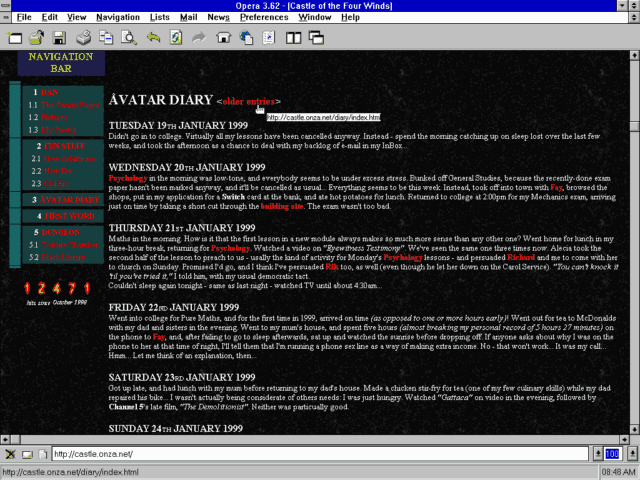
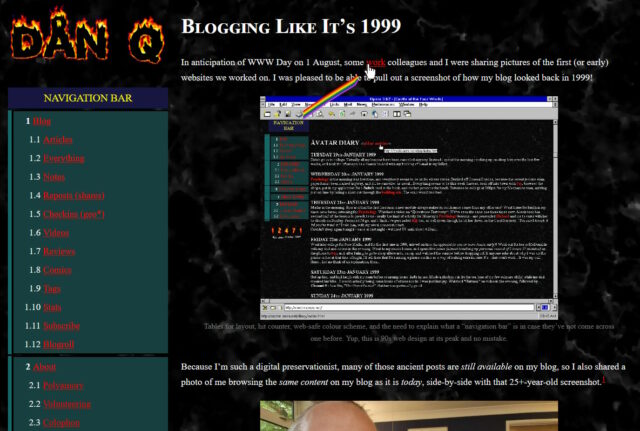
In anticipation of WWW Day on 1 August, some work colleagues and I were
sharing pictures of the first (or early) websites we worked on. I was pleased to be able to pull out a screenshot of how my blog looked back in 1999!
Tables for layout, hit counter, web-safe colour scheme, and the need to explain what a “navigation bar” is in case they’ve not come across one before. Yup, this is 90s web design at
its peak and no mistake.
Because I’m such a digital preservationist, many of those ancient posts are still available on my blog, so I also shared a photo of me browsing the same content on my
blog as it is today, side-by-side with that 25+-year-old screenshot.1
The posts are in reverse-chronological order now, rather than chronological order, but the content’s all the same (even though the design is now very different and, of course,
responsive!).
I’ve even applied img { image-rendering: crisp-edges; } to try to compensate for modern browsers’ capability for subpixel rendering when rescaling images: let them
eat pixels!5
Or if you can’t be bothered to switch to 1999 Mode, you can just look at this screenshot to get an idea of how it looks.
I’ve added 1999 Mode to my April Fools gags so, like this year, if you happen to visit my site on or around 1 April,
there’s a change you’ll see it in 1999 mode anyway. What fun!
I think there’s a possible future blog post about Web design challenges of the 1990s. Things like: what it the user agent doesn’t support images? What if it supports GIFs, but not
animated ones (some browsers would just show the first frame, so you’d want to choose your first frame appropriately)? How do I ensure that people see the right content if they skip my
frameset? Which browser-specific features can I safely use, and where do I need a fallback6? Will this
work well on all resolutions down to 640×480 (minus browser chrome)? And so on.
Any interest in that particular rabbit hole of digital history?
Footnotes
1 Some of the addresses have changed, but from Summer 2003 onwards I’ve had a solid chain
of redirects in place to try to keep content available via whatever address it was at. Because Cool URIs Don’t Change. This occasionally turns out to be useful!
2 Actually, the entire theme is just a CSS change, so no tables are added. But I’ve tried to make it look like I’m using tables for layout, because that (and spacer GIFs) were all
we had back in the day.
3 Obviously the title saying “Dan Q” is modern, because that
wasn’t even my name back then, but this is more a reimagining of how my site would have looked if I were transported back to 1999 and made to do it all again.
4 I was slightly obsessed for a couple of years in the late 90s with flaming text on black
marble backgrounds. The hit counter in my screenshot above – with numbers on fire – was one I made, not a third-party one; and because mine was the only one of my friends’
hosts that would let me run CGIs, my Perl script powered the hit counters for most of my friends’ sites too.
5 I considered, but couldn’t be bothered, implementing an SVG CSS filter: to posterize my images down to 8-bit colour, for that real
“I’m on an old graphics card” feel! If anybody’s already implemented such a thing under a license that I can use, let me know and I’ll integrate it!
This is what the endgame should be IMO. Some things are better represented as text. Some are best understood visually. We should mix and match what works best on a case-by-case
basis. Don’t try to visualize simple code. Don’t try to write code where a diagram is better.
