The OpenStreetMap project consists of raw map data, collected and aggregated by thousands of users. This tutorial covers the configuration and maintenance of a web service using
Open Source Routing Machine (OSRM), which is based on the OpenStreetMap d
The OpenStreetMap project consists of raw map data, collected and aggregated by thousands of users. However, its open access policy
sparked a number of collateral projects, which collectively cover many of the features typically offered by commercial mapping services.
The most obvious advantage in using OpenStreetMap-based software over a commercial solution is economical convenience, because OpenStreetMap comes as free (both as in beer and as in
speech) software. The downside is that it takes a little configuration in order to setup a working web service.
This tutorial covers the configuration and maintenance of a web service which can answer questions such as:
What is the closest street to a given pair of coordinates?
What’s the best way to get from point A to point B?
How long does it take to get from point A to point B with a car, or by foot?
The software that makes this possible is an open-source project called Open Source Routing Machine (OSRM), which is based on the OpenStreetMap
data. Functionalities to embed OpenStreetMaps in Web pages are already provided out-of-the-box by APIs such as OpenLayers.
…
While slightly dated, I found this guide to be really valuable in my effort to set up a server that could spit out fastest walking routes around Oxford to support a PWA-driven tour of places relevant to J. R. R. Tolkien’s life, at my “day job”.
Tower of the Five Orders, Oxford OX1 3BW, United Kingdom.
Rating: ⭐⭐⭐⭐⭐
This iconic Oxford landmark is named for the architectural characteristics of each of its five floors. Each exhibits a different order – or “style” – of classical architecture: from
bottom to top – tuscan, doric, ionic, corinthian and composite. Part of the joy of “discovering” the tower, visiting as a tourist, comes from the fact that despite it’s size it’s
unlikely to be the first thing you see as you enter the quad: coming in from the Great Gate, for example, it won’t be until you turn around and look up that you see it… and even at a
glance you won’t necessarily observe its unusual architecture unless you’ve been told to look specifically at the columns.
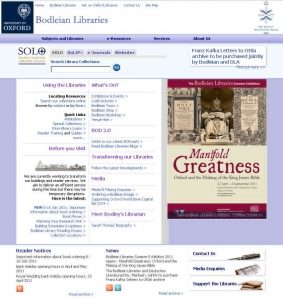
When I first started working at the Bodleian Libraries in 2011, their websites were looking… a little
dated. I’d soon spend some time working with a vendor (whose premises mysteriously caught fire while I was there, freeing me up to spend my
birthday in a bar) to develop a fresh, modern interface for our websites that, while not the be-all and end-all, was a huge leap forwards and has served us well for the last five years
or so.
The colour scheme, the layout, the fact that it didn’t remotely work on mobiles… there was a lot wrong with the old design of the Bodleian Libraries’ websites.
Fast-forward a little: in about 2015 we noticed a few strange anomalies in our Google Analytics data. For some reason, web addresses were appearing that didn’t exist anywhere on our
site! Most of these resulted from web visitors in Turkey, so we figured that some Turkish website had probably accidentally put our Google Analytics user ID number into their
code rather than their own. We filtered out the erroneous data – there wasn’t much of it; the other website was clearly significantly less-popular than ours – and carried on. Sometimes
we’d speculate about the identity of the other site, but mostly we didn’t even think about it.
How a Bodleian Libraries’ website might appear today. Pay attention, now: there’ll be a spot-the-difference competition in a moment.
Earlier this year, there was a spike in the volume of the traffic we were having to filter-out, so I took the time to investigate more-thoroughly. I determined that the offending
website belonged to the Library of Bilkent University, Turkey. I figured that some junior web developer there must have copy-pasted the
Bodleian’s Google Analytics code and forgotten to change the user ID, so I went to the website to take a look… but I was in for an even bigger surprise.
