People being unwilling to discuss their wild claims later using the lack of discussion as evidence of widespread acceptance.
When people balance the new toilet roll one atop the old one’s tube.3
Come on! It would have been so easy!
Shellfish. Why would you eat that!?
People assuming my interest in computers and technology means I want to talk to them about cryptocurrencies.4
Websites that nag you to install their shitty app. (I know you have an app. I’m choosing to use your website. Stop with the banners!)
People who seem to only be able to drive at one speed.5
The assumption that the fact I’m “sharing” my partner is some kind of compromise on my part; a concession; something that I’d “wish away” if I could.
(It’s very much not.)
Brexit.
Wow, that was strangely cathartic.
Footnotes
1 I have a special pet hate for websites that require JavaScript to render their images.
Like… we’d had the<img>tag since 1993! Why are you throwing it away and replacing it with something objectively slower, more-brittle, and
less-accessible?
2 Or, worse yet, claiming
that my long, random password is insecure because it contains my surname. I get that composition-based password rules, while terrible (even when they’re correctly
implemented, which they’re often not), are a moderately useful model for people to whom you’d otherwise struggle to
explain password complexity. I get that a password composed entirely of personal information about the owner is a bad idea too. But there’s a correct way to do this, and it’s not “ban
passwords with forbidden words in them”. Here’s what you should do: first, strip any forbidden words from the password: you might need to make multiple passes. Second, validate the
resulting password against your composition rules. If it fails, then yes: the password isn’t good enough. If it passes, then it doesn’t matter that forbidden words
were in it: a properly-stored and used password is never made less-secure by the addition of extra information into it!
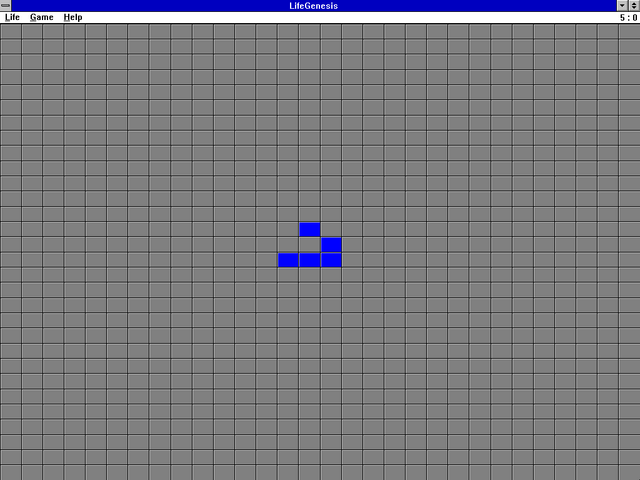
An RM Nimbus was not the first computer on which I played Game of Life1. But this glider is here symbolically, anyway.
I can trace my hacker roots back further than my first experience of using an RM
Nimbus M-Series in circa 19922.
But there was something particular about my experience of this popular piece of British edutech kit which provided me with a seminal experience that shaped my “hacker identity”. And
it’s that experience about which I’d like to tell you:
Shortly after I started secondary school, they managed to upgrade their computer lab from a handful of Nimbus PC-186s to a fancy new network of M-Series PC-386s. The school were clearly very proud of this cutting-edge new acquisition, and we watched the
teachers lay out the manuals and worksheets which smelled fresh and new and didn’t yet have their corners frayed nor their covers daubed in graffiti.
I only got to use the schools’ older computers – this kind! – once or twice before the new ones were delivered.
Program Manager
The new ones ran Windows 3 (how fancy!). Well… kind-of. They’d been patched with a carefully-modified copy of Program Manager that imposed a variety of limitations. For example, they had removed the File > Run… menu item, along
with an icon for File Manager, in order to restrict access to only the applications approved by the network administrator.
A special program was made available to copy files between floppy disks and the user’s network home directory. This allowed a student to take their work home with them if they wanted.
The copying application – whose interface was vastly inferior to File Manager‘s – was limited to only copying files with extensions in its allowlist. This meant that (given
that no tool was available that could rename files) the network was protected from anybody introducing any illicit file types.
Bring a .doc on a floppy? You can copy it to your home directory. Bring a .exe? You can’t even see it.
To young-teen-Dan, this felt like a challenge. What I had in front of me was a general-purpose computer with a limited selection of software but a floppy drive through which media could
be introduced. What could I make it do?
This isn’t my school’s computer lab circa mid-1990s (it’s this school) but it has absolutely the same
energy. Except that I think Solitaire was one of the applications that had been carefully removed from Program Manager.
Spoiler: eventually I ended up being able to execute pretty much anything I wanted, but we’ll get to that. The journey is the important part of the story. I didn’t start by asking “can
I trick this locked-down computer lab into letting my friends and I play Doom deathmatches on it?” I started by asking “what can I make it do?”; everything else built up over
time.
Recorder + Paintbrush made for an interesting way to use these basic and limited tools to produce animations. Like this one, except at school I’d have put more effort in4.
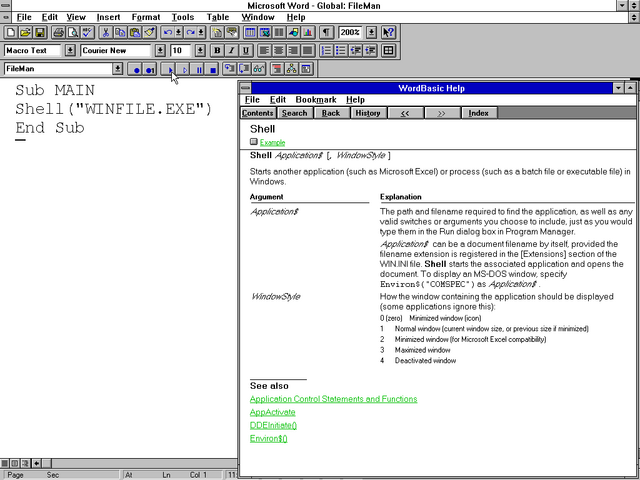
Microsoft Word
Then I noticed that Microsoft Word also had a macro recorder, but this one was scriptable using a programming language called WordBasic (a predecessor to Visual Basic for
Applications). So I pulled up the help and started exploring what it could do.
And as soon as I discovered the Shell function, I realised that
the limitations that were being enforced on the network could be completely sidestepped.
A Windows 3 computer that runs Word… can run any other executable it has access to. Thanks, macro editor.
Now that I could run any program I liked, I started poking the edges of what was possible.
Could I get a MS-DOS prompt/command shell? Yes, absolutely5.
Could I write to the hard disk drive? Yes, but any changes got wiped when the computer performed its network boot.
Could I store arbitrary files in my personal network storage? Yes, anything I could bring in on floppy disks6
could be persisted on the network server.
I didn’t have a proper LAN at home7
So I really enjoyed the opportunity to explore, unfettered, what I could get up to with Windows’ network stack.
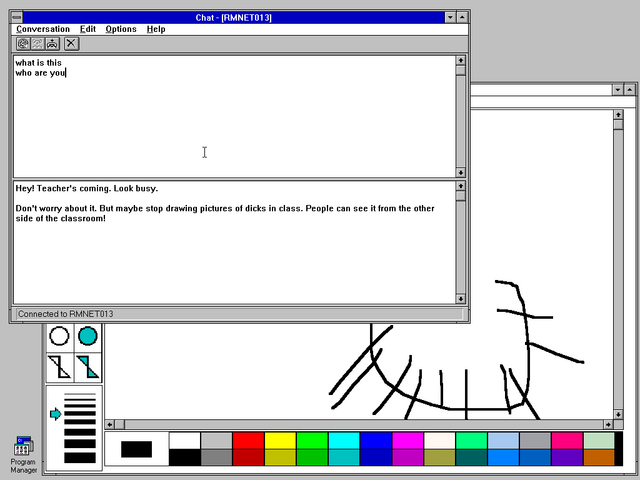
The “WinNuke” NetBIOS remote-crash vulnerability was a briefly-entertaining way to troll classmates, but unlocking WinPopup/Windows Chat capability was ultimately more-rewarding.
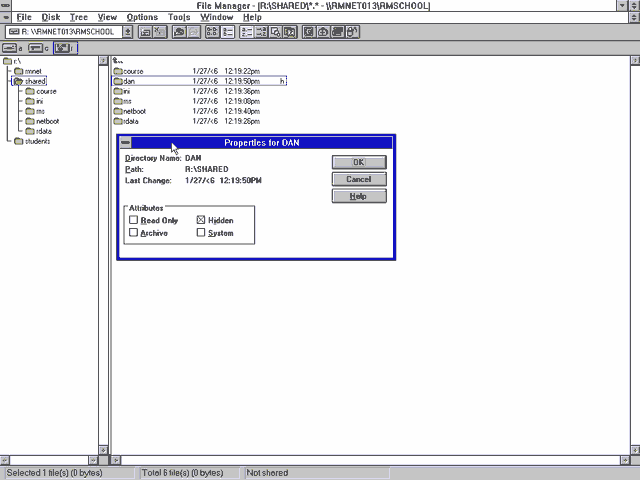
File Manager
I started to explore the resources on the network. Each pupil had their own networked storage space, but couldn’t access one another’s. But among the directories shared between
all students, I found a directory to which I had read-write access.
I created myself a subdirectory and set the hidden bit on it, and started dumping into it things that I wanted to keep on the network8.
By now my classmates were interested in what I was achieving, and I wanted in the benefits of my success. So I went back to Word and made a document template that looked
superficially like a piece of coursework, but which contained macro code that would connect to the shared network drive and allow the user to select from a series of programs that
they’d like to run.
Gradually, compressed over a series of floppy disks, I brought in a handful of games: Commander Keen, Prince of Persia, Wing Commander, Civilization,
Wolfenstein 3D, even Dune II. I got increasingly proficient at modding games to strip out unnecessary content, e.g. the sound and music files9,
minimising the number of floppy disks I needed to ZIP (or ARJ!) content to before smuggling it in via my shirt pocket, always sure not to
be carrying so many floppies that it’d look suspicious.
The goldmine moment – for my friends, at least – was the point at which I found a way to persistently store files in a secret shared location, allowing me to help them run whatever
they liked without passing floppy disks around the classroom (which had been my previous approach).
In a particularly bold move, I implemented a simulated login screen which wrote the entered credentials into the shared space before crashing the computer. I left it running,
unattended, on computers that I thought most-likely to be used by school staff, and eventually bagged myself the network administrator’s password. I only used it twice: the first time,
to validate my hypothesis about the access levels it granted; the second, right before I finished school, to confirm my suspicion that it wouldn’t have been changed during my entire
time there10.
