Terence Eden wrote about his recent experience of IndieWebCamp Brighton, in which he mentioned that somebody – probably Jeremy Keith – had said, presumably to provoke discussion:
A blog post doesn’t need a title.
Terence disagrees, saying:
In a literal sense, he was wrong. The HTML specification makes it clear that the
<title>element is mandatory. All documents have title.
But I think that’s an overreach. After all, where is it written that a blog must be presented in HTML?
Non-HTML blogs
There are plenty of counter-examples already in existence, of course:
- Terence’s own no-ht.ml (now offline) demonstrated that a website needn’t use HTML1. This inspired my own “page with no code”, which worked by hiding content in CSS and loading the CSS using HTTP headers2.
-
theunderground.blog‘s content, with the exception of its homepage, is delivered entirely through an XML Atom feed. Atom feed entries do require
<title>s, of course, so that’s not the strongest counterexample! -
This blog is available over several media other than the Web. For example, you can read this blog post:
- in Gemtext3
- via Gemini at gemini://danq.me/posts/does-a-blog-have-to-be-html
- via Spartan at spartan://danq.me/posts/does-a-blog-have-to-be-html
- in plain text4
- via Gopher at gopher://danq.me/1/posts/does-a-blog-have-to-be-html
- via Finger at finger://does-a-blog-have-to-be-html@danq.me
- in Gemtext3
But perhaps we can do better…
A totally text/plain blog
We’ve looked at plain text, which as a format clearly does not have to have a title. Let’s go one step further and implement it. What we’d need is:
- A webserver configured to deliver plain text files by preference, e.g. by adding directives like
index index.txt;(for Nginx).5 - An index page listing posts by date and URL. Most browser won’t render these as “links” so users will have to copy-paste or re-type them, so let’s keep them short,
- Pages for each post at those URLs, presumably without any kind of “title” (just to prove a point), and
- An RSS feed: usually I use RSS as shorthand for all feed
types, but this time I really do mean RSS and not e.g. Atom because RSS, strangely, doesn’t require that an
<item>has a<title>!
I’ve implemented it! it’s at textplain.blog.
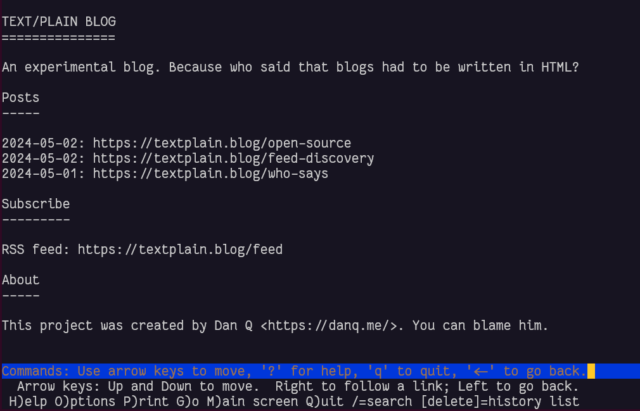
In the end I decided it’d benefit from being automated as sort-of a basic flat-file CMS, so I wrote it in PHP. All requests are routed by the webserver to the program, which determines whether they’re a request for the homepage, the RSS feed, or a valid individual post, and responds accordingly.
It annoys me that feed
discovery doesn’t work nicely when using a Link: header, at least not in any reader I tried. But apart from that, it seems pretty solid, despite its limitations. Is this,
perhaps, an argument for my .well-known/feeds proposal?
Anyway, I’ve open-sourced the entire thing in case it’s of any use to anybody at all, which is admittedly unlikely! Here’s the code.
Footnotes
1 no-ht.ml technically does use HTML, but the same content could easily be delivered with an appropriate non-HTML MIME type if he’d wanted.
2 Again, I suppose this technically required HTML, even if what was delivered was an empty file!
3 Gemtext is basically Markdown, and doesn’t require a title.
4 Plain text obviously doesn’t require a title.
5 There’s no requirement that default files served by webservers are HTML, although it’s highly-unsual for that not to be the case.
Chris Coyier started no-title posts in March- https://chriscoyier.net/2024/03/03/11148/
His starting point is that social content doesn’t have titles, and RSS doesn’t require it…
Now I’m wondering whether I could have implemented textplain.blog as a WordPress theme. 🤔
@Dan Oooooh!
Yes, it *should* be possible. I might have a play this weekend 😁
Here’s a plaintext functions.php
RSS not requiring a title element was a conscious design detail, much of its original form was expressed by Dave Winer (who is still writing at scripting.com) and he very strongly believed that the flexible nature of the “weblog” as we then called them meant short entries would most likely be self-descriptive and hence no separate title.
Therefore, RSS conveniently is flexible to be appropriate for much of the social, micro blogging type content we now see and also the full blown full-text blog entries. Given the recent move (resurgence?) toward POSSE, I’m encouraged to see adoptees like Molly White push forward and adopt/exploit this. ATOMs more rigorous XML schema looks a little inflexible and prescriptive sometimes …
Thanks @CraigM. I work adjacent to Dave Winer; I should ping him to let him know about this conversation!
I doubt there will be much call for it but, off the back of this, I included a check for Link http headers in my reader. It found the feed when giving it https://textplain.blog/ but, for some reason, refuses to bring in the posts. Not sure why.
@Colin Walker: perhaps you’re requiring a title in the item?
@Dan: nope, it’s coded not to need them as per the spec.
Thanks to @danq for the heads up on this thread. I think @craigm pretty much nails it.
If Google Reader had handled untitled posts more gracefully we’d be in a much better place today.
Their choice to require titles meant we have had a fracture, on one side — social web and on the other feed readers.
A lot of us now are trying to get rid of that separation.
For example, in FeedLand we handle titleless posts as well as titled posts.
Also RSS 2.0 and 0.91 didn’t anticipate that there would be untitled posts, there were untitled posts at the time. UserLand’s blogging products did not require titles for posts, they were organized so writers had the choice whether or not to add a title. Therefore any format we supported at UserLand had to have the option.
Have a look at the home page of scripting.com right now, you’ll see a mix of titled and untitled posts. It’s been that way for a long time. ;-)
I’ve gone a little overboard!
You can now add .txt the end of most URls on my blog and get a plaintext version of the page.