how do you find things you want to blog about? is it just about letting out one’s thoughts and feelings and some sort of catch-up to one’s latest projects?
probably will start a blog of my own soon™ :3
What an interesting question, and not one I’ve heard before.
I’ve not heard it before… probably because my blogging is… eclectic! Sometimes I blog about technology. Sometimes I blog about geocaching and geohashing. Sometimes I blog about what’s
going on in my life. Sometimes I blog about news, politics, and what’s going on in the world. Sometimes I blog just to share weird things I’ve seen on the Internet.
(I’ve sometimes worried that my approach to blogging alienates every conceivable audience. I mean: who wants to read all the topics above? But it helped me a lot to
remind myself that I blog, primarily, for myself. I am my own target audience! Everybody else comes second.)
I certainly have more things that I want to blog about than that I actually do. And even for the things I start, I often don’t finish: I’ve got
literally hundreds of incomplete drafts, and perhaps even more “concepts” noted down in Obsidian that I’ve never even started writing about.
It’s all a little skewed right now because I’ve kinda been trying to achieve the #100DaysToOffload challenge – which I’ve achieved for six consecutive years so far – in the first hundred days of 2026! Given that it’s called “100 Days To
Offload” I don’t feel like it’s legitimate to claim it for 100 blog posts that aren’t on different days (otherwise I’d have achieved it already, with about 149 in the first 82
days of this year).
So yeah: I’m currently working towards a hundred-day streak, and that’s almost certainly having me blog more than I might “organically”. To that
end, I’m often digging out old drafts and finalising them, right now, or else being more “impulsive” in my blogging, compared to the norm. This lunchtime, for example, I took a cycle,
and it gave me a sense of normalcy that’s been somewhat missing in my life recently, and I considered writing a blog post about the experience. Impulsive, y’see!
But in general… my “process”, such as it is… is that I just look at what interests me today. There’s no secret to blogging as prolifically as I do: you’ve
just got to start writing, and then keep writing. That’s all there is to it.
Many years ago, someone tried to get me into cryptocurrencies. “They’re the future of money!” they said. I replied saying that I’d rather wait until they were more useful, less
volatile, easier to use, and utterly reliable.
“You don’t want to get left behind, do you?” They countered.
That struck me as a bizarre sentiment. What is there to be left behind from? If BitCoin (or whatever) is going to liberate us all from economic drudgery, what’s the point
of “getting in early”? It’ll still be there tomorrow and I can join the journey whenever it is sensible for me.
…
100%. If I “get in early” on something, it’s because that thing interests me, not because I’m betting on its future. With a hundred new ideas a day and only one of them “making it”,
it’s a fools’ game to try to jump on board every bandwagon that comes along.
With cryptocurrencies, though, I’m fortunate enough to have an even better comeback at the cryptobros that try to shill me whatever made-up currency they’re “investing” in
today: I’ve already done better than they ever will, at them.
When Bitcoin first appeared, I took a technical interest in it. I genuinely never anticipated it’d take off (I made the same incorrect
guess with MP3s, too!), but I thought it was a fun concept to play about with. The only Bitcoins I ever paid for must’ve been worth an average of 50p each, or so.
I sold my entire wallet of Bitcoins when they hit around £750 each. I know a tulip economy when I see one, I thought. Plus: I was
no longer interested in blockchains now I was seeing how they were actually being used: my interest had been entirely in the technology and its applications, not in the actual idea of a
currency!
Sure, I kick myself ocassionally, given that I later saw the value rise to tens of thousands of pounds each. But hey, I was never in it for the money anyway.
So yeah, I tell cryptobros; I already made a 1500% ROI on cryptocurrency. And no, I’m not buying any cryptocurrencies any more. Whatever they think “getting in early” was, they’re
wrong, because I was there years ahead of them and I wasn’t even doing it to “get in early”; I did it because it was interesting. And honestly, isn’t that a better story to be able to
tell?
…
I feel the same way about the current crop of AI tools. I’ve tried a bunch of them. Some are good. Most are a bit shit. Few are useful to me as they are now.
…
If this tech is as amazing as you say it is, I’ll be able to pick it up and become productive on a timescale of my choosing not yours.
…
Yup, that’s the attitude I’m taking.