Are you sure you want to quit?
My single biggest mistake was sharing my new-found power with my classmates. When I made that Word template that let others run the software I’d introduced to the
network, the game changed.
When it was just me, asking the question what can I make it do?, everything was fun and exciting.
But now half a dozen other teens were nagging me and asking “can you make it do X?”
This wasn’t exploration. This wasn’t innovation. This wasn’t using my curiosity to push at the edges of a system and its restrictions! I didn’t want to find the exploitable boundaries
of computer systems so I could help make it easier for other people to do so… no: I wanted the challenge of finding more (and weirder) exploits!
I wanted out. But I didn’t want to say to my friends that I didn’t want to do something “for” them any more11.
I figured: I needed to get “caught”.
I considered just using graphics software to make these screenshots… but it turned out to be faster to spin up a network of virtual machines running Windows 3.11 and some basic tools.
I actually made the stupid imaginary dialog box you’re seeing.12
I chose… to get sloppy.
I took a copy of some of the software that I’d put onto the shared network drive and put it in my own home directory, this time un-hidden. Clearly our teacher was already suspicious and
investigating, because within a few days, this was all that was needed for me to get caught and disciplined13.
I was disappointed not to be asked how I did it, because I was sufficiently proud of my approach that I’d hoped to be able to brag about it to somebody who’d
understand… but I guess our teacher just wanted to brush it under the carpet and move on.
Aftermath
The school’s IT admin certainly never worked-out the true scope of my work. My “hidden” files remained undiscovered, and my friends were able to continue to use my special Word template
to play games that I’d introduced to the network14.
I checked, and the hidden files were still there when I graduated.
The warning worked: I kept my nose clean in computing classes for the remainder of secondary school. But I would’ve been happy to, anyway: I already felt like I’d “solved” the challenge
of turning the school computer network to my interests and by now I’d moved on to other things… learning how to reverse-engineer phone networks… and credit card processors… and
copy-protection systems. Oh, the stories I could tell15.
I “get” it that some of my classmates – including some of those pictured – were mostly interested in the results of my hacking efforts. But for me it always was – and still
is – about the journey of discovery.
But I’ll tell you what: 13-ish year-old me ought to be grateful to the RM Nimbus network at my school for providing an interesting system about which my developing “hacker brain” could
ask: what can I make it do?
Which remains one of the most useful questions with which to foster a hacker mentality.
Footnotes
1 I first played Game of Life on an Amstrad CPC464, or possibly a PC1512.
2 What is the earliest experience to which I can credit my “hacker mindset”?
Tron and WarGames might have played a part, as might have the
“hacking” sequence in Ferris Bueller’s Day Off. And there was the videogame Hacker and its sequel (it’s funny to
see their influence in modern games). Teaching myself to program so that I could make
text-based adventures was another. Dissecting countless obfuscated systems to see how they worked… that’s yet another one: something I did perhaps initially to cheat at games by
poking their memory addresses or hexediting their save games… before I moved onto reverse-engineering copy protection systems and working out how they could be circumvented… and then
later still when I began building hardware that made it possible for me to run interesting experiments on telephone networks.
Any of all of these datapoints, which took place over a decade, could be interpreted as “the moment” that I became a hacker! But they’re not the ones I’m talking about today.
Today… is the story of the RM Nimbus.
3 Whatever happened to Recorder? After it disappeared in Windows 95 I occasionally had
occasion to think to myself “hey, this would be easier if I could just have the computer watch me and copy what I do a few times.” But it was not to be: Microsoft decided that this
level of easy automation wasn’t for everyday folks. Strangely, it wasn’t long after Microsoft dropped macro recording as a standard OS feature that Apple decided that MacOS
did need a feature like this. Clearly it’s still got value as a concept!
4 Just to clarify: I put more effort in to making animations, which were not part of
my schoolwork back when I was a kid. I certainly didn’t put more effort into my education.
5 The computers had been configured to make DOS access challenging: a boot menu let you
select between DOS and Windows, but both were effectively nerfed. Booting into DOS loaded an RM-provided menu that couldn’t be killed; the MS-DOS prompt icon was absent from Program
Manager and quitting Windows triggered an immediate shutdown.
6 My secondary school didn’t get Internet access during the time I was enrolled there. I
was recently trying to explain to one of my kids the difference between “being on a network” and “having Internet access”, and how often I found myself on a network that wasn’t
internetworked, back in the day. I fear they didn’t get it.
7 I was in the habit of occasionally hooking up PCs together with null modem cables, but only much later on would I end up acquiring sufficient “thinnet”
10BASE2 kit that I could throw together a network for a LAN party.
8 Initially I was looking to sidestep the space limitation enforcement on my “home”
directory, and also to put the illicit software I was bringing in somewhere that could not be trivially-easily traced back to me! But later on this “shared” directory became the
repository from which I’d distribute software to my friends, too.
9 The school computer didn’t have soundcards and nobody would have wanted PC speakers
beeping away in the classroom while they were trying to play a clandestine videogame anyway.
10 The admin password was concepts. For at least four years.
11 Please remember that at this point I was a young teenager and so was pretty well
over-fixated on what my peers thought of me! A big part of the persona I presented was of somebody who didn’t care what others thought of him, I’m sure, but a mask that
doesn’t look like a mask… is still a mask. But yeah: I had a shortage of self-confidence and didn’t feel able to say no.
13 I was briefly alarmed when there was talk of banning me from the computer lab for
the remainder of my time at secondary school, which scared me because I was by now half-way through my
boring childhood “life plan” to become a computer programmer by what seemed to be the appropriate route, and I feared that not being able to do a GCSE in a CS-adjacent subject
could jeopardise that (it wouldn’t have).
14 That is, at least, my friends who were brave enough to carry on doing so after the
teacher publicly (but inaccurately) described my alleged offences, seemingly as a warning to others.
15 Oh, the stories I probably shouldn’t tell! But here’s a teaser: when I
built my first “beige box” (analogue phone tap hardware) I experimented with tapping into the phone line at my dad’s house from the outside. I carefully shaved off some of
the outer insulation of the phone line that snaked down the wall from the telegraph pole and into the house through the wall to expose the wires inside, identified each, and then
croc-clipped my box onto it and was delighted to discovered that I could make and receive calls “for” the house. And then, just out of curiosity to see what kinds of protections were
in place to prevent short-circuiting, I experimented with introducing one to the ringer line… and took out all the phones on the street. Presumably I threw a circuit breaker in the
roadside utility cabinet. Anyway, I patched-up my damage and – fearing that my dad would be furious on his return at the non-functioning telecomms – walked to the nearest functioning
payphone to call the operator and claim that the phone had stopped working and I had no idea why. It was fixed within three hours. Phew!
Hey, let’s set up an account with Hive. After the security scares they faced in the mid-2010s, I’m sure they’ll be competent at
making a password form, right?
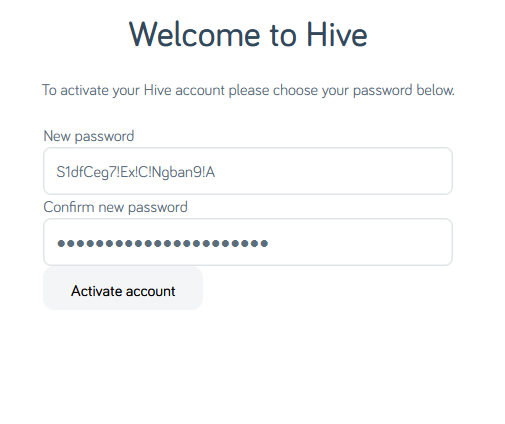
Your password must be at least 8 characters; okay.
Just 8 characters would be a little short in this day and age, I reckon, but what do I care: I’m going to make a long and random one with my password safe anyway. Here we go:
I’ve unmasked the password field so I can show you what I tried.
Obviously the password I eventually chose is unrelated to any of my screenshots.
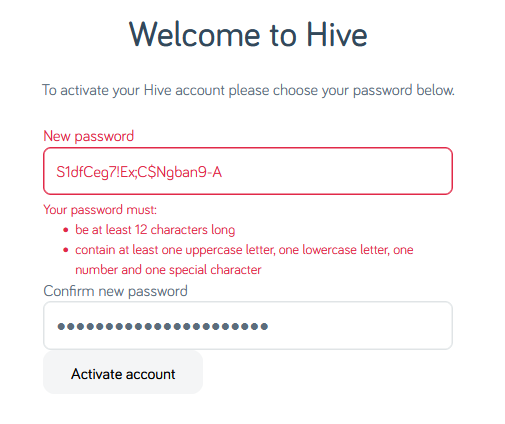
Now my password must be at least 12 characters long, not 8 as previously indicated. That’s still not a problem.
Oh, and must contain at least one of four different character classes: uppercase, lowercase, numbers, and special characters. But wait… my proposed password already does
contain all of those things!
Let’s simplify.
The password 1111AAAAaaaa!!!! is valid… but S1dfCeg7!Ex;C$Ngban9-A is not. I guess my password is too
strong?
Composition rules are bullshit already. I’d already checked to make sure my surname didn’t appear in the password in case that was the problem (on a few occasions services have forbidden me from using the letter “Q” in random passwords
because they think that would make them easier to guess… wot?). So there must be something else amiss. Something that the error message is misleading about…
A normal person might just have used the shit password that Hive accepted, but I decided to dig deeper.
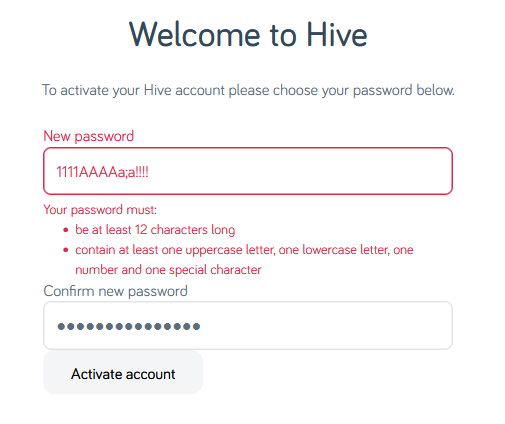
Using the previously-accepted password again but with a semicolon in it… fails. So clearly
the problem is that some special characters are forbidden. But we’re not being told which ones, or that that’s the problem. Which is exceptionally sucky user experience,
Hive.
