Today, while I cooked dinner, I introduced my two children (aged 10 and 8) to Goat Simulator.
Within half an hour, they’d added an imaginative twist and a role-playing element. My eldest had decreed themselves Angel of Goats and the younger Goat Devil and the two were locked in
an endless battle to control the holy land at the top of a rollercoaster.
The shrieks of joy and surprise from the living room could be heard throughout the entire house. Perhaps our whole village.
“We completely redesigned this thing you need to do your job for no good reason” Got it.
“Disable any adblocker.” Absolutely not.
…
I don’t know if I’m supposed to read this as a poem, but I did, and I love it. It speaks to me. It speaks of my experience of using (way too much of) the Web nowadays, enshittified as
it is.
But yeah, I run a fine-tuned setup on most of my computers that works for me… by working against most of the way the Web seems to expect me to use it, these days. I block all
third-party JavaScript and cookies by default (and drops first-party cookies extremely quickly). I use plugins to quietly reject consent banners, suppress soft paywalls, and so on. And
when I come across sites that don’t work that way, I make a case-by-case decision on whether to use them at all (if you hide some features in your “app” only, I just don’t use
those features).
Sure, there are probably half a dozen websites that you might use that I can’t. But in exchange I use a Web that’s fast, clean, and easy-to-read.
And just sometimes: when I’m on somebody else’s computer and I see an ad, or a cookie consent banner, or a “log in to keep reading” message, or a website weighed down and crawling
because of the dozens of tracking scripts, or similar… I’m surprised to remember that these things actually exist, and wonder for a moment how people who do see them
all time time cope with them!
Sigh.
Anyway: this was an excellent poem, assuming it was supposed to be interpreted as being a poem. Otherwise, it was an
excellent whatever-it-is.
Even when you’re not remotely ready to think about Christmas yet and yet it keeps getting closer every second.
Even when the house is an absolute shambles and trying to rectify that is one step forward/one step sideways/three steps back/now put your hands on your hips and wait, what was I
supposed to be tidying again?
Even when the electricity keeps yo-yoing every few minutes as the country continues to be battered by a storm.
Even when you spent most of the evening in the hospital with your injured child and then most of the night habitually getting up just to reassure yourself he’s still breathing (he’s
fine, by the way!).
Even then, there’s still the comfort of a bacon sarnie for breakfast. 😋
Here in Oxfordshire we’re nowhere near the epicentre of Storm Darragh, but we’re still feeling the effects. A huge tree came down and blocked the Thorney Leys road in Witney near
Burwell Meadow and the kids and I needed to take an ad-hoc diversion.
🤞 Fingers crossed for all my friends and family in worse-hit places!
the world needs more recreational programming.
like, was this the most optimal or elegant way to code this?
no, but it was the most fun to write.
Yes. This.
As Baz Luhrmann didn’t say, despite the implications of this video: code one thing every day that amuses you.
There is no greater way to protest the monetisation of the Web, the descent into surveillance capitalism, and the monoculture of centralised social media silos… than to create things
just for the hell of it. Maybe that’s Kirby eating a blog post. Maybe that’s whatever slippy stuff Lu put out this week. Maybe it’s a podcast exclusively about random things that interest one person.
The pre-corporate Web was fun and weird. Nowadays, keeping the Internet fun and weird is relegated to a
counterculture.
But making things (whether code, or writing, or videos, or whatever) “just because” is a critical part of that counterculture. It’s beautiful art flying in the face of rampant
commercialism. The Web provides a platform where you can share what you create: it doesn’t have to be good, or original, or world-changing… there’s value in just creating and giving
things away.
Today is International Volunteer Day. And because I’m in the middle of my (magical) sabbatical, I’ve had no difficulty dedicating what would have been the entire workday to a variety
of volunteer activities for the benefit of Three Rings, the nonprofit I founded 22 years ago for the purpose of making volunteer management,
and therefore volunteering, easier.
Liveblogging my day
Step one in a highly productive day of tech volunteering is, as you might have expected: coffee.
I’m pretty sure that most folks don’t know what my voluntary work at Three Rings involves1,
and so I decided I’d celebrate this year’s International Volunteer Day by live-blogging what I got up to in a series of notes throughout the day (1, 2, 3, 4, 5, 6, 7, 8)2.