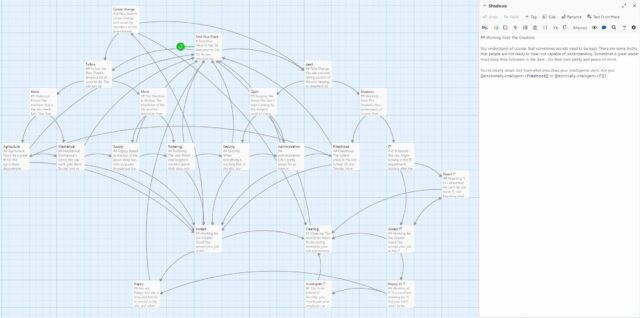
One of the attempts was Luna. They tried dual representation: everything is code and diagram at the same time, and you can switch between the two:
But this way, you are not only getting benefits of both ways, you are also constrained by both text and visual media at the same time. You can’t do stuff that’s hard to
visualize (loops, recursions, abstractions) AND you can’t do stuff that’s hard to code.
…
Interesting thoughts from Niki (and from Sebastian Bensusan) on how diagrams and code might someday be
intertwined as first class citizens (but not in the gross ways you might have come across in the past when people have tried to sell you on “visual programming”).
As Niki wrote about what he calls levels 2 and 3 of the concept – in which diagrams and code are intrinsically linked I found myself thinking about Twine, a programming language (or framework? or tool?… not sure how best to describe or define it!) intended for making interactive “choose your own
adventure”-style hypertext fiction.
Twine’s sort-of a level 2 implementation of visual programming: the code (scene descriptions) is mostly what’s responsible for feeding the diagram. But that’s not entirely
true: it’s possible to create new nodes in your story graph in a completely visual way, and then dip into them to edit their contents and imply how they link to others.
It’s possible that the IF engine community – who are working to lower the barriers to programming in order to improve accessibility
to people who are fiction authors first, developers second – are ahead of the curve in the area of visual programming. Consider for example how Inform’s automated test framework graphs
the permutations you (or your human testers) try, and allow you to “bless” (turn into assertions) the results so that regression testing becomes visually automated affair:
If you’ve been a programmer or programming-adjacent nerd1
for a while, you’ll have doubtless come across an ASCII table.
An ASCII table is useful. But did you know it’s also beautiful and elegant.
Even non-programmer-adjacent nerds may have a cultural awareness of ASCII thanks to books and
films like The Martian2.
ASCII‘s still very-much around; even if you’re transmitting modern Unicode3 the
most-popular encoding format UTF-8 is specifically-designed to be backwards-compatible with ASCII! If
you decoded this page as ASCII you’d get the gist of it… so long as you ignored the garbage
characters at the end of this sentence! 😁
History
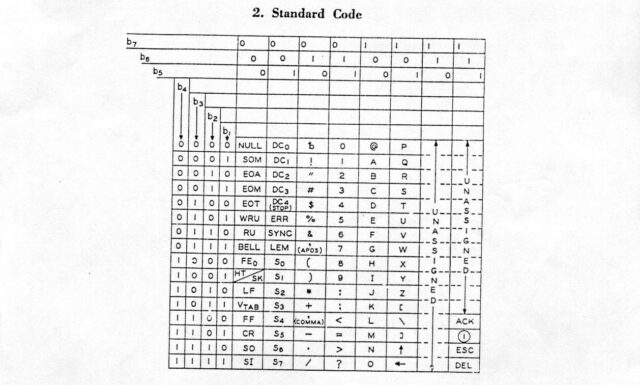
ASCII was initially standardised in X3.4-1963 (which just rolls off the tongue, doesn’t it?) which assigned meanings to 100 of the
potential 128 codepoints presented by a 7-bit4
binary representation: that is, binary values 0000000 through 1111111:
Notably absent characters in this first implementation include… the entire lowercase alphabet! There’s also a few quirks that modern ASCII fans might spot, like the curious “up” and “left” arrows at the bottom of column 101____ and the ACK and ESC control
codes in column 111____.
If you’ve already guessed where I’m going with this, you might be interested to look at the X3.4-1963 table and see that yes, many of the same elegant design choices I’ll be talking
about later already existed back in 1963. That’s really cool!
Table
In case you’re not yet intimately familiar with it, let’s take a look at an ASCII table. I’ve
colour-coded some of the bits I think are most-beautiful:
That table only shows decimal and
hexadecimal values for each character, but we’re going to need some binary too, to really appreciate some of the things that make ASCII sublime and clever.
Control codes
The first 32 “characters” (and, arguably, the final one) aren’t things that you can see, but commands sent between machines to provide additional instructions. You might be
familiar with carriage return (0D) and line feed (0A) which mean “go back to the beginning of this line” and “advance to the next line”,
respectively5.
Many of the others don’t see widespread use any more – they were designed for very different kinds of computer systems than we routinely use today – but they’re all still there.
32 is a power of two, which means that you’d rightly expect these control codes to mathematically share a particular “pattern” in their binary representation with one another, distinct
from the rest of the table. And they do! All of the control codes follow the pattern 00_____: that is, they begin with two zeroes. So when you’re reading
7-bit ASCII6, if it starts with
00, it’s a non-printing character. Otherwise it’s a printing character.
Not only does this pattern make it easy for humans to read (and, with it, makes the code less-arbitrary and more-beautiful); it also helps if you’re an ancient slow computer system
comparing one bit of information at a time. In this case, you can use a decision tree to make shortcuts.
That there’s one exception in the control codes: DEL is the last character in the table, represented by the binary number 1111111. This
is a historical throwback to paper tape, where the keyboard would punch some permutation of seven holes to represent the ones and zeros of each character. You can’t delete
holes once they’ve been punched, so the only way to mark a character as invalid was to rewind the tape and punch out all the holes in that position: i.e. all
1s.
