Folks at work have been encouraging to make more use of generative AI in my workflow1; going beyond my current “fancy autocomplete” use and giving my agents more autonomy. My experience of such “vibe coding” so far has been… mixed2, but I promised I’d revisit it.
One thing that these models are usually effective at is summarisation3. This is valuable if you’re faced with a large and unfamiliar codebase and you’re looking to trace a particular thing but you’re not certain where it is or what it’ll be called. While they’re not always fast, these tools can at least work in the background, which allows the developer to get on with something else while the agent trawls logs, code, and configuration to find and explain a fuzzily-defined thing.
Recently, I had a moment which I thought might be such an instance… but it didn’t turn out quite the way I expected. Here’s the story4:
The broken dev env
I’d been drafted into an established and ongoing project to provide more hands, following a coworker’s departure last week. This project touches parts of our (sprawling, microsevices-based) infrastructure that I hadn’t looked at before, so there was a lot I didn’t yet know.
I picked an issue that had belonged to my former colleague that QA had rejected and set out to retrace their steps: to replicate the problem that the QA engineers had identified and in doing so learn more about the underlying process. I spun up my development environment and tried to follow the steps.
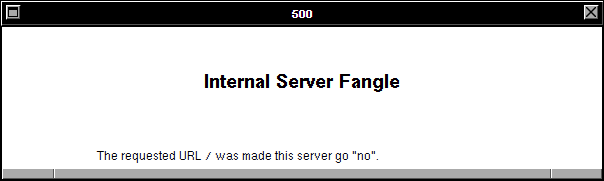
But I couldn’t even get as far as their problem before my frontend barfed out an error message. Sigh! Probably there’s some configuration I’ve missed somewhere in the myriad microservices, or else the data I’m testing with isn’t a fair reflection on what they’re doing as-standard.
Following some staff changes, I have no teammates on this side of the Atlantic who could help me decipher this: a “quick question on Slack” wouldn’t solve this one until hours from now. It was time to start debugging!
But… maybe Claude could help? It’s got access to almost all the same code, logs, tools and browser windows I do. I started typing:
✨ What’s up next, Dan?
Context is key
It’s quite possible that Claude would have gone away, had a “think”, done some tests, and then come back to me with a believable answer. It might even have been correct, and I’d have been able to short-cut my way back to productivity (and I’d have time to make a mug of coffee and finish reading my emails while it did so). Then, I’d just have to check that it was right, make the change, and get on with things.
But I realised that it’d probably work faster (and cheaper, and using less energy) if it had slightly more context from the get-go, so I elaborated. The first thing I’d want to know if I were debugging this is what was actually happening behind the scenes. I dipped into my browser’s Network debugger and extracted the relevant output, adding it to my prompt:
✨ What’s up next, Dan?
{ content: 'test1', audience: [ 'one' ], status: 'draft' } and
the response is a HTTP 500 with the following stack trace:
That’s more like it, now I could let it get on with its work. But wait…
Rubberducking
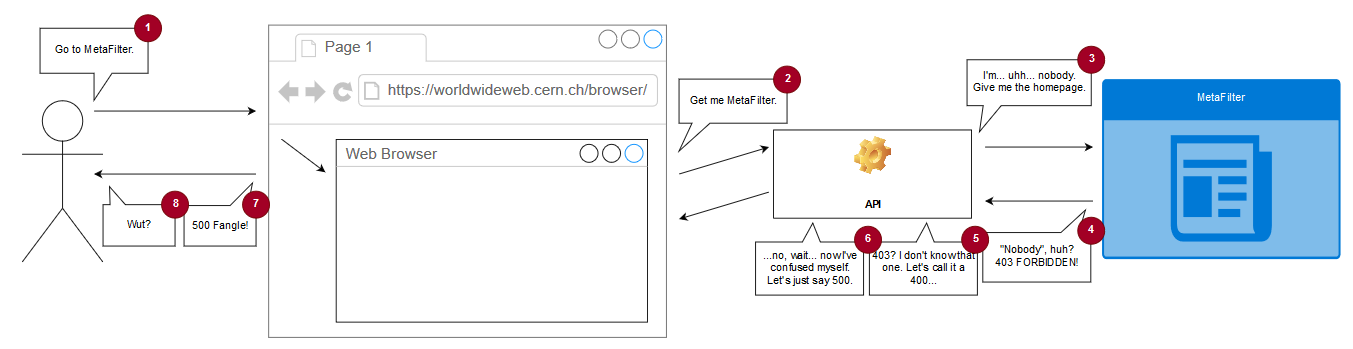
There’s a concept in computer programming called “rubberducking”. The name comes from an anecdote in The Pragmatic Programmer about a developer who, when stuck on a problem, would explain the code line-by-line to a rubber duck. The thinking is that talking-through a problem, even to someone (or something) who doesn’t understand it, can lead the speaker to insights they were otherwise missing.
