Different games in the same style (absurdle plays adversarially like my cheating hangman
game, crosswordle involves reverse-engineering a wordle colour grid into a crossword, heardle
is like Wordle but sounding out words using the IPA…)
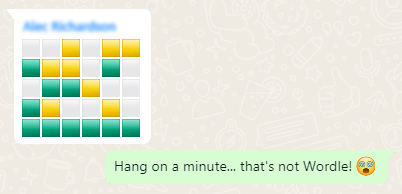
I’m sure that by now all your social feeds are full of people playing Wordle. But the cool nerds are playing something new…
Now, a Wordle clone for D&D players!
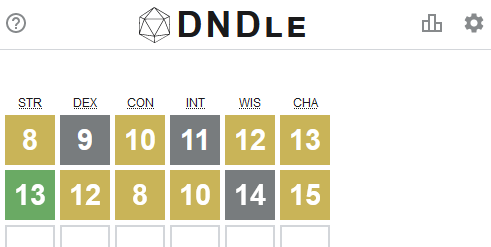
But you know what hasn’t been seen before today? A Wordle clone where you have to guess a creature from the Dungeons & Dragons (5e) Monster Manual by putting numeric values into a
character sheet (STR, DEX, CON, INT, WIS, CHA):
Just because nobody’s asking for a game doesn’t mean you shouldn’t make it anyway.
What are you waiting for: go give DNDle a try (I pronounce it “dindle”, but you can pronounce it however you like). A new monster
appears at 10:00 UTC each day.
And because it’s me, of course it’s open source and works offline.
The boring techy bit
Like Wordle, everything happens in your browser: this is a “backendless” web application.
I’ve used ReefJS for state management, because I wanted something I could throw together quickly but I didn’t want to drown myself (or my players)
in a heavyweight monster library. If you’ve not used Reef before, you should give it a go: it’s basically like React but a tenth of the footprint.
A cache-first/background-updating service worker means that it can run completely offline: you can install it to your homescreen in the
same way as Wordle, but once you’ve visited it once it can work indefinitely even if you never go online again.
I don’t like to use a buildchain that’s any more-complicated than is absolutely necessary, so the only development dependency is rollup. It
resolves my import statements and bundles a single JS file for the browser.
Of course, you don’t strictly need a digital wallet to use EGX. But as we’re in a culture where people invariably ask “is
there an app for it?”, I thought I’d make one.
You can install it as an offline-first progressive web application, which means that this could be the first ever digital currency to have an app that works without an Internet
connection. That’s probably something no other digital currency can claim to have, right?
Here’s what it looks like if I send 0.1 EGX to my friend Chris using the app:
Naturally, I wouldn’t be backing Emma Goldcoin if it didn’t represent such a brilliant step up better-known digital currencies like Bitcoin, Ripple, and Etherium. Specific features
unique to Emma Goldcoin include:
Using it doesn’t massively contribute to energy wastage and environmental damage.
It doesn’t increase the digital divide by helping early adopters at the expense of late adopters.
It’s entirely secure: it’s mathematically impossible to “steal”EGX.
Emma Goldcoin is so simple that you don’t even need a computer to use it: it “just works”.
Sure, it’s got its downsides, and I’d encourage you to read the specification if you’d like to learn more about what
those are. Or if you already know what EGX is all about and just want to try a new way to manage your portfolio, give my new site EGXchange.org a go!
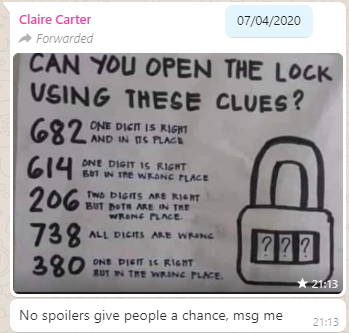
About three months ago, my friend Claire, in a WhatsApp group we both frequent, shared a brainteaser:
Was this way back at the beginning of April? Thank heavens for WhatsApp scrollback.