Space
The first printing character is space; it’s an invisible character, but it’s still one that has meaning to humans, so it’s not a control character (this sounds obvious today,
but it was actually the source of some semantic argument when the ASCII standard was first being
discussed).
Putting it numerically before any other printing character was a very carefully-considered and deliberate choice. The reason: sorting. For a computer to sort a list
(of files, strings, or whatever) it’s easiest if it can do so numerically, using the same character conversion table as it uses for all other purposes7.
The space character must naturally come before other characters, or else John Smith won’t appear before Johnny Five in a computer-sorted list as you’d expect him to.
Being the first printing character, space also enjoys a beautiful and memorable binary representation that a human can easily recognise: 0100000.
Numbers
The position of the Arabic numbers 0-9 is no coincidence, either. Their position means that they start with zero at the nice round binary value 0110000
(and similarly round hex value 30) and continue sequentially, giving:
Binary
Hex
Decimal digit (character)
011 0000
30
0
011 0001
31
1
011 0010
32
2
011 0011
33
3
011 0100
34
4
011 0101
35
5
011 0110
36
6
011 0111
37
7
011 1000
38
8
011 1001
39
9
The last four digits of the binary are a representation of the value of the decimal digit depicted. And the last digit of the hexadecimal representation
is the decimal digit. That’s just brilliant!
If you’re using this post as a way to teach yourself to “read” binary-formatted ASCII in your head,
the rule to take away here is: if it begins 011, treat the remainder as a binary representation of an actual number. You’ll probably be
right: if the number you get is above 9, it’s probably some kind of punctuation instead.
Shifted Numbers
Subtract 0010000 from each of the numbers and you get the shifted numbers. The first one’s occupied by the space character already, which is a
shame, but for the rest of them, the characters are what you get if you press the shift key and that number key at the same time.
“No it’s not!” I hear you cry. Okay, you’re probably right. I’m using a 105-key ISO/UK QWERTY keyboard and… only four of the nine digits 1-9 have their shifted variants
properly represented in ASCII.
That, I’m afraid, is because ASCII was based not on modern computer keyboards but on the shifted
positions of a Remington No. 2 mechanical typewriter – whose shifted layout was the closest compromise we could find as a standard at the time, I imagine. But hey, you got to learn
something about typewriters today, if that’s any consolation.
Bonus fun fact: early mechanical typewriters omitted a number 1: it was expected that you’d use the letter I. That’s fine for printed work, but not much help for computer-readable
data.
Letters
Like the numbers, the letters get a pattern. After the @-symbol at 1000000, the uppercase letters all begin
10, followed by the binary representation of their position in the alphabet. 1 = A = 1000001, 2 = B = 1000010, and so on up to 26 = Z =
1011010. If you can learn the numbers of the positions of the letters in the alphabet, and you can count
in binary, you now know enough to be able to read any ASCII uppercase letter that’s been encoded as
binary8.
And once you know the uppercase letters, the lowercase ones are easy too. Their position in the table means that they’re all exactly 0100000higher than the uppercase variants; i.e. all the lowercase letters begin 11! 1 = a = 1100001, 2 = b = 1100010, and 26 = z =
1111010.
If you’re wondering why the uppercase letters come first, the answer again is sorting: also the fact that the first implementation of ASCII, which we saw above, was put together before it was certain that computer systems would need separate
character codes for upper and lowercase letters (you could conceive of an alternative implementation that instead sent control codes to instruct the recipient to switch case, for
example). Given the ways in which the technology is now used, I’m glad they eventually made the decision they did.
Beauty
There’s a strange and subtle charm to ASCII. Given that we all use it (or things derived from it)
literally all the time in our modern lives and our everyday devices, it’s easy to think of it as just some arbitrary encoding.
But the choices made in deciding what streams of ones and zeroes would represent which characters expose a refined logic. It’s aesthetically pleasing, and littered with
historical artefacts that teach us a hidden history of computing. And it’s built atop patterns that are sufficiently sophisticated to facilitate powerful processing while being coherent
enough for a human to memorise, learn, and understand.
Footnotes
1 Programming-adjacent? Yeah. For example, geocachers who’ve ever had to decode a
puzzle-geocache where the coordinates were presented in binary (by which I mean: a binary representation of ASCII) are “programming-adjacent nerds” for the purposes of this discussion.
2 In both the book and the film, Mark Watney divides a circle around the recovered
Pathfinder lander into segments corresponding to hexadecimal digits 0 through F to allow the rotation of its camera (by operators on Earth) to transmit pairs of 4-bit words.
Two 4-bit words makes an 8-bit byte that he can decode as ASCII, thereby effecting a means to
re-establish communication with Earth.
3 Y’know, so that you can type all those emoji you love so much.
4 ASCII is often thought of as an 8-bit code, but it’s not: it’s 7-bit. That’s why virtually every ASCII message you see starts every octet with a zero. 8-bits is a convenient number for transmission purposes (thanks
mostly to being a power of two), but early 8-bit systems would be far more-likely to use the 8th bit as a parity check, to help
detect transmission errors. Of course, there’s also nothing to say you can’t just transmit a stream of 7-bit characters back to back!