I play with new AI technologies, sometimes. I don’t do it because I’m afraid of being left behind because – as you say – if a technology is transformative, we’ll all get to catch up
eventually.
Do you think that people who had smartphones first are benefitting today because they “got in early” on something that later became mainstream?
Of course they’re not. Their experience is eventually exactly the same as everybody else’s, just like it was for everybody who “got in early” on hype trains whose final station came
early, like Compuserve GO-words, WAP, Beenz.com, WebTV, the CueCat, m-Commerce, HD-DVD, the JooJoo, or Google+.
Ok, I’m NOT an immediate fan of “vibe coding” and overusing LLMs in programming. I have a healthy amount of skepticism
about the use of these tools, mostly related to the maintainability of the code, security, privacy, and a dozen other more factors.
But some arguments I’ve seen from developers about not using the tools because it means they “will lose their coding skills” its just bonkers. Especially in a professional context.
Imagine you go to a carpenter, and they say “this will take 2x the time because I don’t use power tools, they make me feel like I’m losing my competence in manual skills”. It’s your
job to deliver software using the most efficient and accurate methods possible.
Sure, it is essential that you keep your skills sharp, but being purposfully less effective in your job to keep them sharp is a red flag. And in an industry made of abstractions to
increase productivity (we’re no longer coding in Assembly last time I checked), this makes even less sense.
/rant
I’m in two minds on this (as I’ve hinted before). The carpenter analogy doesn’t really hold, because the underlying skill of carpentry
is agnostic to whether or not you use power tools: it’s about understanding the material properties of woods, the shapes of joins, the ways structures are strong and where they are
weak, the mathematics and geometry that make design possible… none of which are taken over by power tools.
25+ years ago I wrote most of my Perl/PHP code without an Internet connection. When you wanted to deploy you’d “dial up”, FTP some files around, then check it had worked. In that
environment, I memorised a lot more. Take PHP’s date formatting strings, for example: I used to have them down by heart! And even when I didn’t, I knew approximately the right spot to
flip the right book open to that I’d be able to look it up quickly.
“Always-on” broadband Internet gradually stole that skill from me. It’s so easy for me to just go to the right page on php.net and have the answer I need right in front of me! Nowadays, I depend
on that Internet connection (I don’t even have the book any more!).
A power tool targets a carpenter’s production speed,
not their knowledge-recovery speed.
Will I experience the same thing from my LLM usage, someday?
Maybe I am just seeing this wrong, but I experience that a lot of people simply don’t reply to emails/messages these days any more. I get that emails can be exhausting at times,
but really, I am answering any email I get. Sometimes late, but I answer.
…
And it is so easy. I can really live with a short message stating no interest or even a “Fuck off”, which is way better as it does not leave me with nothing and not knowing
whether my message arrived or not.
…
I try to reply to every personal (i.e. from a human, not an automated service, not not including spam) email, unless it very-clearly doesn’t need one: e.g. it’s the end of a
conversation or was the response to my query. I suppose that I’m trying to say is that an initial contact with me – a new conversation – should always get a response,
because that reassures you that it arrived.
But I see the trend, and I’ve been part of it. Thanks to my many points of presence on the Web, I receive messages on a great number of subjects. Sometimes, if – say – one arrives while
I’m travelling, and then when I get around to properly reading it I think it deserves a well-thought out and researched and reasoned answer… I’ll save it for later. And that’s when the
trouble starts.
Drifting down my Inbox, it falls out of sight and mind. Whenever I see it, I’m back to square one: having not yet made the time and space to give it the consideration it deserves. The
longer it remains there, the more the pressure builds: if it took me three weeks to reply to this email, my reply has to be really good, right? Just firing off a
“thanks for your email, sorry I haven’t given it a proper reply yet” now would just be awkward. So it sits longer and stagnates. Eventually, crushed under the weight of the
emails above it and of my growing awkwardness with the situation, it gets deleted.
Usually that takes about six months, but in one particularly terrible case – a friend shared with me a draft of some fiction they’d been writing – it took eight years. Eight
years of a message sitting in my Inbox, begging me to write a proper response, and me not doing so because any reply I could by-that-point produce nothing that would possibility justify
the time it took to respond.