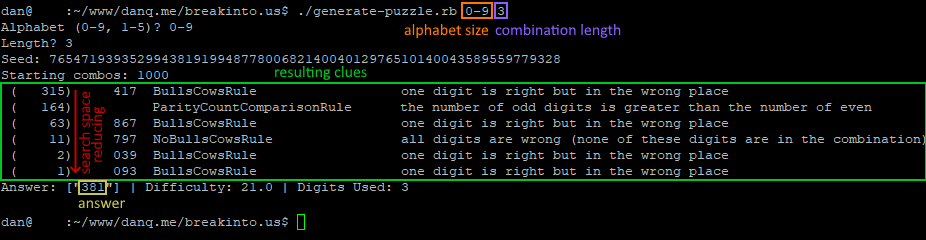
The puzzle was to be interpreted as follows: you have a three-digit combination lock with numbers 0-9; so 1,000 possible combinations in total. Bulls and Cows-style, a series of clues indicate how “close” each of several pre-established “guesses” are. In “bulls and
cows” nomenclature, a “bull” is a correctly-guessed digit in the correct location and a “cow” is a correctly-guessed digit in the wrong location, so the puzzle’s clues are:
682 – one bull
614 – one cow
206 – two cows
738 – no bulls, no cows
380 – one cow
Feel free to stop scrolling at this point and solve it for yourself. Or carry on; there are no spoilers in this post.
By the time I’d solved her puzzle the conventional way I was already interested in the possibility of implementing a general-case computerised solver for this kind of puzzle, so I did.
My solver uses a simple “brute force” technique, as follows:
Put all possible combinations into a search space.
For each clue, remove from the search space all invalid combinations.
Whatever combination is left is the correct answer.
The first three clues of Claire’s puzzle are sufficient alone to reduce the search space to a single answer, although a human is likely to need more.
Visualising the solver as a series of bisections of a search space got me thinking about something else: wouldn’t this be a perfectly reasonable way to programatically generate
puzzles of this type, too? Something like this:
Put all possible combinations into a search space.
Randomly generate a clue such that the search space is bisected (within given parameters to ensure that neither too many nor too few clues are needed)
Repeat until only one combination is left
Interestingly, this approach is almost the opposite of what a human would probably do. A human, tasked with creating a puzzle of this sort, would probably choose the answer
first and then come up with clues that describe it. Instead, though, my solution would come up with clues, apply them, and then see what’s left-over at the end.
Sometimes it comes up with inelegant or unchallenging suggestions, but for the most part my generator produces adequate puzzles.
I expanded my generator to go beyond simple bulls-or-cows clues: it’s also capable of generating clues that make reference to the balance of odd and even digits (in a numeric lock), the
number of different digits used in the combination, the sum of the digits of the combination, and whether or not the correct combination “ascends” or “descends”. I’ve ideas for
other possible clue types too, which could be valuable to make even tougher combination locks: e.g. specifying how many numbers in the combination are adjacent to a consecutive number,
specifying the types of number that the sum of the digits adds to (e.g. “the sum of the digits is a prime number”) and so on.
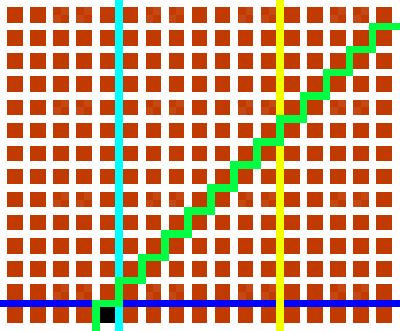
Like the original puzzle, puzzles produced by my generator might have redundancies. In the picture above, the black square can be defined by the light blue, dark blue, and green
bisections only: the yellow bisection is rendered redundant by the light blue one. I’ve left this as a deliberate feature.