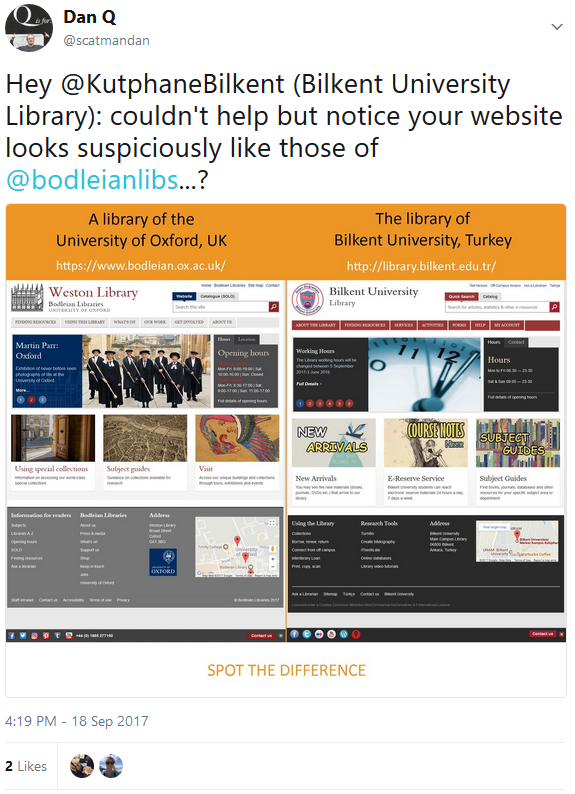
Hey, that looks… basically identical!
Whoah! The web design of a British university was completely ripped-off by a Turkish university! Mouth agape at the audacity, I clicked my way through several of their pages to try to
understand what had happened. It seemed inconceivable that it could be a coincidence, but perhaps it was supposed to be more of an homage than a copy-paste job? Or perhaps they
were ripped-off by an unscrupulous web designer? Or maybe it was somebody on the “inside”, like our vendor, acting unethically by re-selling the same custom design? I didn’t believe it
could be any of those things, but I had to be sure. So I started digging…
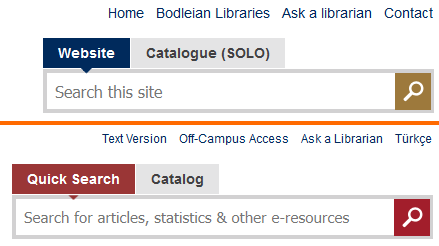
Our user research did indicate that putting the site and catalogue search tools like this was smart. Maybe they did the same research?
Menus are pretty common on many websites. They probably just had a similar idea.
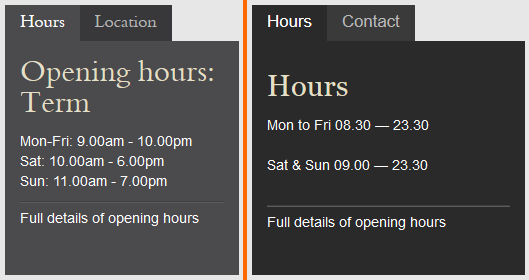
Tabs are a great way to show opening hours. Everybody knows that. And this is obviously just the a popular font.
Oh, you’ve got a slider too. With circles? And you’ve got an identical Javascript bug? Okay… now that’s a bit of a coincidence…
Okay, I’m getting a mite suspicious now. Surely we didn’t independently come up with this particular bit of design?
Well these are clearly different. Ours has a copyright notice, for example…
Oh, you DO have a copyright notice. Hang on, wait: you’ve not only stolen our design but you’ve declared it to be open-source???
I was almost flattered as I played this spot-the-difference competition, until I saw the copyright notice: stealing our design was galling enough, but then relicensing it in such a way
that they specifically encourage others to steal it too was another step entirely. Remember that we’re talking about an academic library, here: if anybody ought to
have a handle on copyright law then it’s a library!