5 Back when data was sent to teletype printers these two characters had a distinct
different meaning, and sometimes they were so slow at returning their heads to the left-hand-side of the paper that you’d also need to send a few null bytes e.g. 0D 0A
00 00 00 00 to make sure that the print head had gotten settled into the right place before you sent more data: printers didn’t have memory buffers at this point! For
compatibility with teletypes, early minicomputers followed the same carriage return plus line feed convention, even when outputting text to screens. Then to maintain backwards
compatibility with those systems, the next generation of computers would also use both a carriage return and a line feed character to mean “next line”. And so,
in the modern day, many computer systems (including Windows most of the time, and many Internet protocols) still continue to use the combination of a carriage return
and a line feed character every time they want to say “next line”; a redundancy build for a chain of backwards-compatibility that ceased to be relevant decades ago but which
remains with us forever as part of our digital heritage.
6 Got 8 binary digits in front of you? The first digit is probably zero. Drop it. Now
you’ve got 7-bit ASCII. Sorted.
7 I’m hugely grateful to section 13.8 of Coded Character Sets, History and
Development by Charles E. Mackenzie (1980), the entire text of which is available freely
online, for helping me to understand the importance of the position of the space character within the ASCII character set. While most of what I’ve written in this blog post were things I already knew, I’d never fully grasped
its significance of the space character’s location until today!
8 I’m sure you know this already, but in case you’re one of today’s lucky 10,000 to discover that the reason we call the majuscule and minuscule letters “uppercase” and “lowercase”, respectively, dates to 19th
century printing, when moveable type would be stored in a box (a “type case”) corresponding to its character type. The “upper” case was where the capital letters would typically be
stored.
I was browsing (BBC) Good Food today when I noticed something I’d not seen before: a “premium” recipe, available on their “app only”:
I clicked on the “premium” recipe and… it
looked just like any other recipe. I guess it’s not actually restricted after all?
Just out of curiosity, I fired up a more-vanilla web browser and tried to visit the same page. Now I saw an overlay and modal attempting1 to
restrict access to the content:
It turns out their entire effort to restrict access to their premium content… is implemented in client-side JavaScript. Even when I did see the overlay and not get access to
the recipe, all I needed to do was open my browser’s debugger and run document.body.classList.remove('tp-modal-open'); for(el of document.querySelectorAll('.tp-modal,
.tp-backdrop')) el.remove(); and all the restrictions were lifted.
What a complete joke.
Why didn’t I even have to write my JavaScript two-liner to get past the restriction in my primary browser? Because I’m running privacy-protector Ghostery, and one of the services Ghostery blocks by-default is one called Piano. Good Food uses Piano to segment their audience in your
browser, but they haven’t backed that by any, y’know, actual security so all of their content, “premium” or not, is available to anybody.
I’m guessing that Immediate Media (who bought the BBC Good Food brand a while back and have only just gotten around to stripping “BBC” out of
the name) have decided that an ad-supported model isn’t working and have decided to monetise the site a little differently2.
Unfortunately, their attempt to differentiate premium from regular content was sufficiently half-hearted that I barely noticed that, too, gliding through the paywall without
even noticing were it not for the fact that I wondered why there was a “premium” badge on some of their recipes.
You know what website I miss? OpenSourceFood.com. It went downhill and then died around 2016, but for a while it was excellent.
Recipes probably aren’t considered a high-value target, of course. But I can tell you from experience that sometimes companies make basically this same mistake with much
more-sensitive systems. The other year, for example, I discovered (and ethically disclosed) a fault in the implementation of the login forms of a major UK mobile network that meant that
two-factor authentication could be bypassed entirely from the client-side.
These kinds of security mistakes are increasingly common on the Web as we train developers to think about the front-end first (and sometimes, exclusively). We need to do
better.
Footnotes
1 The fact that I could literally see the original content behind the modal
was a bit of a giveaway that they’d only hidden it, not actually protected it in any way.
2 I can see why they’d think that: personally, I didn’t even know there were ads
on the site until I did the experiment above: turns out I was already blocking them, too, along with any anti-ad-blocking scripts that might have been running alongside.
If I could offer you only one tip for the future, coding would be it. The long term benefits of coding websites remains unproved by scientists, however the rest of my advice has a
basis in the joy of the indie web community’s experiences. I will dispense this advice now:
Enjoy the power and beauty of PHP; or never mind. You will not understand the power and beauty of PHP until your stack is completely jammed. But trust me, in 20 years you’ll look
back at your old sites and recall in a way you can’t grasp now, how much possibility lay before you and how simple and fast they were. JS is not as blazingly fast as you imagine.
Don’t worry about the scaling; or worry, but know that premature scalability is as useful as chewing bubble gum if your project starts cosy and small. The real troubles on the web
are apt to be things that never crossed your worried mind; if your project grows, scale it up on some idle Tuesday.
I can’t say I loved Baz Luhrmann’s Everybody’s Free To Wear Sunscreen. I’m not sure it’s possible for anybody who lived through it being played to death in the late
1990s; a period of history when a popular song was basically inescapable. Also, it got parodied a lot. I must’ve seen a couple of dozen different parodies of varying quality in
the early 2000s.
But it’s been long enough that I was, I guess, ready for one. And I couldn’t conceive of a better topic.
Y’see: the very message of the value of personal websites is, like Sunscreen, a nostalgic one. When I try to sell
people on the benefits of a personal digital garden or blog, I tend to begin by pointing out that the best time to set up your own website is… like 20+ years ago.
