A master class in how not to lead through crisis is continuing at Automattic and it’s rough to watch.
After Matt Mullenweg sets off a firestorm by going “scorched earth” on WP Engine in September 2024 (if you don’t know the story) there’s been one dodgy decision after another but through it all Mullenweg and his executive leadership team continue to blame the lack of success and growth on staffers.
- October 2024: Make two “alignment offers” to root out anyone willing to speak sense to the madness of all the wpdrama. 159 walk in the first and 25-30 in the second. Allege that the people who chose to leave were low performers and now that everyone left is aligned things should be better.
- January 10: Matt Mullenweg states “There are no layoffs plans at Automattic, in fact we’re hiring fairly aggressively and have done a number of acquisitions since this whole thing started, and have several more in the pipeline.”
- April 2: Automattic decimates its engineering staff in a 280 person layoff with a paltry severance compared to alignment offers. Leaving many feeling like suckers for showing loyalty.
- April 8: The engineering lead admits that just this week they are beginning to see the gaps in engineering due to the layoffs.
- April 9: CFO accidentally sends a Slack message to the entire company that not only do engineers need to, but all of Automattic needs to “Get aligned, get productive, deliver or move on”.
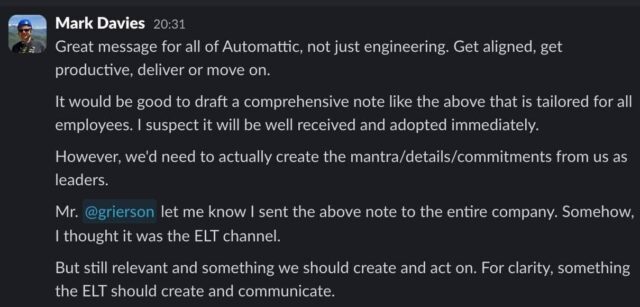
The call is coming from inside the house. The C-suite is failing to get real alignment because “leadership” at WordPress.com, Automattic, et al. is not, and have not, been leading. They haven’t come up with an executable commercial plan for the company in nearly a decade. Any time they get close to doing so a shiny object appears and **poof** on to something else.
A scathing take from Kellie Peterson, who was Head of Domains at Automattic until 2023. There’s lots more/similar spiciness from her on Bluesky, for those inclined to such things.
I’m not sure whether I agree with everything Kellie asserts, but I’ve certainly been concerned about the direction of management for the last year or more. Obviously I’d be biased, speaking as one of the “suckers” who showed loyalty in October only to get axed in April…
But for a while now it had felt like my reasons for staying were entirely about my love for (a) my team, a full half of whom got laid off at the same time as me anyway, and (b) WordPress and the open source space it represents, which of course Automattic’s been distancing itself from.
(Incidentally – and speaking of open source – I’m quite enjoying the freedom to contribute to ClassicPress, which previously might have been frowned-upon by my employers. I’ve not got a first PR out yet, but I’m hoping to soon.)
So yeah… while I might not agree with all of Kellie’s sentiments (here and elsewhere)… I increasingly find I have the clarity to agree with many of them. Automattic seems to be a ship on fire, right now, and I really feel for my friends and former colleagues still aboard what must be an increasingly polarised environment, seemingly steering hard towards profits over principles.












