This afternoon I’m acting as backup driver for my partner Ruth, who’s walking the
length of the Thames Path by (very gradual) instalments. Having parked at Culham Lock I began to walk back towards Abingdon to meet the walking team coming the other way, when I
noticed that a new cache had been published nearby and diverted to find it.
A delightful tree climb later and I had this great cache container in hand. TFTC, FP awarded!
A little sad to DNF this cache which is probably just well-hidden, but I’ve only got limited time to hunt as I’m the backup driver for this segment of a walk down the entire length of the Thames Path.
On the 6th of January 1995, viewers of BBC Two were treated to a new series of Waiting for Godot Bottom. Stuck at the top of a Ferris wheel, Vyvyan and the People’s
Poet Eddie and Ritchie wait to see what the cruel hand of fate has dealt them in this week’s episode “Hole”.
At one point, Captain Edrison Peavey Edward Elizabeth Hitler pulls out a newspaper to read.
It may surprise you to know that the “Hammersmith Bugle” is not a real paper and they never ran a headline “No News Shocker”. At which point, it is time to rip off Dirty Feed’s shtick and find out what that paper really is.
…
This is exactly the kind of rabbitholey deep-dive I know and love (and have experienced ever so frequently myself). Take a ride with Terence on a long (and not-entirely satisfying!)
ride to try to find the actual newspaper that’s been adapted by the Bottom production team in this particular episodes.
Anyway, it’s an amusing journey that I enjoyed going along with, this morning, and maybe you will too.
I took the dog out for a walk from the Chicory House yesterday. At one point, we found ourselves on a familiar-looking footpath: I couldn’t place
exactly why I’d been there before. Geocaching, possibly: I couldn’t see any on the map but perhaps they’d been since archived?
Personal location tracking continues to be awesome. Being able to both forwards-search (“where was I on this date?”) and reverse-search (“when was I last within this area?”) unlocks a
wealth of aides mémoire that are otherwise hard to come by.
It’s hard to sell people on the idea, probably because it’s a slow-burner – you need lots of data before it starts to pay off! – but I still recommend it.
With its few-columns and large hit-areas, the game’s well-optimised for mobile play.
The premise is simple enough:
5-column solitaire game with 1-5 suits.
23 cards dealt out into those columns; only the topmost ones face-up.
2 “reserve” cards retained at the bottom.
Stacks can be formed atop any suit based on value-adjacency (in either order, even mixing the ordering within a stack)
Individual cards can always be moved, but stacks can only be moved if they share a value-adjacency chain and are all the same suit.
Aim is to get each suit stacked in order at the top.
Well this looks like a suboptimal position…
One of the things that stands out to me is that the game comes with over five thousand pre-shuffled decks to play, all of which guarantee that they are “winnable”.
Playing through these is very satisfying because it means that if you get stuck, you know that it’s because of a choice that you made2,
and not (just) because you get unlucky with the deal.
After giving us 5,105 pregenerated ‘decks’, author Zach Gage probably thinks we’ll never run out of playable games. Some day, I might prove him wrong.
Every deck is “winnable”?
When I first heard that every one of FlipFlop‘s pregenerated decks were winnable, I misinterpreted it as claiming that every conceivable shuffle for a game
of FlipFlop was winnable. But that’s clearly not the case, and it doesn’t take significant effort to come up with a deal that’s clearly not-winnable. It only takes a
single example to disprove a statement!
If you think you’ve found a solution to this deal – for example, by (necessarily) dealing out all of the cards, then putting both reserve kings out and stacking everything else on top
of them in order to dig down to the useful cards, bear in mind that (a) the maximum stack depth of 20 means you can get to a 6, or a 5, but not both, and (b) you can’t then move any
of those stacks in aggregate because – although it’s not clear in my monochrome sketch – the suits cycle in a pattern to disrupt such efforts.
That it’s possible for a fairly-shuffled deck of cards to lead to an “unwinnable” game of FlipFlop Solitaire means the author must have necessarily had some
mechanism to differentiate between “winnable” (which are probably the majority) and “unwinnable” ones. And therein lies an interesting problem.