But… the second-best time to start a personal website is right now. With cheap and free static
hosting all over the place (and more-dynamic options not much-more expensive) and domain names still as variably-priced as they ever were, the biggest impediment is the learning
curve… which is also the fun part! Siloed social media is either eating its own tail or else fighting to adapt to once again be part of a more-open Web, and there’s nothing that says
“I’m part of the open Web” like owning your own online identity, carving out your own space, and expressing yourself there however you damn well like.
As always, this is a drum I’ll probably beat until I die, so feel free to get in touch if you want some help getting set up on the Web.
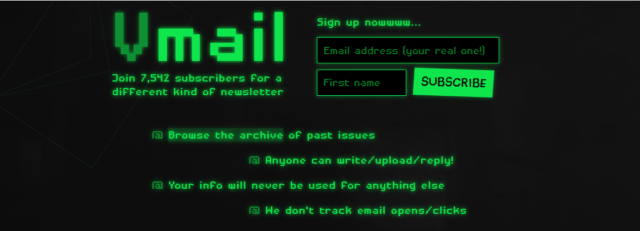
Vmail is cool. It’s vole.wtf’s (of ARCC etc. fame) community
newsletter, and it’s as batshit crazy as you’d expect if you were to get the kinds of people who enjoy that site and asked them all to chip in on a newsletter.
Totes bonkers.
But email’s not how I like to consume this kind of media. So obviously, I scraped it.
I’m not a monster: I want Vmail’s stats to be accurate. So I signed up with an unmonitored OpenTrashMail account as well. I just don’t read it (except for the confirmation link
email). It actually took me a few attempts because there seems to be some kind of arbitrary maximum length validation on the signup form. But I got there in the end.
Recipe
Want to subscribe to Vmail using your own copy of FreshRSS? Here’s the settings you’re looking for –
Type of feed source:HTML + XPath (Web scraping)
XPath for finding news items://table/tbody/tr
It’s just a table with each row being a newsletter; simple!
XPath for item title:descendant::a
XPath for item content:.
XPath for item link (URL):descendant::a/@href
XPath for item date:descendant::td[1]
Custom date/time format:d M *y
The dates are in a format that’s like 01 May ’24 – two-digit days with leading zeros, three-letter months, and a two-digit year preceded by a curly quote, separated by spaces. That
curl quote screws up PHP’s date parser, so we have to give it a hint.
XPath for unique item ID:descendant::th
Optional, but each issue’s got its own unique ID already anyway; we might as well use it!
Article CSS selector on original website:#vmail
Optional, but recommended: this option lets you read the entire content of each newsletter without leaving FreshRSS.
So yeah, FreshRSS continues to be amazing. And lately it’s helped me keep on top of the amazing/crazy of vole.wtf too.
There are a whole bunch of things that could be the source for the name, e.g. where we found most of their work (The Dipylon Master) or the potter with whom they worked (the
Amasis Painter), a favourite theme (The Athena Painter), the Museum that ended up with the most famous thing they did (The Berlin Painter) or a notable aspect of their style.
Like, say, The Eyebrow Painter.
Guess what kind of pottery the Eyebrow Painter made?
I’m not a tea-drinker1. But while making a cuppa for Ruth
this morning, a thought occurred to me and I can’t for a moment believe that I’m the first person to think of it:
Modern digital pressure cookers have a lot of different settings and modes, but ‘tea’ is somehow absent?
It’s been stressed how important it is that the water used to brew the tea is 100℃, or close to it possible. That’s the boiling point of water at sea level, so you can’t really boil
your kettle hotter than that or else the water runs away to pursue a new life as a cloud.
That temperature is needed to extract the flavours, apparently3.
And that’s why you can’t get a good cup of tea at high altitudes, I’m told: by the time you’re 3000 metres above sea level, water boils at around 90℃ and most British people wilt at
their inability to make a decent cuppa4.
It’s a question of pressure, right? Increase the pressure, and you increase the boiling point, allowing water to reach a higher temperature before it stops being a liquid and starts
being a gas. Sooo… let’s invent something!
I’m thinking a container about the size of a medium-sized Thermos flask or a large keep-cup – you need thick walls to hold pressure, obviously – with a safety valve and a heating
element, like a tiny version of a modern pressure cooker. The top half acts as the lid, and contains a compartment into which you put your teabag or loose leaves (optionally in an
infuser). After being configured from the front panel, the water gets heated to a specified temperature – which can be above the ambient boiling point of water owing to the
pressurisation – at which point the tea is released from the upper half. The temperature is maintained for a specified amount of time and then the user is notified so they can release
the pressure, open the top, lift out the inner cup, remove the teabag, and enjoy their beverage.
This isn’t just about filling the niche market of “dissatisfied high-altitude tea drinkers”. Such a device would also be suitable for other folks who want a controlled tea experience.
You could have it run on a timer and make you tea at a particular time, like a teasmade. You can set the temperature lower for a
controlled brew of e.g. green tea at 70℃. But there’s one other question that a device like this might have the capacity to answer:
What is the ideal temperature for making black tea?
We’re told that it’s 100℃, but that’s probably an assumption based on the fact that that’s as hot as your kettle can get water to go, on account of physics. But if tea is bad
when it’s brewed at 90℃ and good when it’s brewed at 100℃… maybe it’s even better when it’s brewed at 110℃!