Maybe, I figured, doing so might provide more of an insight into what a developer/devops role at Three Rings looks like.
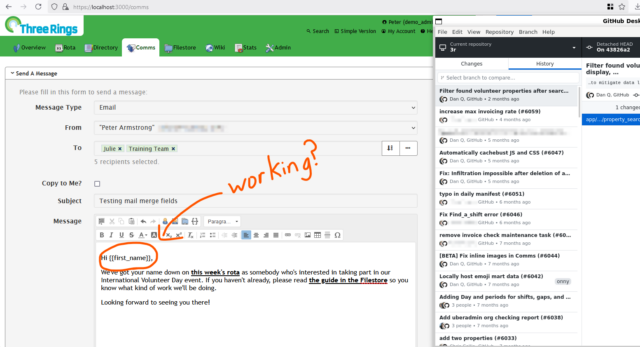
Regression-testing a fix
My first task for the day related to a bugfix that we’re looking to deploy. Right now, there’s a problem which sometimes stops the “mail merge”
fields in emails sent by Three Rings3.
We have a candidate fix, but because it’s proposed as a hotfix (i.e. for deployment directly to production), it requires a more-thorough review process involving more volunteer
developers than code which will be made available for beta testing first.
My aim with this task was to roll-back to an earlier version of the software, before the bug was first introduced (by fixing something different!), and ensure that the functionality
remained the same as it always had been.
It turned out that everything was alright, so I reported back to my fellow reviewers about how I’d tested and what my results had been. Once some
more eyes have hit the tests and the new/changed code, that’ll hopefully be ready-to-launch.
Three Rings volunteers primarily communicate via Slack: it helps us to work asynchronously, which supports the fact that our volunteers all have different schedules and preferences
for how they plan their volunteering: some spend whole days, some just a few hours now and then. We’re the ultimate “armchair volunteering” opportunity!
We’re all about collaboration, discussion, learning from one another, and volunteer-empowerment, so my suggestions in this case were non-blocking: I trust my fellow volunteer to
either accept my suggestion (if it’s right), reject it (if it’s wrong), or solicit more reviews or bring it to Slack or our fortnightly dev meeting (if it requires discussion).
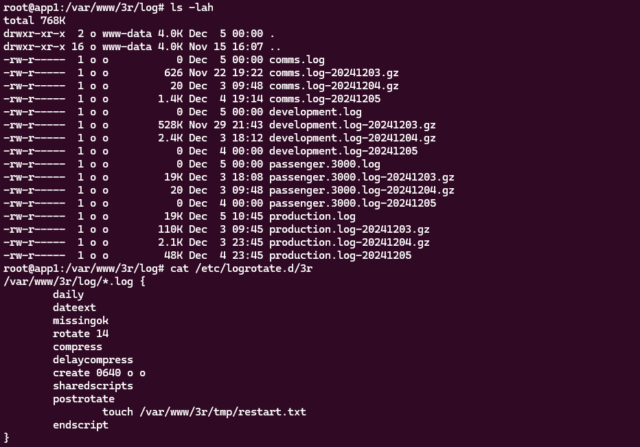
Preparing new infrastructure
Next week we’re scheduled to do a big migration of server infrastructure to help provide more future growing-room: it’s exciting, but also a little scary4!
For now, though, all I needed to do was to tweak our logrotate and backup configurations in response to testing of our new systems.
Not all of our developer volunteers also wear a “devops” hat, but a few of us do5.
It’s quite a satisfying role – devops can feel like tidying and organising, and just as a physical space can feel clean, simple, and functional when it’s carefully and minimalistically
laid out, a well-organised cluster of servers humming along in exactly the way they should can be a highly-satisfying thing to be responsible for, too.
Sorting the post
It’s not all techy work, though. And while it’s true that Three Rings has a good group of less-nerdy6 people to handle many of the non-programming tasks that you need
to run a voluntary organisation like ours, it’s also true that many of us wear multiple hats and pull our weight in several different roles.
Our time as volunteers may be free, but our servers aren’t, so the larger and richer charities that use our services help contribute to our hosting costs. Most send money digitally,
but some use dual-signatory accounts that require they send cheques.
