We’ve missed out on or delayed a number of trips and holidays over the last year and a half for, you know, pandemic-related reasons. So this summer, in addition to our trip to Lichfield, we arranged a series of back-to-back expeditions.
1. Alton Towers
The first leg of our holiday saw us spend a long weekend at Alton Towers, staying over at one of their themed hotels in between days at the water park and theme park:



























2. Darwin Forest
The second leg of our holiday took us to a log cabin in the Darwin Forest Country Park for a week:





























3. Preston
Kicking off the second week of our holiday, we crossed the Pennines to Preston to hang out with my family (with the exception of JTA, who had work to do back in Oxfordshire that he needed to return to):







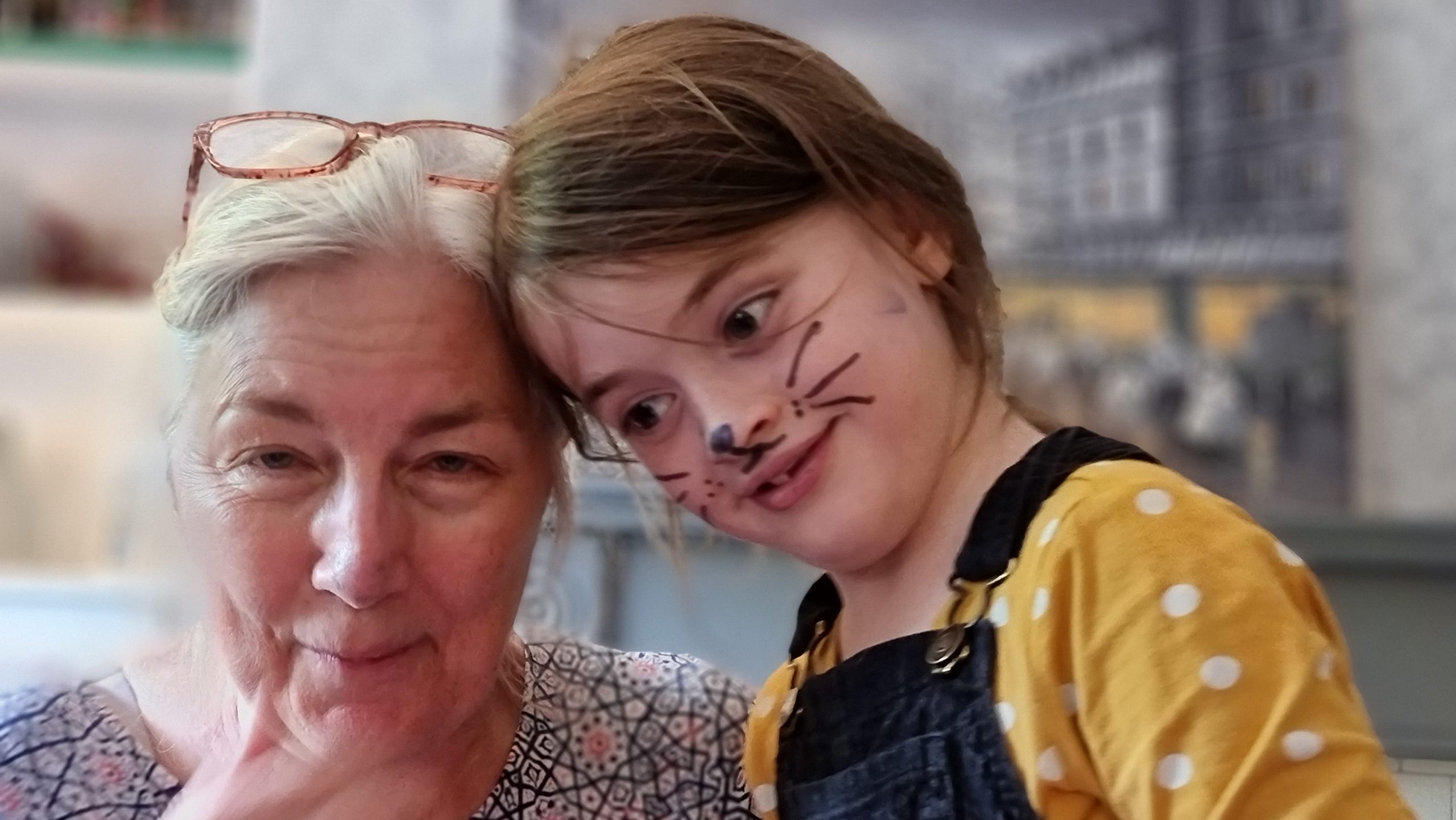






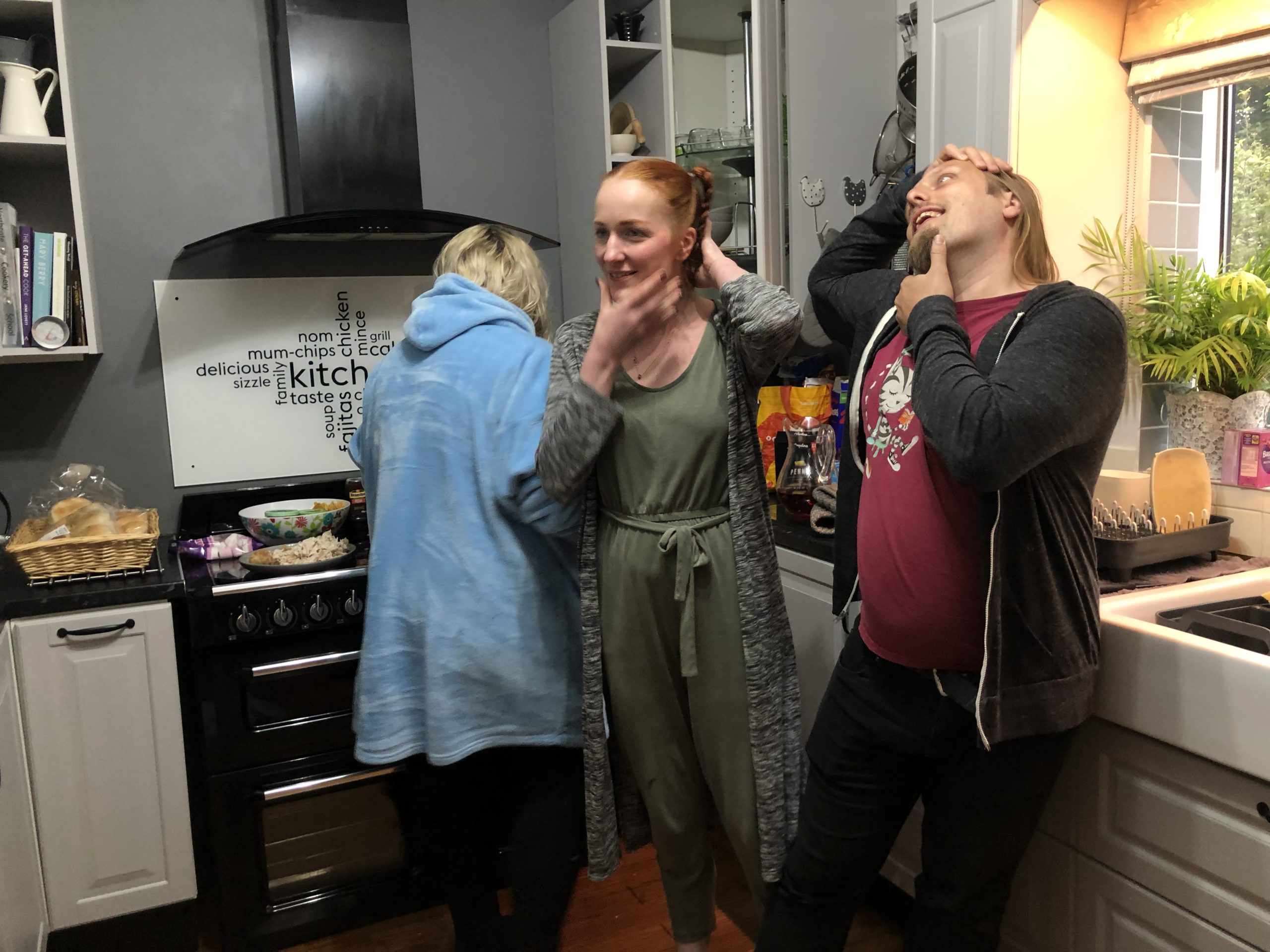





















4. Forest of Bowland
Ruth and I then left the kids with my mother and sisters for a few days to take an “anniversary mini-break” of glamping in the gorgeous Forest of Bowland:













(If you’re interested in Steve Taylor’s bathtub-carrying virtual-Everest expedition, here’s his Facebook page and JustGiving profile.)
5. Meanwhile, in Preston
The children, back in Preston, were apparently having a whale of a time:














6. Suddenly, A Ping
The plan from this point was simple: Ruth and I would return to Preston for a few days, hang out with my family some more, and eventually make a leisurely return to Oxfordshire. But it wasn’t to be…
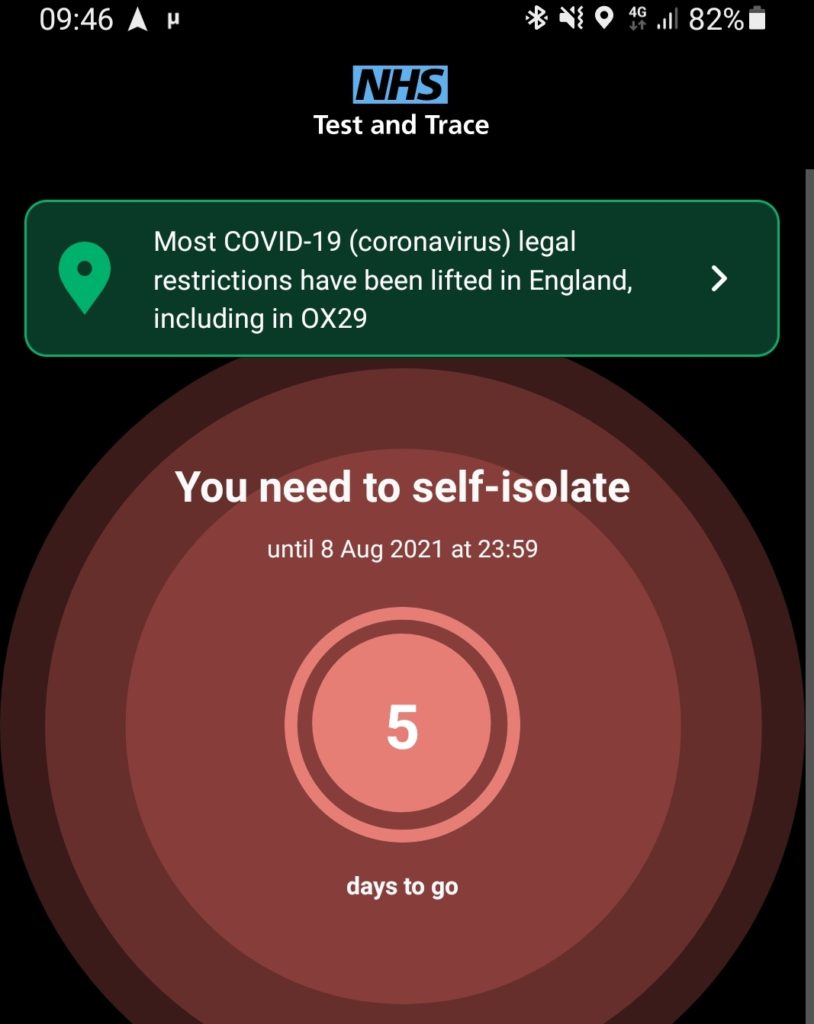
I got a “ping”. What that means is that my phone was in close proximity to somebody else’s phone on 29 August and that other person subsequently tested positive for COVID-19.
My risk from this contact is exceptionally low. There’s only one place that my phone was in close proximity to the phone of anybody else outside of my immediate family, that day, and it’s when I left it in a locker at the swimming pool near our cabin in the Darwin Forest. Also, of course, I’d been double-jabbed for a month and a half and I’m more-cautious than most about contact, distance, mask usage etc. But my family are, for their own (good) reasons, more-cautious still, so self-isolating at Preston didn’t look like a possibility for us.

As soon as I got the notification we redirected to the nearest testing facility and both got swabs done. 8 days after possible exposure we ought to have a detectable viral load, if we’ve been infected. But, of course, the tests take a day or so to process, so we still needed to do a socially-distanced pickup of the kids and all their stuff from Preston and turn tail for Oxfordshire immediately, cutting our trip short.
The results would turn up negative, and subsequent tests would confirm that the “ping” was a false positive. And in an ironic twist, heading straight home actually put us closer to an actual COVID case as Ruth’s brother Owen turned out to have contracted the bug at almost exactly the same time and had, while we’d been travelling down the motorway, been working on isolating himself in an annex of the “North wing” of our house for the duration of his quarantine.

7. Ruth & JTA go to Berwick
Thanks to negative tests and quick action in quarantining Owen, Ruth and JTA were still able to undertake the next part of this three-week holiday period and take their anniversary break (which technically should be later in the year, but who knows what the situation will be by then?) to Berwick-upon-Tweed. That’s their story to tell, if they want to, but the kids and I had fun in their absence:


















8. Reunited again
Finally, Ruth and JTA returned from their mini-break and we got to do a few things together as a family again before our extended holiday drew to a close:





























9. Back to work?
Tomorrow I’m back at work, and after 23 days “off” I’m honestly not sure I remember what I do for a living any more. Something to do with the Internet, right? Maybe ecommerce?
I’m sure it’ll all come right back to me, at least by the time I’ve read through all the messages and notifications that doubtless await me (I’ve been especially good at the discipline, this break, of not looking at work notifications while I’ve been on holiday; I’m pretty proud of myself.)
But looking back, it’s been a hell of a three weeks. After a year and a half of being pretty-well confined to one place, doing a “grand tour” of so many destinations as a family and getting to do so many new and exciting things has made the break feel even longer than it was. It seems like it must have been months since I last had a Zoom meeting with a work colleague!
For now, though, it’s time to try to get the old brain back into work mode and get back to making the Web a better place!