If the only way to conclusively prove that a particular deal is “winnable” is to win it, then the developer must have had an algorithm that they were using to test that a given
deal was “winnable”: that is – a brute-force solver.
So I had a go at making one3.
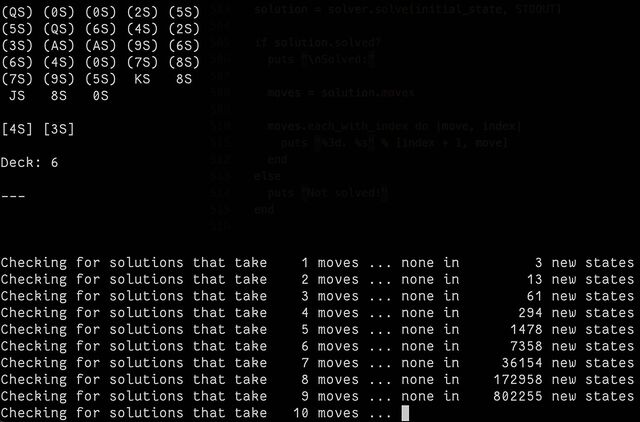
The code is pretty hacky (don’t judge me) and, well… it takes a long, long time.
This isn’t an animation, but it might as well be! By the time you’ve permuted all possible states of the first ten moves of this starting game, you’re talking about having somewhere
in the region of three million possible states. Solving a game that needs a minimum of 80 moves takes… a while.
Partially that’s because the underlying state engine I used, BfsBruteForce, is a breadth-first optimising algorithm. It aims to
find the absolute fewest-moves solution, which isn’t necessarily the fastest one to find because it means that it has to try all of the “probably stupid” moves it
finds4
with the same priority as the the “probably smart” moves5.
If you pull off a genuinely random shuffle, then – statistically-speaking – you’ve probably managed to put that deck into an order that no deck of cards has never been in
before!6
And sure: the rules of the game reduce the number of possibilities quite considerably… but there’s still a lot of them.
So how are “guaranteed winnable” decks generated?
I think I’ve worked out the answer to this question: it came to me in a dream!
Show this puzzle to any smarter-than-average child and they’ll quickly realise that the fastest way to get the solution is not to start from each programmer and trace
their path… but to start from the laptop and work backwards!
The trick to generating “guaranteed winnable” decks for FlipFlop Solitaire (and, probably, any similar game) is to work backwards.
Instead of starting with a random deck and checking if it’s solvable by performing every permutation of valid moves… start with a “solved” deck (with all the cards stacked
up neatly) and perform a randomly-selected series of valid reverse-moves! E.g.:
The first move is obvious: take one of the kings off the “finished” piles and put it into a column.
For the next move, you’ll either take a different king and do the same thing, or take the queen that was exposed from under the first king and place it either in an empty
column or atop the first king (optionally, but probably not, flipping the king face down).
With each subsequent move, you determine what the valid next-reverse-moves are, choose one at random (possibly with some kind of weighting), and move on!
In computational complexity theory, you just transformed an NP-Hard problem7
into a P problem.
Once you eliminate repeat states and weight the randomiser to gently favour moving “towards” a solution that leaves the cards set-up and ready to begin the game, you’ve created a
problem that may take an indeterminate amount of time… but it’ll be finite and its complexity will scale linearly. And that’s a big improvement.
I started implementing a puzzle-creator that works in this manner, but the task wasn’t as interesting as the near-impossible brute-force solver so I gave up, got distracted,
and wrote some even more-pointless code instead.
If you go ahead and make an open source FlipFlop deck generator, let me know: I’d be interested to play with it!
Footnotes
1 I don’t get much time to play videogames, nowadays, but I sometimes find that I’ve got
time for a round or two of a simple “droppable” puzzle game while I’m waiting for a child to come out of school or similar. FlipFlop Solitaire is one of only three games I
have installed on my phone for this purpose, the other two – both much less frequently-played – being Battle of Polytopia and the
buggy-but-enjoyable digital version of Twilight Struggle.
2 Okay, it feels slightly frustrating when you make a series of choices that are
perfectly logical and the most-rational decision under the circumstances. But the game has an “undo” button, so it’s not that bad.
