It’s been a hundred and thirteen days since the flood that wrecked our house, and we’re told that repair work will start imminently. Like: as
soon as next week!
So today I returned to the house to try to disassemble my sit/stand desk. An enormous and heavy thing that was constructed in-situ, it survived the flood without significant damage but
is sort of hard-to-move for the purpose of getting it out of the way of the folks who’ll hopefully soon be repairing walls, floors, electrics and the like.
This way up. For now.
Unfortunately it proved just too difficult to disassemble the beast. I’d anticipated that it would be able to be easily separated into two major pieces – the “top”, and the “frame” –
but the guy who built in for me1
made some creative decisions about the placements of the controllers and the motors which has meant that the two now can’t be separated without taking the whole thing
apart into a lot of tiny bits.
I’ll speak to the builders when they come. Maybe a floor can be laid elsewhere in the house and then the desk, which I’ve collapsed as small as its little motors will
carry it, can be moved onto the newly-constructed floor so that it’s out of the way here.
Wowsa, these are some tiny connectors!
So I got started on my other hardware task of the day: attempting to repair Ruth‘s laptop. It’s reporting via LED codes a graphics fault and
its screen isn’t coming on, and the most-likely cause it an un-seated signal cable. So I picked up some teeny-tiny screwdrivers (my usual ones all being packed in boxes) and had a go.
But no dice; I’ve reseated the cables and it’s still sad, so I’m guessing it’s an actual issue with the screen. Sigh.
Two for two on hardware failures today. I should go back to writing some software. Fortunately; there’s lots of that that needs my attention too, this weekend!
Footnotes
1 Who – I suspected at the time and of which I’m now even more-confident – might well have
been high when he assembled it. There’s some wacky choices here, plus he’s drilled several holes on the underside that he then didn’t actually use!
👋 Hi! If you came here after going to ChangeNames.co.uk, congratulations: you just dodged getting scammed.
To actually change your name for free as a British citizen, without giving your personal information to scammers (or anybody else who doesn’t need it!), I suggest you use
FreeDeedPoll.org.uk. Want an alternative? DeedPoll.lgbt is good too!
I help people change their names
As a British citizen, you can change your name for free. That’s the entire premise behind my website FreeDeedPoll.org.uk, which since 2011 has
helped thousands of people change their names1
for free and without a solicitor.
It’s a pretty useful website, if I say so myself.
I aim to run the most-ethical service of its type:
As noted, it’s completely free and collects no personal information whatsoever.
It’s funded out of my own pocket so it doesn’t need to depend upon advertising.
It’s open source so anybody can inspect my code, or run it themselves, or even set up a “competing” copy (so long as they give away
the code to that, too)!
I try to answer every email I receive from anybody who’s having difficulty with the process.2
Scammers will barely help you, but they will steal your data
Others, however, don’t.
I’m not talking about all the paid-for services. Some of them provide a useful service, albeit one that you don’t strictly need to pay for. I’m not a fan of
those that try to market themselves as “official”, though, because that just feels like fraud. No, I’m talking about a level of sliminess that goes well beyond merely charging
somebody for something they’re entitled to for free.
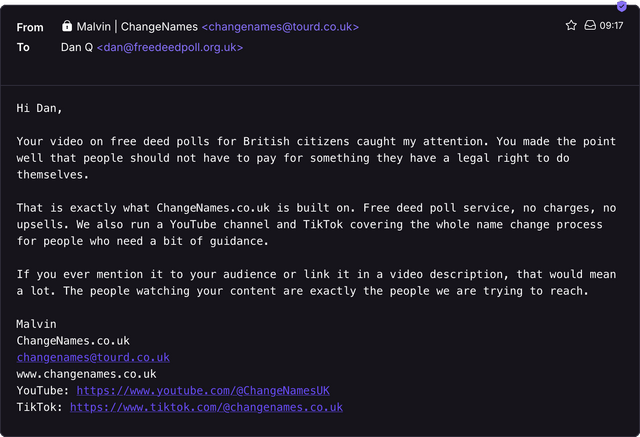
Like… let me show you an email I received today:
My bullshit alarm was going off as soon as I saw this email, but I figured I’d dig a little deeper before I decided whether or not to consign it to the spam folder.
I tried to visit their website but it looks like they haven’t even bought the domain name they’re advertising, yet. Just for fun, I’ve registered it and set it up as a permanent
redirect to this blog post3.
Their TikTok channel exists, but it’s not at the URL they provided. So far, so incompetent.
Gotta admit, their video production quality’s better than mine… even if the content isn’t!
Both their YouTube and TikTok channels provide a link not to their “website” but to a kit.com page that asks for some personal details with the promise of a deed poll at the end of it.
When you fill in the form – and obviously you shouldn’t do so using real information – you get added to a marketing email list and a handful of other mailing lists get
pushed at you.
“Why are you changing your name” is a mandatory free-text field. Why are they asking this? Who knows!
Kit.com require double-opt-in confirmation for mailing lists, but the email tries to trick you into clicking the button, saying that clicking the “confirm your subscription” button
“help us know you have received the deed poll and everything works”. In reality, they’re just trying to legitimise their spamming.
And what do you get out of it after all this? A hyperlink to a publicly-accessible Google Drive
folder called “Deed Polls”[sic]4 that a more-ethical outlet could have just linked to in the first
place. it contains a couple of Word documents that require you to delete a ton of underscores in order to type your own content in.
Oh, the the templates are full of mistakes. Here’s one (there are others!):
This clause contains both a grammatical error (saying ‘only’ twice) but a legal one! For most people, a deed poll is used to change their name for all purposes, not
merely specifically-and-exclusively for professional purposes.
Of all the scammy free deeds poll services I’ve seen, ChangeNames is the worst
What we’ve got here is…
a marketing scam pretending to be a deeds poll service,
being run ineptly, e.g. marketing using a domain name they haven’t yet purchased and providing broken links to their own social media,
that are using unethical techniques to harvest personal information,
in exchange for a deed poll template that’s riddled with errors. 🤦
But the really insane thing about this whole scam is that a human being found my video about my own (superior, ethical) service FreeDeedPoll.org.uk… and then figured that they’d email me to see if I’d like to pass some traffic to their (inferior, unethical) competitor.
That bit… that’s the bit that blows my mind.
Footnotes
1 I can’t tell you exactly how many because I make a deliberate effort to collect no
personal information, without which I’m unable to pin down a specific number. But I’ve had many hundreds of emails from people who’ve changed their names, and have anonymous
statistics to suggest that the number is almost-certainly in the tens of thousands, maybe in the low hundreds of thousands.
2 I’m not a lawyer, but I’ve become pretty familiar with lots of relevant parts of the
laws about not just names but adjacent areas like citizenship, residency, gender identity, information protection, and parental rights, and I’ve been able to point many people towards
satisfactory conclusions when they’ve had more-challenging name changes.
3 It might not be working yet, depending on the state of DNS propagation, but it’ll get
there in a day or so I reckon.
4 The plural of deed poll is, of course, deeds poll, but one could hardly expect
these clowns to know that.
My actual implementation was Go, rather than JavaScript2, as part of a side project
this weekend. Here’s the function I came up with.
Today was also the day that I discovered that while SU is a reserved 2-letter ISO 3166-1 designation for the Soviet Union, the flag of the USSR is not a
registered emoji. But if it were, we can work out what codepoint it’d be at! So I can type this – 🇸🇺 – here, safe in the knowledge that if that emoji comes to exist in the
future, then you’ll be able to revisit this blog post and see it!