I took a dive into the source code to see if this really was, as it appeared to be, a copy-paste-and-change-the-name job (rather than “merely” a rip-off of the entire graphic design),
and, sure enough…
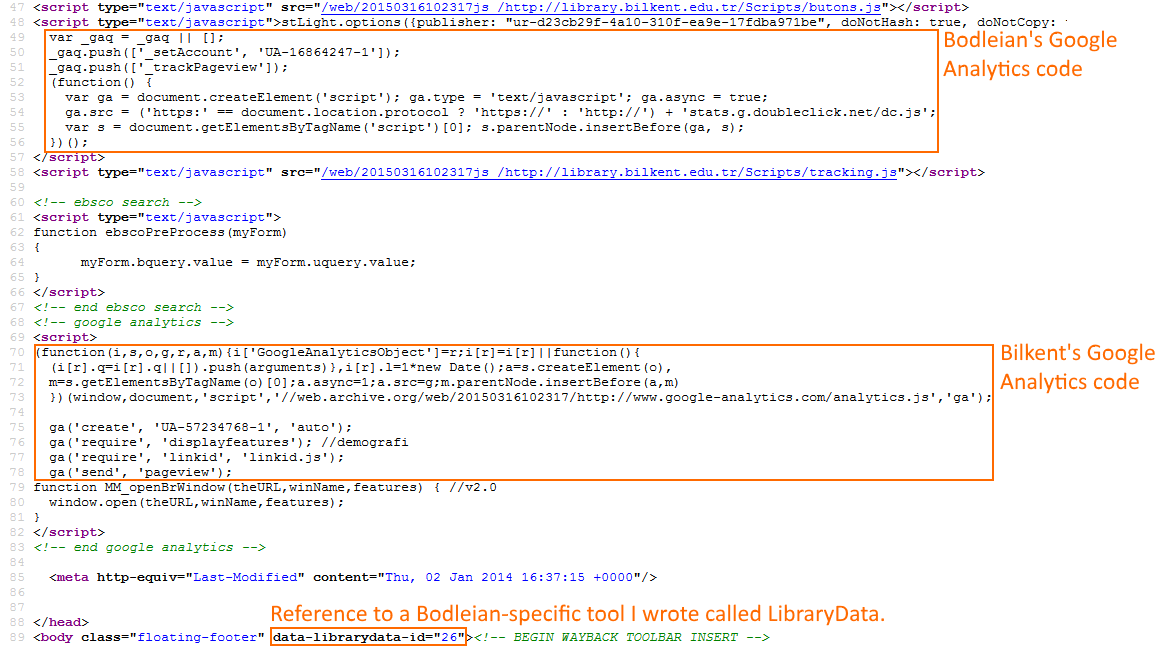
In their HTML source code, you can see both the Bodleian’s Google Analytics code (which they failed to remove) but also their own. And a data- attribute related to a project I wrote
and that means nothing to their site.
It looks like they’d just mirrored the site and done a search-and-replace for “Bodleian”, replacing it with “Bilkent”. Even the code’s spelling errors, comments, and indentation were
intact. The CSS was especially telling (as well as being chock-full of redundant code relating to things that appear on our website but not on theirs)…
The search-replace resulted in some icky grammar, like “the Bilkent” appearing in their code. And what’s this? That’s MY NAME in the middle of their source code!
So I reached out to them with a tweet:
My first tweet to Bilkent University Library contained a “spot the difference” competition.
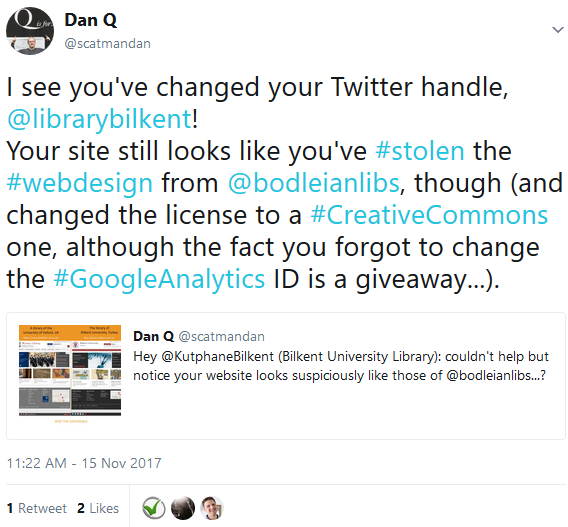
I didn’t get any response, although I did attract a handful of Turkish followers on Twitter. Later, they changed their Twitter handle and I thought I’d take advantage of the then-new
capability for longer tweets to have another go at getting their attention:
This time, I was a little less-sarcastic and a little more-aggressive. Turns out that’s all that was needed.