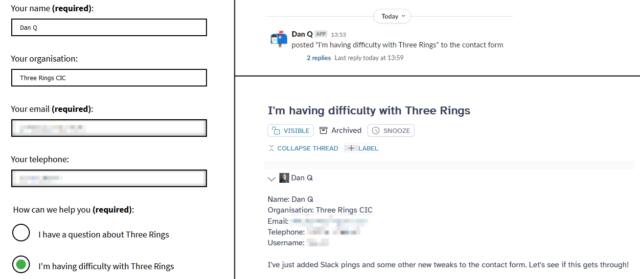
When people are stuck with Three Rings, or considering using it, or have feature suggestions, or anything else, we encourage them to fill in our contact form. The results of that make their way into our ticketing system where Support Team volunteers help people with whatever it is
they need7.
They asked if they could have a Slack notification when the form was filled, to grab their attention all the quicker if they were already online, so I obliged and added one.
Adding the Slack notifications meant writing some WordPress PHP code, which feels closer to my “day job” than my Three Rings volunteering!
That quick improvement done, it was time to move on to a task both bigger and more-exciting:
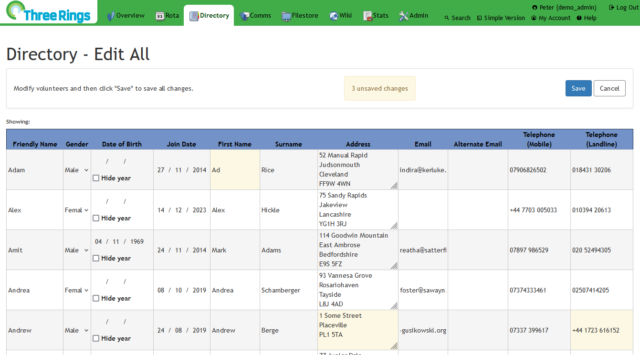
Wrapping up a new feature
I’ve recently been working on an upcoming new feature for Three Rings. Inspired by only occasional user requests, this idea’s been sitting in our (long!) backlog for a while
now8:
a way to edit the details of volunteers in your organisation in bulk, as though they were in a spreadsheet.
The feature’s been almost-complete for weeks now, but I had a few last tweaks to make, based on early feedback and show-and-tell sessions.
I’ve been working on this feature by a series of iterations since the end of October, periodically demonstrating it to other Three Rings volunteers and getting early feedback. In the
last round of demonstrations (plus a little user testing, at an in-person Three Rings event) I solicited opinions on how the new feature should be presented, and who it should be made
available to9.
So this afternoon I was working on bits of the user interface and, delightfully, got the feature to a point where I only need to update the test instructions and it’ll be ready for a
full review and consideration for inclusion in our next milestone release, early next year. Hurrah!
It’s only a draft PR for now, but at least the initial checks look positive.
Reflecting on my day
I don’t normally get this much Three Rings work done in a day. Even since my sabbatical started, I don’t always get so productive a day10,
and when I’m working normally I’d probably only get maybe one or two of these achievements done in a typical week.
So I’m hugely appreciative that my employer encourages staff to take a three-month sabbatical every five years. Because it
gives me the opportunity have days like this International Volunteer Day, where I can spend the whole day throwing myself headlong at some valuable volunteering efforts and come out the
other side with the satisfaction that I gave my time to make the world a very slightly better place.
If you’re not already volunteering somewhere, I’d highly recommend that you consider it. Volunteering can be purposeful, enriching, and hugely satisfying. Happy International Volunteer
Day!
Footnotes
1 In fact, most of the charities who use Three Rings’ services are surprised to discover
that we’re a voluntary organisation at all, because we provide the kinds of uptime guarantee, tech support response times, software quality etc. that they might have come to
expect from much-richer organisations with a much larger – and paid! – staff. That we’re a voluntary organisation helping voluntary organisations is so unusual that sometimes people
have been unsure how to handle us: one time, for example, a helpline charity that was considering making use of us declared us “unsustainable” without a commercial model. At some
point in the last decade or two they saw that we’ve outlasted many other services of our type, most of them commercial, and realised: yeah, okay, it turns out we’re in this for the
long haul.