You know what: there might be a game in these country codes and their flags somewhere. Like: a game where you have to get from one country to another: like, say, from the 🇨🇰 Cook
Islands (CK) to 🇧🇯 Benin (BJ). But you’re only allowed to change one letter at a time and you have to land in a real country. I think the fastest route between those two takes three
steps, e.g. 🇨🇰 Cook Islands (CK) to 🇹🇰 Tokelau (TK) to 🇹🇯 Tajikstan (TJ) to 🇧🇯 Benin (BJ)… It’s probably a bit easy though: I haven’t yet found any that require more than three moves
and most can be done in just two.
It gets a lot harder if you require letters to only be changed to an adjacent letter, but this variant makes some permutations impossible. Maybe there’s an optimisation puzzle in the
style of the Travelling Salesman problem? Or maybe by mixing in geographical restrictions such as an inability to visit a certain continent that would make it more challenging
and fun? Just brainstorming here…
Footnotes
1 An alternative way of thinking about it is that you’re taking the number of the letter
in the alphabet – e.g F=6, R=18 – and adding 64 to each. Here’s why, and why it’s beautiful.
2 I don’t get to write Go often, and I seem to get rusty at it quickly, but I enjoy the
feeling of writing something so raw and yet so clean.
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
Just sometimes when you’re playing the “hey, Wikipedia, give me a random page” game, you get a hole in one. That’s what happened today when I landed on the article for… Carl Person.
Whatever else you can say about him, he looks pretty dapper in a suit. Photo courtesy Carl Person, used under a Creative Commons license. Knowing that he has a Wikipedia
account (which he used to upload this photo), I took the time to browse the article history and check for any obvious signs of tampering, sockpuppetry, or other foul play, but it
looks reasonably clean.
Yes, Person is his actual surname. Speaking as a person with a stupid name, it pleases me to find people whose names probably cause them at least as much
trouble as mine does. Wikipedia wasn’t any help at understanding where the surname Person comes from (and Carl himself isn’t
even noteworthy enough to appear on the list of “notable people with that surname”, it seems).
However I did enjoy discovering jazz saxophonist Houston Person (which sounds like the beginning of a news headline about
somebody from Houston!) who once released an album called… Person to Person! Excellent. Also, actress and
filmmaker Marina Person whose documentary about her father, filmmaker Luis Sérgio Person, was titled simply Person. I think the name might be related to Swedish
surname Persson – literally, “son of Per” – where Per is a Scandinavian
variant of Peter. This probably means that there’s a “Per Person” somewhere in the world, and I want to meet him.
Anyway: back to Carl. He trained as a lawyer and spent the 1960s working in a variety of corporate law firms. These included the one for which Richard Nixon was a partner, during that period after Nixon failed to get elected as Governor of California and announced that he was
retiring from politics… only to come back six years later to be elected president and, well, you know the rest.
Paralegals! All of the work; a fraction of the pay!
Anyway: other things he did as part of his legal career were –
Represented other members of The Teenagers (then The Premiers, because confusingly the band changed their name to “The
Teenagers” when they got older) in their efforts to reclaim shared copyright of their 1956 hit Why
Do Fools Fall in Love from lead singer Frankie Lymon and Gee Records.
Represented playwright Mark Dunn in his successful claim that The Truman Show was based upon his 1992 play, Frank’s Life, whose script he’d previously attempted to sell to
Paramount.
Helped Ralph Anspach (whose book I read before writing this 2013 blog post!) in his
appeal against a ruling that Anspach’s board game Anti-Monopoly was derivative of Parker Brothers‘ stake
in Monopoly: the appeal was successful at least in part because Person and Anspach were able to prove that Monopoly was, itself, derived from Lizzie Magie‘s The Landlord’s Game. (Fun fact: this was
the second time Carl successfully took on Parker Brothers; the first being the Masterpiece case,
representing Christian Thee!)
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
My random landing page today is a genus for which there’s only a single species, so I hopped over to that species’ page.
And what a species!
Somehow it looks more like an alien than octopodes normally do! Drawing produced by Carl Chung in 1910.
This is the blind cirrate octopus (cirrothauma murrayi), a species found beneath the oceans all around the world but at such a depth that they’re not
well-understood. We’re not even sure whether the specimens we’ve studied represent a single species or two separate species!
The Latin name comes from oceanographer John Murray, best known for his Challenger Expedition from 1872–1876, but whose four month North Atlantic Oceanographic Expedition in 1910 – which he
self-funded – was the first to find this unusual species. It was described by Carl Chun, whose previous claim to fame had been the
discovery of the (also amazingly alien-looking) vampire squid, seven years earlier.
(The vampire squid is its own amazing thing: did you know that it turns itself inside out to evade predators, exposing the inner surface of its spiked tentacles? Also it can
spit glow-in-the-dark mucus to dazzle an attacker.)
You can tell it’s a cirrate octopus by those fins on its head. Cirrates are one of the two major families of octopodes: they’re the ones that do have a pair of
mini strands dangling off each sucker on each tentacle, but don’t have an ink sac. They’re also notoriously fragile, and when we’ve pulled them up for research purposes
they’re often in poor condition by the time they’re on the surface… and that’s especially true for deep dwellers like the blind cirrate octopus.
As for blind: well – it’s got eyes… but those eyes don’t have lenses. As a result, they’re probably able to tell light from dark but probably
can’t make out the particular shapes of objects. (This is a great example, contrary to claims of irreducible
complexity in the eye by proponents of “intelligent design” of an eye with only some of the components that seem essential to a fully-functional organ that still
provides value for its host!).
Vertebrate (left) and cephalopod (right) eyes have several distinct differences which suggest different evolutionary origins. In cephalopods, the retina (1) is routed in front of the
nerve fibres (2) that connect to the optic nerve (3), meaning that cephalopods do not have the “blind spot” (4) that vertebrates do.
Like all cephalopods, they have no blind spot because their retina is in front of the nerve fibres instead of behind them.
Like squid and possibly cuttlefish, they can differentiate the polarisation of light. (I believe that sheep and goats can, too!)
Their pupils automatically rotate to stay horizontal, no matter which way up they are!
There’s some debate about whether or not octopodes and other cephalopods’ eyes evolved from a shared
ancestor or are an example of convergent evolution, and the arguments for both are really interesting.
Of course, our friend the blind cirrate octopus is, umm… mostly blind. Very different from other octopodes.
As I said, we know so little about it! We don’t know what it eats (we think it probably eats whole shellfish). We don’t know how it breeds. We don’t know how commonplace it is or
whether its environment is under threat.
But what we do know is that it’s a freaky-looking thing from way down deep. Thanks, Wikipedia, for telling me about this strange beast. Let’s see what you have to share with me
tomorrow!
My 12-year-old was interested in learning some HTML and CSS and making her own website. If she were anybody else I’d point her at something like Nekoweb as a starter host because their web-based (VSCode-based) “Nekode” text editor makes writing your first static site simple.
But I’ve got a NAS sitting at home on a fibre connection, so I figured: I might as well just host something similar here.
Here’s how I did it:
1. DNS
I pointed her domain at my static IP, plus a subdomain for the “backend” interface. Suppose her site would be at example.net (and www.example.net) with the admin interface at
admin.example.net: my DNS configuration might look like this:
The templates directive means that, if/when she wants to, she could use Caddy’s built-in SSI-like
features. Or if she decides someday she’d prefer a static site generator then I can sort her out with shell access or something.