A modern pressure cooker can easily maintain a liquid water temperature of 120℃, enabling excellent extraction of flavour into water (this is why a pressure cooker makes such
excellent stock).
It’s possible that the perfect cup of tea hasn’t been invented yet, owing to limitations in the boiling point of water.
I’m not the person to answer this question, because, as I said: I’m not a tea drinker. But surely somebody’s tried this5? It shouldn’t be too hard to retrofit a pressure cooker lid with a
sealed compartment that releases, even if it’s just on a timer, to deposit some tea into some superheated water?
Because maybe, just maybe, superheated water makes better tea. And if so, there’s a possible market for my proposed device.
Footnotes
1 I probably ought to be careful confessing to that or they’ll strip my British
citizenship.
3 Again, please not that I’m not a tea-drinker so I’m not really qualified to comment on
the flavour of tea at all, let alone tea that’s been brewed at too-low a temperature.
4 Some high-altitude tea drinkers swear by switching from black tea to green tea, white
tea, or oolong, which apparently release their aromatics at lower temperatures. But it feels like science, not compromise, ought to be the solution to this problem.
5 I can’t find the person who’s already tried this, if they exist, but maybe they’re out
there somewhere?
We’ve recently had the attics of our house converted, and I moved my bedroom up to one of the newly-constructed rooms.
To make the space my own, I did a little light carpentry up there: starting with a necessary reshaping of the doors, then moving on to shelving
and eventually… a secret cabinet!
I’d love to tell you about how I built it: but first, a disclaimer! I am a software engineer, and with good reason. Letting me near a soldering iron is ill-advised. Letting me
use a table saw is tempting fate.
Letting me teach you anything about how you should use a soldering iron or a table saw is, frankly, asking for trouble.
Knowing that I’d been short on shelf space in my old bedroom, I started work on fitting shelves for my new bedroom before the carpet had even arrived.
Building a secret cabinet wasn’t part of my plan, but came about naturally after I got started. I’d bought a stack of pine planks and – making use of Ruth’s table saw – cut them to squarely fit beneath each of the two dormer windows1.
While sanding and oiling the wood I realised that I had quite a selection of similarly-sized offcuts and found myself wondering if I could find a use for them.
The hardest part of sanding and oiling wood on the hottest day of the year is all the beer breaks you have to take. Such a drag.
I figured I had enough lumber to insert a small cabinet into one of the bookshelves, and that got me thinking… what about if it were a secret cabinet, disguised as books unless
you knew where to look. Or to go one step further: what if it had some kind of electronic locking mechanism that could be triggered from somewhere else in the room2.
There are other ways in which I’ve made my new room distinctly-“mine” – like the pair of magpies – but probably the secret cabinet is the most-distinctive.
Not wanting to destroy a stack of real books, which is the traditional way to get a collection of book spines for the purpose of decorating a “fake bookshelf” panel3,
I looked online and discovered the company that made the fake book spines used at the shop of my former
employer. They looked ideal: carefully shaped and painted panels with either an old-school or contemporary look.
Buuut, they don’t seem to be well-equipped for short runs and are doubtless pricey, so I looked elsewhere and found the eBay
presence of Beatty Lockey Antiques in Lowestoft. They’d acquired a stack of them second-hand from the set of Netflix’s
The School for Good and Evil.4
(By the way: at time of writing they’ve still got a few panels left, if you want to make your own…)
I absolutely must sing the praises of Brad at Beatty Lockey Antiques who, after the first delivery of fake book fronts was partially-damaged in transit, was super quick about helping
me find the closest-available equivalent (I’d already measured-up based on the one I’d thought I was getting) and sent a replacement.
The cabinet is just a few bits of wood glued together and reinforced with L-shaped corner braces, with a trio of thin strips – made from leftover architrave board – attached using small
brass hinges. The fake book fronts are stuck to the strips using double-sided mounting tape left over from installing a bathroom mirror. A simple magnetic clasp holds the door shut when
pushed closed5,
and the hinges are inclined to “want” the door to stand half-open, which means it only needs a gentle push away from the magnetic catch to swing it open.
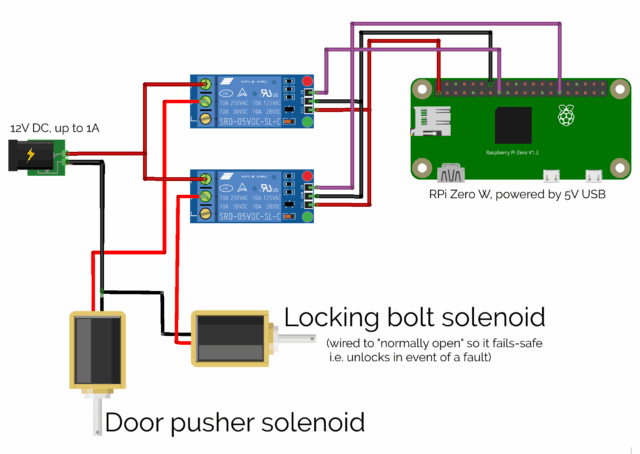
The wiring is uncomplicated enough that even I – a self-confessed software engineer – could manage it. Note the separate power supply: those solenoids can draw a full 1 amp in a
“surge” that’s enough to give a little Raspberry Pi Zero a Bad Day if you try to power it directly from the computer (there might be some capacitor-based black magic that I don’t
understand that could have made this easier, I suppose)!