(At some points in my past I’ve had the same problem with blogging: if I take a month without writing a post, it feels like the pressure to produce a real banger is so high that it
makes me stagnate. That’s part of the reason that nowadays I semi-automate the inclusion of so much of my life into my blog: ad-hoc notes, checkins to geocaches, etc.
Blogging more helps fight the pressure.)
I’d like to think I do better nowadays. I don’t think I’ve got any unanswered personal email in my Inbox (though now I mention it, I think there’s a mailing list I feel like I’m overdue
to chip in on).
But on behalf of the people who don’t reliably reply because it feels like too much pressure if you missed the opportunity to do so immediately, I have some empathy. I’ve been there,
and the struggle is real. It’s possible, like me, to come out the other side of a mindset of letting email stagnate because you can’t find the words to justify the time it took
to respond.
(Anybody who’s got different reasons to mine for failing to respond to personal emails can speak for themselves. Though – possibly – not by email.)
Had a fight with the Content-Security-Policy header today. Turns out, I won, but not without sacrifices.
Apparently I can’t just insert <style> tags into my posts anymore, because otherwise I’d have to somehow either put nonces on them, or hash their content (which would
be more preferrable, because that way it remains static).
I could probably do the latter by rewriting HTML at publish-time, but I’d need to hook into my Markdown parser and process HTML for that, and, well, that’s really complicated,
isn’t it? (It probably is no harder than searching for Webmention links, and I’m overthinking it.)
I’ve had this exact same battle.
Obviously the intended way to use nonces in a Content-Security-Policy is to have the nonce generated, injected, and served in a single operation. So in PHP,
perhaps, you might do something like this:
<?php$nonce=bin2hex(random_bytes(16));
header("Content-Security-Policy: script-src 'nonce-$nonce'");
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>PHP CSP Nonce Test</title>
</head>
<body>
<h1>PHP CSP Nonce Test</h1>
<p>
JavaScript did not run.
</p>
<!-- This JS has a valid nonce: -->
<script nonce="<?phpecho$nonce; ?>">
document.querySelector('p').textContent = 'JavaScript ran successfully.';
</script>
<!-- This JS does not: -->
<script nonce="wrong-nonce">
alert('The bad guys won!');
</script>
</body>
</html>
Viewing this page in a browser (with Javascript enabled) should show the text “JavaScript ran successfully.”, but should not show an alertbox containing the text “The bad
guys won!”.
But for folks like me – and you too, Vika,, from the sounds of things – who serve most of their pages, most of the time, from the cache or from static HTML files… and who add the CSP
header on using webserver configuration… this approach just doesn’t work.
I experimented with a few solutions:
A long-lived nonce that rotates.
CSP allows you to specify multiple nonces, so I considered having a rotating nonce that was applied to pages (which were then cached for a period) and delivered
by the header… and then a few hours later a new nonce would be generated and used for future page generations and appended to the header… and after the
cache expiry time the oldest nonces were rotated-out of the header and became invalid.
Dynamic nonce injection.
I experimented with having the webserver parse pages and add nonces: randomly generating a nonce, putting it in the header, and then basically doing a
s/<script/<script nonce="..."/ to search-and-replace it in.
Both of these are terrible solutions. The first one leaves a window of, in my case, about 24 hours during which a successfully-injected script can be executed. The second one
effectively allowlists all scripts, regardless of their provenance. I realised that what I was doing was security theatre: seeking to boost my A-rating to an A+-rating on SecurityHeaders.com without actually improving security at all.
But the second approach gave me an idea. I could have a server-side secret that gets search-replaced out. E.g. if I “signed” all of my legitimate scripts with something like
<script nonce="dans-secret-key-goes-here" ...> then I could replace s/dans-secret-key-goes-here/actual-nonce-goes-here/ and thus have the best of both
worlds: static, cacheable pages, and actual untamperable nonces. So long as I took care to ensure that the pages were never delivered to anybody with the secret key still
intact, I’d be sorted!