4 An example of a “probably stupid” move would be splitting a same-suit stack in order to
sit it atop a card of a different suit, when this doesn’t immediately expose any new moves. Sometimes – just sometimes – this is an optimal strategy, but normally it’s a pretty bad
idea.
5 Moving a card that can go into the completed stacks at the top is usually a good idea…
although just sometimes, and especially in complex mid-game multi-suit scenarios, it can be beneficial to keep a card in play so that you can use it as an anchor for something else,
thereby unblocking more flexible play down the line.
6 Fun fact: shuffling a deck of cards is a sufficient source of entropy that you can use
it to generate cryptographic keystreams, as Bruce Schneier demonstrated in 1999.
7 I’ve not thought deeply about it, but determining if a given deck of cards will result
in a winnable game probably lies somewhere between the travelling salesman and the halting problem, in terms of complexity, right? And probably not something a right-thinking person
would ask their desktop computer to do for fun!
As if I hadn’t suffered enough “flood damage” this year, I started my first workday since rebuilding my home office setup – hour the first time in months! – in our rental… by pouring a
cup of coffee into my keyboard. 😱
Now that we’ve finished our move into the Chicory House, I
have for the first time in over two months been able to set up my preferred coding environment… with a proper monitor on a proper desk with a proper office chair. Bliss!
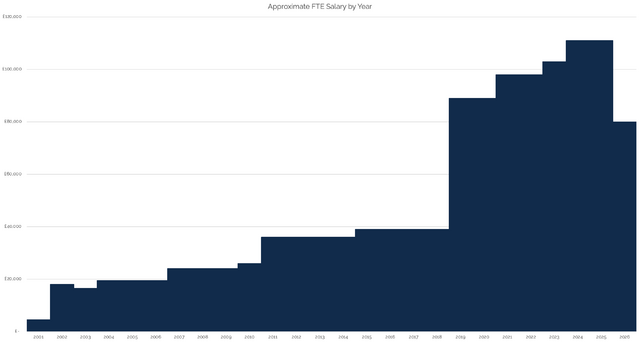
Jeremy Keith posted his salary history last week. I absolutely agree with him that employers exploit
the information gap created by opaque salary advertisement, and I think that our industry of software engineering is especially troublesome for this.
So I’m joining him (and others) in choosing to share my salary history. I’ve set up a new page for that purpose, but here’s the summary of its
initial state:
Understand
A few understandings and caveats:
For most of my career I’ve described myself as a “Full-Stack Web Applications Developer”, but I’ve worked outside of every one of those words and my job titles have often been more
like “CMS Developer” or “Senior Engineer (Security)”.
My specialisms and “hot areas” are security engineering, web standards, performance, and accessibility.
When I worked multiple roles in a year, I’ve tried to capture that, but there’ll be some fuzziness around the edges.
The salaries are rounded slightly to make nice readable numbers.
I’ve not always worked full-time; all salaries are translated into “full-time equivalent”1.
I’ve only included jobs that fit into my software engineering career2.
If the table below looks out-of-date then I’ve probably just forgotten to update it. Let me know!
Ad-hoc and hard to estimate.
Alongside full-time study.
What does that look like?
I drew a graph, but I don’t like it. Mostly because I don’t see my salary as a “goal” to aim for or some kind of “score”.
It’s gone up; it’s gone down; but I’ve always been more-motivated by what I’m working on, with whom, and for what purpose than I have been on how much I get paid for it3.
But if you want to see:
I’m not sure to what degree my career looks typical or not. But I guess I also don’t care! My motivations are probably different than most (a little-more idealistic, a little-less
capitalistic), I’d guess.
Footnotes
1 i.e. what I’d have earned if I had worked full-time
2 That summer back in college that I worked in a factory building striplight fittings
doesn’t appear, for example!
3 Pro-tip if you’re looking at my CV and pitching me an opportunity:
mention what you expect to pay, sure, but if you’re trying to win me over then tell me about the problems I’ll be solving and how that’ll make the world a better
place. That’s how you motivate me to accept your offer!