I mounted a Raspberry Pi Zero W into a rear corner inside the cabinet6, and wired it up via a relay to what was sold to me as a “large push-pull solenoid”, then
began experimenting with the position in which I’d need to mount it to allow it to “kick” open the door, against the force of the magnetic clasp7.
This was, amazingly, the hardest part of the whole project! Putting the solenoid too close to the door didn’t work: it couldn’t “push” it from a standing start. Too far away, and the
natural give of the door took the strain without pushing it open. Just the right distance, and the latch had picked up enough momentum that its weight “kicked” the door away from the
magnet and followed-through to ensure that it kept moving.
A second solenoid, mounted inside the top of the cabinet, slides into the “loop” part of a large bolt fitting, allowing the cabinet to be electronically “locked”.
I seriously must’ve spent about an hour getting the position of that little “kicker” in the bottom right just right.
Next up came the software. I started with a very simple Python program8
that would run a webserver and, on particular requests, open the lock solenoid and push with the “kicker” solenoid.
#!/usr/bin/python## a basic sample implementation of a web interface for a secret cabinet## setup:# sudo apt install -y python3-flask# wget https://github.com/sbcshop/Zero-Relay/blob/master/pizero_2relay.py## running:# sudo flask --app web run --host=0.0.0.0 --port 80fromflaskimport Flask, redirect, url_for
importpizero_2relayaspizerofromtimeimport sleep
# set up pizero_2relay with the two relays attached to this Pi Zero:
r1 = pizero.relay("R1") # The "kicker" relay
r2 = pizero.relay("R2") # The "locking bolt" relay
app = Flask(__name__)
# GET / - nothing here@app.route("/")
defindex():
return"Nothing to see here."# GET /relay - show a page with "open" and "lock" links@app.route("/relay")
defrelay():
return"<html><head><meta name='viewport' content='width=device-width, initial-scale=1'></head><body><ul><li><a href='/relay/open'>Open</a></li><li><a href='/relay/lock'>Lock</a></li></ul>"# GET /relay/open - open the secret cabinet then return to /relay# This ought to be a POST request in your implementation, and you probably# want to add some security e.g. a @app.route("/relay/open")
defopen():
# Retract the lock:
r2.off()
sleep(0.5)
# Fire the kicker twice:
r1.on()
sleep(0.25)
r1.off()
sleep(0.25)
r1.on()
sleep(0.25)
r1.off()
# Redirect back:return redirect(url_for('relay'))
@app.route("/relay/lock")
deflock():
# Engage the lock:
r2.on()
return redirect(url_for('relay'))
Don’t use this code as-is on any kind of open network, obviously. Follow the comments for some tips on what you’ll need to change.
Once I had something I could trigger from a web browser or with curl, I could start experimenting with trigger mechanisms. I had a few ideas (and prototyped a couple of
them), including:
A mercury tilt switch behind a different book, so you pull it to release the cabinet in the style of a classic movie secret door.
A microphone that listens for a specific pattern of knocks on a nearby surface.
I had far too much fun playing about with crappy prototypes.
An RFID reader mounted underneath another surface, and a tag on the underside of an ornament: moving the ornament to the “right” place on the surface triggers the cabinet (elsewhere
in the room).
The current design, shown in the video above, where a code9 is transmitted to the cabinet for verification.
I think I’m happy with what I’ve got going on with it now. And it’s been a good opportunity to improve my carpentry, electronics, and Python.
Footnotes
1 The two dormer windows, wouldn’t you guarantee it, were significantly different
widths despite each housing a window of the same width. Such are the quirks of extending a building that the previous occupier had previously half-heartedly tried to
extend, I guess.
2 Why yes, I am a big fan of escape rooms. Why do you ask?
3 For one thing, I live with JTA, and
I’m confident that he’d somehow be able to hear the silent screams of whatever trashy novels I opted to sacrifice for the good of the project.
4 As a bonus, my 10-year-old is a big fan of the book series that inspired the film (and a
more-muted fan of the film itself) and she was ever-so excited at my project using real-life parts of the set of the movie… that she’s asked me to make a similar secret cabinet for
her, when we get around to redecorating her room later in the year!
5 If I did it again, I might consider using a low-powered electromagnetic lock to hold the
door shut. In this design, I used a permanent magnet and a pair of latch solenoids: one to operate a bolt, the second to “kick” the door open against the pull of the magnet, and… it
feels a little clumsier than a magnetic lock might’ve.
6 That double-sided mounting tape really came in handy for this project!
7 Props to vlogger Technology Connections, one of whose excellent videos on the
functionality of 1970s pinball tables – maybe this one? – taught me what a latch solenoid was in the first place, last year,
which probably saved me from the embarrassment of trying to do this kind of thing with, I don’t know, a stepper motor or something.
8 I’m not a big fan of Python normally, but the people who made my relays had some up with
a convenience library for them that was written in it, so I figured it would do.