At this point it’s worth stressing that there’s absolutely no valid reason to limit what characters are used in a password. Sometimes well-meaning but ill-informed
developers will ban characters like <, >, ' and " out of a misplaced notion that this is a good way to protect against XSS and
injection attacks (it isn’t; I’ve written about this before…), but banning ; seems especially obtuse (and inadequately explaining that in
an error message is just painfully sloppy). These passwords are going to be hashed anyway (right… right!?) so there’s really no reason to block any character, but anyway…
I wondered what special characters are forbidden, and ran a quick experiment. It turns out… it’s a lot:
Characters Hive forbids use of in passwords include-,.+="£^#'(){}*|<>:` – also space
“Special” characters Hive they allow:!@$%&?
What the fuck, Hive. If you require that users add a “special” character to their password but there are only six special characters you’ll accept (and they don’t even include the most
common punctuation characters), then perhaps you should list them when asking people to choose a password!
Or, better yet, stop enforcing arbitrary and pointless restrictions on passwords. It’s not 1999 any more.
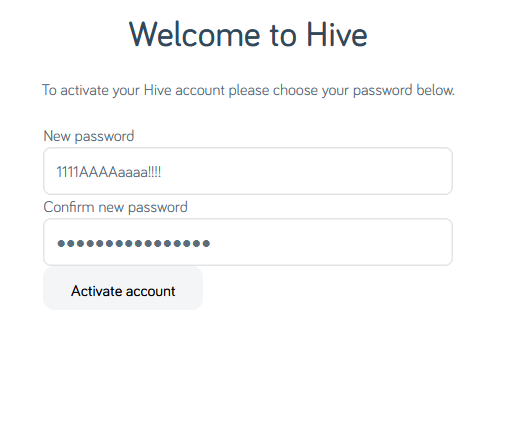
I eventually found a password that would be accepted. Again, it’s not the
one shown above, but it’s more than a little annoying that this approach – taking the diversity of punctuation added by my password safe’s generator and swapping them all for
exclamation marks – would have been enough to get past Hive’s misleading error message.
Having eventually found a password that worked and submitted it…
…it turns out I’d taken too long to do so, so I got treated to a different misleading error message. Clearly the problem was that the CSRF token had expired, but instead they told me
that the activation URL was invalid.
If I, a software engineer with a quarter of a century of experience and who understands what’s going wrong, struggle with setting a password on your site… I can’t begin to image the
kinds of tech support calls that you must be fielding.
Brainfart moment this morning when my password safe prompted me to unlock it with a password, and for a moment I thought to myself “Why am I having to manually type in a password? Don’t
I have a password safe to do this for me?” 🤦
The two most important things you can do to protect your online accounts remain to (a) use a different password, ideally a randomly-generated one, for every service, and (b) enable
two-factor authentication (2FA) where it’s available.
If you’re not already doing that, go do that. A password manager like 1Password, Bitwarden, or LastPass will help (although be aware that the latter’s had some security issues lately, as I’ve mentioned).
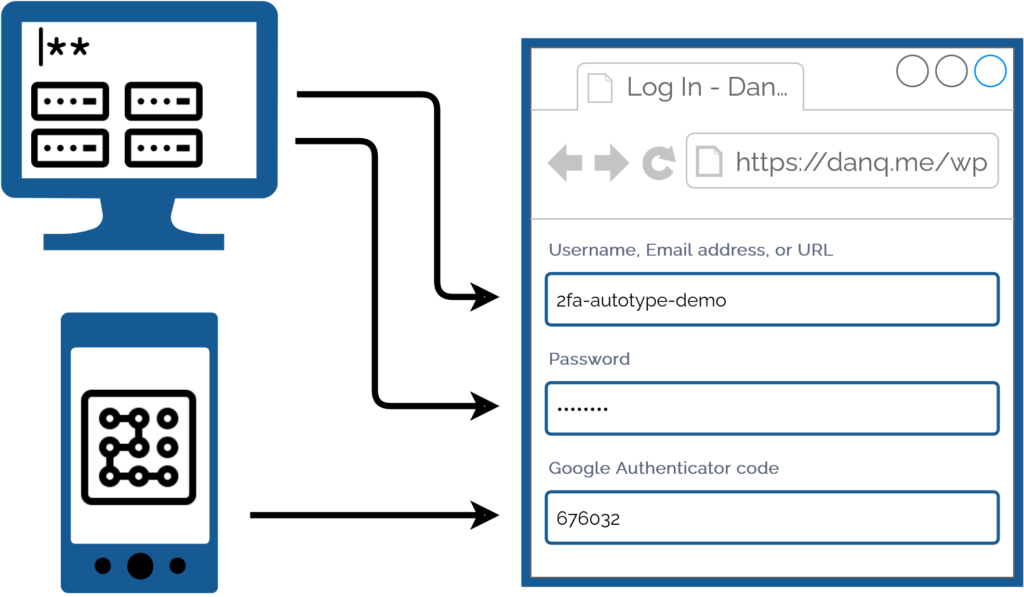
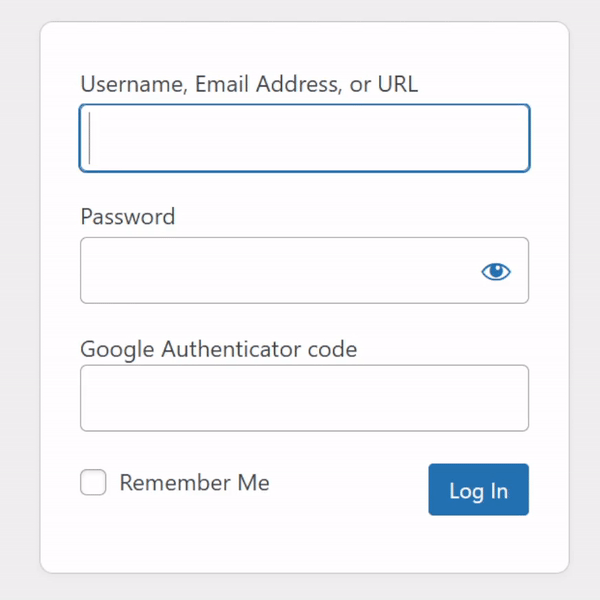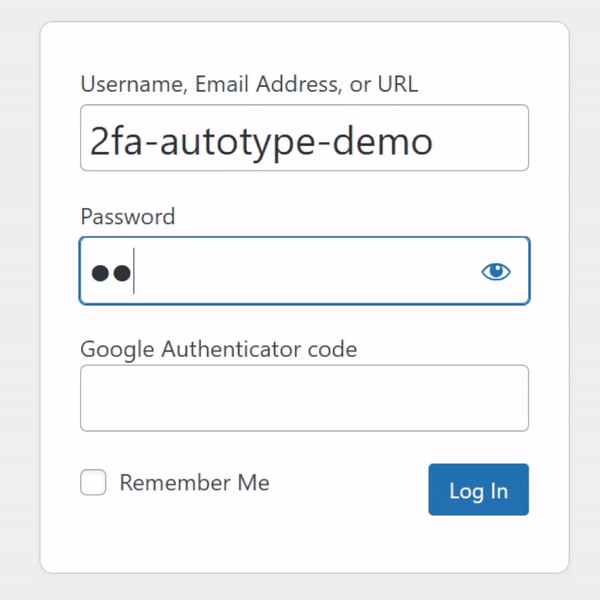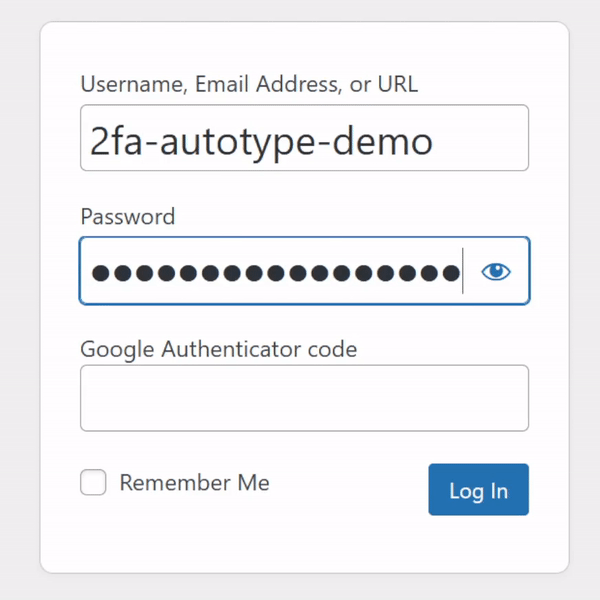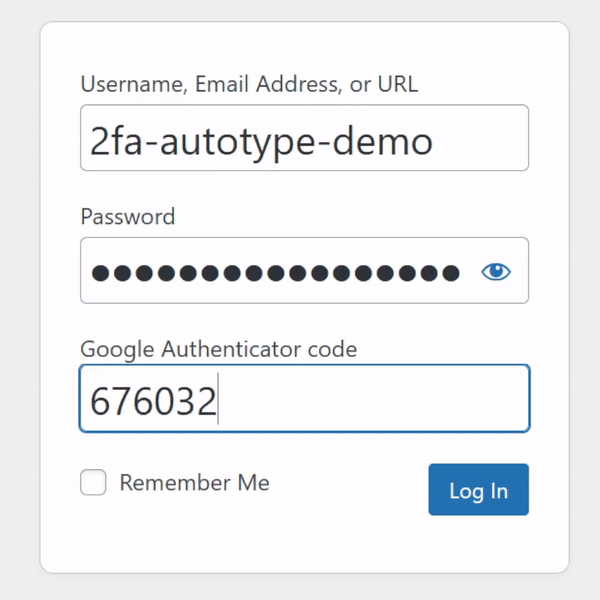
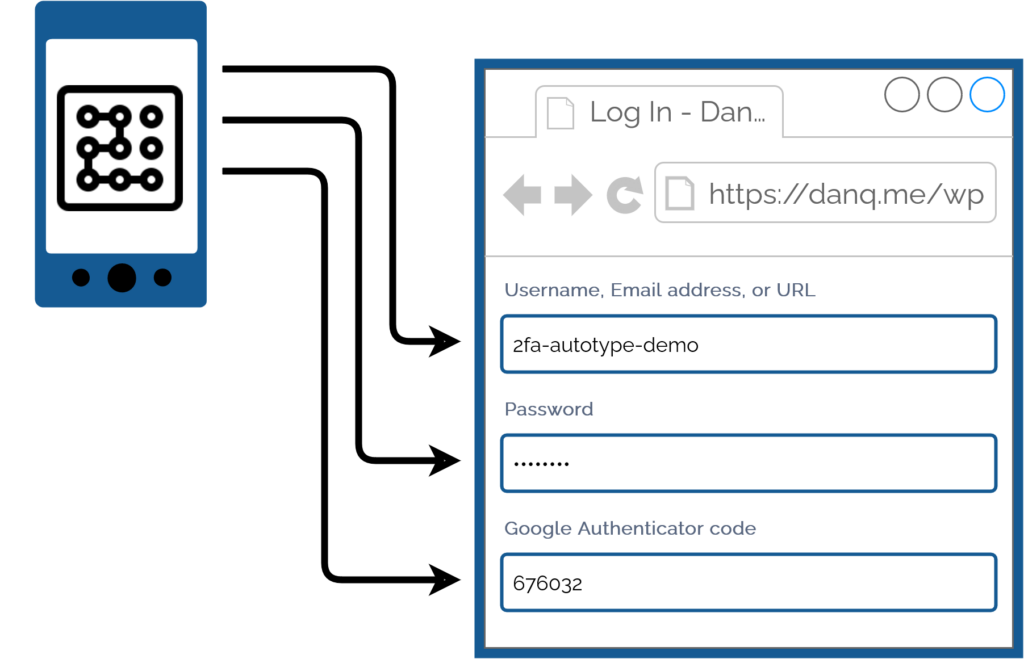
For many people, authentication looks like this: put in a username and password from a password safe (or their brain), and a second factor from their phone.