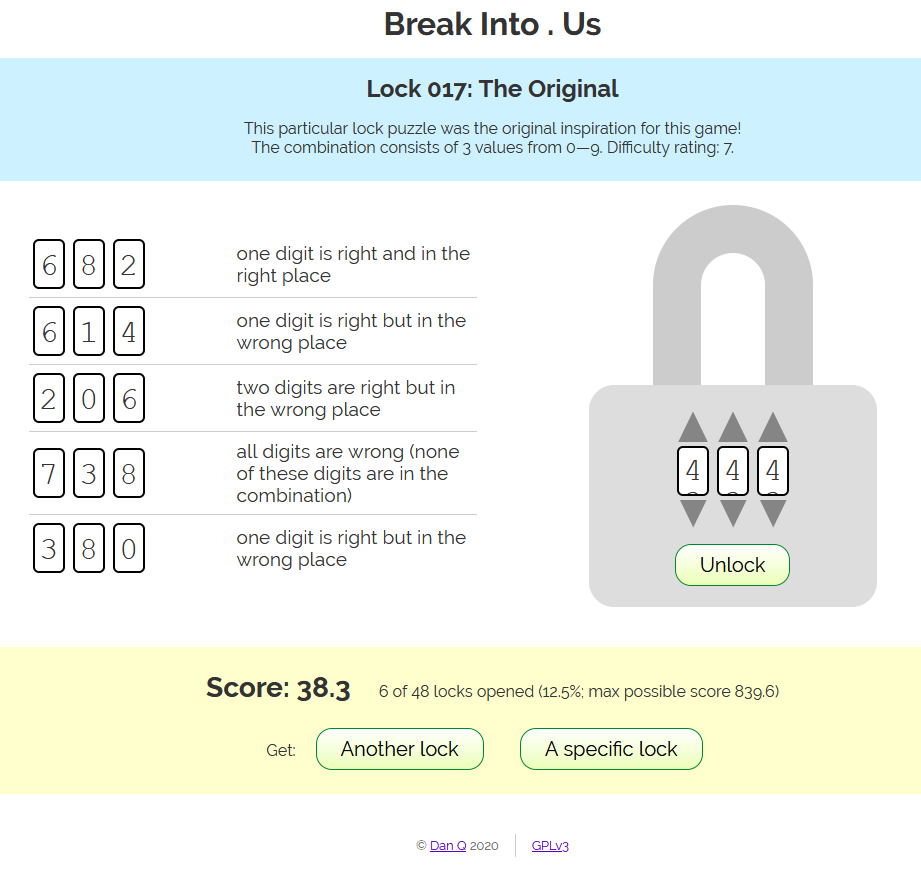
Next up, I wanted to make a based interface so that people could have a go at the puzzles in their web browser, track their progress through the levels, get a “score” based on the
number and difficulty of the locks that they’d cracked (so they can compare it to their friends), and save their progress to carry on next time.
I implemented in pure vanilla HTML, CSS, SVG and JS, with no dependencies. Compressed, it delivers to your browser and is ready-to-play in a little
under 10kB, most of which is the puzzles themselves (which are pregenerated and stored in a JSON file). Naturally, it lends itself well to running offline, so it’s PWA-enhanced with a
service worker so it can be “installed” onto your device, too, and it’ll check for bonus puzzles and other updates periodically.
Naturally, the original puzzle appears in the web-based game, too.
Honestly, the hardest bit of implementing the frontend was the “spinnable” digits: depending on your browser, these are an endless-scrolling <ul> implemented mostly in
CSS and with snap points set, and then some JS to work out “what you meant” based on
where you span to. Which feels like the right way to implement such a thing, but was a lot more work than putting together my own control, not least because of browser
inconsistencies in the implementation of snap points.
Anyway: you should go and play the game, now, and let me know what you think. Is it worth expanding and improving? Should I leave it as it is? I’m
open to ideas (and if you don’t like that I’m not implementing your suggestions, you can always fork a copy of the code and change
it yourself)!
Block all third-party cookies, yes, by all means1. But deleting all local storage (including Indexed DB, etc.) after 7 days effectively blocks any future decentralised apps using the browser (client side)
as a trusted replication node in a peer-to-peer network. And that’s a huge blow to the future of privacy.
…
Like Aral and doubtless many others, I was initially delighted to see that Safari has beaten Chrome to the punch, blocking basically all third-party cookies through its
Intelligent Tracking Protection. I don’t even routinely use Safari (although I do block virtually all third-party and many first-party cookies using uMatrix for Firefox), but I loved this announcement because I knew that this, coupled with Google’s promise to (eventually)
do the same in their browser, would make a significant impact on the profitability of surveillance capitalism on the Web. Hurrah!
But as Aral goes on to point out, Apple’s latest changes also effectively undermines the capability of people to make Progressive Web Applications that run completely-offline, because their new privacy features delete the cache of all
offline storage if it’s not accessed for 7 days.
PWAs have had a bumpy ride. They were brought to the foreground by Apple in the first place when Steve Jobs suggested that
something-like-this would be the way that apps should one day be delivered to the iPhone, but then that idea got sidelined by the App Store. In recent years, we’ve begun to see the
concept take off again as Chrome, Firefox and Edge gradually added support for service workers (allowing offline-first), larger local storage, new JavaScript interfaces for e.g.
cameras, position, accelerometers, and Bluetooth, and other PWA-ready technologies. And for a while I thought that the day
of the PWA might be drawing near… but it looks like we might have to wait a bit longer.