Alternatively, I was looking into whether Caddy can do something like mod_asis does for Apache: that is, serve a
file “as is”, with headers included in the file. That way, I could have the CSP header generated with the page and then saved into the cache, so it’s delivered with the same
none every time… until the page changes. I’d love more webservers to have an “as is” mode, but I appreciate that might be a big ask (Apache’s mechanism, I suspect,
exploits the fact that HTTP/1.0 and HTTP/1.1 literally send headers, followed by two CRLFs, then content… but that’s not what happens in HTTP/2+).
So yeah, I’ll probably do a server-side-secret approach, down the line. Maybe that’ll work for you, too.
When you’re writing online, being unique doesn’t matter nearly as much as being found.
I’m not sure I could disagree more. But I’ve jumped in half way through his post. Let’s backtrack a bit.
Andy begins:
A blogger showed me his website the other day.
…
But no one was reading it.
Firstly: let’s just observe that you were shown a website… and now you’re talking about it… but you haven’t linked to it? You’re complaining about its lack of discoverability,
while simultaneously being part of the problem.
Hyperlinks remain, as they have been since the mid-to-late 1990s, a primary mechanism in helping search engines’ spiders to discover new sites, and nowadays they’re doubly-important
because they help establish legitimacy.
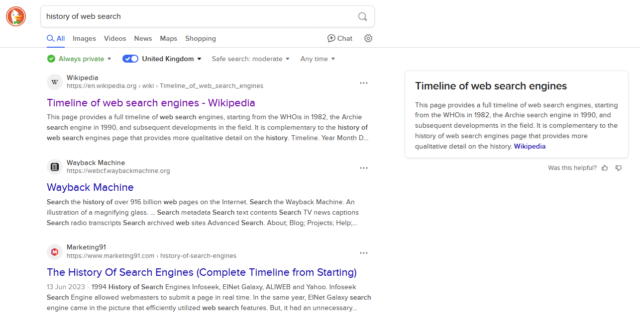
When you search for, say, “history of web search” and this Wikipedia article is at the top, a significant
reason for that is that people link to that page when talking about the history of web search! A secondary reason is that lots of people link to Wikipedia in
general.
Your mileage may vary depending on your preferred search engine and other factors.
Berating somebody for an unindexed site… but not linking to that site… feels awfully-close to victim-blaming!
(Especially recently, as still-dominant search engine Google continues to make it harder and harder for “new” sites to get onto the ladder.)
When I asked him why he didn’t just use WordPress or Bear Blog, he looked offended.
“Those are so basic. Everyone uses those. I wanted something unique.”
I’m not sure I understand the logic of the person whose argument against e.g. WordPress is that it’s not “unique”. There are lots of great reasons that you might use WordPress. There
are lots of great reasons that you might not. The right choice of CMS should be based on a variety of factors.
It’s possible that the person being referred to meant “customisable”. They’d still be wrong (in the case of WordPress, at least: Bear Blog offers significantly less customisation
options, which is fine if the other features are what you’re looking for), but anyway: the short of it is that I briefly agreed, here, until:
WordPress powers about 43% of all websites. That means search engines know exactly how to read WordPress sites.
They know where to look for the content, the metadata, the tags.
Let’s correct the points here:
Search engines know exactly how to read HTML. WordPress outputs HTML. (If you’re outputting HTML, your site can be indexed. Hell, even that isn’t a firm
requirement: my plaintext-only blog shows up in search engines!)
Web standards dictate how content, metadata, and tags should be laid out. A search engine’s spider doesn’t look at your site and go “hey, it’s WordPress, so I need to
look for this“. Instead, it’ll generally look for content and metadata based on established standards. Titles, headings, <meta> tags, semantic elements:
these are the things a search engine looks for.
Sure, WordPress gets those things right. But they’re not hard to get right. You shouldn’t use WordPress (or Bear, or anything else) based just on the fact
that it exposes metadata correctly. Any site can do this. And because what’s eventually exposed to the search engine – and to the user – is HTML code… which is independent of the CMS
that generated it… it doesn’t have to matter what the underlying CMS is.
Then there’s some more confusion:
Here’s what matters: WordPress and other major platforms have spent years optimising for search engines and social sharing.
They’ve spent millions making sure posts load fast.
This sounds like it’s conflating WordPress (the open-source CMS) with one or more of several WordPress hosting providers (probably WordPress.com). That’s a common mistake, but it is a mistake.