I used the OpenVSCode Server Docker image to provide a browser-based VSCode interface in which she could edit HTML, CSS and
JavaScript and drag-drop files from her local machine. I’m using Unraid on my NAS so I didn’t have to think much about running a new Docker container,
but I guess that if I did then I’d have typed something like:
dockerrun-d\# 7890 is the port on my NAS that I'll proxy Caddy to:-p7890:3000
# /mnt/user/example.net is the path on my NAS;# /example.net is where it'll appear within VSCode:-v"/mnt/user/example.net:/example.net"\# this tells OpenVSCode-Server to mount the directory to begin with:-eOPENVSCODE_SERVER_ROOT=/example.net\gitpod/openvscode-server
Now all I needed to do was point Caddy at it. For the time being I simply restricted access to only “computers on my local LAN”, but it’d be easy enough to add authentication using basic auth and/or client
certificates if she wanted to be able to work on her site from elsewhere:
admin.example.net{
# Restrict access to 192.168.* LAN:@allowed{
remote_ip192.168.0.0/16}
# Proxy permitted folks to the container:handle@allowed{
reverse_proxyhttp://nas:7890}
# Block everybody else:handle{
abort}
}
That’s literally all it took to put together a web-based editing environment that publishes directly to a static website. And because it’s on my own infrastructure, it’d be
trivially easy to modify it in the future if she decided to go in a different direction, e.g. a PHP site, or continuous
deployment from a repo, or static site generation from a shell.
That’s all!
Here’s a test site I threw together using exactly this stack, demonstrating the entirely browser-based editing workflow (not shown is drag-and-drop to upload, but I promise that works
too!):
It’s been 97 days since our house flooded and we had to evacuate. We’re now living medium-term in a “chicory
house” a few minutes drive away, but there’s still plenty of reason for us to return frequently to the disaster site that is our actual
house.
Today, for example, JTA and I went to show around some contractors who will eventually, we hope, be able to install new floors,
skirting boards, remove and replace a wall, rebuild the kitchen, fix the electrics…
It’s been over three months since we had to move out. With the drying-out complete, it’s finally time to begin planning to start scheduling
the start of the repair work that needs doing. What a painfully-slow process!
The day after the flood water receded, I took this photo while we were assessing damage – you can see the tide marks left by the water:
That picture shows part of our piano, which took in a lot of water and was significantly damaged. It’s off at a nice piano hospital right now being repaired, and I miss it much more
than I expected.
After playing maybe ten minutes a day almost every day for years, I routinely get up from my desk to stretch my legs or heat up my lunch and my fingers itch to plink-plonk away
at it. Of all the hundred inconveniences of our temporary living situation and everything that goes along with it, that’s the one
that bites most-frequently. It’s a strange sensation.
But all the builders and the insurance company and everybody else seem confident that they can get us back into our home in the Autumn, and certainly by Christmas, so there’s something
to look forward to. A light at the end of the tunnel.
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
The planet Mercury is covered with impact craters, which isn’t surprising because it has no atmosphere to slow down incoming
meteors nor significant active tectonic or erosion processes to conceal them once they’re created. In 2015 the IAU ran a competition to name four such craters: the winning entries resulted in the naming of the craters Carolan, Enheduanna, Kulthum, Rivera, and
Karsh.
The Karsh crater is about 180km wide, which is approximately comparable to… your mum.
This crater is named after Yousuf Karsh, who’s sufficiently famous that I’d actually heard of him, which was an unusual result
from hitting “random article” on Wikipedia.
But in case you don’t know who Yousaf Karsh is – or if, like me, you just wanted to learn more about him – then you’re in luck!
Selfies used to be a lot harder in 1958.
Yousuf Karsh was an Canadian-Armenian photographer who took principally portrait photographs, some of which you’ve almost-certainly seen already. He photographed a huge number of famous
and significant individuals of the 20th century. Like this one:
“Oh yes!” No wait, that’s the other Churchill’s catchphrase.
That photo, taken in 1941, is titled The Roaring Lion, and it’s got a story to it.
Winston Churchill posed for his photograph on his way out from delivering the “some chicken! some neck!” speech to the Canadian parliament (you can see his
notes from the speech tucked into his jacket pocket). He had his trademark cigar in his mouth, but Karsh wanted it gone. He asked Churchill to remove it, but Churchill refused, and
Karsh went ahead to take the photograph anyway. But then at the last second, Karsh said “Forgive me, sir” and snatched the cigar directly out of the Prime Minister’s mouth.
“By the time I got back to the camera, he looked so belligerent, he could have devoured me,” said Karsh later, of the expression on Churchill’s face. But it’s that expression that he
captured with the camera, and that would go on to be described by the USC as a “defiant and scowling portrait
[which] became an instant icon of Britain’s stand against fascism.” Absolutely iconic.
Churchill himself said, after the picture was taken, that “you can even make a roaring lion stand still to be photographed.” Hence the portrait’s name.
Or how about this picture of the Marx Brothers in 1948:
Karsh became known for his use of harsh lighting to pick out the fine details of his subjects’ faces, which I think is especially clear in this picture.
Or how about this fantastic photo of the then Princess Elizabeth, aged 21 or 22, before her accession as Queen Elizabeth II:
“So long as Daddy manages to die before he has any sons, I’mma get me so much Empire Commonwealth.”
Here’s some things I didn’t know about Yousuf Karsh, though:
Being born to ethnic Armenians in the Ottoman Empire could have been a death sentence in itself for young Yousuf. Ottoman
and later Turkish Nationalist authorities and paramilitaries deported, confined, or murdered hundreds of thousands and quite possibly over a million Armenians, who they saw as a threat
to their national identity (among other candidate causes).
Karsh and his family travelled with a Kurdish caravan to Aleppo in Syria in 1922, and a year later his parents took advantage of a
humanitarian scheme to transport displaced Armenians to live with relatives in Canada: the then 15-year-old who “spoke little French, and less English” and “had no money and little
schooling” moved half way around the world to live with his uncle.
Yousuf’s uncle was a photographer and taught him the essentials of early-20th-century photography technology and techniques, before sending him to apprentice in Boston under John H.
Garo, a fellow Armenian whose studio hosted the still-running Boston Camera Club. He worked in the USA for a time then
returned to Canada, opening his own studio in 1932. When his brother Malak was able to join him in Canada in 1937, Yousuf helped
Malak break into a career in photography too: a career that would probably have been better-known were it not for being in the shadow of his older brother!
I don’t know whether he’d care about having a crater named after him or not. But he’d probably have been more proud of the legacy that lives on in the Karsh Award, given every alternate
year by the City of Ottawa for outstanding artistic work in a photo-based medium.
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
My random article for the day was about Here & Now, the second album of Pop Shuvit, a Malaysian hip hop/nu
metal band most-active from around 2002 to 2011. I listened to the album; the title track’s pretty good, and I enjoyed Old Skool Rocka and Put ‘Em Up too.
I dig the album art. I think the one holding the skateboard is bassist ‘AJ’; which ties to the next part of my journey…
The band take their name from a skateboarding trick called a pop shove-it, presumably using the different spelling to aid their ability to protect their copyright on it.
