Microsoft engineers have been spotted committing code to Chromium, the backend of Google Chrome and many other web browsers. This, among other things, has lead to speculation that Microsoft’s browser, Edge, might be planned to switch from its current rendering engine (EdgeHTML) to Blink (Chromium’s). This is bad news.
The younger generation of web developers are likely to hail this as good news: one fewer engine to develop for and test in, they’re all already using Chrome or something similar (and certainly not Edge) for development and debugging anyway, etc. The problem comes perhaps because they’re too young to remember the First Browser War and its aftermath. Let me summarise:
-
Once upon a time – let’s call it the mid-1990s – there were several web browsers: Netscape Navigator, Internet Explorer, Opera, etc. They all used different rendering
engines and so development was sometimes a bit of a pain, but only if you wanted to use the latest most cutting-edge features: if you were happy with the standard, established
features of the Web then your site would work anywhere, as has always been the case.

-
Then, everybody starting using just one browser: following some shady dealings and monopoly abuse, 90%+ of Web users started using just one web browser, Internet Explorer. By the time anybody took
notice, their rivals had been economically crippled beyond any reasonable chance of recovery, but the worst had yet to come…

-
Developers started targeting only that one browser: instead of making websites, developers started making “Internet Explorer sites” which were only tested in that one
browser or, worse yet, only worked at all in that browser, actively undermining the Web’s position as an open platform. As the grip of the monopoly grew tighter,
technological innovation was centred around this single platform, leading to decade-long knock-on
effects.

-
The Web ceased to grow new features: from the release of Internet Explorer 6 there were no significant developments in the technology of the Web for many years.
The lack of competition pushed us into a period of stagnation. A
decade and a half later, we’re only just (finally) finishing shaking off this unpleasant bit of our history.

History looks set to repeat itself. Substitute Chrome in place of Internet Explorer and update the references to other web browsers and the steps above could be our future history, too. Right now, we’re somewhere in or around step #2 – Chrome is the dominant browser – and we’re starting to see the beginnings of step #3: more and more “Chrome only” sites. More-alarmingly this time around, Google’s position in providing many major Web services allows them to “push” even harder for this kind of change, even just subtly: if you make the switch from Chrome to e.g. Firefox (and you absolutely should) you might find that YouTube runs slower for you because YouTube’s (Google) engineers favour Google’s web browser.
Chrome is becoming the new Internet Explorer 6, and that’s a huge problem. Rachel Nabors wrote in her excellent article The Ecological Impact of Browser Diversity:
So these are the three browser engines we have: WebKit/Blink, Gecko, and EdgeHTML. We are unlikely to get any brand new bloodlines in the foreseeable future. This is it.
If we lose one of those browser engines, we lose its lineage, every permutation of that engine that would follow, and the unique takes on the Web it could allow for.
And it’s not likely to be replaced.
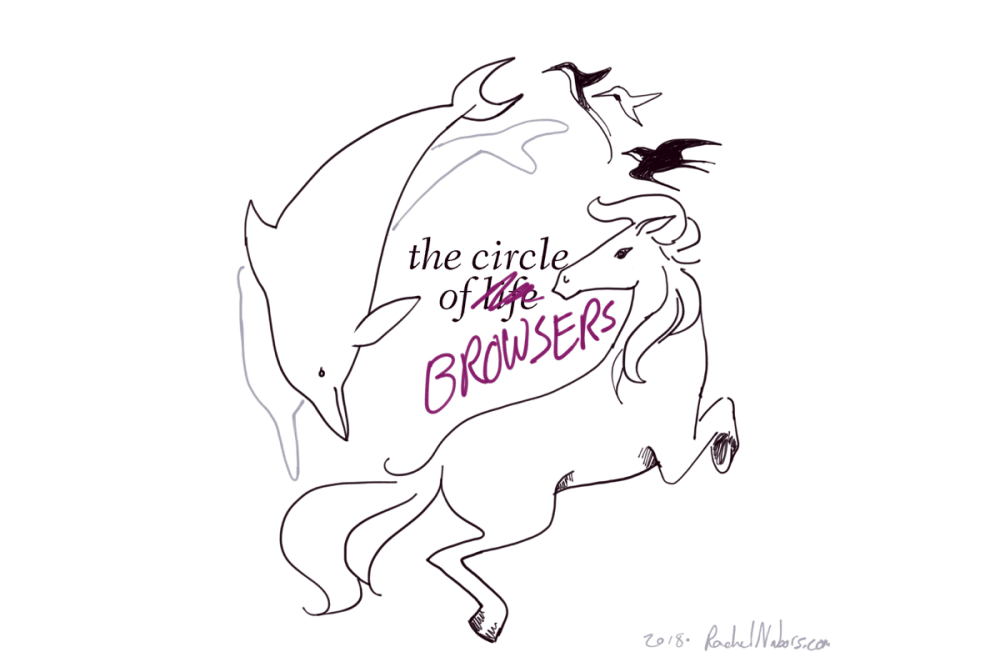
Imagine a planet populated only by hummingbirds, dolphins, and horses. Say all the dolphins died out. In the far, far future, hummingbirds or horses could evolve into something that could swim in the ocean like a dolphin. Indeed, ichthyosaurs in the era of dinosaurs looked much like dolphins. But that creature would be very different from a true dolphin: even ichthyosaurs never developed echolocation. We would wait a very long time (possibly forever) for a bloodline to evolve the traits we already have present in other bloodlines today. So, why is it ok to stand by or even encourage the extinction of one of these valuable, unique lineages?
We have already lost one.
We used to have four major rendering engines, but Opera halted development of its own rendering engine Presto before adopting Blink.
Three left. Spend them wisely.
As much as I don’t like having to work-around the quirks in all of the different browsers I test in, daily, it’s way preferable to a return to the dark days of the Web circa most of the first decade of this century. Please help keep browsers diverse: nobody wants to start seeing this shit –
![]()
Update: this is now confirmed. A sad day for the Web.





















{kind=link}