2 Gosh: a nine-post day is gonna keep throwing the stats of my recent streak all over the place, isn’t it?
3 My use of italics for Three Rings isn’t arbitrary, but I’ll admit it is
confusing. “Three Rings” is the name of our nonprofit. “Three Rings” is the name of the software service we provide. Branding is hard when your company name and product name
are the same. And it’s even harder when all of your users insist on abbreviating both to “3R”. 🙄
4 With around 60,000 volunteers depending on Three Rings to coordinate their
efforts, the pressure is always on to minimise downtime. I’ve spent many hours over the last few weeks running and re-running through practice runs of the migration strategy before I
take the lead on it next week.
5 That said, one of the big things I’ve been pushing for in our new infrastructure is new
tools to make it easier for our developers to do “server stuff” like deploying new releases, in an effort to bring us closer to the dream of a continuous integration pipeline. Some
day!
6 Or “normal people”, as they might call themselves.
7 The Support Team are a wonderful and hard-working group of volunteers, who aim to reply
to every contact within 24 hours, 365 days a year, and often manage a lot faster than that. They’re at the front-line of what makes Three Rings a brilliant
system.
8 While we curate a backlog of user requests and prioritise them based on the optimisation
ratio of amount-of-good-done to the amount-of-effort-expected, our developer volunteers enjoy a huge amount of autonomy about what tasks they choose to pick up. It’s not unknown for
developers who also volunteer at other organisations (that might be users of Three Rings) to spend a disproportionate amount of time on features that their
organisation would benefit from, and that’s fine… so long as the new feature will also benefit at least a large minority of the other organisations that depend on
Three Rings. Also, crucially: we try to ensure that new features never inconvenience existing users and the ways in which they work. That’s increasingly challenging in our
22-year-old software tool, but it’s important to us that we’re not like your favourite eCommerce or social networking service that dramatically change their user interface every other
year or drop features without warning nor consideration for who might depend upon them.
9 The new feature’s secured such that it works for everybody: if you accessed it
as a volunteer with low privileges, you might be able to see virtually nothing about most of the other volunteers and be able to edit only a few details about yourself, for example.
But that’d be a pretty-confusing interface, so we concluded that it probably didn’t need to be made available to all volunteers but only those with certain levels of
access. We can always revisit later.
For my final bit of Three Rings volunteering this International Volunteer Day, I’m working on improving the UI of a new upcoming feature: a spreadsheet-like page that makes it easy for
administrators to edit the details of many volunteers simultaneously (all backed by the usual level of customisation and view/edit permissions that Three Rings is known for).
It’s a moderately-popular request, and I can see it being helpful to volunteer coordinators at many different types of voluntary organisation.
Don’t have time to write up the test instructions today, though, because I’ve got to wrap up my volunteering and go do some childwrangling, so that’ll do for now!
Even when it’s technical, not all of my International Volunteer Day work for Three Rings has been spent using our key technologies (LNMR [Linux, Nginx, MariaDB, Ruby] stacks).
Today, I wrote some extra PHP for our WordPress-powered contact form to notify our Support Team volunteers via Slack when messages are sent. We already aim to respond to every message
within 24 hours, 365 days a year, and are often faster than that… but this might help us to be even more-responsive to the needs of the charities who we help look after.
My Three Rings volunteering this International Volunteer Day isn’t all technical work. It’s also time to process the incoming postal mail.
Our time as volunteers may be free, but our servers aren’t, so the larger and richer charities that use our services help contribute to our hosting costs. Most send money digitally, but
some use dual-signatory accounts that require they send cheques.
As well as the programming tasks I’m working on for Three Rings this International Volunteer Day, I’m also doing a little devops. We’ve got a new server architecture rolling out next
week, and I’m tasked with ensuring that the logging on them meets our security standards.
Each server’s on-device logs are retained in date-stamped files for 14 days, but they’re also backed-up offsite daily.
Those bits all seem to be working, so next I need to work out a way to add a notification to our monitoring platform if any server doesn’t successfully push a log to the offsite backup
in a timely manner.