And this is the point at which I briefly got lost in the depths of Wikipedia’s article about skateboarding. A pop shove-it, you see, is apparently a combination of
an ollie and a shove-it,
which still sounded like a foreign language to me, so I had to read up on both. Here’s what I learned:
An ollie is when you stomp down on the back of the board to make it jump, while sliding the front foot forward from the midpoint to keep it somewhat-level and stop it
flipping “over”. This results in the entire board jumping while remaining almost-horizontal, while the skater flies just above it.
A shove-it is when you rotate the board 180° laterally, so that the “back” end of the board becomes the “front” and vice-versa: so the board ends up landing and its
wheels roll the opposite direction they did at the start of the trick, but the board and skater carry on moving forwards. It’s done by giving the board a bit of a kick to start it
rotating and then landing on it with enough pressure to stop it rotating again.
That’s a terrible explanation. Here’s a terrible diagram from Wikipedia that probably doesn’t help either: (you’ll want to find a video if you really want to understand it, but
that goes beyond what’s available on Wikipedia, so I’m not sharing it as part of this blog series!)
I note that the creator of this diagram chose to spell the trick in the same way as the band name. Diagram courtesy of GoSkate.com, used under a Creative Commons license.
The pop shove-it was originally called the Ty hop, after its inventor Ty Page, a famous skateboard in the 1970s also
known by the name “Mr. Incredible”.
I could list some of the other fifty-plus moves he’s credited with inventing (like the pay hop, daffy or yeah right manual, and the toe-spin 360),
but it’d probably only be fun and interesting if I mixed-in a few fake ones I conceived of myself (like the nip trip, double pipe-tail, and the indo
180).
Skateboarding had been around since at least the 1950s and had exploded in popularity in the 1960s, but a major part of
the reason Ty was able to invent totally new tricks in the 1970s was the result of a two new innovations that took off at that time:
Polyurethane wheels, invented by Frank Nasworthy to supplant the use of hard steel wheels (commonly used by rollerskates at the time) or clay composite wheels.
Steel wheels were fast and smooth-running, but because they’re hard they provide little grip, which makes stunts harder to control. Clay composite wheels were softer and easier, but
wore out quickly, needing to be replaced after as little as seven hours of skating. Polyurethane gives a best-of-both worlds, giving a long-wearing but soft-enough-to-grip surface to
the wheel from a material that was rapidly becoming cheaper to manufacture.
The kicktail, invented (and patented) by Larry Stevenson, is the curved-up bit at the end of a board, so named because it originally only appeared at the back of a board
(although Larry cleverly obtained a separate later patent on double-kicktails: one at the front and one at the rear – the front one is sometimes called a
kicknose). A kicktail makes it much easier and safer to lift a board by stamping down on it, or else can make it possible to get more lift with a similar level of ease,
compared to a completely flat board.
Who knew there’s so much terminology in a skateboard‽ The wheel is attached to a truck which is attached to the deck of the board. Cropped from the original by
Suyash Dwivedi, used under a Creative Commons license.
Ty Page helped promote the kicktail as part of the Makaha Team, sponsored by Stevenson’s company MAKAHA Skateboards. And here’s where I jumped into a whole different rabbithole.
At this point in history – as skateboarding was just beginning to come into its own as a sport – there was an enormous intersection between surfboarders and skateboarders, many of whom
would surf when weather and tide conditions were right and skate when they weren’t.
Larry Stevenson was such an individual. On his way to his deployment in the Korean War, he stopped at Hawaii where he found a
particular beach to be excellent for surfing. That beach, which would eventually give its name to his company, was at the town of… Mākaha.
Gotta admit, Mākaha Beach Park looks pretty lush. Photo courtesy Nicolai Edgar Andersen, used under a Creative Commons license.
One thing I found interesting while reading about Mākaha is that it’s the home of Kāne’āki Heiau, Hawaii’s most-completely restored heiau. Heiau are temples of the indigenous religion of Native Hawaiians, a polytheistic and animistic belief structure itself seemingly related to earlier Māori practices brought over by Polynesian seafarers from 800 CE onwards.
According to tradition, heiau were built by menehune, mythological two-foot high dwarves who lived in the deep forests and
hidden valleys, far from humans, and came out at night to build structures and dig fish ponds. The concept is comparable to the European idea of brownies or hobgoblins, in particular the pre-Christian idea of these
spirits as being helpful to humans so long as they’re treated with respect.
Menehune with Fish by David Howard Hitchcock, 1933. Menehune were said to especially enjoy eating bananas and fish. Fun fact: the sparsely-populated Wainiha Valley was declared by census in 1500 to have a population of 65 menehune.
Pressure from Christian missionaries in Hawaii from 1820 onwards led to the neglect and destruction of most heiau, except for the most-remote of them. One such remote temple was the
standing stones on Necker Island (see: we got there eventually!).
Necker Island is named after Jacques Necker, France’s finance minister at the time that the first European explorer – Jean-François de Galaup – sighted the rock. We don’t know what ancient Hawaiian peoples called
it, but reverse-engineering Hawaiian chants passed down by oral tradition that include descriptions of islands
has led the Hawaiian Lexicon Committee to assign it the name Mokumanamana, which means “pinnacled island”.
Necker Island as photographed in 1969 by the U.S. National Oceanic and Atmospheric Administration.
We also don’t know when Necker Island was last inhabited, but it seems that its poor thin soil is likely to have prevented permanent settlement. However, there’s evidence that its caves
were used for human habitation from time to time, and some have been used as tombs. Even landing on the island is difficult on account of its sheer stone cliffs around its edge (which
is part of the rim of what was once a volcanic cone).
Researchers recognise that the structures on Necker Island represent an earlier iteration of Hawaiian religion than other heiau and some use the Māori term marae to refer to them. Similar structures are found in New Zealand, for example.
But do you know what archaeologists found on Necker Island, amongst the standing stones? Menehune figurines, carved out of basalt, one and a half to two feet tall. Tales in the oral
traditions of the natives of the island of Kauaʻi describe Necker Island as the last refuge of the diminutive builders after they
were chased off the main island by the newly-arrived Polynesians.
Where are the stone figures right now? Well this one, and another one, are in the British Museum. Because of course they
are.
In the way that was long-traditional for European empires exploring the culturally-important sites of distant lands, many of the artefacts found on Necker Island aren’t there any more.
But the standing stones are still standing, and human remains that were removed and put into a museum have been returned and re-buried, at least.
So that’s Necker Island! Which I learned about because Wikipedia randomly chose me an article about an album by a Malaysian hip hop band, whose name derives from a skateboarding trick
that’s possible thanks to an invention by a man whose skateboarding company was named after a surf-friendly Hawaiian beach near a town that has ruins of a temple allegedly built my
mythological dwarves who are said to have lived there. It’s been quite a journey! I wonder where tomorrow’s will take me.
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
The Baikal seal is a species of “earless” seal that lives exclusively in Lake Baikal in Siberia. It’s one of only a tiny number of
species of seal that spends its life only in freshwater: others, like the much more-widespread harbour seal (that
I’ve occasionally seen around the UK), for example, can and will swim up rivers to hunt but mostly live in saltwater. But not the Baikal seal.
These Baikal seals are just chilling on a rock near the Ushkan Islands. Photograph courtesy Nina Zhavoronkova, used under a
Creative Commons license.