Towards the end of last week we picked up the keys to the Chicory House.1 We’ve now officially moved in to
the place we’ll be calling home for the next six months or so, while we wait for our Actual House to be repaired following our catastrophic flood in February.2
As part of my efforts to travel light, I use a pretty small
wallet – a lump of carbon fibre about the size of a deck of cards3 that contains my ID, bank cards, and – in pocket at the back – my essential keys.
Typically that’s my front door key and my bike lock key.
The keys tuck in around the back, but there’s a “hook” on the end to which additional keys can be ringed. Sometimes I hook up a second-factor hardware token to it when I’m travelling
with one.
And so when I received my front door key to the Chicory House, I had to decide: where does this key belong?
The obvious answer would have been to remove the front door key for my actual home from its special place within my wallet and replace it with the Chicory House’s front
door key. That’s the one I’ll need most-often for the foreseeable future, right? My regular front door key can move to the supplementary hook, on a ring, and/or be removed entirely and
taken with me only when I need to visit my uninhabitable home.
But that’s not what I did.
I didn’t even think about what I was doing until I noticed, afterwards, that I’d chosen to put the Chicory House key on the “supplementary keys” hook rather than in the “primary keys”
spot.
This made sense as an instinctive move: it’s where I’d clip on the key to any of the half-dozen or so AirBnBs I’ve lived in for the last couple of months, after all! But for a house I’m
going to live in for half a year or more it doesn’t seem so rational.
But I haven’t put it back. I think I’m keeping it this way. My regular key gets to keep its special spot because it represents the lost status quo and the aspiration to return. Sure,
it’s less-practical for me to keep it there, but its position is symbolic, not sensible.
Swapping the two over would feel like giving in: like caving to the inevitability of us being out of our home for an extended period. Keeping the key where it is means that every time I
put my hand in my pocket I’m reminded that the current arrangement is temporary; things will go back to normal. And that’s nice.4
2 The flood was exactly two months ago today, which makes today “F-Day plus 60”. We’ve
spent most of the intervening time hopping from AirBnB to AirBnB.
3 As somebody who often carries a deck of cards, this is a pretty-convenient size to me!
4 That said, the Chicory House is way better than most of the AirBnB’s we’ve
been living in, and I’m especially loving being able to sleep on my own familiar mattress again! While I wouldn’t want to live here forever like I’d be happy to in
the place we’ve called home since 2020, it’ll certainly suffice for the
immediate future. A stepping-stone back towards the lives we’d built before.
Today’s mission in what we’re calling the Chicory House – our home while our actual house gets repaired – was to unpack the kitchen. I think it’s looking pretty good!
The cardboard box you can see contains pans we brought with us that turn out to be incompatible with the induction hobs at the Chicory House, boo!
Next weekend’s mission will be to set myself up a workspace that isn’t the conservatory dining table. 😬
Second: the language “committed suicide” is no longer appropriate. Princess Irenedied by suicide. “Committed” is the language of crime. For example,
one does not commit a heart attack.
…
You clearly feel strongly enough about this point to have committed it to writing.
(It’s obviously a cause that you’re committed to.)
I’m being sarcastic, of course, but there’s a point. While (like most mental health services) I’m not a fan of describing the act of suicide as “committing” suicide today, for exactly
the reasons you describe, it might be appropriate for a historical case.
That’s all I meant to say in a comment… but then I ended up going down a rabbithole.
Let’s sidestep into an example: I said “John William Gott committed blasphemy in 1921” that would be fair. His actions would not be considered criminal today: he was initially
arrested for selling pamphlets containing information on birth control but prosecutors tacked on a blasphemy charge because they figured they could get it to stick too, based on the
ways his literature was presented. But legally-speaking, Gott committed a crime; a crime that doesn’t exist today.
It’s not a coincidence I’ve lumped jumped from suicide to blasphemy: both were formerly criminalised in Britain and her empire (among many other places) as a direct result of Christian
religious tradition: you can probably blame Thomas Aquinas!