WordPress can do terrible SEO. WordPress can be really slow. Trust me: in a previous life I’ve made a part of my living out of fixing and improving people’s WordPress-powered websites!
A large part of this comes from WordPress’s flexibility: the theme you choose, for example, can completely change the functionality of your site. Inspired by my plain text blog,
Terence Eden made a WordPress theme that does the same thing! That WordPress theme completely
upends the way that most people would use WordPress, but it’s still fundamentally WordPress, even though it exposes to search engines no HTML code, no metadata,
and no tags.
WordPress can also do great SEO, and it can be really fast. A properly-configured WordPress site can be a well-oiled machine. But if you conflate WordPress itself with its output,
you’re arguing against a straw man.
Don’t get me wrong: I love WordPress! But I dislike people making the false claim that if you’re not using it (or another popular blogging tool), you’re destined to fail at SEO. There’s
nothing “magical” about WordPress. It just takes content and renders HTML, in the end!
But all of this is moot, perhaps, when we get back to that first point:
When you’re writing online, being unique doesn’t matter nearly as much as being found.
This entire statement presupposes the purpose of “writing online”.
It’s 100% okay to write for yourself, first and foremost. It’s also okay to write for a small target audience, like for your friends or family. It’s okay to write content that
isn’t exposed to search engines (consider all of the wonderful content that my fellow RSS Club members put out, sometimes!). It’s
okay to write just for the joy of making things.
A website doesn’t have to be “professional”, as Andy’s post goes on to imply. A website doesn’t have to be anything in particular. A website can just… be. And that’s
enough.
[a quote from Ed Catmull’s book Creativity Inc.] made me think a lot about the early days of Gutenberg and the huge
resistance it had in the community, including causing the fork of ClassicPress. Now that we’re much further along there’s a pretty widespread acceptance of Gutenberg, and it’s
responsible for the vast majority of all WP posts and pages made, however if we had taken a vote for whether it should happen or not, it probably wouldn’t have ever gotten off the
ground.
What’s funny is if you go back even further, using a visual WYSIWYG editor in the first place was very controversial, and many people didn’t want the classic editor brought into
WordPress.
Long-term WordPresser here; I remember when 2.0 integrated TinyMCE and it was absolutely necessary to ensure that raw HTML editing
remained an option, clear and up-front. Which I’m glad of: I probably hit raw HTML about once a month when I’m blogging, to this day!
I was among those who strongly resisted Gutenberg. Nowadays I use it every day! But my primary personal blog, which was already almost six years old when it migrated to WordPress 1.2
back in 2004, still uses the classic editor. I enjoy that I have the freedom to do that.
When we talk about open source meaning freedom, this is the kind of thing we mean. Years ago, I was in charge of the CMS for a major academic
institution when the company behind that CMS made a gradual and concerted effort to become less-open-source. That CMS didn’t have the ecosystem
and community around it that WordPress has, and so no forks took off, and so my employer got locked-in to upgrading to a new version that was mostly-closed-source and was in some ways
inferior. Ugh.
(Incidentally, I got them off that CMS: they’re now using a mixture of WordPress and Drupal for most of their
systems. Open source won.)
Change isn’t always good. But open source provides the freedom to embrace change in the way that suits you best.
Note that there are differences in how they are described in some cases:
“grinning face” is also “beaming face”
“beaming face” is also a “smiling face”
“open mouth” is described by JAWS/Narrator but not by NVDA/VoiceOver
“big eyes” are described by NVDA/VoiceOver but not by JAWS/Narrator
“cold sweat” is “sweat” and also “sweat drop”
…
The differences don’t matter to me (but I am just one and not the intended consumer), as I usually experience just the symbol. Reading the text descriptions is useful though as
quite often I have no idea what the symbols are meant to represent. It is also true that emoji’s take on different meanings in different contexts and to different people. For
example I thought 🤙 meant “no worries” but its description is “call me hand”, what do I know 🤷
What Steve observes is representative of a the two sides of emoji’s biggest problem, which are
that when people use them for their figurative meaning, there’s a chance that they have a different interpretation than others (this is, of course, a risk with any communication,
although the effect is perhaps more-pronounced when abbreviating1),
and
when people use them for the literal image they show, it can appear differently: consider the inevitable confusion that arises from the fact that Twitter earlier this year
changed the “gun” emoji, which everybody changed to look like a water pistol
to the extent that the Emoji Consortium changed its official description, which is likely to be used by screen readers, to “water pistol”, back to looking like a firearm. 🤦
But the thing Steve’s post really left me thinking about was a moment from Season 13, Episode 1 of Would I Lie To
You? (still available on iPlayer!), during which blind comedian Chris McCausland described how the screen reader on his phone processes emoji:
My phone talks, so it reads everything out. And just to give you an insight, even the emojis… if you use an emoji it tells you what the emoji is… and the smiley face – the main
smiley face – specifically for blind people… that one is called “smiling face with normal eyes”. I don’t know if I’m expected to use the smiling face with sunglasses?