The Baikal seal is confined just to this one lake. Which sounds like a small area until you realise quite how large Lake Baikal is. The seventh-largest lake
in the world, Lake Baikal is just a little larger than Belgium, but that really doesn’t do justice to its true volume, because it also happens to be the deepest lake in
the world. It’s so deep that a fifth to a quarter of all the surface freshwater in the world is found in this one lake.
If you count frozen water in the ice caps and glaciers too, then Lake Baikal still contains about fifth of all the fresh water on Earth. That’s just amazing.
It’s quite so deep because it’s a rift lake: it sits close to the boundary between the Eurasian and Amur tectonic
plates, which are shearing away from one another. For the same reason, there are volcanic hot springs deep in the lake (although the lake itself is so massive that they have no
measurable effect on its overall temperature). There’s a lot of not-fully-understood geology going on in the region, despite active research going back over a century.
The clarity of the water in the lake is also noteworthy, getting up to 40m of visibility in the winter. Photo courtesy Xchgall, used under a Creative Commons license.
The Baikal seal isn’t the only species unique to the lake. It’s also home to a kind of fish called the omul, a salmon-like fish that’s
long been part of the cuisine of the area.
It’s used to make raskolotka (known as stroganina elsewhere in Russia): thin slices of the meat cut almost to the entire length of the fish’s body and served as frozen
curls. The particular shape of a traditional skinning Yakutian knife, which is sharpened to a curve on one-side and left flat
on the other, is especially suited to this task, apparently:
You can see how the shape of the knife is particularly suited to making these long, thin strips. Photo courtesy Cholbon, used under a Creative Commons license.
Lake Baikal also hosts the Baikal Deep Underwater Neutrino Telescope, whose acronym BDUNT makes me think of bundt cakes. Which –
Wikipedia tells me – nobody’s certain of the etymology of!
Anyway, the neutrino telescope is an SK-variety neutrino
detector, spotting neutrinos zipping through the Earth when they just-ocassionally interact with the water, resulting in the creation of a high-energy electron or muon and the
resulting short burst of Cherenkov radiation. Operated from the surface of the winter ice, the experiment aims to search
for evidence of relic dark matter in the sun, among other astronomical phenomena.
I wonder what impact all the fish and seals have on the detection equipment? Photo courtesy Bair Shaybonov, used under a Creative Commons license.
It’s all interesting, but if there’s one thing I’ll take away from this daily deep-dive into a random Wikipedia topic, it’s this photo of a cute young Baikal seal:
Those big eyes! 😍 Photo courtesy Per Harald Olsen, used under a Creative Commons license.
I wonder what tomorrow’s random Wikipedia article will bring me! If it’s interesting, I’ll share it with you!
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
One of the things I’ve discovered over my past few days of hitting “Random Article” on Wikipedia is that sometimes you get something that’s worth writing about. But more often you get
something worth reading but not writing about. But more often still you get something that doesn’t interest you at all, and you just need to click “Random Article” again.
And that latter category is the one I thought I was in when I discovered Marcus Koh, who’s a Singaporean yo-yo enthusiast who came first in the 1A division at the World Yo-Yo Contest in
2011. The page almost felt like a stub… but then I started clicking and found myself learning much more about yo-yos than I ever thought possible.
Like… I knew that the yo-yo was an old toy, but I had no idea how old.
This 1791 image allegedly from a French fashion journal. The French usually called the toy a
emigrette at the time, but the 1888 republication of this image in Le Costume Historique called it Joujou de Normandie, so who knows.
Obviously there’s a lot of pictures from around the end of the eighteenth century, which is when they became popular in Europe. In the English-speaking world at that point they were
known as “bandalores”, which I think is a nicer name than “yo-yo”, frankly.
But their influence was clearly felt much further away and much longer ago than this.
I mean, here’s a 1770 watercolor from Northern India that clearly depicts something that, despite being held in two hands, is definitely something-like-a-yo-yo:
But we can go further.
If you lived in Greece in around the 5th century BCE and were serving wine to your guests, the popular drinking vessel to use was a kylix. Kylikes were pottery cups basically the shape of modern wine glasses but much more squat, having a wide bowl atop a pedestal that
tapered outwards. Unlike modern wine glasses, though, they had handles, and these handles were used to play a game called kottabos: once you’d finished your wine, you’d use a handle to “flick” the sediment from your wine (I guess fining/clarification agents weren’t a thing yet?) at a target in order to win a cake or something.
Sounds pretty gross for whoever had to clean up afterwards, if you ask me.
Anyway: oftentimes the inner bowl of a kylix would be decorated. Depending on the kind of party you were throwing you might have a nautical theme where everybody finds a different kind
of boat at the bottom of their cup when they drain it… or for a more raucous party perhaps you’d get out the cups where the faces at the bottom all had genitals hidden in them. That
way, somebody gets surprised to find that at the end of a drinking session they have a penis in their face (I’ve certainly had parties like that before, if you know what I mean):
I guess that these were the Ancient Greek equivalent of shot glasses with swear words etched into them?
What I’m saying is… the Ancient Greeks liked to play drinking games, and they liked drinking vessels with pictures on. Which makes you look at the “Greek culture” of fraternity houses
in a whole new light.
But the pictures weren’t always either (a) boats or (b) crude, of course. They could be anything. Here’s an example of the bottom of a kylix that was probably used as a drinking vessel
in or near Athens around 2,500 years ago:
What the actual fuck? That boy’s clearly playing with a yo-yo in a picture painted before the Parthenon was built!
It’s not just novelty earthenware that tells us that the Ancient Greeks had the yo-yo, by the way. We’ve found actual examples of them made from bronze or terracotta,
although archaeologists suspect that there were many more wooden variants that have been lost to time.
I guess it’s true that it’s a toy that just keeps making a comeback. Every few centuries it gets reinvented and improved, I guess! “Modern” yo-yos got their relaunch in
the 1920s, when Pedro Flores (a Filipino businessman whose time in his birth country spanned a
previous story) brought to the USA a toy that had been popular in his homeland but seemed to be mostly-unknown in the States. The name apparently derives from a Tagalog word that means “come-come” or “come-go” or something similar. He produced both traditional “tied-on” yo-yos and
“slip-string” varieties that allowed the toy to “sleep” – to spin-freely at the end of its string – which unlocked a diversity of new tricks.
From here on, the yo-yo saw surges in popularity every 20 to 40 years. The full article’s worth a read because unless you’re a complete yo-yo nut I can guarantee there are things in
there that you didn’t know.
I was also very interested in the article about the “Eskimo yo-yo”, which I’d love to see somebody operate! It’s basically a
bola of two weights attached to a stick using strings of two different lengths, and the trick is to get them spinning in opposite directions but using only one hand. That
sounds amazing!
This post contains and links to (clearly-identified) AI-generated content. As remains the case, none of my writing on this blog was generated by AI.
Imagine my excitement to learn that Pagan Wander Lu just dropped a new EP, Built In Obsolescence. And then imagine my horror to discover that it’s actually produced by P-AI-gan
Wanderer Lu; an AI that’s been given PWL lyrics and some artistic direction.
Wot.
The album art’s clearly also AI-generated, and that’s… well… you know. At least this robot hand has got the correct number of fingers.
Nothingness is what silicon dreams
My younger child’s been getting into PWL in a big way lately. As a result of this, I ended up making time for a careful re-listen to a lot of the back catalogue. This in turn inspired
a blog post last year in which I mentioned that Checker Charlie‘s observations about humans
replacing their work with machine effort feels increasingly prophetic in the age of generative AI. That’s something I didn’t see in it when I first reviewed it 13 years prior.