I promised back in 2018 to talk about what
this kind of authentication usually1
looks like for me, because my approach is a little different:
My password manager fills the username, password, and second factor parts of most login forms for me. It feels pretty magical.
I simply press my magic key combination, (re-)authenticate with my password safe if necessary, and then it does the rest. Including, thanks to some light scripting/hackery, many
authentication flows that span multiple pages and even ones that ask for randomly-selected characters from a secret word or similar2.
I love having long passwords and 2FA enabled. But I also love being able to log in with the convenience of a master
password and my fingerprint.
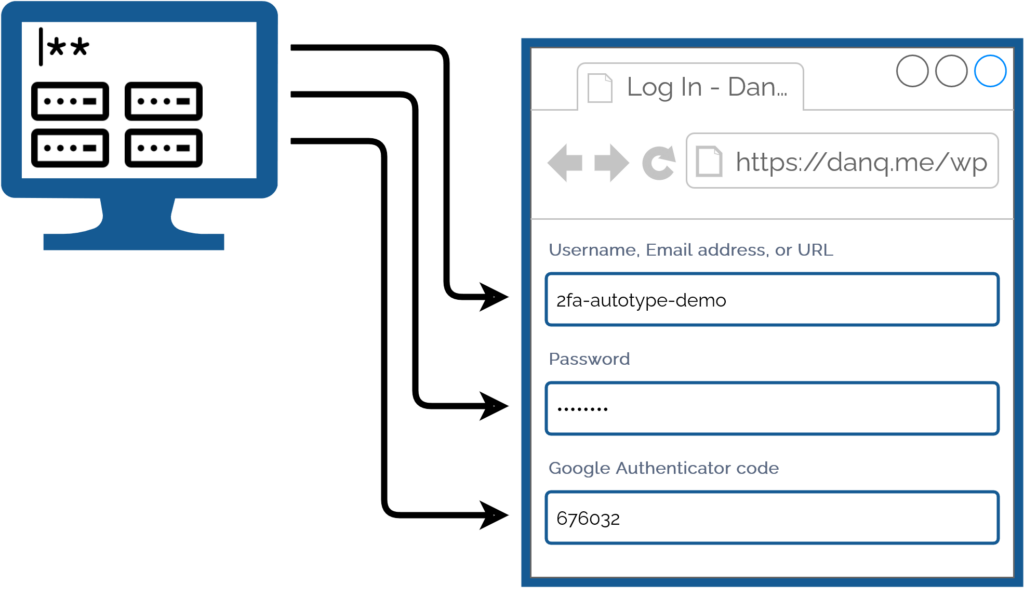
My approach isn’t without its controversies. The argument against it broadly comes down to this:
Storing the username, password, and the means to provide an authentication code in the same place means that you’re no-longer providing a second factor. It’s no longer e.g.
“something you have” and “something you know”, but just “something you have”. Therefore, this is equivalent to using only a username and password and not enabling 2FA at all.
I disagree with this argument. I provide two counter-arguments:
1. For most people, they’re already simplifying down to “something you have” by running the authenticator software on the same device, protected in the same way, as their
password safe: it’s their mobile phone! If your phone can be snatched while-unlocked, or if your password safe and authenticator are protected by the same biometrics3,
an attacker with access to your mobile phone already has everything.
If your argument about whether it counts as multifactor is based on how many devices are involved, this common pattern also isn’t multifactor.
2. Even if we do accept that this is fewer factors, it doesn’t completely undermine the value of time-based second factor codes4.
Time-based codes have an important role in protecting you from authentication replay!
For instance: if you use a device for which the Internet connection is insecure, or where there’s a keylogger installed, or where somebody’s shoulder-surfing and can see what you type…
the most they can get is your username, password, and a code that will stop working in 30 seconds5. That’s
still a huge improvement on basic username/password-based system.6
Note that I wouldn’t use this approach if I were using a cloud-based password safe like those I linked in the first paragraph! For me personally: storing usernames, passwords, and
2FA authentication keys together on somebody else’s hardware feels like too much of a risk.
But my password manager of choice is KeePassXC/KeePassDX, to which I migrated after I realised that the
plugins I was using in vanilla KeePass were provided as standard functionality in those forks. I keep the master copy of my password database
encrypted on a pendrive that attaches to my wallet, and I use Syncthing to push
secondary copies to a couple of other bits of hardware I control, such as my phone. Cloud-based password safes have their place and they’re extremely accessible to people new to
password managers or who need organisational “sharing” features, but they’re not the right tool for me.
As always: do your own risk assessment and decide what’s right for you. But from my experience I can say this: seamless, secure logins feel magical, and don’t have to require an
unacceptable security trade-off.
Footnotes
1 Not all authentication looks like this, for me, because some kinds of 2FA can’t be provided by my password safe. Some service providers “push” verification checks to an app, for example. Others use proprietary
TOTP-based second factor systems (I’m looking at you, banks!). And some, of course, insist on proven-to-be-terrible
solutions like email and SMS-based 2FA.
2 Note: asking for a username, password, and something that’s basically another-password
is not true multifactor authentication (I’m looking at you again, banks!), but it’s still potentially useful for organisations that need to authenticate you by multiple media
(e.g. online and by telephone), because it can be used to help restrict access to secrets by staff members. Important, but not the same thing: you should still demand 2FA.
3 Biometric security uses your body, not your mind, and so is still usable even if you’re
asleep, dead, uncooperative, or if an attacker simply removes and retains the body part that is to be scanned. Eww.
4 TOTP is a very popular
mechanism: you’ve probably used it. You get a QR code to scan into the authenticator app on your device (or multiple devices,
for redundancy), and it comes up with a different 6-digit code every 30 seconds or so.
5 Strictly, a TOTP code is
likely to work for a few minutes, on account of servers allowing for drift between your clock and theirs. But it’s still a short window.
6 It doesn’t protect you if an attacker manages to aquire a dump of the usernames,
inadequately-hashed passwords, and 2FA configuration from the server itself, of course, where other forms of 2FA (e.g. certificate-based) might, but protecting servers from bad actors is a whole separate essay.
Following their security incident last month, many users of LastPass are in the process of cycling
their security credentials for many of their accounts1.
I don’t use LastPass2,
but I’ve had ocassion to cycle credentials before, so I appreciate the pain that people are going through.
It’s not just passwords, though: it may well be your “security question” answers you need to rotate too. Your passwords quickly become worthless if an attacker can guess the answers to
your “security questions” at services that use them. If you’re using a password safe anyway, you should either:
Answer security questions with long strings of random garbage3,
or
Ensure that you use different answers for every service you use, as you would with passwords.4
In the latter case, you’re probably storing your security answers in a password safe5.
If the password safe they’re stored in is compromised, you need to change the answers to those security questions in order to secure the account.
This leads to the unusual situation where you can need to call up your bank and say: “Hi, I’d like to change my mother’s maiden name.” (Or, I suppose, father’s middle
name, first pet’s name, place of birth, or whatever.) Banks in particular are prone to disallowing you from changing your security answers over the Internet, but all kinds of other
businesses can also make this process hard… presumably because a well-meaning software engineer couldn’t conceive of any reason that a user might want to.
I sometimes use a pronouncable password generator to produce fake names for security question answers. And I’ll tell you what: I get some bemused reactions when I say things like “I’d
like to change my mother’s maiden name from Tuyiborhooniplashon to Mewgofartablejuki.”
1 If you use LastPass, you should absolutely plan to do this. IMHO, LastPass’s reassurances about the difficulty in cracking the encryption on the leaked data is a gross exaggeration. I’m not saying you need to
panic – so long as your master password is reasonably-long and globally-unique – but perhaps cycle all your credentials during 2023. Oh, and don’t rely on your second factor:
it doesn’t help with this particular incident.
2 I used to use LastPass, until around 2016, and I still think it’s a good choice for many
people, but nowadays I carry an encrypted KeePassXC password safe on a pendrive (with an automated backup onto an encrypted partition on our
household NAS). This gives me some security and personalisation benefits, at the expense of only a little convenience.
3 If you’re confident that you could never lose your password (or rather: that you could
never lose your password without also losing the security question answers because you would store them in the same place!), there’s no value in security questions, and the best thing
you can do might be to render them unusable.
4 If you’re dealing with a service that uses the security questions in a misguided effort
to treat them as a second factor, or that uses them for authentication when talking to them on the telephone, you’ll need to have usable answers to the questions for when they come
up.
5 You can, of course, use a different password safe for your randomly-generatred
security question answers than you would for the password itself; perhaps a more-secure-but-less-convenient one; e.g. an encrypted pendrive kept in your fire safe?
But sometimes, they disappear slowly, like this kind of web address:
http://username:password@example.com/somewhere
If you’ve not seen a URL like that before, that’s fine, because the answer to the question “Can I still use HTTP Basic Auth in URLs?” is, I’m afraid: no, you probably can’t.
But by way of a history lesson, let’s go back and look at what these URLs were, why they died out, and how web
browsers handle them today. Thanks to Ruth who asked the original question that inspired this post.
