such a
short-term let.
When the house first flooded and friends told me that I’d be faced with manymonths of headaches, I figured this was hyperbole. Or that, somehow, with the epic
wrangling and project management skills of Ruth, JTA and I combined, that we’d be able to accelerate the process somewhat. Little did I know
that so many of the problems wouldn’t be issues of scale or complexity but of bureaucracy and other people’s timescales. Clearly,
we’re in it for the long haul.
It feels silly that we’re still in the first quarter of this 2026 and already I’m looking forward to next year and the point where we can look back and laugh, saying “ah,
remember 2026: the year of the flood?” Sigh.
My recent post How an RM Nimbus Taught Me a Hacker Mentality kickstarted several conversations, and I’ve enjoyed talking to people about the “hacker
mindset” (and about old school computers!) ever since.1
Thinking “like a hacker” involves a certain level of curiosity and creativity with technology. And there’s a huge overlap between that outlook and the attitude required to
be a security engineer.
By way of example: I wrote a post for a Web forum2
recently. A feature of this particular forum is that (a) it has a chat room, and (b) new posts are “announced” to the chat room.
It’s a cute and useful feature that the chat room provides instant links to new topics.
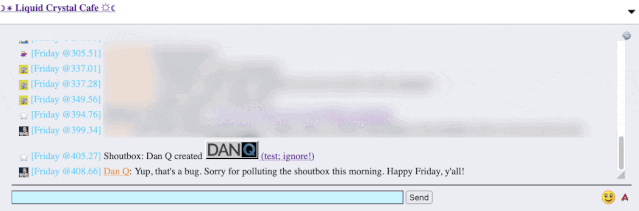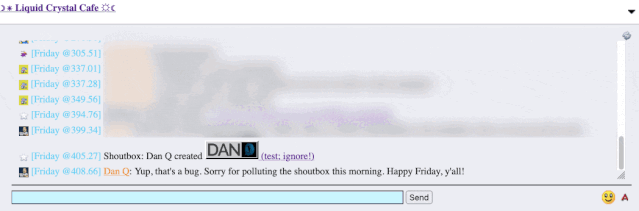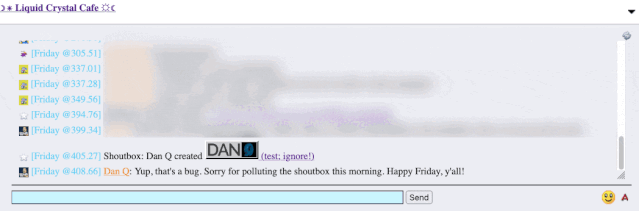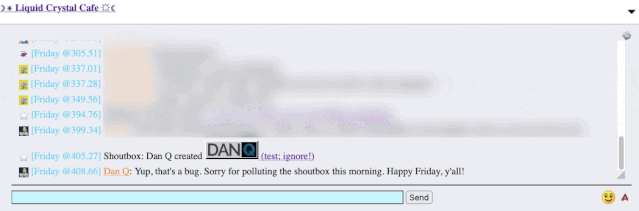
The title of my latest post contained a HTML tag (because that’s what the post was talking about). But when the post got “announced” to the chat room… the HTML tag seemed to have
disappeared!
And this is where “hacker curiosity” causes a person to diverge from the norm. A normal person would probably just say to themselves “huh, I guess the chat room doesn’t show HTML
elements in the subjects of posts it announces” and get on with their lives. But somebody with a curiosity for the technical, like me, finds themselves wondering exactly
what went wrong.
It took only a couple of seconds with my browser’s debug tools to discover that my HTML tag… had actually been rendered to the page! That’s not good: it means that, potentially, the
combination of the post title and the shoutbox announcer might be a vector for an XSS attack. If I wrote a post with a title of, say, <script
src="//example.com/some-file.js"></script>Benign title, then the chat room would appear to announce that I’d written a post called “Benign title”, but anybody viewing it
in the chat room would execute my JavaScript payload3.
I reached out to an administrator to let them know. Later, I delivered a proof-of-concept: to keep it simple, I just injected an <img> tag into a post title and, sure
enough, the image appeared right there in the chat room.
Injecting an 88×31 seemed like a less-disruptive proof-of-concept than, y’know, alert('xss'); or something!
This didn’t start out with me doing penetration testing on the site. I wasn’t looking to find a security vulnerability. But I spotted something strange, asked
“what can I make it do?”, and exercised my curiosity.
Even when I’m doing something more-formally, and poking every edge of a system to try to find where its weak points are… the same curiosity still sometimes pays dividends.
And that’s why you need that mindset in your security engineers. Curiosity, imagination, and the willingness to ask “what can I make it do?”. Because if you don’t find the loopholes,
the bad guys will.
Footnotes
1 It even got as far as the school run, where I ended up chatting to another parent about
the post while our kids waited to be let into the classroom!
2 Remember forums? They’re still around, and – if you find one with the right group of
people – they’re still delightful. They represent the slower, smaller communities of a simpler Web: they’re not like Reddit or Facebook where the algorithm will always find something
more to “feed” you; instead they can be a place where you can make real human connections online, so long as you can deprogram yourself of your need to have an endless-scroll of
content and you’re willing to create as well as consume!
3 This, in turn, could “act as” them on the forum, e.g. attempting to steal their
credentials or to make them post messages they didn’t intend to, for example: or, if they were an administrator, taking more-significant actions!