Clearly this was what it took to make the difference. I received an email from the personal email account of somebody claiming to be Taner
Korkmaz, Systems Librarian with Bilkent’s Technical Services team. He wrote (emphasis mine):
Dear Mr. Dan Q,
My name is Taner Korkmaz and I am the systems librarian at Bilkent. I am writing on behalf of Bilkent University Library, regarding your share about Bilkent on
your Twitter account.
Firstly, I would like to explain that there is no any relation between your tweet and our library Twitter handle change. The librarian who is Twitter admin at Bilkent did not notice
your first tweet. Another librarian took this job and decided to change the twitter handle because of the Turkish letters, abbreviations, English name requirement etc. The first name
was @KutphaneBilkent (kutuphane means library in Turkish) which is not clear and not easy to understand. Now, it is @LibraryBilkent.
About 4 years ago, we decided to change our library website, (and therefore) we reviewed the appearance and utility of the web pages.
We appreciated the simplicity and clarity of the user interface of University of Oxford Bodlien Library & Radcliffe Camera, as an academic pioneer in many fields. As a not profit institution, we took advantage of your template by using CSS and HTML, and added our own original content.
We thought it would not create a problem the idea of using CSS codes since on the web page there isn’t any license notice or any restriction related to
the content of the template, and since the licenses on the web pages are mainly more about content rather than templates.
The Library has its own Google Analytics and Search Console accounts and the related integrations for the web site statistical data tracking. We would like to point out that there is
a misunderstanding regarding this issue.
In 2017, we started to work on creating a new web page and we will renew our current web page very soon.
Thank you in advance for your attention to this matter and apologies for possible inconveniences.
Yours sincerely,
Or to put it another way: they decided that our copyright notice only applied to our content and not our design and took a copy of the latter.
Do you remember when I pointed out earlier that librarians should be expected to know their way around copyright law? Sigh.
They’ve now started removing evidence of their copy-pasting such as the duplicate Google Analytics code fragment and the references to LibraryData, but you can still find the unmodified
code via archive.org, if you like.
That probably ends my part in this little adventure, but I’ve passed everything on to the University of Oxford’s legal team in case any of them have anything to say about it. And now
I’ve got a new story to tell where web developers get together over a pint: the story of the time that I made a website for a university… and a different university stole it!
If you’re a tourist on one of “Jump Man” of Footprints Tours’ tours, I’m sure that the obligatory “jump for a photograph” moment at the end is a fun novelty. However, the novelty
quickly wears off when you work in one of the library offices right next to their usual spot, and the call of “3… 2… 1… JUMP!” is the loudest thing you hear all day, each day,
throughout the summer season.
Last month I got the opportunity to attend the EEBO-TCP Hackfest,
hosted in the (then still very-much under construction) Weston Library at my workplace. I’ve
done a couple of hackathons and similar get-togethers before, but this one was somewhat different in that it was unmistakably geared towards a different kind of geek than the
technology-minded folks that I usually see at these things. People like me, with a computer science background, were remarkably in the minority.
Me in the Weston Library (still under construction, as evidenced by the scaffolding in the background).
Instead, this particular hack event attracted a great number of folks from the humanities end of the spectrum. Which is understandable, given its theme: the Early English Books Online
Text Creation Partnership (EEBO-TCP) is an effort to digitise and make available in marked-up, machine-readable text formats a huge corpus of English-language books printed between 1475
and 1700. So: a little over three centuries of work including both household names (like Shakespeare, Galileo, Chaucer, Newton, Locke, and Hobbes) and an enormous number of others that
you’ll never have heard of.