Basic authentication
The early Web wasn’t built for authentication. A resource on the Web was theoretically accessible to all of humankind: if you didn’t want it in the public eye, you didn’t put
it on the Web! A reliable method wouldn’t become available until the concept of state was provided by Netscape’s invention of HTTP
cookies in 1994, and even that wouldn’t see widespread for several years, not least because implementing a CGI (or
similar) program to perform authentication was a complex and computationally-expensive option for all but the biggest websites.
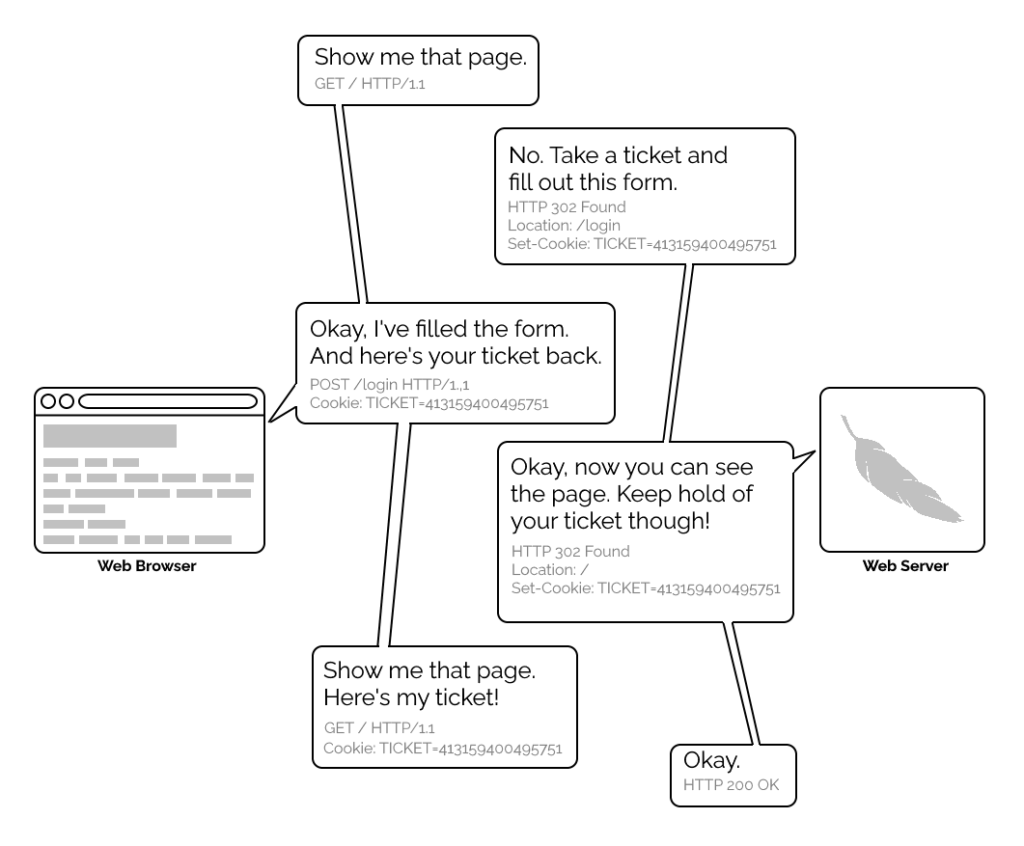
A simplified view of the form-and-cookie based authentication system used by virtually every website today, but which was too computationally-expensive for many sites in the 1990s.
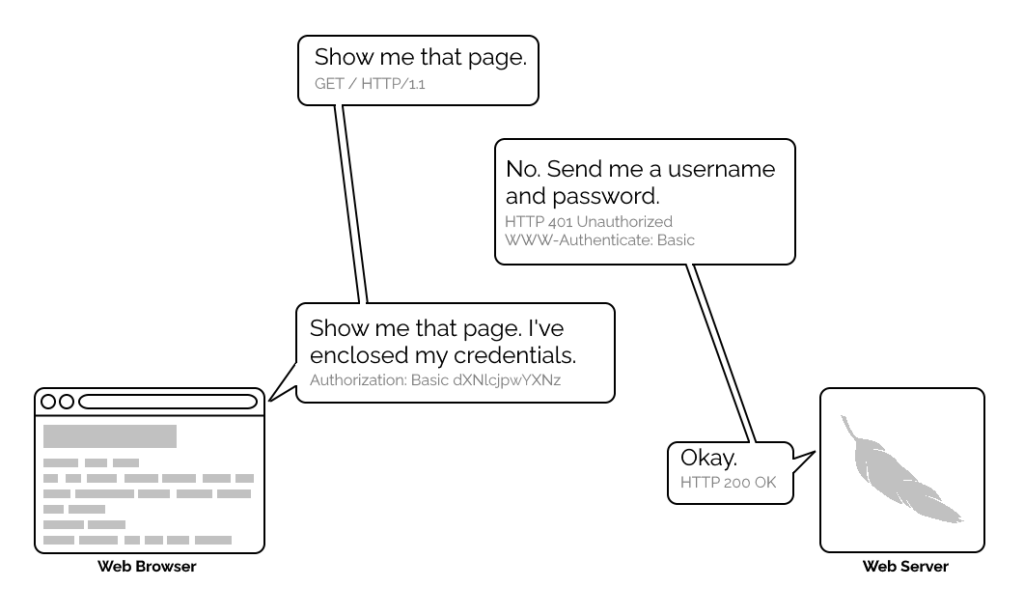
1996’s HTTP/1.0 specification tried to simplify things, though, with the introduction of the WWW-Authenticate header. The idea was that when a browser tried to access something that required
authentication, the server would send a 401 Unauthorized response along with a WWW-Authenticate header explaining how the browser could authenticate
itself. Then, the browser would send a fresh request, this time with an Authorization: header attached providing the required credentials. Initially, only “basic
authentication” was available, which basically involved sending a username and password in-the-clear unless SSL (HTTPS) was in use, but later, digest authentication and a host of others would appear.
For all its faults, HTTP Basic Authentication (and its near cousins) are certainly elegant.
Webserver software quickly added support for this new feature and as a result web authors who lacked the technical know-how (or permission from the server administrator) to implement
more-sophisticated authentication systems could quickly implement HTTP Basic Authentication, often simply by adding a .htaccessfile to the relevant directory.
.htaccess files would later go on to serve many other purposes, but their original and perhaps best-known purpose – and the one that gives them their name – was access
control.
Credentials in the URL
A separate specification, not specific to the Web (but one of Tim Berners-Lee’s most important contributions to it), described the general structure of URLs as follows:
At the time that specification was written, the Web didn’t have a mechanism for passing usernames and passwords: this general case was intended only to apply to protocols that
did have these credentials. An example is given in the specification, and clarified with “An optional user name. Some schemes (e.g., ftp) allow the specification of a user
name.”
But once web browsers had WWW-Authenticate, virtually all of them added support for including the username and password in the web address too. This allowed for
e.g. hyperlinks with credentials embedded in them, which made for very convenient bookmarks, or partial credentials (e.g. just the username) to be included in a link, with the
user being prompted for the password on arrival at the destination. So far, so good.
Encoding authentication into the URL provided an incredible shortcut at a time when Web round-trip times were much longer owing to higher latencies and no keep-alives.
This is why we can’t have nice things
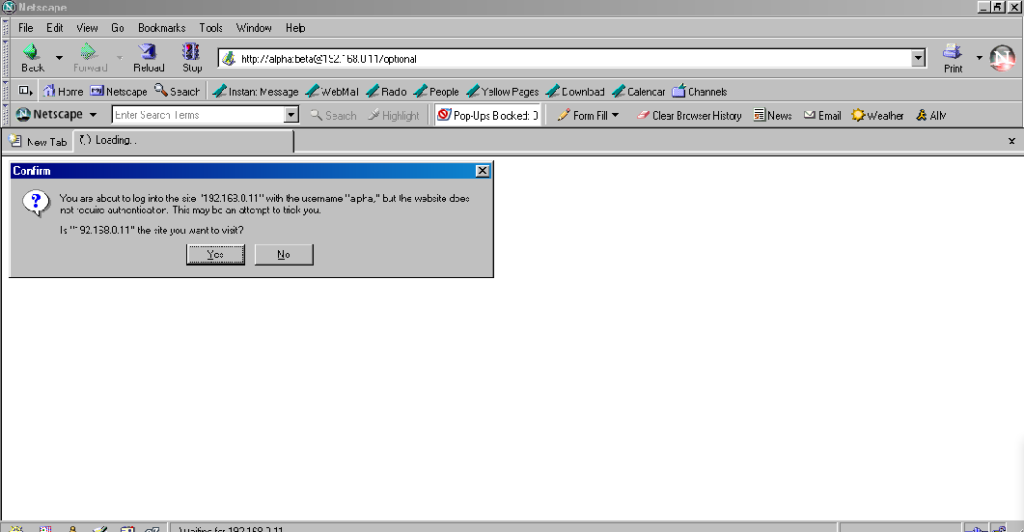
The technique fell out of favour as soon as it started being used for nefarious purposes. It didn’t take long for scammers to realise that they could create links like this:
https://YourBank.com@HackersSite.com/
Everything we were teaching users about checking for “https://” followed by the domain name of their bank… was undermined by this user interface choice. The poor victim would
actually be connecting to e.g. HackersSite.com, but a quick glance at their address bar would leave them convinced that they were talking to YourBank.com!
Theoretically: widespread adoption of EV certificates coupled with sensible user interface choices (that were never made) could
have solved this problem, but a far simpler solution was just to not show usernames in the address bar. Web developers were by now far more excited about forms and
cookies for authentication anyway, so browsers started curtailing the “credentials in addresses” feature.