9 Obviously the code isn’t A-B; I changed it temporarily for the video.
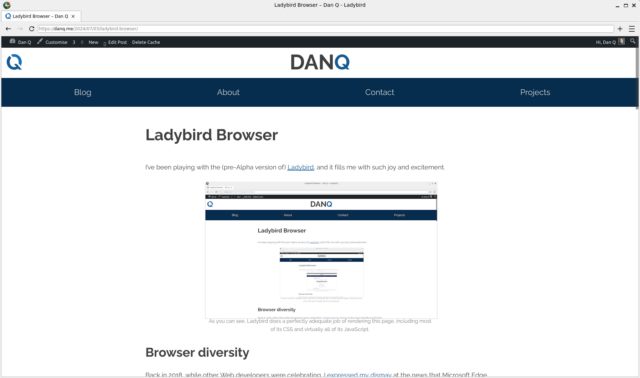
I’ve been playing with the (pre-Alpha version of) Ladybird, and it fills me with such joy and excitement.
As you can see, Ladybird does a perfectly adequate job of rendering this page, including most of its CSS and
virtually all of its JavaScript.
Browser diversity
Back in 2018, while other Web developers were celebrating, I expressed my dismay at the news that Microsoft Edge was on the cusp of switching
from using Microsoft’s own browser engine EdgeHTML to using Blink. Blink is the engine that powers almost all other mainstream browsers; all but Firefox, which continues to
stand atop Gecko.
The developers who celebrated this loss of rendering engine diversity were, I suppose, happy to have one fewer browser in which they must necessarily test their work. I guess these are
the same developers who don’t test the sites they develop for accessibility (does your site work if you can’t see the images? what about with a keyboard but without a pointing device?
how about if you’re colourblind?), or consider what might happen if a part of their site fails (what if the third-party CDN
that hosts your JavaScript libraries goes down or is blocked by the user’s security software or their ISP?).
When was the last time you tested your site in a text-mode browser?
But I was sad, because – as I observed after Andre
Alves Garzia succinctly spelled it out – browser engines are an endangered species. Building a new browser that supports the myriad complexities of the
modern Web is such a huge endeavour that it’s unlikely to occur from scratch: from this point on, all “new” browsers are likely to be based upon an existing browser engine.
Engine diversity is important. Last time we had a lull in engine diversity, the Web got stuck, stagnating in the
shadow of Internet Explorer 6’s dominance and under the thumb of Microsoft’s interests. I don’t want those days to come back; that’s a big part of why Firefox is my primary web browser.
A Ladybird book browser
I actually still own a copy of the book from which I adapted this cover!
Ladybird is a genuine new browser engine. Y’know, that thing I said that we might never see happen again! So how’ve they made it happen?
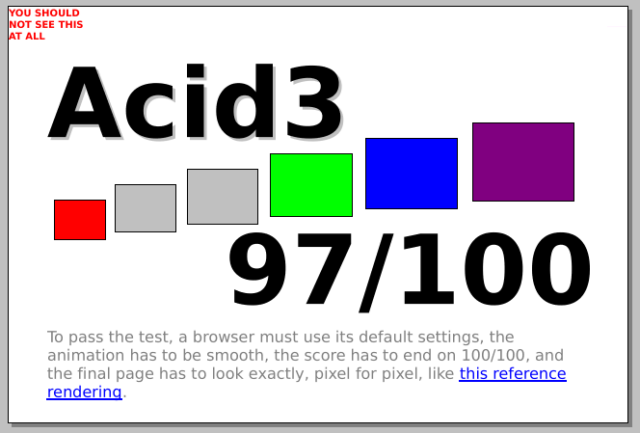
It helps that it’s not quite starting from scratch. It’s starting point is the HTML viewer component from SerenityOS. And… it’s pretty good. It’s DOM processing’s solid, it seems to support enough JavaScript and CSS that the modern Web is usable, even if it’s not beautiful 100% of the time.
I’ve certainly seen browsers do worse than this at Acid3 and related tests…
They’re not even expecting to make an Alpha release until next year! Right now if you want to use it at all, you’re going to need to compile the code for yourself and fight with a
plethora of bugs, but it works and that, all by itself, is really exciting.
They’ve got four full-time engineers, funded off donations, with three more expected to join, plus a stack of volunteer contributors on Github. I’ve raised my first issue against the repo; sadly my C++ probably isn’t strong enough to be able to help more-directly, even if I
somehow did have enough free time, which I don’t. But I’ll be watching-from-afar this wonderful, ambitious, and ideologically-sound initiative.
Part of the joy of the collaborative Internet is that people can share their passion. Today’s example comes from this YouTuber who’s made an hour long video demonstrating and
ranking the 35 elevators in the first five games in the Myst series.
Starting with a discussion of what defines an elevator, the video goes on to show off some of the worst of the lifts in the series of games (mostly those that are uninspired,
pointless, or which have confusing interfaces) before moving on to the well-liked majority.
I only ever played the first two Myst games (and certainly haven’t played the first since, what, the mid-1990s?) and I don’t think I finished either. But that didn’t stop me
watching the entirety of this video and revelling in the sheer level of dedication and focus it’ll have taken on the part of the creator. When I made my
(mere 15-minute!) video describing my favourite video game Easter Egg I spent tens of hours over the prior weeks researching the quirk and its background, configuring a copy of the
(elderly) game so that it’d play and record in the way I wanted, and of course playing through the game far enough to be able to fully demonstrate the Easter Egg. Dustin’s
video, which doubtless involved replaying (possibly multiple times) five different games released over a 12-year window is mindblowing by comparison.
I don’t really care about the Myst series. I care even less about its elevators. But I really enjoyed this video, if only for its creator’s enthusiasm.