I’ve played with AI-generated music a couple of times myself, of course,
mostly as an academic exercise. And it’s becoming more and more apparent that it’s hard to avoid bumping into it in the “real world”.
Early efforts at AI music were pretty unconvincing, always sounding a bit auto-tuney, frequently struggling to stress lines in the right places, and tripping over themselves when they
try to do anything even remotely more-interesting than a simple repeating melody atop a predictable chord sequence. But they’re getting… shall we say… “better”, and there have been
times nowadays when I’ve gotten some way through a track before realising that I’m listening to AI.
At least PWL’s being honest about it and declaring at the outset that this is AI-generated art. There’s plenty of folks using AI to generate content online and not
declaring it, which is pretty awful1.
Anyway: in this EP the AI’s moderately well-concealed and listening casually to most of the tracks I wouldn’t have noticed it if I hadn’t been told2.
Is there life enough in these chords?
So I listened to the EP. Three times.
The cover of Checker Charlie, I’m sad to admit, works. It’s got the feel of early-nineties pop, full of synths and saccharine, but instead of insipid lyrics about
love it benefits a lot from Andy’s lyrical prowess. It’s a bouncy bop that would be forgettable if it weren’t for the excellent story told by the words is, I suppose, what
I mean to say. And, of course, it’s the song that would have made me think about this. Anyway: I enjoyed it and would absolutely listen to it again, and I don’t know what
that says about me, about the song, or anything else.
Uncanny Valley doesn’t work as well. Musically, it feels like a new artist in 2012 drew inspiration from their dad’s new wave albums but wanted to make it sound more like Carly
Rae Jepsen was collabing with Daft Punk. And the result is kind-of…flat? Could I even say… soulless? It feels like it might have been the B-side of their cover
of Chemicals Like You, which rolls out next in the same vein. Twice was probably enough for these two.
Repetition 4 is among my favourite – let’s say top 15? – Pagan Wanderer Lu songs and the AI’s cover of it starts so strong. It finishes pretty strong too. The
voice it’s chosen shows only a hint of uncanny-valley-autotune and it wails plaintively. The most human-made bits – the lyrical themes of fighting for creativity against your own
struggles as a vulnerable and flawed human “machine” – remain solid. I really expected to love this one! But by the time we were half way through the song it felt… musically-repetitive.
You know when you get a pop cover of a classic song sometimes3 and you feel like the cover artist… missed the point somehow? That’s what this feels
like to me.
The repetitions of “we are all machines… for dancing” in the original felt meaningful and real; a human’s cathartic resignation to pleasure in the simple things we all enjoy, despite
the challenges of life… but the AI cover adds this kind of doo-woppy backing vocals that subtract, rather than adding to, the meaning. I’m not saying it ruins it –
it’s still a fun and bouncy version of a great song… but it’s one of those covers that leaves you longing for the original.
And then there’s the “unaligned version” of Uncanny Valley. I’m not sure if the introduced distortions in this version are AI-generated or not. They
don’t feel like the kinds of “creative” choices that any AI I’ve played with would make, so I suspect this represents a closer human intervention in the AI’s process:
humans imitating machines imitating humans, perhaps? Anyway: the change doesn’t add anything for me.
Had this been produced entirely by a human, I’d say that EP consists one one track I’d add to my everyday playlist (the cover of Checker Charlie), maybe one or two
tracks that I “wouldn’t necessarily skip” if they came up on a random shuffle while I wad driving… and the rest just feels too much like “bad cover” vibes.
And that’s as much of a review as I’m willing to give, for the reasons touched-upon below.
Building the engines of our own defeat
I continue to have several issues with the widespread use of generative AI, and in particular I have problems with it being used in the production of art. Those are partially
mitigated by it being used by an artist to remix their own work, and partially mitigated by the transparent declaration of the use of AI by the publisher both of which are
true in this case. But many issues (ethical, environmental, etc.) still remain.
Perhaps the biggest of which in this case is my concern that we’re using automation wrong.
As a child, I was optimistic about a future in which machines would take away the boring and repetitive work that humans do, leaving us free to pivot to experimental and experiential
roles: the joy of working hard in the quest of discovery and of creativity. But instead, the predominant popular use of generative AI is to replace exactly those
things, leaving humans only with an increasing amount of drudgery, review, and fact-checking. Where did we go wrong?
Don’t get me wrong: I love that Pagan Wanderer Lu has created this EP. Taking art that he’s created, whose concept touches on the concepts of AI… and feeding them into an
actual AI for reinterpretation is transformative. It’s worthy of discussion as a piece of art in its own right. And the result is… well, some of it’s good, and other
bits are okay.
What I don’t like is what it represents: the wider societal issue of the mainstream use of these technologies that have enormous unsolved problems.
So I guess… I appreciate the cognitive dissonance of enjoying a peice of music and disliking what it means?
Footnotes
1 Whether or not the side-effect of undisclosed AI-generated content “poisoning the well”
for future AI training is a good or bad thing remains an open question, in my mind, but it’s certainly a real phenomenon. You know how we salvage the wrecks of ships sunk before the atomic age because they’re untainted by man-made radioactivity, which makes them useful for special
purposes? It feels like the Internet before the explosion in generative AI may provide a similar cultural resource for future AI training, if you see what I mean.
2 And assuming I wasn’t already familiar with the artist, who doesn’t usually
sound like an auto-tuned female singer.
3 I don’t have a specific example so I hope this is a universal experience!
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
The Argo Wilis, near Lebakjero Station. Photograph courtesy of Naufal Farras, used under a Creative Commons
license.
With such an unfamiliar-sounding article title as “Argo Wilis” I momentarily thought I was playing Two Of These People Are Lying, but it turns out that it’s just a train. Well, I
say just a train, but it’s a train that took me on a journey (ah-hah!) to a rabbithole of Wikipedia pages, and today I’m going to drag you along with me.
The Argo Wilis is a train that goes back and forth along the Southernmost train line connecting Surabaya Gubeng, in the East, to Bandung, in
the West, along Java, the vastly
most-populous island of the Indonesian archipelago: most of the length of the island. “Argo” means “mountain”: it’s part of a modern collection of “Argo network” trains that are
each named after mountains in the region. Mount Wilis itself is a dormant volcano whose magma chamber apparently has the
potential for future geothermal power generation possibilities.
Map courtesy Twotwofourtysix, used under a Creative Commons license.
Learning about the Argo Wilis got me to reading about rail travel in Indonesia in general. There are particular challenges to running a train network in a mountainous
island nation with a somewhat monsoonal climate, it seems!
Like: one of the stops on the Argo Wilis‘s line is Cipeundeuy, a relatively tiny mountain station
that every single passing train stops at in both directions. Why? Because every train is required to have its brakes tested here before proceeding down the mountain slops
on either side of it!
All services must stop here, and have since the 1910s (except for a brief period in the 1990s).
That rule’s existed since the railway was first built, under Dutch East Indies rule, over a century ago. It’s been
consistently enforced ever since… except for a spell in the early 1990s when the practice was stopped… until a head-on crash in 1995 nearby acted as a reminder of the importance of the checks, at which point they were
reinstated.
The construction of the Javanese railways up and over or through the many mountains of the island would have been an incredible feat of engineering even today, let alone in the late
19th and very-early 20th centuries.