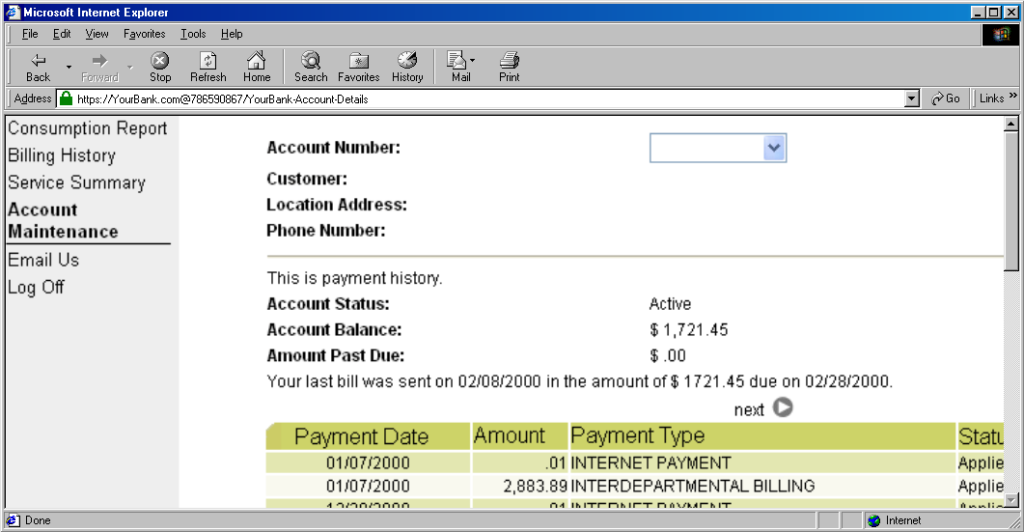
Users trained to look for “https://” followed by the site they wanted would often fall for scams like this one: the real domain name is after the @-sign. (This attacker is
also using dword notation to obfuscate their IP address; this
dated technique wasn’t often employed alongside this kind of scam, but it’s another historical oddity I enjoy so I’m shoehorning it in.)
(There are other reasons this particular implementation of HTTP Basic Authentication was less-than-ideal, but this reason is the big one that explains why things had to change.)
One by one, browsers made the change. But here’s the interesting bit: the browsers didn’t always make the change in the same way.
How different browsers handle basic authentication in URLs
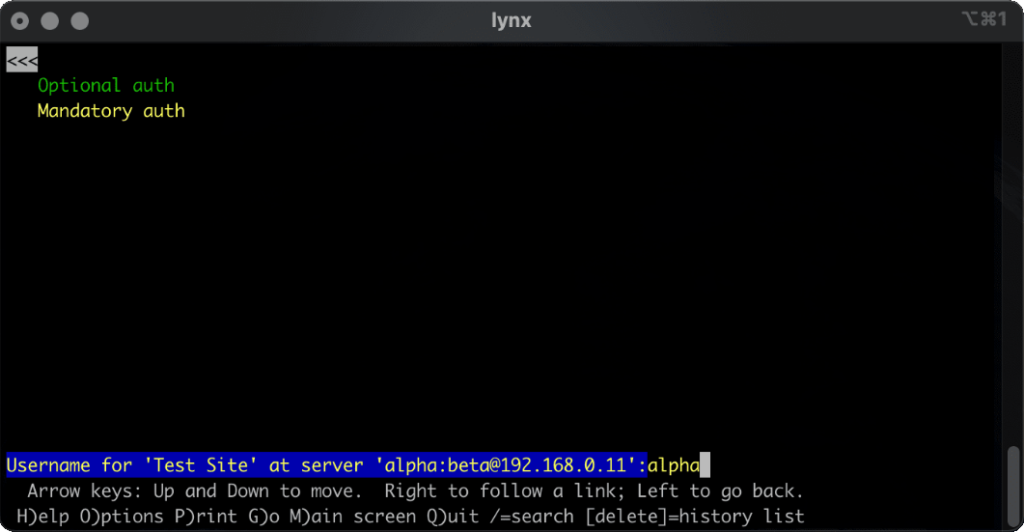
Let’s examine some popular browsers. To run these tests I threw together a tiny web application that outputs
the Authorization: header passed to it, if present, and can optionally send a 401 Unauthorized response along with a WWW-Authenticate: Basic realm="Test Site" header in order to trigger basic authentication. Why both? So that I can test not only how browsers handle URLs containing credentials when an authentication request is received, but how they handle them when one is not. This is relevant because
some addresses – often API endpoints – have optional HTTP authentication, and it’s sometimes important for a user agent (albeit typically a library or command-line one) to pass credentials without
first being prompted.
In each case, I tried each of the following tests in a fresh browser instance:
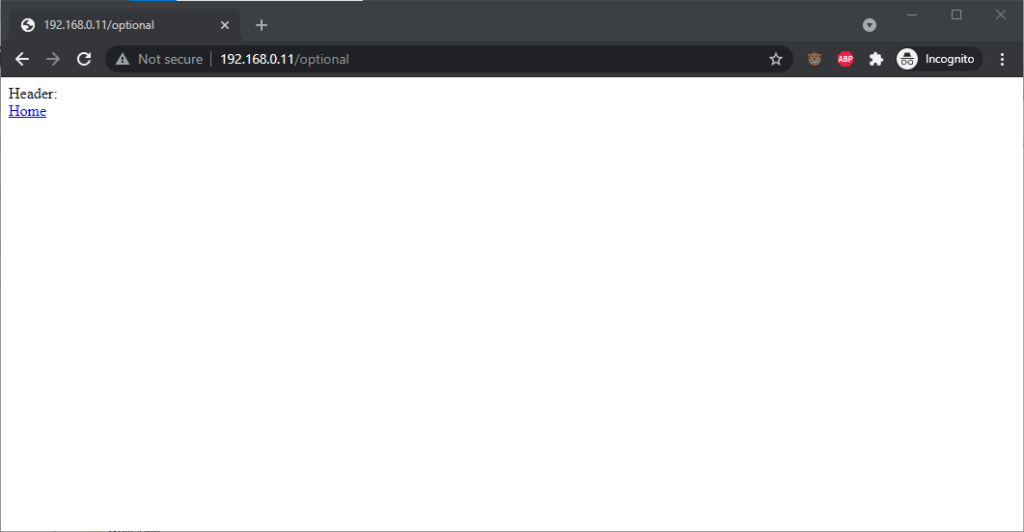
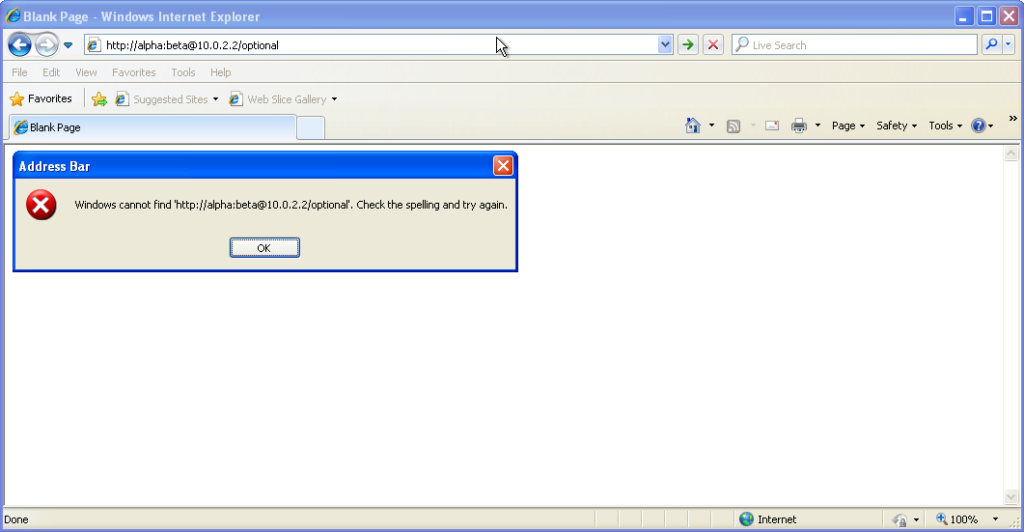
Go to http://<username>:<password>@<domain>/optional (authentication is optional).
Go to http://<username>:<password>@<domain>/mandatory (authentication is mandatory).
Experiment 1, then f0llow relative hyperlinks (which should correctly retain the credentials) to /mandatory.
Experiment 2, then follow relative hyperlinks to the /optional.
I’m only testing over the http scheme, because I’ve no reason to believe that any of the browsers under test treat the https scheme differently.
Chromium desktop family
Chrome 93 and Edge 93 both immediately suppressed the username and password from the address bar, along with the “http://” as we’ve come to expect of them. Like the “http://”, though,
the plaintext username and password are still there. You can retrieve them by copy-pasting the entire address.
Opera 78 similarly suppressed the username, password, and scheme, but didn’t retain the username and password in a way that could be copy-pasted out.
Authentication was passed only when landing on a “mandatory” page; never when landing on an “optional” page. Refreshing the page or re-entering the address with its credentials did not
change this.
Navigating from the “optional” page to the “mandatory” page using only relative links retained the username and password and submitted it to the server when it became mandatory,
even Opera which didn’t initially appear to retain the credentials at all.
Navigating from the “mandatory” to the “optional” page using only relative links, or even entering the “optional” page address with credentials after visiting the “mandatory” page, does
not result in authentication being passed to the “optional” page. However, it’s interesting to note that once authentication has occurred on a mandatory page, pressing enter at
the end of the address bar on the optional page, with credentials in the address bar (whether visible or hidden from the user) does result in the credentials being passed to
the optional page! They continue to be passed on each subsequent load of the “optional” page until the browsing session is ended.
Firefox desktop
Firefox 91 does a clever thing very much in-line with
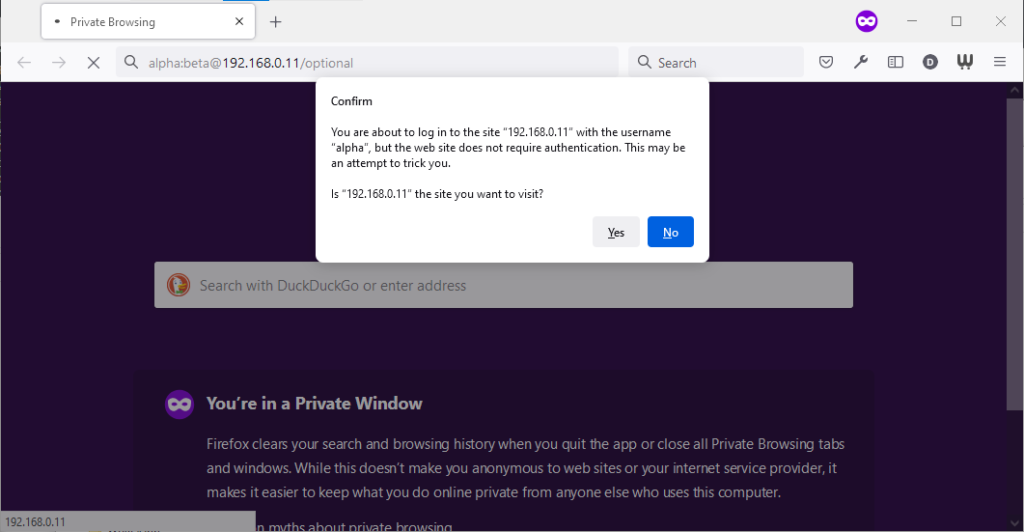
its image as a browser that puts decision-making authority into the hands of its user. When going to the “optional” page first it presents a dialog, warning the user that they’re going
to a site that does not specifically request a username, but they’re providing one anyway. If the user says that no, navigation ceases (the GET request for the page takes place the same
either way; this happens before the dialog appears). Strangely: regardless of whether the user selects yes or no, the credentials are not passed on the “optional” page. The credentials
(although not the “http://”) appear in the address bar while the user makes their decision.