I hope that Google doesn’t follow Apple’s lead on this particular “privacy” point, although I’m sure that it’s tempting for them to do so. Offline Web applications have the potential to
provide an open, simple, and secure ecosystem for the “apps” of tomorrow, and after several good steps forwards… this week we took a big step back.
As I’ve previously mentioned (sadly), Microsoft Edge is to drop its own rendering engine EdgeHTML and replace it with Blink, Google’s one (more
of my and others related sadness here, here, here, and here). Earlier this month, Microsoft made available the first prerelease versions of the browser, and I gave it a go.
At a glance, it looks exactly like you’d expect a Microsoft reskin of Chrome to look, right down to the harmonised version numbers.
All of the Chrome-like features you’d expect are there, including support for Chrome plugins, but Microsoft have also clearly worked to try to integrate as much as possible of the
important features that they felt were distinct to Edge in there, too. For example, Edge Blink supports SmartScreen filtering and uses Microsoft accounts for sync, and Incognito is of
course rebranded InPrivate.
But what really interested me was the approach that Edge Dev has taken with Progressive Web Apps.
NonStopHammerTi.me might not be the best PWA in the world, but it’s the best one linked from this blog post.
Edge Dev may go further than any other mainstream browser in its efforts to make Progressive Web Apps visible to the user, putting a plus sign (and sometimes an extended
install prompt) right in the address bar, rather than burying it deep in a menu. Once installed, Edge PWAs “just work” in
exactly the way that PWAs ought to, providing a simple and powerful user experience. Unlike some browsers, which
make installing PWAs on mobile devices far easier than on desktops, presumably in a misguided belief in the importance of
mobile “app culture”, it doesn’t discriminate against desktop users. It’s a slick and simple user experience all over.
Once installed, Edge immediately runs your new app (closing the tab it formerly occupied) and adds shortcut icons.
Feature support is stronger than it is for Progressive Web Apps delivered as standalone apps via the Windows Store, too, with the engine not falling over at the first sign of a modal
dialog for example. Hopefully (as I support one of these hybrid apps!) these too will begin to be handled properly when Edge Dev eventually achieves mainstream availability.
If you’ve got the “app” version installed, Edge provides a menu option to switch to that from any page on the conventional site (and cookies/state is retained across both).
But perhaps most-impressive is Edge Dev’s respect for the importance of URLs. If, having installed the progressive “app”
version of a site you subsequently revisit any address within its scope, you can switch to the app version via a link in the menu. I’d rather have seen a nudge in the address bar, where
the user might expect to see such things (based on that being where the original install icon was), but this is still a great feature… especially given that cookies and other
state maintainers are shared between the browser, meaning that performing such a switch in a properly-made application will result in the user carrying on from almost exactly where they
left off.
Unlike virtually every other PWA engine, Edge Dev’s provides a “Copy URL” feature even to apps without address bars, which is a killer feature for sharability.
Similarly, and also uncommonly forward-thinking, Progressive Web Apps installed as standalone applications from Edge Dev enjoy a “copy URL” option in their menu, even if the app runs without an address bar (e.g. as a result of a "display": "standalone" directive
in the manifest.json). This is a huge boost to sharability and is enormously (and unusually) respectful of the fact that addresses are the
Web’s killer feature! Furthermore, it respects the users’ choice to operate their “apps” in whatever way suits them best: in a browser (even a competing browser!), on their
mobile device, or wherever. Well done, Microsoft!
I’m still very sad overall that Edge is becoming part of the Chromium family of browsers. But if the silver lining is that we get a pioneering and powerful new Progressive Web App
engine then it can’t be all bad, can it?
tl;dr: TRRTL.COM is my reimplementation of a Logo on-screen turtle as a CoffeeScript-backed web application
For many children growing up in the 1970s and 1980s, their first exposure to computer programming may have come in the form of Logo, a general-purpose educational programming language best-known for its “turtle graphics” capabilities. By issuing
commands to an on-screen – or, if they were really lucky, robotic – cursor known as a turtle, the student could draw lines and curves all over the screen (or in the case of
robotic turtles: a large sheet of paper on the floor).
Back in the day, screens were monochrome and turtles were wired. What a way to live.