Language about the criminality of past offences gets very complicated, very quickly. Some contemporary values seem to be considered so fundamental that it feels wrong to
describe historical convictions as criminal. In some of these cases, we see pardons issued or other admissions of fault by the state. Take for example in recent years the payment of
compensation to former military personnel who were dishonourably discharged on account of their sexuality. But I’m not aware of anything like that happening related to past convictions
of suicide (or, indeed, blasphemy).
With that grounding: let’s take a deeper dive into Irene Duleep Singh, to decide whether or not her suicide would have been considered criminal at the time (it was certainly considered
shameful and taboo, even within societies that would not have considered it illegal, but that’s not what I’m interested in right now). Irene died by suicide in the Principality f Monaco
in 1926. At that time, Monaco was a protectorate of France with less independence than it is today, and for the most part its legal system seems to have paralleled that in France. I
can’t find a specific provision for suicide in Monaco, so it would probably not have been illegal (suicide was illegal under the Ancien Régime but was
effectively decriminalised by its omission from the Napoleonic Penal Codes). So: no crime.
Buuuut… Irene could also be considered a citizen of Britain, or of India, or of British India. Suicide was illegal in the UK prior to 1961 and in India
until 2024 (wait, what? yeah, really… well… kinda; it’s complicated, especially after 2018). So in her capacity as a citizen or subject of the British Empire, her suicide was
criminal.
Both John William Gott and Irene Duleep Singh may well both have committed crimes that would not be considered crimes today. In both cases, their crimes were things that, in my opinion,
should never have been criminalised in the first place. But that doesn’t make the historical fact any less-true.
And that’s why I picked up on this one line for my comment.
I absolutely agree that it’s inappropriate and unhelpful to talk about somebody have “committed suicide” today. The language creates a barrier to help and support, which is what should
be offered to people experiencing suicidal thoughts! But I don’t see the harm in using it when discussing a historical case from a century ago, at a time at which suicide was seen very
differently.
So long as it’s appropriately contextualised for the audience, it seems to me to be harmless. By which I mean to say: not worthy of being called-out by your one-liner… and even-less
worthy of my having gone down this long and complicated rabbithole which, somehow, has involved translating old French legislation, digging through the history of Monaco, and learning
about the courts of the British Raj.
I guess what I mean to say is that if your intention was to nerdsnipe me with this line… then well played, Sundeep, well played.
I remain a huge fan of Kev Quirk‘s “100 Days To Offload” blogging challenge. And today… I just completed
it for the seventh time!
Kev announced that he completed it again today, too. He uses a different metric to me – he counts “posts over
a twelve month period”, while I use a slightly more-restrictive subset of that: “posts in a calendar year”, because it was easy for me to make a
table out of in my blog stats.
My blogging ramped up again this year, and on 24 August I shared a motivational poster with a funny twist, plus a pun at the intersection
between my sexuality and my preferred mode of transport.
* Pedants might claim this year was not a success for the reasons described above. Make your own mind up.
After some discussion, Kev agreed that the earliest year I could claim for was 2020.
Personally, I feel like each of the hundred posts should occur on different days too. This is relevant to me, because sometimes I post multiple times in a day… but it’s
100 days to offload, not 100 posts to offload, right?
Therefore, by my own restrictions… the soonest I could achieve the goal in a year would be the 100th day of the year. Right?
Which is today.
Which I just did. 🎉
I started the year knowing that I’d be trying to do this “speedrun”. What I didn’t realise was how hard it would be.
Unlike Alice, who spent the year reading papers with a pencil in hand, scribbling notes in the margins, getting confused, re-reading, looking things up, and slowly assembling a
working understanding of her corner of the field, Bob has been using an AI agent. When his supervisor sent him a paper to read, Bob asked the agent to summarize it. When he needed
to understand a new statistical method, he asked the agent to explain it. When his Python code broke, the agent debugged it. When the agent’s fix introduced a new bug, it debugged
that too. When it came time to write the paper, the agent wrote it. Bob’s weekly updates to his supervisor were indistinguishable from Alice’s. The questions were similar. The
progress was similar. The trajectory, from the outside, was identical.