Similar to Opera, the credentials do not appear in the address bar thereafter, but they’re clearly still being stored: if the refresh button is pressed the dialog appears again. It does
not appear if the user selects the address bar and presses enter.
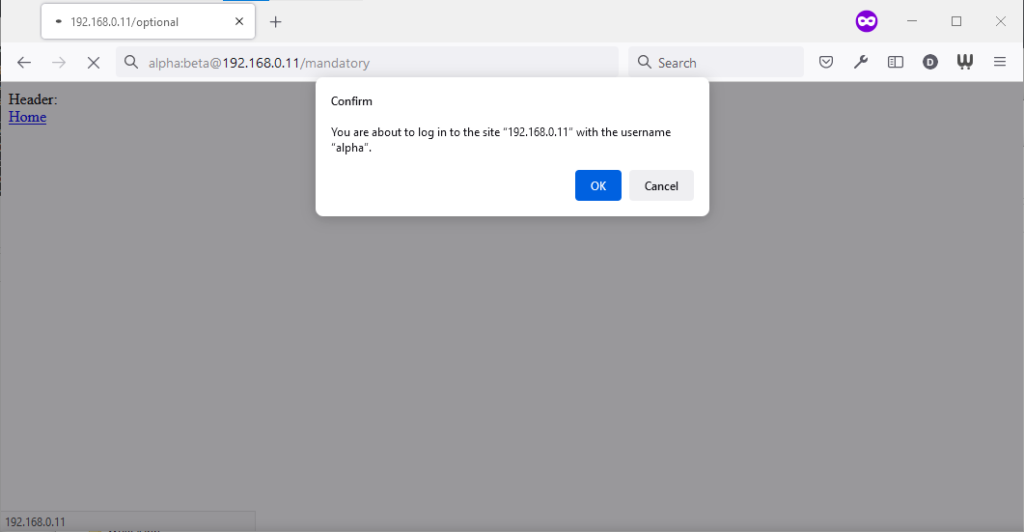
Similarly, going to the “mandatory” page in Firefox results in an informative dialog warning the user
that credentials are being passed. I like this approach: not only does it help protect the user from the use of authentication as a tracking technique (an old technique that I’ve not
seen used in well over a decade, mind), it also helps the user be sure that they’re logging in using the account they mean to, when following a link for that purpose. Again, clicking
cancel stops navigation, although the initial request (with no credentials) and the 401 response has already occurred.
Visiting any page within the scope of the realm of the authentication after visiting the “mandatory” page results in credentials being sent, whether or not they’re included in the
address. This is probably the most-true implementation to the expectations of the standard that I’ve found in a modern graphical browser.
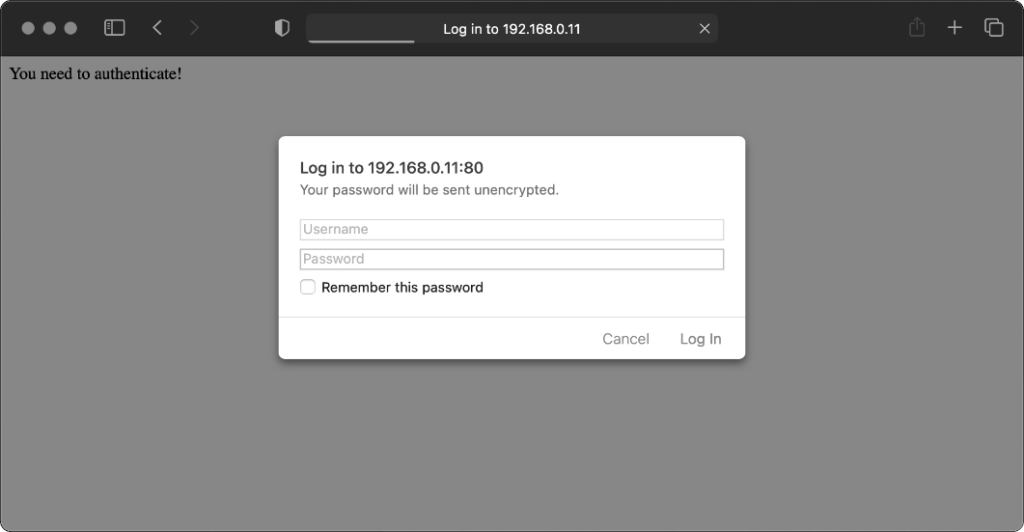
Safari desktop
Safari 14 never displays or uses credentials provided via the web address, whether or not
authentication is mandatory. Mandatory authentication is always met by a pop-up dialog, even if credentials were provided in the address bar. Boo!
Once passed, credentials are later provided automatically to other addresses within the same realm (i.e. optional pages).
Older browsers
Let’s try some older browsers.
From version 7 onwards – right up to the final version 11 – Internet Explorer fails to even recognise
addresses with authentication credentials in as legitimate web addresses, regardless of whether or not authentication is requested by the server. It’s easy to assume that this is yet
another missing feature in the browser we all love to hate, but it’s interesting to note that credentials-in-addresses is permitted for ftp:// URLs…
…and if you go back a little way, Internet Explorer 6 and below supported credentials in the address bar pretty
much as you’d expect based on the standard. The error message seen in IE7 and above is a deliberate design
decision, albeit a somewhat knee-jerk reaction to the security issues posed by the feature (compare to the more-careful approach of other browsers).
These older versions of IE even (correctly) retain the credentials through relative hyperlinks, allowing them to be passed when
they become mandatory. They’re not passed on optional pages unless a mandatory page within the same realm has already been encountered.
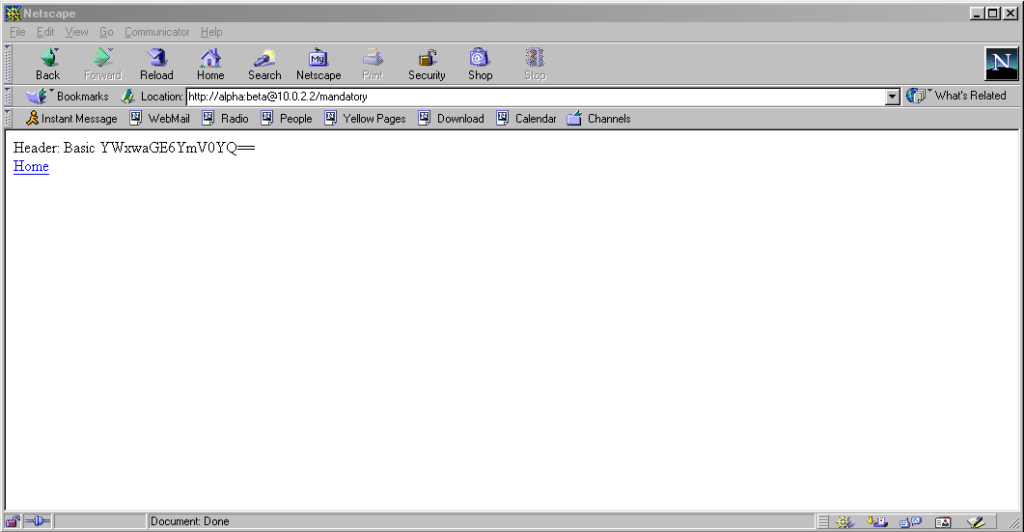
Pre-Mozilla Netscape behaved the same way. Truly this was the de facto standard for a long period on the Web, and the varied approaches we see today are the
anomaly. That’s a strange observation to make, considering how much the Web of the 1990s was dominated by incompatible implementations of different Web features (I’ve written about the <blink> and <marquee> tags before, which was perhaps the most-visible division between
the Microsoft and Netscape camps, but there were many, many more).
Interestingly: by Netscape 7.2 the browser’s behaviour had evolved
to be the same as modern Firefox’s, except that it still displayed the credentials in the address bar for all to see.
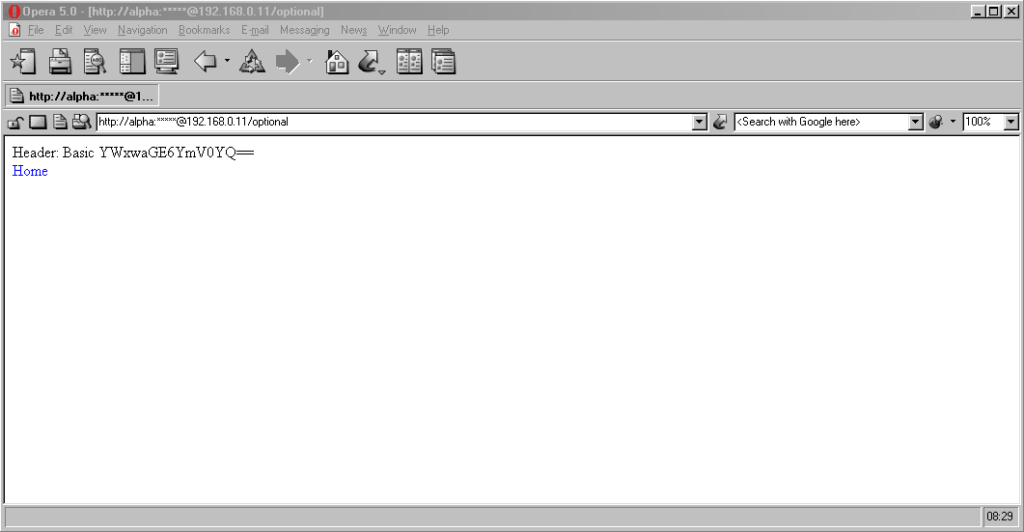
Now here’s a real gem: pre-Chromium Opera. It would send credentials to “mandatory” pages and remember them for the
duration of the browsing session, which is great. But it would also send credentials when passed in a web address to “optional” pages. However, it wouldn’t remember
them on optional pages unless they remained in the address bar: this feels to me like an optimum balance of features for power users. Plus, it’s one of very few browsers that
permitted you to change credentials mid-session: just by changing them in the address bar! Most other browsers, even to this day, ignore changes to HTTP Authentication credentials, which was sometimes be a source of frustration back in the day.