After an introduction to the concept and the material, attendees engaged in a speed-networking event to share their thoughts prior to pitching their ideas.
The hackday event was scheduled to coincide with and celebrate the release of the first 25,000 texts into the public domain, and attendees were challenged to come up with ways to use
the newly-available data in any way they liked. As is common with any kind of hackathon, many of the attendees had come with their own ideas half-baked already, but as for me: I had no
idea what I’d end up doing! I’m not particularly familiar with the books of the 15th through 17th centuries and I’d never looked at the way in which the digitised texts had been
encoded. In short: I knew nothing.
The ideas pitch session quickly showed some overlap between different project ideas, and teams were split and reformed a few times as people found the best places for themselves.
Instead, I’d thought: there’ll be people here who need a geek. A major part of a lot of the freelance work I end up doing (and a lesser part of my work at the Bodleian, from
time to time) involves manipulating and mining data from disparate sources, and it seemed to me that these kinds of skills would be useful for a variety of different conceivable
projects.
XML may have been our interchange format, but everything fell into Excel in the end for speedy management even by less-technical team members.
I paired up with a chap called Stephen Gregg, a lecturer in 18th century literature from Bath Spa University. His idea
was to use this newly-open data to explore the frequency (and the change in frequency over the centuries) of particular structural features in early printed fiction: features like
chapters, illustrations, dedications, notes to the reader, encomia, and so on). This proved to be a perfect task for us to pair-up on, because he had the domain knowledge to ask
meaningful questions, and I had the the technical knowledge to write software that could extract the answers from the data. We shared our table with another pair, who had
technically-similar goals – looking at the change in the use of features like lists and tables (spoiler: lists were going out of fashion, tables were coming in, during the 17th century)
in alchemical textbooks – and ultimately I was able to pass on the software tools I’d written to them to adapt for their purposes, too.
A quick meeting on the relative importance of ‘chapters’ as a concept in 16th century literature. Half of the words that the academics are saying go over my head, but I’m formulating
XPath queries in my head while I wait.
And here’s where I made a discovery: the folks I was working with (and presumably academics of the humanities in general) have no idea quite how powerful data mining tools could be in
giving them new opportunities for research and analysis. Within two hours we were getting real results from our queries and were making amendments and refinements in our questions and
trying again. Within a further two hours we’d exhausted our original questions and, while the others were writing-up their findings in an attractive way, I was beginning to look at how
the structural differences between fiction and non-fiction might be usable as a training data set for an artificial intelligence that could learn to differentiate between the two,
providing yet more value from the dataset. And all the while, my teammates – who’d been used to looking at a single book at a time – were amazed by the possibilities we’d uncovered for
training computers to do simple tasks while reading thousands at once.
The area around Old St. Paul’s Cathedral was the place to be if you were a 16th century hipster looking for a new book.
Elsewhere at the hackathon, one group was trying to simulate the view of the shelves of booksellers around the old St. Paul’s Cathedral, another looked at the change in the popularity
of colour and fashion-related words over the period (especially challenging towards the beginning of the timeline, where spelling of colours was less-standardised than towards the end),
and a third came up with ways to make old playscripts accessible to modern performers.
Aside from an increase in the relative frequency of the use of colour words to describe yellow things, there’s not much to say about this graph.
At the end of the session we presented our findings – by which I mean, Stephen explained what they meant – and talked about the technology and its potential future impact – by which I
mean, I said what we’d like to allow others to do with it, if they’re so-inclined. And I explained how I’d come to learn over the course of the day what the word encomium meant.
Presenting our findings in amazing technicolour Excel.
My personal favourite contribution from the event was by Sarah Cole, who adapted the text of a story about a witch
trial into a piece of interactive fiction, powered by Twine/Twee, and then
allowed us as an audience to collectively “play” her game. I love the idea of making old artefacts more-accessible to modern audiences through new media, and this was a fun and
innovative way to achieve this. You can even play her game
online!