I’ve done it myself many, many times: recruiting a convenient colleague or friend and talking them through the technical problem I was faced with, and inviting them to ask me to go into greater detail if I seemed to be skimming over anything, and I can promise that it can work.

The panel above is part of a series in which a sorceress called Cepper who’s coerced by her university into using Avian Intelligence (“AI”) – a robotic parrot5 that her headmaster insists is the future of magic. She experiments with it, finds it occasionally useful but more-often frustrating, attempts to implement her own local version but find that troublesome in different ways, and eventually settles on using an inanimate rubber duck instead. I get it, Cepper!
Let’s put that distraction aside for a moment and get back to the story of my broken development environment.
Clues in the stack trace
The top entry in the stack trace was an unsuccessful call to a different microservice, so I figured I’d pull its logs too, in order to further help direct the AI in the right direction6:
✨ What’s up next, Dan?
{ content: 'test1',
audience: [ 'one' ], status: 'draft' } and the response is a HTTP 500 with the following stack trace: The stack
trace suggests that a call is being made to the dojo backend service, where the following error log looks relevant:
I haven’t tried it, but I’m pretty confident that the LLM, after much number-crunching and a little warming-up of some datacentre somewhere, would get to the answer. But again, I found
something niggling inside me: the second-from top line in the dojo logs suggested that a connection was being made to a further, deeper microservice.
I should pull its logs too, I figured.
The final puzzle piece
As an aide mémoire – in a way I’ve taken to doing when taking notes or when talking to AI – I first typed what I was going to provide. This is useful if, for example, somebody distracts me at a key moment: it means you’ve got a jumping-off point predefined by my past self:
✨ What’s up next, Dan?
{ content: 'test1',
audience: [ 'one' ], status: 'draft' } and the response is a HTTP 500 with the following stack trace: The stack
trace suggests that a call is being made to the dojo backend service, where the following error log looks relevant: . It’s calling osiris, which says:
I dipped into the directory for
osiris
The entire event took only a few minutes. I’d find some information, type it into Claude’s input field, realise that more information could be valuable, and repeat.
By the time I’d finished describing the problem, I’d discovered the solution. That’s the essence of successful rubberducking. I didn’t need the AI at all. All I needed was the illusion of something that might be able to help if I just talked through what I was thinking.
I don’t know what the moral is, here.
I wonder if I’d have been as effective had I just typed into my text editor. I suppose I would have, but I wonder if I’d have been motivated to do so in the first place? I’ve tried rubberducking before by talking to an imaginary person, but I’ve never tried typing to one7; maybe I should start?
Footnotes
1 I’m pretty sure every engineering department nowadays has it’s rabid fanboys, but I’m pleased that for the most part my colleagues take a more-pragmatic and realistic outlook: balancing the potential benefits of LLM-assisted coding with its many shortfalls, downsides, and risks.
2 My experience of vibe-coding in a nutshell: LLMs are great at knocking out the easy 80% of any engineering problem, but often in a way that makes the remaining 20% – already the hard part – harder than it would have been if a human had done the first 80% (especially if it’s the same human and they can bring their learnings with them)… and I’m definitely not the only one who’s found that. I also suspect that the unsatisfying and unimproving task of shepherding a flock of agents to write code and then casually reviewing it is not significantly more-productive (which research backs up) and results in a significantly increased regression rate… but I’m ready to be proven wrong when more studies come out. In short: I continue to think that GenAI isn’t useless, but neither is it necessarily always worthwhile.
3 So long as what you’ve got them summarising is something you can later verify!
4 I’ve taken huge liberties with the strict factual accuracy to make this more-readable as well as to to not-expose things I probably oughtn’t. So before you swoop in to criticise my prompt-fu (not that I asked you, but I know there’s somebody out there who’s thinking about doing this right now), please note that none of the text in this page are what I actually wrote to the AI; it’s a figurative example.
5 A literal stochastic parrot, one might say!
6 I’d had an experience just the previous week in which it’d gone off on completely the wrong track, attempting to change code in order to “fix” what was ultimately a configuration or data problem, and so I thought it might be useful to give it some rails to follow, to start with.
7 Except insofar as this AI agent is an “imaginary person”, which it possibly already a step-too-far in implying personhood for my liking!







{kind=link}