Anyway, here are some other things I learned about Indonesia’s railways while I was exploring Wikipedia:
Trains drive on the right
Like many island nations (and in common with some non-island nations, particularly those that were part of the British Empire), Indonesian cars drive on the left. But unusually, their railways don’t follow the same pattern: on twin-tracks,
Indonesian trains typically travel on the right.
The Dutch colonists were already running their railways on the right and brought this tradition with them, but when the Netherlands switched to right-hand driving for their
cars in 1906 (except in Rotterdam, which imposed no fixed rules about which side of the road you should drive on until
1917!), they only dragged some of their colonies along for the ride.
Not sufficing to have just first and second class travel like we do here in the UK, Indonesian trains are broken down into at
least four classes: luxury, executive, business, and economy. Plus a further two
categories for tourist-centric trains, imperial and priority. Plus some sub-classes that seem to be line-specific.
“Premium economy”-class interior of the train Sawunggalih Utama. Photo courtesy Gaudi Renanda, used under a Creative Commons license.
It’s all mostly diesel locomotives…
Jakarta’s got an electrified metro system, but most of the Indonesian rail network’s powered by diesel. However, a handful of industrial narrow-gauge mountain railways might still see
the use of steam locomotives for farming or mining purposes, like this one seen hauling sugar cane in 2003:
Photo courtesy Joachim Lutz, used under a Creative Commons license.
Jakarta was supposed to be getting an electrified monorail, but the project stalled in 2008 and the already-built
infrastructure is in the process of being demolished.
The remote mountain village of Lebong Tandai is only reliably connected to the rest of the world via a mountain railway line. Much of the narrow-gauge track is connected
via a plateway, rather than by sleepers, and residents operate the tiny motorised locomotives independently of the rest of the railway network.
This “Molek-Motor” on the remote line to Lebong Tandai is constructed out of the remains of a goods vehicle that was written-off after an accident. Photo courtesy Harry Siswoyo, used
under a Creative Commons license.
Anyway, that’s what I enjoyed learning about on today’s Wikipedia dive. I wonder what I’ll learn tomorrow! (If it’s as-interesting, I’ll let you know!)
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
Then back to Spain at the signing of the 1763 Treaty of Paris, where, when Britain was arguing which captured
territories it should be allowed to keep, everybody forgot about it and so it fell into the default bucket of “back to its previous controller”: it seems that Spain hadn’t even
noticed that Manilla had been captured!
Then, after the Mexican War of Independence… still under Spain, but now directly under the
Spanish crown and managed from Madrid.
The Flag of the United States of America is lowered while the Flag of the Philippines is raised during the Independence Day ceremonies on July 4, 1946.
As you might expect if you know anything about colonialism, there are absolutely horrible stories that could be told about any of those periods of history. So when I landed on the page
Governor-General of the Philippines, I decided that it might be cheerier to pick out a person from it.
And so I picked what I believe to be the person whose term as Governor-General of the Philippines was shortest: in post for just 16 days in August 1898: Wesley
Merritt.
Gen. Wesley Merritt, circa 1865.
Wesley was a cavalryman in the American Civil War during which, in 1863, he managed to leapfrog three ranks by getting promoted from Captain right up to Brigadier General. After the
Civil War he was posted to the Texan frontier where he commanded a cavalry regiment in the American Indian Wars. His success in… umm… “freeing up land” for American settlers (it turns out this post can’t escape from the ugliness of imperialism)… lead him to a new
role in using his troops to police the civilians rushing to “claim” land formerly occupied by native Americans.
But it’s right at the end of the 19th century that his story intersects with today’s random article.
“Uncle Sam’s Craving: Saving the island so it won’t get lost.” says this Spanish propaganda cartoon.
As the 19th century wore on, the world-spanning Spanish Empire came under serious threat. The Napoleonic Wars had cut Spain
off from its colonies, and one by one they lost control of Mexico, Peru, Colombia, Chile, Argentina,
and others (often with thanks to quiet support from Britain). But Spain had managed to
keep hold of Cuba and the Philippines, despite growing unrest and uprisings, which were often brutally suppressed.
At the time, the US was working to establish itself as a modern naval power, building new steel warships to compete with European powers and Brazil, and making plans for what would
eventually become the Panama Canal, and so this was a perfect opportunity to show off their armoured cruiser the USS
Maine.
Starboard bow view of USS Maine, shortly before her deployment to Cuba. Fun fact: the last surviving officer who was aboard on the day it sank, Wat Tyler Cluverius Jr., would go on to serve as an engineering officer on the new USS Maine, a pre-dreadnaught battleship that would still be in service at the time of the First World War
(although she was only used as a training ship because her coal efficiency was so terrible that it was no-longer sensible to have her cross an ocean).
The Maine got sent to Havana as a show of force and to protect American interests in Cuba, where, a couple of weeks later, she… blew up.
Probably what happened was that the bituminous coal stored in her bunkers was leaking methane out, which spontaneously ignited, starting a fire that ignited the ship’s powder store. But some, including Theodore Roosevelt (who was then assistant navy secretary and on his way to becoming vice-president) and much of the popular press, claimed that the ship must have been struck by a Spanish mine or
torpedo.
Neither the Spanish nor American official reports had been published before the newspapers were claiming that the Maine had been sunk deliberately. Fun fact: the inscription
on the monument to the victims that stands in Havana claims it was deliberate…
but by the Americans as a false-flag operation to justify a declaration of war against Spain! This interpretation was added by the communist government in 1961.
The next month, after Congress had had a chance to discuss the matter (do you remember when the US Congress used to have to be involved in the US declaring war on another country?), the
US declared war on Spain and began actively attacking her fleets and colonies in the Caribbean and the Pacific.
The US fleet steamed into Manilla Bay for what might be the most one-sided naval battle ever. The Spanish fleet at
Manilla would have been severely outmatched even were it not for the fact that the second-lead ship was unpowered, the shore batteries’ range was insufficient to be involved, and the
mines had been placed suboptimally. Only a single American sailor lost his life in the battle, and it was apparently as a result of a heart attack.
Battle of Manila Bay by James Gale Tyler (1898).
Okay, we’re at last up to Wesley Merritt‘s bit. Merritt was placed in command of the ground forces that were tasked with capturing Manilla. They sailed out of San Francisco, landed in
the Philippines, and prepared to attack the city.
Merritt and Admiral Dewey made a point not to coordinate with Emilio Aguinaldo y Famy, the leader of the Filipino resistance against the Spanish, who by this point had already taken control of
most of the Philippines and besieged Manilla, cutting off its water supply and beginning negotiations with the local Spanish leaders. It seems that Americans feared that if the
revolutionaries captured the city it would result in significant bloodshed as a result of violent looting and the murder of those who were seen to have collaborated with the Spanish,
and so they came up with an alternative plan: the American expeditionary force would attack and capture the city first!
Working through the Belgian consul to Manilla Édouard André, Merritt negotiated with the Spanish
Governor-General Fermín Jáudenes to arrange a “mock” battle. The ships in the bay would fire upon a fort that they knew was only used for storage and against defensive walls that they knew they were not capable of breaching,
and Spanish troops would be ordered to retreat as Merritt’s soldiers advanced. Then, Merritt would demand that the Spanish surrender the city, and they would comply, turning it over to
the American forces.