(by the way: for those of you who enjoy my IF recommendations: have a
look at Detritus; it’s a delightful little experimental/experiential game)
Things are about to go very badly for Joan Buts.
But while that was clearly my favourite, the judges were far more impressed by the work of my teammate and I, as well as the team who’d adapted my software and used it to investigate
different features of the corpus, and decided to divide the cash price between the four of us. Which was especially awesome, because I hadn’t even realised that there was a
prize to be had, and I made the most of it at the Drinking About Museums event
I attended later in the day.
Cold hard cash! This’ll be useful at the bar, later!
If there’s a moral to take from all of this, it’s that you shouldn’t let your background limit your involvement in “hackathon”-like events. This event was geared towards literature,
history, linguistics, and the study of the book… but clearly there was value in me – a computer geek, first and foremost – being there. Similarly, a hack event I attended last year, while clearly tech-focussed, wouldn’t have
been as good as it was were it not for the diversity of the attendees, who included a good number of artists and entrepreneurs as well as the obligatory hackers.
“Nice work, Stephen.” “Nice work, Dan.”
But for me, I think the greatest lesson is that humanities researchers can benefit from thinking a little bit like computer scientists, once in a while. The code I wrote (which uses Ruby and Nokogiri) is freely
available for use and adaptation, and while I’ve no idea whether or not it’ll ever be useful to anybody again, what it represents is the research benefits of
inter-disciplinary collaboration. It pleases me to see things like the “Library Carpentry” (software for research, with a library slant) seeming to take off.
Anybody who has, like me, come into contact with the Squiz Matrix CMS for any length of time will
have come across the reasonably easy-to-read but remarkably long CAPTCHA that it
shows. These are especially-noticeable in its administrative interface, where it uses them as an exaggerated and somewhat painful “are you sure?” – restarting the CMS’s internal
crontab manager, for example, requires that the administrator types a massive 25-letter CAPTCHA.
Four long CAPTCHA from the Squiz Matrix CMS.
But there’s another interesting phenomenon that one begins to notice after seeing enough of the back-end CAPTCHA that appear. Strange patterns of letters that appear in sequence
more-often than would be expected by chance. If you’re a fan of wordsearches, take a look at the composite screenshot above: can you find a person’s name in each of the four lines?
Four long CAPTCHA from the Squiz Matrix CMS, with the names Greg, Dom, Blair and Marc highlighted.
There are four names – Greg, Dom, Blair and Marc – which routinely appear in these CAPTCHA.
Blair, being the longest name, was the first that I noticed, and at first I thought that it might represent a fault in the pseudorandom number generation being used that was resulting
in a higher-than-normal frequency of this combination of letters. Another idea I toyed with was that the CAPTCHA text might be being entirely generated from a set of pronounceable
syllables (which is a reasonable way to generate one-time passwords that resist entry errors resulting from reading difficulties: in fact, we do this at Three Rings), in which these four names also appear, but by now I’d have
thought that I’d have noticed this in other patterns, and I hadn’t.
Instead, then, I had to conclude that these names were some variety of Easter Egg.
Smiley decorated eggs. Picture courtesy Kate Ter Haar.
I was curious about where they were coming from, so I searched the source code, but while I found plenty of references to Greg Sherwood, Marc McIntyre, and Blair Robertson. I
couldn’t find Dom, but I’ve since come to discover that he must be Dominic Wong – these four were, according to Greg’s blog – developers with Squiz in the early 2000s, and seemingly saw themselves as a
dynamic foursome responsible for the majority of the CMS’s code (which, if the comment headers are to be believed, remains true).
Greg, Marc, Blair and Dom, as depicted in Greg’s 2007 blog post.