Here’s where it gets interesting. If you are an administrator, a funding body, a hiring committee, or a metrics-obsessed department head, Alice and Bob had the same year. One paper
each. One set of minor revisions each. One solid contribution to the literature each. By every quantitative measure that the modern academy uses to assess the worth of a scientist,
they are interchangeable. We have built an entire evaluation system around counting things that can be counted, and it turns out that what actually matters is the one thing that
can’t be.
…
The strange thing is that we already know this. We have always known this. Every physics textbook ever written comes with exercises at the end of each chapter, and every physics
professor who has ever stood in front of a lecture hall has said the same thing: you cannot learn physics by watching someone else do it. You have to pick up the pencil. You have to
attempt the problem. You have to get it wrong, sit with the wrongness, and figure out where your reasoning broke. Reading the solution manual and nodding along feels like
understanding. It is not understanding. Every student who has tried to coast through a problem set by reading the solutions and then bombed the exam knows this in their bones. We
have centuries of accumulated pedagogical wisdom telling us that the attempt, including the failed attempt, is where the learning lives. And yet, somehow, when it comes to AI
agents, we’ve collectively decided that maybe this time it’s different. That maybe nodding at Claude’s output is a substitute for doing the calculation yourself. It isn’t. We knew
that before LLMs existed. We seem to have forgotten it the moment they became convenient.
Centuries of pedagogy, defeated by a chat window.
…
This piece by Minas Karamanis is excellent throughout, and if you’ve got the time to read it then you should. He’s a physics postdoc, and this post comes from his experience in his own
field, but I feel that the concerns he raises are more-widely valid, too.
In my field – of software engineering – I have similar concerns.
Let’s accept for a moment that an LLM significantly improves the useful output of a senior software engineer (which is very-definitely disputed, especially for the “10x” level of claims we often hear, but let’s just take it as-read for now). I’ve
experimented with LLM-supported development for years, in various capacities, and it certainly sometimes feels like they do (although it sometimes also feels like they have the
opposite effect!). But if it’s true, then yes: an experienced senior software engineer could conceivably increase their work performance by shepherding a flock of agents through a
variety of development tasks, “supervising” them and checking their work, getting them back on-course when they make mistakes, approving or rejecting their output, and stepping in to
manually fix things where the machines fail.
In this role, the engineer acts more like an engineering team lead, bringing their broad domain experience to maximise the output of those they manage. Except who they manage is… AI.
Again, let’s just accept all of the above for the sake of argument. If that’s all true… how do we make new senior developers?
Junior developers can use LLMs too. And those LLMs will make mistakes that the junior developer won’t catch, because the kinds of mistakes LLMs make are often hard to spot and require
significant experience to identify. But if they’re encouraged to use LLMs rather than making mistakes by hand and learning from them – to keep up, for example, or to meet corporate
policies – then these juniors will never gain the essential experience they’ll one day need. They’ll be disenfranchised of the opportunity to grow and learn.
It’s yet to be proven that more-sophisticated models will “solve” this problem, but my understanding is that issues like hallucination are fundamentally unsolvable: you might
get fewer hallucinations in a better model, but that just means that those hallucinations that slip through will be better-concealed and even harder to identify in code review
or happy-path testing.
Maybe – maybe – the trajectory of GPTs is infinite, and they’ll keep getting “smarter” to the point at which this doesn’t matter: programming genuinely will become a natural language
exercise, and nobody will need to write or understand code at all. In this possible reality, the LLMs will eventually develop entire new programming languages to best support their
work, and humans will simply express ideas and provide feedback on the outputs. But I’m very sceptical of that prediction: it’s my belief that the mechanisms by which LLMs work has a
fundamental ceiling – a capped level of sophistication that can be approached but never exceeded. And sure, maybe some other, different approach to AI might not have this
limitation, but if so then we haven’t invented it yet.
Which suggests that we will always need experienced engineers to shepherd our AIs. Which brings us back to the fundamental question: if everybody uses AI to code, how do we
make new senior developers?
I have other concerns about AI too, of course, some of which I’ve written about. But this one’s top-of-mind today, thanks to Minas’ excellent article. Go read it to learn more about how
physics research faces a similar threat… and, perhaps, consider how your own field might need to face this particular challenge.