While our eldest and I were experimenting with programming (because, well…) a small robotic toy of hers, inspired by a book, it occurred to me that this was an experience that she might miss out on. That’s fine, of course: she doesn’t have to find the same joy
in playing with Logo on an Amstrad CPC or a BBC Micro that I did… but I’d like her to be able to have the option. In fact, I figured, there’s probably a whole generation of folks who
played with Logo in their childhood but haven’t really had the opportunity to use something as an adult that gives the same kind of satisfaction. And that’s the kind of thing I can fix.
Don’t interrupt a programmer when she’s “in the flow”.
TRRTL.COM is my attempt to produce a modern, web-based (progressive,
offline-first) re-imagining of Logo. It uses CoffeeScript as its base language because it provides all of the power of JavaScript but supports a
syntax that’s more-similar to that of traditional Logo implementations (with e.g. optional semicolons and unparenthesised parameters).
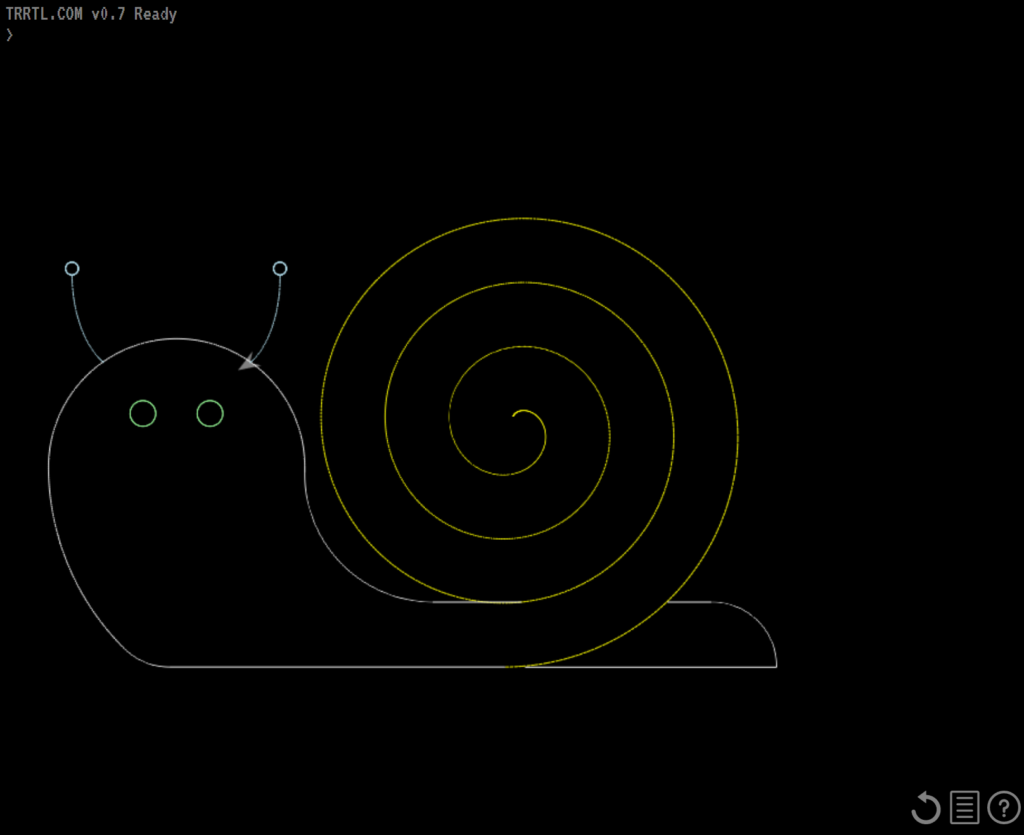
Turtles can be surprisingly fast. Snails, less-so.
If you’ve not used Logo before, give it a go. Try typing simple commands like forward 100 (steps), right 90 (degrees), and so
on and you’ll find it’s a bit like an etch-a-sketch. Click the “help” icon in the corner for more commands (and shorter forms of them) as well as instructions on writing longer programs
and sharing your work with the world.
Users can share their creations with the world, and then optionally expand upon them. Click the image to carry on where I left off, here.
And of course the whole thing is open source in the most permissive way imaginable, so if you’re of an
inclination to do your own experiments with <canvas>, Progressive Web Apps, and the like, you’re welcome to borrow from me. Or if anybody wants to tag-team on making
a version that uses the Web Bluetooth API to talk to a robotic turtle or to use WebRTC to make LAN “multiplayer” turtle art, I’m totally game for that.