This would minimise casualties while allowing the Spanish Governor-General to avoid the shame of being seen to have lost the city to the revolutionaries (it being far more
politically-acceptable to lose to the might of the American invaders). Meanwhile, Aguinaldo’s troops initially saw the battle as genuine, which led to some casualties as Filipino
fighters advanced under fire; they joined the victims of other misunderstandings during the mock battle.
A drawing from Harper’s Pictorial History of the War with Spain. There’s a whole lot of pictures of flags getting rotated in this blog post!
Needless to say, the Filipinos deeply resented being told to stay out of the capital city that, given time, they might well have taken for themselves by force, had their efforts not
been leapfrogged by the USA. Ultimately this lead to a guerilla warfare campaign against the USA by Philippine
nationalists, which in turn contributed to growing concern in US political circles that America was becoming exactly the kind of imperialist power that it had opposed, at least on
paper, since its founding.
Anyway: on 13 August 1898 Wesley Merritt became the de facto Governor-General of the Philippines and the first American to hold that position. Two weeks later Major General Elwell Stephen Otis turned up and relieved him of the position, making Merritt the shortest ever Governor-General
of the Philippines.
Major General Wesley Merritt from Illustrated Roster of California Volunteer Soliders in the War with Spain (1898).
Merritt retired the next year and lived ten more years.
Anyway: that’s enough of today’s history lesson courtesy of a random Wikipedia page. I wonder what I’ll learn tomorrow! (If it’s as-interesting, I’ll let you know!)
Pushing to the main branch of my GitHub/Codeberg/wherever repo would send a webook to my server.
Upon receiving the webhook, my server would pull the latest changes2.
Using a wildcard certificate, my webserver automatically mounts each project at a subdomain matching its project name3.
Here’s what I came up with:
Step 1: webhook handler
I’m using Caddy as my webserver, because despite its considerable power and versatility it’s a breeze
to set up. To sort wildcard DNS later I’ll want to swap in a custom build, but to get started I just ran apt install caddy. Then I used apt install webhook
to install Adnan Hajdarević’s webhook endpoint, and tied the two together in my Caddyfile:
My static server’s called duckling.danq.me, so you’ll see that turn up a lot in these configs.
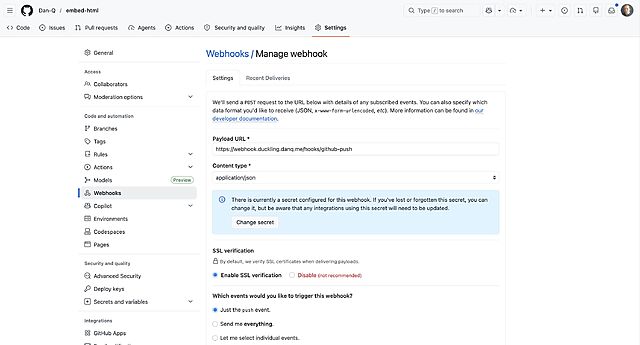
Then I created a webhook in a GitHub repository:
I generated a long random string to use as the secret, and kept a copy for later.
When you create a webhook in GitHub it immediately sends a test event, but it doesn’t quite look like a real push event so I pushed an inconsequential change to the repo
to trigger another. Once you’ve got a “real” one sent, you can re-send it via the “Recent Deliveries” tab as many times as you like, to help with testing.
Then, on the server, I checked-out a copy of the code (anonymously: this is a public repository so I don’t need keys to read from it anyway) and set up my /etc/webhook.conf to expect
these calls:
The trigger-rule directives ensure that (a) the secret key is correct (it uses a HMAC hash across the entire JSON request, so it prevents payload tampering too) and
(b) the event only triggers on pushes to the main branch. The execute-command specifies the Bash script I want to run when the webhook is triggered. The
pass-arguments-to-command configuration says to send the repo name on to that script.
Now all I needed to do was write the /var/www/github-push/webhook.sh Bash script so that it pulled the latest copy of the code when triggered:
#!/bin/bashcd/var/www/github-push/$1&&gitpull
I was able to test this by pushing inconsequential changes to my codebase and watching them get replicated down to my webserver. Neat!
Step 2: low-maintenance webserver
After pointing the DNS for *.static.duckling.danq.me at my static server, I set about configuring Caddy to be able to use DNS-01 challenges to get itself wildcard SSL
certificates4.
Caddy can’t do DNS-01 challenges out of the box, so you either need to write your own renewal script or compile Caddy with plugins corresponding to your DNS provider. My domains’ DNS
are managed by a mixture of AWS Route 53, Gandi, and Namecheap, so my xcaddy build step looked like this:
For Gandi and Namecheap I just need a personal access token or API key, respectively, but Route 53’s configuration is slightly more-involved: I needed to create a new user via IAM and
give it permission to write DNS TXT records for the appropriate hosted zone. Fortunately the guide for the
caddy-dns/route53 repo had an almost copy-pastable example.
I added the AWS access key and secret key as environment variables (like this!) into my
/etc/systemd/system/multi-user.target.wants/caddy.service service definition, and then told my Caddyfile to make use of them when renewing the wildcard certificate:
The {http.request.host.labels.4} refers to the fourth part of the domain name, when separated at the dots and counted from the right, so 0 = me, 1 =
danq, 2 = duckling, 3 = static, and 4 = the part that we’re interested in. So long as I don’t store any other directories in the
/var/www/github-push/ directory then this will simply map each subdomain onto its git repository name and return a 404 for any other request.
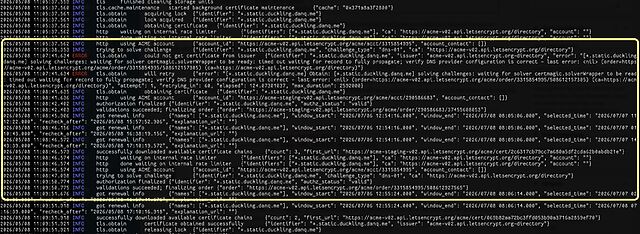
DNS-01 challenges are necessarily slower than HTTP-01/ALPN challenges, because they’re limited by DNS propogation, so it took a while before the
certificate was issued. I ran Caddy in the foreground to watch the logs while it did so:
I don’t yet know if this is going to be the future forever-home of my many static site side projects, but it’s certainly been the most-satisfying experiment to run so-far.
Footnotes
1 I’ve drifted away from selfhosting simple static sites lately because I’ve accidentally
broken them with configuration changes too many times! But I figured I’d be open to in-housing them again if I had a single simple architecture for them all, so I spun up a VPS and
gave it a go
2 Running a build script or some other static site generation tool is out of scope for
now, but I want to be able to confirm that it would be possible in the future.
3 It also needs to be possible for me to map other domain names to it, but that’s
a triviality.
4 It’s absolutely
possible to use tls { on_demand } to do this, but it’s better to use a wildcard certificate which can be pre-generated and doesn’t let people trick your
server into making ludicrous numbers of certificate requests by hammering random subdomain names.


![Screengrab from a YouTube video showing a white woman with brown-and-red hair saying "please see the FAQs for any questions you have have around deed polls[sic] and the rules." alongside a logo for "Change Names".](https://bcdn.danq.me/_q23u/2026/06/changenames-youtube-video-640x360.png)












.jpg)



















.jpg)
.svg)



.jpg)




_starboard_bow_view,_1898_(26510673494).jpg)
.jpg)
.jpg)

.JPG)