I don’t know if it’s true that Chris’s phone actually describes the generic smileys as having “normal eyes”, but it certainly makes for a fantastic gag.
Footnotes
1 I remember an occasion where a generational divide resulted in a hilarious difference of
interpretation of a common acronym, for example. My friend Ash, like most people of their generation, understood “LOL” to mean “laughing out loud”, i.e. an expression of humour. Their
dad still used it in the previous sense of “lots of love”. And so there was a moment of shock and confusion when Ash’s dad,
fondly recalling their recently-deceased mother, sent Ash a text message saying something like: “Thought of your mum today. I miss her. LOL.”.
If you’ve ever found yourself missing the “good old days” of the #web, what is it that you miss? (Interpret “it” broadly: specific websites? types of activities? feelings?
etc.) And approximately when were those good old days?
No wrong answers — I’m working on an article and wanted to get some outside thoughts.
I miss the era of personal web sites started out of genuine admiration for something, rather than out of a desire to farm a few advertising pennies
This. You wanted to identify a song? Type some of the lyrics into a search engine and hope that somebody transcribed the same lyrics onto their fansite. You needed to know a fact?
Better hope some guru had taken the time to share it, or it’d be time for a trip to the library
Not having information instantly easy to find meant that you really treasured your online discoveries. You’d bookmark the best sites on whatever topics you cared about and feel no
awkwardness about emailing a fellow netizen (or signing their guestbook to tell them) about a resource they might like. And then you’d check back, manually, from time to time to see
what was new.
The young Web was still magical and powerful, but the effort to payoff ratio was harder, and that made you appreciate your own and other people’s efforts more.
After a first attempt at mobile blogging, I found a process that works better for my work flow.
Throughout the day, I have ideas and need to write them down. This could be a coding process, a thought to remember, the start of a blog post, and more. I love a good notes app. I’ve
gone through quite a few and use a few for different things. Lately it’s been Simplenote.
…
As I took part in Bloganuary and began what’ll hopefully become a fifth
consecutive year of 100 Days To Offload, I started to hate my approach to mobile blogging and seek something better, too. My blog’s on WordPress, but it’s so highly-customised that
I can’t meaningfully use any of the standard apps, and I find the mobile interface too slow and clunky to use over anything less than a great Internet connection… which – living out in
the sticks – I don’t routinely have when I’m out and about. So my blogging almost-exclusively takes place at my desktop or laptop.
But your experience of using a notetaking app is reasonably inspiring. I’m almost never away from a “real” computer for more than a day, so there’s no reason I can’t simply write into
such an app, let it sync, and copy-paste into a blog post (and make any tweaks) when I’m sitting at a proper keyboard! I’m using Obsidian for
notetaking, and it Syncthing‘s to my other computers, so I should absolutely be leveraging that. I already have an Obsidian folder full of
“blog post ideas”… why shouldn’t I just write blog posts there.
This is a reply to a post published elsewhere. Its content might be duplicated as a traditional comment at the original source.
In his blog post “The ethics of syndicating comments using WebMentions”, Terence Eden said:
…
I want to see what people are writing in public about my posts. I also want to direct people to the conversations which are happening elsewhere on the web. But people – quite
rightly – might not want their content permanently stored by my site.
So I think I have a few options.
Do nothing. My site; my rules. If you don’t want me to grab your hot takes, don’t post them in public. (Feels a bit rude, TBQH.)
Be reactive. If someone asks me to remove their content, do so. (But, of course, how will they know I’ve made a copy?)