My volunteering and academic workload for the rest of this year is likely to reduce the amount of random/weird stuff I put online, so it might get boring here for a while. Hope this
tides you over in the meantime.
If you look closely, you’ll find I’ve shown you a sneak-peek at some of what’s behind tomorrow’s door. Shh. Don’t tell our social media officer.
As each door is opened, a different part of a (distinctly-Bodleian/Oxford) winter scene unfolds, complete with an array of fascinating characters connected to the history, tradition,
mythology and literature of the area. It’s pretty cool, and you should give it a go.
If you want to make one of your own – for next year, presumably, unless you’ve an inclination to count-down in this fashion to something else that you’re celebrating 25 days
hence – I’ve shared a version of the code that you can adapt for yourself.
The open-source version doesn’t include the beautiful picture that the Bodleian’s does, so you’ll have to supply your own.
Features that make this implementation a good starting point if you want to make your own digital advent calendar include:
Secure: your server’s clock dictates which doors are eligible to be opened, and only content legitimately visible on a given date can be obtained (no path-traversal,
URL-guessing, or traffic inspection holes).
Responsive: calendar adapts all the way down to tiny mobiles and all the way up to 4K fullscreen along with optimised images for key resolutions.
Friendly: accepts clicks and touches, uses cookies to remember the current state so you don’t have to re-open doors you opened yesterday (unless you forgot to open
one yesterday), “just works”.
Debuggable: a password-protected debug mode makes it easy for you to test, even on a production server, without exposing the secret messages behind each door.
Expandable: lots of scope for the future, e.g. a progressive web app version that you can keep “on you” and which notifies you when a new door’s ready to be opened,
was one of the things I’d hoped to add in time for this year but didn’t quite get around to.
But on the second day, Sebastiaan spent a fair bit of time investigating a more complex use of service workers with the Push API.
…
While I’m very unwilling to grant permission to be interrupted by intrusive notifications, I’d be more than willing to grant permission to allow a website to silently cache timely
content in the background. It would be a more calm technology.
…
Then when I’m on a plane, or in the subway, or in any other situation without a network connection, I could still visit these websites and get content that’s fresh to me. It’s kind of
like background sync in reverse.
…
Yes, yes, yes.The Push API’s got incredible potential for precaching, or even re-caching existing content. How about if you could always instantly open my web site,
whether you were on or off-line, and know that you’d always be able to read the front page and most-recent articles. You should be able to opt-in to “hot” push notifications if that’s
what you really want, but there should be no requirement to do so.
By the time you’re using the Push API for things like this, why not go a step further? How about PWA feed readers or email clients that use web-pushes to keep your Inbox full? What
about social network clients that always load instantly with the latest content? Or even analytics packages to push your latest stats to your device? Or turn-based online games that
push the latest game state, ready for you to make your next move (which can be cached offline and pushed back when online)?
There are so many potential uses for “quiet” pushing, and now I’m itching for an opportunity to have a play with them.
The OpenStreetMap project consists of raw map data, collected and aggregated by thousands of users. This tutorial covers the configuration and maintenance of a web service using
Open Source Routing Machine (OSRM), which is based on the OpenStreetMap d
The OpenStreetMap project consists of raw map data, collected and aggregated by thousands of users. However, its open access policy
sparked a number of collateral projects, which collectively cover many of the features typically offered by commercial mapping services.
The most obvious advantage in using OpenStreetMap-based software over a commercial solution is economical convenience, because OpenStreetMap comes as free (both as in beer and as in
speech) software. The downside is that it takes a little configuration in order to setup a working web service.
This tutorial covers the configuration and maintenance of a web service which can answer questions such as:
What is the closest street to a given pair of coordinates?
What’s the best way to get from point A to point B?
How long does it take to get from point A to point B with a car, or by foot?
The software that makes this possible is an open-source project called Open Source Routing Machine (OSRM), which is based on the OpenStreetMap
data. Functionalities to embed OpenStreetMaps in Web pages are already provided out-of-the-box by APIs such as OpenLayers.
…
While slightly dated, I found this guide to be really valuable in my effort to set up a server that could spit out fastest walking routes around Oxford to support a PWA-driven tour of places relevant to J. R. R. Tolkien’s life, at my “day job”.