That still didn’t answer for me why searching for their names in the source didn’t find the responsible code. I started digging through the CMS’s source code, where I eventually
found fudge/general/general.inc (a lot of Squiz CMS code is buried in a folder called “fudge”, and web addresses used internally sometimes contain this word, too: I’d like to
believe that it’s being used as a noun and that the developers were just fans of the buttery sweet, but I have a horrible feeling that it was used in its popular verb form). In that file, I found
this function definition:
/**
* Generates a string to be used for a security key
*
* @param int $key_len the length of the random string to display in the image
* @param boolean $include_uppercase include uppercase characters in the generated password
* @param boolean $include_numbers include numbers in the generated password
*
* @return string
* @access public
*/
function generate_security_key($key_len, $include_uppercase = FALSE, $include_numbers = FALSE) {
$k = random_password($key_len, $include_uppercase, $include_numbers);
if ($key_len > 10) {
$gl = Array('YmxhaXI=', 'Z3JlZw==', 'bWFyYw==', 'ZG9t');
$g = base64_decode($gl[rand(0, (count($gl) - 1)) ]);
$pos = rand(1, ($key_len - strlen($g)));
$k = substr($k, 0, $pos) . $g . substr($k, ($pos + strlen($g)));
}
return $k;
} //end generate_security_key()
For the benefit of those of you who don’t speak PHP, especially PHP that’s been made deliberately hard to decipher, here’s what’s happening when “generate_security_key” is being called:
A random password is being generated.
If that password is longer than 10 characters, a random part of it is being replaced with either “blair”, “greg”, “marc”, or “dom”. The reason that you can’t see these words in the
code is that they’re trivially-encoded using a scheme called Base64 – YmxhaXI=, Z3JlZw==, bWFyYw==, and ZG9t are Base64 representations of the four
names.
This seems like a strange choice of Easter Egg: immortalising the names of your developers in CAPTCHA. It seems like a strange choice especially because this somewhat weakens the
(already-weak) CAPTCHA, because an attacking robot can quickly be configured to know that a 11+-letter codeword will always consist of letters and exactly one instance of one of these
four names: in fact, knowing that a CAPTCHA will always contain one of these four and that I can refresh until I get one that I like, I can quickly turn an
11-letter CAPTCHA into a 6-letter one by simply refreshing until I get one with the longest name – Blair – in it!
A lot has been written about how Easter Eggs undermine software security (in
exchange for a small boost to developer morale) – that’s a major
part of why Microsoft has banned them from its operating systems (and, for the most part, Apple has too). Given that these particular CAPTCHA in Squiz CMS are often nothing more than
awkward-looking “are you sure?” dialogs, I’m not concerned about the direct security implications, but it does make me worry a little about the developer culture that produced them.
I know that this Easter Egg might be harmless, but there’s no way for me to know (short of auditing the entire system) what other Easter Eggs might be hiding under the
surface and what they do, especially if the developers have, as in this case, worked to cover their tracks! It’s certainly the kind of thing I’d worry about if I were, I don’t
know, a major government who use Squiz software, especially their cloud-hosted variants
which are harder to effectively audit. Just a thought.
On the way out to the French Alps for a week of skiing, and we had enough air miles to upgrade to business class on the way out, so I’m sat in the lounge enjoying complimentary gin &
tonic and croissants. 10 in the morning, and I’m already buzzed: after a long and hectic few months, I’m really glad to be off on holiday!
Aaaand…. right before I left I put in an application for my boss’s job, which she vacated a few months ago. Should hear by the time I get back whether I’m being invited to interview,
so that’s exciting too!
Anyway: just wanted to share my excitement with my favourite MegaMasons. If I’m not online much this week, you’ll know why! Have a great week, folks: love you all!
Despite having helped the CO to hunt for hiding spots, it still took me a while to retrieve this one as muggles kept passing by! Got there in the eve. TFTC!
An easy enough find made easier by the fact that I helped find the hiding spot for the owner! Came by on the way home from work to drop off a Georgian. TFTC!






















{kind=link}