Stop syndicating comments. (I don’t wanna!)
Replace the verbatim comments with a link saying “Fred mentioned this article on Twitter” . (A bit of a disruptive experience for readers.)
Use oEmbed to capture the user’s comment and dynamically load it from the 3rd party site. That would update automatically if the user changes their name or deleted the
comment. (A massive faff to set up.)
…
Terence describes a problem that I’ve wrestled with myself. If somebody comments directly on my blog using the form at the bottom of a post, that’s a pretty strong indicator of
them giving their consent for their comment to be published at the bottom of that post (at my discretion). If somebody publicly replies somewhere my post is syndicated, that’s
less-obvious, but still pretty clear. If somebody merely mentions my post publicly, writing their own post and linking to mine… that’s a real fuzzy area.
I take a minimal approach; only capturing their full content if it’s short and otherwise trying to extract a snippet that contains the bit that mentioned my content, and I think that
works great. But Terence points out an important follow-up: what if the commenter deletes that content?
My approach so far has always been a reactive one – the second in Terence’s list – and I think it’s a morally-acceptable stance for a personal blogger. But I’m not sure it scales. I
find myself asking: what if a news outlet did this, taking my self-published feedback to their story and publishing it on their site, even if I later amended, retracted, or deleted it
on my own? If somebody’s making money out of my content, that feels different: I’ve always been clear that what I write on my blog is permissively-licensed, but that permissiveness is based on the prohibition of
commercial use of my content.
Perhaps down the line this can be solved technologically: something machine-readable akin to the <link rel="license" ...> tag could state an author’s preference for
how their content is syndicated by third parties they’ve mentioned, answering questions like:
Can you quote me, or just link to me? Who do these rules apply to? (Should we be attaching metadata to individual links?)
Should you inform me that you’ve done so, and if so: how (WebMention, etc.)?
If you (or your site) observe that my content has disappeared or changed for an extended time, should that be taken as revokation of consent to syndicate it?
Right now, the relevant technologies are not well-established enough to even begin this kind of work, but if a modern interconected federated web of personal websites takes off, it’s
the kind of question we might one day have to answer.
For now my gut feeling is that option #2 (reactive moderation of syndicated comments) is ethically-sufficient for personal websites. But I’ll be watching the feedback Terence (who
probably gets many more readers than I) receives in case my gut doesn’t represent the majority!
…Mastodon by its very nature as a decentralized service can’t verify accounts.
We’d still need some trusted third party to do offline verifications and host them in a centralized repository.
…
Let’s not sell Mastodon short here. The service you compare it to – Twitter – solves this problem… but only if you trust Twitter as an authority on the identity of people.
Mastodon also solves the problem, but it puts the trust in a different place: domain names and account pages.
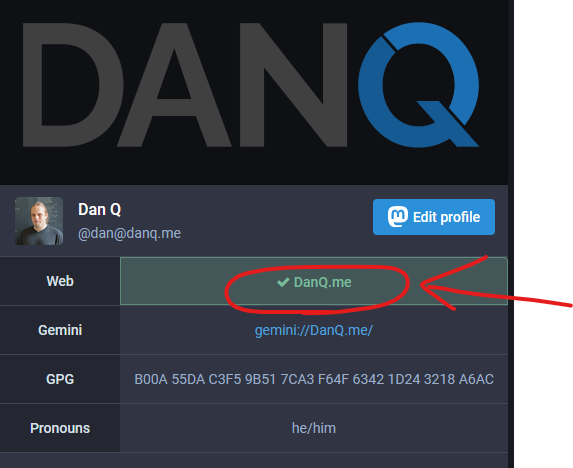
If you want to “verify” yourself on Mastodon, you can use a rel=”me” link from a page or domain you control. It looks like this:
The tick is green, not blue, but I can’t imagine anybody complains.
A great thing about this form of verification is you don’t have to trust my server (and you probably shouldn’t): you can check it for yourself to ensure that the listed website
really does state that this is the official Mastodon account of “me”.
