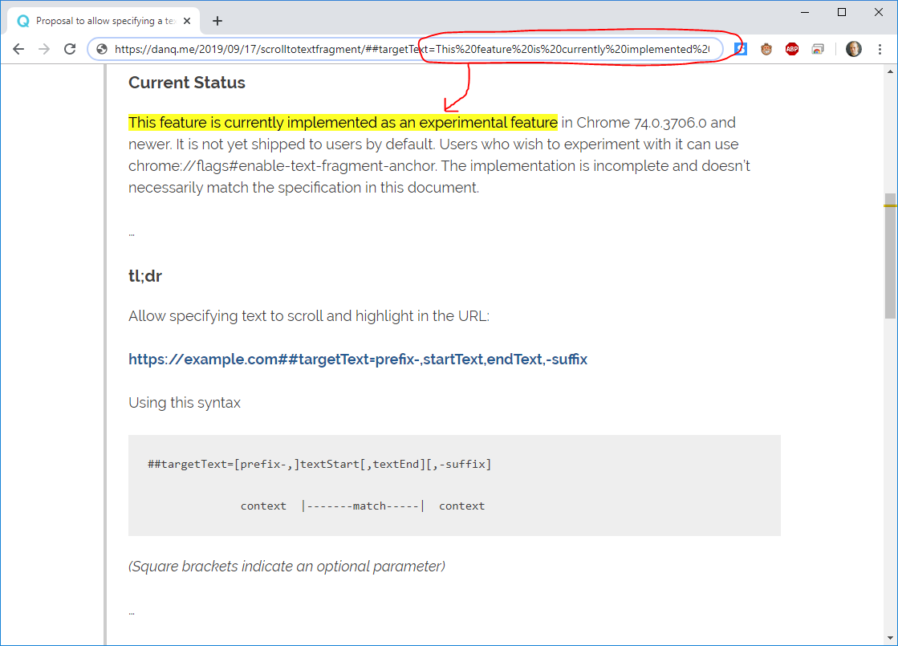
…
This adventure took a lot of planning. It’s 350 miles from where I live to Glasgow. I have a Honda CG 125cc, and my maximum range in one day is around 200 miles – if I have the full day for travelling, which I wouldn’t have, most days. I figured if I was going to have a road trip, I’d have to make stop offs at various parts of the UK, to break it up. This actually worked out really well, as there are lots of parts of the UK that I wanted to visit.
…
After booking the series of hotel rooms, I started to think about the actual riding. It was two weeks before the trip. I didn’t have enough thermals, or a bike suit that was protective enough. I also didn’t have a way of storing luggage on my bike, or keeping it dry (and two laptops would be in the bags). There was also an issue with the chain on my bike that needed fixing. Not exactly a trivial to do list! So the next two weeks turned into a bit of an eBay and Amazon frenzy, with a trip down to see my dad in Kent to get the bike chain fixed, and rummage around for my old waterproofs in my grandparent’s attic. It was pretty close: the final item arrived the day before the trip. I got ridiculously lucky on eBay with my new, more visible, better padded, comfy bike suit though, which I love to bits. In hindsight, more time for all of this would have been helpful!
…
My friend Bev wrote about their motorcycling adventure up and down the UK; it’s pretty awesome.