Finally, classic Opera was the only browser I’ve seen to mask the password in the address bar, turning it into a series of asterisks. This ensures the user knows that a
password was used, but does not leak any sensitive information to shoulder-surfers (the length of the “masked” password was always the same length, too, so it didn’t even leak the
length of the password). Altogether a spectacular design and a great example of why classic Opera was way ahead of its time.
The Command-Line
Most people using web addresses with credentials embedded within them nowadays are probably working with code, APIs,
or the command line, so it’s unsurprising to see that this is where the most “traditional” standards-compliance is found.
I was unsurprised to discover that giving curl a username and password in the URL meant that
username and password was sent to the server (using Basic authentication, of course, if no authentication was requested):
However, wgetdid catch me out. Hitting the same addresses with wget didn’t result in the credentials being sent
except where it was mandatory (i.e. where a HTTP 401 response and a WWW-Authenticate: header was received on the initial attempt). To force wget to
send credentials when they haven’t been asked-for requires the use of the --http-user and --http-password switches:
lynx does a cute and clever thing. Like most modern browsers, it does not submit credentials unless specifically requested, but if
they’re in the address bar when they become mandatory (e.g. because of following relative hyperlinks or hyperlinks containing credentials) it prompts for the username and password,
but pre-fills the form with the details from the URL. Nice.
What’s the status of HTTP (Basic) Authentication?
HTTP Basic Authentication and its close cousin Digest Authentication (which overcomes some of the security limitations of running Basic Authentication over an
unencrypted connection) is very much alive, but its use in hyperlinks can’t be relied upon: some browsers (e.g. IE, Safari)
completely munge such links while others don’t behave as you might expect. Other mechanisms like Bearer see widespread use in APIs, but nowhere else.
The WWW-Authenticate: and Authorization: headers are, in some ways, an example of the best possible way to implement authentication on the Web: as an
underlying standard independent of support for forms (and, increasingly, Javascript), cookies, and complex multi-part conversations. It’s easy to imagine an alternative
timeline where these standards continued to be collaboratively developed and maintained and their shortfalls – e.g. not being able to easily log out when using most graphical browsers!
– were overcome. A timeline in which one might write a login form like this, knowing that your e.g. “authenticate” attributes would instruct the browser to send credentials using an
Authorization: header:
In such a world, more-complex authentication strategies (e.g. multi-factor authentication) could involve encoding forms as JSON. And single-sign-on systems would simply involve the browser collecting a token from the authentication provider and passing it on to the
third-party service, directly through browser headers, with no need for backwards-and-forwards redirects with stacks of information in GET parameters as is the case today.
Client-side certificates – long a powerful but neglected authentication mechanism in their own right – could act as first class citizens directly alongside such a system, providing
transparent second-factor authentication wherever it was required. You wouldn’t have to accept a tracking cookie from a site in order to log in (or stay logged in), and if your
browser-integrated password safe supported it you could log on and off from any site simply by toggling that account’s “switch”, without even visiting the site: all you’d be changing is
whether or not your credentials would be sent when the time came.
The Web has long been on a constant push for the next new shiny thing, and that’s sometimes meant that established standards have been neglected prematurely or have failed to evolve for
longer than we’d have liked. Consider how long it took us to get the <video> and <audio> elements because the “new shiny” Flash came to dominate,
how the Web Payments API is only just beginning to mature despite over 25 years of ecommerce on the Web, or how we still can’t
use Link: headers for all the things we can use <link> elements for despite them being semantically-equivalent!
The new model for Web features seems to be that new features first come from a popular JavaScript implementation, and then eventually it evolves into a native browser feature: for
example HTML form validations, which for the longest time could only be done client-side using scripting languages. I’d love
to see somebody re-think HTTP Authentication in this way, but sadly we’ll never get a 100% solution in JavaScript alone: (distributed SSO is almost certainly off the table, for example, owing to cross-domain limitations).
Or maybe it’s just a problem that’s waiting for somebody cleverer than I to come and solve it. Want to give it a go?
The reality is that your sensitive data has likely already been stolen, multiple times. Cybercriminals have your credit card information. They have your social
security number and your mother’s maiden name. They have your address and phone number. They obtained the data by hacking any one of the hundreds of companies you entrust with the
data — and you have no visibility into those companies’ security practices, and no recourse when they lose your data.
Given this, your best option is to turn your efforts toward trying to make sure that your data isn’t used against you. Enable two-factor authentication for all important
accounts whenever possible. Don’t reuse passwords for anything important — and get a password manager to remember them all.
“the local part of my email address is just the letter ‘d’ by itself, which means microsoft has imposed the interesting restriction that my randomly generated password cannot
contain the letter ‘d’”
the local part of my email address is just the letter 'd' by itself, which means microsoft has imposed the interesting restriction that my randomly generated password cannot contain
the letter 'd' pic.twitter.com/tqTklyotTj
@notrevenant@PWtoostrong you wouldn’t believe how often I’m told I’m not allowed to use the
letter “Q” in passwords, because “my password mustn’t contain my surname”. O_o
An open source checklist of resources designed to improve your online privacy and security. Check things off to keep track as you go.
…
I’m pretty impressed with this resource. It’s a little US-centric and I would have put the suggestions into a different order, but many of the ideas on it are very good and are
presented in a way that makes them accessible to a wide audience.
2004 called, @virginmedia. They asked me to remind you that maximum password lengths and prohibiting pasting makes your security worse, not better. @PWTooStrong
In more detail:
Why would you set an upper limit on security? It can’t be for space/capacity reasons because you’re hashing my password anyway in accordance with best security practice, right?
(Right?)
Why would you exclude spaces, punctuation, and other “special” characters? If you’re afraid of injection attacks, you’re doing escaping wrong (and again: aren’t you hashing
anyway?). Or are you just afraid that one of your users might pick a strong password? Same for the “starts with a letter” limitation.
Composition rules like “doesn’t contain the same character twice in a row” reflects wooly thinking on that part of your IT team: you’re saying for example that “abababab” is
more-secure than “abccefgh”. Consider using exclusion lists/blacklists for known-compromised/common passwords e.g. with HaveIBeenPwned
and/or use entropy-based rather than composition-based rules e.g. with zxcvbn.
Disallowing pasting into password fields does nothing to prevent brute-force/automated attacks but frustrates users who use password managers (by forcing them to retype their
passwords, you may actually be reducing their security as well as increasing the likelihood of mistakes) and can have an impact on accessibility too.
Counterarguments I anticipate: (a) it’s for your security – no it’s not; go read any of the literature from the last decade and a half, (b) it’s necessary for integration with a
legacy system – that doesn’t fill me with confidence: if your legacy system is reducing your security, you need to update or replace your legacy system or else you’re setting yourself
up to be the next Marriott, Equifax, or Friend Finder Network.
German chat platform Knuddels.de (“Cuddles”) has been fined €20,000 for storing user passwords in plain text (no hash at all? Come on, people, it’s 2018).
The data of Knuddels users was copied and published by malefactors in July. In September, someone emailed the company warning them that user data had been published at Pastebin (only
8,000 members affected) and Mega.nz (a much bigger breach). The company duly notified its users and the Baden-Württemberg data protection authority.
…
Interesting stuff: this German region’s equivalent of the ICO applied a fine to this app for failing to hash
passwords, describing them as personal information that was inadequately protected following their theft. That’s interesting because it sets a German, and to a lesser extend a European,
precedent that plaintext passwords can be considered personal information and therefore allowing the (significant) weight of the GDPR to be applied to their misuse.
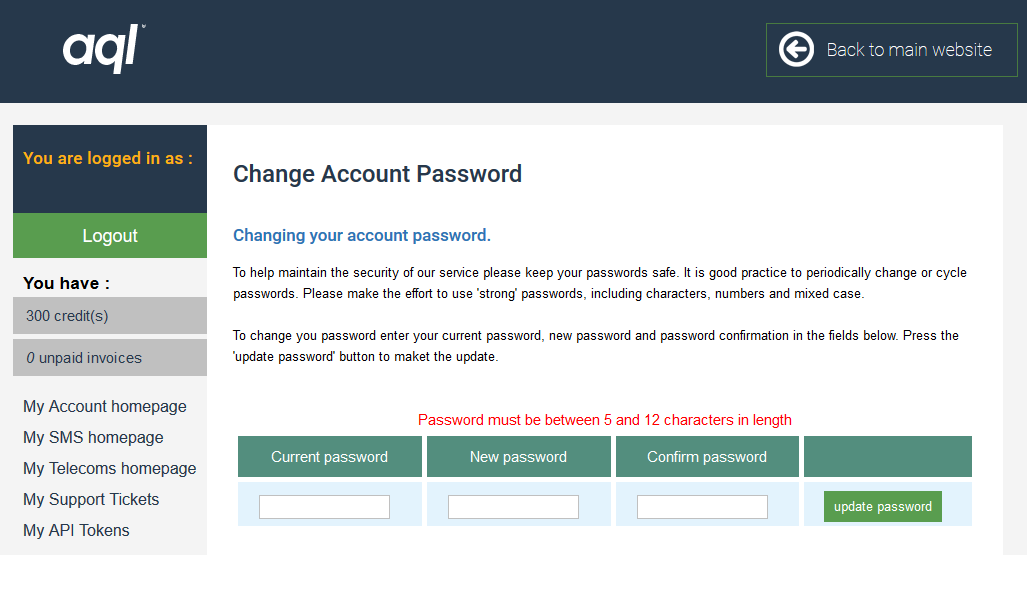
Hey @aqldotcom: why must my password for your enterprise telecommunications platform be no longer than 12 characters? Are you worried my #passwordistoostrong? CC @pwtoostrong
Let this pledge be duly noted on the permanent record of the Internet. I don’t know if there’s an afterlife, but I’ll be finding out soon enough, and I plan to go out mad as
hell…
One of the things people often tweet to us @ncsc are examples of websites which prevent you pasting in a password. Why do websites do this? The debate has raged – with most
commentators raging how annoying it is.
So why do organisations do this? Often no reason is given, but when one is, that reason is ‘security’. The NCSC don’t think the reasons add up. We think that stopping password
pasting (or SPP) is a bad thing that reduces security. We think customers should be allowed to paste their passwords into forms, and that
it improves security…