You can argue this just moves the problem further down the road – instead of trusting a corporation that have shown that they’re not above selling the rights to your identity
you have to trust that a website is legitimate – and you’d be right. But in my case for example you can use years of history, archive.org, cross-links etc. to verify that the domain is
“me”, and from that you can confirm the legitimacy of my Mastodon account. Anybody who can spoof multiple decades of my history and maintain that lie for a decade of indepdendent web
archiving probably deserves to be able to pretend to be me!
There are lots of other distributed methods too: web-of-trust systems, signed keys, even SSL certificates would be a potential
solution. Looking again at my profile, you’ll see that I list the fingerprint of my GPG key, which you can compare to ones in public directories (which are
co-signed by other people). This way you’d know that if you sent an encrypted DM to my Mastodon inbox it could only be decrypted if I were legitimately me. Or I could post a message
signed with that key to prove my identity, insofar as my web-of-trust meets your satisfaction.
If gov.uk’s page about 10 Downing Street had profile pages for cabinet members
with rel=”me” links to their social profiles I’d be more-likely to trust the legitimacy of those social profiles than I would if they had a centralised verification such as a
Twitter “blue tick”.
Fediverse identify verification isn’t as hard a problem to solve as Derek implies, and indeed it’s already partially-solved. Not having a single point of authority is less convenient,
sure, but it also protects you from some of the more-insidious identity problems that systems like Twitter’s have.
We’re going to use ENF matching to answer the question “here’s a recording, when was it was (probably) taken?” I say “probably” because all that ENF matching can give us is a
statistical best guess, not a guarantee. Mains hum isn’t always present on recordings, and even when it is, our target recording’s ENF can still match with the wrong section of the
reference database by statistical misfortune.
Still, even though all ENF matching gives us is a guess, it’s usually a good one. The longer the recording, the more reliable the estimate; in the academic papers that I’ve read 10
minutes is typically given as a lower bound for getting a decent match.
To make our guess, we’ll need to:
Extract the target recording’s ENF values over time
Find a database of reference ENF values, taken directly from the electrical grid serving the area where the recording was made
Find the section of the reference ENF series that best matches the target. This section is our best guess for when the target recording was taken
We’ll start at the top.
…
About a year after Tom Scott did a video summarising how deviation over time (and location!) of the background electrical “hum”
produced by AC power can act as a forensic marker on audio recordings, Robert Heaton’s produced an excellent deep-dive into how you
can play with it for yourself, including some pretty neat code.
I remember first learning about this technique a few years ago during my masters in digital forensics, and my first thought was about
how it might be effectively faked. Faking the time of recording of some audio after the fact (as well as removing the markers) is challenging, mostly because you’ve got to ensure you
pick up on the harmonics of the frequencies, but it seems to me that faking it at time-of-recording ought to be reasonably easy: at least, so long as you’re already equipped with a
mechanism to protect against recording legitimate electrical hum (isolated quiet-room, etc.):
Taking a known historical hum-pattern, it ought to be reasonably easy to produce a DC-to-AC converter (obviously you want to be running off a DC circuit to begin with, e.g. from batteries, so you
don’t pick up legitimate hum) that regulates the hum frequency in a way that matches the historical pattern. Sure, you could simply produce the correct “noise”, but doing it this way
helps ensure that the noise behaves appropriately under the widest range of conditions. I almost want to build such a device, perhaps out of an existing portable transformer (they come
in big battery packs nowadays, providing a two-for-one!) but of course: who has the time? Plus, if you’d ever seen my soldering skills you’d know why I shouldn’t be allowed to work on
anything like this.
This weekend I was experimentally reimplenting how my blog displays comments. For testing I needed to find an old post with both trackbacks and pingbacks on it. I found my post that you linked, here, and was delighted to be reminded that despite both of our blogs changing domain name (from photomatt.net to ma.tt
and from blog.scatmania.org to danq.me, respectively), all the links back and forth still work perfectly because clearly we share an apporopriate dedication to the principle that
Cool URIs Don’t Change, and set up our redirects accordingly. 🙌
Incidentally, this was about the point in time at which I first thought to myself “hey, I like what Matt’s doing with this Automattic thing; I should work there someday”. It took me
like a decade to a decade-and-a-half to get around to applying, though… 😅
Anyway: thanks for keeping your URIs cool so I could enjoy this trip down memory lane (and debug an experimental wp_list_comments callback!).