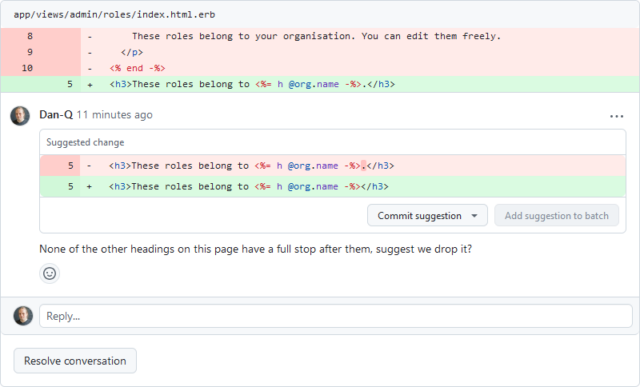
Not every code review is fireworks, but most Three Rings changes come from the actual needs of the voluntary organisations that Three Rings supports. Some of our users were confused by
the way the Admin > Roles page was laid out, so one of our volunteers wrote an improved version.
And because we’re all about collaboration, discussion, learning from one another, and volunteer-empowerment… I’ve added a minor suggestion… but approved their change “with or without”
it. I trust my fellow volunteer to either accept my suggestion (if it’s right), reject it (if it’s wrong), or solicit more reviews or bring it to Slack or our fortnightly dev meeting
(if it requires discussion).
Good news! It turns out that the new code to fix the mail merge fields in Three Rings doesn’t introduce an inconsistency with established behaviour. It was important to check, but it
turns out all is well.
I touched bases with a fellow volunteer on Slack. Three Rings volunteers primarily communicate via Slack: it helps us to work asynchronously, which supports the fact that our volunteers
all have different schedules and preferences. Some might do a couple of evenings a week, others might do the odd weekend, others still might do an occasional intense solid week of
volunteering with us and then nothing for months! A communication model that works both synchronously and asynchronously is really important to make that volunteering model work, and
Slack fits the bill.
We get together in person sometimes, and we meet on Zoom from time to time too, but Slack is king of communication at Three Rings
My first task this International Volunteer Day is to test a pull request that aims to fix a bug with Three Rings’ mail merge fields functionality. As it’s planned to be a hotfix (direct
into production) we require extra rigor and more reviewers than code that just goes into the main branch for later testing on our beta environment.
My concern is that fixing this bug might lead to a regression not described by our automated tests, so I’m rolling back to a version from a couple of months ago to compare the behaviour
of the affected tool then and now. Sometimes you just need some hands-on testing!
As I’m on sabbatical, I’m in the lucky position of being able to spend most of the day on a volunteer project very close to my heart: Three
Rings. Three Rings is a 22-year-old web-based service produced by volunteers, for volunteers. The software service we produce supports the efforts of around 60,000 volunteers
working at charities and other voluntary organisations around the globe.
I’ll be posting throughout the day about some of the different tasks I take on. My volunteer role with Three Rings is primarily a developer/devops one, but it takes all sorts to make a
project like this work (even if my posts look biased towards the technical stuff)!
“I was sincere! I wanted to tell you happy Birthday but I wanted to have AI do it.”
“Why?” I shot back, instantly annoyed.
“Because I didn’t know how to make it lengthy. Plus, it’s just easier.”
I felt as if I’d been punched in the gut. I just sat there, stunned. The last sentence repeating itself in my head.
It’s just easier. It’s just easier. It’s. Just. Easier.
…
Robert shares his experience of receiving a birthday greeting from a friend, that had clearly been written by an AI. The friend’s justification was because they’d wanted to make the
message longer, more easily. But the end result was a sour taste in the recipient’s mouth.
There’s a few things wrong here. First is the assumption by the greeting’s author (and perhaps a reflection on society in general) that a longer message automatically implies more care
and consideration than a shorter one. But that isn’t necessarily true (and it certainly doesn’t extend to artificially stretching a message, like you’re being paid by the word
or something).
A second problem was falling back on the AI for this task in the first place. If you want to tell somebody you’re thinking of them, tell somebody you’re thinking of them. Putting an LLM
between you and then introduces an immediate barrier: like telling your personal assistant to tell your friend that you’re thinking of them. It weakens the connection.
And by way of a slippery slope, you can imagine (and the technology has absolutely been there for some time now) a way of hooking up your calendar so that an AI would
automatically send a birthday greeting to each of your friends, when their special day comes around, perhaps making reference to the last thing they wrote online or the last
message they sent to you, by way of personalisation. By which point: why bother having friends at all? Just stick with the AI, right? It’s just easier.
Ugh.
Needless to say: like Robert, I’d far rather you just said a simple “happy birthday” than asked a machine to write me a longer, more seemingly-thoughtful message. I care more about
humans than about words.